仿牛客网项目总结
Posted woyaottk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了仿牛客网项目总结相关的知识,希望对你有一定的参考价值。
项目开源地址以及演示地址
项目地址:https://gitee.com/suosuozi/community-exchange-website
演示地址:www.suosuozi.cn
环境搭建
直接使用idea提供的模板进行创建工程

值得注意的是初始化模板的时候有几个自定义配置

架构

Spring介绍
简介
Spring 是一款开源的轻量级 Java 开发框架,旨在提高开发人员的开发效率以及系统的可维护性。
其中 IoC(Inverse of Control:控制反转) 和 AOP(Aspect-Oriented Programming:面向切面编程)是Spring的两个核心思想
Spring的一些重要模块
下图对应的是 Spring4.x 版本。目前最新的 5.x 版本中 Web 模块的 Portlet 组件已经被废弃掉,同时增加了用于异步响应式处理的 WebFlux 组件。

Spring Core
核心模块, Spring 其他所有的功能基本都需要依赖于该类库,主要提供 IoC 依赖注入功能的支持。Spring以bean的方式组织和管理Java应用中的各个组件及其关系。Spring使用BeanFactory来产生和管理Bean,它是工厂模式的实现。BeanFactory使用控制反转(IoC)模式将应用的配置和依赖性规范与实际的应用程序代码分开
Spring Aspects
该模块为与 AspectJ 的集成提供支持。
Spring AOP
提供了面向切面的编程实现。
Spring Data Access/Integration :
Spring Data Access/Integration 由 5 个模块组成:
-
spring-jdbc : 提供了对数据库访问的抽象 JDBC。不同的数据库都有自己独立的 API 用于操作数据库,而 Java 程序只需要和 JDBC API 交互,这样就屏蔽了数据库的影响。
-
spring-tx : 提供对事务的支持。
-
spring-orm : 对象关系映射,用来把对象模型表示的对象映射到基于SQL的关系模型数据库结构中去,程序中的对象与数据库通过这个桥梁进行相互转换。
-
spring-oxm : O 代表 Object,X代表XML,M代表Mapping,目的是在Java对象和XML之间进行转换操作。
-
spring-jms : Java Message Service Java 消息服务。
Spring Web
Spring Web 由 4 个模块组成:
-
spring-web :对 Web 功能的实现提供一些最基础的支持。
-
spring-webmvc : 提供对 Spring MVC 的实现。
-
spring-websocket : 提供了对 WebSocket 的支持,WebSocket 可以让客户端和服务端进行双向通信。
-
spring-webflux :WebFlux 是 Spring Framework 5.0 中引入的新的响应式框架。
Spring Test
Spring 团队提倡测试驱动开发(TDD)。有了控制反转 (IoC)的帮助,单元测试和集成测试变得更简单。
Spring 的测试模块对 JUnit(单元测试框架)等常用的测试框架支持的都比较好。
优点
| 序号 | 好处 | 说明 |
|---|---|---|
| 1 | 轻量 | Spring轻量的,基本的版本大约2MB。 |
| 2 | 控制反转 | Spring通过控制反转实现了松散耦合,对象们给出它们的依赖,不是创建或查找依赖的对象们。 |
| 3 | 面向切面编程 | Spring支持面向切面的编程,把应业务逻辑和系统服务分开。 |
| 4 | 容器 | Spring包含并管理应用中对象的生命周期和配置。 |
| 5 | 集成各种优秀框架 | Spring不排斥各种优秀的开源框架,其内部提供了对各种优秀框架(如MyBatis等)的直接支持。 |
| 6 | 支持声明式事务处理 | 只需要通过配置就可以完成对事物的管理,而无须手动编程。 |
| 7 | 方便程序的测试 | Spring提供了对Junit4的支持,可以通过注解方便的测试Spring程序。 |
IoC(Inverse of Control:控制反转)
-
控制:对与JavaBean的创建(实例化、管理)的权力
-
反转:将控制权转交给Spring框架来管理而非程序员本身
IoC是一种设计思想而非一种技术,实现IoC思想的方法是依赖注入(Dependency Injection,简称 DI)
使用 IoC 的思想,我们将对象的控制权(创建、管理)交有 IoC 容器去管理,我们在使用的时候直接向 IoC 容器 “要” 就可以了
AOP(Aspect-Oriented Programming:面向切面编程)
AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。
AOP是对与OOP的一种延伸
先以OOP举例:
假如有一个父类Animal有一个eat方法而其子类Cat、Dog继承了Animal那么Cat和Dog也会有eat方法,Java通过继承的方式使子类扩展了父类的方法,由下图可知这是一种纵向的扩展

然后以AOP举例:
假如我想让Cat的eat方法和run方法同时加上性能监控代码、日志代码等这显然会产生大量相同的代码,这部分重复的代码,一般统称为 横切逻辑代码。AOP就是为了解决这个问题

public class Animal
public void eat()
// 性能监控代码
long start = System.currentTimeMillis();
// 业务逻辑代码
System.out.println("I can eat...");
// 性能监控代码
System.out.println("执行时长:" + (System.currentTimeMillis() - start)/1000f + "s");
public void run()
// 性能监控代码
long start = System.currentTimeMillis();
// 业务逻辑代码
System.out.println("I can run...");
// 性能监控代码
System.out.println("执行时长:" + (System.currentTimeMillis() - start)/1000f + "s");
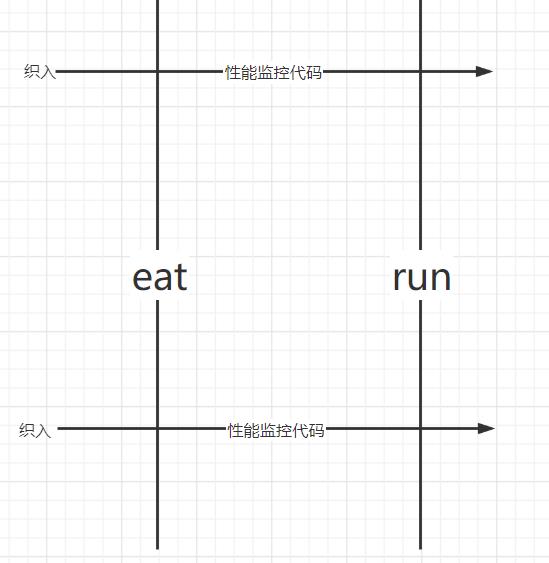
切 :指的是横切逻辑,原有业务逻辑代码不动,只能操作横切逻辑代码,所以面向横切逻辑
面 :横切逻辑代码往往要影响的是很多个方法,每个方法如同一个点,多个点构成一个面。这里有一个面的概念
这就是AOP为什么被称为面向切面编程
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么Spring AOP会使用JDK Proxy,去创建代理对象(基于Java多态的特性所以成立),而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候Spring AOP会使用Cglib ,这时候Spring AOP会使用 Cglib 生成一个被代理对象的子类来作为代理(基于Java继承的特性)。
这是代理模式的一种体现,当要调用需要被增强的方法时调用一个代理对象,而代理对象的该方法是已经被增强了,所以就达到了增强方法的作用。
Spring AOP 和 AspectJ AOP 的区别
Spring AOP 属于运行时增强,而 AspectJ 是编译时增强。 Spring AOP 基于代理(Proxying),而 AspectJ 基于字节码操作(Bytecode Manipulation)。
Spring AOP 已经集成了 AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。AspectJ 相比于 Spring AOP 功能更加强大,但是 Spring AOP 相对来说更简单,
如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择 AspectJ ,它比Spring AOP 快很多。
Spring Bean
JavaBean就是那些只有私有属性,和Getter和Setter方法的类
Spring Bean可以理解为由IoC容器管理的类
bean 的作用域
Spring 中 Bean 的作用域通常有下面几种:
-
singleton : 唯一 bean 实例,Spring 中的 bean 默认都是单例的,对单例设计模式的应用。
-
prototype : 每次请求都会创建一个新的 bean 实例。
-
request : 每一次 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP request 内有效。
-
session : 每一次来自新 session 的 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP session 内有效。
-
global-session : 全局 session 作用域,仅仅在基于 portlet 的 web 应用中才有意义,Spring5 已经没有了。Portlet 是能够生成语义代码(例如:html)片段的小型 Java Web 插件。它们基于 portlet 容器,可以像 servlet 一样处理 HTTP 请求。但是,与 servlet 不同,每个 portlet 都有不同的会话。
单例 bean 的线程安全问题
大部分时候我们并没有在项目中使用多线程,所以很少有人会关注这个问题。单例 bean 存在线程问题,主要是因为当多个线程操作同一个对象的时候是存在资源竞争的。
常见的有两种解决办法:
-
在 bean 中尽量避免定义可变的成员变量。
-
在类中定义一个
ThreadLocal成员变量,将需要的可变成员变量保存在ThreadLocal中(推荐的一种方式)。
不过,大部分 bean 实际都是无状态(没有实例变量)的(比如 Dao、Service),这种情况下, bean 是线程安全的。
例如我们可以用方法2来检测登录状态,显示登录信息,你可能有疑惑为啥不用session来存储User信息呢?因为服务器是要同时处理多个浏览器的请求的所有服务器会对不同的浏览器创建不同的线程,假如每个线程也就是浏览器都使用同一个bean那么就会产生问题。所以我门应该为一个线程创建一个bean
/**
* 用于替换session
*/
@Component
public class HostHolder
private ThreadLocal<User> users = new ThreadLocal<>();
public void setUser(User user)
users.set(user);
public User getUser()
return users.get();
public void clear()
users.remove();
我们将User对象封装到ThreadLocal中,ThreadLocal为我们提供set和get方法可以将bean放入ThreadLocal和取出,我们来看一下源码
public void set(T value)
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
其实很好理解,set方法就是先获取当前线程然后以以当前线程为key,要保存的bean为value存储到一个map当中。
public T get()
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null)
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
return setInitialValue();
get方法就是以当前线程为key从map中取数据
@Component 和 @Bean 的区别是什么?
