spark常用的调参详解
Posted 格格巫 MMQ!!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark常用的调参详解相关的知识,希望对你有一定的参考价值。
1.在submit中设置
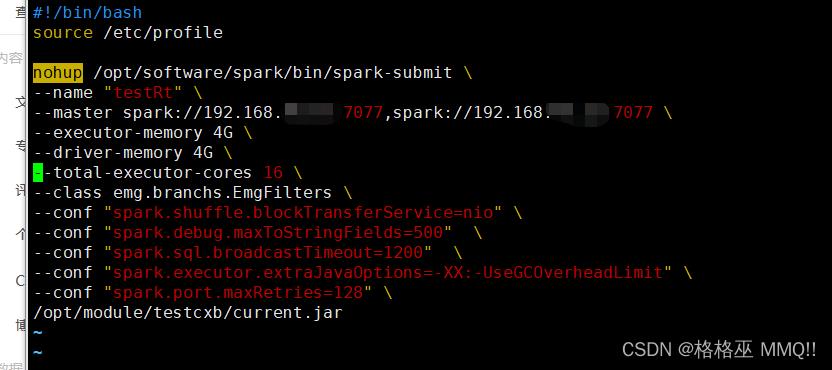
在submit中设置注意后面的 \\
–conf “spark.shuffle.blockTransferService=nio” \\ 大数据集shuffle的时候,节点之间传输数据时使用netty 改为nio
–conf “spark.debug.maxToStringFields=500” \\ 字段的字符串太长了
–conf “spark.sql.broadcastTimeout=1200” \\ 广播等待超时时间,单位秒
–conf “spark.executor.extraJavaOptions=-XX:-UseGCOverheadLimit” \\ 关闭限制GC的运行时间(默认启用 )
–conf “spark.port.maxRetries=128” \\ Spark任务都会绑定一个端口来显示WebUI,默认端口为4040,如果被占用则依次递增+1端口重试,重试次数由参数spark.port.maxRetries=16控制,默认重试16次后就放弃执行
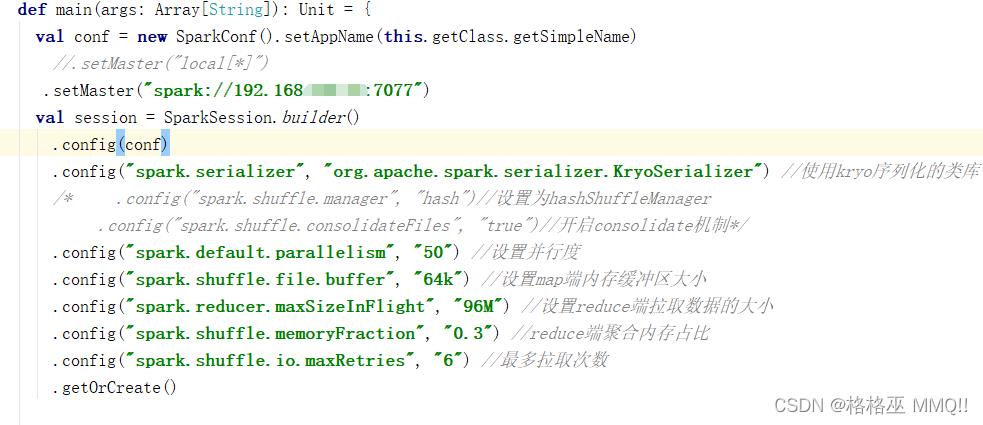
" class=“reference-link”>2.在代码中设置watermark_type_ZmFuZ3poZW5naGVpdGk_shadow_10_text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MTgwNDA0OQ_size_16_color_FFFFFF_t_70 1
.config(“spark.serializer”, “org.apache.spark.serializer.KryoSerializer”) //使用kryo序列化的类库
/* .config(“spark.shuffle.manager”, “hash”)//设置为hashShuffleManager
.config(“spark.shuffle.consolidateFiles”, “true”)//开启consolidate机制 这两个不能使用不知道怎么回事 */
.config(“spark.default.parallelism”, “50”) //设置并行度 根据所使用的core来算 是core的3–5倍
.config(“spark.shuffle.file.buffer”, “64k”) //设置map端内存缓冲区大小
.config(“spark.reducer.maxSizeInFlight”, “96M”) //设置reduce端拉取数据的大小
.config(“spark.shuffle.memoryFraction”, “0.3”) //reduce端聚合内存占比
.config(“spark.shuffle.io.maxRetries”, “6”) //最多拉取次数
以上是关于spark常用的调参详解的主要内容,如果未能解决你的问题,请参考以下文章