场景应用:100亿的数据你怎么排序?昂??你怎么排序啊?你别愣着啊,你说啊?!!!!
Posted 流楚丶格念
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了场景应用:100亿的数据你怎么排序?昂??你怎么排序啊?你别愣着啊,你说啊?!!!!相关的知识,希望对你有一定的参考价值。
文章目录
场景
给100亿个数字排序,100亿个 int 型数字放在文件里面大概有 37.2GB,非常大,内存一次装不下了。那么肯定是要拆分成小的文件一个一个来处理,最终在合并成一个排好序的大文件。
实现思路
1.把这个37GB的大文件,用哈希分成1000个小文件,每个小文件平均38MB左右(理想情况),把100亿个数字对1000取模,模出来的结果在0到999之间,每个结果对应一个文件,所以我这里取的哈希函数是 h = x % 1000,哈希函数取得"好",能使冲突减小,结果分布均匀。

2.拆分完了之后,得到一些几十MB的小文件,那么就可以放进内存里排序了,可以用快速排序,归并排序,堆排序等等。
3.1000个小文件内部排好序之后,就要把这些内部有序的小文件,合并成一个大的文件,可以用二叉堆(二叉堆有两种:最大堆和最小堆)来做1000路合并的操作,每个小文件是一路,合并后的大文件仍然有序。
-
首先遍历1000个文件,每个文件里面取第一个数字,组成 (数字, 文件号) 这样的组合加入到堆里(假设是从小到大排序,用小顶堆),遍历完后堆里有1000个 (数字,文件号) 这样的元素
-
然后不断从堆顶拿元素出来,每拿出一个元素,把它的文件号读取出来,然后去对应的文件里,加一个元素进入堆,直到那个文件被读取完。拿出来的元素当然追加到最终结果的文件里。
-
按照上面的操作,直到堆被取空了,此时最终结果文件里的全部数字就是有序的了。

