Flink - The heartbeat of TaskManager with id container timed out 分析与 Heartbeat 简介
Posted BIT_666
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink - The heartbeat of TaskManager with id container timed out 分析与 Heartbeat 简介相关的知识,希望对你有一定的参考价值。
一.引言
Flink 运行任务期间报错 The heartbeat of TaskManager with id container timed out,对应任务由 Running 切换为 Failed,下面基于该问题进行排查与解决。

二.问题描述
该 Flink 任务 7x24 h 挂起,为 EventTime 模式下的有状态带 ValueState 作业,运行期间 ValueState 大小稳定,但程序会在 4-8 h 的不确定间隔下报错 The heartbeat of TaskManager with id container timed out,从而导致任务失败。

通过 yarn-streaming 任务日志可以看到任务分别在当天共重启3次:
Failed A -> 6:00 - 12:42 运行 6 h 42 min 后异常退出
Failed B -> 12:50 - 19:05 运行 6 h 15 min 后异常退出
Failed C -> 19: 10 - 22:52 运行 3 h 42 min 后异常退出
三次报错的异常栈都对应 The heartbeat of TaskManager with id container timed out,无其他显式的程序内报错,其中马赛克部分为对应 Timeout 机器,可以看到 Timeout 是在 Jobmanager 检测 TaskManager 的时候 Taskmanager 未在规定时间内 report 导致了 Timeout:

三.问题排查
1.资源问题
由于任务有 ValueState,所以运行期间可能存在短时流量高或者负载不均衡导致某台机器压力过载出现 RPC 回复超时等原因,所以优先查看对应 Timeout 的 Container 在 Failed 时间点前是否存在 CPU 压力过载或者内存超出的情况,这里 Contanier 可以理解为 TaskManager,上述日志出现时间为 18:45 左右,经过一次重启后 Failed,所以 Failed 时间为 19:05,下面检查下对应时间对应 Contanier 对应机器的压力。

查看对应机器信息,可以看到 CPU-Busy 即 CPU 利用率在 18:45 前大概维持在 50%-90% 之间,负载虽高但不至于达到 Failed 的程度,再看内存使用率,内存使用率在 56% 上缓慢浮动并未达到超过 80% 的高危情况,56% -> 53% 的跃阶段为程序根据 CKPT 重试导致的内存下降,而 19:05 附近从 53% 增加至 55% 左右则是因为任务重启导致的内存增加,最后查看 Load Average,平均负载也不高,所以此次 Timeout 基本排除是由于机器资源瓶颈导致的机器压力负载过高导致的。
2.网络问题
排除资源问题,再查看一下对应 18:45 附近机器是否存在网络流量过大导致机器压力过载的情况:

网络接收和发送速率相对值也不高,因此排除网络的问题。
四.问题解决
排除 Container 本身的 CPU、内存、IO 和 网路的问题外,可能是如下问题:
A.Jobmanager 内存不足
本例下为 Container Timeout,所以大概率排除该问题,不过同学了调试时也可以尝试加大 JM 内存
B.TaskManager 内存不足
本例下分析了 Contanier 的 CPU 使用率与内存使用率,整体有压力但不是压死骆驼的最后一根稻草,如果内存压力较大,可以尝试增大 TM 的内存
C.HeartBeat.Timeout 参数过小
还有一种情况比较好解决,就是单纯的 HeartBeat.Timeout 参数值太小,任务压力较大的情况下会有一定延时,该情况下只需提高参数值即可:

Flink 下关于 Heartbeat 的参数主要有如上几个参数,这里我们只需调整 heartbeat.timeout 即可,该参数默认为 50000 ms,这里直接提高 10 倍:
-yD heartbeat.timeout=500000 \\
修改为任务不再出现 4-8 H 左右 Failed 的情况,也未出现 The heartbeat of TaskManager with id container timed out 的报错异常栈,截止到这里异常解决已经搞定,有兴趣的同学可以看下后续的 heartbeat 机制分析。
五. Flink HeartBeat 简介
1.Flink 组件构成

Flink 主要包含 4 个组件:
| Dispatcher | 接收 APP 提交的任务并启动对应的 JobManager |
| JobManager | 转换 Execution Graph,向 RM 申请资源,保存元数据 |
| ResourceManager | 接收 JM 的资源请求,向 TM 分配 Slot 资源 |
| TaskManager | 负责任务具体的执行,多个 Slot 平分内存,共享缓存 |
一般而言,Flink 内部的 Heartbeat 心跳机制就是上述组件之间的互相通信以及确认对方是否保持 Aliver 状态,具体到任务执行主要是 RM、JM 与 TM 三者相互之间通信。
- ResourceManager 发送 send 请求检测 JobManager 与 TaskManager 是否 Alive
- JobManager 发送 send 请求检测 TaskManager 是否 Alive,根据重启策略决定重启或者退出
//设置重启策略 重启次数以及重启间隔
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(restartAttempts, delayBetweenAttempts));有 Spark 基础的同学可以把 Flink 组件进行类比,Dispatcher 看作是 AM 即 ApplicationMaster,ResourceManager 与 JobManager 不变,TaskManager 看作是 Executor,每个 slot 看作是 1个 core。
2.Flink 通信框架

