Python爬虫第二课 网络编程基础
Posted 笔触狂放
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫第二课 网络编程基础相关的知识,希望对你有一定的参考价值。
2.1 认识Python网络编程
套接字(socket)
网络上的两个程序通过一个双向的通信连接实现数据的交换,这个连接的一端称为一个socket。
套接字是socket的通常叫法,用于描述IP地址和端口,是一个通信链的句柄,可以用来实现不同虚拟机或不同计算机之间的通信。
Python中Socket库为操作系统的socket实现提供了一个Python接口。
1. socket协议类型
socket库中整合了多种协议类型。
| socket协议类型 | 描述 |
|---|---|
| socket.AF_UNIX | 用于同一台机器上的进程通信(本地通信) |
| socket.AF_INET | 用于服务器与服务器之间的网络通信 |
| socket.AF_INET6 | 基于IPV6方式的服务器与服务器之间的网络通信 |
| socket.SOCK_STREAM | 基于TCP的流式socket通信 |
| socket.SOCK_DGRAM | 基于UDP的数据报式socket通信 |
| socket.SOCK_RAW | 原始套接字,普通的套接字无法处理ICMP、IGMP等网络报文,而SOCK_RAW可以;其次SOCK_RAW也可以处理特殊的IPV4报文;此外,利用原始套接字,可以通过IP_HDRINCL套接字选项由用户构造IP头 |
| socket.SOCK_SEQPACKET | 可靠的连续数据包服务 |
2. socket函数
服务器端Socket函数:socket库中的服务器端函数仅供服务器使用。
| 语法格式 | 描述 |
|---|---|
| socket.bind(address) | 将套接字绑定到地址,在AF_INET协议下,以tuple(host,port)的方式传入,如socket.bind((host,port)),其中host为绑定的地址,port为监听的端口 |
| socket.listen(backlog) | 开始监听TCP传入连接,backlog指定在拒绝链接前,操作系统可以挂起的最大连接数,该值最少为1,大部分应用程序通常设为5 |
| socket.accept() | 接受TCP链接并返回(conn,address),其中conn是新的套接字对象,可以用来接收和发送数据,address是链接客户端的地址 |
客户端Socket函数:socket库中的客户端函数仅供客户端使用。
| 语法格式 | 描述 |
|---|---|
| socket.connect(address) | 连接到address处的套接字,一般address的格式为tuple(host,port),若连接出错,则返回socket.error错误 |
| socket.connect_ex(address) | 功能与socket.connect相同,但成功返回0,失败返回error的值 |
公共Socket函数:socket库中的公共函数即可在服务器端使用也可在客户端使用,为通用函数。
| 语法格式 | 描述 |
|---|---|
| socket.recv(buffsize[,flag]) | 接受TCP套接字的数据,数据以字符串形式返回,buffsize指定要接受的最大数据量,flag提供有关消息的其他信息,通常可以忽略 |
| socket.send(string[,flag]) | 发送TCP数据,将字符串中的数据发送到链接的套接字,返回值是要发送的字节数量,该数量可能小于string的字节大小 |
| socket.sendall(string[,flag]) | 完整发送TCP数据,将字符串中的数据发送到链接的套接字,但在返回之前尝试发送所有数据。成功返回None,失败则抛出异常 |
| socket.recvfrom(bufsize[,flag]) | 接受UDP套接字的数据,与recv函数类似,但返回值是tuple(data,address)。其中data是包含接受数据的字符串,address是发送数据的套接字地址 |
| socket.sendto(string[,flag],address) | 发送UDP数据,将数据发送到套接字,address形式为tuple(ipaddr,port),指定远程地址发送,返回值是发送的字节数 |
| socket.close() | 关闭套接字 |
