ViTag :在线 WiFi 精细时间测量辅助多人环境中的视觉-运动身份关联
Posted AI浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ViTag :在线 WiFi 精细时间测量辅助多人环境中的视觉-运动身份关联相关的知识,希望对你有一定的参考价值。
摘要
在本文中,我们提出了 ViTag 来关联多模态数据中的用户身份,尤其是那些从相机和智能手机获得的数据。 ViTag 将一系列视觉跟踪器生成的边界框与来自智能手机的惯性测量单元 (IMU) 数据和 Wi-Fi 精细时间测量 (FTM) 相关联。我们将问题表述为序列到序列(seq2seq)翻译的关联。在这个两步过程中,我们的系统首先使用多模态 LSTM 编码器-解码器网络 (X-Translator) 执行跨模态翻译,该网络将一种模态转换为另一种模态,例如纯粹从相机边界框重建 IMU 和 FTM 读数。其次,关联模块在相机和电话域之间找到身份匹配,然后将翻译后的模态与来自同一模态的观察数据进行匹配。与现有工作相比,我们提出的方法可以在所有用户可能正在执行相同活动的多人场景中关联身份。在现实世界的室内和室外环境中进行的大量实验表明,相机和电话数据(IMU 和 FTM)的在线关联在 1 到 3 秒的窗口内实现了 88.39% 的平均身份精度准确度 (IDP),优于最先进的 Vi-Fi (82.93%)。对电话领域内模态的进一步研究表明,FTM 可以将关联性能平均提高 12.56%。最后,我们的灵敏度实验结果证明了 ViTag 在不同噪声和环境变化下的鲁棒性。
索引词——跨模态、精细时间测量、惯性跟踪、对象跟踪、关联
1、简介
由于我们周围有大量传感器,跨多种传感模式关联用户身份对于支持跨异构传感器的多视图学习非常重要。 多模态关联有可能适用于需要跨模态识别的广泛应用,例如定位、重新识别和连续跟踪。 随着相机和智能手机的广泛使用,一个关键的应用场景是在相机视频中检测到的人与从他们的智能手机捕获的传感器数据之间的关联,如图 1 所示。 一个示例应用程序包括向在摄像头上检测到的特定用户设备发送警报消息(即使他们的脸可能不可见); 一个特殊的用例是在当前 COVID-19 大流行期间促进暴露通知。
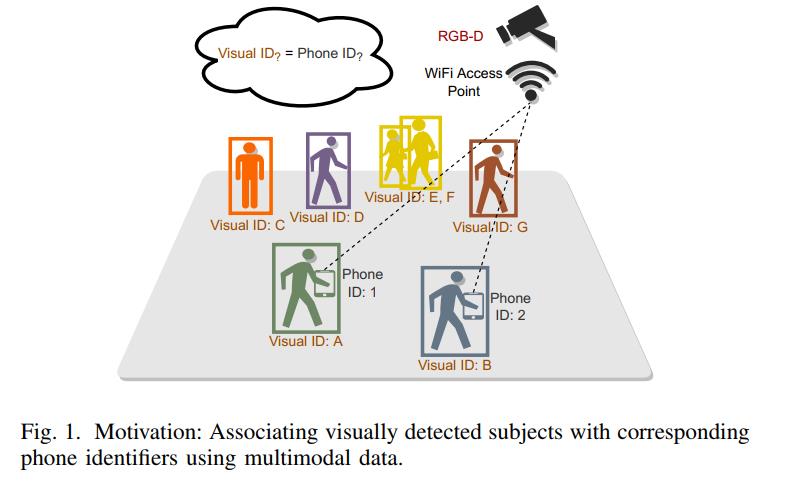
为了跨模式关联数据,现有方法需要预定义的视觉特征(例如衣服颜色 [34] 或手势 [7])、多个 IMU 设备放置 [28](例如臀部高度的背部)、校准的 IMU 和相机坐标 [11] ,有限的深度变化 [2],从相机的视野中可见的手指运动 [18]。过去很少有工作专注于关联视觉和惯性数据 [2]、[9]。然而,这些系统不提供实时关联,因此在现实世界场景中不可用。