ArcGIS Pro中使用深度学习的高分辨率土地覆盖制图
Posted 树谷-胡老师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ArcGIS Pro中使用深度学习的高分辨率土地覆盖制图相关的知识,希望对你有一定的参考价值。
本文非常详细的讲解了利用深度学习在高分辨率土地覆盖制图的应用,本文作者:Amin Tayyebi,文章从数据准备到训练U-Net模型等等细节都有讲解。本译文只是使用谷歌翻译而成。文章可能有错误语句及不通顺情况,所以仅供参考学习。有需要的可点击文末阅读原文跳转原文英文版。
使用Keras和ArcGIS应用深度学习模型在阿拉巴马州提供高分辨率土地覆盖的概述。
01
土地覆盖制图
全球土地覆盖图已广泛用于各种应用,包括生态系统服务、气候变化、水文过程以及地方和区域尺度的政策制定。虽然低分辨率、空间(例如,30m)和时间(例如,每 5 年),但各种机构(例如,USGS、USDA、NASA)已经为整个欧洲和美国开发了土地覆盖图,创建实时缺乏区域尺度的高分辨率时空土地覆盖图(例如 1 米)。自 2000 年代初以来,土地变化科学界一直在追求这一目标,但没有取得广泛的成功。
在这篇博客文章中,我将向您介绍我们开发的模型,该模型可以根据国家农业影像计划 (NAIP) 的像素级图像创建具有 1 米分辨率的分类土地覆盖图(图 1)。训练后的模型将 NAIP 图像分为六个土地覆盖类别:1) 建筑物、2) 道路或停车场、3) 水、4) 收获、开阔地或裸地、5) 森林和 6) 种植或黑暗的农田。

图 1. 原始 NAIP 图像与分类图像
除了您可以在其他博客中找到的土地覆盖分类方法之外,我也有兴趣在这里展示如何利用 ArcGIS API for Python 和 ArcGIS Pro 并将它们与深度学习工具(例如,此处的 Keras)集成。这使您能够通过利用 ArcGIS Pro 中可在 Python 中使用的地理处理工具更快地准备地理空间数据(栅格或矢量数据),并在 ArcGIS Pro 中可视化进度(图 2)。

