数据分析 | Pandas 200道练习题,每日10道题,学完必成大神
Posted 小鱼干儿♛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析 | Pandas 200道练习题,每日10道题,学完必成大神相关的知识,希望对你有一定的参考价值。
文章目录
1.读取本的数据集
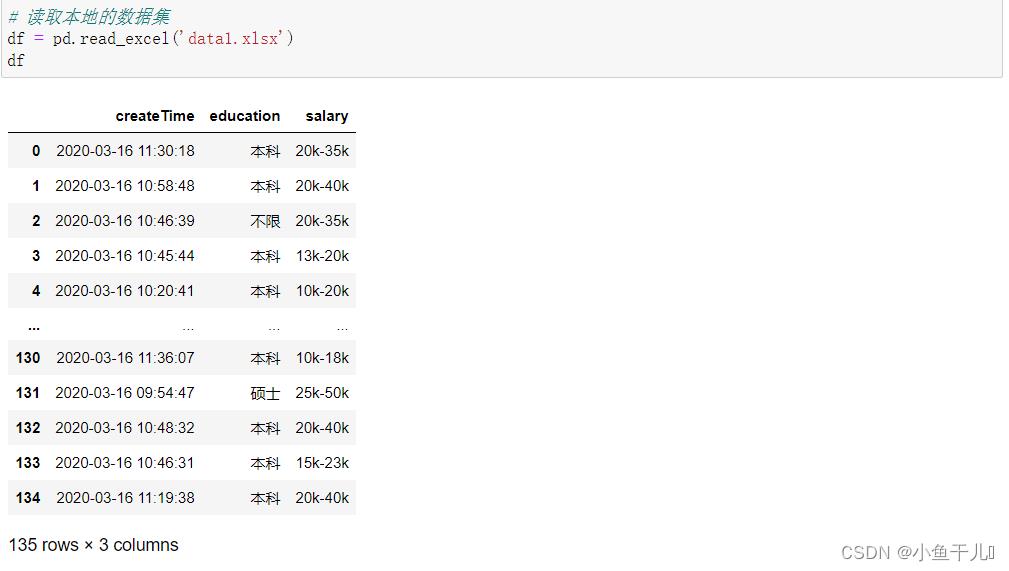
# 读取本地的数据集
# 数据集可以私信我我发给你们,同样也可以
df = pd.read_excel('data1.xlsx')
df
2.查看数据的前5行
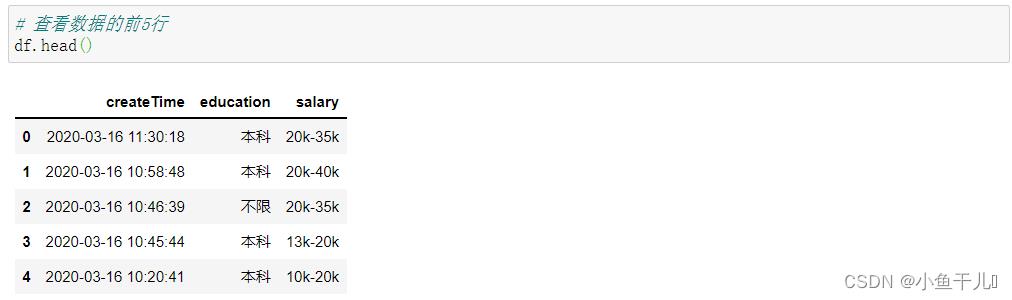
使用head()函数查看数据的前几行,可以传入具体的数,默认是5
# 查看数据的前5行
df.head()
3.将salary列的数据转换为最大值和最小值的平均值
map和apply函数接受的参数都是一个行数,而且都不会直接改变原数据,都是返回一个新的DataFrame对象
# 将salary列数据转换为最大值和最小值的平均值
# 方式一 使用map函数
def fun(x):
a,b = x.split('-')
a = int(a.strip('k'))*1000
b = int(b.strip('k'))*1000
return int((a+b)/2)
df['salary'].map(fun)
# 方式二使用apply函数
df['salary'] = df['salary'].apply(fun)
df
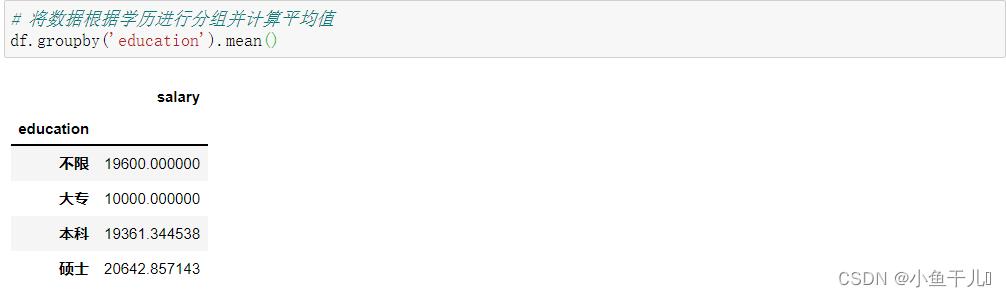
4.将数据根据学历进行分组计算平均值
使用groupby()函数进行分组
# 将数据根据学历进行分组并计算平均值
df.groupby('education').mean()
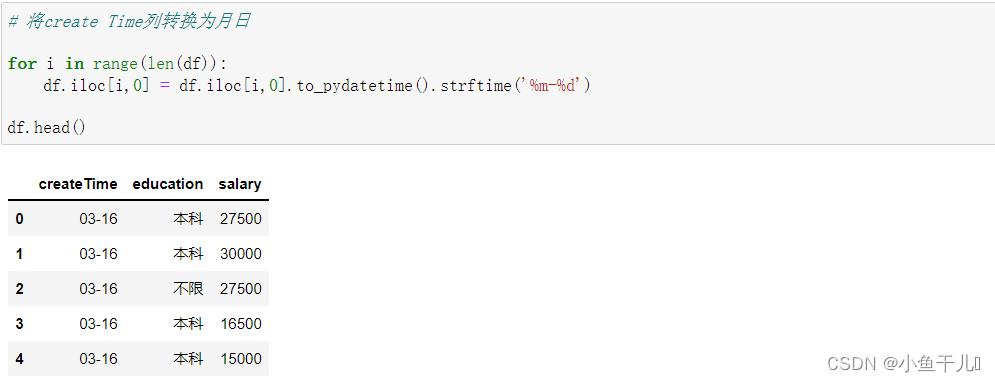
5.将createTime列转换为月日
# 将create Time列转换为月日
for i in range(len(df)):
df.iloc[i,0] = df.iloc[i,0].to_pydatetime().strftime('%m-%d')
df.head()
6.查看所索引,数据类型和内存信息
info()函数
# 查看索引,数据类型,和内存信息
df.info()

7.查看数值型列的汇总统计
describe() 返回的数据包括,数量,数据的平均值,标准差,最小值,最大值,25%、50% 75 % 的分位数
# 查看数值型列的汇总统计
df.describe()

8.新增一列根据salary将数据分为三组
# 新增一列根据salary将数据分为三组,并且设置等级
bins = [0,5000,20000,50000]
group_names = ['底','中','高']
df['categories'] = pd.cut(df['salary'],bins,labels=group_names)
df
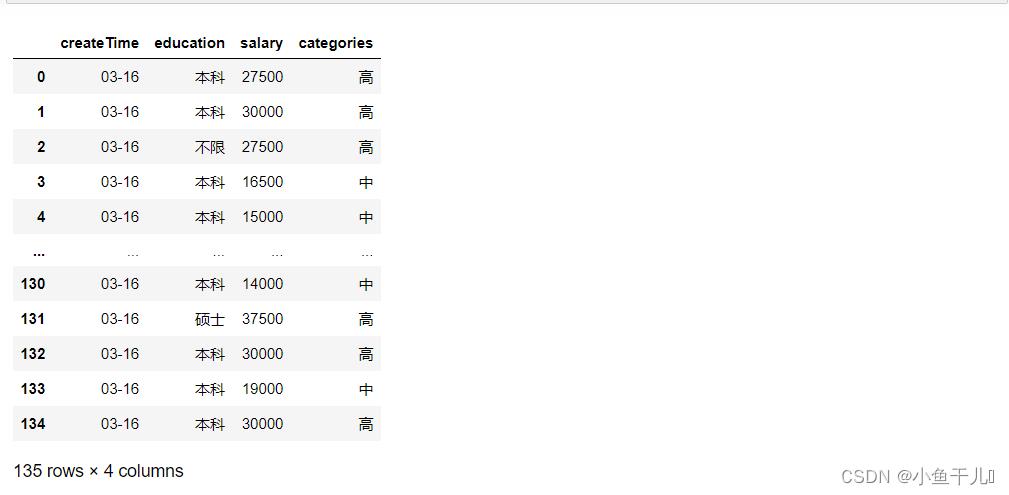
9.按照salary列队数据降序排序
sort_values 默认是升序
# 按照salary列对数据降序排列
# ascending=False降序
# ascending=True升序
df.sort_values('salary',ascending=False)

10.取出第33行的数据
根据索引选出第33行,索引从0开始
# 取出第33行的数据
df.loc[32]

今天的10道题涉及的东西多了一些,
groupby、describe、cut、sort_values、info等,如果想要全部的了解这些,仅靠这10道题是远远不够的,希望大家能够额外找些试题练习,也可以根据跟着博主的文章一块刷题✨✨✨
推荐使用牛客网进行练习 直达牛客,快人一步
欢迎您的关注

Pandas高级数据分析快速入门之二——基础篇
Pandas高级数据分析快速入门之一——Python开发环境篇
Pandas高级数据分析快速入门之二——基础篇
Pandas高级数据分析快速入门之三——统计分析篇
Pandas高级数据分析快速入门之四——表内、表间数据处理篇
Pandas高级数据分析快速入门之五——机器学习特征工程篇
Pandas高级数据分析快速入门之六——机器学习预测分析篇