基于报错日志我们可以看出来 Flink 的通信是基于 rpc 的 akka 实现的:
2.1 RPC
RPC,全称 Remote Procedure Call 即远程控制调控,主要用于分布式计算的远程通信,当一个过程在不同的地址空间执行时会发生此调用,对应 Flink 分布式场景下不同进程在多台执行机器。
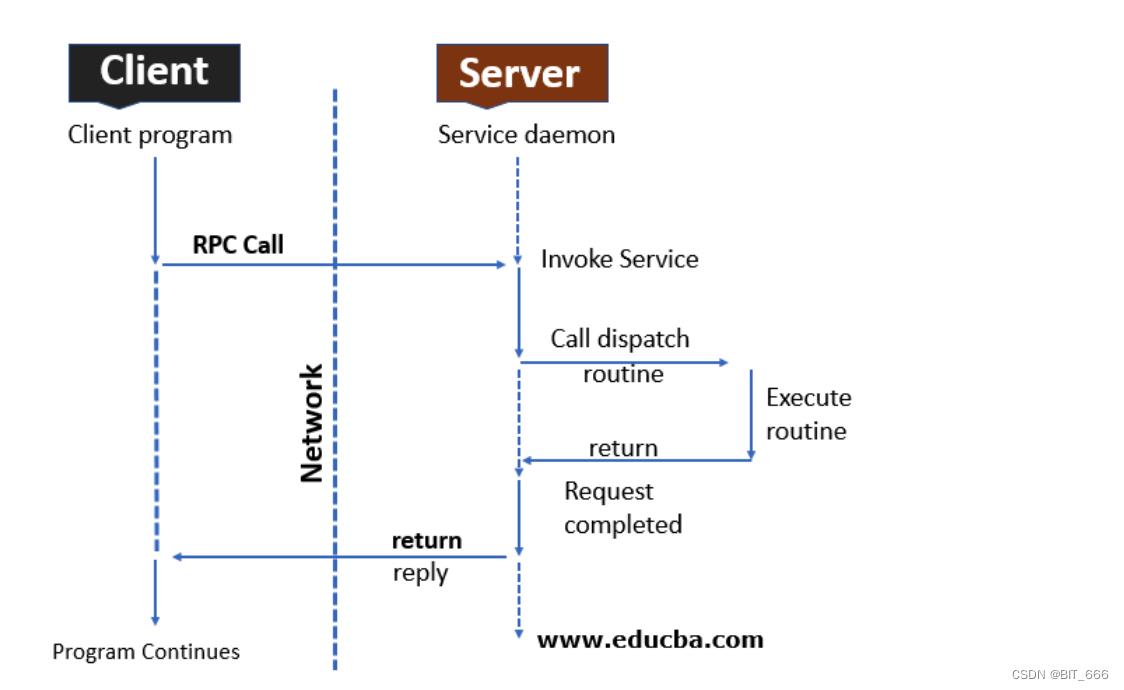
其过程可以简化为如下步骤:
- A. Client 向注册 RPC 服务的 Server 服务器机器发出 RPC 调用
- B. 调用系统参数传递至服务器机器 Server 端
- C. 服务端机器 Server 执行响应操作并作出 CallBack 回应到 Client 端
以 Flink JM 与 TM 心跳为例,JM 作为 Client 向 TM 发送心跳测试请求,TM 作为 Server 接收到 JM 发送的 heatbeat 请求,重置 heartbeat 检测周期并标记 JM 为活跃状态,最后 report 给 JM 信息,JM 接收到 TM 的信息,重置heartbeat 发送周期并标记 TM 为活跃状态,如果 TM 在规定的 timeout 范围内未回传 report 到 JM 中,则 JM 会执行相应的重启或退出指令。
2.2 Akka
Akka 用于在 JVM 平台上简化编写具有可容错的、高可伸缩性的 Java 和 Scala 的 Actor 模型应用,其同时提供了Java 和 Scala 的开发接口。Akka 允许我们专注于满足业务需求,而不是编写初级代码。在 Akka 中,Actor 之间通信的唯一机制就是消息传递。Akka 对 Actor 模型的使用提供了一个抽象级别,使得编写正确的并发、并行和分布式系统更加容易。Actor 模型贯穿了整个 Akka 库,为我们提供了一致的理解和使用它们的方法,其特点如下:
- A. 对并发模型进行抽象,使得编写并发系统更加容易
- B. 是异步、非阻塞、高性能的事件驱动编程模型
- C. 轻量级事件处理,Akka 基于 Actor 模型,1GB 可以存储百万级别 Actor
- D. 容错机制,所有 Actor 都受到监控,如果有故障会连接到新的 Actor 或重启 Actor
Akka 中最重要的概念就是 Actor,Actor 是 Akka 中的基本执行单元,并发模型中 Actor 主要负责信息的传递,一般通过 tell 或者 ask 发送消息给 Actor,tell 表示 'fire-and-forget' 即发送并忘记,例如异步发送消息并立即返回,ask 则是异步发送信息,并返回一个表示可能的答复,一般推荐使用 tell,因为它不用等待消息返回,因此是非阻塞的,这对并发提供了最佳的可伸缩性,因此 RPC 分布式通信计算时,会选择通过 Actor 完成信息的传递。
3.Flink 通信基类
上面简单介绍了 Flink 的框架构成与通信协议框架,下面简单看下 heartbeat 如何在不同组件间实现通信。
- A. HeartbeatTarget 监控目标抽象类
- B. HeartbeatMonitor 管理 Targer 心跳状态
- C. HeartbeatManager 心跳机制管理类
- D. HeartbeatListener 心跳结果处理类
3.1 HeartbeatTarget