-
@Component注解作用于类,而@Bean注解作用于方法。 -
@Component通常是通过类路径扫描来自动侦测以及自动装配到 Spring 容器中(我们可以使用@ComponentScan注解定义要扫描的路径从中找出标识了需要装配的类自动装配到 Spring 的 bean 容器中)。@Bean注解通常是我们在标有该注解的方法中定义产生这个 bean,@Bean告诉了 Spring 这是某个类的实例,当我需要用它的时候还给我。 -
@Bean注解比@Component注解的自定义性更强,而且很多地方我们只能通过@Bean注解来注册 bean。比如当我们引用第三方库中的类需要装配到Spring容器时,则只能通过@Bean来实现。
@Bean
public OneService getService(status)
case (status)
when 1:
return new serviceImpl1();
when 2:
return new serviceImpl2();
when 3:
return new serviceImpl3();
Spring 框架中用到了哪些设计模式?
-
工厂设计模式 : Spring 使用工厂模式通过
BeanFactory、ApplicationContext创建 bean 对象。 -
代理设计模式 : Spring AOP 功能的实现。
-
单例设计模式 : Spring 中的 Bean 默认都是单例的。
-
模板方法模式 : Spring 中
jdbcTemplate、hibernateTemplate等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。 -
包装器设计模式 : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
-
观察者模式: Spring 事件驱动模型就是观察者模式很经典的一个应用。
-
适配器模式 : Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配
Controller。 -
......
SpringMVC的介绍
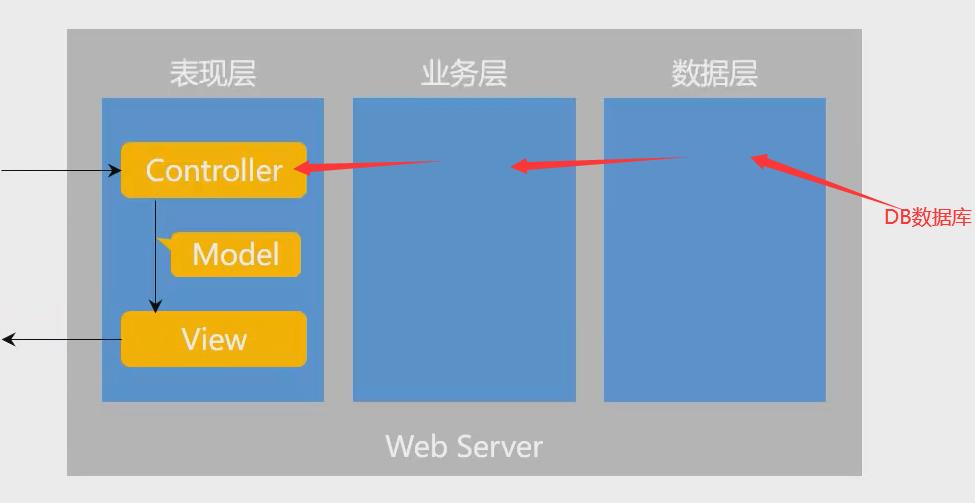
对于MVC的理解:
M代表Model,V代表View,C代表Control
MVC与三层架构是两个不一样的东西,一个是设计思想,一个是架构设计,所以其实两者是不能一一对应的SpringMVC主要是处理三层架构中View层的功能。
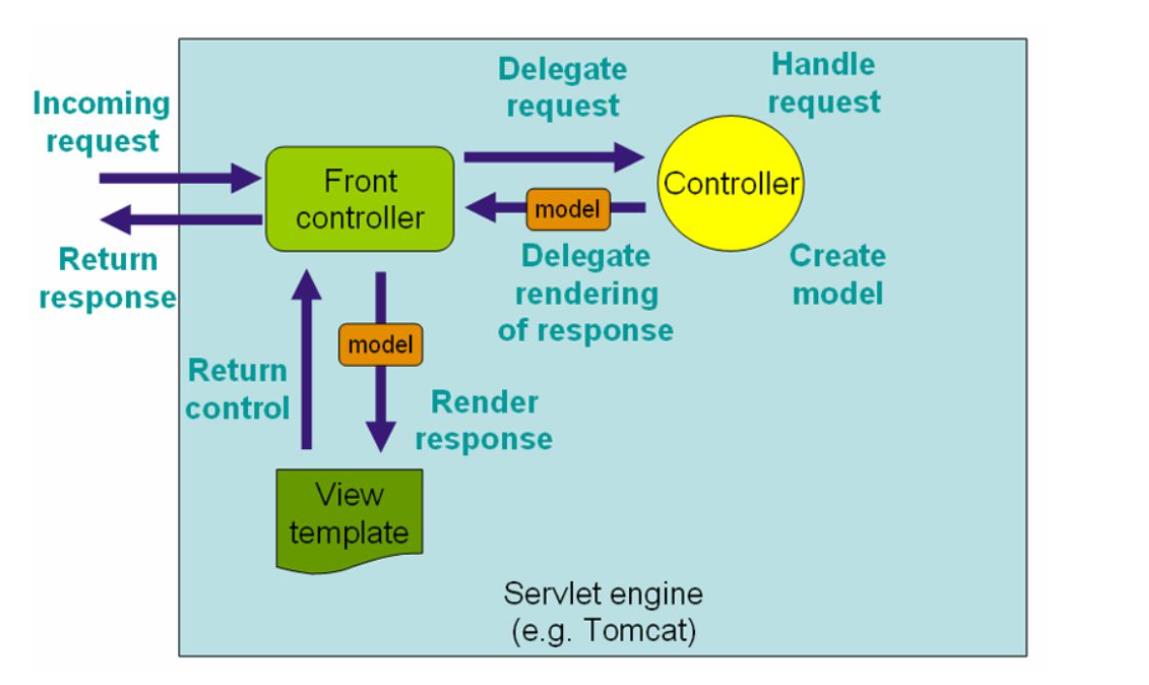
流程说明(重要):
-
客户端(浏览器)发送请求,直接请求到
DispatcherServlet。 -
DispatcherServlet根据请求信息调用HandlerMapping,解析请求对应的Handler。 -
解析到对应的
Handler(也就是我们平常说的Controller控制器)后,开始由HandlerAdapter适配器处理。 -
HandlerAdapter会根据Handler来调用真正的处理器开处理请求,并处理相应的业务逻辑。 -
处理器处理完业务后,会返回一个
ModelAndView对象,Model是返回的数据对象,View是个逻辑上的View。 -
ViewResolver会根据逻辑View查找实际的View。 -
DispaterServlet把返回的Model传给View(视图渲染)。 -
把
View返回给请求者(浏览器)
Spring 事务
事务是逻辑上的一组操作,要么都执行,要么都不执行。
事务的特性(ACID)
-
原子性(Atomicity): 一个事务(transaction)中的所有操作,或者全部完成,或者全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。即,事务不可分割、不可约简。
-
一致性(Consistency): 在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设约束、触发器、级联回滚等。
-
隔离性(Isolation): 数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括未提交读(Read uncommitted)、提交读(read committed)、可重复读(repeatable read)和串行化(Serializable)。
-
持久性(Durability): 事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。

Spring 管理事务的方式
-
编程式事务 : 在代码中硬编码(不推荐使用) : 通过
TransactionTemplate或者TransactionManager手动管理事务,实际应用中很少使用,但是对于你理解 Spring 事务管理原理有帮助。 -
声明式事务 : 在 XML 配置文件中配置或者直接基于注解(推荐使用) : 实际是通过 AOP 实现(基于
@Transactional的全注解方式使用最多)
Spring 事务中事务传播行为
事务传播行为是为了解决业务层方法之间互相调用的事务问题。
当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。
正确的事务传播行为可能的值如下:
1.TransactionDefinition.PROPAGATION_REQUIRED
使用的最多的一个事务传播行为,我们平时经常使用的@Transactional注解默认使用就是这个事务传播行为。如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
2.TransactionDefinition.PROPAGATION_REQUIRES_NEW
创建一个新的事务,如果当前存在事务,则把当前事务挂起。也就是说不管外部方法是否开启事务,Propagation.REQUIRES_NEW修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
3.TransactionDefinition.PROPAGATION_NESTED
如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
4.TransactionDefinition.PROPAGATION_MANDATORY
如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
这个使用的很少。
若是错误的配置以下 3 种事务传播行为,事务将不会发生回滚:
-
TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。 -
TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。 -
TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
Spring 事务中的隔离级别
和事务传播行为这块一样,为了方便使用,Spring 也相应地定义了一个枚举类:Isolation
public enum Isolation
DEFAULT(TransactionDefinition.ISOLATION_DEFAULT),
READ_UNCOMMITTED(TransactionDefinition.ISOLATION_READ_UNCOMMITTED),
READ_COMMITTED(TransactionDefinition.ISOLATION_READ_COMMITTED),
REPEATABLE_READ(TransactionDefinition.ISOLATION_REPEATABLE_READ),
SERIALIZABLE(TransactionDefinition.ISOLATION_SERIALIZABLE);
private final int value;
Isolation(int value)
this.value = value;
public int value()
return this.value;
下面我依次对每一种事务隔离级别进行介绍:
-
TransactionDefinition.ISOLATION_DEFAULT:使用后端数据库默认的隔离级别,mysql 默认采用的REPEATABLE_READ隔离级别 Oracle 默认采用的READ_COMMITTED隔离级别. -
TransactionDefinition.ISOLATION_READ_UNCOMMITTED:最低的隔离级别,使用这个隔离级别很少,因为它允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读 -
TransactionDefinition.ISOLATION_READ_COMMITTED: 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生 -
TransactionDefinition.ISOLATION_REPEATABLE_READ: 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。 -