此外,依靠手工制作的特征 [2] 的技术通常在更复杂的场景中失败,其中照明条件变化,多人退出并重新进入相机视图等。Kwon 等人 [16]和 Rey 等人[26]提出了一个自动化管道,将人类活动的视频转换为惯性数据,用于训练常见的人类活动识别 (HAR) 模型。然而,这些方法侧重于捕获用于活动识别的显着特征,而不是用于消除可能都执行相同活动(例如,步行)的多个人的更严格的特征。此外,先前的工作 [23][25]、[36] 具有编码器 - 解码器架构,可同时学习视觉、惯性和特别是 WiFI FTM 数据之间的联合表示。我们提出的工作通过将在多模态数据中捕获的场景中行走的受试者的身份关联起来,进一步推进了这一研究。
方法。 在本文中,我们介绍了 ViTag,它将跨相机和电话域的数据关联起来。 具体来说,视觉跟踪器用于从相机帧生成轨迹。 然后将这些轨迹与从智能手机获得的 IMU 和 FTM 数据进行匹配。 我们的框架由一个跨模式编码器-解码器网络 X-Translator 组成,它采用双向 LSTM 以及来自相机的视觉数据与来自智能手机的运动和 WiFi 数据之间的联合表示。 X-Translator 利用联合表示来重建或将一种模态转换为另一种模态。 然后将重建的数据(例如,重建的电话数据)与从该模态(捕获的 IMU 测量或 FTM)中观察到的数据实时匹配。 鉴于这种方法引发的隐私问题,我们专注于用户选择与相机共享来自手机的传感器数据以及此类应用程序的接入点设置的场景。
挑战。由于数据的异质性,多模式学习提出了独特的挑战。特别是,关联相机和手机传感数据提出了两个重大挑战。首先,每种传感模式在不同的坐标空间中捕获数据。这要求系统能够将数据从相机坐标转换到本地参考系,例如 IMU 的参考系。其次,每种模式都提供不同级别的数据保真度。例如,即使在不影响惯性数据质量的情况下,视觉传感器在低光照条件下也不太有用。同时,惯性传感器数据在较长时间内表现出漂移和累积偏差。同样,FTM 数据中的距离和误差估计也会受到多径的影响。
贡献。为应对上述挑战,我们做出以下贡献:
- 我们设计和开发ViTag 来关联通过相机(视觉)和智能手机(运动和FTM)数据检测到的对象的身份,实现平均88.39% 的在线关联IDP。
- 我们提出了一种跨模式编码器-解码器架构X-Translator,它学习相机和手机域之间的联合表示,并将视觉轨迹转换为手机(IMU+FTM)读数,反之亦然。
- ViTag 对传感器噪声和从室内到室外多人环境的场景变化具有鲁棒性,在室内、室外和拥挤数据集中分别实现了 90.21%、87.85% 和 87.11% 的关联准确率 (IDP)。
2、 系统总览
