大数据面试之hive重点
Posted 大数据小理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据面试之hive重点相关的知识,希望对你有一定的参考价值。
大数据面试之hive重点(三)
介绍下知道的Hive窗口函数,举一些例子
问过的一些公司:小米,池鹜,快手,网易参考答案:
Hive中的窗口函数和sql中的窗口函数相类似,都是用来做一些数据分析类的工作,一般用于OLAP分析
(在线分析处理)。
在sql中有一类函数叫做聚合函数,例如sum()、avg()、max()等等,这类函数可以将多行数据按照规则聚 集为一行,一般来讲聚集后的行数是要少于聚集前的行数的。但是有时我们想要既显示聚集前的数据, 又要显示聚集后的数据,这时我们便引入了窗口函数。
注意:在SQL处理中,窗口函数都是最后一步执行,而且仅位于Order by字句之前。
准备一张order表,字段分别为name,orderdate,cost。数据内容如下:
1 jack,2015-01-01,10
2 tony,2015-01-02,15
3 jack,2015-02-03,23
4 tony,2015-01-04,29
5 jack,2015-01-05,46
6 jack,2015-04-06,42
7 tony,2015-01-07,50
8 jack,2015-01-08,55
9 mart,2015-04-08,62
10 mart,2015-04-09,68
11 neil,2015-05-10,12
12 mart,2015-04-11,75
13 neil,2015-06-12,80
14 mart,2015-04-13,94
15
在hive中建立一张表t_window,将数据插入进去。
聚合函数+over
假如说我们想要查询在2015年4月份购买过的顾客及总人数,我们便可以使用窗口函数去去实现
-
select name,count(*) over ()
-
from t_window
-
where substring(orderdate,1,7) = ‘2015-04’ 4
结果如下:
1 name count_window_0
2 mart 5
3 mart 5
4 mart 5
5 mart 5
6 jack 5
在2015年4月一共有5次购买记录,mart购买了4次,jack购买了1次。事实上,大多数情况下,我们是只 看去重后的结果的。针对于这种情况,我们有两种实现方式:
第一种:distinct -
select distinct name,count(*) over ()
-
from t_window
-
where substring(orderdate,1,7) = ‘2015-04’ 4
结果如下:
name mart
jack
count_window_0 2
2
第二种:group by -
select name,count(*) over ()
-
from t_window
-
where substring(orderdate,1,7) = ‘2015-04’
-
group by name 5
结果如下:
name mart
jack
count_window_0 2
2
partition by子句
Partition By子句也可以称为查询分区子句,非常类似于Group By,都是将数据按照边界值分组,而Over
之前的函数在每一个分组之内进行,如果超出了分组,则函数会重新计算。
我们想要去看顾客的购买明细及月购买总额: -
select name,orderdate,cost,sum(cost) over(partition by month(orderdate))
-
from t_window 3
结果如下:
1 name orderdate cost sum_window_0
2 jack 2015-01-01 10 205
3 jack 2015-01-08 55 205
4 tony 2015-01-07 50 205
5 jack 2015-01-05 46 205
6 tony 2015-01-04 29 205
7 tony 2015-01-02 15 205
8 jack 2015-02-03 23 23
9 mart 2015-04-13 94 341
10 jack 2015-04-06 42 341
11 mart 2015-04-11 75 341
12 mart 2015-04-09 68 341
13 mart 2015-04-08 62 341
14 neil 2015-05-10 12 12
15 neil 2015-06-12 80 80
16
数据已经按照月进行汇总了
order by子句
假如我们想要将cost按照月进行累加.这时我们引入order by子句
order by子句会让输入的数据强制排序(文章前面提到过,窗口函数是SQL语句最后执行的函数,因此可以把SQL结果集想象成输入数据)。Order By子句对于诸如Row_Number(),Lead(),LAG()等函数是必须的,因为如果数据无序,这些函数的结果就没有任何意义。因此如果有了Order By子句,则Count(), Min()等计算出来的结果就没有任何意义。
在上面的sql中加入order by -
select name,orderdate,cost,sum(cost) over(partition by month(orderdate) order by orderdate )
-
from t_window 3
结果如下:(order by默认情况下聚合从起始行到当前行的数据)
1 name orderdate cost sum_window_0
2 jack 2015-01-01 10 10
3 tony 2015-01-02 15 25 //10+15
4 tony 2015-01-04 29 54 //10+15+29
5 jack 2015-01-05 46 100 //10+15+29+46
6 tony 2015-01-07 50 150
7 jack 2015-01-08 55 205
8 jack 2015-02-03 23 23
9 jack 2015-04-06 42 42
10 mart 2015-04-08 62 104
11 mart 2015-04-09 68 172
12 mart 2015-04-11 75 247
13 mart 2015-04-13 94 341
14 neil 2015-05-10 12 12