图 2. 集成 ArcGIS Pro、Python API 和深度学习
02图像分割
图像分割是计算机视觉领域的关键问题之一。图像分割是将图像分割成多个片段。换句话说,图像分割是为图像中的每个像素分配标签的过程,使得具有相同标签的像素具有某些特征。图像分割是用于土地覆盖分类的理想方法,因为在每个土地覆盖类别中,像素在多个波段具有相似的特征。图像分割的重要性已在自动驾驶汽车、人机交互、虚拟现实等各种应用中得到体现。
03数据来源
我们的研究区域是阿拉巴马州的一部分。我们使用 ArcGIS Online [Ref 2]收集了 12 幅 NAIP 图像[Ref 1],北部 8 幅 NAIP 图像和南部 4 幅 NAIP 图像。NAIP 图像是在 1 米地面采样距离处以水平精度获取的。NAIP 的光谱分辨率有四个波段,包括自然色(红色、绿色和蓝色,或 RGB)和近红外。
首先,我使用 ArcGIS Pro [Ref 3]中的创建镶嵌数据集功能在地理数据库中创建了一个空镶嵌数据集。其次,我使用 ArcGIS Pro [Ref 4]中的“将栅格添加到镶嵌数据集”功能将 NAIP 图像添加到空的镶嵌数据集。因此,将栅格添加到镶嵌数据集函数会创建两个要素类,称为 1) 显示研究区域范围的边界层,2) 显示每个 NAIP 影像范围的足迹图层以及一个称为影像图层的栅格包含 NAIP 图像的马赛克(图 3)。
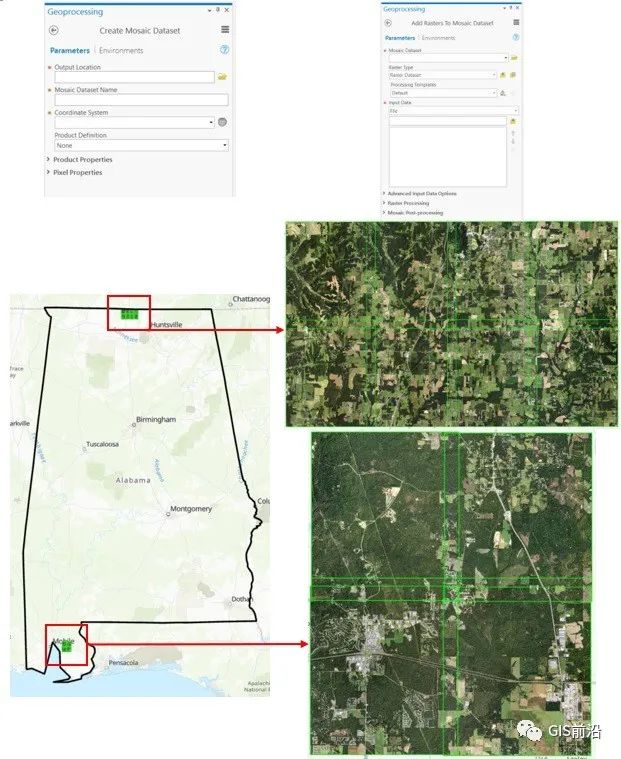
图 3. 地理处理工具、NAIP 图像和研究区域
04ArcGIS Pro 和 ArcGIS API for Python 进行数据准备
对于训练运行,我需要像其他深度学习模型一样为每个土地覆盖类别提供标记数据。我使用 ArcGIS Pro [Ref 5]中的训练样本管理器在NAIP 图像上标注了六个土地覆盖类别。在整个研究区域随机收集的标签(图 4)。

图 4. 训练样本管理器和采样标签
图像分割模型的输入和输出应为光栅格式,以供训练运行。由于标注数据采用要素类或矢量格式,因此我使用 ArcGIS Pro [参照 6]中的要素转栅格功能将要素类格式的标注数据转换为栅格格式。
由于标记整个 NAIP 图像非常耗时,因此我在 NAIP 图像中存在未标记的区域。对于我没有标注数据的区域,ArcGIS Pro 分配了无数据。我使用 ArcGIS Pro [Ref 7]中的 Reclassify 函数将 No-Data 转换为零并保持其他土地类别的值相同。您可以将具有 0 值的区域视为对训练运行没有任何影响的背景类。我将在后面的损失函数中解释我如何最小化背景类的影响。
由于 NAIP 图像占用空间很大(~7.5km × ~6.5km)并且它们不能直接馈送到模型中,我将 NAIP 图像和相应的光栅格式的标记数据转换为更小的图像。为此,我在 ArcGIS Pro [Ref 8] 中使用 Export Training Data For Deep Learning 将 NAIP 镶嵌栅格转换为模型的输入,并将相应的栅格标记数据转换为较小的芯片。此工具可让您选择每个芯片的大小以及 X 和 Y 轴的步幅。我沿 X 和 Y 轴选择了 256 的芯片大小和 64 的步幅大小。此工具仅导出同时具有 NAIP 和标记数据的芯片(图 5;Python #1)。我以 TIFF 格式定义了图像和标签的格式。每个 NAIP 图像的芯片总数取决于每个 NAIP 图像的标记数据。