ViTag 跨两个域关联身份:相机和智能手机。在摄像机观察场景中的人的情况下,如图 1 所示,目标是识别场景中的哪个对象正在携带哪个设备。图 2 显示了系统的概述。我们安装了一个带有 WiFi 接入点的 RGB-D 摄像头,可以俯瞰广阔的空间。场景中的用户带着他们的智能手机四处走动,每个设备都会捕获加速度计、陀螺仪和磁力计数据,同时与接入点交换 FTM 消息。
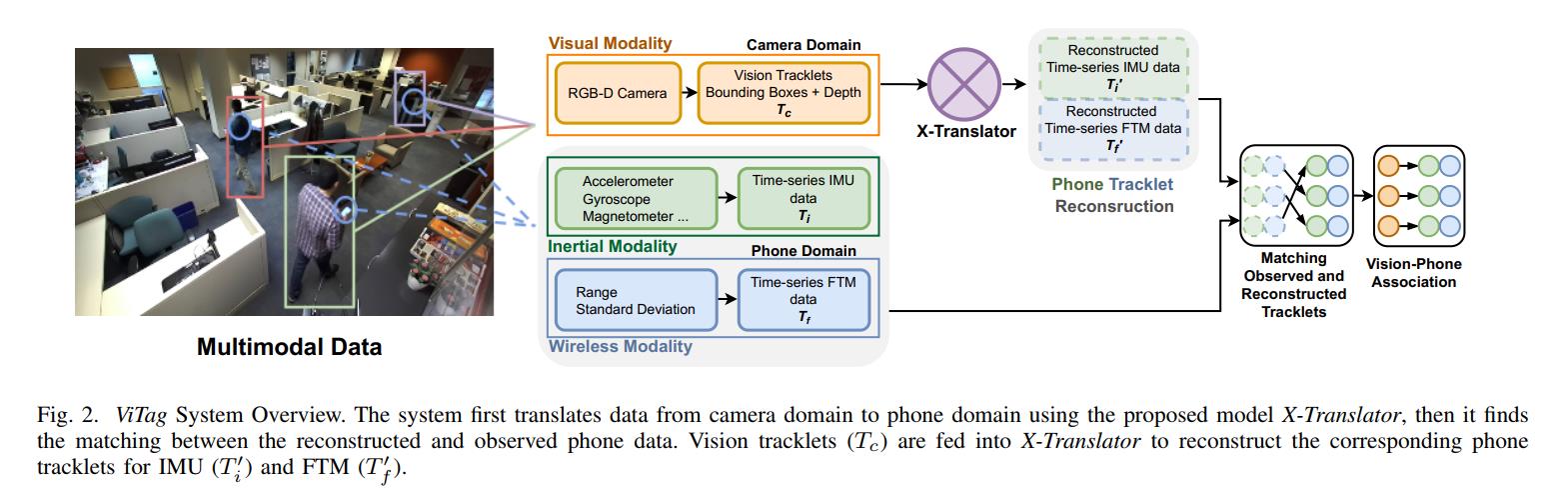
使用最先进的跟踪器在相机数据中检测和跟踪对象以生成轨迹。每个 tracklet 是相机坐标系中的一系列边界框。 ViTag 部署了一个两步流程来关联多种模式。首先,跨模态翻译,其中我们提出的 X-Translator 将这些视觉轨迹作为输入并重建相应的电话数据,包括时间序列 IMU 读数和 FTM 数据。据我们所知,X-Translator 是第一个联合学习惯性运动、视觉数据和无线模态的网络。其次,我们使用最大二分匹配(匈牙利算法)将重建的电话数据与从电话域接收到的数据进行实时匹配。
3、跨模式翻译
A. 预处理工作流程
相机数据。 我们使用 StereoLabs ZED 跟踪器从 RGB 深度相机数据生成轨迹(在本文的其余部分称为轨迹)。 由于主题经常移出相机视野,因此小轨迹的长度通常很短。 来自摄像机数据 (Tc) 的轨迹表示为边界框 (BBX) 的时间序列序列。 每个边界框表示为:
B
B
X
=
[
x
,
y
,
d
,
w
,
h
]
;
T
c
∈
R
K
×
5
(1)
B B X=[x, y, d, w, h] ; \\quad T_c \\in \\mathbbR^K \\times 5 \\tag1
BBX=[x,y,d,w,h];Tc∈RK×5(1)
其中 x 和 y 是边界框质心的坐标,d 是质心的深度测量值,w 和 h 是边界框的宽度和高度。
电话数据。 为了预处理智能手机数据,我们连接了来自时间序列 IMU 数据的 6 种类型的测量值:
T
i
t
=
[
acc
;
grav
;
lin
;
mag
;
gyro
;
q
]
;
T
i
∈
R
K
×
19
(2)
T_i^t=[\\text acc ; \\text grav ; \\text lin ; \\text mag ; \\text gyro ; q] ; \\quad T_i \\in \\mathbbR^K \\times 19 \\tag2
Tit=[ acc ; grav ; lin ; mag ; gyro ;q];Ti∈RK×19(2)
其中 acc 代表 3 轴加速度计数据,grav 和 lin 是加速度计数据的重力和线性分量。 gyro 和 mag 代表 3 轴陀螺仪和磁力计数据。 q 表示 4 轴四元数数据。 在时间 t 的 FTM 测量定义为:
T
f
t
=
[
r
,
s
t
d
]
;
T
f
∈
R
K
×
2
(3)
