深度学习在语音识别方面主要的难题和困难是啥?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习在语音识别方面主要的难题和困难是啥?相关的知识,希望对你有一定的参考价值。
参考技术A深度学习的应用:语音识别系统长期以来,在描述每个建模单元的统计概率模型时,大多采用的是混合高斯模型(GMM)。这种模型由于估计简单,适合海量数据训练,同时有成熟的区分度训练技术支持,长期以来,一直在语音识别应用中占有垄断性地位。但这种混合高斯模型本质上是一种浅层网络建模,不能充分描述特征的状态空间分布。另外,GMM建模的特征维数一般是几十维,不能充分描述特征之间的相关性。最后,GMM建模本质上是一种似然概率建模,虽然区分度训练能够模拟一些模式类之间的区分性,但能力有限。微软研究院语音识别专家邓立和俞栋从2009年开始和深度学习专家GeofferyHinton合作。2011年微软宣布基于深度神经网络的识别系统取得成果并推出产品,彻底改变了语音识别原有的技术框架。采用深度神经网络后,可以充分描述特征之间的相关性,可以把连续多帧的语音特征并在一起,构成一个高维特征。最终的深度神经网络可以采用高维特征训练来模拟。由于深度神经网络采用模拟人脑的多层结果,可以逐级地进行信息特征抽取,最终形成适合模式分类的较理想特征。这种多层结构和人脑处理语音图像信息时,是有很大的相似性的。深度神经网络的建模技术,在实际线上服务时,能够无缝地和传统的语音识别技术相结合,在不引起任何系统额外耗费情况下,大幅度提升了语音识别系统的识别率。其在线的使用方法具体如下:在实际解码过程中,声学模型仍然是采用传统的HMM模型,语音模型仍然是采用传统的统计语言模型,解码器仍然是采用传统的动态WFST解码器。但在声学模型的输出分布计算时,完全用神经网络的输出后验概率乘以一个先验概率来代替传统HMM模型中的GMM的输出似然概率。百度在实践中发现,采用DNN进行声音建模的语音识别系统相比于传统的GMM语音识别系统而言,相对误识别率能降低25%。最终在2012年11月,百度上线了第一款基于DNN的语音搜索系统,成为最早采用DNN技术进行商业语音服务的公司之一。
国际上,Google也采用了深层神经网络进行声音建模,是最早突破深层神经网络工业化应用的企业之一。但Google产品中采用的深度神经网络只有4-5层,而百度采用的深度神经网络多达9层。这种结构差异的核心其实是百度更好地解决了深度神经网络在线计算的技术难题,因此百度线上产品可以采用更复杂的网络模型。这将对于未来拓展海量语料的DNN模型训练有更大的优势。

语音识别是一门交叉学科。近二十年来,语音识别技术取得显著进步,开始从实验室走向市场。人们预计,未来10年内,语音识别技术将进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域。 语音识别听写机在一些领域的应用被美国新闻界评为1997年计算机发展十件大事之一。很多专家都认为语音识别技术是2000年至2010年间信息技术领域十大重要的科技发展技术之一。 语音识别技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。与机器进行语音交流,让机器明白你说什么,这是人们长期以来梦寐以求的事情。中国物联网校企联盟形象得把语音识别[1] 比做为“机器的听觉系统”。