字节跳动大规模实践埋点自动化测试框架设计
Posted 起码有故事
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字节跳动大规模实践埋点自动化测试框架设计相关的知识,希望对你有一定的参考价值。

大数据时代,多数的web或app产品都会使用第三方或自己开发相应的数据系统,进行用户行为数据或其它信息数据的收集,在这个过程中,埋点是比较重要的一环。埋点收集的数据一般有以下作用:
- 驱动决策:ABtest、漏斗优化、用户增长、bug修复、精准营销、流失用户预警
- 驱动产品智能:智能推荐(千人千面)、场景化提示(私人助理)等
- 驱动安全:风险识别
01、埋点测试分类
埋点测试,首先要了解埋点的分类。
埋点主要分为:前端埋点、后端埋点
-
前端埋点:前端埋点可以理解为web端,app端等在前端触发相关规则时进行的埋点上报等,主要记录的是用户的操作行为,例如点击了哪个按钮,进入了哪个页面等等。
-
后端埋点:主要是服务端埋点,可以理解为当用户进行相关操作触发相关接口请求或相关业务的时候,进行的埋点上报。
那么两者有什么区别呢?
在实际过程中,有些埋点是不用特意区分前后端的,用户的一个埋点事件在前端埋点或后端埋点都可以实现,但是需要注意的是,在实际埋点上报、数据收集等过程中会有数据丢失的情况,从这个角度来看的话,其实后端埋点要比前端埋点更有优势,前端埋点会因为一些网络问题、适配问题等等容易出现上报异常造成数据丢失且丢失后排查困难,因为前端相关的是没有记录相关操作的,只负责上报,上报成功与否没有记录。
而如果是后端埋点,无论是自己的数据系统还是第三方数据系统都是可以通过自己系统本身相关的数据库查询或记录日志等操作进行埋点数据的校验排查,所以针对一些比较重要的埋点,还是建议以后端埋点为主,必要时通过记录日志或记入数据库等方式对相关数据进行二次记录以便进行数据核实。
02、埋点测试过程
埋点测试的过程有两个比较重要的环节,埋点上报和埋点落库
-
埋点上报:无论是前端埋点还是后端埋点,有没有正常按照相关规则进行上报,相关的事件名、属性值都是否完整正确上报,这个是需要关注的
-
埋点落库:埋点上报完的数据是需要存储到数据库当中再进行相关的数据统计、分析、归类等等,除了检查埋点上报,还要看最终数据是否正常落库,相关数据字段是否正常。
03、埋点自动化测试设计
了解了埋点测试的分类和过程,再思考如何针对埋点进行自动化测试。首先埋点自动化测试与其它自动化测试的方案设计在目的层面应该是一致的,是为了更好的进行埋点回归测试,扩大埋点回归的覆盖率,特别是针对一些核心的埋点数据,例如一些埋点数据是转化相关数据,而转化数据直接跟核心业务相关,有些核心业务还会根据转化数据进行营销、销售、业绩等相关统计,埋点数据不准直接影响到这些东西。
那么如何进行埋点自动化测试设计呢?
可以进行分层设计
-
用户应用层框架-移动端Appium,web端selenium,主要是模拟用户正常的业务操作
-
数据mock、上报数据收集-通过构造测试数据给到用户应用层使用,并且通过代理抓包收集上报数据,进行上报数据校验(jsonschema校验)
-
服务端上报及落库查询-通过链接数据数据库或使用相关API,查询测试上报数据是否落库。
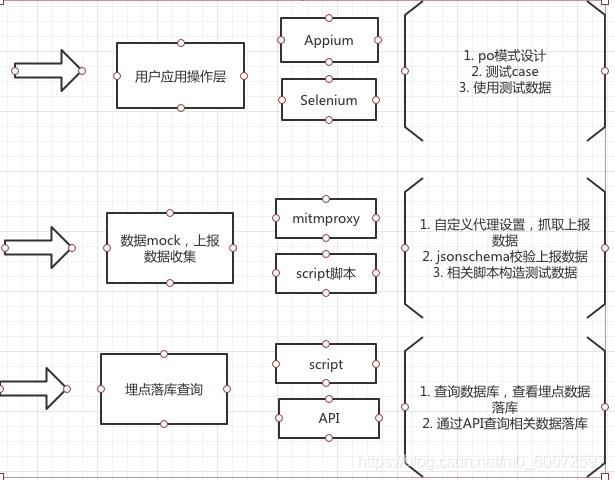
另外,还需要结合Jenkins进行持续集成,每天或每次发版前对所有埋点进行回归测试。

最后:如果对软件测试、接口测试、自动化测试、技术同行、持续集成、面试经验交流。感兴趣可以进到 902061117,群内会有不定期的分享测试资料。
如果文章对你有帮助,麻烦伸出发财小手点个赞,感谢您的支持,你的点赞是我持续更新的动力。
好文推荐
2021软件测试工程师面试题汇总(内含答案)-看完BATJ面试官对你竖起大拇指!

