机器学习正则化线性模型和模型保存
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习正则化线性模型和模型保存相关的知识,希望对你有一定的参考价值。
目录
1 正则化线性模型
1.1 岭回归
岭回归(Ridge Regression ,又名 Tikhonov regularization)是线性回归的正则化版本,即在原来的线性回归的 cost function 中添加正则项(regularization term):
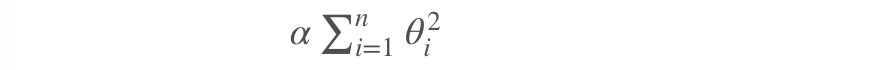
以达到在拟合数据的同时,使模型权重尽可能小的目的,岭回归代价函数:
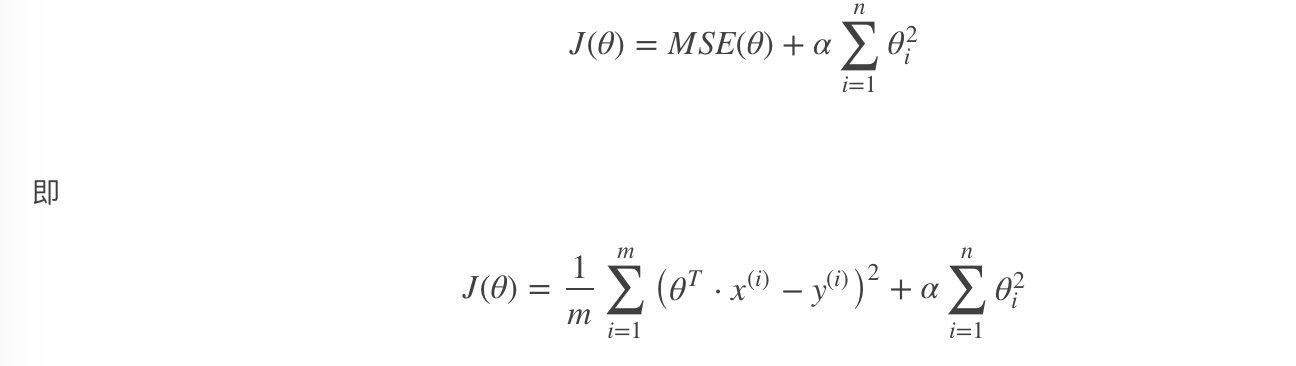
- α=0:岭回归退化为线性回归
1.2 Lasso 回归
Lasso 回归(Lasso Regression)是线性回归的另一种正则化版本,正则项为权值向量的ℓ1范数。
Lasso回归的代价函数 :
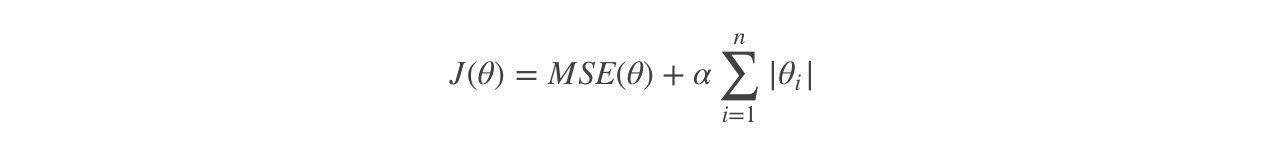
【注意 】
- Lasso Regression 的代价函数在 θi=0处是不可导的.
- 解决方法:在θi=0处用一个次梯度向量(subgradient vector)代替梯度,如下式
- Lasso Regression 的次梯度向量

Lasso Regression 有一个很重要的性质是:倾向于完全消除不重要的权重。
例如:当α 取值相对较大时,高阶多项式退化为二次甚至是线性:高阶多项式特征的权重被置为0。
也就是说,Lasso Regression 能够自动进行特征选择,并输出一个稀疏模型(只有少数特征的权重是非零的)。
1.3 弹性网络
弹性网络(Elastic Net)在岭回归和Lasso回归中进行了折中,通过 混合比(mix ratio) r 进行控制:
- r=0:弹性网络变为岭回归
- r=1:弹性网络便为Lasso回归
弹性网络的代价函数 :
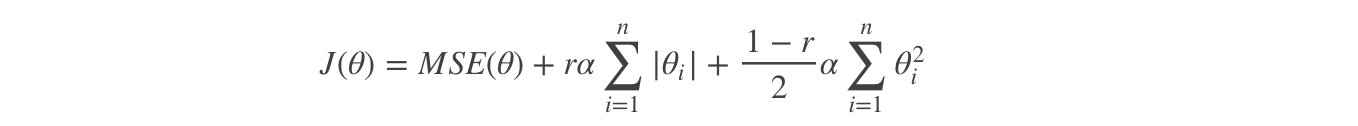
一般来说,我们应避免使用朴素线性回归,而应对模型进行一定的正则化处理,那如何选择正则化方法呢?
