浅谈常量字符串
Posted 追梦小蔡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈常量字符串相关的知识,希望对你有一定的参考价值。
今天早上看网课刚好学到字符函数的部分,刚好对常量字符串有些疑惑的地方,现在组织了下语言,把今天关于常量字符串的思考写成这篇博客
当我们编写程序时,常量字符串是一种非常常见的数据类型。常量字符串指的是在程序中声明的一个不可更改的字符串变量,其值在声明后就不能再被修改。在许多情况下,将字符串定义为常量可以提高程序的可读性和可维护性。
常量字符串可以通过两种方式来定义:使用关键字 const 或者使用预处理器指令 #define。
使用 const 关键字定义常量字符串时,可以将其作为一个变量进行声明并且初始化,如下所示:
const char* const STR = "Hello, world!";
这里 const char* 表示一个指向字符型数据的指针,而第二个 const 则表示该指针是一个常量,即它本身的值也不能被修改。STR 是一个指向字符串 "Hello, world!" 的常量指针。
另一种常量字符串的定义方式是使用预处理器指令 #define,如下所示:
#define STR "Hello, world!"
这里 #define 定义了一个名为 STR 的常量字符串,其值为 "Hello, world!"。在编译时,预处理器将会把所有 STR 出现的地方替换成 "Hello, world!"。
需要注意的是,在使用 #define 定义常量字符串时,没有办法像使用 const 关键字定义的常量字符串那样获取其长度。因此,在使用 #define 定义常量字符串时,需要自行计算其长度,并且不能使用 C++11 中的 constexpr 特性。
在程序中使用常量字符串可以带来很多好处。首先,由于常量字符串的值不能被修改,因此可以防止程序中不想要的错误修改。其次,将字符串定义为常量可以提高程序的可读性和可维护性,因为常量名称本身就可以表达出字符串的含义,而无需再花费额外的精力进行解释。
总之,在编写程序时,使用常量字符串是一种非常好的实践,可以提高代码的质量和可读性,从而让程序更加易于维护。
浅谈JAVA中字符串常量的储存位置
在讲述这些之前我们需要一些预备知识:
Java的内存结构我们可以通过两个方面去看待它。
一、从抽象的JVM的角度去看。相关定义请参考JVM规范:Chapter 2. The Structure of the Java Virtual Machine
从该角度看的话Java内存结构包含以下部分:该部分内容可以结合:JVM简介(更加详细深入的介绍)
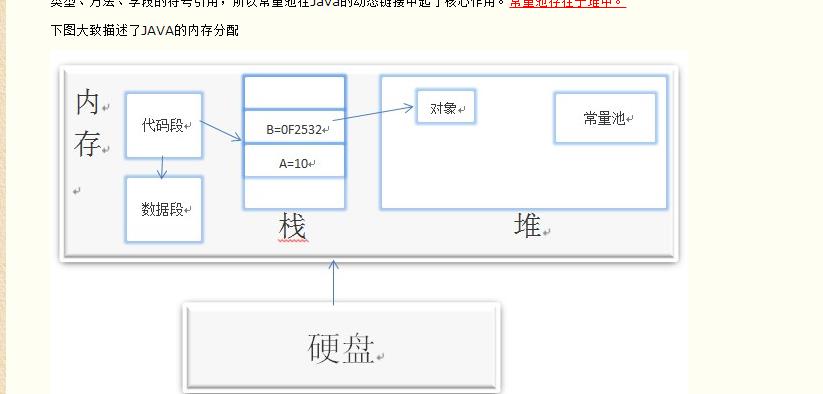
1、栈区:由编译器自动分配释放,具体方法执行结束后,系统自动释放JVM内存资源。
其作用有保存局部变量的值,包括:1.用来保存基本数据类型的值;2.保存类的实例对象的引用。也可以用来保存加载方法时的帧。
2、堆区:一般由程序员分配释放,JVM不定时查看这个对象,如果没有引用指向这个对象就回收。
其作用为用来存放动态产生的数据,包括new出来的实例,数组等。注意创建出来的对象只包含属于各自的成员变量,并不包括成员方法。
因为同一个类的对象拥有各自的成员变量,存储在各自的堆中,但是他们共享该类的方法,并不是每创建一个对象就把成员方法复制一次。
3、代码区:存放程序中方法的二进制代码,而且是多个对象共享一个代码空间区域。
4、数据区:用来存放static定义的静态成员。
5、常量池:JVM为每个已加载的类型维护一个常量池,常量池就是这个类型用到的常量的一个有序集合。包括直接常量(基本类型,String)和对其他类型、方法、字段的符号引用。池中的数据和数组一样通过索引访问。由于常量池包含了一个类型所有的对其他类型、方法、字段的符号引用,所以常量池在Java的动态链接中起了核心作用。常量池存在于堆中。
下图大致描述了JAVA的内存分配
二、从操作系统上的进程的角度。相关定义请参考各种操作系统的资料,例如Linux的话可以参考这个简单的介绍:Linux Processes explained (此方面一般被较少地谈论到,本文对此仅仅做一个稍微的介绍)
这里切记一点:JVM规范所描述的抽象JVM概念与实际实现并不总一一对应。
接来下我们来看一段代码实例与注释:
public class TestStringConstant { public static void main(String args[]) { // 字符串常量,分配在常量池中,编译器会对其进行优化, Interned table // 即当一个字符串已经存在时,不再重复创建一个相同的对象,而是直接将s2也指向"hello". String s1 = "hello"; String s2 = "hello"; // new出来的对象,分配在heap中.s3与s4虽然它们指向的字符串内容是相同的,但是是两个不同的对象. // 因此==进行比较时,其所存的引用是不同的,故不会相等 String s3 = new String("world"); String s4 = new String("world"); System.out.println(s1 == s2); // true System.out.println(s3 == s4); // false System.out.println(s3.equals(s4)); // true // String中equals方法已经被重写过,比较的是内容是否相等. } }
那么对于上例代码中提到的编译器的优化,下面将进行更进一步的详细介绍。请看下例代码:
class A { private String a = "aa"; public boolean methodB() { String b = "bb"; final String c = "cc"; return false; } }
"aa"、"bb"的String对象按JVM规范在Java heap上,在JDK8之前的HotSpot VM实现里在PermGen,在JDK7开始的HotSpot VM里在普通Java heap里(而不在PermGen里);"cc"如果存在的话也一样,但是可能会不存在。
这些String对象属于“interned String”。String是Java对象,根据JVM规范的定义它必须存在于Java heap中,interned String也不例外。Interned String特别的地方在于JVM会有个StringTable存着interned String的引用,保证内容相同的String对象不被重复intern。(这里便是编译器的优化)
这个StringTable怎样实现JVM规范里并没有规定,不过通常它并不保存String对象的内容,而只是保存String对象的引用而已。
- 从JVM规范看a、b、c变量:
a变量作为A类的对象实例字段,会跟随A的实例在Java heap上。
b变量作为局部变量会在Java线程栈上。
c变量虽然也是局部变量,但因为有final修饰并且有初始化为一个常量值,所以c是一个常量。它可能会被优化掉(就没有c这个变量了),也可能跟b一样作为局部变量在Java线程栈上。
通过以上相信大家对于字符串常量的分配区域以及java的内存分配有了一个较为形象的了解。
下面是一些相关知识点的补充与注意事项:
1.分清什么是实例什么是对象。Class a= new Class();此时a叫实例,而不能说a是对象。实例在栈中,对象在堆中,操作实例实际上是通过实例的指针间接操作对象。多个实例可以指向同一个对象。
2.栈中的数据和堆中的数据销毁并不是同步的。方法一旦结束,栈中的局部变量立即销毁,但是堆中对象不一定销毁。因为可能有其他变量也指向了这个对象,直到栈中没有变量指向堆中的对象时,它才销毁,而且还不是马上销毁,要等垃圾回收扫描时才可以被销毁。
3.以上的栈、堆、代码段、数据段等等都是相对于应用程序而言的。每一个应用程序都对应唯一的一个JVM实例,每一个JVM实例都有自己的内存区域,互不影响。并且这些内存区域是所有线程共享的。这里提到的栈和堆都是整体上的概念,这些堆栈还可以细分。
4.类的成员变量在不同对象中各不相同,都有自己的存储空间(成员变量在堆中的对象中)。而类的方法却是该类的所有对象共享的,只有一套,对象使用方法的时候方法才被压入栈,方法不使用则不占用内存。
- 从HotSpot VM的实现看:
当methodB()被解释执行时,输入的字节码是怎样的就会怎样执行,而由于javac的实现不会优化掉变量b,所以调用methodB()时它一定会在Java线程栈上的局部变量区里;当字节码里变量c存在时,它也跟b一样在Java线程栈的局部变量区。
