UDP协议详解
Posted 白杨783
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了UDP协议详解相关的知识,希望对你有一定的参考价值。
目录
UDP协议报文结构
 UDP会把载荷数据(也就是通过 UDP socekt,send方法拿来的数据基础上,再前面拼装(相当于字符串拼接此处是二进制的)上几个字节的报头
UDP会把载荷数据(也就是通过 UDP socekt,send方法拿来的数据基础上,再前面拼装(相当于字符串拼接此处是二进制的)上几个字节的报头
UDP报头里包含了一些特定的属性,这些属性携带了一些重要的信息
不同的协议,功能不同,报头中带有的属性信息就不同,对于UDP来说,报头一共8个字节,分成四个部分:源端口号,目的端口号,报文长度,校验和
端口号
端口号是传输层协议的概念,每个进程(程序)属于自己的端口号,起到的效果就是区分一个主机上具体的应用程序.因此我们要求同一个主机上,一个端口号不能被多个进程绑定
UDP协议中包含源端口号,和目的端口号,他们都是用2个字节,也就是16个bit位来表示的,因此这里的端口号的取值范围是0->65535,注意0->1023这个范围的端口,被称为"知名端口号/具体端口号",这些端口号都已经分配给了一些广泛使用的知名的应用程序了,因此我们自己写的程序绑定的端口号需要从1024开始
报文长度
报文长度也是由2个字节表示的,范围同样是0->65535,换算一下单位,也就是64KB.也就是说一个UDP数据报最多只能传输64KB的数据
如果我们需要传输的数据大于64KB怎么办呢?
1.需要在应用层,通过代码的方式针对应用层数据报进行手动的分包,拆成多个包,通过多个UDP数据报来进行传输(本来send一次,现在要send多次)
2.不用UDP协议,使用TCP协议
校验和
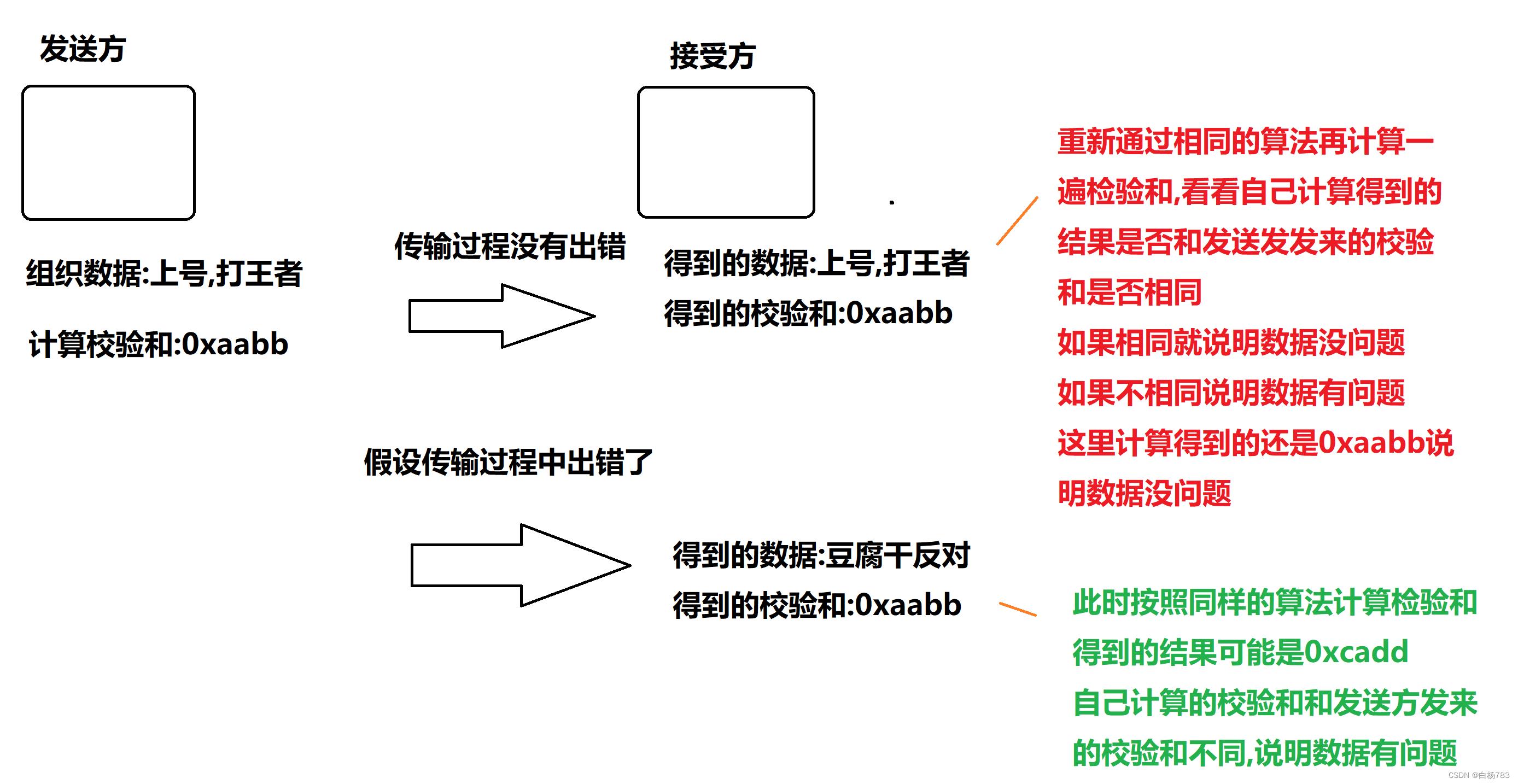
网络传输的本质是光信号/电信号,在传输过程中,可能会受到一些物理因素的影响,在这些干扰因素的影响下,可能会发生"比特翻转",也就是原来要传输二进制1,发生比特翻转,就变成了0,原来要传输二进制0,发生比特翻转,就变成了1,此时我们传输过后得到的数据就变了,数据的含义也就不同了,本来数据报是想开启功能,可能就变成了关闭功能了
