C++——WebServer服务器项目
Posted wrdoct
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++——WebServer服务器项目相关的知识,希望对你有一定的参考价值。
项目场景:
C++——WebServer服务器编程
项目搭建
(1)配置虚拟机,下载XShell、Xftp以及windows版本的VScode;
(2)安装SSH:
sudo apt install openssh-server
(3)在XShell中配置会话以连接到虚拟机,VScode中配置远程SSH;
(4)安装数据库:
sudo apt install mysql-server
sudo apt install mysql-client
sudo apt install libmysqlclient-dev
查看账号以及密码以登录数据库:
sudo cat /etc/mysql/debian.cnf
之后修改密码。。。遇到修改密码问题参考mysql debian-sys-maint_关于mysql安装后登不进的问题–ERROR 1045 (28000): Access denied for user 'debian-sys-main…
(5)安装g++、gcc、make等工具:
sudo apt install build-essential
(6)在当前目录(有Makefile文件的目录):
make
生成的可执行文件在bin目录下。
在终端输入:
bin/server
打开浏览器,输入自己虚拟机的IP地址以及端口号1316。

知识点
1.Linux相关
(1)常用命令:
ifconfig //查看网络配置和IP地址
ps aux //查看进程
ps -ef | grep ssh //ps查看进程信息 |管道符 grep过滤
top //实时显示进程动态
ulimit -a //查看进程id、状态、可使用的资源上限
kill -l //列出所有信号
netstat -anp //查看网络状态
cd //返回根目录
cd .. //返回上一级目录
pwd //查看当前目录
ll //查看当前目录下各文件(夹)的详细信息(权限、大小、修改时间等)
chmod //更改权限
mkdir //新建文件夹
rename //重命名文件夹
rmdir //删除文件夹
mv //移动 改名
ls //显示当前目录下的所有文件(夹)
cp //复制
rm //删除 -r 删除文件夹
touch //创建文件
cat //显示文件内容
tree //查看树形的文件分布
echo //用于字符串的输出
clear //清除屏幕 ctrl+l
man //使用手册
history //查看历史使用命令
free -m //查看内存使用情况
gcc -v //查看gcc版本
g++ -v //查看g++版本
(2)程序的运行过程:
预处理–>编译–>汇编–>链接。
预处理-E:宏替换、去掉注释、头文件拷贝生成.i文件;
编译不汇编-S生成.s文件,编译汇编-c:语法检查生成.o文件;
链接整合定义生成可执行程序.out文件。
【注】声明作用在编译阶段,定义(装在链接库里)作用在链接阶段。
(3)Makefile定义了一系列规则,通过make执行——>自动化编译。
(4)gdb调试:
-g //调试 在可执行文件中加入源代码信息
-D //在编译时指定一个宏
-w //不生成警告
-Wall //生成所有警告
-On //优化级别 n:1 2 3
-l //指定使用的库
-L //库路径
-std //-std==c++11
-I //指定include包含搜索的目录
终端输入
g++ -g -Wall main.cpp -o main
gdb main
进入调试模式,命令:
l 行号 //查看代码
b 行号 //打断点
i break //查看断点信息
d 断点编号 //删除断点
start //程序停在第一行
run //遇到断点停止
c //继续,到下一个断点停
s //向下单步调试(会进入函数体)
finish //跳出函数体
n //向下直行一行代码(不进入函数体)
p 变量名 //打印变量的值
ptype 变量名 //打印变量类型
【注】多进程下的GDB调试:
set follow-fork-mode child 调试子进程