HeartbeatTarget 抽象类为心跳的基础对象,其定义了2个抽象方法:
receiveHeartbeat:向某个节点发送心跳回应,ResourceID 对应 Receiver
requestHeartbeat:向某个节点要求回应一个心跳,ResourceID 对应 Sender
3.2 HeartbeatMonitor

getHeartbeatTarget 返回一个 HeartbeatTarget 实例,本质上是对 HeartbeatTarget 的一层封装,后续 HeartbeatMonitor 对 target 的操作都是基于 Monitor 执行,而不是直接操作 Target。
3.3 HeartbeatManager

继承 HeartbeatTarget 实现并增加了 4 个方法:
monitorTarget:把和某资源对应的节点加入到心跳监控列表
unmonitorTarget:从心跳监控列表删除某资源对应的节点
stop:停止心跳管理服务,释放资源
getLastHeartbeatFrom:获取某节点的最后一次心跳数据
3.4 HeartbeatListener

HeartbeatListener 负责实现用户处理心跳的逻辑,其实现了三个回调函数:
notifyHeartbeatTimeout:处理心跳超时的情况
reportPayload:处理节点发送的 Payload 荷载
retrievePayload:获取对某节点发下一次心跳请求 Payload 的荷载

从异常栈的最后一行可以看到,程序调用了 TaskManagerHeartbeatListener. notifyHeartbeatTimeout 处理了 TaskManager 心跳超时的情况,如果有重启策略则执行对应的重启策略,没有则任务异常退出。这里我们也看到了调用 TaskManagerHeartbeatListener 的父类,即 HeartbeatMonitorImpl,该类继承 HeartbeatMonitor 并实现了对 HeartbeatTarget 的处理。
4.Flink 通信实例
上述基类提供的均为 interface 接口,具体实现的 Heartbeat 类如下:
- A. HeartbeatManagerImpl - Receiver
- B. HeartbeatManagerSenderImpl - Sender
- C. HeartbeatMonitorImpl - Montior Target
- D. HeartbeatServices
4.1 HeartbeatManagerImpl