当methodB()被JIT编译执行时,由于局部变量b、c都没有被使用,所以它们经过JIT编译后就消失了,调用methodB()不会在栈上给b或c变量分配任何空间。
通过以上相信大家对于字符串常量的分配区域以及java的内存分配有了一个较为形象的了解。
下面是一些相关知识点的补充与注意事项:
1.分清什么是实例什么是对象。Class a= new Class();此时a叫实例,而不能说a是对象。实例在栈中,对象在堆中,操作实例实际上是通过实例的指针间接操作对象。多个实例可以指向同一个对象。
2.栈中的数据和堆中的数据销毁并不是同步的。方法一旦结束,栈中的局部变量立即销毁,但是堆中对象不一定销毁。因为可能有其他变量也指向了这个对象,直到栈中没有变量指向堆中的对象时,它才销毁,而且还不是马上销毁,要等垃圾回收扫描时才可以被销毁。
3.以上的栈、堆、代码段、数据段等等都是相对于应用程序而言的。每一个应用程序都对应唯一的一个JVM实例,每一个JVM实例都有自己的内存区域,互不影响。并且这些内存区域是所有线程共享的。这里提到的栈和堆都是整体上的概念,这些堆栈还可以细分。
4.类的成员变量在不同对象中各不相同,都有自己的存储空间(成员变量在堆中的对象中)。而类的方法却是该类的所有对象共享的,只有一套,对象使用方法的时候方法才被压入栈,方法不使用则不占用内存。
对于String的相关补充:
对于String的修改其实是new了一个StringBuilder并调用append方法,然后调用toString返回一个新的String.
(注意:append方法并不会new一个新的对象.)
但是JVM是会对String进行优化的,比如:
String str = "I" + "love" + "java"
其中的字符串在编译的时候就能够确认,所以编译器会直接将其拼接成一个字符串放在常量池:"I love java"
但是若代码为下面这样:
String a = "I"; String b = "love"; String c = "java"; String str = a + b + c;
那么只有等到运行的时候才能够确定str最终是什么,编译器并不会对其进行优化,而是通过StringBuilder对字符串改变来实现的。
但是注意,要是此处给 a, b, c添加上 final 关键字,则编译器就能够对其进行优化。我们可以做下面这样一个测试:
public class foo{ public static void main(String[] args) { String a = "I "; String b = "love "; String c = "java"; final String a1 = "I "; final String b1 = "love "; final String c1 = "java"; String str = a + b + c; String str1 = a1 + b1 + c1; // equals to str1 = "I " + "love " + "java" String str2 = "I " + "love " + "java"; System.out.println(str == "I love java"); // output false System.out.println(str1 == "I love java"); // output true System.out.println(str2 == "I love java"); // output true System.out.println(a + "love " + "java" == "I love java"); // output false System.out.println(a1 + "love " + "java" == "I love java"); // output true } }
Note:
StringBuilder 和 StringBuffer 的区别:
StringBuffer 是线程安全的;StringBuilder 是非线程安全的。
因为StingBuffer是在StringBuilder的基础上加锁,而加锁是一个重量级的操作,需要调用操作系统内核来实现。
比较耗时。
故在效率上: StringBuilder > StringBuffer
以上是关于浅谈常量字符串的主要内容,如果未能解决你的问题,请参考以下文章