0. Pandas构成
Pandas由两种常用的数据类型:
(1)Series是一种一维的带标签数组对象;
(2)DataFrame,二维数据表,Series容器。
其中,最常用的是DataFrame,做为数据分析数据载体——二维数据表,基于此有大量的统计分析函数。

DataFrame是一个二维表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。跟其他类似的数据结构相比(如R的data.frame),DataFrame中面向行和面向列的操作基本上是平衡的。其实,DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。
0.1. 第一个DataFrame
df = pd.DataFrame({'float': [1.0],
'int': [1],
'datetime': [pd.Timestamp('20180310')],
'string': ['foo'],
'stringtoint':['666']})
df.dtypes #显示数据类型
float float64
int int64
datetime datetime64[ns]
string object
stringtoint object
dtype: object
0.2. Pandas数据类型
| Pandas dtype | Python类型 | Numpy类型 | 说明 |
|---|---|---|---|
| object | str | string_,unicode_ | 用于文本 |
| int64 | int | int_,int8_,int16,int32,int64,uint8,uint16,uint32,uint64 | 用于整数 |
| float64 | float | float_,float16,float32,float64 | 用于浮点数 |
| bool | bool | bool_ | 用于布尔值 |
| datetime64 | NA | NA | 用于日期时间 |
| timedelta[ns] | NA | NA | 用于时间差 |
| category | NA | NA | 用于有限长度的文本值列表 |
0.3. Pandas数据类型转换
df['stringtoint'] = df['stringtoint'].astype('int64') #object转换为整型
print(df)
print(df.dtypes)
float int datetime string stringtoint
0 1.0 1 2018-03-10 foo 666
float float64
int int64
datetime datetime64[ns]
string object
stringtoint int64
dtype: object
0.4. 用到的Python基础
0.4.1. 序列(List)
序列是 Python 中最基本的数据结构。
序列中的每个值都有对应的位置值,称之为索引,第一个索引是 0,第二个索引是 1,依此类推。
list = ['Google', 'Runoob', 1997, 2000]
print ("第三个元素为 : ", list[2])
list[2] = 2001
print ("更新后的第三个元素为 : ", list[2])
list1 = ['Google', 'Runoob', 'Taobao']
list1.append('Baidu')
print ("更新后的列表 : ", list1)
第三个元素为 : 1997
更新后的第三个元素为 : 2001
更新后的列表 : ['Google', 'Runoob', 'Taobao', 'Baidu']
del list[2]
print ("删除第三个元素 : ", list)
list.remove('Google')
print ("删除Google元素 : ", list)
删除第三个元素 : ['Google', 'Runoob', 2000]
删除Google元素 : ['Runoob', 2000]
0.4.2. 字典
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key=>value 对用冒号 : 分割,每个对之间用逗号(,)分割,整个字典包括在花括号 {} 中 ,格式如下所示:
d = {key1 : value1, key2 : value2, key3 : value3 }
dict = {'Name': 'Runoob', 'Age': 7, 'Class': 'First'}
print ("dict['Name']: ", dict['Name'])
print ("dict['Age']: ", dict['Age'])
dict['Age'] = 10
print ("dict['Age']: ", dict['Age'])
dict['Name']: Runoob
dict['Age']: 7
dict['Age']: 10
1. 从读取通用数据文件开始
Pandas直接读取CSV、Excel、Json等数据文件为数据表(DataFrame)。
1.1. 读XLS数据文件
首先,用表格工具新建Excel表“sport.xlsx”,内容以部分田径运动员信息为例如下图所示。

import pandas as pd
df = pd.read_excel('sport.xlsx')
print(df)
id name age Gender sport
0 1001.0 董国建 34.000000 男 马拉松
1 1002.0 苏炳添 31.000000 男 百米
2 1003.0 彭建华 24.000000 男 马拉松
3 1004.0 张德顺 25.000000 女 马拉松
4 1005.0 焦安静 25.000000 女 马拉松
5 1006.0 葛曼棋 24.000000 女 百米
6 NaN 6 27.166667 NaN NaN
1.2. 读CSV数据文件
用文本编辑器工具新建CSVl表“sport.csv”,内容如下图所示。

import pandas as pd
df = pd.read_csv('sport.csv',encoding='utf_8')
print(df)
Name Team Grander Birth Age
0 董国建 马拉松 男 1987-3-16 34.0
1 苏炳添 百米 男 1981-8-29 31.0
2 张德顺 马拉松 女 1996-2-21 25.0
3 葛曼棋 百米 女 1997-10-13 24.0
2. 对表(DataFrame)增减数据
2.1. 增减行数据
2.1.1. 增加行
按索引行赋值,数据格式为列表(List)。
df.loc[4] = ['焦安静','马拉松','女','1995-9-3',26.0] #按索引增加行
#如下增加数据行都是有效的,并且不依赖索引
df.append(pd.DataFrame({'Name':['彭建华'],'Team':['马拉松'],'Grander':['男'],'Birth':['1996-12-18'],'Age':[25.0]}), ignore_index=True)
df=df.append({'Name':'杨绍辉','Team':'马拉松','Grander':'男','Birth':'1992-7-9','Age':29.0}, ignore_index=True)
print(df)
Name Team Grander Birth Age
0 董国建 马拉松 男 1987-3-16 34.0
1 苏炳添 百米 男 1981-8-29 31.0
2 张德顺 马拉松 女 1996-2-21 25.0
3 葛曼棋 百米 女 1997-10-13 24.0
4 焦安静 马拉松 女 1995-9-3 26.0
5 杨绍辉 马拉松 男 1992-7-9 29.0
2.1.2. 删除行
按索引行删除数据行。
df = df.drop(index=[5]).reset_index(drop=True)
print(df)
Name Team Grander Birth Age
0 董国建 马拉松 男 1987-3-16 34.0
1 苏炳添 百米 男 1981-8-29 31.0
2 张德顺 马拉松 女 1996-2-21 25.0
3 葛曼棋 百米 女 1997-10-13 24.0
4 焦安静 马拉松 女 1995-9-3 26.0
按条件筛选数据行(获取索引)而删除数据行。
df=df.drop(df.loc[df['Name']=='焦安静'].index)
print(df)
Name Team Grander Birth Age