字节跳动自研的 Go RPC 框架 KiteX 核心技术讲解
本文选自“字节跳动基础架构实践”系列文章。
“字节跳动基础架构实践”系列文章是由字节跳动基础架构部门各技术团队及专家倾力打造的技术干货内容,和大家分享团队在基础架构发展和演进过程中的实践经验与教训,与各位技术同学一起交流成长。
RPC 框架作为研发体系中重要的一环,承载了几乎所有的服务流量。本文将简单介绍字节跳动自研网络库 netpoll 的设计及实践;以及我们实际遇到的问题和解决思路,希望能为大家提供一些参考。
前言
字节跳动框架组主要负责公司内 RPC 框架的开发与维护。RPC 框架作为研发体系中重要的一环,承载了几乎所有的服务流量。随着公司内 Go 语言使用越来越广,业务对框架的要求越来越高,而 Go 原生 net 网络库却无法提供足够的性能和控制力,如无法感知连接状态、连接数量多导致利用率低、无法控制协程数量等。为了能够获取对于网络层的完全控制权,同时先于业务做一些探索并最终赋能业务,框架组推出了全新的基于 epoll 的自研网络库 —— netpoll,并基于其之上开发了字节内新一代 Golang 框架 KiteX。
新型网络库设计
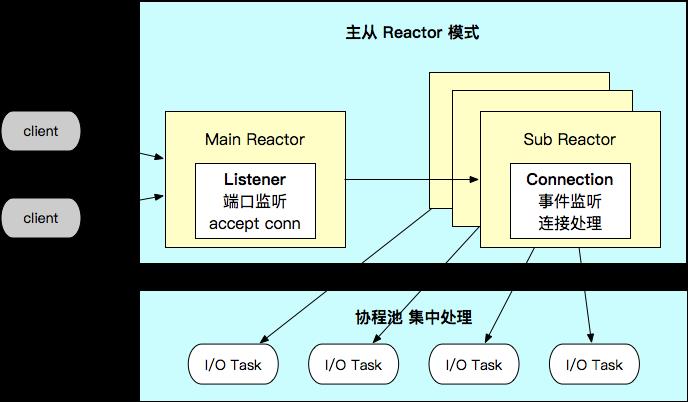
Reactor - 事件监听和调度核心
netpoll 核心是 Reactor 事件监听调度器,主要功能为使用 epoll 监听连接的文件描述符(fd),通过回调机制触发连接上的 读、写、关闭 三种事件。
Server - 主从 Reactor 实现
netpoll 将 Reactor 以 1:N 的形式组合成主从模式。
-
MainReactor 主要管理 Listener,负责监听端口,建立新连接; -
SubReactor 负责管理 Connection,监听分配到的所有连接,并将所有触发的事件提交到协程池里进行处理。 -
netpoll 在 I/O Task 中引入了主动的内存管理,向上层提供 NoCopy 的调用接口,由此支持 NoCopy RPC。 -
使用协程池集中处理 I/O Task,减少 goroutine 数量和调度开销。
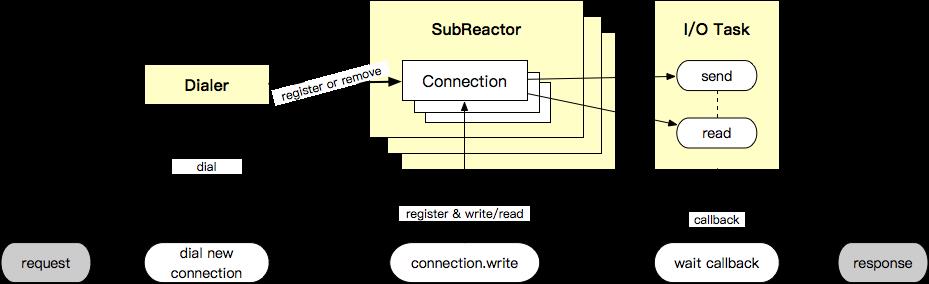
Client - 共享 Reactor 能力
client 端和 server 端共享 SubReactor,netpoll 同样实现了 dialer,提供创建连接的能力。client 端使用上和 net.Conn 相似,netpoll 提供了 write -> wait read callback 的底层支持。
Nocopy Buffer
为什么需要 Nocopy Buffer ?
