项目实训---视频中单个目标对象逐帧检查
Posted 阿May ♬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了项目实训---视频中单个目标对象逐帧检查相关的知识,希望对你有一定的参考价值。
2021SC@SDUSC
这部分我主要实现了对视频中指定人物出现次数逐帧(每6帧)进行检查。
利用前面生成的人脸库,对视频中的人物进行逐帧的检查,如果人物出现则计数加一。最终返回计数值更大的gif给用户。
目录
一.引言
人脸识别这里我使用的是dlib人脸识别的库,dlib进行人脸识别有很经典的思路:
1.计算已知图⽚中所有⼈脸对应的特征向量;
2.计算要识别的未知图⽚中所有⼈脸对应的特征向量;
3.计算⼈脸之间的欧式距离;
4.如果两张⼈脸之间的欧式距离⼩于设定的阈值,则认为是同⼀个⼈,否则认为不是同⼀个⼈
这些方法都已经是封装好的方法,所以我们使用起来直接调用很方便。
二.相关代码
视频中人脸检测关键代码:
使用的库:
import dlib,os,glob,time
import cv2
import numpy as np
import pandas as pd加载模型:
#人脸特征提取器
detector = dlib.get_frontal_face_detector()
#人脸关键点标记
predictor= dlib.shape_predictor(predictor_path)
#生成面部识别器
facerec = dlib.face_recognition_model_v1(model_path)
#定义视频创建器,用于输出视频
video_writer = cv2.VideoWriter(resources_vResult+"result1.avi",
cv2.VideoWriter_fourcc(*'XVID'), int(fps),
(int(video.get(cv2.CAP_PROP_FRAME_WIDTH)), int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))))识别过程核心代码:
#目标人物出现次数
count=0
#读取本地人脸库
head = []
for i in range(128):