这种现象是客观存在的,不可避免的,我们能做的就是在发生比特翻转,数据改变了的时候,能够及时的识别出当前的数据是否出现问题.
此时我们就需要校验和了,校验和的作用就是验证传输的数据是否是正确的
校验和是如何鉴别我们的数据是否出现了问题的呢?
检验和会针对数据内容进行一系列的数学运算,得到一个比较短的结果(比如2字节),如果数据内容一定,得到的校验和结果就一定,如果数据变了,得到的检验和也就变了
生成校验和的算法
1.CRC 循环冗余校验,把数据每个字节,循环往上累加,如果累加益处了,高位就不要了
2.MD5 有一系列公式,来进行更复杂的运算,最后得到一个定长的结果
MD5的特点
1.定长:无论原始数据有多长,得到的md5的值都是固定长度(4字节版本,也有8字节版本)
2.冲突概率小 原始数据哪怕变动一个地方,一个bit位,算出来的MD5天差地别(MD5让结果更分散了)
3.不可逆,通过原始数据计算出MD5很容易,但是想要通过MD5计算出原始数据非常难(计算量极大,理论上不可以完成)
4.可以用来计算校验和,也可以计算hash值,还可以当作一种加密方式
TCP/IP详解UDP用户数据报协议
UDP是一个简单的面向数据报的运输层协议:进程的每个输出操作都正好产生一个UDP数据报,并组成一份待发送的IP数据报。UDP提供了不可靠性:它把应用程序传给IP层的数据发送出去,但是并不保证它们能到达目的地。
【UDP首部】
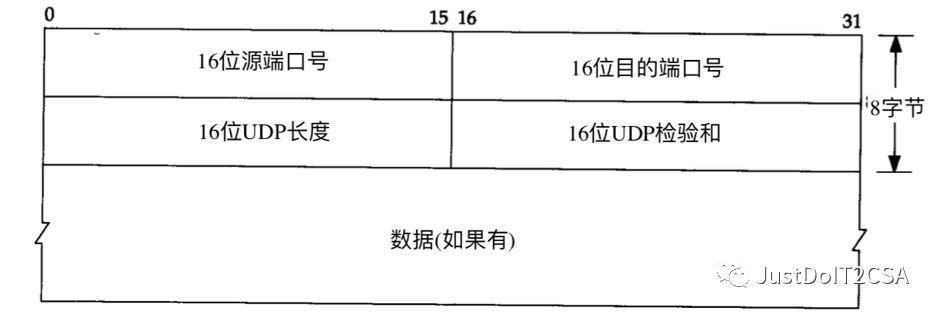
1. 端口号表示发送进程和接收进程。TCP端口号和UDP端口号是独立的。
2. UDP长度字段指的是UDP首部和UDP数据的字节长度。该字段的最小值为8字节(发送一份0字节的UDP数据报是OK)。这个有冗余的。
3. IP数据报长度指的是数据报全长,= 全长 – IP首部的长度。【UDP检验和】
UDP检验和覆盖UDP首部和UDP数据,UDP和TCP在首部中都覆盖它们首部和数据的检验和。UDP的检验和是可选的,而TCP的检验和是必需的。