语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。 语音识别技术主要包括特征提取技术、模式匹配准则及模型训练技术三个方面。语音识别技术车联网也得到了充分的引用,例如在翼卡车联网中,只需按一键通客服人员口述即可设置目的地直接导航,安全、便捷。根据识别的对象不同,语音识别任务大体可分为3类,即孤立词识别(isolated word recognition),关键词识别(或称关键词检出,keyword spotting)和连续语音识别。其中,孤立词识别 的任务是识别事先已知的孤立的词,如“开机”、“关机”等;连续语音识别的任务则是识别任意的连续语音,如一个句子或一段话;连续语音流中的关键词检测针对的是连续语音,但它并不识别全部文字,而只是检测已知的若干关键词在何处出现,如在一段话中检测“计算机”、“世界”这两个词。根据针对的发音人,可以把语音识别技术分为特定人语音识别和非特定人语音识别,前者只能识别一个或几个人的语音,而后者则可以被任何人使用。显然,非特定人语音识别系统更符合实际需要,但它要比针对特定人的识别困难得多。另外,根据语音设备和通道,可以分为桌面(PC)语音识别、电话语音识别和嵌入式设备(手机、PDA等)语音识别。不同的采集通道会使人的发音的声学特性发生变形,因此需要构造各自的识别系统。语音识别的应用领域非常广泛,常见的应用系统有:语音输入系统,相对于键盘输入方法,它更符合人的日常习惯,也更自然、更高效;语音控制系统,即用语音来控制设备的运行,相对于手动控制来说更加快捷、方便,可以用在诸如工业控制、语音拨号系统、智能家电、声控智能玩具等许多领域;智能对话查询系统,根据客户的语音进行操作,为用户提供自然、友好的数据库检索服务,例如家庭服务、宾馆服务、旅行社服务系统、订票系统、医疗服务、银行服务、股票查询服务等等。

我们需要看到,目前语音识别超过人类水平主要还是在某些受限的场景下,比如在近场麦克风和口音不重的情形下机器可以做得非常好;另外就是在语音识别系统有更多知识的场景下,比如大家经常不知道怎么转写没有接触过的一些特殊的地名和店名,而机器可以靠更大的语言模型而在这方面拥有优势。但是在更复杂场景下,尤其是在训练数据覆盖不好的场景下,机器的识别率还有待进一步提高。许多的这些复杂场景都是在使用远场麦克风时才会出现,这主要是因为麦克风距离远了之后,语音信号到达麦克风时衰减比较厉害,使得干扰信号,包括环境噪音、混响、音乐、以及其他人声的影响不能再被简单忽略。所以从需要解决的问题的角度来讲,识别系统在训练数据覆盖不好的具有多重干扰(尤其是人声干扰)的环境下的鲁棒性,是一个重要的问题。从研究的方向来讲,至少有以下几点:
* 更有效的能更好使用语言模型信息的端到端直接映射模型
* 鸡尾酒会问题的解决方案
* 能持续预测并自适应的识别系统
* 前端信号处理和后端识别系统联合优化技术

深度学习与人类语言处理-语音识别(part2)
上节回顾深度学习与人类语言处理-语音识别(part1),这节课我们将学习如何将seq2seq模型用在语音识别
LAS

那我们来看看LAS的Encoder,Attend,Decoder分别是什么
Listen
Listen是一个典型的Encoder结构,输入为声学特征({x^1,x^2,...,x^T}),输出和输入长度相同,是对声学特征的高阶表示,({h^1,h^2,...,h^T}).
