ES 搜索引擎
Posted 上官玺
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ES 搜索引擎相关的知识,希望对你有一定的参考价值。
ES 搜索引擎
查询文档
基本语法
GET /索引库名/_search
"query":
"查询类型":
"查询条件":"查询条件值"
这里的query代表一个查询对象,里面可以有不同的查询属性,ES提供了基于JSON的DSL来定义查询。常见的查询类型包括:
- 查询所有:查询出所有数据,一般测试用。例如:match_all
- 全文检索:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:match_query、multi_match_query
- 精确查询:根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段。例如:term、range
- 地理查询:根据经纬度查询。例如:geo_distance、geo_bounding_box
- 复合查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:bool、function_score
#查询所有
GET /hotel/_search
"query":
"match_all":
效果:
"took" : 1, //查询花费时间,单位是毫秒
"timed_out" : false, //是否超时
"_shards" : //分片信息
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
,
"hits" : //搜索结果
"total" : //搜索到的总条数
"value" : 201,
"relation" : "eq"
,
"max_score" : 1.0, //所有结果中文档得分的最高分
"hits" : [ //搜索结果的文档对象数组,每个元素是一条搜索到的文档信息
"_index" : "hotel",
"_type" : "_doc",
"_id" : "36934",
"_score" : 1.0,
"_source" :
"address" : "静安交通路40号",
"brand" : "7天酒店",
"business" : "四川北路商业区",
"city" : "上海",
"id" : 36934,
"location" : "31.251433, 121.47522",
"name" : "7天连锁酒店(上海宝山路地铁站店)",
"pic" : "https://m.tuniucdn.com/fb2/t1/G1/M00/3E/40/Cii9EVkyLrKIXo1vAAHgrxo_pUcAALcKQLD688AAeDH564_w200_h200_c1_t0.jpg",
"price" : 336,
"score" : 37,
"starName" : "二钻"
,
//省略..........
]
全文检索
- 对用户搜索的内容做分词,得到词条
- 根据词条去倒排索引库中匹配,得到文档id
- 根据文档id找到文档,返回给用户
match
match查询:全文检索查询的一种,会对用户输入内容分词,然后去倒排索引库检索,语法:
#match 倒排索引库查询
GET /hotel/_search
"query":
"match":
"all": "外滩如家"
效果:
"took" : 3,
"timed_out" : false,
"_shards" :
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
,
"hits" :
"total" :
"value" : 32,
"relation" : "eq"
,
"max_score" : 5.920452,
"hits" : [
"_index" : "hotel",
"_type" : "_doc",
"_id" : "434082",
