Redis_04_Redis八种特殊数据类型
Posted 毛奇志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis_04_Redis八种特殊数据类型相关的知识,希望对你有一定的参考价值。
文章目录
- 一、前言
- 二、位图Bitmap(底层不是一个独立的数据结构,底层还是string)
- 三、HyperLogLog
- 四、布隆过滤器(不是一个独立的数据结构)
- 五、Geospatial
- 六、Pub/Sub
- 七、Pipeline
- 八、Lua脚本
- 九、Redis事务
- 十、尾声
一、前言
Redis的八种特殊的数据类型,开发者需要掌握使用 ./redis-cli --raw 命令操作,还有就是 jedis 的操作。
二、位图Bitmap(底层不是一个独立的数据结构,底层还是string)
2.1 位图的特点
作用:位图可以用最小的空间存放最大量的数据,比如,对于bool类型,按位存放,用 0|1 来表示 false|true,由于一个字节8位,相对于String类型用一个字节来存放 true|false ,使用位图的方式,空间缩小为原来的 1/8 。
局限:值得注意的是,位图不是一个独立的数据结构,从底层来说,它是string字符串类型。位图不是特殊的数据结构,它的内容其实就是普通的字符串,也就是 byte 数组。我们可以使用普通的 get/set 直接获取和设置整个位图的内容,也可以使用位图操作 getbit/setbit 将 byte 数组看成位数组来处理。
2.2 位图的命令
SETBIT key offset value
对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。
GETBIT key offset
对 key 所储存的字符串值,获取指定偏移量上的位(bit)。
BITCOUNT key [start] [end]
计算给定字符串中,被设置为 1 的比特位的数量。默认情况下,给定的整个字符串都会被进行计数,通过指定额外的 start 或 end 参数,可以让计数只在特定的位上进行。start 和 end 参数的设置和 GETRANGE 命令类似,比如 0 表示左边第一位,1表示左边第二位,-1 表示右边第一位,-2 表示右边第二位。另外,不存在的 key 被当成是空字符串来处理,因此对一个不存在的 key 进行 BITCOUNT 操作,结果为 0 。
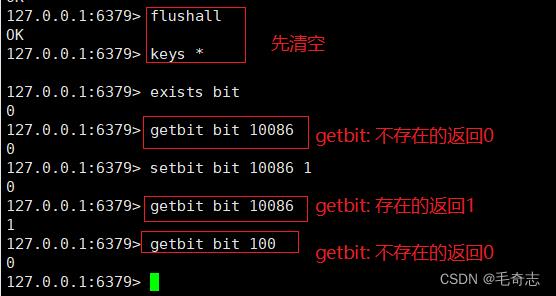
exists bit
getbit bit 10086
setbit bit 10086 1
getbit bit 10086
getbit bit 100
2.3 位图的应用
位图的最常见的应用就是用位来存储bool类型的true|false,比如统计签到和统计日活/月活。
统计签到:每个用户每天只有 已签到 和 未签到 两种状态,直接用 1 和 0 表示,或者用 true 和 false 表示。
统计日活:每个用户每天只有 活跃 和不活跃 两种状态,直接用 1 和 0 表示,或者用 true 和 false 表示。
2.3.1 统计签到
业务情景1:在我们平时开发过程中,会有一些 bool 型数据需要存取(即只有两个值 true|false 0|1),比如用户一年的签到记录,签了是 1,没签是 0,要记录 365 天。如果使用普通的 key/value,每个用户要记录 365 个,当用户上亿的时候,需要的存储空间是惊人的。