实现方案
方案一:放数据库里(哈哈哈)
统统存数据库里,让数据库来处理数据进行排序。
当然直接弄肯定也卡死,这又涉及到分库分表,或者分布式,其实思想都是差不多的,拆分成各个桶分别处理,再合并处理
方案二:桶排序(正经桶)
随机的乱数普遍用法
桶排序,顾名思义,会用到“桶”,核心思想和上面相差无几:就是将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序。
桶内排完序之后,再把每个桶里的数据按照顺序依次取出,组成的序列就是有序的了。比如说我们有10GB的订单数据,我们希望按订单金额(假设金额都是正整数)进行排序,我们可以先扫描一遍文件,看订单金额所处的数据范围。假设经过扫描之后我们得到,订单金额最小是1元,最大是10万元。我们将所有订单根据金额划分 到100个桶里,第一个桶我们存储金额在1元到1000元之内的订单,第二桶存储金额在1001元到2000元之内的订单,以此类推。每一个桶对应一个文件,并且按照 金额范围的大小顺序编号命名(00,01,02…99)。
理想的情况下,如果订单金额在1到10万之间均匀分布,那订单会被均匀划分到100个文件中,每个小文件中存储大约100MB的订单数据,我们就可以将这100个小文件依次放到内存中,用快排来排序。等所有文件都排好序之后,我们只需要按照文件编号,从小到大依次读取每个小文件中的订单数据,并将其写入到一个文件中,那这个文件中存储的就是按照金额从小到大排序的订单数据了。
但是光这样其实还是有一定问题的:就比如说:订单按照金额在1元到10万元之间并不一定是均匀分布的 ,所以10GB订单数据是无法均匀地被划分到100个文件中的。有可能某个金额区间的数据特别多,划分之后对应的文件就会很大,没法一次性读入内存进行对该文件的排序。这又该怎么办呢?
针对这些划分之后还是比较大的文件,我们可以继续划分,比如,订单金额在1元到1000元之间的比较多,我们就将这个区间继续划分为10个小区间,1元 到100元,101元到200元,201元到300元…901元到1000元。如果划分之后,101元到200元之间的订单还是太多,无法一次性读入内存,那就继续再划分,直到所有的文件都能读入内存为止。
方案三:计数排序(特殊桶)
一般分数、年龄用计数排序
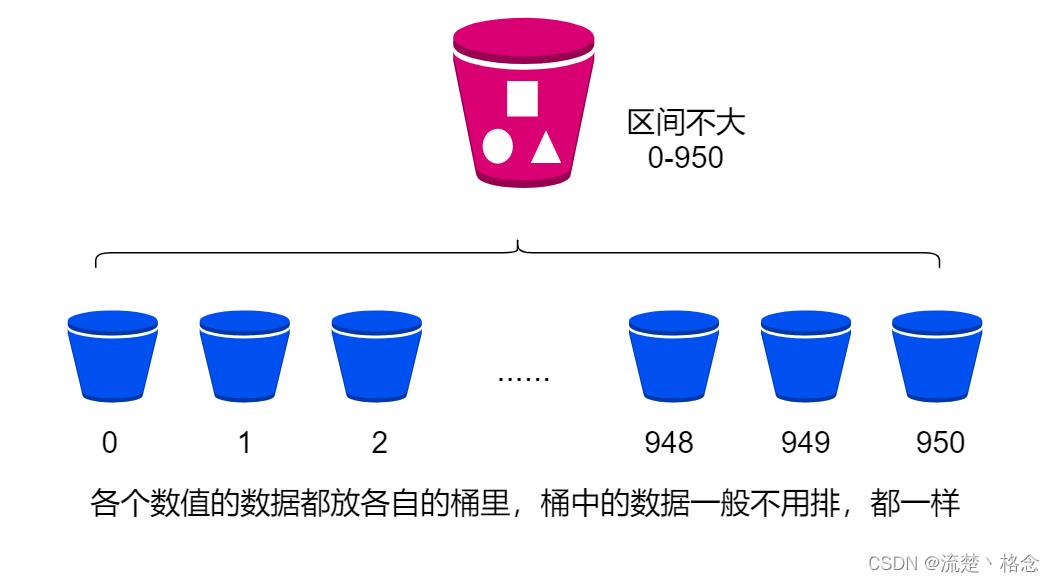
计数排序其实是桶排序的一种特殊情况。当要排序的n个数据,所处的范围并不大的时候,比如最大值是k,我们就可以把数据划分成k个桶。每个桶内的数据值都是相同的,省掉了桶内排序的时间。
我们都经历过高考,高考查分数系统你还记得吗?我们查分数的时候,系统会显示我们的成绩以及所在省的排名。如果你所在的省有50万考生,如何通过成绩快 速排序得出名次呢?
考生的满分是900分,最小是0分,这个数据的范围很小,所以我们可以分成901个桶,对应分数从0分到900分。根据考生的成绩,我们将这50万考生划分到 这901个桶里。桶内的数据都是分数相同的考生,所以并不需要再进行排序。我们只需要依次扫描每个桶,将桶内的考生依次输出到一个数组中,就实现了50
万考 生的排序。因为只涉及扫描遍历操作,所以时间复杂度是O(n)。
方案四:基数排序(特殊情况)
一般用于身份证、手机号、什么什么号的
我们再来看这样一个排序问题。假设我们有 10 万个手机号码,希望将这 10 万个手机号码从小到大排序,你有什么比较快速的排序方法呢?
这十一位的数,桶一个我看看?你桶,你给我桶
不好分桶吧,跨度太大了。
我们可以用这样一种方法:
先用第一位来进行排序,然后第二位,第三位,··· ,第十一位。
根据每一位来排序,我们可以用刚讲过的桶排序或者计数排序,它们的时间复杂度可以做到 O(n)。如果要排序的数据有 k 位,那我们就需要 k 次桶排序或者计数排序,总的时间复杂度是 O(k*n)。当 k 不大的时候,比如手机号码排序的例子,k 最大就是 11,所以基数排序的时间复杂度就近似于 O(n)。
但是,耗桶。
实际上,有时候要排序的数据并不都是等长的
比如下面排这三个数,因为他们是十进制的得用十个桶。
燕山大学胡帅涛画的下面的图,在此表示感谢,大佬就是牛,出了问题我不愁;大佬就是棒,一天一个新花样

以上是关于场景应用:100亿的数据你怎么排序?昂??你怎么排序啊?你别愣着啊,你说啊?!!!!的主要内容,如果未能解决你的问题,请参考以下文章