在上述提及的 Reactor 和 I/O Task 设计中,epoll 的触发方式会影响 I/O 和 buffer 的设计,大体来说分为两种方式:
-
采用水平触发(LT),则需要同步的在事件触发后主动完成 I/O,并向上层代码直接提供 buffer。 -
采用边沿触发(ET),可选择只管理事件通知(如 go net 设计),由上层代码完成 I/O 并管理 buffer。
两种方式各有优缺,netpoll 采用前者策略,水平触发时效性更好,容错率高,主动 I/O 可以集中内存使用和管理,提供 nocopy 操作并减少 GC。事实上一些热门开源网络库也是采用方式一的设计,如 easygo、evio、gnet 等。
但使用 LT 也带来另一个问题,即底层主动 I/O 和上层代码并发操作 buffer,引入额外的并发开销。比如:I/O 读数据写 buffer 和上层代码读 buffer 存在并发读写,反之亦然。为了保证数据正确性,同时不引入锁竞争,现有的开源网络库通常采取 同步处理 buffer(easygo, evio) 或者将 buffer 再 copy 一份提供给上层代码(gnet) 等方式,均不适合业务处理或存在 copy 开销。
另一方面,常见的 bytes、bufio、ringbuffer 等 buffer 库,均存在 growth 需要 copy 原数组数据,以及只能扩容无法缩容,占用大量内存等问题。因此我们希望引入一种新的 Buffer 形式,一举解决上述两方面的问题。
Nocopy Buffer 设计和优势
Nocopy Buffer 基于链表数组实现,如下图所示,我们将 []byte 数组抽象为 block,并以链表拼接的形式将 block 组合为 Nocopy Buffer,同时引入了引用计数、nocopy API 和对象池。
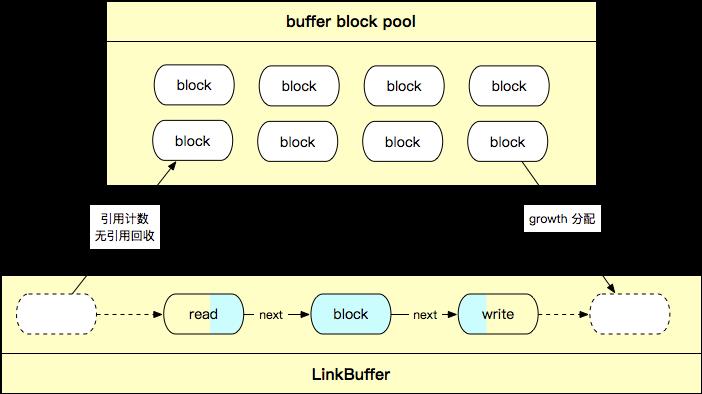
Nocopy Buffer 相比常见的 bytes、bufio、ringbuffer 等有以下优势:
-
读写并行无锁,支持 nocopy 地流式读写 -
读写分别操作头尾指针,相互不干扰。 -
高效扩缩容 -
扩容阶段,直接在尾指针后添加新的 block 即可,无需 copy 原数组。 -
缩容阶段,头指针会直接释放使用完毕的 block 节点,完成缩容。每个 block 都有独立的引用计数,当释放的 block 不再有引用时,主动回收 block 节点。 -
灵活切片和拼接 buffer (链表特性) -