0 董国建 马拉松 男 1987-3-16 34.0
1 苏炳添 百米 男 1981-8-29 31.0
2 张德顺 马拉松 女 1996-2-21 25.0
3 葛曼棋 百米 女 1997-10-13 24.0
2.2. 增减列数据
2.2.1. 增加列数据
通过序列数据(List),直接增加列,其中,要求序列数组个数与数据行数保持一致。
native = ['重庆','广东','云南','福建']
df['Native']=native
# 以下方法都可以插入列数据
#df.loc[:,'Native'] = native
#df.insert(1,'Native',native) # 在指点位置(列),插入列数据
print(df)
Name Team Grander Birth Age Native
0 董国建 马拉松 男 1987-3-16 34.0 重庆
1 苏炳添 百米 男 1981-8-29 31.0 广东
2 张德顺 马拉松 女 1996-2-21 25.0 云南
3 葛曼棋 百米 女 1997-10-13 24.0 福建
2.2.2. 删除列数据
按列名删除数据。
df=df.drop(['Birth'],axis=1)
print(df)
Name Team Grander Age Native
0 董国建 马拉松 男 34.0 重庆
1 苏炳添 百米 男 31.0 广东
2 张德顺 马拉松 女 25.0 云南
3 葛曼棋 百米 女 24.0 福建
通过筛选数据子表方法,达到删除数据的效果,原数据仍得以保留。先从DataFrame中获取列名为List数据类型,再删除其中不需要的列(可以多个),然后,再通过筛选数据方式获得新的数据表。
#df.columns 返回Index,可以通过 tolist(), 或者 list(array) 转换为list
cols = df.columns.tolist()
cols.remove('Native')
df = df[cols]
print(df)
Name Team Grander Age
0 董国建 马拉松 男 34.0
1 苏炳添 百米 男 31.0
2 张德顺 马拉松 女 25.0
3 葛曼棋 百米 女 24.0
3. 把数据保存到CSV文件
# encoding设置是针对中文问题,如果系统以及设置为中文,则可以略去
df.to_csv('sport_update.csv',encoding='utf_8_sig')
# 保存文件不带索引,我比较喜欢
df.to_csv('sport_noindex.csv',encoding='utf_8_sig',index=False)
# 保存文件不带表头(header)
df.to_csv('sport_noheader.csv',encoding='utf_8_sig',header=False)
# 对于不带表头的数据读取,需要设置header=None,否则,第一行数据变成表头
df1 = pd.read_csv('sport_noheader.csv',encoding='utf_8',header=None)
print(df1)
0 1 2 3 4
0 0 董国建 马拉松 男 34.0
1 1 苏炳添 百米 男 31.0
2 2 张德顺 马拉松 女 25.0
3 3 葛曼棋 百米 女 24.0
4. DataFrame单元格操作
4.1. 读取单元格数据
print('iloc[[1],[1]]: ' + df.iloc[[1],[1]])
print('iloc[1,1]: ' + df.iloc[1,1])
print(df.loc[1],[1])
Team
1 iloc[[1],[1]]: 百米
iloc[1,1]: 百米
Name 苏炳添
Team 百米
Grander 男
Birth 1981-8-29
Age 31
Name: 1, dtype: object [1]
4.2. 修改单元格数据
按索引及列位置顺序修改单元格数据。
# 后增加内容,后面讲
df.iloc[1,1] = '田径'
print(df)
Name Team Grander Birth Age
0 董国建 马拉松 男 1987-3-16 34.0
1 苏炳添 田径 男 1981-8-29 31.0
2 张德顺 马拉松 女 1996-2-21 25.0
3 葛曼棋 百米 女 1997-10-13 24.0