T_f^t=[r, s t d] ; \\quad T_f \\in \\mathbbR^K \\times 2\\tag3
Tft=[r,std];Tf∈RK×2(3)
其中 r 表示估计范围,或从手机到 WiFi 接入点的距离,而 std 表示在单个 RTT 突发中计算的标准偏差。
在我们的工作中,一种模态是指一种类型的数据,例如边界框、IMU 读数或 FTM 数据,而域是指源,例如相机或智能手机。 因此,在相机域中考虑视觉轨迹(
T
c
T_c
Tc),而电话域(
T
p
T_p
Tp)由 IMU 和 FTM 数据组成:
T
p
=
[
T
i
;
T
f
]
;
(4)
T_p=\\left[T_i ; T_f\\right] ;\\tag4
Tp=[Ti;Tf];(4)
为了实现准确的实时关联,我们在有限的时间窗口内处理和匹配数据。 虽然较长的时间序列窗口可能包含更多可用于关联的判别特征,但它们会增加关联任务的延迟。 为了解决这种权衡,我们根据经验选择窗口大小 K 为两个域中所有模式的 10 个样本。 由于室内和室外数据集的采样率略有不同,10个样本在室内环境中相当于3秒,在室外环境中相当于1秒。 因此,关联总是在不到 3 秒的时间内完成。 在每个时间步,最近的 K 个样本被用作网络的输入。
同步。 由于不同的采样率和时间戳,我们需要在将所有模态输入模型之前同步它们。 我们使用设备上的网络时间协议 (NTP) 同步相机和手机数据。 相机帧的采样率为 30 fps,IMU 读数为 100 Hz,FTM 为 3-5 Hz。 此外,相机 (BBX) 和电话 (IMU, FTM) 数据具有 16 和 13 精度时间戳。 我们使用来自相机域的数据(下采样到 10 fps)作为锚点来重新采样其他模态。 具体来说,对于每个相机帧,我们找到具有最接近时间戳的 IMU 和 FTM 读数。
B. 网络架构设计
X-Translator 的设计灵感来自自动编码器的自我监督能力。 与单峰自动编码器不同,XTranslator 需要相机和手机数据之间的标记对应关系。 所提出的架构的新颖之处在于将自动编码器方法应用于多种模式。 X-Translator 由三个主要模块组成:(1) 一个编码器,用于学习每个输入模态的单峰表示,(2) 一个学习跨模态潜在特征的联合表示层,以及 (3) 一个解码器,用于重建每个模态 . 该架构如图 3 所示。
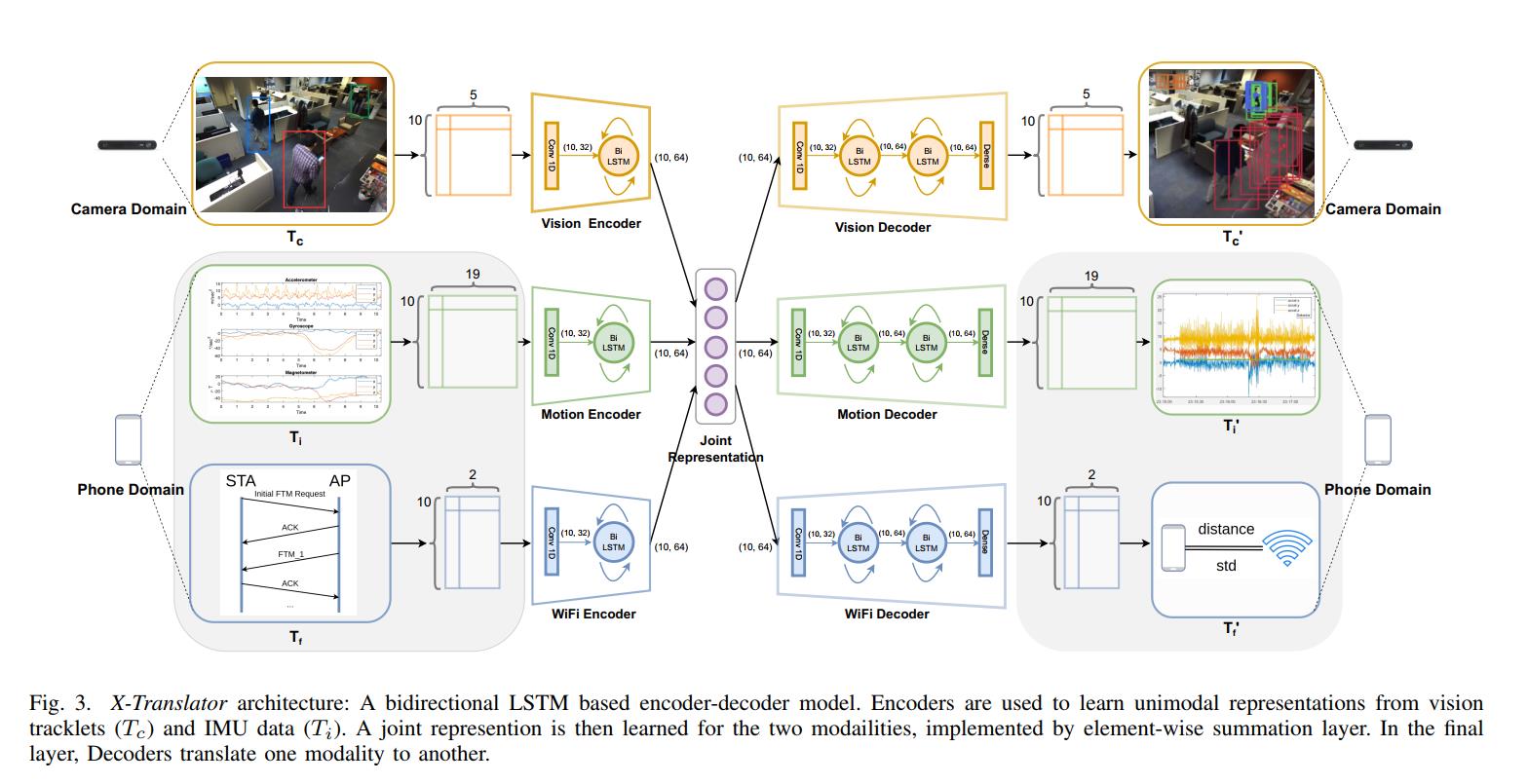
X-Translator 由几个编码器实例组成,每个实例都学习一种模态的表示。 编码器包括一个具有 32 个滤波器的一维卷积层,内核大小为 16,步幅为 1,然后是 ReLU 激活函数。 然后双向 LSTM 层从 IMU 和视觉模态中提取时间特征,在早期帧到后期帧之间的两个方向上。 联合表示通过求和将从单峰数据流中提取的特征集成到单个多峰表示中。 最后,每个解码器由两个堆叠的双向 LSTM 层组成,以分层方式提取融合特征。 我们使用术语编解码器来指代相同模态的一对编码器和解码器。