set follow-fork-mode parent 调试父进程
(5)静态库(lib/a)和动态库(dll/so):
静态库在链接阶段复制到程序中(速度快,占内存)
动态库在运行时由系统动态加载到程序中(速度慢,共享库)
静态库:
g++得到.o文件
ar rcs libxxx.a xxx.o
动态库:
g++ -c -fpic xxx.cpp
g++ -shared xxx.o -o libxxx.so
//
ldd 可执行文件名称 //查看动态库的依赖关系
添加环境变量:
env //查看当前系统所有的环境变量
echo $LD_LIBRARY_PATH //查看某个环境变量的值
//临时添加环境变量
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/目录路径/
//永久添加环境变量
vim .bashrc //.bashrc是用户级的配置文件
再将export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/目录路径/ 加进去
. .bashrc 或者 source .bashrc
2.多进程
(1)程序是包含一系列信息的文件,这些信息描述了如何在运行时创建一个进程。
进程是正在运行的程序的实例。
(2)并行:同一时刻,有多条指令在多个处理器上同时执行。
并发:同一时刻,只能有一条指令执行,但多个进程指令被快速轮换执行,宏观上同时执行,微观上并不是同时执行,只是把时间片分成若干段,使多个进程快速交替的执行
(3)进程控制块PCB:为了管理进程,内核必须对每个进程所作的事情进行清楚的描述。
Linux的进程控制块是task_struct结构体。
里面主要有:
进程id、状态、可使用资源的上限;
切换时要保存和恢复的CPU寄存器;
虚拟地址空间信息;
终端信息、信号相关信息;
当前工作目录;
umask掩码;
文件描述符表;
用户id、组id、会话和进程组。
(4)在终端输入ulimit -a可以查看资源上限。
可以使用ulimit -s 具体数值进行修改。
(5)进程状态:
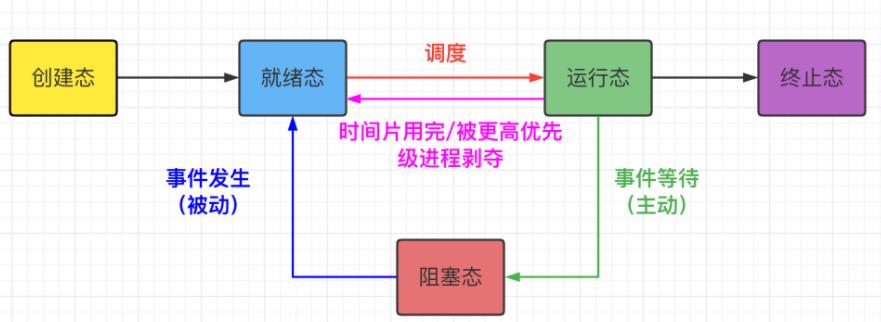
新建态:创建进程;
终止态:终止进程。
(6)
top //实时显示进程动态
kill 信号值 PID //杀死进程
kill -l //列出所有信号
kill -9 PID
(7)除了init进程外,每个进程都有父进程PPID。
pid_t getpid(void);//获取当前进程号
pid_t getppid(void);//获取当前进程的父进程号
pid_t getpgid(pid_t pid);//如果传None获取当前进程的进程组id,如果传进程号获取进程号的进程组ID
pid_t fork(void); //创建进程 //读时共享 写时拷贝 //会返回两次
//pid_t pid = fork(); //pid > 0时,执行父进程代码,此时的pid为子进程ID;pid = 0时,执行子进程代码;
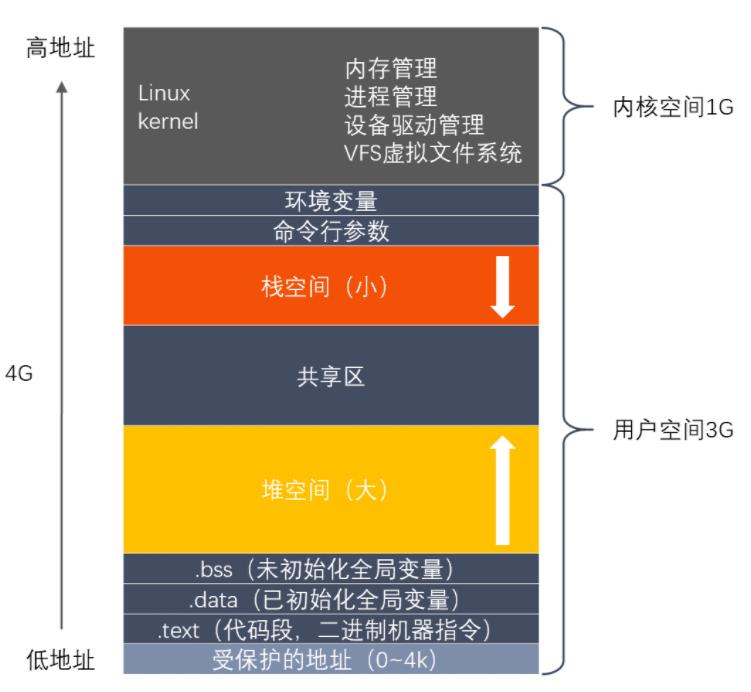
在虚拟地址空间的视角下,fork()函数相当于把父进程的虚拟地址空间clone给子进程。fork()以后,子进程用户区数据和父进程一样。内核区也会拷贝过来,但是PID不一样。但是两个虚拟地址空间是相互独立的。

(8)exec 函数族的作用是根据指定的文件名找到可执行文件,并用它来取代调用进程的内容。换句话说,就是在调用进程内部执行一个可执行文件。

(9)进程的退出:
exit(0); //会刷新I/O缓冲
_exit(0); //不会刷新I/O缓冲
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main()
printf("hello\\n");
printf("world");
// exit(0); //输出hello world
_exit(0); //输出hello
return 0;
(10)孤儿进程和僵尸进程:
孤儿进程:父死子没死,会被init进程接管回收;
僵尸进程:父活子死,无法杀死,可以杀死父进程让init进程接管回收。也可以让内核给父进程一个SIGCHLD信号让其回收其子。
