Flink窗口与水位线不得不说的秘密
Posted 梧桐生湘云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink窗口与水位线不得不说的秘密相关的知识,希望对你有一定的参考价值。
众所周知,Apache Flink是一个框架和分布式处理引擎,用于对无界和有界流进行有状态计算。在我们的这个Flink框架中,自Flink1.12.0正式发布流批一体统一运行之后,我们的实时计算框架真正步入了Flink的时代,flink实现了流批一体,那么在我们的flink计算中怎么实现我们的批处理,这时候就有了这个窗口的概念;
在我们的flink框架中有四大基石:时间语义(time)、状态编程(State)、检查点(checkpoint)、窗口(Window);窗口(Window)概念是将我们的数据流根据时间分片来划分一个个窗口,用于我们更好实现数据的批处理;下面就说一下我们的窗口;
窗口概念
窗口:将无限数据切割成有限的“数据块”进行处理,串口是处理无界流的核心;
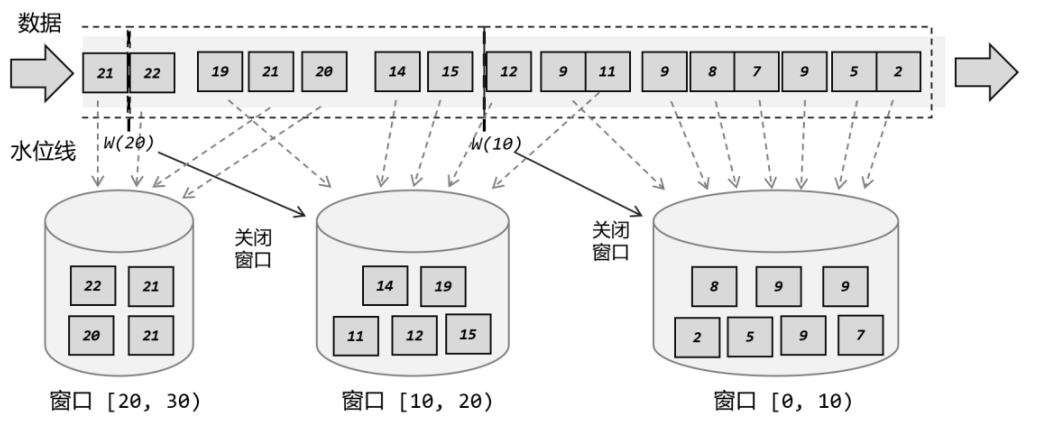
窗口更像一个“桶”,将流切割成有限大小的多个存储桶,每个数据都会分发到对应的桶中,当到达窗口结束时间时,就对每个桶中收集的数据进行计算处理。
- 动态创建:当有落在这个窗口区间范围的数据到达时,才创建对应的窗口
- 窗口关闭:到达窗口结束时间时,窗口就触发计算并关闭
窗口的分类
按驱动类型分类
通常我们数据的事件流通过什么标准来划分窗口叫做窗口的“驱动类型”,常见有时间窗口、计数窗口;
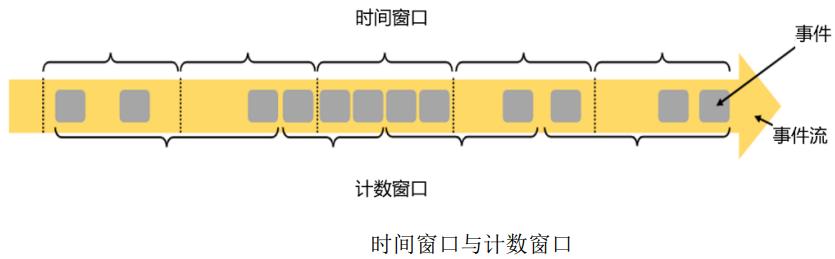
(1)时间窗口(timeWindow)
时间窗口以时间点来定义窗口开始和结束,通常以一个时间段的形式来表示我们数据的一个窗口。结束时间后,窗口不再收集数据,触发计算输出结果,并将窗口关闭销毁;
窗口大小 = 结束时间 - 开始时间
Flink对于我们的程序中事件流数据处理中有TimeWindow方法来表示我们使用时间窗口,其实有一个TimeWindow类来表示时间窗口,有两个私有属性表示窗口的开始和结束的时间戳,单位毫秒
private final long start;
private final long end;可以通过公有get set方法调用这两个时间戳;另外还提供了maxTimestamp()方法用来获取窗口中能够包含数据的最大时间戳(end - 1);这代表我们定义的窗口范围都是左闭右开的区间;
public long maxeTimestamp()
return end - 1;
(2)计数窗口(countWindow)
基于元素个数在截取数据,到达固定的个数就触发计算并关闭窗口。
按照窗口分配数据的规则分类
时间窗口、计数窗口只是对窗口的一个大致划分。在具体应用时,还需要定义更加精细的规则,来控制数据应该划分到哪个窗口中去。不同的分配数据的方式,就可以由不同的功能应用。
(1)滚动窗口(Tumbling Windows)