解决:为了解决这个问题,Redis 提供了位图数据结构,这样每天的签到记录只占据一个位,365 天就是 365 个位,46 个字节 (一个稍长一点的字符串) 就可以完全容纳下,这就大大节约了存储空间。
具体实现:
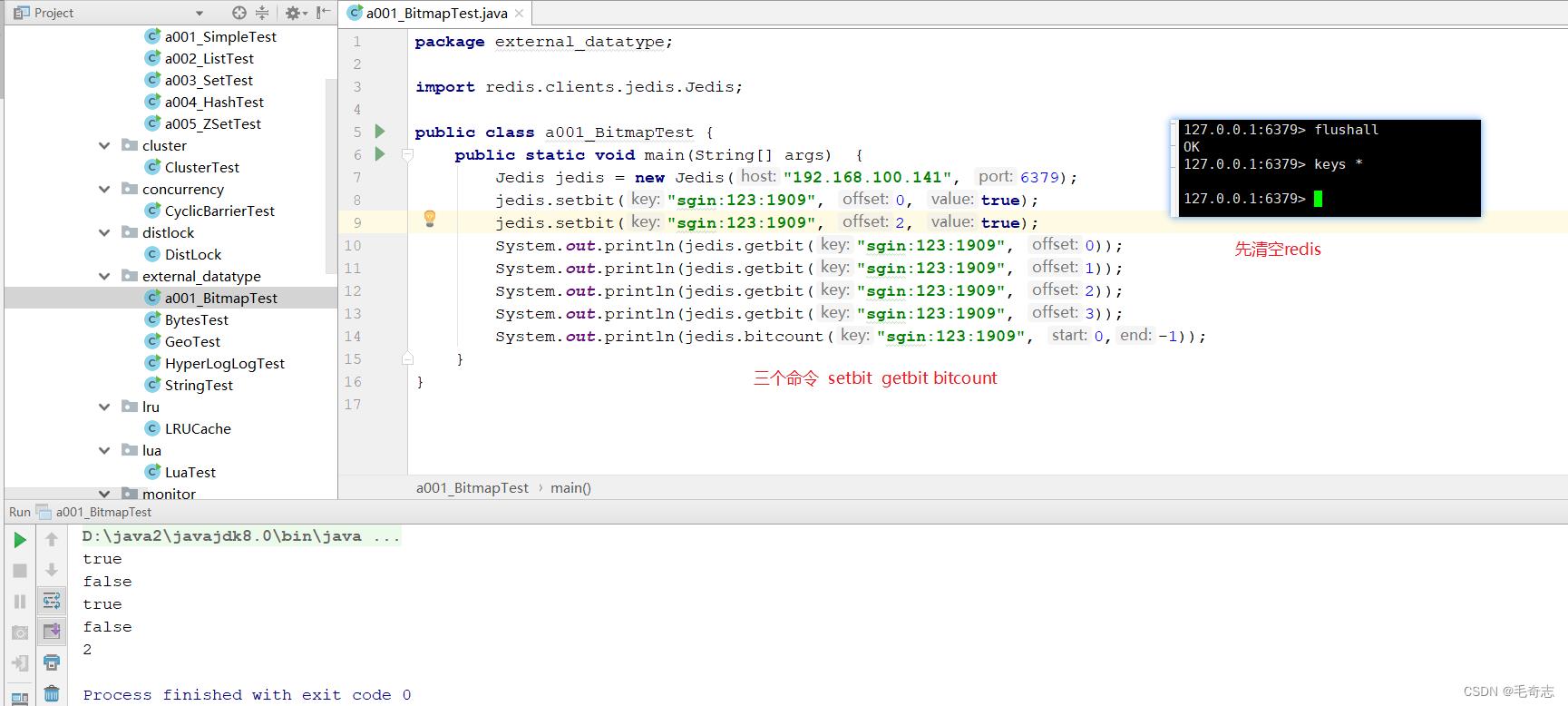
key 可以设置为 “前缀:用户id:年月” ,譬如 setbit sign:123:1909 0 1 代表用户ID=123签到,签到的时间是19年9月份,0代表该月第一天,1代表签到了。第二天没有签到,无需处理,系统默认为0,第三天签到 setbit sign:123:1909 2 1,可以查看一下目前的签到情况,显示第一天和第三天签到了,前8天目前共签到了2天,如下:
127.0.0.1:6379> setbit sign:123:1909 0 1 set 第一天签到了
0
127.0.0.1:6379> setbit sign:123:1909 2 1 set 第三天签到了
0
127.0.0.1:6379> getbit sign:123:1909 0 get 查看第一天是否签到,返回为1,第一天签到了
1
127.0.0.1:6379> getbit sign:123:1909 1 get 查看第二天是否签到,返回为0,第二天没签到
0
127.0.0.1:6379> getbit sign:123:1909 2 get 查看第三天是否签到,返回为1,第三天签到了
1
127.0.0.1:6379> getbit sign:123:1909 3 get查看第四天是否前端,返回为0,第四天没签到
0
127.0.0.1:6379> bitcount sign:123:1909 0 0 count查看所有签到天数,返回为2,一共两天签到
2
2.3.2 统计日活/月活
业务情景:当我们要统计日活/月活的时候,因为需要去重,需要使用 set 来记录所有活跃用户的 id,这非常浪费内存。
解决:可以看作是存储bool类型数据问题,所以可以考虑使用位图来标记用户的活跃状态。每个用户会都在这个位图的一个确定位置上,0 表示不活跃,1 表示活跃。然后到第二天/月底遍历一次位图就可以得到日度活跃用户数/月度活跃用户数。
三、HyperLogLog
从统计页面PV到统计页面UV,从set数据类型到HyperLogLog数据类型
3.1 HyperLogLog的特点
HyperLogLog数据结构,添加操作命令为pfadd,查看数量命令为pfcount,两个命令中这个 pf 是HyperLogLog 这个数据结构的发明人 Philippe Flajolet 的首字母缩写。
HyperLogLog与上面使用的位图bitmap一样,在完成同一业务下,使用更小的空间存储数据(相对于set数据结构)。其核心应用在于计数,常见的业务是统计网页的PV和UV。
3.2 HyperLogLog的命令
版本引入:Redis 在 2.8.9 版本添加了 HyperLogLog 结构。(我们使用的Redis 6.0.9 版本就一定有这个数据类型了)
作用:Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
优势(占用内存小):在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
局限(只集合计数,不存储集合): HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
PFADD key element [element …]