4 焦安静 马拉松 女 1995-9-3 26.0
5 杨绍辉 马拉松 男 1992-7-9 29.0
按筛选条件:“Name”等于“苏炳添”,定位列名为“Team”修改单元格数据。
df.loc[df.loc[df['Name']=='苏炳添'].index,'Team'] = '马拉松'
print(df)
Name Team Grander Birth Age
0 董国建 马拉松 男 1987-3-16 34.0
1 苏炳添 马拉松 男 1981-8-29 31.0
2 张德顺 马拉松 女 1996-2-21 25.0
3 葛曼棋 百米 女 1997-10-13 24.0
4 焦安静 马拉松 女 1995-9-3 26.0
5 杨绍辉 马拉松 男 1992-7-9 29.0
按索引及列名为“Team”修改单元格数据。
df.loc[1,'Team'] = '百米'
print(df)
Name Team Grander Birth Age
0 董国建 马拉松 男 1987-3-16 34.0
1 苏炳添 百米 男 1981-8-29 31.0
2 张德顺 马拉松 女 1996-2-21 25.0
3 葛曼棋 百米 女 1997-10-13 24.0
4 焦安静 马拉松 女 1995-9-3 26.0
5 杨绍辉 马拉松 男 1992-7-9 29.0
5. 读取Clickhouse数据
使用clickhouse_driver 接口,查询数据返回DataFrame格式数据。
from clickhouse_driver import Client
db_name = 'ebd_all_b04'
host='192.168.17.61' #服务器地址
port ='9000'
database=db_name #数据库
send_receive_timeout = 25 #超时时间
client = Client(host=host, port=port, database=database)
query_sql = '''select E.carduser_id,anyLast(E.p500) as p500,anyLast(E.org_id) as org_id,E.occurday as occurday,
anyLast(E.balance) as balance,sum(recharge) as recharge,sum(volumn) as volumn,
sum(all_oils) as all_oils,sum(all_goods) as all_goods,sum(E.discount) as discount,
max(goodscategory_id) as goods_id,count(*) as trans_sum from (
......
group by E.carduser_id,E.occurday
order by E.carduser_id,E.occurday
'''
# 查询直接返回DataFrame
collection = client.query_dataframe(query_sql)
print(collection)
carduser_id p500 org_id occurday balance recharge volumn \\
0 131***3 101*** 102*** 2017-04-29 600 20000 3205
1 131***3 101*** 102*** 2017-05-12 1575 10000 0
2 131***3 101*** 102*** 2017-05-14 2575 20000 0
3 131***3 101*** 102*** 2017-05-18 6305 10000 0
all_oils all_goods discount goods_id trans_sum
0 -19400 0 -600 101701.0 2
1 0 -9025 -475 100016.0 2
2 0 -19000 -1000 100016.0 3
3 0 -6270 -330 100073.0 2
[3193 rows x 12 columns]
参考:
肖永威 ,Python使用ClickHouse实践与踩坑记 , CSDN博客 ,2021.06
以上是关于数据分析 | Pandas 200道练习题,每日10道题,学完必成大神的主要内容,如果未能解决你的问题,请参考以下文章