滚动窗口有固定的大小,是一种对数据进行“均匀切片”的划分方式,首尾相接。我们之前所举的例子都是滚动窗口,也正是因为滚动窗口无缝衔接,所以每个数据都会被分配到一个窗口,而且只会属于一个窗口。
滚动窗口可以基于时间定义,也可以基于数据个数定义;需要的参数只有窗口大小,我们可以定义一个长度为1小时的滚动时间窗口,那么每个小时就会进行一次统计;或者定义一个长度为10的滚动计数窗口,就会每10个数进行一次统计
(2)滑动窗口(Sliding Windows)
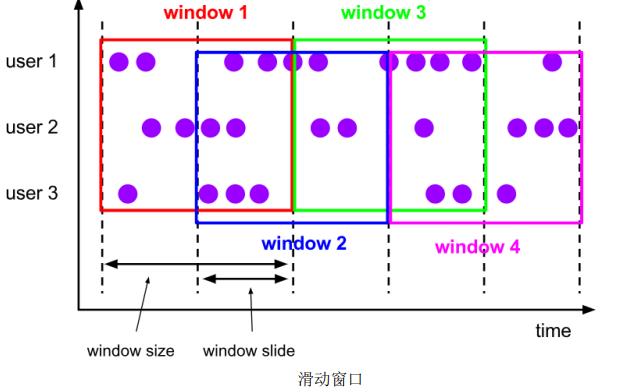
滑动窗口的大小固定,但窗口之间不是首尾相接,而有部分重合。滑动窗口可以基于时间定义、数据个数。
定义滑动窗口的参数与两个:窗口大小,滑动步长。滑动步长是固定的,且代表了两个个窗口开始/结束的时间间隔。数据分配到多个窗口的个数 = 窗口大小/滑动步长
(3)会话窗口(Session Windows)
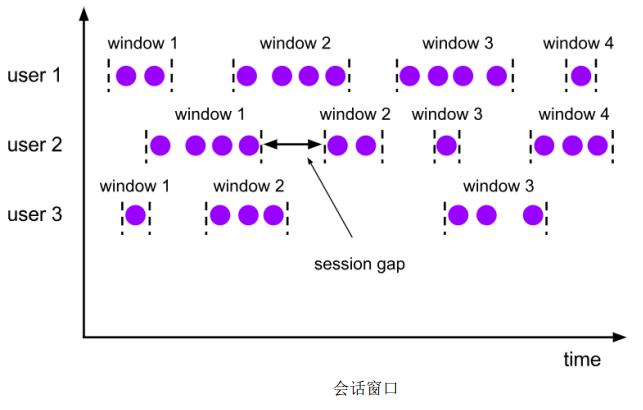
会话窗口只能基于时间来定义,“会话”终止的标志就是隔一段时间没有数据来。
简单来说就是数据来了之后就开启一个会话窗口,如果接下来还有数据,那就一直保持会话;如果一段时间一直没收到数据,那就认为会话超时,窗口失效自动关闭;
(4)全局窗口(Global Windows)

相同key的所有数据都分配到一个同一个窗口中;无界流的数据永无止境,窗口没有结束的时候,默认不做触发计算,如果希望对数据进行计算处理,还需要自定义“触发器”(Trigger)
特点
滚动窗口:窗口固定大小,无重复数据;
滑动窗口:窗口固定大小,有重复数据;
会话窗口:窗口不固定大小,窗口不重叠,数据无重复;
时间语义
作为Flink四大基石之一,时间语义可以说是我们Flink窗口计算不得不说的一个点,不仅仅在窗口中使用,在整个Flink框架中也是很重要的一个点;
相比较sparkStreaming只支持处理时间,Flink支持处理时间、事件时间、注入时间,同时也支持watermark机制来处理滞后的数据;
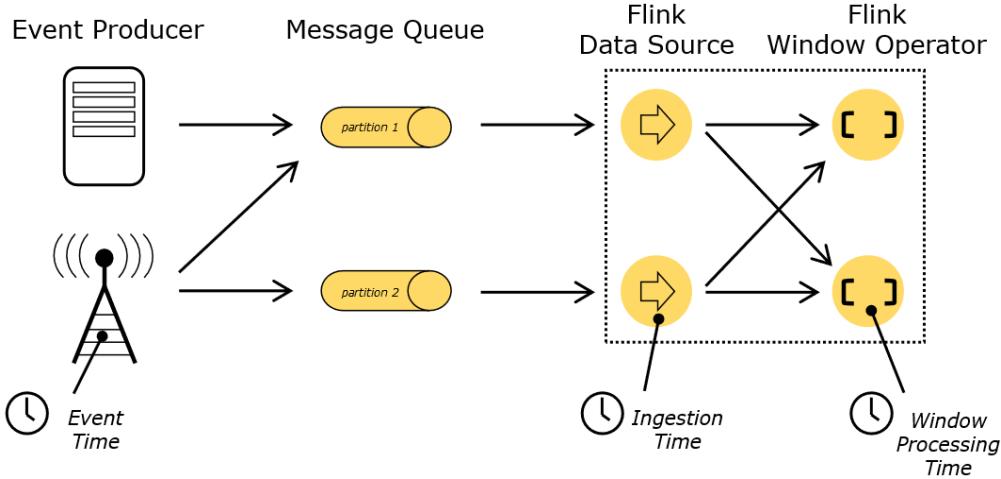
这里有【Event Time】事件创建的时间,也就是事件时间,通常是事件中的时间戳;【Ingestion Time】是数据进入Flink的时间,即注入时间,也是摄入时间;【Processing Time 】是每一个执行基于时间操作的算子本地系统时间,就是处理时间,与机器相关;默认的时间属性就是Processing Time。
Watermark 水位线
watermark是我们flink在进行窗口编程中用的最多的一种处理乱序事件的机制,通常我们流处理数据从事件产生到我们Flink程序中国进行处理是有一个过程的,在这个过程中大部分数据是按照事件产生的时间顺序来的,但也有各种原因导致乱序的产生,这时候就用到了我们的watermark水位线机制处理
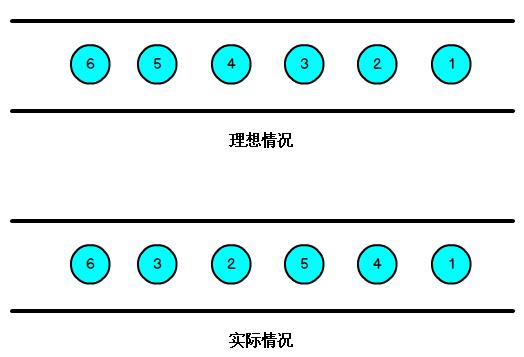