TransactionDefinition.ISOLATION_SERIALIZABLE: 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
@Transactional(rollbackFor = Exception.class)注解
Exception 分为运行时异常 RuntimeException 和非运行时异常。事务管理对于企业应用来说是至关重要的,即使出现异常情况,它也可以保证数据的一致性。
当 @Transactional 注解作用于类上时,该类的所有 public 方法将都具有该类型的事务属性,同时,我们也可以在方法级别使用该标注来覆盖类级别的定义。如果类或者方法加了这个注解,那么这个类里面的方法抛出异常,就会回滚,数据库里面的数据也会回滚。
在 @Transactional 注解中如果不配置rollbackFor属性,那么事务只会在遇到RuntimeException的时候才会回滚,加上 rollbackFor=Exception.class,可以让事务在遇到非运行时异常时也回滚。
数据库表的梳理
总共5张表,
-
comment:
CREATE TABLE `comment` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) DEFAULT NULL,
`entity_type` int(11) DEFAULT NULL,
`entity_id` int(11) DEFAULT NULL,
`target_id` int(11) DEFAULT NULL,
`content` text,
`status` int(11) DEFAULT NULL,
`create_time` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `index_user_id` (`user_id`) /*!80000 INVISIBLE */,
KEY `index_entity_id` (`entity_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;评论表,其中user_id用于表示发这条评论的用户id
entity_type表示评论的类型 1表示回复帖子的评论 2表示回复评论的评论
entity_id表示该评论的帖子id
target_id表示回复时回复对象的id,如果id=0说明这是一条回复帖子的评论,如果id!=0说明这是回复target_id用户的评论
content评论内容
status评论的状态0表示有用的评论 1表示以删除的评论
create_time评论的发表时间
-
discuss_post:
CREATE TABLE `discuss_post` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(45) DEFAULT NULL,
`title` varchar(100) DEFAULT NULL,
`content` text,
`type` int(11) DEFAULT NULL COMMENT '0-普通; 1-置顶;',
`status` int(11) DEFAULT NULL COMMENT '0-正常; 1-精华; 2-拉黑;',
`create_time` timestamp NULL DEFAULT NULL,
`comment_count` int(11) DEFAULT NULL,
`score` double DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `index_user_id` (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;帖子表,
user_id表示发帖人的id
title表示标题
content表示帖子内容
type表示帖子类型 0表示普通帖子 1表示置顶帖子
status表示帖子的状态 0表示正常帖子 1表示精华帖 2表示拉黑帖
create_time表示发帖日期
comment_count表示帖子的评论数,是一个冗余参数,目的是为了提供查询效率
score
-
login_ticket:
CREATE TABLE `login_ticket` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`ticket` varchar(45) NOT NULL,
`status` int(11) DEFAULT '0' COMMENT '0-有效; 1-无效;',
`expired` timestamp NOT NULL,
PRIMARY KEY (`id`),
KEY `index_ticket` (`ticket`(20))
) ENGINE=InnoDB DEFAULT CHARSET=utf8;登录凭证表,目的是为了保护用户数据的安全,用于检测用户是否处于登录状态,然后在启动服务器时通过拦截器获取登录凭证创建User对象
user_id用户id
ticket凭证编号
status凭证状态 0表示有效凭证 1表示无效凭证
expired用于检测这个凭证是否已经过期
-
message:
CREATE TABLE `message` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`from_id` int(11) DEFAULT NULL,
`to_id` int(11) DEFAULT NULL,
`conversation_id` varchar(45) NOT NULL,
`content` text,
`status` int(11) DEFAULT NULL COMMENT '0-未读;1-已读;2-删除;',
`create_time` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `index_from_id` (`from_id`),
KEY `index_to_id` (`to_id`),
KEY `index_conversation_id` (`conversation_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;消息表
from_id是发消息的人的id
to_id是发送目标的人的id
conversation_id也是一个冗余的字段目的是便于查询,规则以from_id和to_id用_拼接且小的在前大的在后
content消息内容
status消息的状态 0表示未读 1表示已读 2表示删除
create_time消息的发送时间
-
user:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(50) DEFAULT NULL,
`password` varchar(50) DEFAULT NULL,
`salt` varchar(50) DEFAULT NULL,
`email` varchar(100) DEFAULT NULL,
`type` int(11) DEFAULT NULL COMMENT '0-普通用户; 1-超级管理员; 2-版主;',
`status` int(11) DEFAULT NULL COMMENT '0-未激活; 1-已激活;',
`activation_code` varchar(100) DEFAULT NULL,
`header_url` varchar(200) DEFAULT NULL,
`create_time` timestamp NULL DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `index_username` (`username`(20)),
KEY `index_email` (`email`(20))
) ENGINE=InnoDB AUTO_INCREMENT=101 DEFAULT CHARSET=utf8;用户表
username用户名称
password用户密码
salt盐用来加密
email用户的邮箱
type用户的类型 0表示普通用户 1表示超级管理员 2表示版主
status 0表示未激活 1表示激活
activation_code激活码
header_url头像地址
create_time用户注册时间
业务梳理
首先业务就是先思考前端需要展示什么什么数据,然后在考虑后端需要什么数据进行处理才能得到前端所需要的数据,最后才是考虑如何处理才能得到目标数据(也就是考虑条件是什么,目标是什么)
后端一定要有一个意识就是程序的完整性,上来二话不说先判断前端返回的数据是否为空,如果为空要进行什么样的处理
开发首页的业务梳理
开发首页需要返回给前端什么数据?
-
帖子的标题
-
发帖人的头像
-
发帖人的名称
-
发帖的时间
仅此而已
后端需要什么样的数据进行处理才能得到这些数据呢?
显然这些数据都与帖子有关所以我们只需要查询帖子表然后将帖子表数据一一展示即可
为了减小服务器和浏览器的压力还得要进行分页处理
分页其实很简单有个叫做pageHelper的插件能轻松解决问题
注册功能业务梳理
前端需要什么数据?
注册功能前端其实不需要什么数据,或者说需要一个反馈,比如注册成功,注册失败,用户名已经存在,邮箱名已经存在等等
后端需要什么数据?