15 neil 2015-06-12 80 80
16 169
window子句
首先要理解两个概念:
如果只使用partition by子句,未指定order by的话,我们的聚合是分组内的聚合。使用了order by子句,未使用window子句的情况下,默认从起点到当前行。
当同一个select查询中存在多个窗口函数时,他们相互之间是没有影响的,每个窗口函数应用自己的规 则。
window子句:
PRECEDING:往前FOLLOWING:往后CURRENT ROW:当前行UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点,UNBOUNDED FOLLOWING:表
示到后面的终点
按照name进行分区,按照购物时间进行排序,做cost的累加。 -
select name,orderdate,cost,
-
sum(cost) over() as sample1,–所有行相加
-
sum(cost) over(partition by name) as sample2,–按name分组,组内数据相加
-
sum(cost) over(partition by name order by orderdate) as sample3,–按name分组,组内数据累加
-
sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,–和sample3一样,由起点到当前行的聚合
-
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --当前行和前面一行做聚合
-
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,–当前行和前边一行及后面一行
-
sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行
-
from t_window; 10
结果如下:
2 jack 2015-01-01 10 661 176 10 10 10 56 176
3 jack 2015-01-05 46 661 176 56 56 56 111 166
4 jack 2015-01-08 55 661 176 111 111 101 124 120
5 jack 2015-02-03 23 661 176 134 134 78 120 65
6 jack 2015-04-06 42 661 176 176 176 65 65 42
7 mart 2015-04-08 62 661 299 62 62 62 130
299
8 mart 2015-04-09 68 661 299 130 130 130 205
237
9 mart 2015-04-11 75 661 299 205 205 143 237
169
10 mart 2015-04-13 94 661 299 299 299 169 169 94
11 neil 2015-05-10 12 661 92 12 12 12 92 92
12 neil 2015-06-12 80 661 92 92 92 92 92 80
13 tony 2015-01-02 15 661 94 15 15 15 44 94
14 tony 2015-01-04 29 661 94 44 44 44 94 79
15 tony 2015-01-07 50 661 94 94 94 79 79 50
name
sample7
orderdate cost sample1 sample2 sample3 sample4 sample5 sample6
窗口函数中的序列函数
Hive中常用的序列函数有下面几个:
- Row_Number,Rank,Dense_Rank这三个窗口函数的使用场景非常多
row_number():从1开始,按照顺序,生成分组内记录的序列,row_number()的值不会存在重复,当排序的 值相同时,按照表中记录的顺序进行排列;通常用于获取分组内排序第一的记录;获取一个session中的第一 条refer等。
rank():生成数据项在分组中的排名,排名相等会在名次中留下空位。dense_rank():生成数据项在分组中的排名,排名相等会在名次中不会留下空位。 注意: rank和dense_rank的区别在于排名相等时会不会留下空位
举例如下:
SELECT
cookieid, createtime, pv,
RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn1, DENSE_RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn2, ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3 FROM lxw1234
WHERE cookieid = ‘cookie1’;
cookieid day
pv
rn1
rn2
rn3
cookie1 2015-04-12
cookie1 2015-04-11
cookie1 2015-04-15
cookie1 2015-04-16
cookie1 2015-04-13
cookie1 2015-04-14
cookie1 2015-04-10
- rn1: 15号和16号并列第3, 13号排第5
- rn2: 15号和16号并列第3, 13号排第4
- rn3: 如果相等,则按记录值排序,生成唯一的次序,如果所有记录值都相等,或许会随机排吧。
60 LAG和LEAD函数
这两个函数为常用的窗口函数,可以返回上下数据行的数据。
以这里的订单表为例,假如我们想要查看顾客上次的购买时间可以这样去查询。
- select name,orderdate,cost,
- lag(orderdate,1,‘1900-01-01’) over(partition by name order by orderdate ) as time1,
- lag(orderdate,2) over (partition by name order by orderdate) as time2
- from t_window; 5
查询后的数据为:
1 name orderdate cost time1 time2
2 jack 2015-01-01 10 1900-01-01 NULL
3 jack 2015-01-05 46 2015-01-01 NULL