UDP的检验和计算方法与IP首部检验和略有不同,UDP的数据报长度可以为奇数字节,但是检验和算法是把若干个16个bit字相加,因此解决方法必要时在最后增加填充字节0,这只是为了检验和的计算。另外,UDP和TCP数据报中都包含一个12字节长的伪首部,其中包含IP首部一些字段,其目的是让UDP 2 次检查数据是否已经正确到达目的地。
UDP检验和是一个端到端的检验和。由发送端计算,然后由接收端验证。其目的是为了发现UDP首部和数据在发送端到接收端之间发生的任何改动。

~~~~~~~~【科普小课堂】~~~~~~~
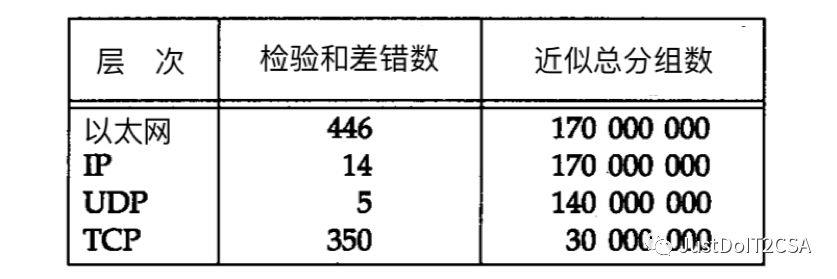
TCP发生检验和差错的比例与UDP相比要高得多。很有可能是因为在该系统中的TCP 连接经常是“远程”连接(经过许多路由器和网桥等中间设备),而UDP一般为本地通信。
不要完全相信数据链路(如以太网、令牌环等)的CRC检验。应该始终打开端到端的检验和功能。而且,如果数据很有价值,也不要完全相信UDP或TCP的检验和,因为这些都只是简单的检验和,不能检测出所有可能发生的错误。
~~~~~~~~~~~~~~~~~~~~~~
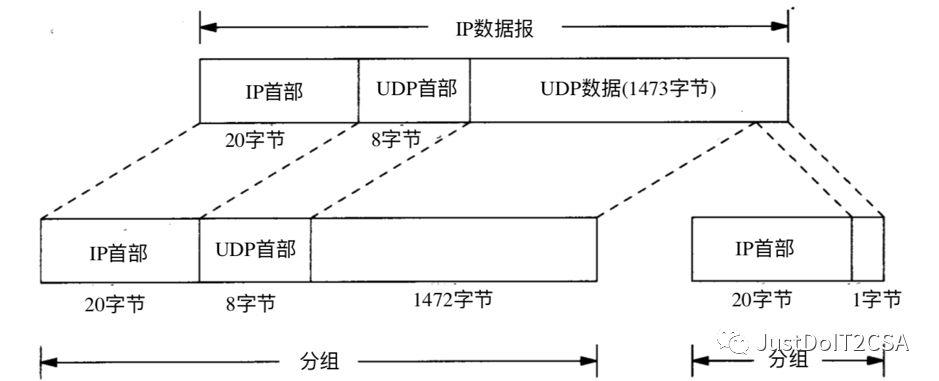
【IP分片】
把一份IP数据报分片以后,只有到达目的地才进行重新组装(与其他协议不同,其他协议要求在下一站就进行重新组装)。重新组装由目的端的IP层完成,其目的是使分片和重新组装过程对运输层(TCP和UDP)是透明的,除了某些可能的越级操作外。已经分片过的数据报有可能再次进行分片(可能不止一次)。IP首部中包含的数据为分片和重新组装提供了足够的信息。
当IP数据报被分片后,每一片都成为一个分组,具有自己的IP首部,并在选择路由时与其他分组独立。这样,当数据报的这些片到达目的端时有可能会失序,但是在IP首部中有足够的信息让接收端能正确组装这些数据报片。
~~~~~~~【科普小课堂】~~~~~~~
IP分片缺点:即使只丢失一片数据也要重传整个数据报,Why???