小结:
- 常用:岭回归
- 假设只有少部分特征是有用的:
- 弹性网络
- Lasso
- 一般来说,弹性网络的使用更为广泛。因为在特征维度高于训练样本数,或者特征是强相关的情况下,Lasso回归的表现不太稳定。
- api:
from sklearn.linear_model import Ridge, ElasticNet, Lasso
1.4 Early Stopping
Early Stopping 也是正则化迭代学习的方法之一。
其做法为:在验证错误率达到最小值的时候停止训练。
1.5 小结
- Ridge Regression 岭回归
- 就是把系数添加平方项
- 然后限制系数值的大小
- α值越小,系数值越大,α越大,系数值越小
- Lasso 回归
- 对系数值进行绝对值处理
- 由于绝对值在顶点处不可导,所以进行计算的过程中产生很多0,最后得到结果为:稀疏矩阵
- Elastic Net 弹性网络
- 是前两个内容的综合
- 设置了一个r,如果r=0–岭回归;r=1–Lasso回归
- Early stopping
- 通过限制错误率的阈值,进行停止
2 线性回归的改进-岭回归
2.1 API
- sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True,solver=“auto”, normalize=False)
- 具有l2正则化的线性回归
- alpha:正则化力度,也叫 λ
- solver:会根据数据自动选择优化方法
- sag:如果数据集、特征都比较大,选择该随机梯度下降优化(SAG)
- normalize:数据是否进行标准化
- normalize=False:可以在fit之前调用preprocessing.StandardScaler标准化数据
- Ridge.coef_:回归权重
- Ridge.intercept_:回归偏置
Ridge方法相当于SGDRegressor(penalty=‘l2’, loss=“squared_loss”),只不过SGDRegressor实现了一个普通的随机梯度下降学习,推荐使用Ridge(实现了SAG)
- sklearn.linear_model.RidgeCV(_BaseRidgeCV, RegressorMixin)
- 具有l2正则化的线性回归,可以进行交叉验证
- coef_:回归系数
class _BaseRidgeCV(LinearModel):
def __init__(self, alphas=(0.1, 1.0, 10.0),
fit_intercept=True, normalize=False,scoring=None,
cv=None, gcv_mode=None,
store_cv_values=False):
2.2 正则化程度变化
观察正则化程度的变化,对结果的影响?
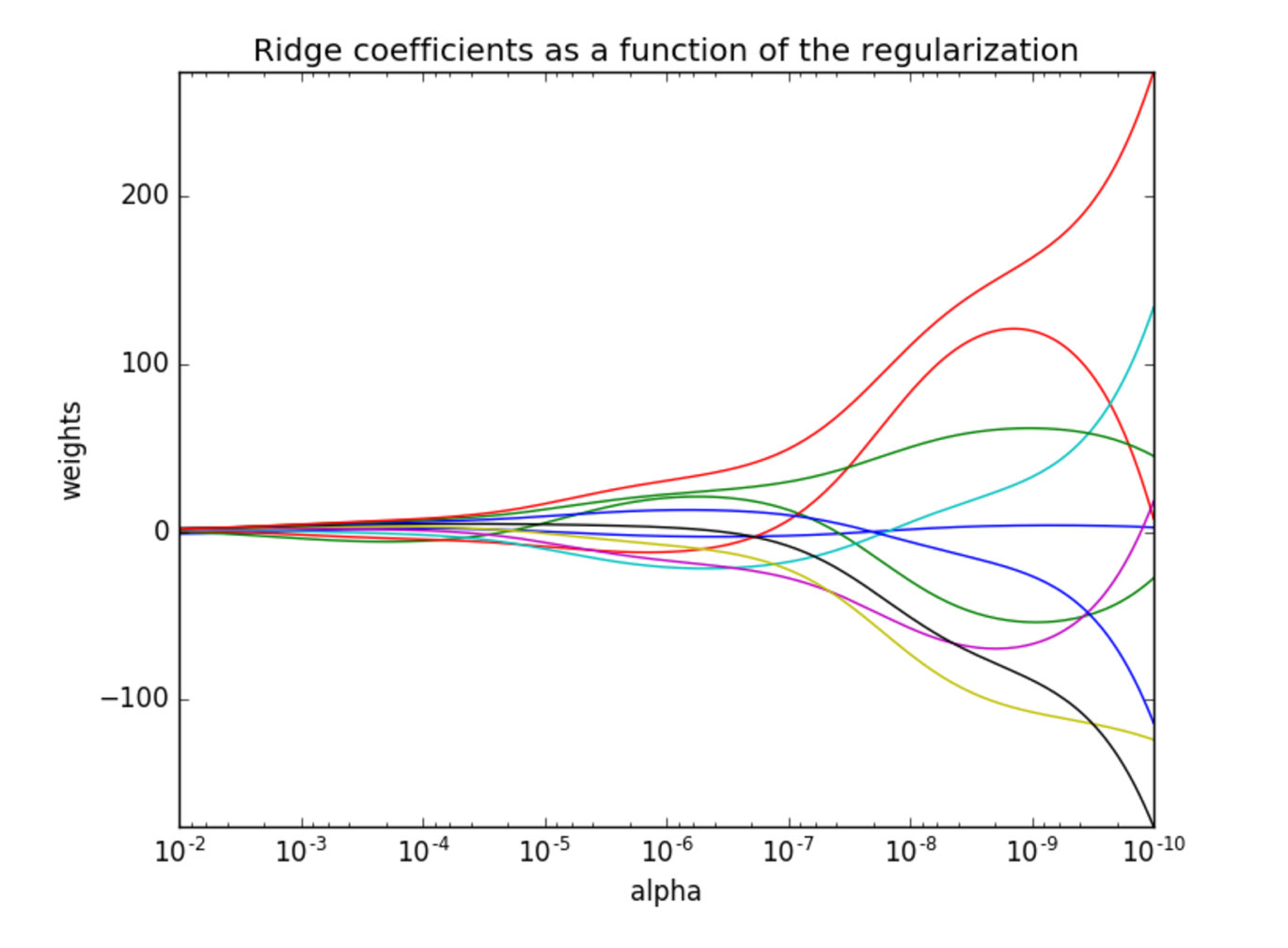
- 正则化力度越大,权重系数会越小
- 正则化力度越小,权重系数会越大
2.3 波士顿房价预测
def linear_model3():
"""
线性回归:岭回归
:return:
"""
# 1.获取数据
data = load_boston()
# 2.数据集划分
x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, random_state=22)
# 3.特征工程-标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
# 4.机器学习-线性回归(岭回归)
estimator = Ridge(alpha=1)
# estimator = RidgeCV(alphas=(0.1, 1, 10))
estimator.fit(x_train, y_train)
# 5.模型评估
# 5.1 获取系数等值
y_predict = estimator.predict(x_test)
print("预测值为:\\n", y_predict)
print("模型中的系数为:\\n", estimator.coef_)