我们希望Encoder可以做到以下两件事:
- 提取输入的内容信息
- 移除不同说话者之间的差异,去掉噪音
那Encoder怎么做呢?可以用RNN、CNN、self-attention
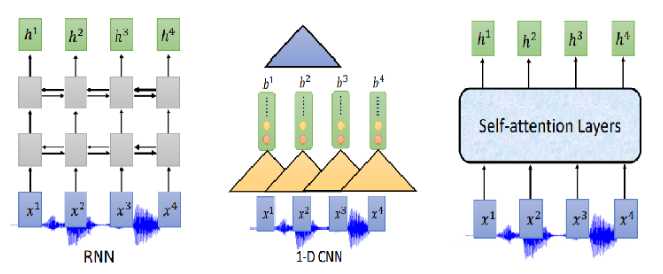
通常我们需要对声音信号进行下采样,为什么呢?当然是声音信号太长了,1s的声音信号就有100个向量(上节声学特征部分讲过),而且相邻的信号之间的差异不是特别大,下采样可以帮助我们有效的进行训练。下图是关于RNN的两个下采样方法
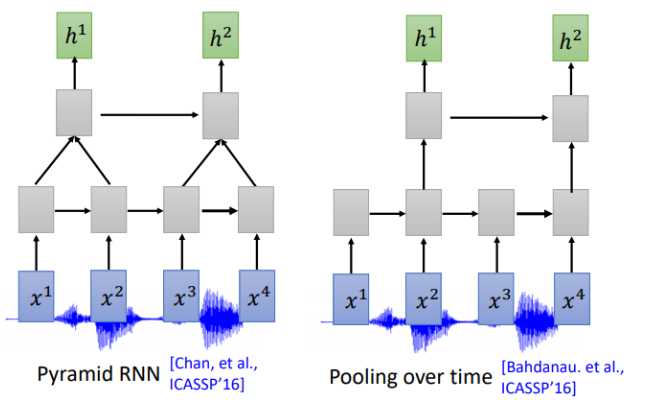
Pyramid RNN将下层每两个隐状态加起来作为下一层,实践证明这种方法还是很有效的。Pooling over time 和Pyramid RNN 很像,不同没有加起来,直接每两个隐状态取一次作为下层输入。
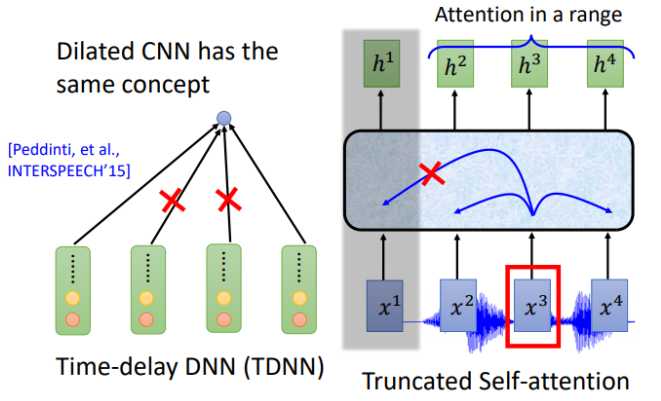
那CNN和self-attention是不是也可以用类似的下采样呢?答案是肯定的。对于CNN常用的变形是TDNN (Time-delay DNN),不同于传统的CNN做卷积操作时会考虑范围内所有的输入,TDNN相当于只让部分参与了运算,提高效率。
同样,对于self-attention,在机器翻译等任务中每一个位置的输入会看过序列中所有的输入,但是在语音识别中,序列实在太长了,Truncated Self-attention 就是让每一个位置的输入只看窗口范围内的其他输入,窗口大小是一个可以调节的参数,例如可以只看未来4个,看以前的30个。
attention
LAS的attention和机器翻译中的attention并没有什么不同,文献中提到了两种attention计算方法,dot-product attention 和additive attention
- dot-product attention
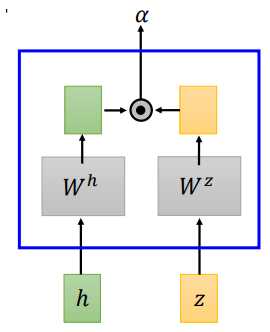
dot-product attention 将输入(h)和(z)经过矩阵(W^h、W^z)转换,将转换结果进行点积,得到(alpha)
- additive attention
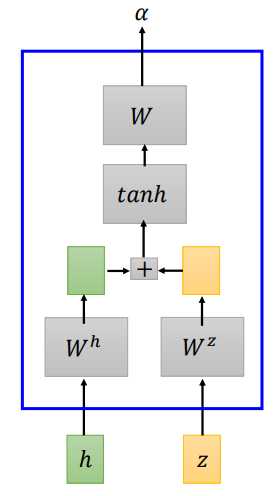
additive attention 将输入(h)和(z)经过矩阵(W^h、W^z)转换,将转换结果相加,经过一个线性变换得到(alpha)
我们来看看LAS的attention具体怎么做的
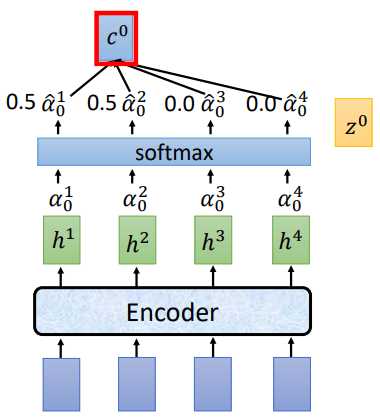
将(z^0)分别和(h^1,h^2,h^3,h^4)做attention运算得到(alpha ^1 _ 0,alpha ^2 _ 0,alpha ^3 _ 0,alpha ^4 _ 0),经过softmax归一化,再将归一化后的结果和(h^i)相乘求和得到 (c^0),将 (c^0)作为Decoder部分的输入
举个栗子:
讲过attention计算和softmax归一化后,得到的(hat{alpha_0})为[0.5,0.5,0.0,0.0],(c^0 = sumhat{alpha}^i_0h^i=0.5h^1+0.5h^2).