这是一个表单,后端需要的数据就是前端表单里的所有数据咯,非常的无脑简单
首先要考虑的业务功能是当鼠标离开账号框时就进行检测是否账号已存在,这个技术可以采用ajax的技术来实现,前端当触发离开文本框时间时,调用后端查数据库的操作,后端将bool值异步返回给前端进行展示
然后就是邮箱的问题了,先进行和上述一样的操作,然后全部没问题之后进行后端service的操作,将表单数据封装成一个User,然后将Userinsert到数据库中,注意此时的user的激活状态处于未激活状态,并且提供一个激活码,然后发送一封邮件给用户用于激活账号,这封邮件中包含一个超链接,这个超链接中跳转的地址携带一个激活码的参数和用户id,后端获取这个参数通过数据库进行比对如果激活码一致则激活账号,返回相应页面,否则直接返回相应页面并提供错误信息
发送邮件的功能实现
发送邮件的功能是为注册功能做准备的,发送邮件用到了Spring Email的技术
来先简单介绍一下该技术
首先进行配置文件,配置文件的目的是告诉Spring需要用哪个邮箱来发送邮件
spring:
mail:
host: smtp.qq.com
port: 465
username: ***@qq.com
password: ***
protocol: smtps
properties:
mail.smtp.auth: true
mail.smtp.starttls.enable: true
mail.smtp.starttls.required: true
mail.smtp.socketFactory.port: 465
mail.smtp.socketFactory.class: javax.net.ssl.SSLSocketFactory
mail.smtp.socketFactory.fallback: false首先是JavaMailSender提供了一个发送邮件send的方法
send方法的参数需要一个MimeMessage进行封装,封装的参数是邮件的发送方,邮件的接受方,邮件的主题,邮件的内容
而MimeMessage不方便进行封装所以Spring又提供了一个类MimeMessageHelper进行封装
MimeMessage通过JavaMailSender的createMimeMessage方法得到
MimeMessageHelper通过MimeMessageHelper的有参构造得到参数就是MimeMessage
再将MimeMessage通过MimeMessageHelper的getMimeMessage方法得到
最后将MimeMessage作为参数传递给send
@Component
public class MailClient
private static final Logger logger = LoggerFactory.getLogger(MailClient.class);
@Autowired
private JavaMailSender mailSender;
@Value("$spring.mail.username")
private String from;
public void sendMail(String to, String subject, String content)
try
MimeMessage mimeMessage = mailSender.createMimeMessage();
MimeMessageHelper helper = new MimeMessageHelper(mimeMessage);
helper.setFrom(from);
helper.setTo(to);
helper.setText(content,true);//表示可以发送HTML文件
helper.setSubject(subject);
mailSender.send(helper.getMimeMessage());
catch (MessagingException e)
logger.error("发送邮件失败:" + e.getMessage());
如果想要发送HTML文件的话 只需要将helper.setText(content,true)方法参数设置为true即可
如果想要返回一个动态渲染后的HTML的话thymeleaf提供了一个模板引擎templateEngine
Context context = new Context();
context.setVariable("username","test");
String process = templateEngine.process("/mail/demo", context);我们只需要new一个Context对象然后将需要动态生成的参数以key:value的形式通过setVariable方法传参即可
最后指定你要发送的HTML路径templateEngine的process方法会自动帮你完成任务
登录与退出功能的业务梳理
登录和退出功能就太简单了
前端需要什么数据?
nothing 或者提供一些交互信息
后端需要什么数据
就是表单数据
登录这个功能还是值得玩味的,传统的做法是直接查询user表获取user对象然后将user对象放入session中,然后之后的一切操作全部基于这个session。
好我们现在来思考一下这个方案有什么问题

如果现在是这么一个状态,现在有多个服务器来处理浏览器请求,那么就会出现这么一个现象一开始是服务器1处理浏览器请求然后下一个请求用服务器2来处理数据此时服务器2没有session对象那么此时服务器就会报错或者重新创建一个新的session对象,这样不仅效率低还浪费资源。不要跟我讲可以用cookie来处理,用cookie的数据是十分不安全的!!!
解决方案
我们新建了一个表叫做凭证表,诶!!!把凭证放到cookie中是不是就安全啦,因为我只放了一个凭证的号码到cookie中其他私密信息都没放到浏览器中
好此时你可能会想这么操作是不是有点浪费资源了,并且效率还不高所以我们采用Redis进行优化
Redis最重要就是对于Key的设计不过这个业务比较无脑直接以凭证为key再加个前缀就好了
private static final String SPLIT = ":";
private static final String PREFIX_TICKET = "ticket";
// 登录的凭证
public static String getTicketKey(String ticket)
return PREFIX_TICKET + SPLIT + ticket;
现在的登录操作就很有趣了,首先第一次登录的时候服务器会发给浏览器一个cookie里面放了个凭证,然后之后登录都是通过拦截器获取这个凭证,再通过这个凭证查询Redis数据库获取userid再通过这个userid查询数据库获得user
好接下来我们再考虑一种情况
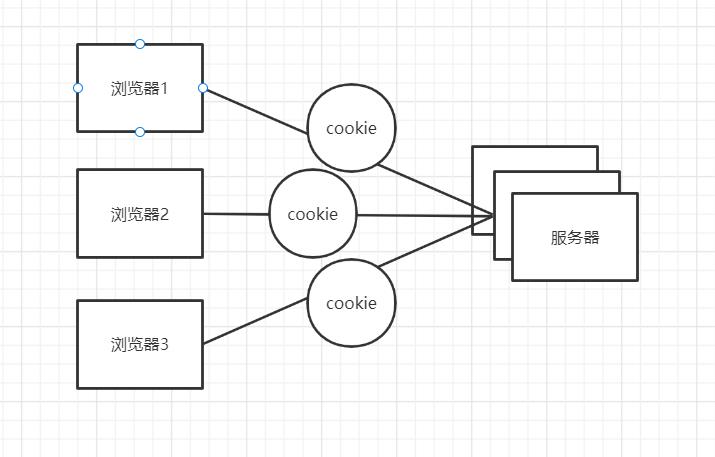
此时有多个浏览器同时发给服务器cookie那么此时服务器创建的user对象到底是哪个cookie呢???
这就涉及到单例 bean 的线程安全问题
大部分时候我们并没有在项目中使用多线程,所以很少有人会关注这个问题。单例 bean 存在线程问题,主要是因为当多个线程操作同一个对象的时候是存在资源竞争的。
常见的有两种解决办法:
-
在 bean 中尽量避免定义可变的成员变量。
-
在类中定义一个
ThreadLocal成员变量,将需要的可变成员变量保存在ThreadLocal中(推荐的一种方式)。
不过,大部分 bean 实际都是无状态(没有实例变量)的(比如 Dao、Service),这种情况下, bean 是线程安全的。
例如我们可以用方法2来检测登录状态,显示登录信息,你可能有疑惑为啥不用session来存储User信息呢?因为服务器是要同时处理多个浏览器的请求的所有服务器会对不同的浏览器创建不同的线程,假如每个线程也就是浏览器都使用同一个bean那么就会产生问题。所以我门应该为一个线程创建一个bean
/**
* 用于替换session
*/
@Component
public class HostHolder
private ThreadLocal<User> users = new ThreadLocal<>();
public void setUser(User user)
users.set(user);
public User getUser()
return users.get();
public void clear()
users.remove();
我们将User对象封装到ThreadLocal中,ThreadLocal为我们提供set和get方法可以将bean放入ThreadLocal和取出,我们来看一下源码
public void set(T value)
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
其实很好理解,set方法就是先获取当前线程然后以以当前线程为key,要保存的bean为value存储到一个map当中。
public T get()
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null)
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
return setInitialValue();
get方法就是以当前线程为key从map中取数据
这样就可以解决这个问题了,每个线程一个user,然后我们再创建一个拦截器,当访问服务器时就将user对象set到ThreadLocal中,需要的时候get一下就好了
SpringMVC拦截器
我们来复习一下SpringMVC的拦截器技术
步骤:
-
创建拦截器
@Component
public class LoginTicketInterceptor implements HandlerInterceptor
@Autowired
private UserService userService;
@Autowired
private HostHolder hostHolder;
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception
//从cookie中获取凭证
String ticket = CookieUtil.getValue(request, "ticket");
if(ticket != null)
LoginTicket loginTicket = userService.findLoginTicket(ticket);
if(loginTicket != null && loginTicket.getStatus() == 0 && loginTicket.getExpired().after(new Date()))
User user = userService.findUserById(loginTicket.getUserId());
hostHolder.setUser(user);
return true;
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception
User user = hostHolder.getUser();
if(user != null && modelAndView!= null)
modelAndView.addObject("loginUser",user);
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception
hostHolder.clear();
拦截器必须继承HandlerInterceptor然后重写三个方法
-
preHandle 在目标方法执行前执行
-
postHandle 在目标方法执行之后,视图未返回前执行
-
afterCompletion 在整个流程执行完毕后执行
-
创建配置类
@Configuration
public class WebMvcConfig implements WebMvcConfigurer
@Autowired
private LoginTicketInterceptor loginTicketInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry)
registry.addInterceptor(loginTicketInterceptor).excludePathPatterns("/**/*.css", "/**/*.js", "/**/*.png", "/**/*.jpg", "/**/*.jpeg");
-
addInterceptor:添加拦截器
-
excludePathPatterns:将一些资源进行除外,不进行拦截
回显登录信息的业务梳理
前端需要什么数据?
user对象
后端需要什么数据?