添加指定元素到 HyperLogLog 中。
PFCOUNT key [key …]
返回给定 HyperLogLog 的基数估算值。
PFMERGE destkey sourcekey [sourcekey …]
将多个 HyperLogLog 合并为一个 HyperLogLog
比如数据集 runoobkey 这个键中, “redis”, “mongdb”, “mysql”, 那么这个数据集的基数集为 “redis”, “mongdb”, “mysql” , 基数(不重复元素)为5。 基数估计就是在误差可接受的范围内,快速计算基数。

3.3 HyperLogLog的应用
业务情景:统计网页的PV和UV
如果统计 PV 那非常好办,给每个网页一个独立的 Redis 计数器就可以了,这个计数器的 key 后缀加上当天的日期。这样来一个请求,incrby 一次,最终就可以统计出所有的 PV 数据。但是 UV 不一样,它要去重,即同一个用户一天之内的多次访问请求只能计数一次。这就要求每一个网页请求都需要带上用户的 ID,无论是登陆用户还是未登陆用户都需要一个唯一 ID 来标识。
当前问题:PV直接统计数量就好了,UV要在统计PV数量上根据用户id去重
注意1:无论是PV,还是UV,都不需要特别精准的数据,一个大致数据就好了
注意2:无论是PV,还是UV,都是针对页面来说的,页面的PV,页面的UV
对于统计UV,这里提供两种方案,Set数据类型和HyperLogLog数据类型
方案一:使用set数据类型
理由:set数据结构自带去重,只要value是用户id,会自动去重
用法与优点:使用set数据结构,为每一个页面一个独立的 set 集合来存储所有当天访问过此页面的用户 ID。当一个请求过来时,我们使用 sadd 将用户 ID 塞进去就可以了。通过 scard 可以取出这个集合的大小,这个数字就是这个页面的 UV 数据。
缺点:第一,爆款页面:如果你的页面访问量非常大,比如一个爆款页面几千万的 UV,你需要一个很大的 set 集合来统计,这就非常浪费空间。
第二,多个页面:如果页面很多,那所需要的存储空间是惊人的。为这样一个去重功能就耗费这样多的存储空间,其实老板需要的数据又不需要太精确,105w 和 106w 这两个数字对于老板们来说并没有多大区别,So,有没有更好的解决方案呢?
方案二:使用HyperLogLog数据类型
HyperLogLog的两个命令:HyperLogLog 提供了两个指令 pfadd 和 pfcount,顾名思义,一个是增加计数,一个是获取计数。pfadd 用法和 set 集合的 sadd 是一样的,来一个用户 ID,就将用户 ID 塞进去就是;pfcount 和 scard 用法是一样的,直接获取计数值。
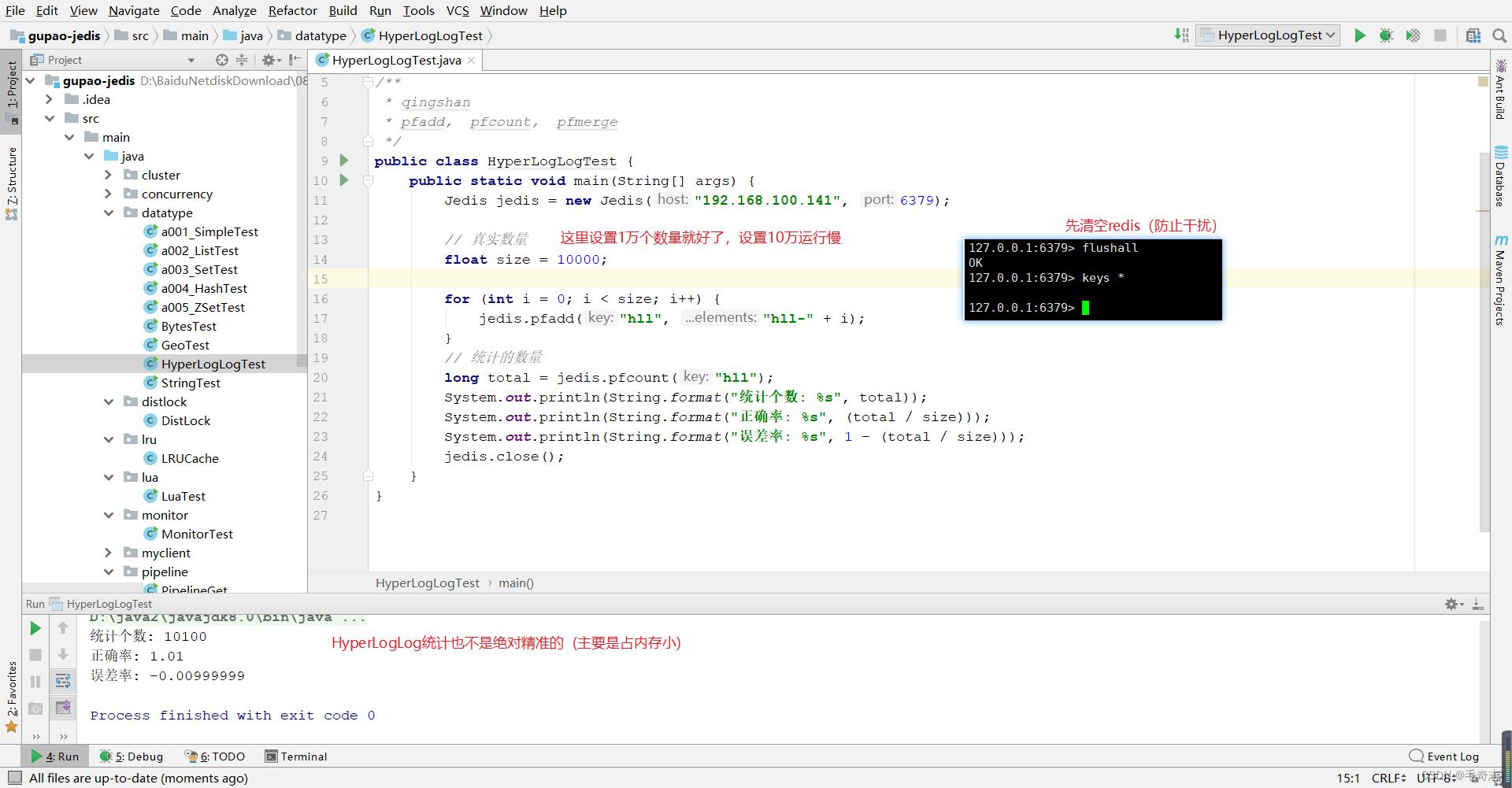
具体实现(HyperLogLog数据类型统计UV)
# 数量使用 pfadd 和 pfcount 两条命令
127.0.0.1:6379> pfadd codehole user1 // 对于HyperLogLog类型变量codehole,添加变量user1
(integer) 1
127.0.0.1:6379> pfcount codehole // pfcount命令对于HyperLogLog类型变量codehole计数,为1
(integer) 1
127.0.0.1:6379> pfadd codehole user2 // 对于HyperLogLog类型变量codehole,添加变量user2
(integer) 1