"_score" : 5.920452,
"_source" :
"address" : "复兴东路260号",
"brand" : "如家",
"business" : "豫园地区",
"city" : "上海",
"id" : 434082,
"location" : "31.220706, 121.498769",
"name" : "如家酒店·neo(上海外滩城隍庙小南门地铁站店)",
"pic" : "https://m.tuniucdn.com/fb2/t1/G6/M00/52/B6/Cii-U13eXLGIdHFzAAIG-5cEwDEAAGRfQNNIV0AAgcT627_w200_h200_c1_t0.jpg",
"price" : 392,
"score" : 44,
"starName" : "二钻"
,
multi_match
multi_match:与match查询类似,只不过允许同时查询多个字段,
语法:
GET /hotel/_search
"query":
"multi_match":
"query": "",
"fields": ["field1","field2"]
示例:
GET /hotel/_search
"query":
"multi_match":
"query": "外滩如家",
"fields": ["name","business","brand"]
效果:
"took" : 9,
"timed_out" : false,
"_shards" :
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
,
"hits" :
"total" :
"value" : 32,
"relation" : "eq"
,
"max_score" : 4.620212,
"hits" : [
"_index" : "hotel",
"_type" : "_doc",
"_id" : "434082",
"_score" : 4.620212,
"_source" :
"address" : "复兴东路260号",
"brand" : "如家",
"business" : "豫园地区",
"city" : "上海",
"id" : 434082,
"location" : "31.220706, 121.498769",
"name" : "如家酒店·neo(上海外滩城隍庙小南门地铁站店)",
"pic" : "https://m.tuniucdn.com/fb2/t1/G6/M00/52/B6/Cii-U13eXLGIdHFzAAIG-5cEwDEAAGRfQNNIV0AAgcT627_w200_h200_c1_t0.jpg",
"price" : 392,
"score" : 44,
"starName" : "二钻"
,
可以看到,match和multi_match两种查询结果是一样的是因为我们将brand、name、business值都利用copy_to复制到了all字段中,虽然效果一样但是 搜索字段越多,对查询性能影响越大,因此建议采用copy_to,然后单字段查询的方式。
精准查询
精确查询一般是查找keyword、数值、日期、boolean等类型字段,它不会对搜索条件分词。常见的有:
- term:根据词条精确匹配,一般搜索keyword类型、数值类型、布尔类型、日期类型字段
- range:根据数值范围查询,可以是数值、日期的范围
term
term: 根据词条进行精确查询,查询过程中不会对词条进行分词处理
语法:
#精确查询
GET /hotel/_search
"query":
"term":
"FIELD":
"value": "VALUE"
示例:
GET /hotel/_search
"query":
"term":
"city":
"value": "北京"
range
范围查找
语法:
GET /indexName/_search
"query":
"range":
"FIELD":