图 5. 为深度学习导出训练数据
如果超过 50% 的芯片具有背景类(0 值),则将它们从进一步分析中删除。由于每个文件夹中的图像体积和数量很大(12 个文件夹对应于 12 个 NAIP 图像),我在文件夹中堆叠芯片并为每个土地覆盖类别转换为单独的 HDF5 格式(Python #2)。这使我能够跟踪每个土地覆盖类别的芯片数量。
05
数据增强
深度学习模型需要大量数据进行训练。从训练数据中,我分别生成了 420、438、702、1008、837、891 个用于建筑物、道路、水、耕地、森林和种植地的芯片。缺乏训练数据的主要解决方案是使用数据增强来增加训练数据的数量。在数据增强中,我只将 HDF5 文件用于稀有土地覆盖类,并使稀有类的数量增加了两到三倍。
我使用了三种常见的数据增强方法来增加稀有土地覆盖类别(建筑物、道路或停车场和水)的训练数据数量:1) 转移:在 ArcGIS Pro [参考资料 8]中导出深度学习训练数据沿 X 和 Y 方向的步幅选项(创建下一个图像芯片时移动的距离)。导出的芯片沿 X 和 Y 方向为 256。我沿 X 和 Y 方向设置步幅 64 以获得更多筹码。这发生在数据处理步骤中,我在这里没有再做一次,2)旋转:在每次数据增强中,每个芯片随机选择四个值[-180, -90, 90, 180]来创建新芯片, 3) 缩放:在每次数据增强运行中,每个芯片在给定范围内随机选择一个缩放因子[0.05, 0.45]创建新芯片(图 6;Python #3)。然后,我将新生成的数据与现有的通常土地覆盖类别(收获或裸露的土地、森林、种植或黑暗的农田)合并。最后,我对 NAIP 图像的每个波段进行了归一化,并对训练样本进行了混洗。

图 6. 数据增强示例
06
修改和训练U-Net模型
U-Net 架构是一种编码器-解码器架构。U-Net 是一种完全传统的网络,由三部分组成:1)像编码器一样的收缩路径,2)像解码器一样的对称扩展路径和 3)通过特征图的跳过连接(例如,残差神经网络)在编码器部分到解码器部分。
由于我没有大型数据集,我不得不将 U-Net 修改为具有更少参数的新结构(图 7)。新的 U-Net 模型有 1,941,351 个参数(Python #3)。正如所讨论的,在每个芯片中都有值为 0 或背景类的单元格,这不是我们感兴趣的。我必须生成这个类,因为标记图像中的所有单元格通常是不可行的。为了在训练运行中克服这个问题,我必须编写一个自定义损失函数,在计算损失时忽略零。这个定制的损失函数通过为每个土地覆盖类别定义权重来处理这个问题。我将背景类的权重设置为接近零。在训练运行中,我使用了 90% 的数据进行校准,并留下了 10% 的数据进行验证。我定义了联合交集的平均值 (IoU) 以使用训练运行中的验证数据计算模型的准确性。我将模型运行了 30 个 epoch。模型在 epoch 20 停止训练,因为验证损失没有显着改善。

图 7. U-Net 的修改结构
07
ArcGIS Pro中部署模型并在NAIP图像上运行经过训练的模型
U-Net 模型以 HDF5 格式保存。ArcGIS Pro 有一种令人愉快的方式来部署模型并大规模运行它们[参照 8]. 我在 ArcGIS Pro 中使用 Python 栅格函数来部署模型。ArcGIS Pro 中的栅格函数使用并行处理来更快地运行模型。ArcGIS Pro 有两个可以运行深度学习模型的地理处理工具:“使用深度学习检测对象”和“使用深度学习分类像素”。因为我正在运行分割模型,所以我使用了 Classify Pixels 选项。外部深度学习模型框架的集成目前适用于任何深度学习框架,前提是您可以提供栅格函数。开箱即用,为 TensorFlow 对象检测 API 和其他一些框架提供了栅格函数。训练模型后,您可以使用 Esri 模型定义文件 (.emd) 运行地理处理工具来检测或分类 ArcGIS Pro 中的要素。您还需要在 ArcGIS Pro Python 环境中安装适当的深度学习框架和支持 Python 库(TensorFlow、CNTK、PyTorch 或 Keras);否则,将 .emd 文件添加到工具时会出现错误。.emd 文件是描述经过训练的深度学习模型的 JSON 文件。它包含运行推理工具所需的模型定义参数,并且应该由训练模型的数据科学家修改。