127.0.0.1:6379> pfcount codehole // pfcount命令对于HyperLogLog类型变量codehole计数,为2
(integer) 2
127.0.0.1:6379> pfadd codehole user3 // 对于HyperLogLog类型变量codehole,添加变量user3
(integer) 1
127.0.0.1:6379> pfcount codehole // pfcount命令对于HyperLogLog类型变量codehole计数,为3
(integer) 3
127.0.0.1:6379> pfadd codehole user4 // 对于HyperLogLog类型变量codehole,添加变量user4
(integer) 1
127.0.0.1:6379> pfcount codehole // pfcount命令对于HyperLogLog类型变量codehole计数,为4
(integer) 4
127.0.0.1:6379> pfadd codehole user5 // 对于HyperLogLog类型变量codehole,添加变量user5
(integer) 1
127.0.0.1:6379> pfcount codehole // pfcount命令对于HyperLogLog类型变量codehole计数,为5
(integer) 5
127.0.0.1:6379> pfadd codehole user6 // 对于HyperLogLog类型变量codehole,添加变量user6
(integer) 1
127.0.0.1:6379> pfcount codehole // pfcount命令对于HyperLogLog类型变量codehole计数,为6
(integer) 6
127.0.0.1:6379> pfadd codehole user7 user8 user9 user10 // 对于HyperLogLog类型变量codehole,添加变量user7 user8 user9 user10
(integer) 1
127.0.0.1:6379> pfcount codehole // pfcount命令对于HyperLogLog类型变量codehole计数,为10
(integer) 10
四、布隆过滤器(不是一个独立的数据结构)
布隆过滤器和bitmap一样,也不是不是独立的数据结构:
bitmap内置在redis里面,底层还是string数据结构;
布隆过滤器根本就不内置在redis里面,只是一个jar包。
HyperLogLog存在的意义是为了统计PV UV,就是大数据量集合计数(redis是运行在内存李,用set占用内存太多了),布隆过滤器的意义是为 hyperLogLog 提供了一个 pfcontains 命令效果。
4.1 布隆过滤器的特点
HyperLogLog局限与布隆过滤器的引入
HyperLogLog局限:对于大数据量,HyperLogLog 数据结构来进行估数,它非常有价值,可以解决很多精确度不高的统计需求。但是如果我们想知道某一个值是不是已经在 HyperLogLog 结构里面了,它就无能为力了,它只提供了 pfadd 和 pfcount 方法,没有提供 pfcontains 这种方法。即对于大数据量,HyperLogLog只能添加和计数,无法判断是否存在contains/exists,这个时候就需要布隆过滤器了。
业务场景:我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的?