4 jack 2015-01-08 55 2015-01-05 2015-01-01
5 jack 2015-02-03 23 2015-01-08 2015-01-05
6 jack 2015-04-06 42 2015-02-03 2015-01-08
7 mart 2015-04-08 62 1900-01-01 NULL
8 mart 2015-04-09 68 2015-04-08 NULL
9 mart 2015-04-11 75 2015-04-09 2015-04-08
10 mart 2015-04-13 94 2015-04-11 2015-04-09
11 neil 2015-05-10 12 1900-01-01 NULL
12 neil 2015-06-12 80 2015-05-10 NULL
13 tony 2015-01-02 15 1900-01-01 NULL
14 tony 2015-01-04 29 2015-01-02 NULL
15 tony 2015-01-07 50 2015-01-04 2015-01-02
16
time1取的为按照name进行分组,分组内升序排列,取上一行数据的值,见下图。
time2取的为按照name进行分组,分组内升序排列,取上面2行的数据的值,注意当lag函数未设置行数 值时,默认为1行。设定取不到时的默认值时,取null值。
lead函数与lag函数方向相反,取向下的数据。

time1取的为按照name进行分组,分组内升序排列,取上一行数据的值。
time2取的为按照name进行分组,分组内升序排列,取上面2行的数据的值,注意当lag函数为设置行数 值时,默认为1行。未设定取不到时的默认值时,去null值。
61 first_value和last_value
first_value取分组内排序后,截止到当前行,第一个值last_value取分组内排序后,截止到当前行,最后一个值 - select name,orderdate,cost,
- first_value(orderdate) over(partition by name order by orderdate) as time1,
- last_value(orderdate) over(partition by name order by orderdate) as time2
- from t_window 5
查询结果如下:
1 name orderdate cost time1 time2
2 jack 2015-01-01 10 2015-01-01 2015-01-01
3 jack 2015-01-05 46 2015-01-01 2015-01-05
4 jack 2015-01-08 55 2015-01-01 2015-01-08
5 jack 2015-02-03 23 2015-01-01 2015-02-03
6 jack 2015-04-06 42 2015-01-01 2015-04-06
7 mart 2015-04-08 62 2015-04-08 2015-04-08
8 mart 2015-04-09 68 2015-04-08 2015-04-09
9 mart 2015-04-11 75 2015-04-08 2015-04-11
10 mart 2015-04-13 94 2015-04-08 2015-04-13
11 neil 2015-05-10 12 2015-05-10 2015-05-10
12 neil 2015-06-12 80 2015-05-10 2015-06-12
13 tony 2015-01-02 15 2015-01-02 2015-01-02
14 tony 2015-01-04 29 2015-01-02 2015-01-04
15 tony 2015-01-07 50 2015-01-02 2015-01-07
16
扩展部分:
row_number的用途非常广泛,排序最好用它,它会为查询出来的每一行记录生成一个序号,依次排序 且不会重复,注意使用row_number函数时必须要用over子句选择对某一列进行排序才能生成序号。
rank函数用于返回结果集的分区内每行的排名,行的排名是相关行之前的排名数加一。简单来说rank函 数就是对查询出来的记录进行排名,与row_number函数不同的是,rank函数考虑到了over子句中排序字 段值相同的情况,如果使用rank函数来生成序号,over子句中排序字段值相同的序号是一样的,后面字 段值不相同的序号将跳过相同的排名号排下一个,也就是相关行之前的排名数加一,可以理解为根据当 前的记录数生成序号,后面的记录依此类推。
dense_rank函数的功能与rank函数类似,dense_rank函数在生成序号时是连续的,而rank函数生成的序 号有可能不连续。dense_rank函数出现相同排名时,将不跳过相同排名号,rank值紧接上一次的rank
值。在各个分组内,rank()是跳跃排序,有两个第一名时接下来就是第四名,dense_rank()是连续排序, 有两个第一名时仍然跟着第二名。
关于Parttion by:
Parttion by关键字是Oracle中分析性函数的一部分,用于给结果集进行分区。它和聚合函数Group by不同的地方在于它只是将原始数据进行名次排列,能够返回一个分组中的多条记录(记录数不变),而Group by是对原始数据进行聚合统计,一般只有一条反映统计值的结果(每组返回一条)。
在使用排名函数的时候需要注意以下三点: 排名函数必须有OVER 子句。
排名函数必须有包含ORDER BY 的OVER 子句。
分组内从1开始排序。
Hive的count的用法
问过的一些公司:小米参考答案:
count() :所有行进行统计,包括NULL行count(1) :所有行进行统计,包括NULL行count(column) :对column中非Null进行统计
注意:count()执行时间比count(1)和count(column)都长,count(1)和count(column)执行时间差不多。
Hive的union和union all的区别
问过的一些公司:小米参考答案:
Union :对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
Union All :对两个结果集进行并集操作,包括重复行,不进行排序。
Hive的join操作原理,leh join、right join、inner join、outer join的异同?