cookie对象
所以其实我们只需要通过cookie来创建user对象就好了,怎么得到呢?上面已经解决了直接ThreadLocal中get一下就好了
修改个人信息的业务梳理
修改信息分为两部分1. 修改头像 2. 修改密码
当然修改前要先判断用户是否已经登录了,其实也有简单粗暴的方法就是,给每个需要检验用户是否登录的方法都进行判断,但这太low了,上面提到了一个拦截器的方法可以用拦截器来实现此功能。用于拦截未登录状态时防止用户进行操作修改数据库
这时又出现了一些问题,那就是拦截器的配置,当你每需要创建一个要被拦截的类时,就要修改拦截器源码,或者些不需要拦截的类时也要修改源码,排除这些类,这时你会想这岂不是比暴力法还麻烦。这里提供一个注解的方法,自己写一个注解,当被这个注解标注时,就会被这个拦截器拦截
元注解一共有四个
-
@Target注解 Target注解的作用是:描述注解的使用范围(即:被修饰的注解可以用在什么地方) 。
-
@Retention注解 Reteniton注解的作用是:描述注解保留的时间范围(即:被描述的注解在它所修饰的类中可以被保留到何时) 。
-
@Documented注解 Documented注解的作用是:描述在使用 javadoc 工具为类生成帮助文档时是否要保留其注解信息。
-
@Inherited注解 Inherited注解的作用是:使被它修饰的注解具有继承性(如果某个类使用了被@Inherited修饰的注解,则其子类将自动具有该注解)。
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface LoginRequired
然后我们只需要在需要拦截的方法上添加这个注解就好了
接下来就是编写拦截器了
@Component
public class LoginRequiredInterceptor implements HandlerInterceptor
@Autowired
private HostHolder hostHolder;
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception
if (handler instanceof HandlerMethod)
HandlerMethod handlerMethod = (HandlerMethod) handler;
Method method = handlerMethod.getMethod();
LoginRequired annotation = method.getAnnotation(LoginRequired.class);
if (annotation != null && hostHolder.getUser() == null)
response.sendRedirect(request.getContextPath() + "/login");
return false;
return true;
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception
HandlerInterceptor.super.postHandle(request, response, handler, modelAndView);
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception
HandlerInterceptor.super.afterCompletion(request, response, handler, ex);
最后配置类修改一下
@Configuration
public class WebMvcConfig implements WebMvcConfigurer
@Autowired
private LoginTicketInterceptor loginTicketInterceptor;
@Autowired
private LoginRequiredInterceptor loginRequiredInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry)
registry.addInterceptor(loginTicketInterceptor).excludePathPatterns("/**/*.css", "/**/*.js", "/**/*.png", "/**/*.jpg", "/**/*.jpeg");
registry.addInterceptor(loginRequiredInterceptor).excludePathPatterns("/**/*.css", "/**/*.js", "/**/*.png", "/**/*.jpg", "/**/*.jpeg");
过滤完后可以正式进入修改信息的主题了
首先是修改头像也就是上传图片的功能
这里涉及SpringMVC文件上传的功能
SpringMVC文件上传
文件上传三要素
-
表单项type="file"
-
表单的提交方式是post
-
表单的enctype="multipart/form-data"
当满足这三个条件时上传文件SpringMVC为我们提供了一个参数MultipartFile,然后这个对象为我们提供了一个方法transferTo(File(url))
@LoginRequired
@RequestMapping(path = "/upload", method = RequestMethod.POST)
public String uploadHeader(MultipartFile headerImage, Model model)
//判断上传文件是否为空
if (headerImage == null)
model.addAttribute("error", "您还没有选择图片!");
return "/site/setting";
//获取文件名的后缀
String fileName = headerImage.getOriginalFilename();
String suffix = fileName.substring(fileName.lastIndexOf("."));
if (StringUtils.isBlank(suffix))
model.addAttribute("error", "文件的格式不正确!");
return "/site/setting";
// 生成随机文件名
fileName = CommunityUtil.generateUUID() + suffix;
// 确定文件存放的路径
File dest = new File(uploadPath + "/" + fileName);
try
//转存文件
headerImage.transferTo(dest);
catch (IOException e)
logger.error("上传文件失败: " + e.getMessage());
throw new RuntimeException("上传文件失败,服务器发生异常!", e);
// 更新当前用户的头像的路径(web访问路径)
User user = hostHolder.getUser();
String headerUrl = domain + contextPath + "/user/header/" + fileName;
userService.updateHeader(user.getId(), headerUrl);
return "redirect:/index";
现在我们来梳理业务逻辑:
为了防止上传重复名的文件导致文件被覆盖所以我们采用生成随机字符串的方式来解决这个问题,所以我们要获得文件的后缀然后拼上随机字符串。最后调用transferTo方法进行转存就好了
过滤敏感词

过滤铭感词这个业务分为两部分(众所周知程序=数据结构+算法)
-
敏感词应该用什么数据结构来存储?
-
如果辨别一个字符串时敏感词,也就是说采用什么算法来过滤敏感词?
第一个问题:我对于敏感词采用树的结构来存储,值得注意的时这个树还得要一个boolean来记录这个节点是否时最后一个节点,树有常见的表示发有双亲表示法,孩子兄弟表示法,孩子表示法,我这里采用的是孩子表示法
// 前缀树
private class TrieNode
// 关键词结束标识
private boolean isKeywordEnd = false;
// 子节点(key是下级字符,value是下级节点)
private Map<Character, TrieNode> subNodes = new HashMap<>();
public boolean isKeywordEnd()
return isKeywordEnd;
public void setKeywordEnd(boolean keywordEnd)
isKeywordEnd = keywordEnd;
// 添加子节点
public void addSubNode(Character c, TrieNode node)
subNodes.put(c, node);
// 获取子节点
public TrieNode getSubNode(Character c)
return subNodes.get(c);
然后树的初始化操作
@PostConstruct
public void init()
try (
InputStream is = this.getClass().getClassLoader().getResourceAsStream("sensitive-words.txt");
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
)
String keyword;
while ((keyword = reader.readLine()) != null)
// 添加到前缀树
this.addKeyword(keyword);
catch (IOException e)
logger.error("加载敏感词文件失败: " + e.getMessage());
// 将一个敏感词添加到前缀树中
private void addKeyword(String keyword)
TrieNode tempNode = rootNode;
for (int i = 0; i < keyword.length(); i++)
char c = keyword.charAt(i);
TrieNode subNode = tempNode.getSubNode(c);
if (subNode == null)
// 初始化子节点
subNode = new TrieNode();
tempNode.addSubNode(c, subNode);
// 指向子节点,进入下一轮循环
tempNode = subNode;
// 设置结束标识
if (i == keyword.length() - 1)
tempNode.setKeywordEnd(true);
第二个问题采用什么算法?
我这里使用三个指针的方式,第一个指针指向树,第二个指针指向要判断字符串的头,第三个指针指向这个字符串的结尾。
思路:
首先起始指针与树进行比对观察是否有匹配的值如果没有则2,3两个指针向后移动一位,如果有则1, 3指针向后移动一位,然后进行判断3指针是否有匹配的节点如果有则1,3向后移动一位并且判断此节点是否为最后一位节点如果是则屏蔽。然后1节点指回root,3++,2=3;如果中途发现没有匹配的节点了说明这不是敏感词,2++,3=2;
/**
* 过滤敏感词
*
* @param text 待过滤的文本
* @return 过滤后的文本
*/
public String filter(String text)
if(StringUtils.isBlank(text))
return null;
// 指针1
TrieNode tempNode = rootNode;
// 指针2
int begin = 0;
// 指针3
int position = 0;
// 结果
StringBuilder sb = new StringBuilder();
while(begin < text.length())
if(position < text.length())
Character c = text.charAt(position);
// 跳过符号
if (isSymbol(c))
if (tempNode == rootNode)
begin++;
sb.append(c);
position++;
continue;
// 检查下级节点
tempNode = tempNode.getSubNode(c);
if (tempNode == null)
// 以begin开头的字符串不是敏感词
sb.append(text.charAt(begin));
// 进入下一个位置
position = ++begin;
// 重新指向根节点
tempNode = rootNode;
// 发现敏感词
else if (tempNode.isKeywordEnd())
sb.append(REPLACEMENT);
begin = ++position;
// 重新指向根节点
tempNode = rootNode;
// 检查下一个字符
else
position++;
// position遍历越界仍未匹配到敏感词
else
sb.append(text.charAt(begin));
position = ++begin;
tempNode = rootNode;
return sb.toString();
// 判断是否为符号
private boolean isSymbol(Character c)
// 0x2E80~0x9FFF 是东亚文字范围
return !CharUtils.isAsciiAlphanumeric(c) && (c < 0x2E80 || c > 0x9FFF);
发布帖子功能的业务梳理
这个功能就很无脑了,还是老样子先思考条件是什么目标是什么
前端需要什么样的数据?
前端不需要数据顶多一个信息交互的提示
后端需要什么数据?
一个是表单一个用户,用户可以直接从ThreadLocal中get,所以其实只需要一个表单数据就好。
梳理
后端从前端获取表单数据然后从ThreadLocal中得到User然后调用插入数据库的方法即可
帖子详情
这个功能也很无脑
前端需要什么样的数据?
前端需要帖子的详细信息和用户的头像和名称
后端需要什么数据?
这个帖子的id
梳理
后端根据帖子的id查询数据库然后将数据返回给前端就好了
事务管理
这里介绍一下Spring的事务管理操作
SpringMVC的声明式事务还是很简单的
直接使用注解就好了@Transactional
在要使用事务的方法上加上这个注解@Transactional然后注解里写上事务的隔离级别和传播行为就好了
@Transactional(isolation = Isolation.READ_COMMITTED, propagation = Propagation.REQUIRED)显示评论
这块应该也属于帖子详情的一部分,因为评论是线上在帖子下面的,还是那样
前端需要什么数据
需要评论者头像姓名、评论的内容时间以及类型,因为要展示这是个评论还是回复,如果是回复还得要显示回复对象名称
后端需要什么
帖子id就够了!!!因为有帖子id我就能得到发帖人以及通过查询评论表得到评论的相关信息(评论人,评论类型,评论内容,如果类型是评论还会有回复对象)
业务梳理
后端从前端获取帖子id通过查询评论表然后首先判断评论类型如果是评论则直接显示如果回复则获取回复人的id和被回复的人的id然后查数据库返回给前端
添加评论
前端需要什么?