watermark本质上来说也就是一个特殊的时间戳,它的作用除了处理事件时间乱序的问题,还可以控制窗口的关闭;通常是结合window来实现:
// TODO 水位线 定义乱序程度
SingleOutputStreamOperator<JSONObject> watermarks = jsonObjDS.assignTimestampsAndWatermarks(
WatermarkStrategy.<JSONObject>forBoundedOutOfOrderness(Duration.ofSeconds(3))
.withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>()
@SneakyThrows
@Override
public long extractTimestamp(JSONObject element, long recordTimestamp)
long addTime = addTime = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(element.getString("addTime")).getTime();
return addTime;
)
);这里是通过对一个JSON事件流数据的一个最大乱序时间为3s的水位线设置,必须使用数据本身的一个时间戳来定义;
当然,处理乱序并不是所有的情况都需要,如果我们的事件流本身并没有时间乱序,那么就不需要设置我们的最大乱序时间
// TODO 水位线 定义乱序程度
SingleOutputStreamOperator<JSONObject> watermarks1 = jsonObjDS.assignTimestampsAndWatermarks(
WatermarkStrategy.<JSONObject>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<JSONObject>()
@SneakyThrows
@Override
public long extractTimestamp(JSONObject element, long recordTimestamp)
long addTime = addTime = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse(element.getString("addTime")).getTime();
return addTime;
)
);watermark能够衡量数据处理速度,保证事件数据全部到达Flink系统,或者在乱序及延迟到达时,也能够像预期一样计算出正确并连续的结果,当任何Event进入到Flink系统时,会根据当前最大事件时间产生Watermark时间戳;
Watermark = 进入Flink的最大的事件时间 - 指定的延迟时间;
以上是关于Flink窗口与水位线不得不说的秘密的主要内容,如果未能解决你的问题,请参考以下文章