fe = "feature_" + str(i + 1)
head.append(fe)
face_path=faceDB_path+"feature_all.csv"
face_feature=pd.read_csv(face_path,names=head)
#人脸库中人物的特征
face_feature_array=np.array(face_feature)
#待识别人物 这个序号和feature_all.csv的特征序号应该保持一致
num=len(face_feature_array)
face_list= []
for i in range(num):
face_list=face_list+[i]
#计算欧式距离
def compute_dst(feature_1,feature_2):
feature_1 = np.array(feature_1)
feature_2 = np.array(feature_2)
dist = np.linalg.norm(feature_1 - feature_2)
return dist
# 处理视频,按帧处理
ret,frame = video.read()
flag = True # 标记是否是第一次迭代
i = 0 # 记录当前迭代到的帧位置
while ret:
if i % 6== 0: # 每6帧截取一帧
# 转为灰度图像处理
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
dets = detector(gray, 1) # 检测帧图像中的人脸
# 处理这一帧检测到的每一张人脸
#检测到了人脸
if len(dets)>0:
for index,value in enumerate(dets):
#获取面部关键点
shape = predictor(gray,value)
#标记人脸
cv2.rectangle(frame, (value.left(), value.top()), (value.right(), value.bottom()), (0, 255, 0), 2)
#进行人脸识别并打上姓名标签