HeartbeatManagerImpl 即 Receiver,即 RPC 中的 Server,Flink 任务中的 TaskManager,接收 Client - JobManager 发出的心跳请求,心跳超时会触发 heartbeatListener 的 notifyHeartbeatTimeout 方法。hearbeatTargets 为同步 HashMap,维护了 TM 的 ID 到对应 HeartbeatMonitor 的一一对应。ScheduledExecutor 则负责 timeout notifications,关于 ScheduledExecutor 可以参考:newScheduledThreadPool : scheduleAtFixedRate 与 scheduleWithFixedDelay 详解。其主要包含三个方法:
monitorTarget
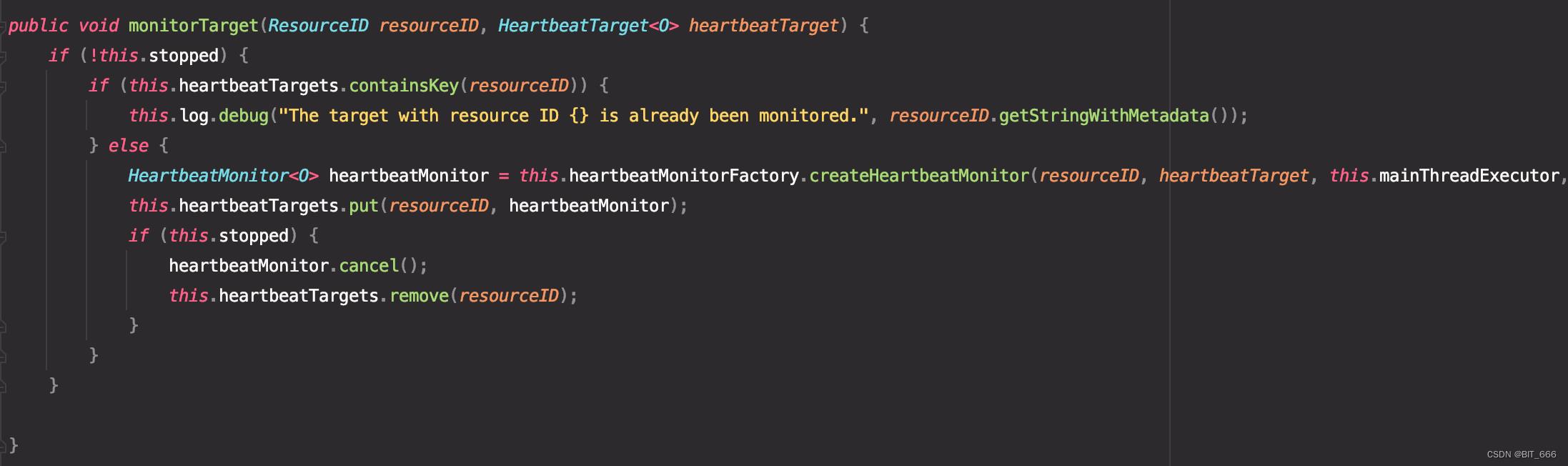
该方法负责生成对应 ResouceId 到 HeartbeatMonitor 的映射。stop 后,对应 hearbeatMonitor 取消并通过 remove 移除当前 TaskManager 的 ResourceId。
reportHearbeat
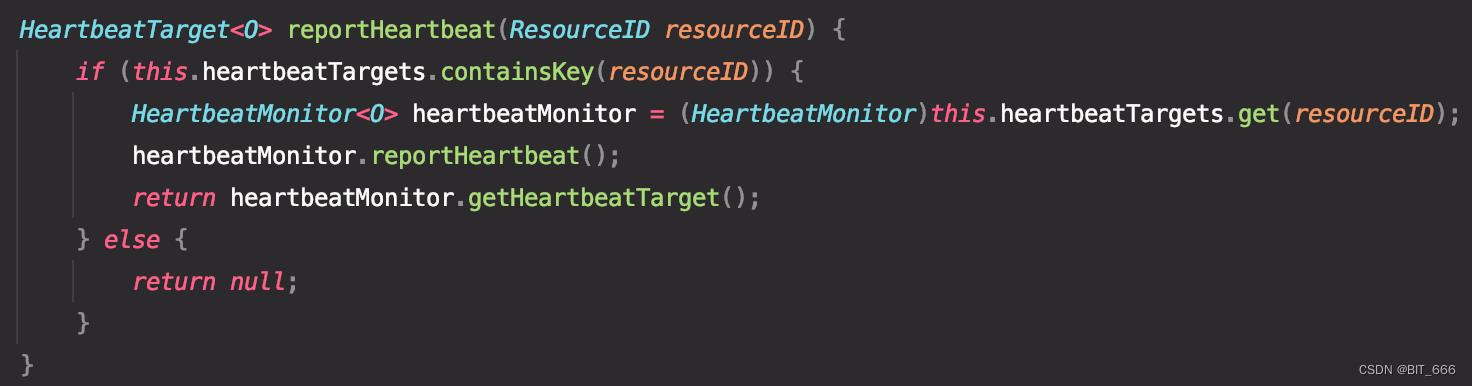
Receiver 通过 hearbeatTargets 索引当前 ResourceId 是否存在,并执行对应 reportHearbeat 操作。回看基类 heartbeatTarget:
receiveHeartbeat:向某个节点发送心跳回应,ResourceID 对应 Receiver,heartMonitor 执行完 report 操作后,return getHeartbeatTarget 即 receive。
requestHeartbeat