| 语法格式 | 描述 |
|---|---|
| socket.getpeername() | 返回套接字的远程地址,返回值通常是一个tuple(ipaddr,port) |
| socket.getsockname() | 返回套接字自己的地址,返回值通常是一个tuple(ipaddr,port) |
| socket.setsockopt(level,optname,value) | 设置给定套接字选项的值 |
| socket.getsockopt(level,optname[,buflen]) | 返回套接字选项的值 |
| 语法格式 | 描述 |
|---|---|
| socket.settimeout(timeout) | 设置套接字操作的超时时间,timeout是一个浮点数,单位是秒,值为None时表示永远不会超时。超时时间应在刚创建套接字时设置,因为它们可能用于连接的操作,如s.connect() |
| socket.gettimeout() | 返回当前超时值,单位是秒,如果没有设置超时则返回None |
| socket.fileno() | 返回套接字的文件描述 |
| socket.makefile() | 创建一个与该套接字相关的文件 |
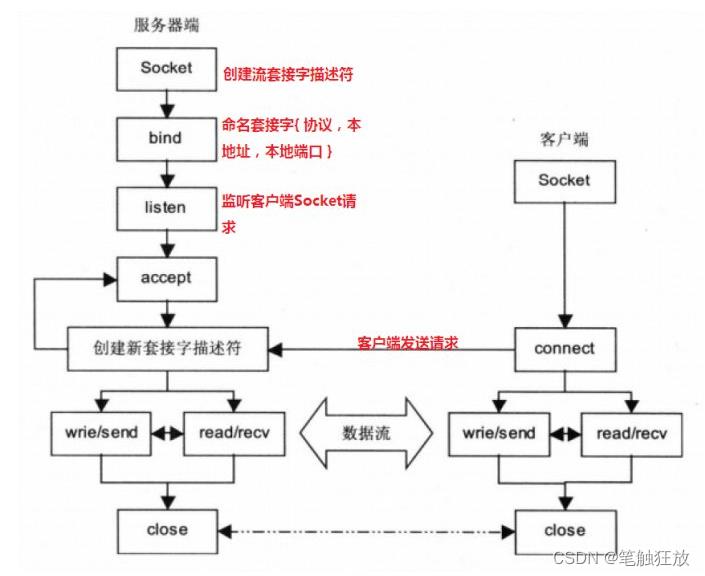
使用Socket进行TCP编程
TCP连接由客户端发起,服务器对连接进行响应。
建立一个服务器,服务器进程需要绑定一个端口并监听来自其他客户端的连接。
若有客户端发起连接请求,服务器就与该客户端建立Socket连接,随后的通信就通过此Socket连接进行。
服务器依赖服务器地址,服务器端口,客户端地址,客户端端口这4项来唯一确定一个Socket连接。

1. 服务器端TCP连接
建立服务器端的TCP连接,具体步骤如下。
在Python中创建一个基于IPv4和TCP协议的Socket.
IntentPY1.py
# scoket的认识和学习
import socket
import threading
import time
# 建立tcp连接
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)绑定监听的地址和端口,地址使用本机地址“127.0.0.1”或“local host”,使用大于1024的端口。
# 绑定地址及监听端口
s.bind("127.0.0.1",6666)调用listen方法开始监听端口,传入的参数指定等待连接的最大数量,设定为5。
# 添加监听器,设置最大允许连接的数量
s.listen(5)
# 打印等待客户端连接
print("Wait for connection……")创建一个tcp函数,该函数在连接建立后,服务器端首先发出一条表示连接成功的消息,然后等待客户端数据,再加上欢迎信息发送给客户端。若客户端发送exit字符串,则直接关闭连接。
# 创建服务器端应答函数
def tcp(sock,addr):
print("Accept new connection from %s:%s……"%addr)
sock.send(b"Success!")
while True:
data=sock.recv(1024)
time.sleep(1)
if not data or data.decode("UTF-8") == "exit":
break
sock.send(("Welcome! %s"%data.decode("UTF-8")).encode("UTF-8"))
sock.close()
print("Connection from %s:%s closed."%addr)通过一个循环接受来自客户端的连接,使用accept函数等待并返回一个客户端的连接,每个连接都分配一个新线程来处理。
# 循环处理客户端连接
while True:
# 接受来自客户端的新连接:
sock, addr = s.accept()
# 创建新线程来处理TCP连接:
t = threading.Thread(target=tcp,args = (sock, addr))
t.start()2. 客户端TCP连接
在服务器端TCP连接建立后,建立客户端TCP连接进行测试,具体步骤如下。
与服务器端的协议保持一致,也建立一个基于IPv4和TCP协议的Socket。
与服务器端建立连接,连接的地址与端口需与服务器端保持一致。
使用recv函数接受服务器提示信息,之后再使用send函数发送数据至服务器,可看到服务器返回的结果。