"gte": 10, // 这里的gte代表大于等于,gt则代表大于
"lte": 20 // lte代表小于等于,lt则代表小于
示例:
GET /hotel/_search
"query":
"range":
"price":
"gte": 1000,
"lte": 2000
地理查询
应用场景:根据经纬度查询常见场景包括:
携程:搜索附近的九点
滴滴:搜索附近的出租车
geo_bounding_box 矩形范围
矩形范围查询,也就是geo_bounding_box查询,查询坐标落在某个矩形范围的所有文档
查询时,需要指定矩形的左上、右下两个点的坐标,然后画出一个矩形,落在该矩形内的都是符合条件的点。
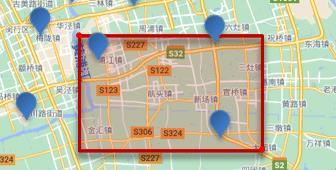
获取坐标请点击这里!
语法:
"query":
"geo_bounding_box":
"location":
"top_left": //左上坐标
"lat": 40.08,
"lon": 116.47
,
"bottom_right": //右下坐标
"lat":39.9,
"lon":116.405
geo_distance 圆形范围
附近查询,也叫做距离查询(geo_distance):查询到指定中心点小于某个距离值的所有文档。
也就是说在地图上找一个点作为圆心,以指定距离为半径,画一个圆,落在圆内的坐标都算符合条件
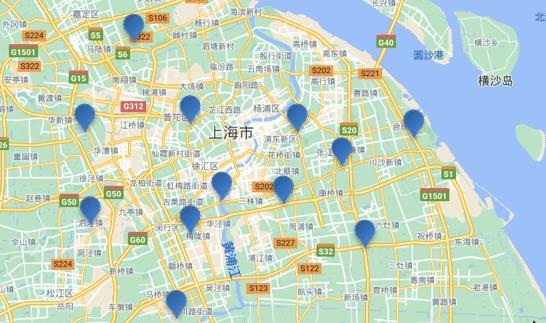
语法:
GET /hotel/_search
"query":
"geo_distance":
"distance":"15km", // 半径
"location":"39.9,116.405" // 圆心 这个坐标是天安门
fuction_score 算分函数
fuction_score:算分函数查询,可以控制文档相关性算分,控制文档排名
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列
例如,我们搜索 "虹桥如家",结果如下:
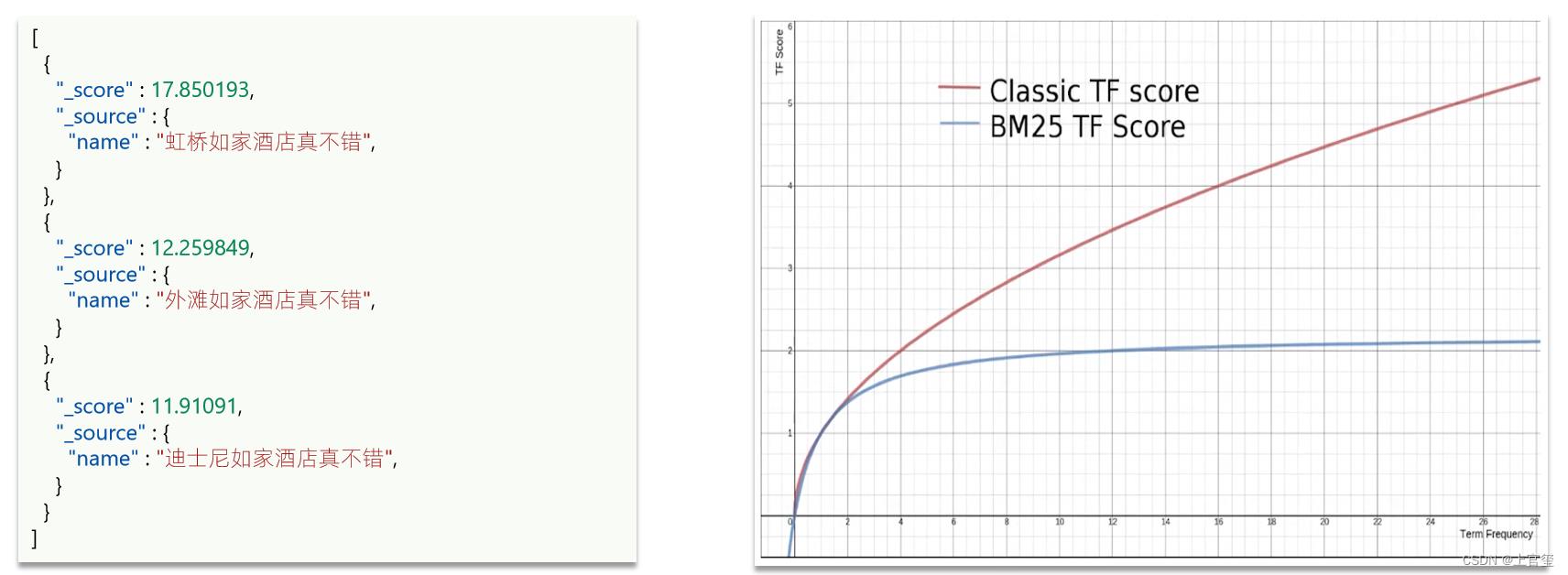
elasticsearch会根据词条和文档的相关度做打分,算法由两种:
- TF-IDF算法
- BM25算法,elasticsearch5.1版本后采用的算法
算分函数查询
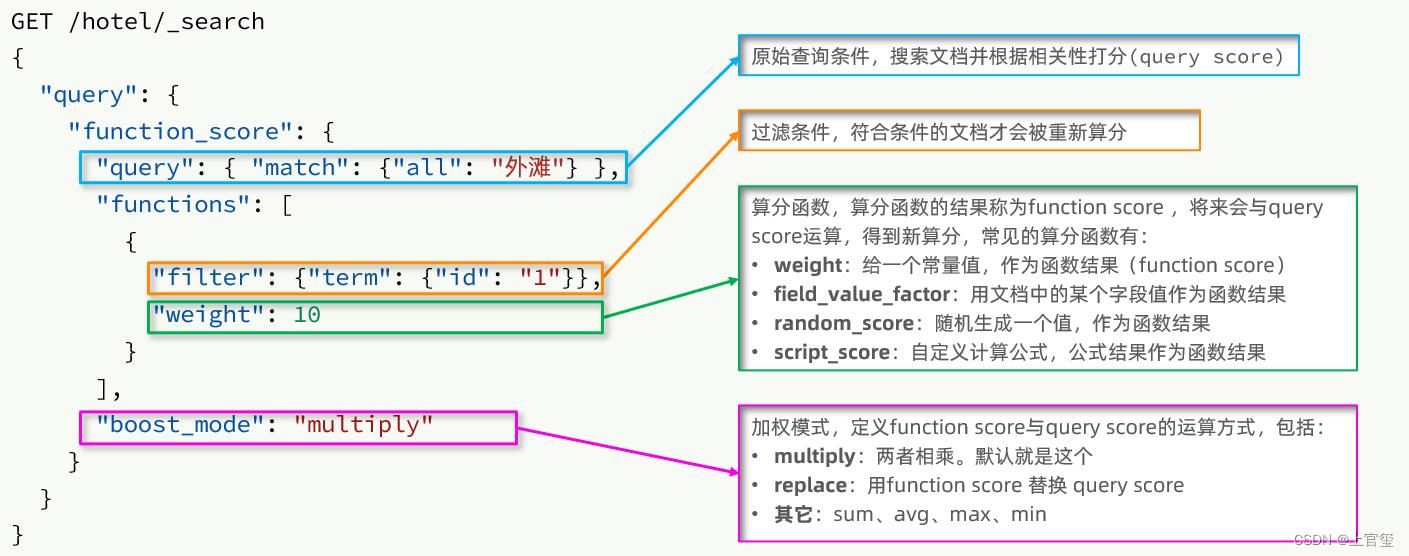
算分函数关键点是:
- 过滤条件:决定哪些文档的算分被修改
- 算分函数:决定函数算分的算法
- 运算模式:决定最终算分结果
示例:
# 默认查询
GET /hotel/_search
"query":
"match":
"all": "北京"
# 算法函数查询
GET /hotel/_search
"query":
"function_score":
"query":
"match":
"all": "北京"
,
"functions": [
"filter":
"term":
"brand": "凯悦"
,
"weight": 10
],
"boost_mode": "multiply"
bool query 复合查询
bool query:复合查询,也称为布尔查询,它可以利用多种逻辑关系将多个查询条件组装在一起,然后实现复杂搜索
布尔查询是一个或多个查询子句的组合,每一个子句就是一个子查询。子查询的组合方式有:
-
must:必须匹配每个子查询,类似“与” and
-
should:选择性匹配子查询,类似“或” or
-
must_not:必须不匹配,不参与算分,类似“非” not
-
filter:必须匹配,不参与算分
搜索时,参与打分的字段越多,查询的性能也越差。因此这种多条件查询时,建议这样做: -
搜索框的关键字搜索,是全文检索查询,使用must查询,参与算分
-
其它过滤条件,采用filter查询。不参与算分
GET /hotel/_search
"query":
"bool":
"must": [
"term":