前端需要有一个来自后端的提示
后端需要什么
帖子id,时间,目标id,目标类型,回复内容,回复人的id
业务梳理
根据回复的地方不同,可以获取回复类型,用户id,帖子id时间回复内容很容易获取,回复目标人id如果是回复帖子则设置为0否则直接从前端页面获取
私信列表
前端需要啥
前端需要私信人信息,以及跟他的第一条聊天记录,以及聊天记录数,未读数据,首页还需要未读数据
后端需要啥
用户id就好了
业务梳理
通过用户id查询消息表找到所有有聊天记录的根据聊天人id进行分类然后将第一条数据返回,点击查看将数据全部标记已读
关键这些信息可以在用户登录时就进行获取因为首页可以显示未读数量
所以我们采用一个拦截器
@Component
public class MessageInterceptor implements HandlerInterceptor
@Autowired
private HostHolder hostHolder;
@Autowired
private MessageService messageService;
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception
User user = hostHolder.getUser();
if (user != null && modelAndView != null)
int letterUnreadCount = messageService.findLetterUnreadCount(user.getId(), null);
int noticeUnreadCount = messageService.findNoticeUnreadCount(user.getId(), null);
Java牛客项目课_仿牛客网讨论区_第五章
文章目录
第五章:Kafka,构建TB级异步消息系统(Kafka端口9092)(Zookeeper端口2181)
5.1、阻塞队列

生产者和消费者线程直接接触,如果生产者速度快于消费者,那么生产者生产的数据不会被消费者消费,那么生产者占用着CPU生产就浪费了系统资源。一方面,生产的数据被浪费,另一方面,白白占用CPU资源。如果在生产者消费者之间加个阻塞队列,生产者把队列生产满了,那么生产者会阻塞,阻塞不会占用CPU,所以可以避免系统资源被白白浪费掉。
BlockingQueueTests
import java.util.Random;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class BlockingQueueTests {
public static void main(String[] args) {
BlockingQueue queue = new ArrayBlockingQueue(10);
new Thread(new Producer(queue)).start();
new Thread(new Consumer(queue)).start();
new Thread(new Consumer(queue)).start();
new Thread(new Consumer(queue)).start();
}
}
class Producer implements Runnable {
private BlockingQueue<Integer> queue;
public Producer(BlockingQueue<Integer> queue) {
this.queue = queue;
}
@Override
public void run() {
try {
for (int i = 0; i < 100; i++) {
Thread.sleep(20);
queue.put(i);
System.out.println(Thread.currentThread().getName() + "生产:" + queue.size());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
class Consumer implements Runnable {
private BlockingQueue<Integer> queue;
public Consumer(BlockingQueue<Integer> queue) {
this.queue = queue;
}
@Override
public void run() {
try {
while (true) {
Thread.sleep(new Random().nextInt(1000));
queue.take();
System.out.println(Thread.currentThread().getName() + "消费:" + queue.size());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
5.5、Kafka入门
牛客课程助教1#
关于Kafka使用的重要提示
现象:在windows的命令行里启动kafka之后,当关闭命令行窗口时,就会强制关闭kafka。这种关闭方式为暴力关闭,很可能会导致kafka无法完成对日志文件的解锁。届时,再次启动kafka的时候,就会提示日志文件被锁,无法成功启动。
方案:将kafka的日志文件全部删除,再次启动即可。
建议:不要暴力关闭kafka,建议通过在命令行执行kafka-server-stop命令来关闭它。
其他:将来在Linux上部署kafka之后,采用后台运行的方式,就会避免这样的问题。
发表于 2019-08-06 12:11:43
牛友2#
老师关闭kafka的方式可以说的再具体一点吗,zookeeper也要用命令行的模式关闭吗,然后每次写写项目的时候要重新把kafka打开吗?
牛客课程助教 V 助教 : 在命令行中调用zookeeper-server-stop.bat关闭zookeeper,在命令行中调用kafka-server-stop.bat关闭kafka。每次运行项目之前,都要保证他们是启动的状态。
2019-08-22 19:06:45回复赞(0)
牛客课程助教 V 助教 : 直接关闭命令行的话,这属于暴力关闭,kafka没有走正常的销毁流程,可能会导致某些文件被锁定,下次启动报错。
2019-08-23 10:16:08
对硬盘的顺序读写的速度要高于对内存的随机读写。Kafka利用这一点,可以保证吞吐量,硬盘容量大,于是它能处理海量数据。Kafka是分布式的服务器,一台挂了还有另一台,因此它能保证高可靠性。有高扩展性,想加一台服务器很方便,简单配置下就好。
Zookeeper是用来管理集群的,其他需要集群的中间件,都可以用到zookeeper。
消息队列有两种实现方式:
点对点模式:每个数据只被一个消费者消费,比如上节课那种,一个生产者,多个消费者,一个阻塞队列。
发布订阅模式:消息可以被很多消费者同时/先后读取。Kafka是这种。
先启动zookeeper(第一个命令行窗口):
F:\\Kafka\\kafka_2.13-2.7.0\\bin\\windows>zookeeper-server-start.bat ..\\..\\config\\zookeeper.properties
启动成功,就显示:
[2021-04-14 08:31:02,245] INFO binding to port 0.0.0.0/0.0.0.0:2181 (org.apache.zookeeper.server.NIOServerCnxnFactory)
再启动Kafka(第二个命令行窗口):
F:\\Kafka\\kafka_2.13-2.7.0\\bin\\windows>kafka-server-start.bat ..\\..\\config\\server.properties
启动成功,就显示:
[2021-04-14 08:32:46,162] INFO [GroupCoordinator 0]: Loading group metadata for community-consumer-group with generation 16 (kafka.coordinator.group.GroupCoordinator)
[2021-04-14 08:32:46,162] INFO [GroupMetadataManager brokerId=0] Finished loading offsets and group metadata from __consumer_offsets-28 in 259 milliseconds, of which 190 milliseconds was spent in the scheduler. (kafka.coordinator.group.GroupMetadataManager)
再建立topic,然后查看是否建立成功,然后这边控制台作为生产者生产两条消息:
F:\\Kafka\\kafka_2.13-2.7.0\\bin\\windows>kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test
Created topic test.