print("模型中的偏置为:\\n", estimator.intercept_)
# 5.2 评价
# 均方误差
error = mean_squared_error(y_test, y_predict)
print("误差为:\\n", error)
2.4 小结
- sklearn.linear_model.Ridge(alpha=1.0, fit_intercept=True,solver=“auto”, normalize=False)【知道】
- 具有l2正则化的线性回归
- alpha – 正则化
- 正则化力度越大,权重系数会越小
- 正则化力度越小,权重系数会越大
- normalize
- 默认封装了,对数据进行标准化处理
3 模型的保存和加载
3.1 sklearn模型的保存和加载API
- from sklearn.externals import joblib
- 保存:joblib.dump(estimator, ‘test.pkl’)
- 加载:estimator = joblib.load(‘test.pkl’)
3.2 线性回归的模型保存加载案例
def load_dump_demo():
"""
模型保存和加载
:return:
"""
# 1.获取数据
data = load_boston()
# 2.数据集划分
x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, random_state=22)
# 3.特征工程-标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
# 4.机器学习-线性回归(岭回归)
# # 4.1 模型训练
# estimator = Ridge(alpha=1)
# estimator.fit(x_train, y_train)
#
# # 4.2 模型保存
# joblib.dump(estimator, "./data/test.pkl")
# 4.3 模型加载
estimator = joblib.load("./data/test.pkl")
# 5.模型评估
# 5.1 获取系数等值
y_predict = estimator.predict(x_test)
print("预测值为:\\n", y_predict)
print("模型中的系数为:\\n", estimator.coef_)
print("模型中的偏置为:\\n", estimator.intercept_)
# 5.2 评价
# 均方误差
error = mean_squared_error(y_test, y_predict)
print("误差为:\\n", error)
3.3 tips
如果你在学习过程中,发现使用上面方法报如下错误:
ImportError: cannot import name 'joblib' from 'sklearn.externals' (/Library/Python/3.7/site-packages/sklearn/externals/__init__.py)
这是因为scikit-learn版本在0.21之后,无法使用from sklearn.externals import joblib进行导入,你安装的scikit-learn版本有可能是最新版本。如果需要保存模块,可以使用:
# 安装
pip install joblib
# 导入
import joblib
安装joblib,然后使用joblib.load进行加载;使用joblib.dump进行保存
参考:https://scikit-learn.org/stable/modules/model_persistence.html
3.4 小结
- sklearn.externals import joblib【知道】
- 保存:joblib.dump(estimator, ‘test.pkl’)
- 加载:estimator = joblib.load(‘test.pkl’)
- 注意:
- 1.保存文件,后缀名是**.pkl
- 2.加载模型是需要通过一个变量进行承接
以上是关于机器学习正则化线性模型和模型保存的主要内容,如果未能解决你的问题,请参考以下文章