Sender 通过 RPC 异步调用到 HeartbeatManagerImpl 即 Recvier 的 requestHearbeat 函数,要求向 request 节点发起一次心跳香型,荷载为 heartbeatPayload。再回看基类 heartbeatTarget:
requestHeartbeat:向某个节点要求回应一个心跳,ResourceID 对应 Sender 即 requestOrigin,这里指的是发起请求的原始节点。
4.2 HeartbeatManagerSenderImpl
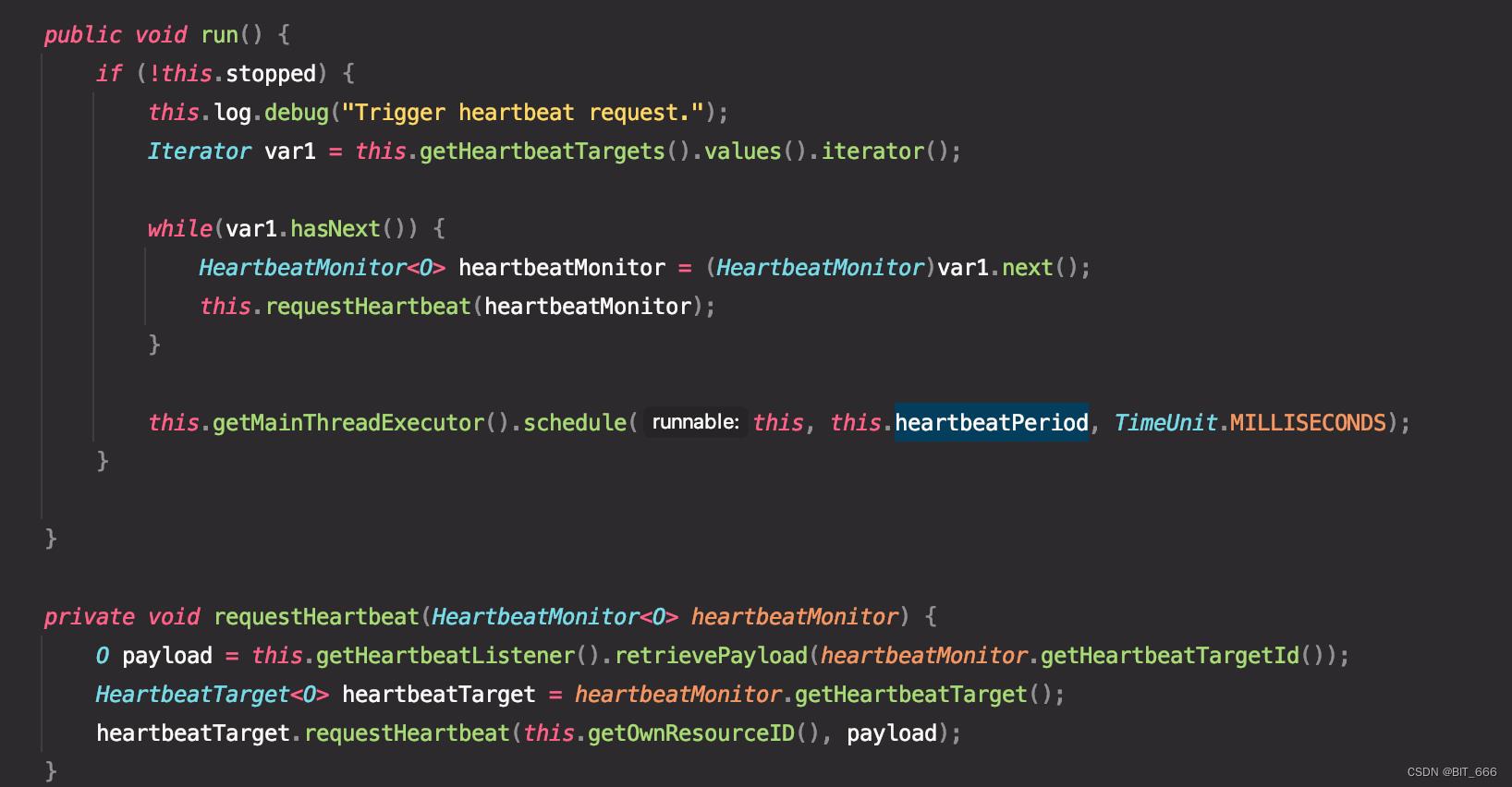