# 提取特征-图像中的68个关键点转换为128D面部描述符,其中同一人的图片被映射到彼此附近,并且不同人的图片被远离地映射。
face_descriptor = facerec.compute_face_descriptor(frame, shape)
#视频中这个人的特征向量
v = np.array(face_descriptor)
#l = len(descriptors)
Flen=len(face_list)
flag=0
for j in range(Flen):
# 人脸匹配,距离小于阈值,表示识别成功,打上标签
if(compute_dst(v,face_feature_array[j])<0.56):
flag=1
cv2.putText(frame,'Attention',(value.left(), value.top()),cv2.FONT_HERSHEY_COMPLEX,0.8, (0, 255, 255), 1, cv2.LINE_AA)
cv2.putText(frame, 'Attention', (value.left(), value.top()), cv2.FONT_HERSHEY_COMPLEX, 0.8, (0, 255, 255), 1, cv2.LINE_AA)
count=count+1
break
if(flag==0):
cv2.putText(frame,"Unknonw", (value.left(), value.top()), cv2.FONT_HERSHEY_COMPLEX, 0.8, (0, 255, 255), 1,
cv2.LINE_AA)
#标记关键点
for pti,pt in enumerate(shape.parts()):
pos=(pt.x,pt.y)
cv2.circle(frame, pos, 1, color=(0, 255, 0))
video_writer.write(frame)
ret,frame = video.read()
i += 1
三.人物出现次数实时统计
输入的目标照片:
只需要一张即可
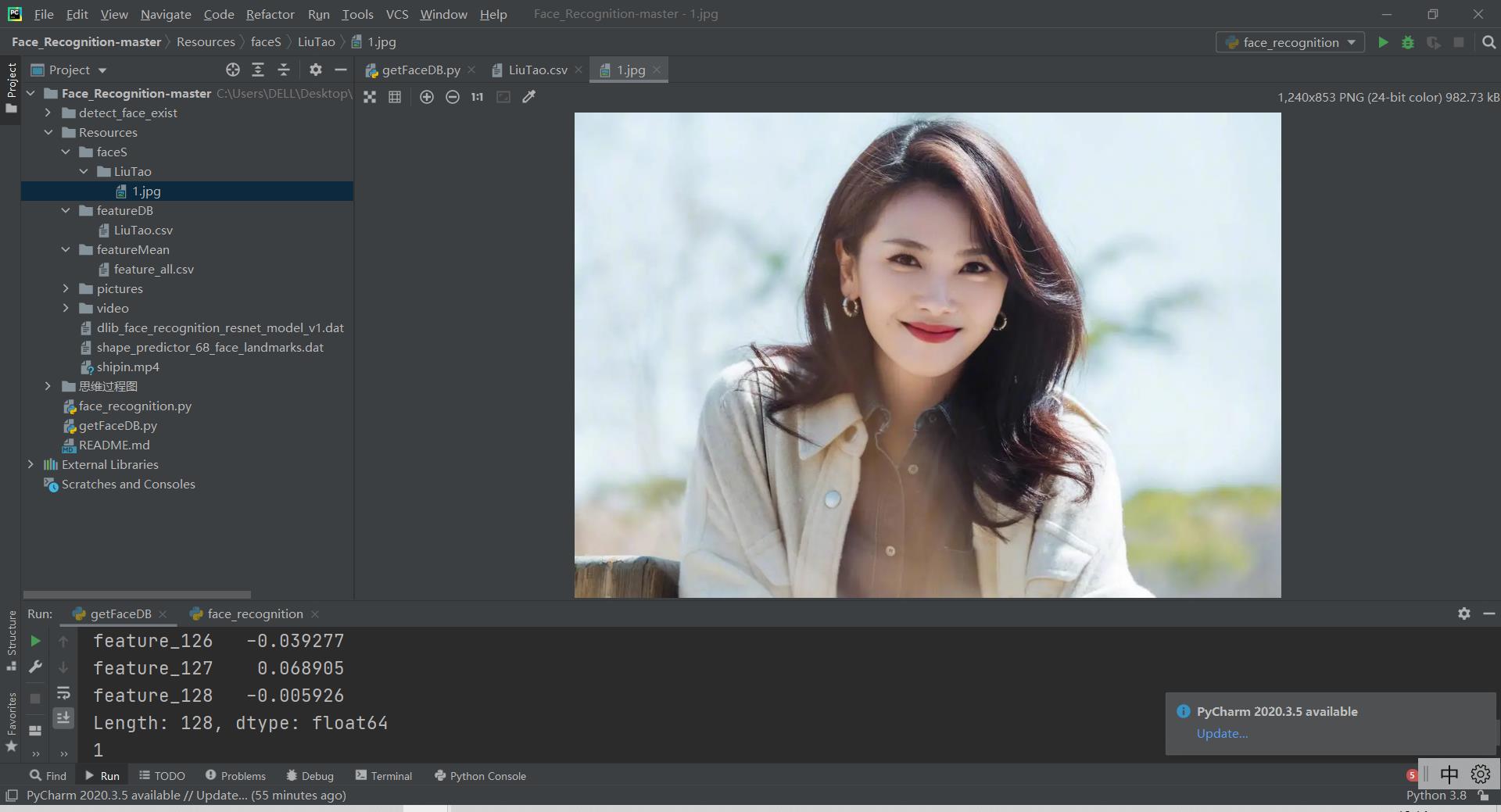
目标对象的特征向量:

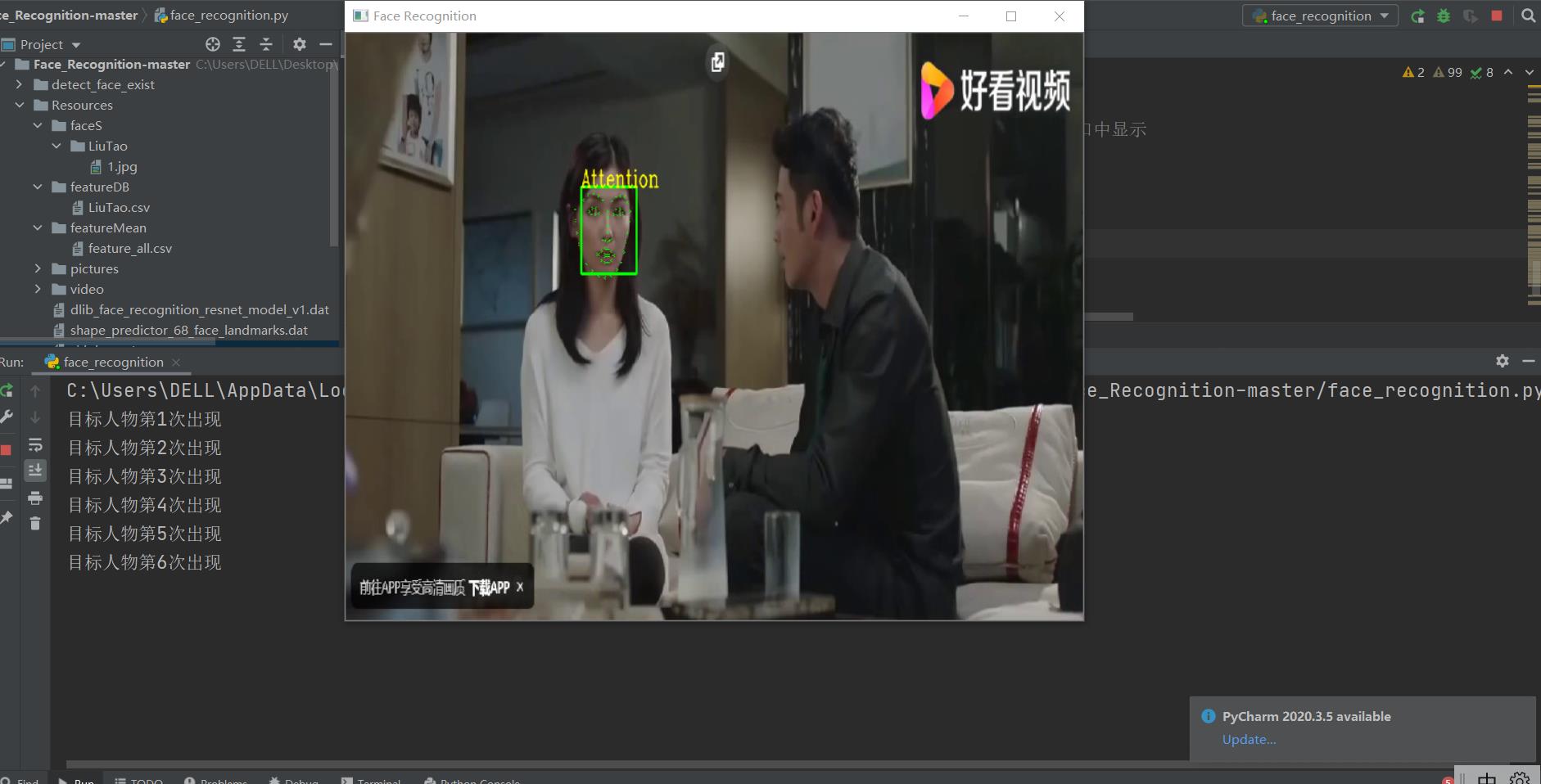
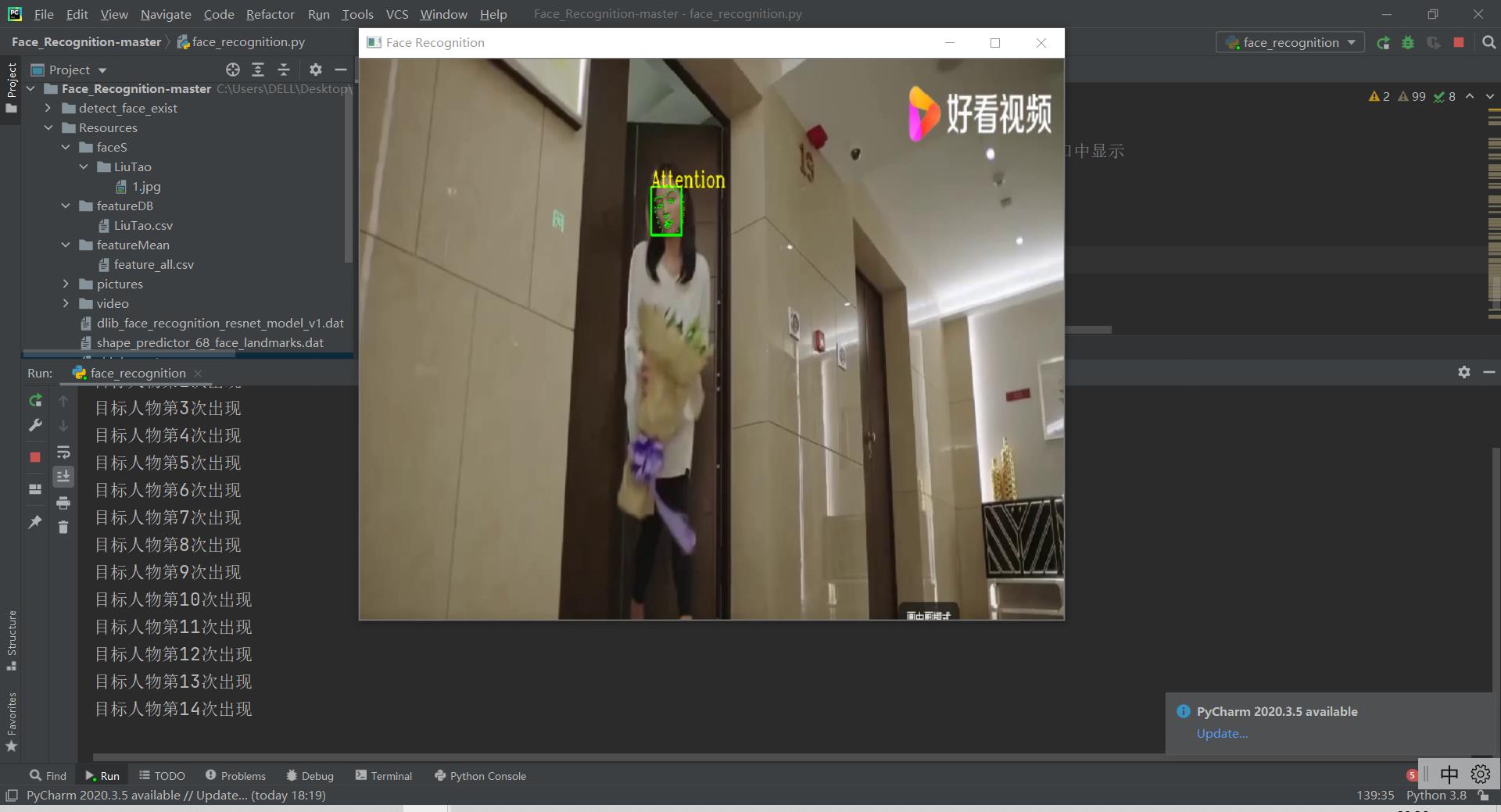