(11)进程退出:
wait(); //一次只能清理一个子进程
waitpid();
(12)进程间的通信(IPC):数据传输、通知事件、资源共享、进程控制。
信号; //Unix
管道; //Unix
有名管道(FIFO); //Unix
消息队列;
共享内存;
信号量;
Socket套接字。
(13)管道:
用于有亲缘关系的进程间通信;
一个管道是一个字节流;
通过管道传递的数据是顺序的,从管道中读取出来字节的顺序和被写入管道的顺序是完全一样的(类似一个队列);
管道中数据传递方向是单向的,一端写入一端读取,是半双工的;
管道读数据是一次性的。
终端命令:
ls | wc -l //wc——统计文件数目
ulimit -a //查看管道缓冲大小
函数:
int pipe(int pipefd[2]);//创建一个匿名管道,用来进程间通信。
long fpathconf(int fd, int name);//查看管道缓冲大小
【注】为什么管道用于有亲缘关系的进程间通信(为什么亲缘关系间的进程能通过管道通信)?
因为父进程fork出来一个子进程,会把虚拟地址空间复制一份,父进程中的这个虚拟地址空间中有一个文件描述符表,指向读端和写端,那么子进程复制出来也有一个文件描述符表,指向读端和写端,所以能进行通信。
【注】为什么要一个关闭读端一个要关闭写端?
为了避免父(子)进程写之后父(子)进程又读。
(14)有名管道FIFO:
有名管道提供了一个路径名与之关联,所以FIFO创建的进程不存在亲缘关系的限制,进程只要能访问该路径,就能通过FIFO相互通信。
终端命令:
mkfifo 名字 //创建FIFO管道
函数:
int mkfifo(const char *pathname, mode_t mode); //创建FIFO管道
管道的读写特点:
读管道:
管道中有数据:
read返回实际读到的字节数
管道中无数据:
写端被全部关闭,read返回0(相当于读到文件的末尾)
写端没有完全关闭,read阻塞等待
写管道:
读端全部被关闭:
进程异常终止(进程收到SIGPIPE信号)
读端没有全部关闭:
管道已满,write阻塞
管道没有满,write将数据写入,并返回实际写入的字节数
(15)内存映射:
(I/O)将磁盘文件数据映射到内存,通过修改内存可修改文件。
内存映射实现的进程通信是非阻塞的。
函数:
//将一个文件或者设备的数据映射到内存中
void *mmap(void *addr, size_t length, int prot, int flags,int fd, off_t offset);
//释放内存映射
int munmap(void *addr, size_t length);
(16)共享内存:
共享内存允许两个或者多个进程共享物理内存的同一块区域(通常被称为段)。
无需内核介入。
终端命令:
ipcs -a //打印所有ipc信息
ipcs -m //打印共享内存ipc信息
ipcs -q //打印消息队列ipc信息
ipcs -s //打印信号ipc信息
ipcrm -M shmkey //移除shmkey创建的共享内存段
ipcrm -m shmid //移除shmid标识的共享内存段
ipcrm -Q msgkey //移除msgkey创建的消息队列
ipcrm -q msgid //移除msgid标识的消息队列
ipcrm -S semkey //移除semkey创建的信号
ipcrm -s semid //移除semid标识的信号
函数:
//创建一个新的共享内存段,或者获取一个既有的共享内存段的标识。新创建的内存段中的数据都会被初始化为0
int shmget(key_t key, size_t size, int shmflg);
//和当前的进程进行关联
void *shmat(int shmid, const void *shmaddr, int shmflg);
//通信 addr
//释放:
//解除当前进程和共享内存的关联
int shmdt(const void *shmaddr);
//删除共享内存,只调用一次,所有的关联进程都解除了关联才调用
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
操作系统如何知道一块共享内存被多少个进程关联?
