缓存一致性
Posted Li-Yongjun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了缓存一致性相关的知识,希望对你有一定的参考价值。
缓存一致性
在多数设计中,每个核心都有自己的 L1 和 L2 缓存(此为私有缓存),L3 缓存挂接到一个共享总线上,可供所有核心存取(此为共享缓存)。
存在这样一种可能:核心 1 和核心 2 上运行的两个独立的线程都要访问地址 A 上的数据,那么,核心 1 可以将地址 A 的数据载入自己的 L1/L2 缓存,同时核心 2 也可以将同一个地址 A 上的数据载入到自己的 L1/L2 缓存。
你一定会有个疑问:如果地址 A 的数据 a 在核心 1 的 L1 缓存中被更改为 b,那么此时核心 2 的 L1 缓存中原本缓存的地址 A 的内容 a 是不是就过期了?还能用吗?肯定是不能用的。那么核心 2 上的程序要将过期的数据 a 载入寄存器进行运算,难道要阻止它吗?这就牵扯到多核心缓存设计上一个最为复杂的问题:缓存一致性问题(cache coherency,CC)。
缓存行
缓存中的数据是如何管理的?首先想到的是数据分块是多大。缓存控制器将数据读入、淘汰、置换、写出的时候,最小的单位就是一条。
假设一下,这一条数据是否可以是 1 字节?理论上完全可以,但是太不划算了,我们说程序的访存行为具有空间局部性,也就是访问了字节 A,很大概率上接着就会访问字节 A+1、A+2,所以缓存从内存中尽量一次读取多个字节才划算,即将缓存和内存之间的数据总线的位宽加大,不要让它只有 8 位。
另外,缓存中保存的不仅仅是实际内容,还要记录这条数据对应的物理地址,以及其他一些控制位和状态位(Dirty、Invalid位等)。所以,单单保存地址(假设为 64 位地址)就得 8 字节,而如果以字节为管理单位,那么就得为每个字节保存至少 64 位(8 字节)的地址记录,记录本身比内容都要大 7 被,简直不可接受。
现实中一般采用 16 字节、64 字节、128 字节的粒度作为一条数据,此时只需要用该条数据第一个字节所在的物理基地址来描述这个块就可以了。这一”条”数据,专业上称为一个缓存行(cache line)。一般来讲,目前主流 CPU 的缓存行的大小都是采用 64 字节,其主要原因是主流的内存一次连续数据传输通常最大只能到 64 字节。

示例
示例一:
thread2.c
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
#define COUNT 1000000000
struct _t
// long p1, p2, p3, p4, p5, p6, p7;
long x;
// long p9, p10, p11, p12, p13, p14, p15;
;
struct _t a;
struct _t b;
void *test_thread1(void *arg)
for (long i = 0; i < COUNT; i++)
a.x = i;
return NULL;
void *test_thread2(void *arg)
for (long i = 0; i < COUNT; i++)
b.x = i;
return NULL;
int main(int argc, char *argv[])
pthread_t test1_thread_t;
pthread_t test2_thread_t;
if (pthread_create(&test1_thread_t, NULL, test_thread1, "test_1_thread") != 0)
printf("test1_thread_t create error\\n");
exit(1);
if (pthread_create(&test2_thread_t, NULL, test_thread2, "test_2_thread") != 0)
printf("test2_thread_t create error\\n");
exit(1);
pthread_join(test1_thread_t, NULL);
pthread_join(test2_thread_t, NULL);
return EXIT_SUCCESS;
$ gcc thread2.c -o thread2.out -lpthread
$ time ./thread2.out
real 0m1.807s
user 0m3.589s
sys 0m0.004s
$
$ time ./thread2.out
real 0m1.852s
user 0m3.679s
sys 0m0.000s
$
$ time ./thread2.out
real 0m1.808s