对目标人物标注Attention,并且计数:
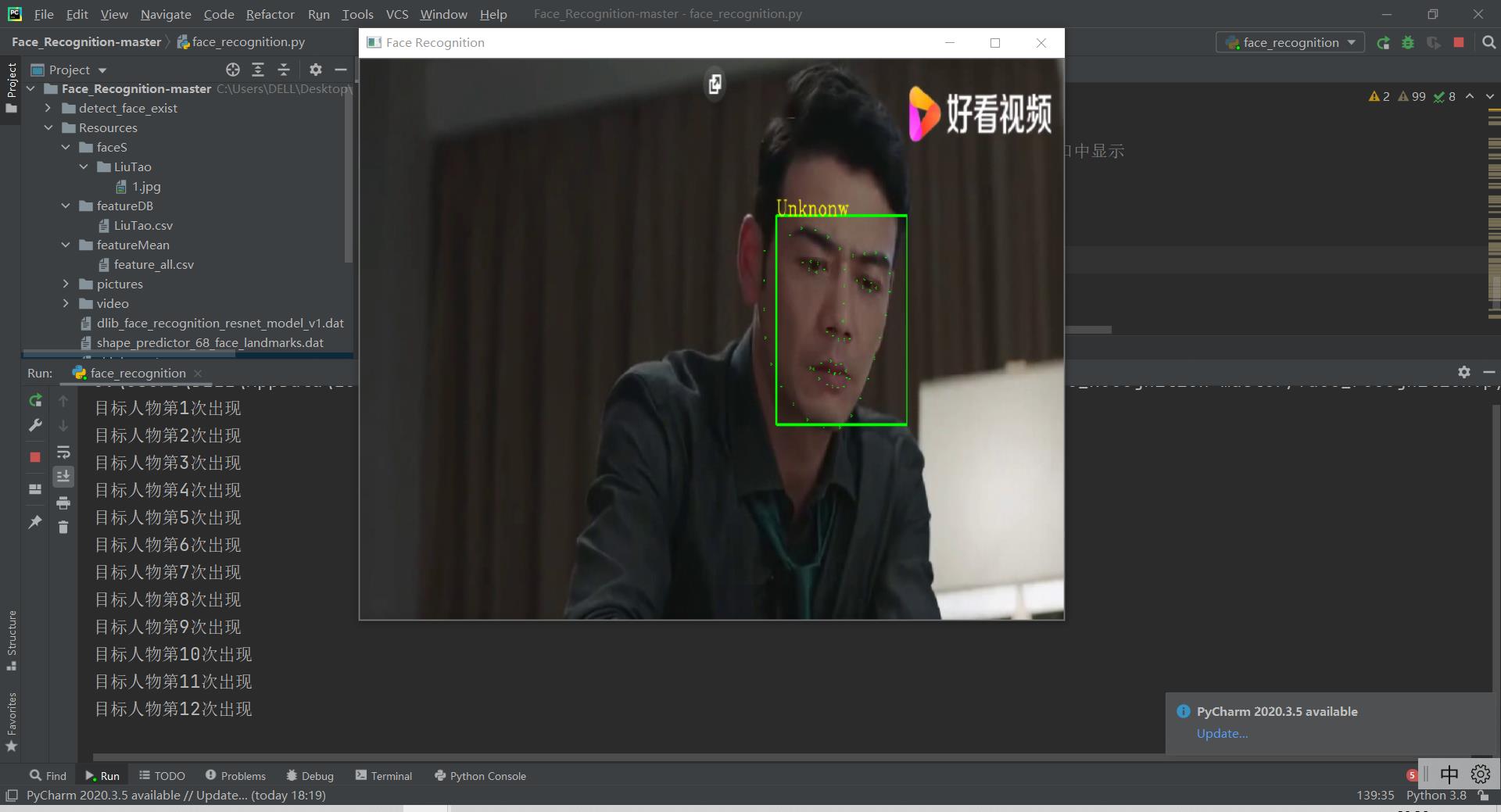
对非目标人物标注unknow,不理会:
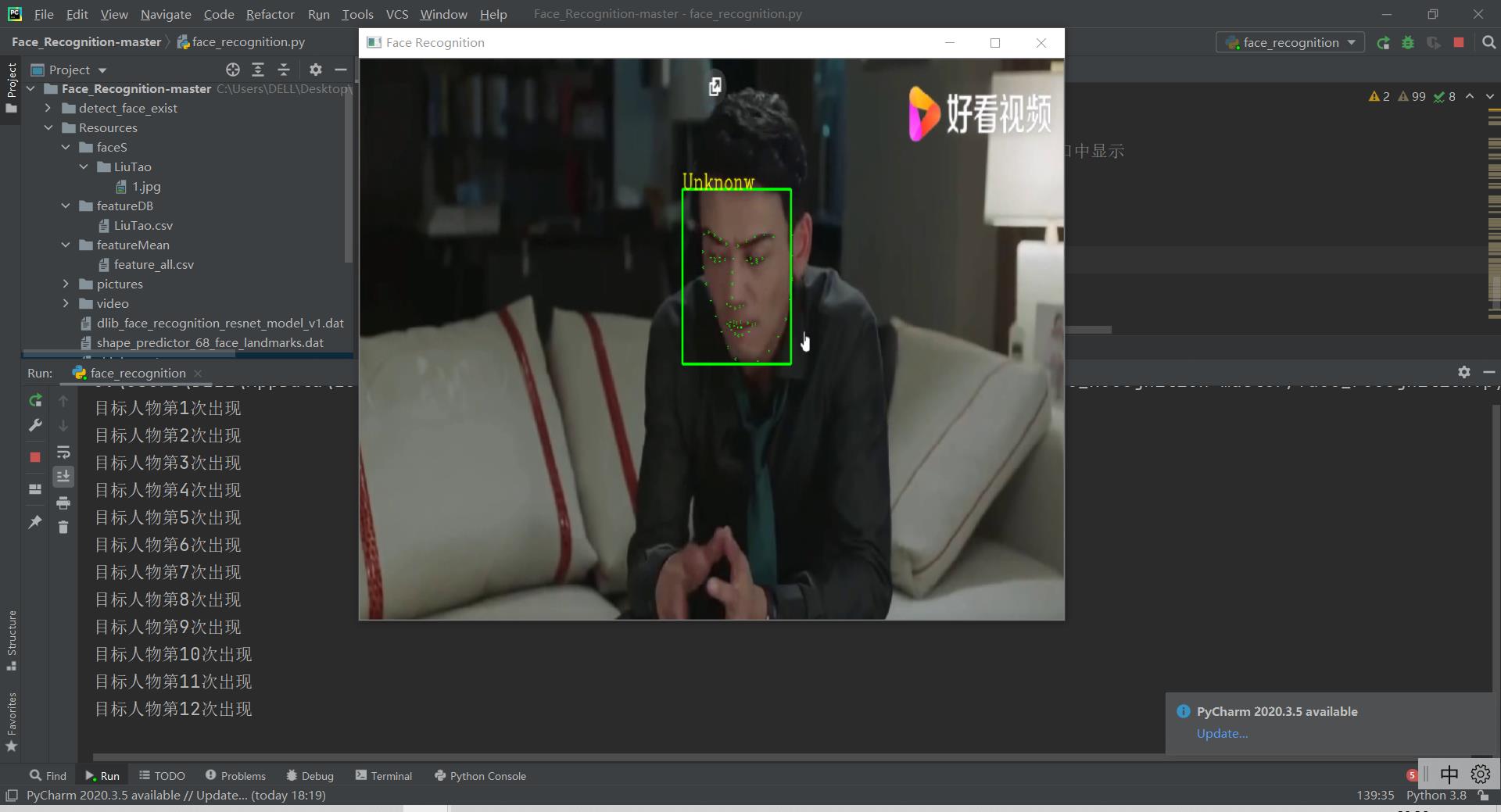
可以观察到目标人物计数没有变:
再次检测到目标人物:
最终输出统计结果:
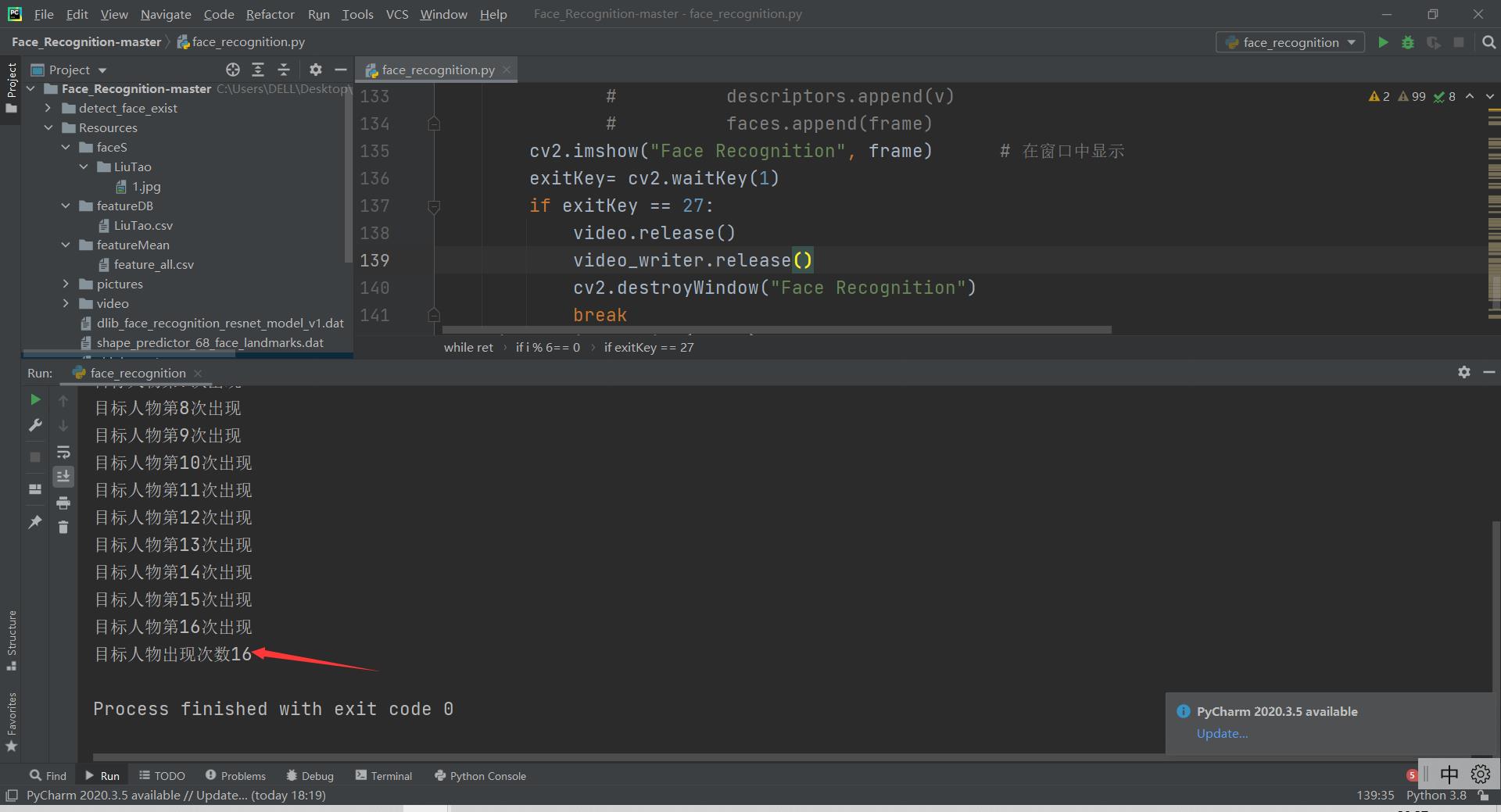
最后只需要对所有Gif执行操作,返回统计次数比较高的几个即可。
注:
这里视频形式演示只是在开发过程中方便检查,项目真正用到的数据就是出现次数这个量,作为比较的量。
如何使用 OpenCV 和 Python 在视频流中逐帧处理视频图像
【中文标题】如何使用 OpenCV 和 Python 在视频流中逐帧处理视频图像【英文标题】:How to process images of a video, frame by frame, in video streaming using OpenCV and Python 【发布时间】:2013-09-28 02:12:22 【问题描述】:我是 OpenCV 的初学者。我想对上传到我的服务器的视频帧进行一些图像处理。我只想读取可用的帧并将它们写入目录。然后,等待视频的另一部分上传,并将帧写入目录。而且,我应该等待每一帧都完全上传,然后将其写入文件。
您能告诉我如何使用 OpenCV (Python) 做到这一点吗?
编辑 1:
我编写了这段代码来从文件中捕获视频,而新数据被附加到文件的末尾。换句话说,out.mp4 文件不是完整的视频,另一个程序正在其上写入新帧。我要做的是,等待其他程序写入新帧,然后读取它们并显示它们。
这是我的代码:
import cv2
cap = cv2.VideoCapture("./out.mp4")
while True:
if cap.grab():
flag, frame = cap.retrieve()
if not flag:
continue
else:
cv2.imshow('video', frame)
if cv2.waitKey(10) == 27:
break