支持任意读取分段(nocopy),上层代码可以 nocopy 地并行处理数据流分段,无需关心生命周期,通过引用计数 GC。 -
支持任意拼接(nocopy),写 buffer 支持通过 block 拼接到尾指针后的形式,无需 copy,保证数据只写一次。 -
Nocopy Buffer 池化,减少 GC -
将每个 []byte 数组视为 block 节点,构建对象池维护空闲 block,由此复用 block,减少内存占用和 GC。
基于该 Nocopy Buffer,我们实现了 Nocopy Thrift,使得编解码过程内存零分配零拷贝。
连接多路复用
RPC 调用通常采用短连接或者长连接池的形式,一次调用绑定一个连接,那么当上下游规模很大的情况下,网络中存在的连接数以 MxN 的速度扩张,带来巨大的调度压力和计算开销,给服务治理造成困难。因此,我们希望引入一种 "在单一长连接上并行处理调用" 的形式,来减少网络中的连接数,这种方案即称为 "连接多路复用"。
当前业界也存在一些开源的连接多路复用方案,掣肘于代码层面的束缚,这些方案均需要 copy buffer 来实现数据分包和合并,导致实际性能并不理想。而上述 Nocopy Buffer 基于其灵活切片和拼接的特性,很好的支持了 nocopy 的数据分包和合并,使得实现高性能连接多路复用方案成为可能。
基于 netpoll 的连接多路复用设计如下图所示,我们将 Nocopy Buffer(及其分片) 抽象为虚拟连接,使得上层代码保持同 net.Conn 相同的调用体验。与此同时,在底层代码上通过协议分包将真实连接上的数据灵活的分配到虚拟连接上;或通过协议编码合并发送虚拟连接数据。
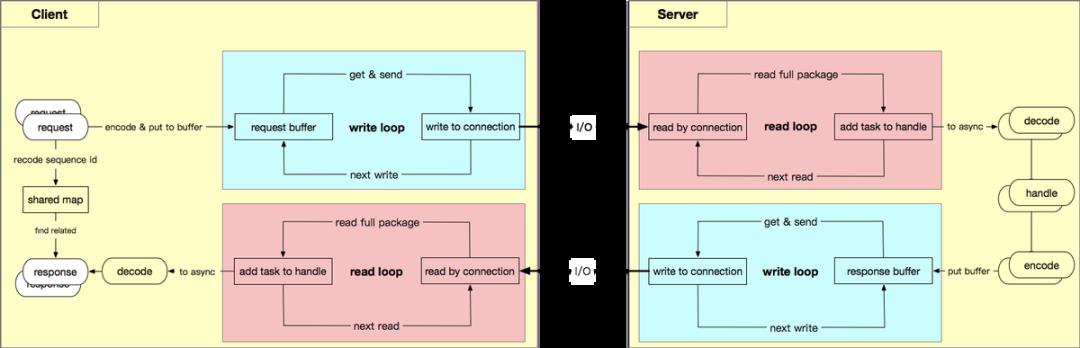
连接多路复用方案包含以下核心要素:
-
虚拟连接
-
实质上是 Nocopy Buffer,目的是替换真正的连接,规避内存 copy。 -
上层的业务逻辑/编解码 均在虚拟连接上完成,上层逻辑可以异步独立并行执行。 -
Shared map
-
引入分片锁来减少锁力度。 -
在调用端使用 sequence id 来标记请求,并使用分片锁存储 id 对应的回调。 -
在接收响应数据后,根据 sequence id 来找到对应回调并执行。 -
协议分包和编码
-
如何识别完整的请求响应数据包是连接多路复用方案可行的关键,因此需要引入协议。 -
