HTMLTestRunner生成报告中有中文乱码解决方案
Posted 测试萌萌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HTMLTestRunner生成报告中有中文乱码解决方案相关的知识,希望对你有一定的参考价值。
造成中文乱码的原因:默认编码模式不是utf-8,查看html文件是输出的编码模式是utf-8,输入输出编码不一致导致中文出现乱码
排查过程:
1.想通过添加编码模式解决,失败了
源码:
with open(“test_report.html”,“wb”) as file:
修改后:
with open(“test_report.html”,“wb”,encoding=“utf-8”) as file:
修改后运行代码会报错,原因是“wb”中的“b”代表的是使用二进制模式,二进制模式与encoding="utf-8"冲突,所以问题没有解决
2.想要通过去掉“b”解决冲突,失败了
源码:
with open(“test_report.html”,“w”,encoding=“utf-8”) as file:
修改完成后运行代码没有报错,但是打开报告仍然中文乱码
3.查看html测试报告head为
head没问题这时候可以确定不是输出的问题
解决办法
1.点击进入HTMLTestrunner模块
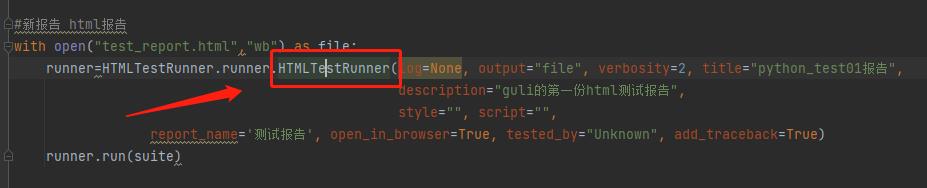
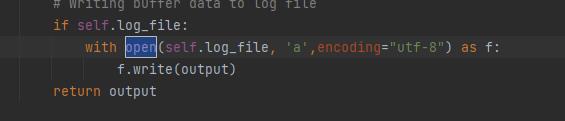
2.进入reunner.py,在reunner.py中,给所有的open方法添加上 encoding=“utf-8“,完成后运行代码问题解决
资源分享
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走…
这些资料,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!凡事要趁早,特别是技术行业,一定要提升技术功底。希望对大家有所帮助…….

以上是关于HTMLTestRunner生成报告中有中文乱码解决方案的主要内容,如果未能解决你的问题,请参考以下文章