所以问题出在cap.grab() 电话上!无框时返回False!即使我等待很长时间,它也不会再捕获帧。
【问题讨论】:
请添加更详细的描述。在上传期间或之后“对帧进行一些图像处理”? “可用框架”它们应该在哪里以及如何可用? '等待视频的其他部分'所以只是追加?... @RobertCaspary 感谢您的评论。 “对帧进行一些图像处理”:假设我想将帧写入目录中的文件。 'available frames':假设视频有 100 帧,但只有 40 帧被上传,所以可用帧是前 40 帧。到目前为止,我已将它们保存到特定目录中的文件中。 '等待视频的其他部分':等待第 41 帧上传,然后将其保存到另一个文件,然后是第 42 帧,依此类推。清楚了吗? 【参考方案1】:阅读VideoCapture的文档后。我发现你可以告诉VideoCapture,下次我们调用VideoCapture.read()(或VideoCapture.grab())时要处理哪个帧。
问题是当你想read()一个没有准备好的框架时,VideoCapture对象卡在那个框架上并且永远不会继续。所以你必须强制它从上一帧重新开始。
这里是代码
import cv2
cap = cv2.VideoCapture("./out.mp4")
while not cap.isOpened():
cap = cv2.VideoCapture("./out.mp4")
cv2.waitKey(1000)
print "Wait for the header"
pos_frame = cap.get(cv2.cv.CV_CAP_PROP_POS_FRAMES)
while True:
flag, frame = cap.read()
if flag:
# The frame is ready and already captured
cv2.imshow('video', frame)
pos_frame = cap.get(cv2.cv.CV_CAP_PROP_POS_FRAMES)
print str(pos_frame)+" frames"
else:
# The next frame is not ready, so we try to read it again
cap.set(cv2.cv.CV_CAP_PROP_POS_FRAMES, pos_frame-1)