Spell
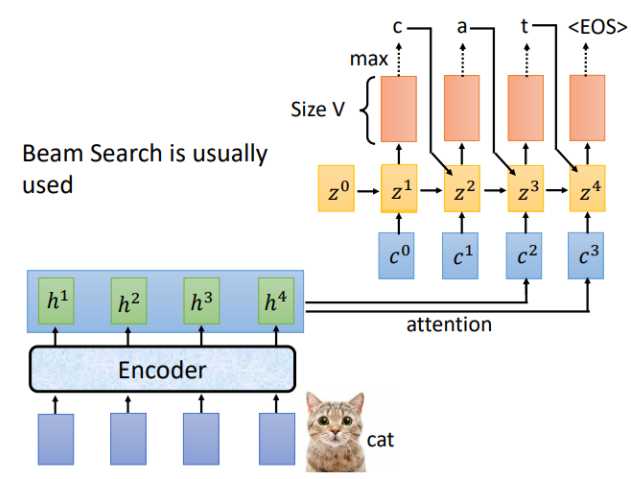
LAS的Listen对应Encoder,Spell对应的就是Decoder,假设Encoder的输入为“cat",Decoder的每一个时间步对应的输出就是词汇表中每个词的分布,通常会选概率最大的那个作为输出。
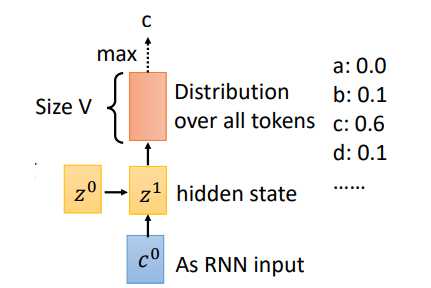
刚才是用(z^0)计算得到(c^0),现在我们用(z^1)进行运算,重复attention过程,就得到了(c^1),对应的结果如下

完整的Spell流程如下,通常输出结果会用束搜索(beam search),有关beam search 的内容可以自行了解。
Trainging
训练过程有一个重要的不同就是Teacher Forcing。刚才在Spell部分我们说到,一个时刻的输入其实有三个部分((c^1,z^0,o^0)),当前位置的attention结果context向量,上一时刻的隐状态,以及上一时刻的预测输出。但是在training阶段,我们会将(o^0)换成真实的上一时刻的输出。假如(t_0)预测的输出为(x),实际应该输出(c),我们会将(c)作为下一时刻的输入。这就是Teacher Forcing
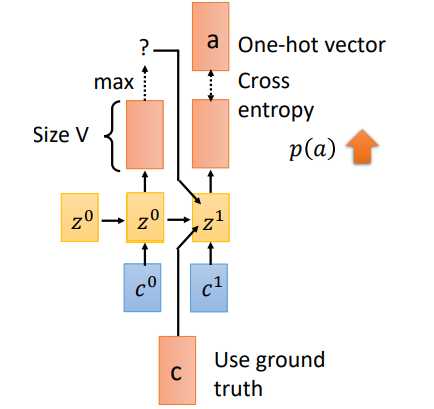
那为什么需要Teacher forcing呢?我们来看看如果使用上一时刻预测的输出作为输入会发生什么
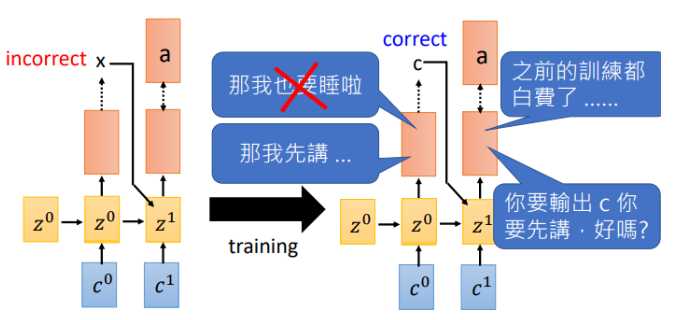
假如在(t_0)输出了(x),下一时刻机器就会学习在输入为(x)时我需要输出(a),然而等到训练的一定回合时,(t_0)可以做出正确的预测了,告诉机器输入(c)需要输出(a),此刻机器已经懵了,刚才不是说(x)对应(a)吗,那之前的训练就白费了。就开始互掐了。。。
