Mysql-索引的底层结构
Posted TGB-Earnest
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql-索引的底层结构相关的知识,希望对你有一定的参考价值。
1、为什么索引结构使用B+树
(1)平衡二叉树
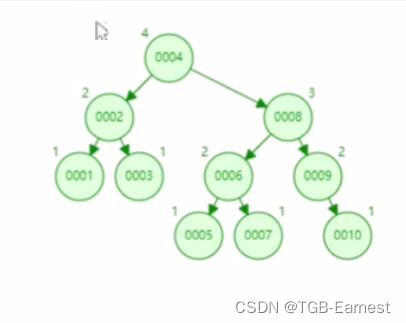
a、如果此时我们查找10需要走3次,并且随着树的深度,查询效率越低
b、如果我们要进行范围查找,查询大于5的数,需要进行遍历
(2)B树
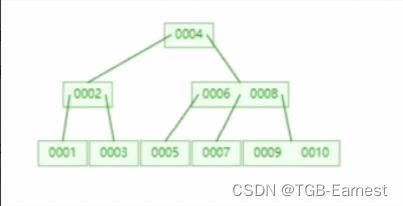
特点: 一个节点可以存储两个值
高度:3 (相比平衡二叉树小了1),所以查找速度也就很快了,如果找10,只需要找2次
但是,他也是存在回旋查找的问题的,比方说查找5,会返回到6。。。。。
(3)B+
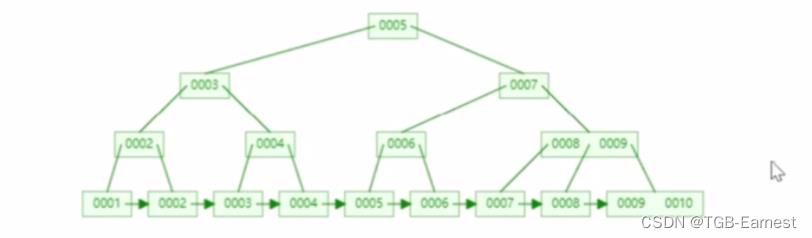
特点:我们会发现和B树存在不同的是,叶子结点存在了链表排序
这样就解决了回旋查找
叶子结点只存储key,非叶子结点即存储key,也存储value
所以范围查找的速度是非常的高的
2、MyISAM与InnoDB的区别?
(1) innodb存储文件有frm、ibd 是数据文件(共享表空间和单独表空间)而myisam是frm、myd(数据文件)、myi(索引文件)
myisam比innodb快
(2)innodb是聚集索引,使用B+Tree作为索引结构, 数据额文件是和(主键)索引绑定在一起的
(表数据文件本身就是按B+Tree组织的一个索引结构),必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大。其他索引也会很大。
MyISAM是非聚集索引,也是使用B+Tree作为索引结构,索引和数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
也就是说:InnoDB的B+树主键索引的叶子节点就是数据文件,辅助索引的叶子节点是主键的值;而MyISAM的B+树主键索引和辅助索引的叶子节点都是数据文件的地址指针。
3、使用索引原则:
回表
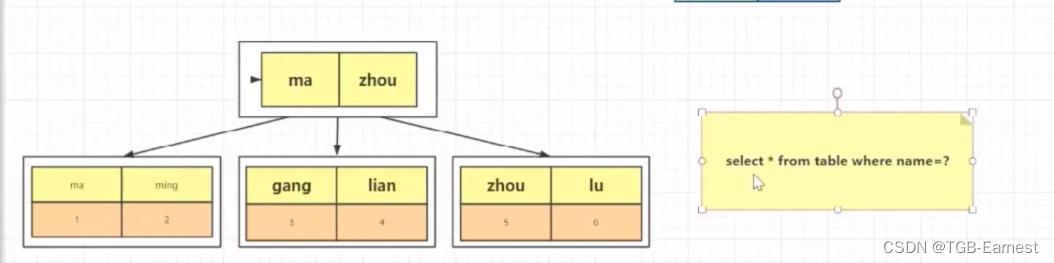
概念:从非聚簇索引跳转到聚簇索引中查找数据的过程中称之为回表
看下表的表2,当执行下面SQL语句的时候,因为查询的是*,所以会回表表1
select * from table where name=?