答: 共享内存维护了一个结构体struct shmid_ds,
这个结构体中有一个成员 shm_nattch,
shm_nattach 记录了关联的进程个数
(17)信号:
信号是 Linux 进程间通信的最古老的方式之一,是事件发生时对进程的通知机制,有时也称之为软件中断,它是在软件层次上对中断机制的一种模拟,是一种异步通信的方式。
信号可以导致一个正在运行的进程被另一个正在运行的异步进程中断,转而处理某一个突发事件。
信号的特点:
简单;不能携带大量信息;满足某个特定条件才发送;优先级比较高。
终端命令:
kill -l //查看所有信号
常用的信号:
SIGINT //终止进程——ctrl+C
SIGQUIT //终止进程——ctrl+\\
SIGKILL //杀死进程
SIGCSTOP //停止进程
SIGCONT //继续进程
信号的 5 种默认处理动作:
Term 终止进程
Ign 当前进程忽略掉这个信号
Core 终止进程,并生成一个Core文件,用于保存错误信息 //
Stop 暂停当前进程
Cont 继续执行当前被暂停的进程
【注】Core的使用:
ulimit -a
ulimit -c unlimited //更改可使用的资源上限
g++ ./a.out -g
gdb a.out core-file core //查看core文件的错误信息
信号的状态:产生、未决(信号产生了没被处理)、阻塞(阻塞信号被处理,不阻塞信号产生)。
int kill(pid_t pid, int sig);//给任何的进程或者进程组pid, 发送任何的信号 sig
int raise(int sig);//给当前进程发送信号
void abort(void);//发送SIGABRT信号给当前的进程,杀死当前进程
//设置定时器(闹钟)。函数调用,开始倒计时,当倒计时为0的时候,函数会给当前的进程发送一个信号:SIGALARM,终止当前进程
unsigned int alarm(unsigned int seconds);
alarm(0); //取消定时器
//设置定时器(闹钟)。可以替代alarm函数。精度微妙us,可以实现周期性定时(每隔几秒钟做一件事)
int setitimer(int which, const struct itimerval *new_value, struct itimerval *old_value);
//设置某个信号的捕捉行为
sighandler_t signal(int signum, sighandler_t handler);
//检查或者改变信号的处理。信号捕捉
int sigaction(int signum, const struct sigaction *act, struct sigaction *oldact);
【注】使用SIGCHLD信号解决僵尸进程的问题。
多个信号可使用一个称之为信号集的数据结构来表示。
int sigemptyset(sigset_t *set);//清空信号集中的数据,将信号集中的所有的标志位置为0
int sigfillset(sigset_t *set);//将信号集中的所有的标志位置为1
int sigaddset(sigset_t *set, int signum);//设置信号集中的某一个信号对应的标志位为1,表示阻塞这个信号
int sigdelset(sigset_t *set, int signum);//设置信号集中的某一个信号对应的标志位为0,表示不阻塞这个信号
int sigismember(const sigset_t *set, int signum);//判断某个信号是否阻塞
int sigprocmask(int how, const sigset_t *set, sigset_t *oldset);//将自定义信号集中的数据设置到内核中(设置阻塞,解除阻塞,替换)
int sigpending(sigset_t *set);//获取内核中的未决信号集
(18)守护进程:在后台运行,不会被ctrl+C停止。一般采用以 d 结尾的名字。
3.多线程
(1)多线程共享虚拟地址空间,其中栈空间和.text(代码段)被每个线程瓜分(不共享),其他都是共享的资源。
线程id、error变量、线程特有数据等也不共享。
(2)
//创建一个子线程
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);