print "frame is not ready"
# It is better to wait for a while for the next frame to be ready
cv2.waitKey(1000)
if cv2.waitKey(10) == 27:
break
if cap.get(cv2.cv.CV_CAP_PROP_POS_FRAMES) == cap.get(cv2.cv.CV_CAP_PROP_FRAME_COUNT):
# If the number of captured frames is equal to the total number of frames,
# we stop
break
【讨论】:
这行得通,但在某个随机点,尽管输入流继续,但帧停止出现。还是有东西挂在这里 对于 OpenCV 3.0 以上版本,将cap.get(cv2.cv.CV_CAP_PROP_POS_FRAMES) 更改为 cap.get(cv2.CAP_PROP_POS_FRAMES)。【参考方案2】:
使用这个:
import cv2
cap = cv2.VideoCapture('path to video file')
count = 0
while cap.isOpened():
ret,frame = cap.read()
cv2.imshow('window-name', frame)
cv2.imwrite("frame%d.jpg" % count, frame)
count = count + 1
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows() # destroy all opened windows
【讨论】:
我相信你的最后一行应该是:cv2.destroyAllWindows()
如果不返回则必须添加:继续【参考方案3】:
根据 OpenCV 3.0 及更高版本的最新更新,您需要在 Mehran 的代码中更改 Property Identifiers 如下:
cv2.cv.CV_CAP_PROP_POS_FRAMES
到
cv2.CAP_PROP_POS_FRAMES