方案一:在服务端记录用户看过的所有历史记录
因为新闻是大数据量,所以使用 HyperLogLog 数据结构,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录,如下:
127.0.0.1:6379> bf.add codehole user1 // bf.add 添加 user1
(integer) 1
127.0.0.1:6379> bf.add codehole user2 // bf.add 添加 user2
(integer) 1
127.0.0.1:6379> bf.add codehole user3 // bf.add 添加 user3
(integer) 1
127.0.0.1:6379> bf.exists codehole user1 // bf.exists user1,返回为1,存在
(integer) 1
127.0.0.1:6379> bf.exists codehole user2 // bf.exists user2,返回为1,存在
(integer) 1
127.0.0.1:6379> bf.exists codehole user3 // bf.exists user3,返回为1,存在
(integer) 1
127.0.0.1:6379> bf.exists codehole user4 // bf.exists user4 返回为0,不存在
(integer) 0
127.0.0.1:6379> bf.madd codehole user4 user5 user6 // bf.madd 添加user4 user5 user6
(1) (integer) 1
(2) (integer) 1
(3) (integer) 1
127.0.0.1:6379> bf.mexists codehole user4 user5 user6 user7 // bf.exists user4 user5 user6 user7 前面三个返回1,存在,user7返回为0,不存在
(1) (integer) 1
(2) (integer) 1
(3) (integer) 1
(4) (integer) 0
问题是当用户量很大,每个用户看过的新闻又很多的情况下,这种方式,推荐系统的去重工作在性能上无法满足。
方案二:使用布隆过滤器,判断是否存在 contains|exists
第一,布隆过滤器的initial_size设置:布隆过滤器的initial_size估计的过大,会浪费存储空间;布隆过滤器的initial_size估计的过小,就会影响准确率。用户在使用之前一定要尽可能地精确估计好元素数量,还需要加上一定的冗余空间以避免实际元素可能会意外高出估计值很多。
第二,布隆过滤器的error_rate设置:布隆过滤器的error_rate越小,需要的存储空间就越大,对于不需要过于精确的场合,error_rate设置稍大一点也无伤大雅。比如在新闻去重上而言,误判率高一点只会让小部分文章不能让合适的人看到,文章的整体阅读量不会因为这点误判率就带来巨大的改变。
4.2 布隆过滤器的应用
布隆过滤器的核心在于快速判断是否存在,去重功能,一般有一下三个应用:
1、爬虫去重,爬虫快速判断是否存在,对于已经存在的去重:在爬虫系统中,我们需要对 URL 进行去重,已经爬过的网页就可以不用爬了。但是 URL 太多了,几千万几个亿,如果用一个集合装下这些 URL 地址那是非常浪费空间的。这时候就可以考虑使用布隆过滤器。它可以大幅降低去重存储消耗,只不过也会使得爬虫系统错过少量的页面。
2、NoSQL数据库,不在数据库的row不到数据库磁盘中去找:布隆过滤器在 NoSQL 数据库领域使用非常广泛,我们平时用到的 HBase、Cassandra 还有 LevelDB、RocksDB 内部都有布隆过滤器结构,布隆过滤器可以显著降低数据库的 IO 请求数量。当用户来查询某个 row 时,可以先通过内存中的布隆过滤器过滤掉大量不存在的 row 请求,然后再去磁盘进行查询。