F:\\Kafka\\kafka_2.13-2.7.0\\bin\\windows>kafka-topics.bat --list --bootstrap-server localhost:9092
test
F:\\Kafka\\kafka_2.13-2.7.0\\bin\\windows>kafka-console-producer.bat --broker-list localhost:9092 --topic test
>hello
>world
>
然后再开一个控制台作为消费者来接收消息:
F:\\Kafka\\kafka_2.13-2.7.0\\bin\\windows>kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
hello
world
后面继续在生产者那边的控制台窗口输入消息,消费者这边的控制台窗口可以很快接收到消息。
1、
问题:【 输入行太长。 命令语法不正确。】windows10下 Kafka环境搭建。
解决方法:使用较短的文件夹和文件的名称。减少文件夹树的深度。
2、
问题:
F:\\Kafka\\kafka_2.13-2.7.0\\bin\\windows>kafka-topics.bat --create --bootstrap-server localhost:9092 --replication-factor 1 --partition 1 --topic test
Exception in thread "main" joptsimple.UnrecognizedOptionException: partition is not a recognized option
at joptsimple.OptionException.unrecognizedOption(OptionException.java:108)
at joptsimple.OptionParser.handleLongOptionToken(OptionParser.java:510)
at joptsimple.OptionParserState$2.handleArgument(OptionParserState.java:56)
at joptsimple.OptionParser.parse(OptionParser.java:396)
at kafka.admin.TopicCommand$TopicCommandOptions.<init>(TopicCommand.scala:688)
at kafka.admin.TopicCommand$.main(TopicCommand.scala:53)
at kafka.admin.TopicCommand.main(TopicCommand.scala)
解决:报错原因是命令参数有问题,可以看到上面的--partitions少了个s。
3、
问题:
WARN Stopping serving logs in dir F:\\Kafka\\data\\kafka-logs (kafka.log.LogManager)
[2021-04-22 10:46:35,895] ERROR Shutdown broker because all log dirs in F:\\Kafka\\data\\kafka-logs have failed (kafka.log.LogManager)
解决:把上方列出的目录"F:\\Kafka\\data\\kafka-logs"删除,然后再重启Kafka。
pom.xml
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
application.properties
# KafkaProperties
# 3000毫秒是3秒
spring.kafka.bootstrap-servers=localhost:9092
spring.kafka.consumer.group-id=community-consumer-group
spring.kafka.consumer.enable-auto-commit=true
spring.kafka.consumer.auto-commit-interval=3000
5.9、Spring整合Kafka
问题:idea用SpringBoot整合报错:
java.lang.IllegalStateException: Failed to load ApplicationContext
at org.springframework.test.context.cache.DefaultCacheAwareContextLoaderDelegate.loadContext(DefaultCacheAwareContextLoaderDelegate.java:125)
at org.springframework.test.context.support.DefaultTestContext.getApplicationContext(DefaultTestContext.java:108)
at org.springframework.test.context.web.ServletTestExecutionListener.setUpRequestContextIfNecessary(ServletTestExecutionListener.java:190)
at org.springframework.test.context.web.ServletTestExecutionListener.prepareTestInstance(ServletTestExecutionListener.java:132)
at org.springframework.test.context.TestContextManager.prepareTestInstance(TestContextManager.java:246)
at org.springframework.test.context.junit4.SpringJUnit4ClassRunner.createTest(SpringJUnit4ClassRunner.java:227)
at org.springframework.test.context.junit4.SpringJUnit4ClassRunner$1.runReflectiveCall(SpringJUnit4ClassRunner.java:289)
at org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
at org.springframework.test.context.junit4.SpringJUnit4ClassRunner.methodBlock(SpringJUnit4ClassRunner.java:291)
at org.springframework.test.context.junit4.SpringJUnit4ClassRunner.runChild(SpringJUnit4ClassRunner.java:246)
at org.springframework.test.context.junit4.SpringJUnit4ClassRunner.runChild(SpringJUnit4ClassRunner.java:97)
at org.junit.runners.ParentRunner$3.run(ParentRunner.java:290)
at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:71)
at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:288)
at org.junit.runners.ParentRunner.access$000(ParentRunner.java:58)
at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:268)
at org.springframework.test.context.junit4.statements.RunBeforeTestClassCallbacks.evaluate(RunBeforeTestClassCallbacks.java:61)
at org.springframework.test.context.junit4.statements.RunAfterTestClassCallbacks.evaluate(RunAfterTestClassCallbacks.java:70)
at org.junit.runners.ParentRunner.run(ParentRunner.java:363)
at org.springframework.test.context.junit4.SpringJUnit4ClassRunner.run(SpringJUnit4ClassRunner.java:190)
at org.junit.runner.JUnitCore.run(JUnitCore.java:137)
at com.intellij.junit4.JUnit4IdeaTestRunner.startRunnerWithArgs(JUnit4IdeaTestRunner.java:69)
at com.intellij.rt.junit.IdeaTestRunner$Repeater.startRunnerWithArgs(IdeaTestRunner.java:33)
at com.intellij.rt.junit.JUnitStarter.prepareStreamsAndStart(JUnitStarter.java:220)
at com.intellij.rt.junit.JUnitStarter.main(JUnitStarter.java:53)
Caused by: org.springframework.context.ApplicationContextException: Failed to start bean 'org.springframework.kafka.config.internalKafkaListenerEndpointRegistry'; nested exception is org.apache.kafka.common.errors.TimeoutException: Timeout expired while fetching topic metadata
at org.springframework.context.support.DefaultLifecycleProcessor.doStart(DefaultLifecycleProcessor.java:185)
at org.springframework.context.support.DefaultLifecycleProcessor.access$200(DefaultLifecycleProcessor.java:53)
at org.springframework.context.support.DefaultLifecycleProcessor$LifecycleGroup.start(DefaultLifecycleProcessor.java:360)
at org.springframework.context.support.DefaultLifecycleProcessor.startBeans(DefaultLifecycleProcessor.java:158)
at org.springframework.context.support.DefaultLifecycleProcessor.onRefresh(DefaultLifecycleProcessor.java:122)
at org.springframework.context.support.AbstractApplicationContext.finishRefresh(AbstractApplicationContext.java:893)
at org.springframework.context.support.AbstractApplicationContext.refresh(AbstractApplicationContext.java:552)
at org.springframework.boot.SpringApplication.refresh(SpringApplication.java:775)
at org.springframework.boot.SpringApplication.refreshContext(SpringApplication.java:397)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:316)
at org.springframework.boot.test.context.SpringBootContextLoader.loadContext(SpringBootContextLoader.java:127)
at org.springframework.test.context.cache.DefaultCacheAwareContextLoaderDelegate.loadContextInternal(DefaultCacheAwareContextLoaderDelegate.java:99)
at org.springframework.test.context.cache.DefaultCacheAwareContextLoaderDelegate.loadContext(DefaultCacheAwareContextLoaderDelegate.java:117)