user 0m3.555s
sys 0m0.000s
示例二:
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
#include <unistd.h>
#define COUNT 1000000000
struct _t
long p1, p2, p3, p4, p5, p6, p7;
long x;
long p9, p10, p11, p12, p13, p14, p15;
;
struct _t a;
struct _t b;
void *test_thread1(void *arg)
for (long i = 0; i < COUNT; i++)
a.x = i;
return NULL;
void *test_thread2(void *arg)
for (long i = 0; i < COUNT; i++)
b.x = i;
return NULL;
int main(int argc, char *argv[])
pthread_t test1_thread_t;
pthread_t test2_thread_t;
if (pthread_create(&test1_thread_t, NULL, test_thread1, "test_1_thread") != 0)
printf("test1_thread_t create error\\n");
exit(1);
if (pthread_create(&test2_thread_t, NULL, test_thread2, "test_2_thread") != 0)
printf("test2_thread_t create error\\n");
exit(1);
pthread_join(test1_thread_t, NULL);
pthread_join(test2_thread_t, NULL);
return EXIT_SUCCESS;
$ gcc thread2.c -o thread2.out -lpthread
$ time ./thread2.out
real 0m0.762s
user 0m1.471s
sys 0m0.004s
$
$ time ./thread2.out
real 0m0.776s
user 0m1.497s
sys 0m0.000s
$
$ time ./thread2.out
real 0m0.774s
user 0m1.473s
sys 0m0.000s
上述示例中,通过两个线程,对两个变量循环赋值 10 亿次,然后退出。
示例一耗时 1.8s,示例二耗时 0.7s,两份代码甚至在指令上没有任何差别,但在执行时间上却差距非常大。这就是缓存一致性问题产生的效果。
两份代码唯一的不同就是,程序二结构体成员变量 x 前后各增加了 8 个 long 类型变量(第9、11行)。
在程序一运行时,线程 1 中的 a.x 和线程 2 中的 b.x 在内存空间上紧挨着,假设线程 1 运行在 CPU0 上,线程 2 运行在 CPU1 上,CPU0 会将变量 a.x 从内存读入到自己的 L1 缓存,由于 a.x 和 b.x 紧挨着,CPU0 从内存中载入一个缓存行(64字节)到 L1 时,大概率会将 b.x 内存数据一同载入。同理,CPU1 也是。这样 CPU0 的 L1 上既有 a.x,又有 b.x,CPU1 的 L1 上也既有 a.x,又有 b.x,当 CPU0 向自己 L1 上的 a.x 写入数据后,根据缓存一致性原则,CPU 必定要耗费一定指令去把 CPU0 L1 上 a.x 的数据同步到 CPU1 L1 的 a.x 中。
实际上 a.x 是 long 类型,占 8 个字节,下图为了方便,画在一个格子里了。
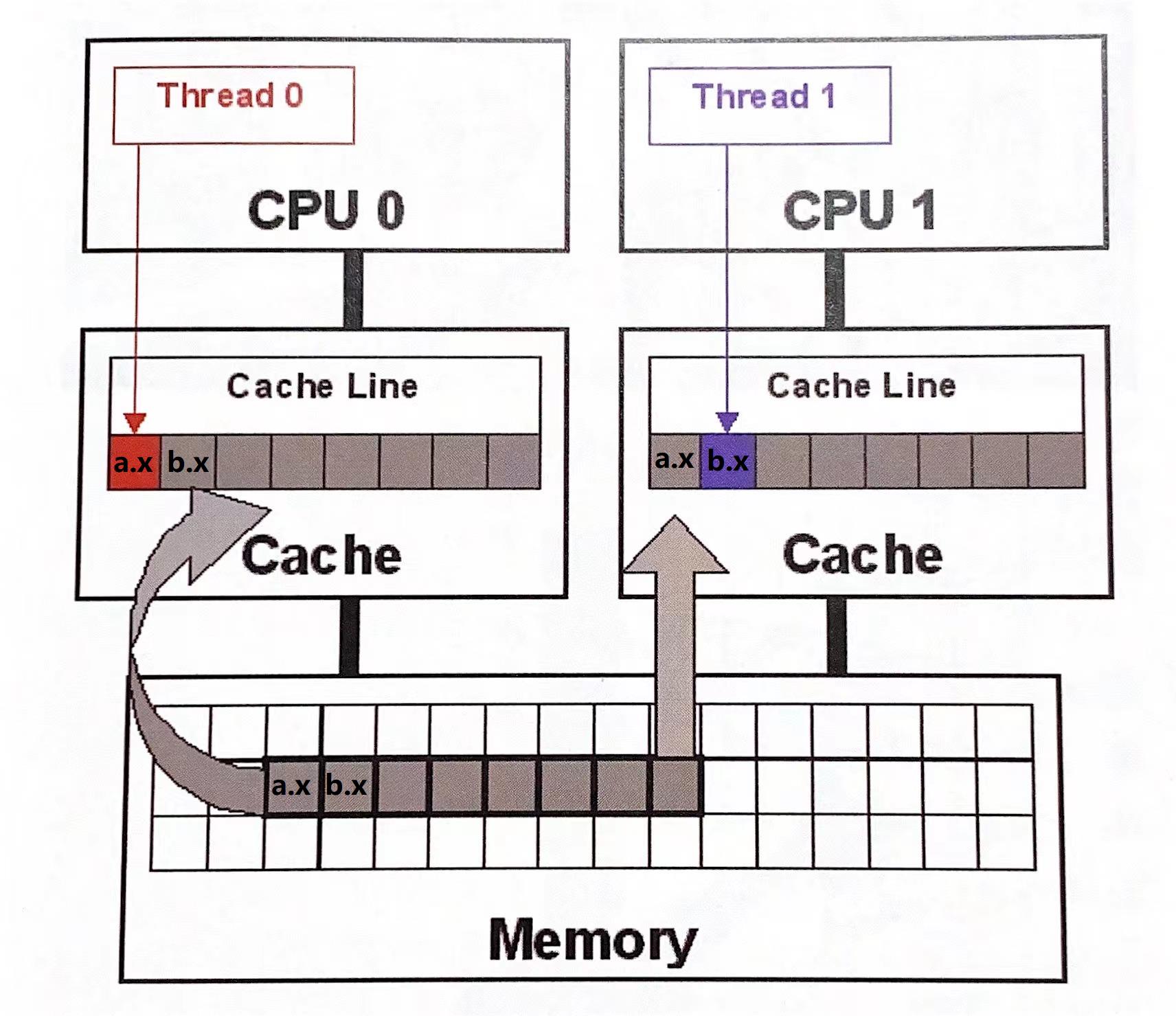
由于 CPU 要频繁的对两个核心上的 L1 上的数据做同步,所以会使得程序总体耗时较长。
在程序二中,由于在成员变量 x 前后都各加了 8 个 long 类型变量,也就是前后各加了 64 字节的内存空间,这样 CPU0 从内存将 a.x 载入自己缓存 L1 时(64 字节),肯定不会把 b.x 也一同载入,换句话说,a.x 和 b.x 不可能在同一个缓存行中。(缓存行中的数据对应内存上一段连续的空间)。这种情况下,就不会出现需要 CPU 同步两个核心上缓存数据的工作,自然程序就能得到更快的执行。这种方法有个名称,叫缓存行填充。
从上述演示示例可以看出,缓存不一致将会导致程序执行效率下降,这个事情如果发生在网络收发包中,将会严重影响网络性能,所以在性能调优时,缓存一致性也是一个要考虑的点。
以上是关于缓存一致性的主要内容,如果未能解决你的问题,请参考以下文章