同样适用于cv2.CAP_PROP_POS_FRAME_COUNT。
希望对你有帮助。
【讨论】:
这没有回答问题。 如果包含指向更多信息的链接将不胜感激。【参考方案4】:在 openCV 的文档中有一个 example 用于逐帧获取视频。它是用 c++ 编写的,但是很容易将示例移植到 python - 您可以搜索每个函数文档以查看如何在 python 中调用它们。
#include "opencv2/opencv.hpp"
using namespace cv;
int main(int, char**)
VideoCapture cap(0); // open the default camera
if(!cap.isOpened()) // check if we succeeded
return -1;
Mat edges;
namedWindow("edges",1);
for(;;)
Mat frame;
cap >> frame; // get a new frame from camera
cvtColor(frame, edges, CV_BGR2GRAY);
GaussianBlur(edges, edges, Size(7,7), 1.5, 1.5);
Canny(edges, edges, 0, 30, 3);
imshow("edges", edges);
if(waitKey(30) >= 0) break;
// the camera will be deinitialized automatically in VideoCapture destructor
return 0;
【讨论】:
非常感谢您的回答。我在python中做到了这一点。但问题是,当你调用 cap>>frame;它不会等待框架完全准备好!所以如果框架没有准备好,那么它将返回null。之后,它不会捕获任何其他帧。有意义吗? @Mehran 能这么温柔的分享一下python版本吗?【参考方案5】:这就是我开始解决这个问题的方法:
创建视频作者:
import cv2.cv as cv
videowriter = cv.CreateVideoWriter( filename, fourcc, fps, frameSize)