和 HeartbeatManagerImpl 差一个 Sender,该类为 Sender 的具体实现类,继承了 HeartbeatManagerImpl,该类一般由心跳发起方即 Sender 创建,例如 RM 或者 JM,且继承 Runnable 实现了 run 函数,因此可以做单独线程运行,run 方法内通过 iterator 的形式遍历 hearbeatTargets 并调用 request 方法依次发送心跳请求,并通过 schedule 实现周期性线程池的调用。
4.3 HeartbeatMonitorImpl
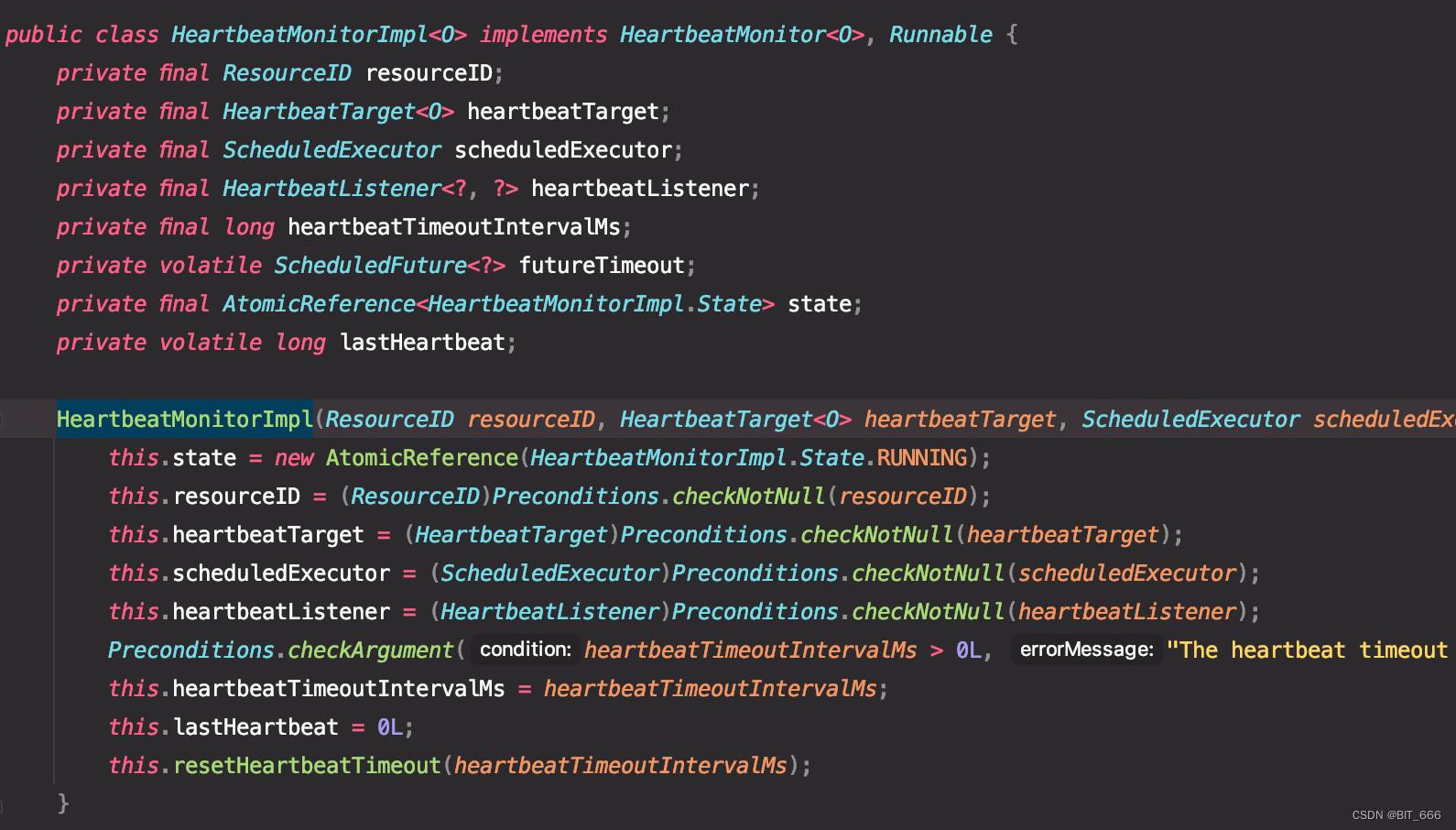
其内部构造了很多变量,我们主要看继承 Runnable 实现的 run 方法:

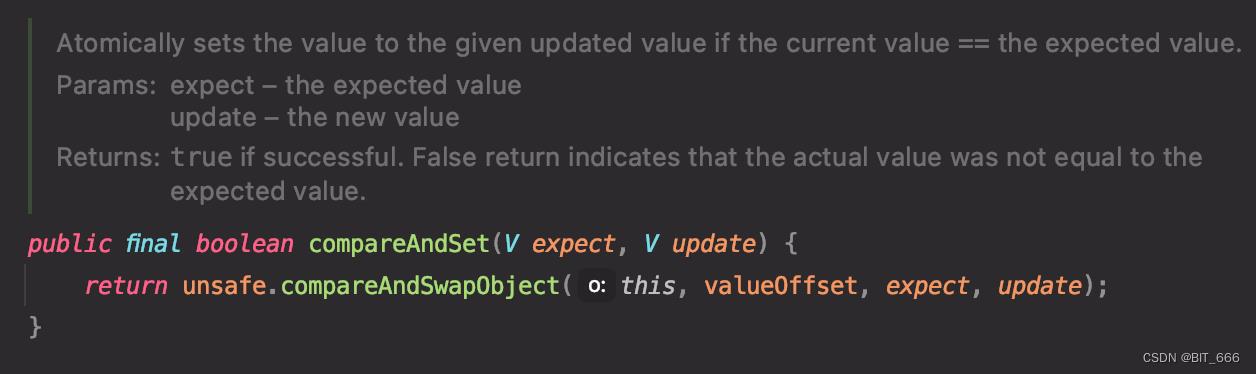
这里使用 compareAndSet,如果当前值与预期值相同,即当前值为 RUNNING,并将该值设定为给定的更新值,返回,否则将调用 Lisenter 的 notifyHeartbeatTimeout 函数处理心跳的情况。False 代表实际值不等于预期值。所以当 run 方法的 if 条件中当前 state 不为 Running 时,会引起 Timeout,并触发后续的 Timeout 操作,例如 The heartbeat of TaskManager with id container timed out 并退出任务。
4.4 HeartbeatServices