可回答:Hive的join的几种操作
问过的一些公司:小米,腾讯,大华,米哈游,有赞参考答案:
hive执行引擎会将HQL“翻译”成为map-reduce任务,如果多张表使用同一列做join则将被翻译成一个reduce,否则将被翻译成多个map-reduce任务。
比如,hive执行引擎会将HQL“翻译”成为map-reduce任务,如果多张表使用同一列做join则将被翻译成一 个reduce,否则将被翻译成多个map-reduce任务。
- SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
- – 将被翻译成1个map-reduce任务
3 - SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
- – 将被翻译成2个map-reduce任务
3
这个很好理解,一般来说(map side join除外),map过程负责分发数据,具体的join操作在reduce完成,因此,如果多表基于不同的列做join,则无法在一轮map-reduce任务中将所有相关数据shuffle到统 一个reducer,对于多表join,hive会将前面的表缓存在reducer的内存中,然后后面的表会流式的进入reducer和reducer内存中其它的表做join。
为了防止数据量过大导致oom,将数据量最大的表放到最后,或者通过“STREAMTABLE”显示指定reducer 流式读入的表。
1、Join的操作原理
Hive中的Join可分为 Map Join (Map阶段完成join)和 Common Join (Reduce阶段完成join)。
Common Join
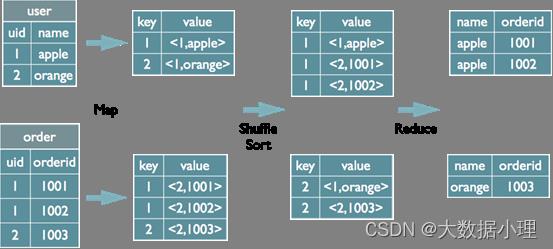
1 select u.name, o.orderid from order o join user u on o.uid = u.uid; 2
Map阶段
读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;
Map输出的value为join之后所关心的(select或者where中需要用到的)列;同时在value中还会包含表的Tag
信息,用于标明此value对应哪个表;
按照key进行排序。
ShuGle阶段
根据key的值进行hash,并将key/value按照hash值推送至不同的reduce中,这样确保两个表中相同的key位 于同一个reduce中
Reduce阶段
根据key的值完成join操作,期间通过Tag来识别不同表中的数据。
Map Join
MapJoin通常用于一个很小的表和一个大表进行join的场景,具体小表有多小,由参数hive.mapjoin.smalltable.filesize来决定,该参数表示小表的总大小,默认值为25000000字节,即25M。
Hive0.7之前,需要使用hint提示 /+ mapjoin(table) /才会执行MapJoin,否则执行Common Join,但在0.7版本之后,默认自动会转换Map Join,由参数hive.auto.convert.join来控制,默认为true。
假设a表为一张大表,b为小表,并且hive.auto.convert.join=true,那么Hive在执行时候会自动转化为
MapJoin。
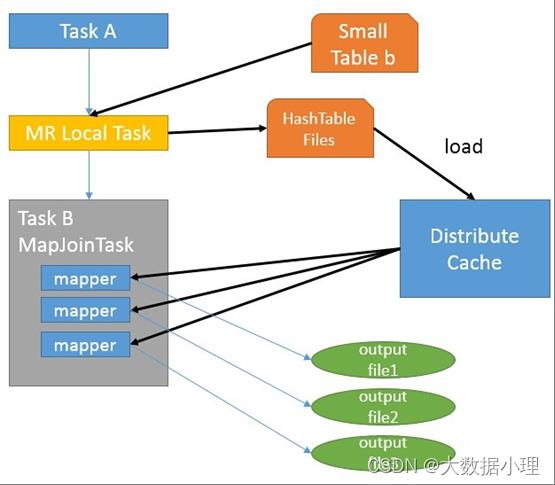
如图中的流程,首先是Task A,它是一个Local Task(在客户端本地执行的Task),负责扫描小表b的数据,将其转换成一个HashTable的数据结构,并写入本地的文件中,之后将该文件加载到DistributeCache 中,该HashTable的数据结构可以抽象为:
key Value
1 26
2 34

图中红框圈出了执行Local Task的信息。
接下来是Task B,该任务是一个没有Reduce的MR,启动MapTasks扫描大表a,在Map阶段,根据a的每一条记录去和DistributeCache中b表对应的HashTable关联,并直接输出结果。
由于MapJoin没有Reduce,所以由Map直接输出结果文件,有多少个Map Task,就有多少个结果文件。
总的来说,因为小表的存在,可以在Map阶段直接完成Join的操作,为了优化小表的查找速度,将其转 化为HashTable的结构,并加载进分布式缓存中。
2、inner join、leh join、right join、outer join
inner join
等值连接,只返回两个表中联结字段相等的行
left join
左联接,返回包括左表中的所有记录和右表中联结字段相等的记录
right join
右联接,返回包括右表中的所有记录和左表中联结字段相等的记录
inner join等价于join,可以理解为join是inner join的缩写;
leh join等价于leh outer join;right join等价于right outer join。
以上是关于大数据面试之hive重点的主要内容,如果未能解决你的问题,请参考以下文章