//终止一个线程,在哪个线程中调用,就表示终止哪个线程
void pthread_exit(void *retval);
//获取当前的线程的线程ID
pthread_t pthread_self(void);
//比较两个线程ID是否相等
int pthread_equal(pthread_t t1, pthread_t t2);
//和一个已经终止的线程进行连接(回收线程)
int pthread_join(pthread_t thread, void **retval);
//分离一个线程。被分离的线程在终止的时候,会自动释放资源返回给系统
int pthread_detach(pthread_t thread);
//取消线程(让线程终止)
int pthread_cancel(pthread_t thread);
(3)线程同步/线程安全:
原因:相较于进程需要通过各种IPC来共享信息进行通信,线程可以很方便的使用全局变量来共享信息。
【注】临界区是指访问某一共享资源的代码片段,并且这段代码的执行应为原子操作,不会被打断。一次仅允许一个线程使用的共享资源。
概念:当有一个线程在对内存进行操作时,其他线程都不可以对这个内存地址进行操作,直到该线程完成操作,其他线程才能对该内存地址进行操作,而其他线程则处于等待状态。
线程同步的实现一般有下面5种:互斥量,读写锁,条件变量,自旋锁,屏障。
//初始化互斥量
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr);
//释放互斥量的资源
int pthread_mutex_destroy(pthread_mutex_t *mutex);
//加锁,阻塞的,如果有一个线程加锁了,那么其他的线程只能阻塞等待
int pthread_mutex_lock(pthread_mutex_t *mutex);
//尝试加锁,如果加锁失败,不会阻塞,会直接返回。
int pthread_mutex_trylock(pthread_mutex_t *mutex);
//解锁 -
int pthread_mutex_unlock(pthread_mutex_t *mutex);
(4)死锁:忘记释放锁;多次加锁;多线程多锁,抢占锁资源。
产生死锁的四个必要条件:
互斥条件:一个资源每次只能被一个进程使用。
请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
不剥夺条件: 进程已获得的资源,在末使用完之前,不能强行剥夺。
循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。存在一个进程等待序列P1,P2,…,Pn,其中P1等待P2所占有的某一资源,P2等待P3所占有的某一资源,……,而Pn等待P1所占有的的某一资源,形成一个进程循环等待环。
解决死锁的四个方式:
鸵鸟算法(直接忽略该问题)。
检测死锁并且恢复(检测与解除策略)。
仔细地对资源进行动态分配,以避免死锁(避免策略)。
通过破除死锁四个必要条件之一,来防止死锁产生(预防策略)
(5)生产者与消费者模型:
条件变量:
//初始化一个条件变量
int pthread_cond_init(pthread_cond_t *restrict cond, const pthread_condattr_t *restrict attr);
//释放一个条件变量
int pthread_cond_destroy(pthread_cond_t *cond);
//等待,调用了该函数,线程会阻塞。
int pthread_cond_wait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex);
//等待多长时间,调用了这个函数,线程会阻塞,直到指定的时间结束。
int pthread_cond_timedwait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex, const struct timespec *restrict abstime);
//唤醒一个或者多个等待的线程
int pthread_cond_signal(pthread_cond_t *cond);
//唤醒所有的等待的线程
int pthread_cond_broadcast(pthread_cond_t *cond);