3、垃圾邮件过滤,设置判断算法,如果是满足判断算法,算做垃圾邮件:邮箱系统的垃圾邮件过滤功能也普遍用到了布隆过滤器,因为用了这个过滤器,所以平时也会遇到某些正常的邮件被放进了垃圾邮件目录中,这个就是误判所致,概率很低。
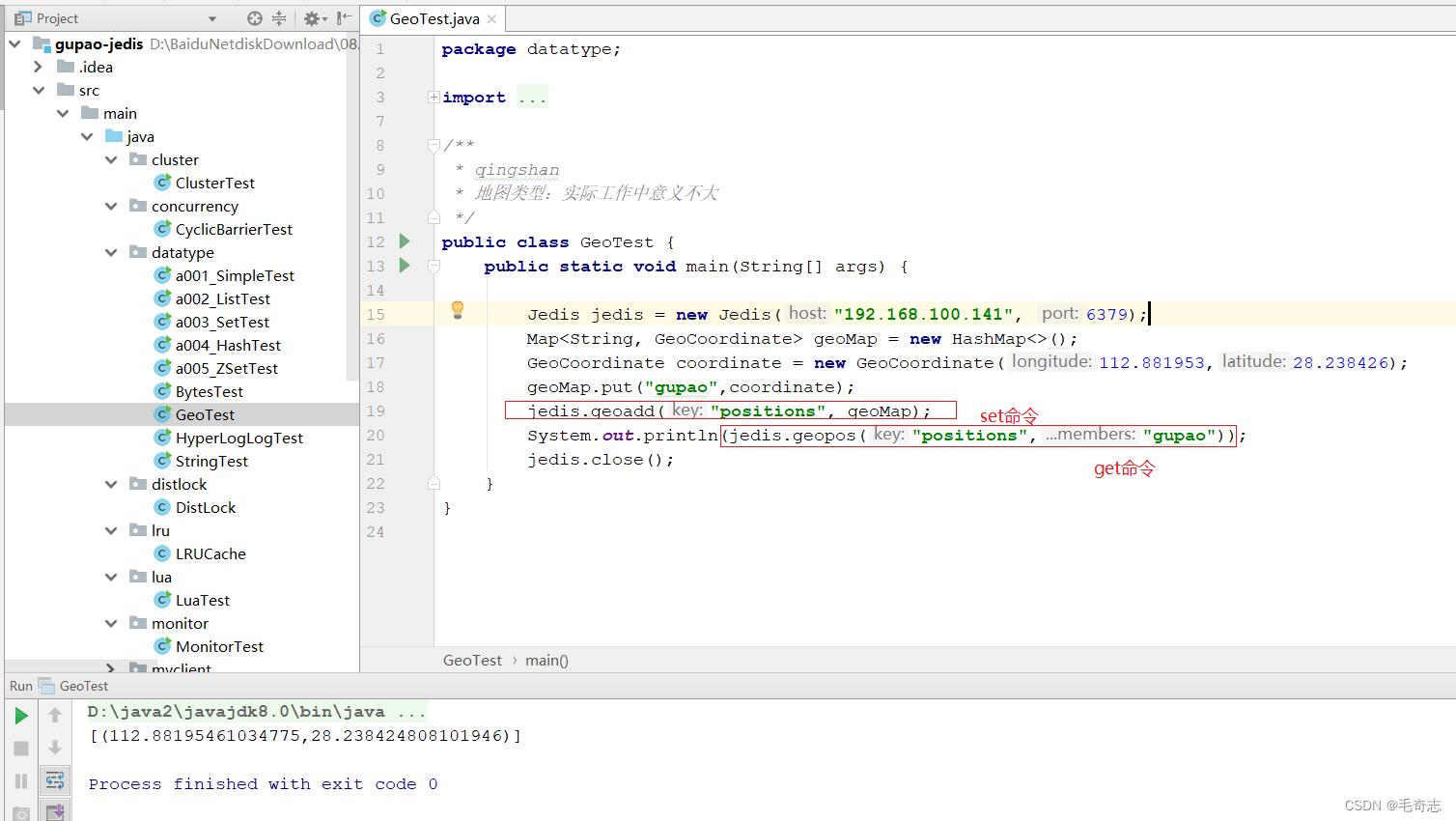
五、Geospatial
作用:用来保存地理位置,并作位置距离计算或者根据半径计算位置等。即可以用Redis来实现附近的人或者计算最优地图路径。
业务实际:查找附近的人,使用GeoHash数据类型,使用布隆过滤器去重
这个地图类型实际工作的时候意义不大,只需要直接如何在 ./redis-cli --raw 里面敲命令,还有就是 jedis 用代码操作就好了
1、在 ./redis-cli --raw 里面敲命令:https://www.runoob.com/redis/redis-geo.html
2、在 jedis 用代码操作:
六、Pub/Sub
作用:功能是订阅发布功能,可以用作简单的消息队列。
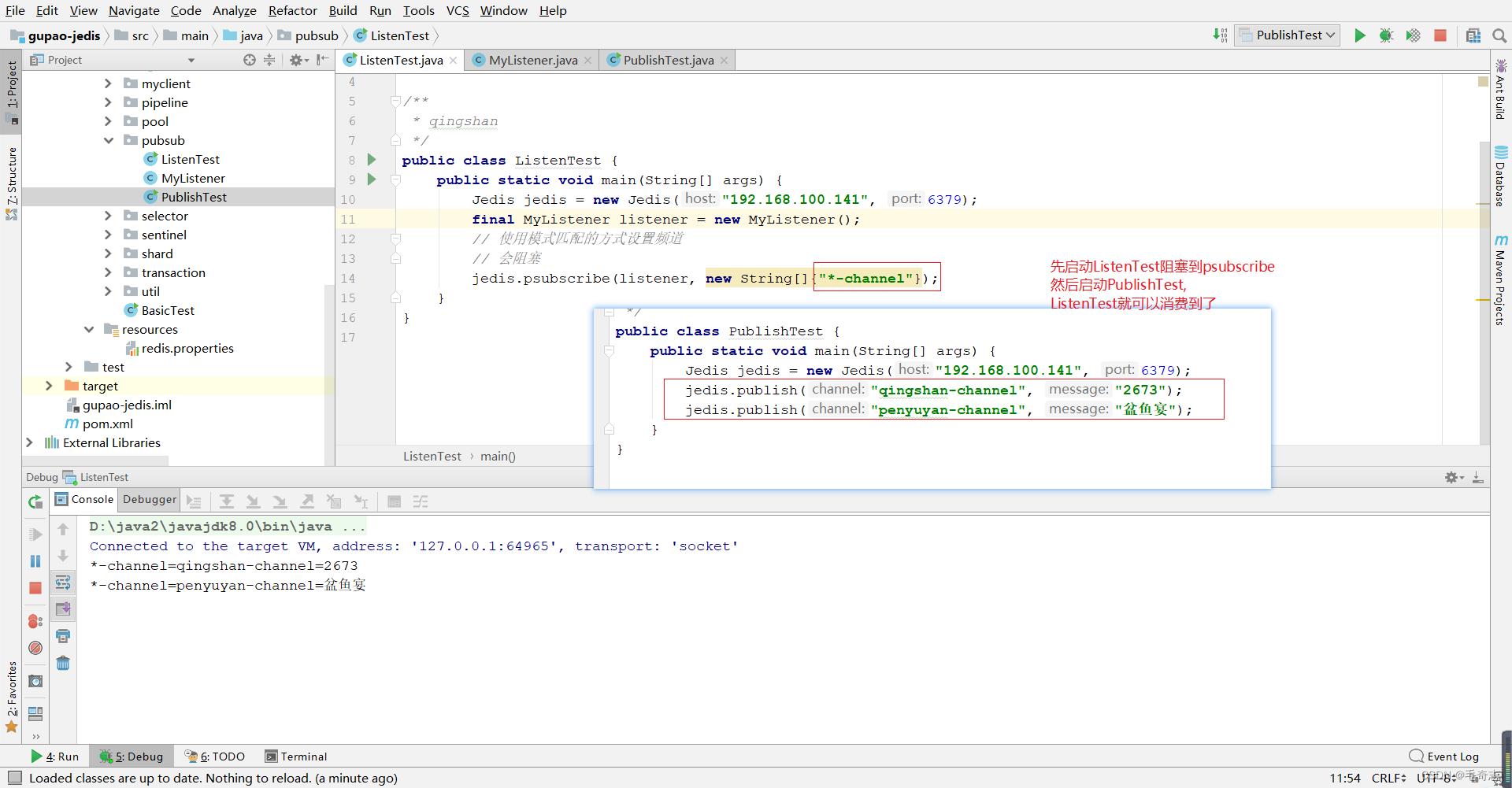
七、Pipeline
作用:可以批量执行一组指令,一次性返回全部结果,可以减少频繁的请求应答。Pipeline可以将多次IO往返的时间缩减为一次,前提是pipeline执行的指令之间没有因果相关性。使用redis-benchmark进行压测的时候可以发现影响redis的QPS峰值的一个重要因素是pipeline批次指令的数目。
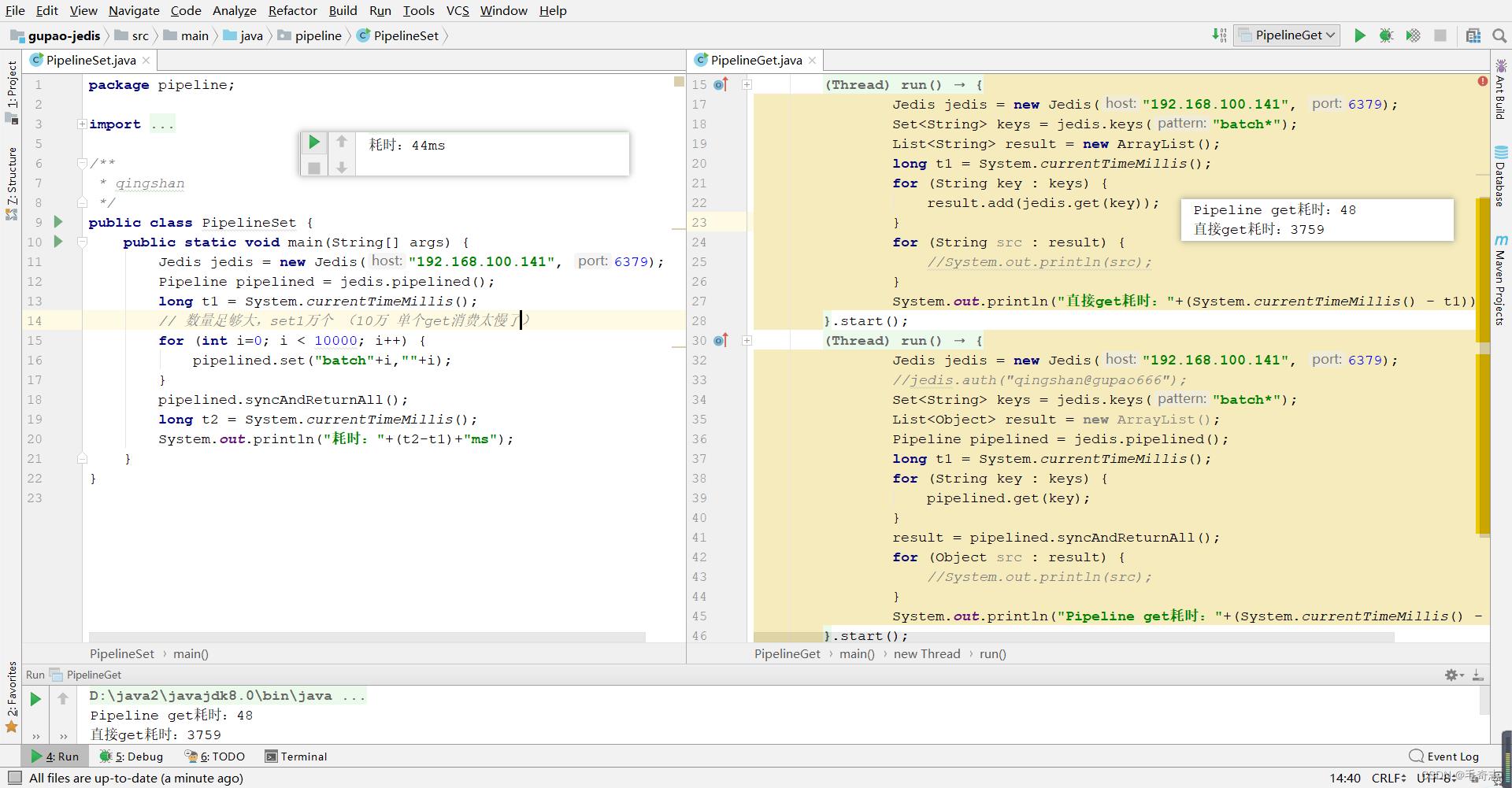
八、Lua脚本
Redis 支持提交 Lua 脚本来执行一系列的功能。电商项目中,秒杀场景经常使用Lua脚本,利用他的原子性。
九、Redis事务
最后一个功能是事务,但 Redis 提供的不是严格的事务,Redis 只保证串行执行命令,并且能保证全部执行,但是执行命令失败时并不会回滚,而是会继续执行下去,为了保证原子性还是需要使用Lua脚本来实现的。
