CS224N WINTER 2022词向量(附Assignment1答案)
Posted 囚生CY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CS224N WINTER 2022词向量(附Assignment1答案)相关的知识,希望对你有一定的参考价值。
CS224N WINTER 2022(一)词向量(附Assignment1答案)
CS224N WINTER 2022(二)反向传播、神经网络、依存分析(附Assignment2答案)
CS224N WINTER 2022(三)RNN、语言模型、梯度消失与梯度爆炸(附Assignment3答案)
CS224N WINTER 2022(四)机器翻译、注意力机制、subword模型(附Assignment4答案)
CS224N WINTER 2022(五)Transformers详解(附Assignment5答案)
序言
-
CS224N WINTER 2022课件可从https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1224/下载,也可从下面网盘中获取:
https://pan.baidu.com/s/1LDD1H3X3RS5wYuhpIeJOkA 提取码: hpu3本系列博客每个小节的开头也会提供该小结对应课件的下载链接。
-
课件、作业答案、学习笔记(Updating):GitHub@cs224n-winter-2022
-
关于本系列博客内容的说明:
-
笔者根据自己的情况记录较为有用的知识点,并加以少量见解或拓展延申,并非slide内容的完整笔注;
-
CS224N WINTER 2022共计五次作业,笔者提供自己完成的参考答案,不担保其正确性;
-
由于CSDN限制博客字数,笔者无法将完整内容发表于一篇博客内,只能分篇发布,可从我的GitHub Repository中获取完整笔记,本系列其他分篇博客发布于(Updating):
CS224N WINTER 2022(一)词向量(附Assignment1答案)
CS224N WINTER 2022(二)反向传播、神经网络、依存分析(附Assignment2答案)
CS224N WINTER 2022(三)RNN、语言模型、梯度消失与梯度爆炸(附Assignment3答案)
-
文章目录
lecture 1 词向量
slides
[slides]
-
以WordNet为例的词库存在的缺陷:slides p.15
-
难以辨别单词间细微差别:同义词列表缺少适当性语境范围标注。
-
缺失单词的最新含义;
-
编纂具有主观性;
-
需要耗费人力进行更新与应用;
-
难以应用于精确计算单词相似度;
-
-
分布语义学(Distributional semantics):slides p.18
单词含义可由频繁出现在其附近的单词推定,即通过上下文语境来建模单词表示。
-
Word2Vec(2013年)词向量1模型的思想:slides p.21
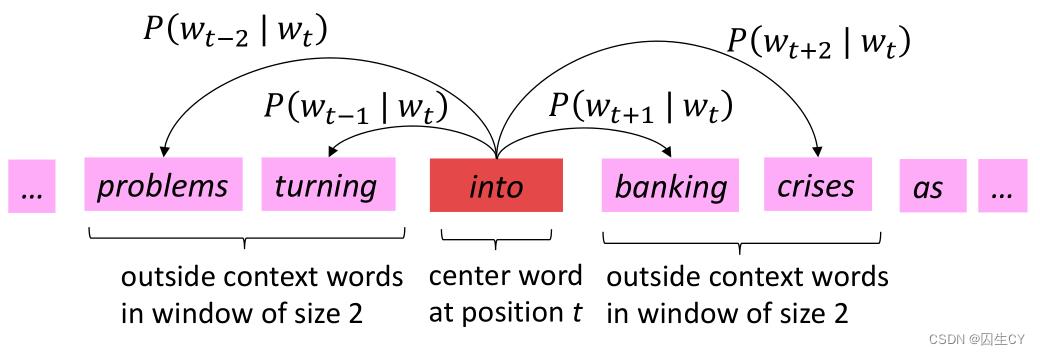
-
已有目标语言的足量语料库与给定的词汇表;
-
目的是将给定词汇表中的每个单词表示为一个向量;
-
对于语料库的每一个单词 c c c(称为中心词),获取其上下文语境 o o o(若干语境词构成);
-
使用单词 c c c的词向量与语境 o o o中各个单词的词向量的相似度来计算在给定 c c c的条件下出现 o o o的概率(或反过来在给定 o o o的条件下出现 c c c的概率,即mask的思想);
-
不断调整词向量使得④中的条件概率尽可能的大;
-
-