IntentPY2.py
# 导入socket库
import socket
# 建立TCP连接
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 与服务器建立连接
s.connect(('127.0.0.1', 6666))
# 接受服务器的连接成功提示信息
print(s.recv(1024).decode('utf-8'))
# 发送数据并接受服务器返回结果
for data in [b'Tom', b'Jerry', b'Spike']:
s.send(data)
print(s.recv(1024).decode('utf-8'))
# 发送退出信息断开连接
s.send(b'exit')
s.close()
使用Socket进行UDP编程
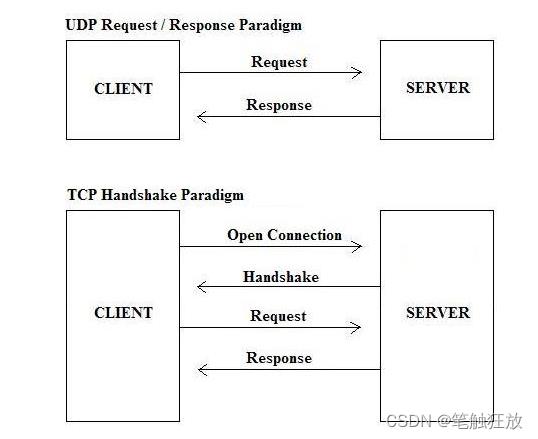
TCP建立的连接可靠,通信双方以流的形式互相传送数据。相对TCP协议,UDP则是面向无连接的协议。
使用UDP协议时,无需建立连接的过程,仅需知道对方的IP地址及端口号,便可直接发送数据包,但无法保证能顺利传达到。
虽然用UDP传输数据不可靠,但其传输速度比TCP快,对于不要求可靠到达的数据,就可以使用UDP协议。
UDP传输通常应用在通讯实时性要求更高于可靠性场景,例如网络游戏。
1. 服务器端UDP连接
UDP连接与TCP连接类似,也分为服务器端和客户端,不同的是UDP连接无需调用listen方法,直接接受来自任何客户端的数据。
建立UDP连接,服务器端同样需要绑定地址与端口。
使用recvfrom方法返回数据及客户端的地址与端口。
当服务器收到数据后,直接调用sendto把数据用UDP发给客户端。
IntentPy3.py
# 导入socket库
import socket
# 建立UDP连接
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# 绑定地址与端口
s.bind(('127.0.0.1', 6666))
print('set UDP on 6666...')
while True:
# 接收来自任意客户端的数据:
data, addr = s.recvfrom(1024)
# 打印接受信息并回传欢迎信息
print('Received from %s:%s.' % addr)
s.sendto(b'Welcom! %s!' % data, addr)2. 客户端UDP连接
客户端使用UDP连接时同样需要先创建socket。
之后无需使用connect方法,直接用sendto方法发送数据至服务器建立UDP连接,服务器端同样需要绑定地址与端口。
UDP连接与TCP连接可同时使用同一端口互不冲突,两者使用的端口是独立绑定的。
IntentPy4.py
# 导入socket库
import socket
# 建立UDP连接
s = socket.socket(socket.AF_INET, socket. SOCK_DGRAM)
# 发送数据并接受服务器回传数据
for data in [b'Tom', b'Jerry', b'Spike']:
s.sendto(data,("127.0.0.1",6666))
print(s.recv(1024).decode('utf-8'))
s.close()
2.2 认识Http协议
HTTP请求方式与过程
爬虫在爬取数据时将会作为客户端模拟整个HTTP通信过程,该过程也需要通过HTTP协议实现。HTTP请求过程如下。
由HTTP客户端向服务器发起一个请求,创建一个到服务器指定端口(默认是80端口)的TCP连接。
HTTP服务器从该端口监听客户端的请求。
一旦收到请求,服务器会向客户端返回一个状态,比如“HTTP/1.1 200 OK”,以及返回的响应内容,如请求的文件、错误消息、或其它信息。
1. 请求方法
在HTTP/1.1协议中共定义了8种方法(也叫“动作”)来以不同方式操作指定的资源,常用方法有GET、HEAD、POST等。
| 请求方法 | 方法描述 |
|---|---|
| GET | 请求指定的页面信息,并返回实体主体。GET可能会被网络爬虫等随意访问,因此GET方法应该只用在读取数据,而不应当被用于产生“副作用”的操作中,例如在Web Application中 |
| HEAD | 与GET方法一样,都是向服务器发出指定资源的请求。只不过服务器将不传回具体的内容,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中该资源的相关信息(元信息或称元数据) |