索引覆盖(推荐使用)
概念:当非聚簇索引的叶子节点中包含了查询需要的所有字段时,不需要回表,这个过程称之为索引覆盖
下面的SQL不需要回表
select name from table where name=?
索引下推
select * from table where name=? and age=? 在没有索引下推之前,执行的过程时,先根据
name 从存储引擎中拉取数据,然后根据age在server中过滤
有了索引下推之后,执行的过程是:根据name,age整体的从存储引擎中做数据检索,返回对应的记录,不再server层做任何操作
https://juejin.cn/post/7005794550862053412
最左前缀匹配原则
表字段 id name age gender (id是主键,name,age是普通索引,组合索引)
select * from table where name=? and age=?
select * from table where name=?
select * from table where age=?
select * from table where age=? and name=? 优化器会优化
其中只有第三个用不了组合索引
index(abc)
where a>10 and b=1 and c=1
where a>10 and b=1 and c=1
4、聚簇索引和非聚簇索引的区别
聚簇索引不是一种单独的索引类型,而是一种数据存储方式。将数据存储与索引放到了一块,找到索引也就找到了数据。
非聚簇索引也叫二级索引,将数据存储与索引分开结构,索引结构的叶子节点指向了数据的对应行地址,通过地址才能找到对应的数据。
判断数据跟索引是否放在一起的,如果放在一起就是聚簇索引,不放在一起就是非聚簇索引
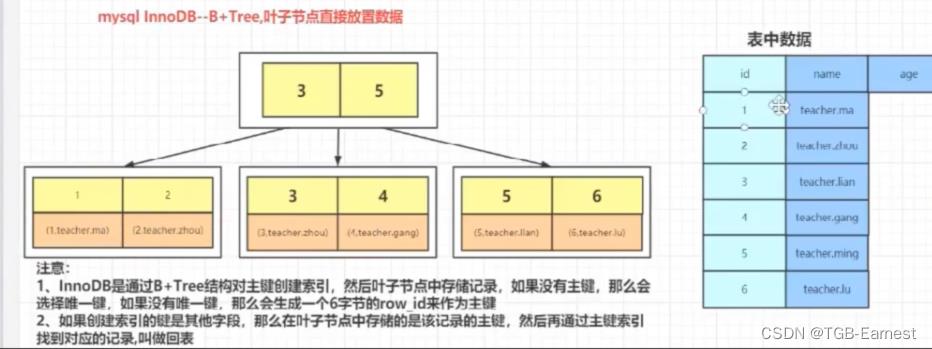
注意:在innodb中,数据在进行插入的时候必须要跟某一个索引的值进行绑定,这个值默认是主键,如果没有主键,选择唯一键,如果没有唯一键,选择6字节的rowid
数据一定跟索引聚集存放-》.frm .ibd
一个表中可以有多少个索引? N个
索引如果是跟数据放在一起,那么数据会存储几分? 数据会存储一份
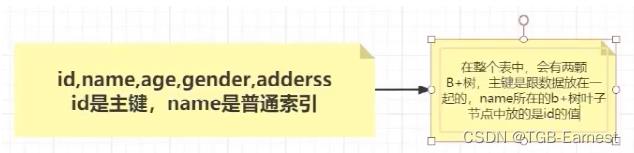
下图是主键的索引结构
下图是Name的建立的索引结构
innodb中,一定有聚簇索引,但是其他索引都是非聚簇索引。
myisam中只有非聚簇索引(本来就是非开放的)
5、B+tree

以上是关于Mysql-索引的底层结构的主要内容,如果未能解决你的问题,请参考以下文章