Word2Vec模型的目标函数:slides p.25
minimize u w i , v w i i = 1 ∣ v ∣ J ( θ ) = − 1 T ∑ t = 1 T ∑ − m ≤ j ≤ m , j ≠ 0 log P ( w t + j ∣ w t ; θ ) (1.1) \\textminimize_\\u_w_i,v_w_i\\_i=1^|v|\\quad J(\\theta)=-\\frac1T\\sum_t=1^T\\sum_-m\\le j\\le m,j\\neq0\\log P(w_t+j|w_t;\\theta)\\tag1.1 minimizeuwi,vwii=1∣v∣J(θ)=−T1t=1∑T−m≤j≤m,j=0∑logP(wt+j∣wt;θ)(1.1)其中概率 P P P(称为预测函数)的计算方式如下:
P ( o ∣ c ) = exp ( u o ⊤ v c ) ∑ w ∈ V exp ( u w ⊤ v c ) (1.2) P(o|c)=\\frac\\exp(u_o^\\top v_c)\\sum_w\\in V\\exp(u_w^\\top v_c)\\tag1.2 P(o∣c)=∑w∈Vexp(uw⊤vc)exp(uo⊤vc)(1.2)
根据assignment2中的说法,这个结果可以理解为是真实的单词概率分布 y y y向量与预测的单词概率分布 y ^ \\hat y y^向量之间的交叉熵。
式中变量说明:
① T T T表示语料库规模(即文本长度);
② V V V表示词汇表;
③ m m m表示上下文窗口大小;
④ w i w_i wi表示在第 i i i个位置上的单词;
⑤ v w v_w vw表示单词 w w w作为中心词的词向量;
⑥ u w u_w uw表示单词 w w w作为语境词的词向量;
⑦ θ \\theta θ表示超参数;
Word2Vec模型中每个单词都有两个词向量,最终将两个词向量取均值作为模型输出的词向量。
因此式 ( 1.1 ) (1.1) (1.1)中决策变量总数为 2 d ∣ V ∣ 2d|V| 2d∣V∣,其中 d d d为给定的词向量嵌入维度。
由于变量数量非常多,因此通常选择随机梯度下降法求解Word2Vec模型。
-
Word2Vec模型预测函数偏导结果的重要意义:slides p.29-32
∂ P ( o ∣ c ) ∂ v c = ∂ ∂ v c log exp ( u o ⊤ v c ) ∑ w ∈ V exp ( u w ⊤ v c ) = ∂ ∂ v c log exp ( u o ⊤ v c ) − ∂ ∂ v c log ( ∑ w ∈ V exp ( u w ⊤ v c ) ) = ∂ ∂ v c u o ⊤ v c − 1 ∑ w ∈ V exp ( u w ⊤ v c ) ⋅ ∂ ∂ v c ∑ x ∈ V exp ( u x ⊤ v c ) = u o − 1 ∑ w ∈ V exp ( u w ⊤ v c ) ⋅ ∑ x ∈ V ∂ ∂ v c exp ( u x ⊤ v c ) = u o − 1 ∑ w ∈ V exp ( u w ⊤ v c ) ⋅ ∑ x ∈ V exp ( u x ⊤ v c ) ∂ ∂ v c u x ⊤ v c = u o − 1 ∑ w ∈ V exp ( u w ⊤ v c ) ∑ x ∈ V exp ( u x ⊤ v c ) u x = u o − ∑ x ∈ V exp ( u x ⊤ v c ) ∑ w ∈ V exp ( u以上是关于CS224N WINTER 2022词向量(附Assignment1答案)的主要内容,如果未能解决你的问题,请参考以下文章