信号量:互斥锁+条件变量
//初始化信号量
int sem_init(sem_t *sem, int pshared, unsigned int value);
//释放资源
int sem_destroy(sem_t *sem);
//对信号量加锁,调用一次对信号量的值-1,如果值为0,就阻塞
int sem_wait(sem_t *sem);
//对信号量解锁,调用一次对信号量的值+1
int sem_post(sem_t *sem);
(6)读写锁:
读多写少时使用读写锁,提高效率。
有线程在读,其他线程也可读,不能写;
有线程在写,其他线程不能读,不能写;
写是独占的,优先级高。
4.网络编程
(1)网卡功能:数据的封装与解封装;链路管理;数据编码与译码。
(2)MAC地址:48位(6个字节)。
IP地址:32位(4个字节)。
(3)特殊地址:
当前主机:0.0.0.0
当前子网的广播地址:255.255.255.255
回路测试:127.0.0.1~127.255.255.255
(4)子网掩码:将IP地址分为网络地址和主机地址两部分。
【注】网络号:IP与子网掩码&
主机号:子网掩码取反与IP&
子网数:首先根据第一个字节判断是哪个类:
<=127:A——255.0.0.0
<=191:B——255.255.0.0
<223:C——255.255.255.0
看子网掩码比默认的多几个1,就是2的几次方个子网数;
主机数:后面的0有几个,就是2的几次方主机数。
(5)端口:网络通信中应用程序对外的一个接口,2个字节。
周知端口:0~1023
注册端口:1024~49151
动态端口:49152~65535
(6)网络模型;TCP/IP协议族;UDP、TCP、IP、以太网帧、ARP的报文头部结构。
(7)上层使用下层提供的服务,通过封装实现。
从下往上进行解析:分用。
(8)socket套接字:一套通信的接口。
socket地址——结构体。
(9)字节序:
大端(网络字节序):整数的高位字节在内存的低地址处。
小端:整数的高位字节在内存的高地址处。
(10)TCP:可靠、面向连接、字节流、传输层。
三次握手目的:为了让双方都知道可以互相通信。
TCP的状态转换。
(11)服务端的端口复用:防止服务器重启时之前绑定的端口还未释放;程序突然退出而系统没有释放端口。
(12)通信并发:多进程/多线程解决。
一个父进程,多个子进程;
父进程负责等待,并接收客户端连接;
子进程完成通信,每接收一个客户端连接,就创建一个子进程用于通信。
缺点:耗费资源。
(13)I/O多路复用技术:使程序能同时监听多个文件描述符,提高程序性能。分为阻塞(BIO)和非阻塞(NIO)。
select、poll、epoll。
具体参考这篇答应我,这次搞懂 I/O 多路复用!
epoll的工作模式:LT水平触发、ET边缘触发(减少了epoll事件被重复触发的次数)。
5.补充(阻塞/非阻塞、同步/异步、HTTP、服务器编程、有限状态机、正则、压力测试等)
(1)阻塞/非阻塞、同步/异步(网络I/O):
【注】磁盘IO(I:从磁盘读入内存;O:从内存写入磁盘)。网络IO。
在处理 IO 的时候,阻塞和非阻塞都是同步 IO,只有使用了特殊的 API 才是异步 IO。
一个典型的网络IO接口调用,分为两个阶段,分别是 “数据就绪” 和 “数据读写”,数据就绪阶段分为阻塞和非阻塞,表现得结果就是,阻塞当前线程或是直接返回。数据读写阶段分为同步和异步。
同步表示A向B请求调用一个网络IO接口时(或者调用某个业务逻辑API接口时),数据的读写都是 由请求方A自己来完成的(不管是阻塞还是非阻塞)——效率低,编程简单,消耗用户时间。
异步表示A向B请求调用一个网络IO接口时 (或者调用某个业务逻辑API接口时),向B传入请求的事件(fd)以及事件发生时通知的方式(sigio),A就可以处理其它逻辑了,当B监听到事件处理完成后,会用事先约定好的通知方式,通知A处理结果——效率高,编程复杂,不消耗用户时间。

(2)Unix/Linux的五种IO模型:
1、阻塞 blocking:
等待数据(中间不能做其他事);拷贝到用户区。
2、非阻塞 non-blocking(NIO):
等待数据(中间能做其他事);拷贝到用户区;
返回-1带上EAGAIN;
线程不会挂起,系统调用次数多,影响性能。
3、IO复用(IO multiplexing):
一个进程检测多个IO操作;