"name":
"value": "如家"
],
"must_not": [
"range":
"price":
"gte": 400
],
"filter": [
"geo_distance":
"distance": "10km",
"location":
"lat": 39.9,
"lon": 116.405
]
结果处理
排序
elasticsearch支持对搜索结果排序,默认是根据相关度算分(_score)来排序。
可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
普通字段排序
语法:
GET /hotel/_search
"query":
"match_all":
,
"sort": [
//语法一
"FIELD": //排序字段,排序方式 ASC,DESC
"order": "desc"
,
//语法二
"field": "desc" //排序字段,排序方式 ASC,DESC
]
示例:酒店数据按照用户评价(score)降序排序,评价相同的按照价格(price)升序排序
GET /hotel/_search
"query":
"match_all":
,
"sort": [
"score":
"order": "desc"
,
"price":
"order": "asc"
]
地理坐标排序
语法:
GET /indexName/_search
"query":
"match_all":
,
"sort": [
"_geo_distance" :
"FIELD" : "纬度,经度", // 文档中geo_point类型的字段名、目标坐标点
"order" : "asc" // 排序方式
]
获取经纬度点击这里
示例:假设我的位置是:31.034661,121.612282,寻找我周围距离最近的酒店。
GET /hotel/_search
"query":
"match_all":
,
"sort": [
"_geo_distance":
"location":
"lat": 39.909187,
"lon": 116.397455
,
"order": "asc"
]
分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。
elasticsearch中通过修改from、size参数来控制要返回的分页结果:
- from:从第几个文档开始
- size:总共查询几个文档
类似于mysql中的limit ?, ?
基本分页
语法:
GET /hotel/_search
"query":
"match_all":
,
"from":0, //分页开始的位置,默认为0
"size":10, //期望获取的文档总数
"sort":[
"price":"asc"
]
高亮
** 基本语法:**
GET /hotel/_search
"query":
"match":
"FIELD": "TEXT"
,
"highlight":
"fields": //指定要高亮的字段
"FIELD":
"pre_tags": "<em>", //标记高亮字段的前置标签
"post_tags": "</em>" //标记高亮字段的后置标签
示例:
# 查询字段跟高亮字段一致
GET /hotel/_search
"query":
"match":
"name": "如家"
,
"highlight":
"fields":
"name":
"pre_tags": "<em>",
"post_tags": "</em>"
# 查询字段跟高亮字段不一致
GET /hotel/_search
"query":
"match":
"all": "如家"
,
"highlight":
"fields":
"name":
"pre_tags": "<em>",
"post_tags": "</em>",
"require_field_match": "false"
以上是关于ES 搜索引擎的主要内容,如果未能解决你的问题,请参考以下文章