因为IP层本身没有超时重传的机制—由更高层来负责超时和重传(TCP有超时和重传机制,但UDP没有。一些UDP应用程序本身也执行超时和重传)。当来自TCP报文段的某一片丢失后,TCP在超时后会重发整个TCP报文段,该报文段对应于一份IP数据包。没有办法只重传数据报中的一个数据报片。事实上,如果对数据报分片的是中间路由器,而不是起始端系统,那么起始端系统就无法再换掉数据报是如何被分片的。就这个原因,经常要避免分片。
【常见术语】
1. IP数据报:指IP层端到端的传输单元(在分片之前和重新组装之后)
2. 分组:指在IP层和链路层之间传送的数据单元。一个分组可以是一个完整的IP数据报,也可以是IP数据报的一个分片。
~~~~~~~~~~~~~~~~~~~~~~~~
【ICMP不可达差错(需要分片)】

发生ICMP 不可达差错的另一种情况是当路由器收到一份需要分片的数据报,而在IP首部又设置了不分片(DF)的标志比特。如果某个程序需要判断到达目的端路途中最小MTU是多少——称作路径MTU发现机制,报文格式如上图。
【UDP和ARP之间的交互作用】
【最大UDP数据报长度】
理论上,IP数据报的最大长度是65535字节,这是由IP首部16比特总长度字段所限制的。去除20个字节的IP首部和8个字节的UDP首部,UDP数据报中用户数据的最长长度为65507字节,大多数都 < 65507。两个限制因素:
1. 应用程序可能会受到其程序接口的限制。Socket API提供了一个可供应用程序调用的函数,以设置接收和发送缓存的长度。现在大部分系统都默认提供了可读写> 8192字节的UDP数据报。
2. 来自于TCP/IP的内核实现。可能存在一些实现特性(或差错),使IP数据报长度小于65535字节。要求主机必须能够接收最短为576字节的IP数据报。
【ICMP源站抑制差错】
当一个系统(路由器或主机)接收数据报的速度比其处理速度快时,可能会产生这个差错。即使一个系统已经没有缓存并丢弃数据报,也不要求它一定要发送源站抑制报文。
~~~~~~~【UDP服务器设计】~~~~~~~
典型的服务器与OS进行交互作用,而且大多数需要同时处理多个客户。通常一个客户启动后直接与单个服务器通信,然后就结束了。而对于服务器来说,它启动后处于休眠状态,等待客户请求的到来。对于UDP来说,当客户数据报到达时,服务器wakeup,数据报中可能包含来自客户的某种形式的请求信息。
【UDP输入队列】
单个服务器进程对单个UDP端口上(服务器上的知名端口)的所有客户请求进行处理。通常程序所使用的每个UDP端口都与一个有限大小的输入队列相联系。其缺点:
1. 应用程序并不知道其输入队列何时溢出。只是由UDP对超出数据报进行丢弃处理。
2. 没有发回任何信息告诉客户其数据报被丢弃。
3. UDP输出队列是FIFO(先进先出)的。
【每个端口有多个接收者】
以上是关于UDP协议详解的主要内容,如果未能解决你的问题,请参考以下文章