select、poll、epoll。
4、信号驱动(signal-driven):
内核在第一个阶段是异步,在第二个阶段是同步。
5、异步:
===========================================================================
(3)HTTP协议:
1.客户端连接到Web服务器;
2.发送HTTP请求;
3.服务器接受请求并返回HTTP响应;
4.释放TCP连接;
5.客户端浏览器解析html内容。
(4)HTTP请求报文和响应报文格式。
(5)HTTP请求方法:
GET:显示请求。
POST:提交数据。
HEAD:请求资源。
PUT:上传资源。
(6)HTTP状态码:
1xx:请求已被接收,正在处理
2xx:请求接收成功
3xx:重定向
4xx:请求错误
5xx:服务器错误
【注】200 OK; 404 Not Found;403 Forbidden; 500 Internal Server Error。
===========================================================================
(7)服务器编程的基本框架:
| 模块 | 功能 |
|---|---|
| I/O 处理单元 | 处理客户连接,读写网络数据/接收发送数据 |
| 逻辑单元 | 业务进程或线程/解析数据 |
| 网络存储单元 | 数据库、文件或缓存 |
| 请求队列 | 各单元之间的通信方式 |
(8)两种高效的事件处理模式:
Reactor 和 Proactor ,同步 I/O 模型通常用于实现 Reactor 模式,异步 I/O 模型通常用于实现 Proactor 模式。
Reactor和Proactor模式的主要区别就是 真正的读取和写入操作是由谁来完成的。
Reactor来了事件操作系统通知应用进程,让应用进程来处理;
Proactor来了事件操作系统来处理,处理完再通知应用进程。
Reactor:(实现简单)
主线程(I/O处理单元)只负责监听fd是否有事件发生,有就通知工作线程(逻辑单元),
将socket事件(可读可写)放入请求队列,交给工作线程处理。除此之外主线程不做其他工作。
Proactor:(性能更高)
将所有I/O操作都交给主线程和内核来处理(进行读写),
工作线程仅仅负责业务逻辑(解析HTTP请求,在封装成响应数据发回去)。
工作流程:
1、Reactor:(同步I/O)
主线程往 epoll 内核事件表中注册(epoll_ctl) socket 上的读就绪事件;
主线程调用 epoll_wait 等待 socket 上有数据可读;
当 socket 上有数据可读时, epoll_wait 通知主线程。主线程则将 socket 可读事件放入请求队列;
睡眠在请求队列上的某个工作线程被唤醒,它从 socket 读取数据,并处理客户请求,
然后往epoll内核事件表中注册(epoll_ctl)该 socket 上的写就绪事件;
当主线程调用 epoll_wait 等待 socket 可写;
当 socket 可写时,epoll_wait 通知主线程。主线程将 socket 可写事件放入请求队列;
睡眠在请求队列上的某个工作线程被唤醒,它往 socket 上写入服务器处理客户请求的结果。
2、Proactor:
(异步I/O 模型)(同步I/O模型)
见Linux高并发服务器开发
【注】服务器处理三类事件:I/O事件、信号事件、定时事件。
(9)线程池:由服务器预先创建的一组子线程;线程池中的线程数量应该和 CPU 数量差不多;线程池中的所有子线程都运行着相同的代码。
实质:
1、空间换时间,浪费服务器的硬件资源,换取运行效率。
2、池是一组资源的集合,这组资源在服务器启动之初就被完全创建好并初始化,这称为静态资源。
3、当服务器进入正式运行阶段,开始处理客户请求的时候,如果它需要相关
webserver
参考技术A web应用服务器是互联网时代最为重要之一的底层支持。它处理相应的应用访问请求,并为前端提供相应的展示数据。
不同的web应用服务器实现性能不同,大型网站服务器可以每秒处理几万到几十万的应用请求,中小型网站服务器可能会因为每秒几千次请求停机。
从架构的角度上而言,web-server的升级是一个迭代的过程,只有现在的应用服务器无法满足网站的访问量,才会在此之上进行优化。对于一名好的架构师而言,落地和防灾、可扩展是优先需要考虑的相关事宜。