| POST | 向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据会被包含在请求中,这个请求可能会创建新的资源或修改现有资源,或二者皆有 |
| PUT | 从客户端上传指定资源的最新内容,即更新服务器端的指定资源。 |
2. 请求(request)与响应(response)
HTTP协议采用了请求/响应模型。
客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。
服务器以一个状态行作为响应,响应的内容包括协议的版本、响应状态、服务器信息、响应头部和响应数据。
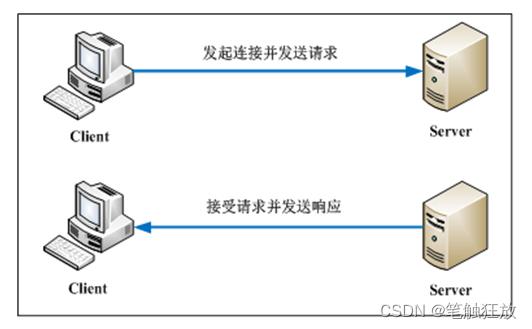
客户端与服务器间的请求与响应的具体步骤如下。
连接Web服务器:由一个HTTP客户端发起连接,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。
发送HTTP请求:客户端经TCP套接字向Web服务器发送一个文本的请求报文。
服务器接受请求并返回HTTP响应:Web服务器解析请求,定位该次的请求资源。之后将资源复本写至TCP套接字,由客户端进行读取。
释放连接TCP连接:若连接的connection模式为close,则由服务器主动关闭TCP连接,客户端将被动关闭连接,释放TCP连接;若connection模式为keepalive,则该连接会保持一段时间。
客户端解析HTML内容:客户端首先会对状态行进行解析,之后解析每一个响应头,最后读取响应数据。
常见HTTP状态码
1. HTTP状态码种类
HTTP状态码是用来表示网页服务器响应状态的3位数字代码,按首位数字分为5类状态码。
| 状态码类型 | 状态码意义 |
|---|---|
| 1XX | 表示请求已被接受,需接后续处理。这类响应是临时响应,只包含状态行和某些可选的响应头信息,并以空行结束 |
| 2XX | 表示请求已成功被服务器接收、理解并接受 |
| 3XX | 表示需要客户端采取进一步的操作才能完成请求。通常用来重定向,重定向目标需在本次响应中指明 |
| 4XX | 表示客户端可能发生了错误,妨碍了服务器的处理。 |
| 5XX | 表示服务器在处理请求的过程中有错误或者异常状态发生,也有可能是服务器以当前的软硬件资源无法完成对请求的处理。 |
HTTP状态码共有67种状态码,常见的状态码如下。
| 常见状态码 | 状态码含义 |
|---|---|
| 200 OK | 请求成功,请求所希望的响应头或数据体将随此响应返回。 |
| 400 Bad Request | 由于客户端的语法错误、无效的请求或欺骗性路由请求,服务器不会处理该请求 |
| 403 Forbidden | 服务器已经理解该请求,但是拒绝执行,将在返回的实体内描述拒绝的原因,也可以不描述仅返回404响应 |
| 404 Not Found | 请求失败,请求所希望得到的资源未被在服务器上发现,但允许用户的后续请求 |
| 500 Internal Server Error | 通用错误消息,服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理,不会给出具体错误信息 |
| 503 Service Unavailable | 由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是暂时的,并且将在一段时间以后恢复 |
HTTP头部信息(HTTP header fields)是指在超文本传输协议(HTTP)的请求和响应消息中的消息头部分。头部信息定义了一个超文本传输协议事务中的操作参数。在爬虫中需要使用头部信息向服务器发送模拟信息,通过发送模拟的头部信息将自己伪装成一般的客户端。


HTTP头部信息
1. HTTP头部类型
HTTP头部类型按用途可分为:通用头,请求头,响应头,实体头。
通用头:既适用于客户端的请求头,也适用于服务端的响应头。与HTTP消息体内最终传输的数据是无关的,只适用于要发送的消息。
请求头:提供更为精确的描述信息,其对象为所请求的资源或请求本身。新版HTTP增加的请求头不能在更低版本的HTTP中使用,但服务器和客户端若都能对相关头进行处理,则可以在请求中使用。
响应头:为响应消息提供了更多信息。例如,关于资源位置的描述Location字段,以及关于服务器本身的描述使用Server字段等。与请求头类似,新版增加的响应头也不能在更低版本的HTTP版本中使用。