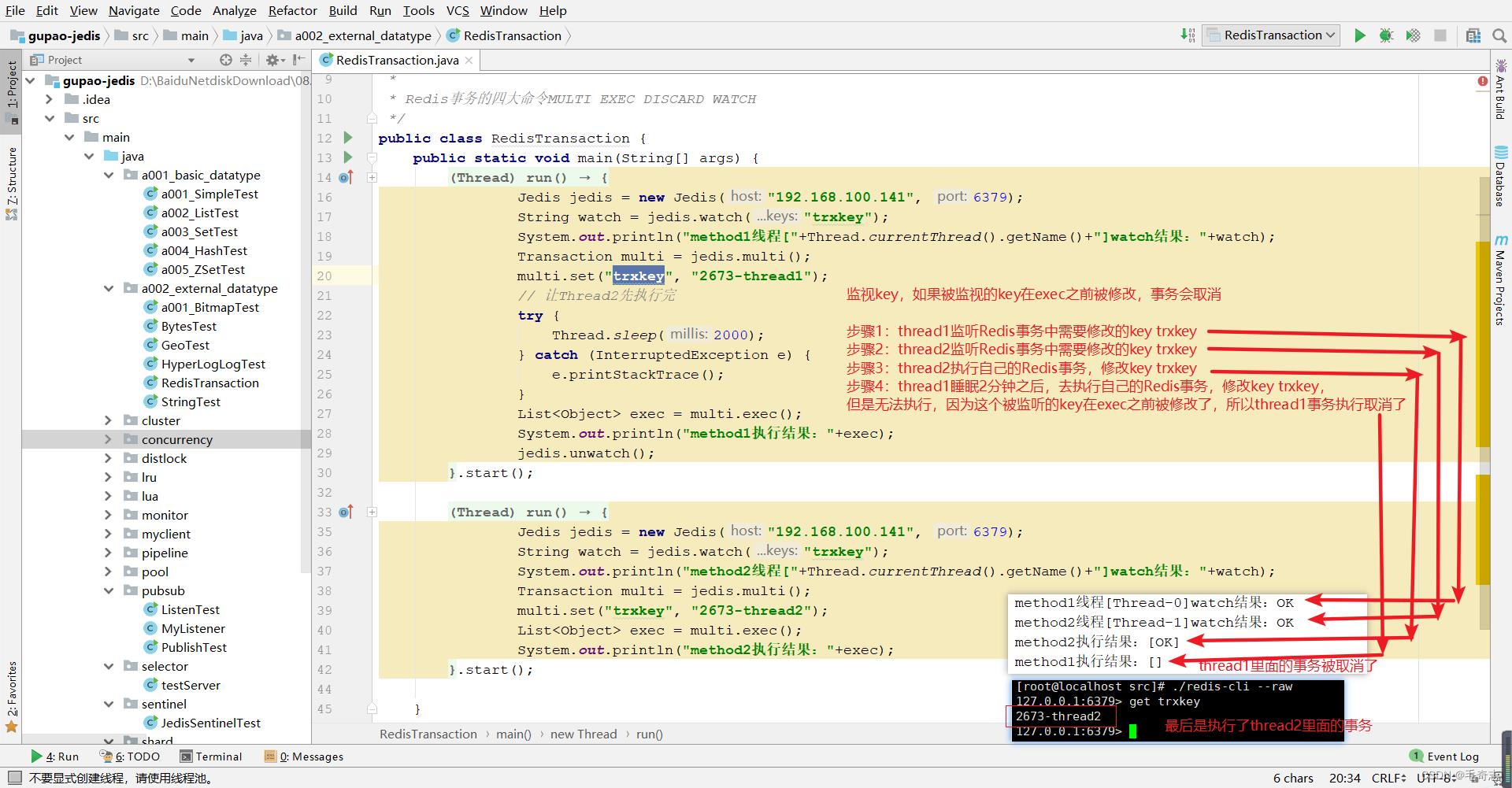
十、尾声
本文介绍了Redis八种特殊的数据类型,如下:
第一,Bitmap位图
原理:支持按 bit 位来存储信息
操作命令: setbit getbit bitcount (exists key)
注意:不是一种独立的数据类型,本质还是string数据类型
第二,HyperLogLog
作用:供不精确的去重计数功能,比较适合用来做大规模数据的去重统计,例如统计 UV,相对于Set数据结构有大数据量处理的优势,缺点是不精确。
操作命令:pfadd pfcount pfmerge (局限:没有提供pfcontians命令,所以引入了布隆过滤器)
第三,布隆过滤器
作用:在大数据处理时可以判断某个数据存不存在。都是处理大数据量,布隆过滤器主要用来判断,某个数据存不存在,HyperLogLog用来做统计 , 没法确认某个数据在不在。
第四,Geospatial
作用:用来保存地理位置,并作位置距离计算或者根据半径计算位置等。即可以用Redis来实现附近的人或者计算最优地图路径。
操作命令:
第五,pub/sub
作用:功能是订阅发布功能,可以用作简单的消息队列。
操作命令:
第六,Pipeline
作用:可以批量执行一组指令,一次性返回全部结果,可以减少频繁的请求应答。
操作命令:
第七,Lua脚本
Redis 支持提交 Lua 脚本来执行一系列的功能。电商项目中,秒杀场景经常使用Lua脚本,利用他的原子性。
操作命令:
第八,Redis事务
Redis事务提供的不是严格的事务,Redis 只保证串行执行命令,并且能保证全部执行,但是执行命令失败时并不会回滚,而是会继续执行下去。
操作命令:MULTI EXEC DISCARD WATCH
以上是关于Redis_04_Redis八种特殊数据类型的主要内容,如果未能解决你的问题,请参考以下文章