这里采用 thrift header protocol 协议,通过消息头判断数据包完整性,通过 sequence id 标记请求和响应的对应关系。
ZeroCopy
这里所说的 ZeroCopy,指的是 Linux 所提供的 ZeroCopy 的能力。上一章中我们说了业务层的零拷贝,而众所周知,当我们调用 sendmsg 系统调用发包的时候,实际上仍然是会产生一次数据的拷贝的,并且在大包场景下这个拷贝的消耗非常明显。以 100M 为例,perf 可以看到如下结果:
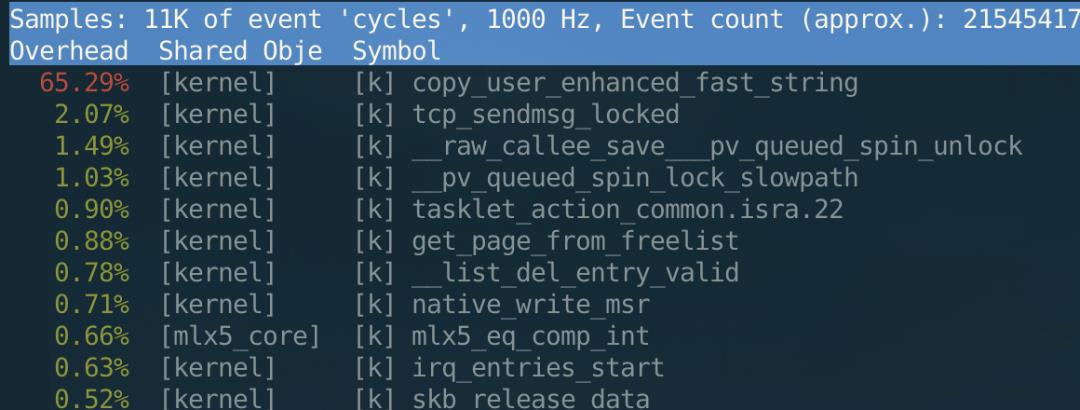
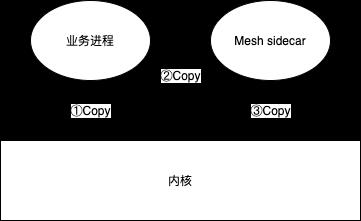
这还仅仅是普通 tcp 发包的占用,在我们的场景下,大部分服务都会接入 Service Mesh,所以在一次发包中,一共会有 3 次拷贝:业务进程到内核、内核到 sidecar、sidecar 再到内核。这使得有大包需求的业务,拷贝所导致的 cpu 占用会特别明显,如下图:
于是,字节跳动框架组和字节跳动内核组合作,由内核组提供了同步的接口:当调用 sendmsg 的时候,内核会监听并拦截内核原先给业务的回调,并且在回调完成后才会让 sendmsg 返回。这使得我们无需更改原有模型,可以很方便地接入 ZeroCopy send。同时,字节跳动内核组还实现了基于 unix domain socket 的 ZeroCopy,可以使得业务进程与 Mesh sidecar 之间的通信也达到零拷贝。
在使用了 ZeroCopy send 后,perf 可以看到内核不再有 copy 的占用:
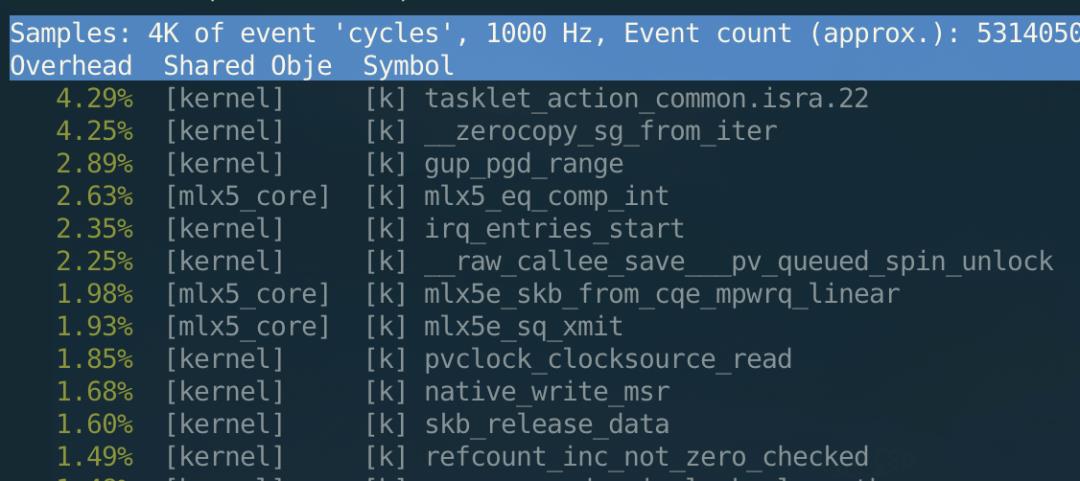 从 cpu 占用数值上看,大包场景下 ZeroCopy 能够比非 ZeroCopy 节省一半的 cpu。
从 cpu 占用数值上看,大包场景下 ZeroCopy 能够比非 ZeroCopy 节省一半的 cpu。
Go 调度导致的延迟问题分享
在我们实践过程中,发现我们新写的 netpoll 虽然在 avg 延迟上表现胜于 Go 原生的 net 库,但是在 p99 和 max 延迟上要普遍略高于 Go 原生的 net 库,并且尖刺也会更加明显,如下图(Go 1.13,蓝色为 netpoll + 多路复用,绿色为 netpoll + 长连接,黄色为 net 库 + 长连接):
我们尝试了很多种办法去优化,但是收效甚微。最终,我们定位出这个延迟并非是由于 netpoll 本身的开销导致的,而是由于 go 的调度导致的,比如说:
-
由于在 netpoll 中,SubReactor 本身也是一个 goroutine,受调度影响,不能保证 EpollWait 回调之后马上执行,所以这一块会有延迟; -
同时,由于用来处理 I/O 事件的 SubReactor 和用来处理连接监听的 MainReactor 本身也是 goroutine,所以实际上很难保证在多核情况之下,这些 Reactor 能并行执行;甚至在最极端情况之下,可能这些 Reactor 会挂在同一个 P 下,最终变成了串行执行,无法充分利用多核优势; -
由于 EpollWait 回调之后,SubReactor 内是串行处理 I/O 事件的,导致排在最后的事件可能会有长尾问题; -
在连接多路复用场景下,由于每个连接绑定了一个 SubReactor,故延迟完全取决于这个 SubReactor 的调度,导致尖刺会更加明显。
由于 Go 在 runtime 中对于 net 库有做特殊优化,所以 net 库不会有以上情况;同时 net 库是 goroutine-per-connection 的模型,所以能确保请求能并行执行而不会相互影响。
对于以上这个问题,我们目前解决的思路有两个:
-
修改 Go runtime 源码,在 Go runtime 中注册一个回调,每次调度时调用 EpollWait,把获取到的 fd 传递给回调执行; -
与字节跳动内核组合作,支持同时批量读/写多个连接,解决串行问题。另外,经过我们的测试,Go 1.14 能够使得延迟略有降低同时更加平稳,但是所能达到的极限 QPS 更低。希望我们的思路能够给业界同样遇到此问题的同学提供一些参考。
后记
希望以上的分享能够对社区有所帮助。 同时,我们也在加速建设 netpoll 以及基于 netpoll 的新框架 KiteX。 欢迎各位感兴趣的同学加入我们,共同建设 Go 语言生态!参考资料
-
http://man7.org/linux/man-pages/man7/epoll.7.html -
https://golang.org/src/runtime/proc.go -
https://github.com/panjf2000/gnet -
https://github.com/tidwall/evio
推荐阅读
喜欢本文的朋友,欢迎关注“Go语言中文网”:
以上是关于字节跳动大规模实践埋点自动化测试框架设计的主要内容,如果未能解决你的问题,请参考以下文章