... 24 more
Caused by: org.apache.kafka.common.errors.TimeoutException: Timeout expired while fetching topic metadata
原因:没启动windows上的kafka。
KafkaTests:测试Spring整合Kafka
@RunWith(SpringRunner.class)
@SpringBootTest
@ContextConfiguration(classes = CommunityApplication.class)
public class KafkaTests {
@Autowired
private KafkaProducer kafkaProducer;
@Test
public void testKafka() {
kafkaProducer.sendMessage("test", "你好");
kafkaProducer.sendMessage("test", "在吗");
try {
Thread.sleep(1000 * 10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
@Component
class KafkaProducer {
@Autowired
private KafkaTemplate kafkaTemplate;
public void sendMessage(String topic, String content) {
kafkaTemplate.send(topic, content);
}
}
@Component
class KafkaConsumer {
@KafkaListener(topics = {"test"})
public void handleMessage(ConsumerRecord record) {
System.out.println(record.value());
}
}
5.11、发送系统通知
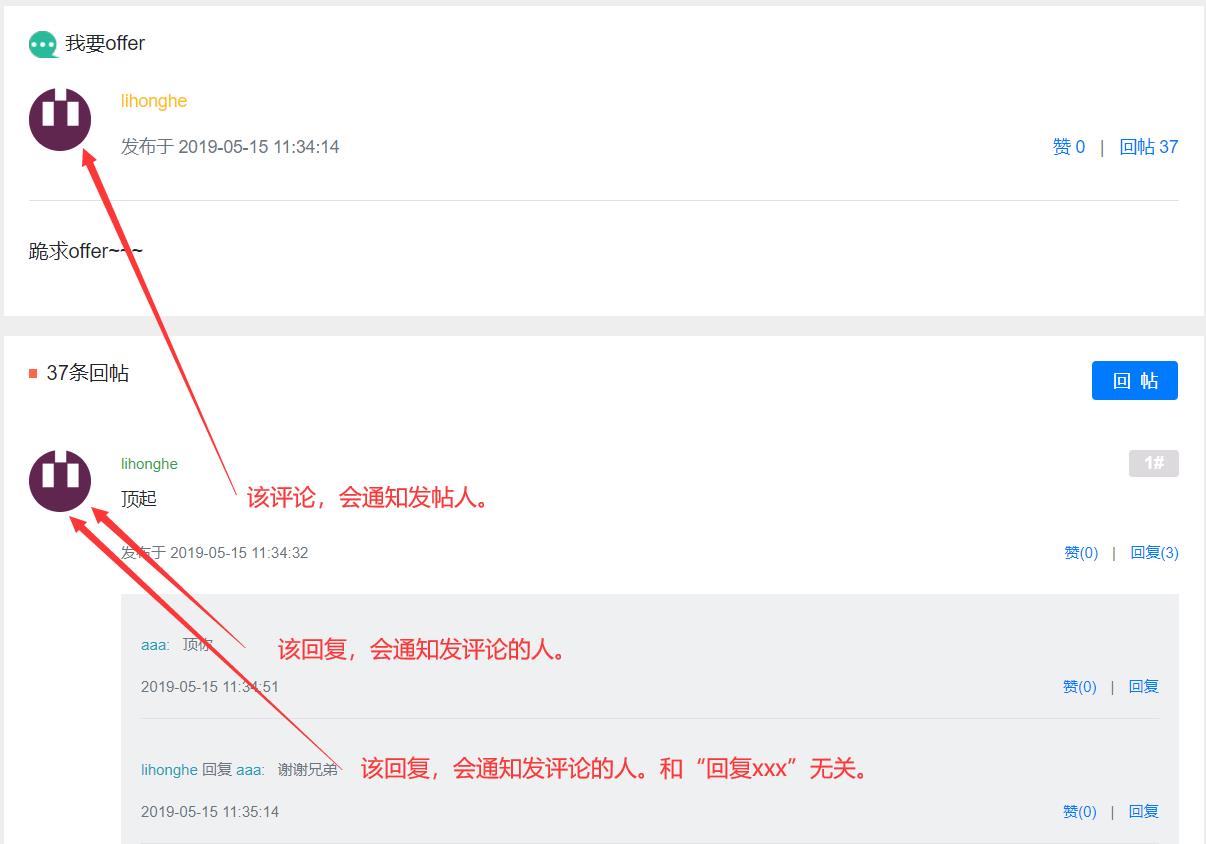
评论是指对帖子的评论,回复是指对评论的回复。
• 触发事件
- 评论后,发布通知 (评论、回复 后,都发通知)
- 点赞后,发布通知 (点赞评论、回复 后,都发通知。评论/回复获得的赞,都算作用户个人信息页面的赞的个数。)
- 关注后,发布通知
通知格式
用户 aaa 评论了你的帖子/回复, 点击查看 ! 链接:帖子详情页面
用户 aaa 点赞了你的帖子/回复, 点击查看 ! 链接:帖子详情页面
用户 lhh 关注了你, 点击查看 ! 链接:lhh的个人信息页面
生产者和消费者,可以同时进行操作,它们是并发的,这种叫做异步。
就是生产者把点赞评论关注的消息包装下扔到消息队列,就不用管了,消费者一条条消息来处理。
从技术角度来说,用Kafka消息队列来解决问题,不同的操作用不同的主题。
从业务角度,解决问题的方式是事件驱动方式。
评论是一个事件、点赞是一个事件、关注是一个事件。
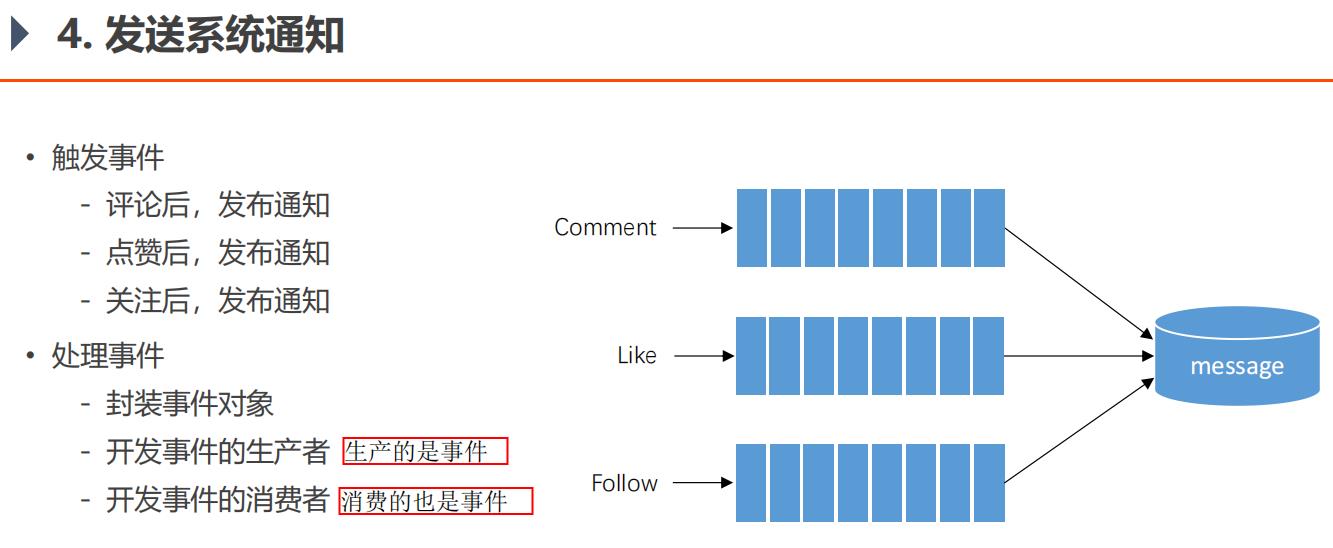
可以一个方法消费多个主题,也可以一个主题被多个方法消费,是多对多的关系。
消费者:
@Component
public class EventConsumer implements CommunityConstant {
private static final Logger logger = LoggerFactory.getLogger(EventConsumer.class);
@Autowired
private MessageService messageService;
@KafkaListener(topics = {TOPIC_COMMENT, TOPIC_LIKE, TOPIC_FOLLOW})
public void handleCommentMessage(ConsumerRecord record) {
if (record == null || record.value() == null) {
logger.error("消息的内容为空!");
return;
}
Event event = JSONObject.parseObject(record.value().toString(), Event.class);
if (event == null) {
logger.error("消息格式错误!");
return;
}
// 发送站内通知
Message message = new Message();
message.setFromId(SYSTEM_USER_ID);//1存为常量SYSTEM_USER_ID,方便看程序的人一眼就能看出这个1是什么意思
message.setToId(event.getEntityUserId());
message.setConversationId(event.getTopic());
message.setCreateTime(new Date());
//status不用设置,因为不设置就默认是0,就代表未读
Map<String, Object> content = new HashMap<>();//用这个拼出一条发送的通知
content.put("userId", event.getUserId());
content.put("entityType", event.getEntityType());
content.put("entityId", event.getEntityId());
//不方便存到message表其他字段的数据,通通存到message表的content字段
if (!event.getData().isEmpty()) {
for (Map.Entry<String, Object> entry : event.getData().entrySet()) {
content.put(entry.getKey(), entry.getValue());
}
}
message.setContent(JSONObject.toJSONString(content));//Map<String, Object> content
messageService.addMessage(message);
}
}
生产者:
@Component
public class EventProducer {
@Autowired
private KafkaTemplate kafkaTemplate;
// 处理事件
public void fireEvent(Event event) {
// 将事件发布到指定的主题
kafkaTemplate.send(event.getTopic(), JSONObject.toJSONString(event));//传一个对象的JSON字符串过去,消费者再把字符串转为对象再做处理
}
}
事件对象Event(用这样一个类,存点赞、评论、关注的信息,而不是直接存字符串:"用户xxx点赞了你的帖子,点击查看"这样,更加灵活,如果以后业务要传其他字符串,也可以修改。):
public class Event {
private String topic;
private int userId;
private int entityType;
private int entityId;
private int entityUserId;
private Map<String, Object> data = new HashMap<>();//如果日后这个对象还要加什么字段,方便扩展
public String getTopic() {
return topic;
}
public Event setTopic(String topic) {
this.topic = topic;
return this;//这种写法方便多次set。为什么不用构造器传参,因为可能某个参数不用传,这样要写很多构造器,而且可能参数非常多,传参混乱。这种方式很灵活。
}
。。。。。。
CommentController:
@RequestMapping(path = "/add/{discussPostId}", method = RequestMethod.POST)
public String addComment(@PathVariable("discussPostId") int discussPostId, Comment comment) {
comment.setUserId(hostHolder.getUser().getId());
comment.setStatus(0);
comment.setCreateTime(new Date());
commentService.addComment(comment);
// 触发评论事件
Event event = new Event()
.setTopic(TOPIC_COMMENT)
.setUserId(hostHolder.getUser().getId())
.setEntityType(comment.getEntityType())
.setEntityId(comment.getEntityId())
.setData("postId", discussPostId);
if (comment.getEntityType() == ENTITY_TYPE_POST) {
DiscussPost target = discussPostService.findDiscussPostById(comment.getEntityId());
event.setEntityUserId(target.getUserId());
} else if (comment.getEntityType() == ENTITY_TYPE_COMMENT) {
Comment target = commentService.findCommentById(comment.getEntityId());
event.setEntityUserId(target.getUserId());
}
//这里把消息发出去后,就立刻往下执行重定向页面了。消费者线程会慢慢从消息队列中取数据,来做处理。
eventProducer.fireEvent(event);
return "redirect:/discuss/detail/" + discussPostId;
}
关于Kafka使用的重要提示:
现象:在windows的命令行里启动kafka之后,当关闭命令行窗口时,就会强制关闭kafka。这种关闭方式为暴力关闭,很可能会导致kafka无法完成对日志文件的解锁。届时,再次启动kafka的时候,就会提示日志文件被锁,无法成功启动。
方案:将kafka的日志文件全部删除,再次启动即可。
建议:不要暴力关闭kafka,建议通过在命令行执行kafka-server-stop命令来关闭它。
其他:将来在Linux上部署kafka之后,采用后台运行的方式,就会避免这样的问题。
ServiceLogAspect类(用于AOP):
@Before("pointcut()")
public void before(JoinPoint joinPoint) {
// 用户[1.2.3.4],在[xxx],访问了[com.nowcoder.community.service.xxx()].
ServletRequestAttributes attributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
//如果不加下方的if判断,会报错:attributes空指针异常。
// 因为这里是AOP,拦截所有对service的调用。而前面我们所有对service的调用都是通过controller调用的,所以有attributes。
//但现在,我们有通过consumer消费者来访问service,于是attributes空指针异常。
if (attributes == null) {
return;
}
HttpServletRequest request = attributes.getRequest();
String ip = request.getRemoteHost();
String now = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date());
String target = joinPoint.getSignature().getDeclaringTypeName() + "." + joinPoint.getSignature().getName();
logger.info(String.format("用户[%s],在[%s],访问了[%s].", ip, now, target));
}
导入的项目,可以根据idea的左侧的project目录,查看改了哪些文件,改过的文件是蓝色的,因为有git。
5.13、显示系统通知
org.springframework.web.util.HtmlUtils 可以实现HTML标签及转义字符之间的转换。
测试:
String s = HtmlUtils.htmlEscape("<div>hello world</div><p> </p>");
System.out.println(s);
String s2 = HtmlUtils.htmlUnescape(s);
System.out.println(s2);
显示:
<div>hello world</div><p> </p>
<div>hello world