实体头:提供了关于消息体的描述。如消息体的长度Content-Length,消息体的MIME类型Content-Type。新版的实体头可以在更低版本的HTTP版本中使用。
| 字段名 | 说明 | 示例 |
|---|---|---|
| Accept | 可接受的响应内容类型(Content-Types) | Accept: text/plain |
| Accept-Charset | 可接受的字符集 | Accept-Charset:utf-8 |
| Accept-Encoding | 可接受的响应内容的编码方式 | Accept-Encoding:gzip,deflate |
| Accept-Language | 可接受的响应内容语言列表 | Accept-Language:en-US |
| Cookie | 由之前服务器通过Set-Cookie设置的一个HTTP协议Cookie | Cookie:$Version=1;Skin=new; |
| Referer | 设置前一个页面的地址,并且前一个页面中的连接指向当前请求,意思就是如果当前请求是在A页面中发送的,那么referer就是A页面的url地址 | Referer:http://zh.wikipedia.org/wiki/Main_Page |
| User-Agent | 用户代理的字符串值 | User-Agent:Mozilla/5.0(X11;Linuxx86_64;rv:12.0)Gecko/20100101Firefox/21.0 |
熟悉Cookie
HTTP是一种无状态的协议,客户端与服务器建立连接并传输数据,在数据传输完成后,本次的连接将会关闭,并不会留存相关记录。
服务器无法依据连接来跟踪会话,也无法从连接上知晓用户的历史操作。这严重阻碍了基于Web应用程序的交互,也影响用户的交互体验。
某些网站需要用户登录才进一步操作,用户在输入账号密码登录后,才能浏览页面。对于服务器而言,由于HTTP的无状态性,服务器并不知道用户有没有登录过,当用户退出当前页面访问其他页面时,又需重新再次输入账号及密码。
1. Cookie机制
为解决HTTP的无状态性带来的负面作用,Cookie机制应运而生。Cookie本质上是一段文本信息。
当客户端请求服务器时,若服务器需要记录用户状态,就在响应用户请求时发送一段Cookie信息。
客户端浏览器会保存该Cookie信息,当用户再次访问该网站时,浏览器会把Cookie做为请求信息的一部分提交给服务器。
服务器对Cookie进行验证,以此来判断用户状态,当且仅当该Cookie合法且未过期时,用户才可直接登录网站。
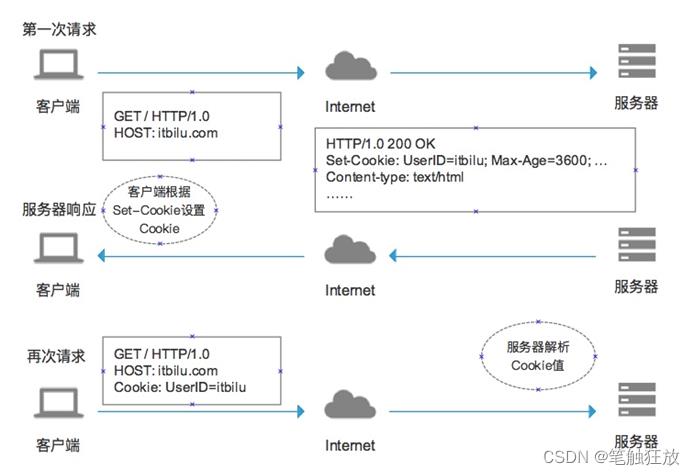
2. Cookie的存储方式
Cookie由用户客户端浏览器进行保存,按其存储位置可分为内存式存储和硬盘式存储。
内存式存储将Cookie保存在内存中,在浏览器关闭后就会消失,由于其存储时间较短,因此也被称为非持久Cookie或会话Cookie。
硬盘式存储将Cookie保存在硬盘中,其不会随浏览器的关闭而消失,除非用户手工清理或到了过期时间。由于硬盘式Cookie存储时间是长期的,因此也被称为持久Cookie。

3. Cookie的实现过程
客户端与服务器间的Cookie实现过程的具体步骤如下。
客户端请求服务器:客户端请求网站页面
服务器响应请求:Cookie是一种字符串,为key=value形式,服务器需要记录这个客户端请求的状态,在响应头中增加一个Set-Cookie字段。
客户端再次请求服务器:
客户端会对服务器响应的Set-Cookie头信息进行存储。
当再次请求时,将会在请求头中包含服务器响应的Cookie信息。

小结
本章介绍了Python中的底层Socket库,及运用socket库建立TCP和UDP连接。并对超文本传输协议(HTTP)及其相关机制进行了简要介绍。对本章做小结如下。
Socket库提供多种协议类型和函数,可用于建立TCP和UDP连接。
HTTP协议基于TCP协议进行客户端与服务器间的通讯,由客户端发起请求,服务器进行应答。
HTTP状态码由3位数字构成,按首位数字可分为5类状态码。
HTTP头部信息为HTTP协议的请求与响应消息中的消息头部分,其定义了该次传输事务中的操作参数。
Cookie机制可记录用户状态,
服务器可依据Cookie对用户状态进行记录与识别。
以上是关于Python爬虫第二课 网络编程基础的主要内容,如果未能解决你的问题,请参考以下文章