首先要说的是软件开发是一个确定性的事件, 有章可循,有理可溯 ,任何现象都是可以被解释的,这是入门级程序员和高级程序员的区别之处。
我们以这种思路自顶向下去分析解决问题。
以主流的JavaEE为例,传统的应用开发两个较为核心的工作内容是:
这可能会涉及持续化集成、自动化测试、测试驱动开发概念。
在这之后,可能还会存在的工作是:
在这个过程中,可能会涉及封装、基类、工具类、反射、泛型的概念。
从上面可以看出,软件开发是一件团队合作的事情。应该由 不同的人员去从事不同的事情 。传统项目的分工基本如下(基于个人主观猜测):
目前比较主流的web应用框架是以spring-boot为主的微服务框架。对于上面说的三个事情而言,重要的是 把其中任何一件事情当作一个工程去做,赋予一个合适的时间周期。 这部分内容在预研过程中非常关键,前期未考虑到的因素后期再修改代价可能为 指数级 。
以spring-boot为主,结合mysql搭建web应用服务器的例子github上有很多,在这里不再赘述。
从客户端传递到服务器,响应时间由以下三个部分组成:
当出现应用响应时间过高这个问题时,对于相关人员,首先需要做的是:
对上面三个部分进行测试,分析它们分别所消耗的时间,然后再对此进行优化。 做到有的放矢,不要四处放枪 。
当我们开发完应用程序之后,该如何进行应用的部署呢?怎样的部署才能够保证服务器的处理时间较短?
下面我们讨论单个tomcatweb应用服务器和多个tomcatweb应用服务器。
通过spring boot 创建web应用有两种方式:war包与jar包。在本文中以war包为例。
servlet解析web请求过程:
tomcat作为servlet容器的一种,管理着部署的多个web应用。tomcat运行架构图如下:
从上图中可以看出:
所以由于每个web应用只创建了一个servlet实例,所以需要线程安全问题。(即servlet中包含静态变量和成员变量的时候会出现线程安全的问题。应该使用局部变量。)
tomcat 并发模型
从单个tomcat运行web应用中可以看出:
java web通过封装servlet屏蔽了服务细节,使web开发人员专注与业务逻辑的实现。这是j2ee能在web开发中有一定地位的原因。
然而,由于servlet的创建和tomcat 多线程的并发处理全部交由tomcat来做,在这一个层次程序员无法做太多的事情,只能对tomcat和jvm进行调优。
万幸的是cpu不是系统性能的瓶颈。但是目前有很多的游戏已经使用goroutine来实现了。因为golang的协程可以开上万个,非常适合多线程的处理。
在一些大型网站中,对这部分性能调优的解决方案有:
第二种方案就引入了多tomcat web应用服务器。它的思路是:
在云计算尚未出现时,负载均衡及容器的维护往往由内部的技术部自行实现,在云计算时代,由于K8S和Docker的出现,使这类问题解决更为容易。
K8S的弹性伸缩,把容器进行拷贝复制,并自动负责负载均衡,可以大大简化其流程。
ps:在K8S上运行的多个tomcat容器是相同的拷贝。
淘宝的例子
从传统的意义上讲,系统的性能瓶颈并不存在于cpu的计算能力,而在于I/O。
所以大型网站架构上通常在思考如何降低I/O的时间。
最常用的降低I/O时间是使用reddis和memcached做缓存,关于这块前辈的经验摘引如下:
安全内容博大精深,关于安全方面相关的一些基本的认知链接如下:
web application security
另外,如果对于java 而言,可以使用一个apache的安全框架
shiro
此外还有一些诸如分布式文件存储、加快服务器脚本运算速度、页面组件分离等都是提高服务器响应的方法。
在web开发中,cookie和seesion经常用到。接下来进行简单的说明。cookie和session主要是用来保存数据及状态。
cookie 和session 的区别:
建议:
cookie和session可以解决跨页面传递数据的问题。
前端跨页面传递数据是一个比较繁琐的问题,依赖于浏览器的架构和实现。cookie和session是一种通用的解决方案。
以上是关于C++——WebServer服务器项目的主要内容,如果未能解决你的问题,请参考以下文章
如何用C++实现支持HTTPS的RESTful WebServer
向 system.webServer.httpErrors 添加 401 自定义错误会导致“无法在 Web 服务器上开始调试”错误