Check here for valid parameters
循环检索[1]并写入帧:
cv.WriteFrame( videowriter, frame )
WriteFrame doc
[1] zenpoy 已经指向正确的方向。您只需要知道您可以从网络摄像头或文件中检索图像 :-)
希望我理解正确的要求。
【讨论】:
【参考方案6】:我找到的唯一解决方案不是将索引设置为前一帧并等待(然后 OpenCV 会停止读取帧,无论如何),而是再初始化一次捕获。所以,它看起来像这样:
cap = cv2.VideoCapture(camera_url)
while True:
ret, frame = cap.read()
if not ret:
cap = cv.VideoCapture(camera_url)
continue
# do your processing here
而且效果很好!
【讨论】:
不错的解决方案。但是,重新初始化 Capture 的开销是多少?我们需要确保销毁和创建对象不会降低性能。 它不会降低性能 - 它会丢几帧。没有拖车或类似的东西,所以这对我们有用。 当流(在本例中为相机)始终从当前帧开始时,此解决方案有效。就我而言,该文件正在上传到服务器并保存到 out.mp4。因此,如果我重新初始化视频捕获,它将从视频的第一帧而不是最后一个可用帧开始。【参考方案7】:这是 a.mp4 是视频文件的示例
import cv2
cap = cv2.VideoCapture('a.mp4')
count = 0
while cap.isOpened():
ret,frame = cap.read()
if not ret:
continue
cv2.imshow('window-name', frame)
#cv2.imwrite("frame%d.jpg" % count, frame)
count = count + 1
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
【讨论】:
你的伯爵在这里做什么? 计算帧数。 哦,好吧,你没有使用它们(打印或归还它们)所以我想也许你正在用计数做其他事情。以上是关于项目实训---视频中单个目标对象逐帧检查的主要内容,如果未能解决你的问题,请参考以下文章