模型损失函数。 为了学习多模态翻译,我们设计我们的损失函数如下:
-
Self-reconstruction Loss:
L self = ∑ m ∈ M L ( D m ( E m ( X m ) ) , X m ) (5) L_\\text self =\\sum_m \\in M L\\left(D_m\\left(E_m\\left(X_m\\right)\\right), X_m\\right) \\tag5 Lself =m∈M∑L(Dm(Em(Xm)),Xm)(5) -
Cross-modal Reconstruction Loss:
L c m = ∑ m ∈ M L ( D m ˉ ( E m ( X m ) ) , X m ˉ ) L_\\mathrmcm=\\sum_m \\in M L\\left(D_\\barm\\left(E_m\\left(X_m\\right)\\right), X_\\barm\\right) Lcm=m∈M∑L(Dmˉ(Em(Xm)),Xmˉ)
- Cross-domain Reconstruction Loss:
L c d = L ( D p ( E c ( X c ) ) , X p ) + L ( D c ( E p ( X p ) ) , X c ) L_\\mathrmcd=L\\left(D_p\\left(E_c\\left(X_c\\right)\\right), X_p\\right)+L\\left(D_c\\left(E_p\\left(X_p\\right)\\right), X_c\\right) Lcd=L(Dp(Ec(Xc)),Xp)+L(Dc(Ep(Xp)),Xc)
- One-to-all Reconstruction Loss:
L 1 -to-all = ∑ m ∈ M L ( D M ( E m ( X m ) ) ) , X M ) \\left.L_1 \\text -to-all =\\sum_m \\in M L\\left(D_M\\left(E_m\\left(X_m\\right)\\right) \\right), X_M \\right) L1-to-all =m∈M∑L(DM(Em(Xm))),XM)
- Fused-reconstruction Loss:
L
fused
=
∑
m
∈
M
L
(
D
m
(
E
M
以上是关于ViTag :在线 WiFi 精细时间测量辅助多人环境中的视觉-运动身份关联的主要内容,如果未能解决你的问题,请参考以下文章