- back to attention
我们在回到之前的attention操作,attention计算得到的context被用于下一时刻的输入(左图),现在还有另一种attention架构,将context直接用于当前时刻的输入(右图)
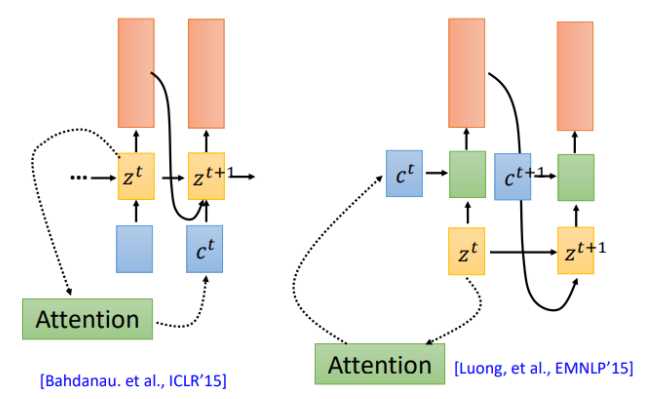
那么哪一种更有效呢?该用那个呢。第一篇使用seq2seq做语音识别的论文说:我全都要。context向量即作用于当前位置,也作用于下一位置
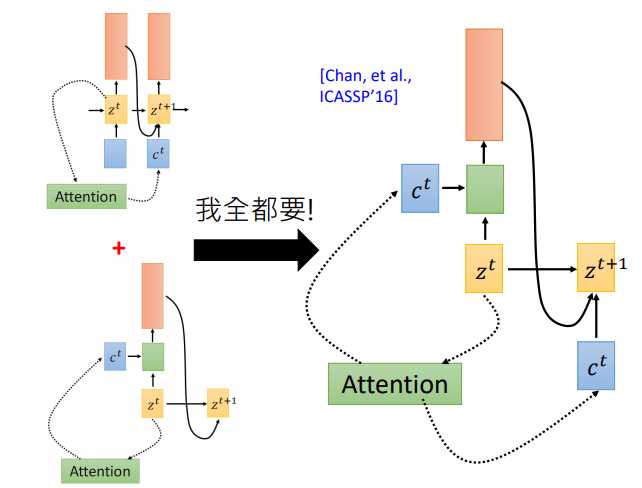
使用Attention作语音识别真的好吗?
有点杀鸡用牛刀的感觉!为好么呢,我们知道用attention的seq2seq模型首先用在机器翻译上,在翻译任务中,输入和输出没有一致的对应关系,需要attention自己寻找对应的那个词。但是对语音来说输入输出是对应的,有人提出了location-aware attention
LAS —Does it work?
刚开始的时候LAS其实打不过传统模型,后来随着训练集的增加以及各种trick,LAS已经很厉害了。可以看到刚开始的时候,打不过传统模型,2018年google在12500小时的训练集上训练,最终打败了传统模型,并没有使用location-aware attention,而且最重要的是模型变小了,从原来的7.2G变成0.4G
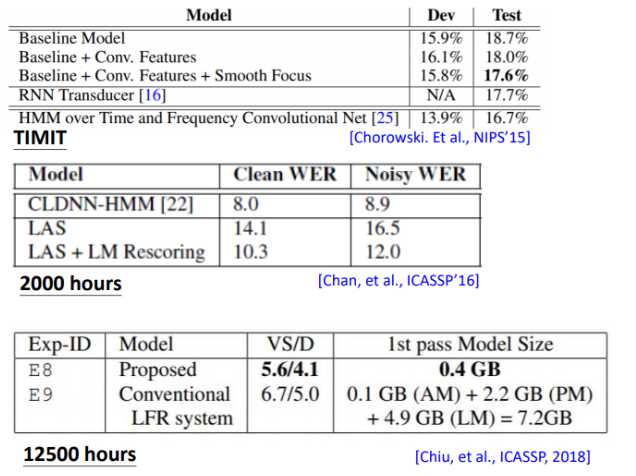
那LAS还有什么问题呢?
LAS采用经典的Encoder和Decoder架构,也就是说,只有在完整的听完一句话之后模型才会输出,那如果我们希望机器在听到声音的同时就输出怎么做呢?我们下节课再讲。
以上是关于深度学习在语音识别方面主要的难题和困难是啥?的主要内容,如果未能解决你的问题,请参考以下文章