图 8. U-Net 模型的 EMD 文件结构
创建 .emd 文件(图 8)后,我对 12 个 NAIP 图像进行了推理(图 9)。



图 9. 来自 U-Net 的原始 NAIP 图像和分类土地覆盖图
准确度评估
我分离了一张带有标签且未在训练运行中使用的 NAIP 图像。我使用此 NAIP 图像进行测试运行。我对此图像进行了推理,并将模型的输出与标记数据的光栅化版本进行了比较。这种比较的结果是一个列联表,通常在遥感中用于准确性评估。我计算了每个土地覆盖类别的精度和召回率。对于给定区域,U-Net 模型的整体准确率约为 85%。与稀有类相比,该模型对常见类的表现更好也就不足为奇了。

表 1. U-Net 模型的准确度评估(Precision and Recall in %)
09GeoAI Cookiecutter数据科学模板
与其他数据科学家共享数据科学项目始终具有挑战性,因为每个人都有自己的结构来构建数据科学项目的模板。数据科学项目的通用格式使数据科学家能够在共享或接收他人的项目时期望特定格式。在这里,我使用了 Cookiecutter 数据科学模板,它是一种合乎逻辑、合理标准化但灵活的项目结构,用于执行和共享数据科学工作。您可以使用一些命令行轻松地为您的项目设置模板。我们的团队(Esri GeoAI 团队)基于数据科学 cookiecutter 模板为地理空间项目实施了一个新的 cookiecutter 模板。

更多学习资源:树谷资料库资源大全(3月16日更新)
wrf
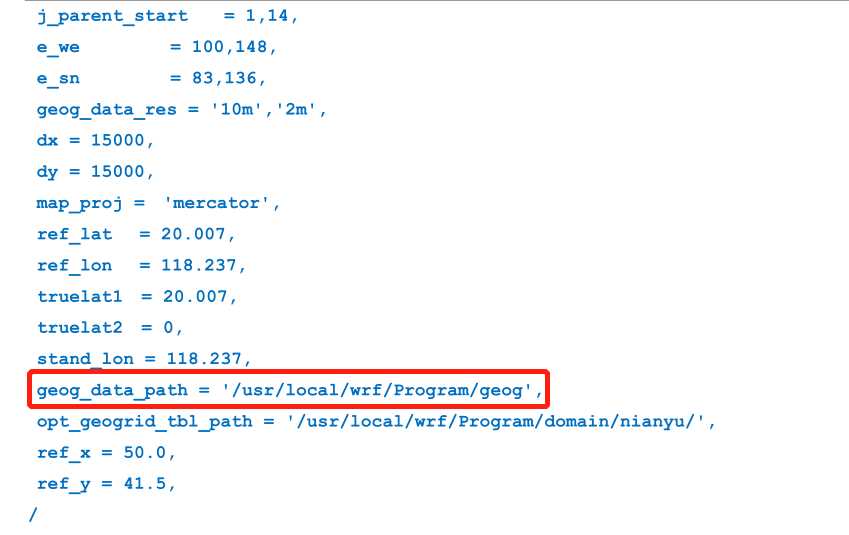
namelist.wps 中的 geog_data_path=后面的文件夹的文件即土地覆被资料:(看下图)
推荐中科院地理所承担的地球系统科学数据共享平台上共享的100m分辨率资料,官网 http://www.geodata.cn/ -->http://www.geodata.cn/data/publisher.html
以上是关于ArcGIS Pro中使用深度学习的高分辨率土地覆盖制图的主要内容,如果未能解决你的问题,请参考以下文章
ArcGIS风暴根据海拔(坡度)范围分级统计土地覆盖的类型和面积(兰州市GlobeLand30m数据为例)