HeartbeatServices 为外部调用接口,其中初始化方法中有一个 fromConfiguration 函数,该方法获取 HEARTBEAT_INTERVAL 与 HEARTBEAT_TIMEOUT 参数,我们上面也提到过:
heartbeat.interval:多久执行一次心跳检测
heartbeat.timeout:超过多久没有回应视为超时
这两个参数都可以通过 -yD 配置到对应 Flink 提交脚本中,也可以通过 env 传入或者默认值配置到 flink-conf.yaml 文件下。
5.Heartbeat 过程
以 JobManager 为例:

JobMaster 初始化需要传入 HeartbeatServices,随后利用 Services 针对 RM 创建 ResouceManager 负责接收 ResourceManager 的 request 请求并返回心跳状态,而针对 TM 则是创建 HearbeatManagerSender,应该再 JM 与 TM 之间,JM 是 sender 方,从而实现与 TM 之间的心跳交互。
5.1 JM 初始化 TaskHeatbeatManager

jobMaster 内部初始化 taskManagerHeartbeatManager, 注意这里初始化的是 heartbeatManagerSender,因为 JM 要向 TM 发送 request 请求即 JM 为 Sender:

5.2 TM 注册到 JM
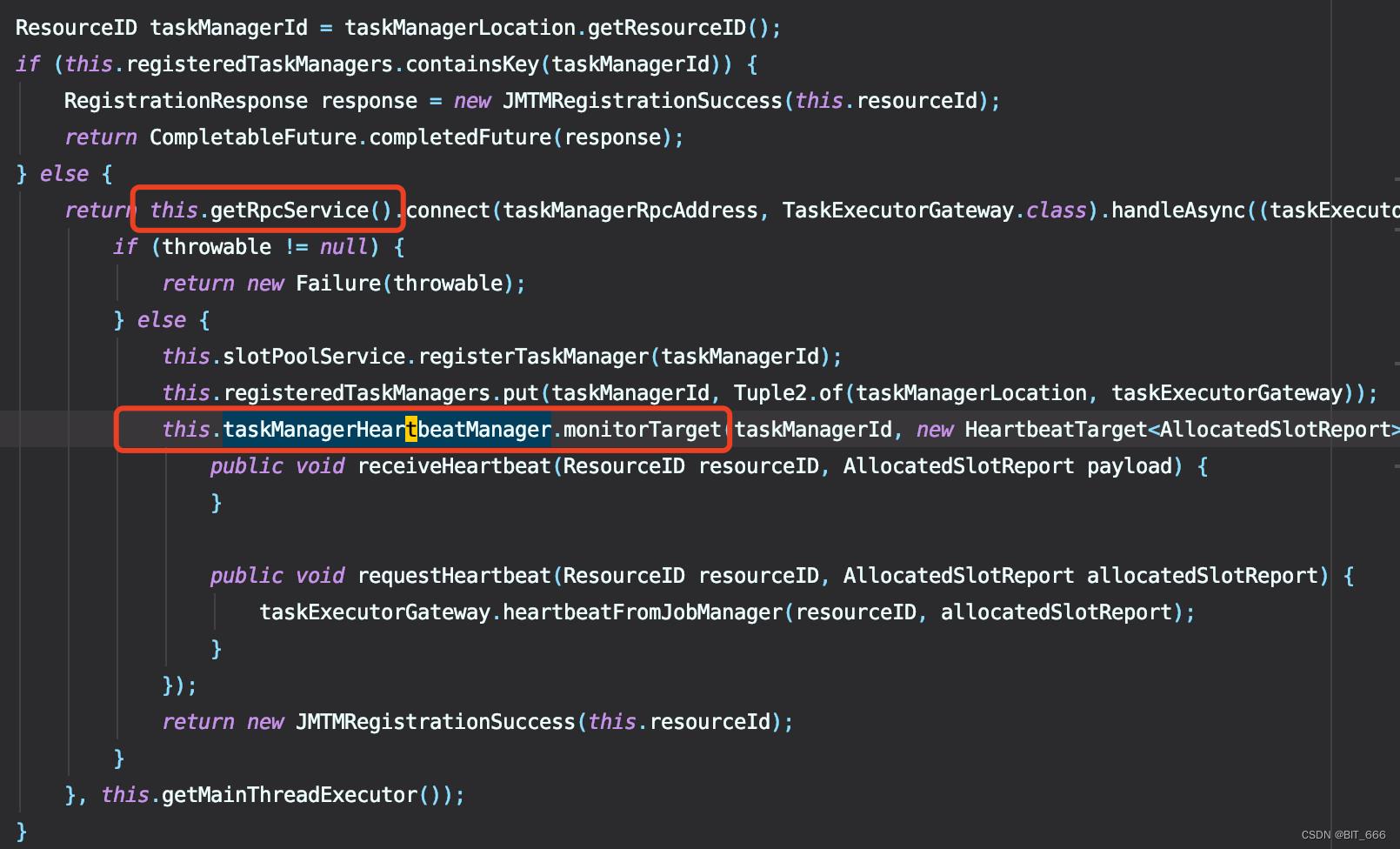
JM 除了初始化 heartbeatManagerSender 外,还会为 TaskManager 注册并生成对应 ResourceId 的 HeartbeatTarget 用于请求,通过 getRpcService 可以看出 JM 与 TM 之间通信通过 RPC,这里 Manager.monitor 将对应 TaskManager 的 ResouceId 与 Target 完成 kv 映射,由于 JM 向 TM 发送请求,所以这里初始化的 HeartbeatTarget 只实现了 requestHearbeat 方法,可以看到最终请求调用的是 taskExecutorGateway。
5.3 向 TM 发送心跳请求

TaskHeartbeatManager 注册形式为 HeartbeatManagerSenderImpl,内部 run 方法实现了遍历 ResourceId 并执行 heartbeat 的操作,上面我们也提到了,TaskManager 注册时只实现了requestHearbeat,其调用 request 方法其实是调用对应 HearbeatTarget 在 taskExecutorGateway 内部的方法:

这样 JM 内部的 TaskHearbeatManager 则实现了通过 RPC 调用至对应 HeartbeatTarget ResourceId 的机器。
5.4 TM 初始化 JobHeartbeatManager
与 JobMaster 类似,JM 与 RM 和 TM 通信,所以维护了 taskManagerHeartbeatManager 和
resourceManagerHeartbeatManager,TM 需要与 RM 与 JM 通信,所以 TaskExecutor 内初始化了 jobManagerHeartbeatManager 与 resourceManagerHeartbeatManager 用于存放 HeartbeatTarget 并实现相互的通信。
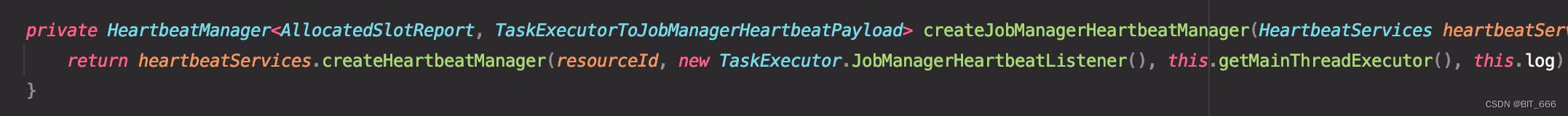
可以看到 TM 侧注册的类型为 HeartbeatManagerImpl,因为 TM 负责 Receiver 的任务:

这里初始化用到了 JobManagerHeartbeatListener 定义接收心跳后执行的事务,这里再重复下上面提到的 Listener 的三个主要函数:
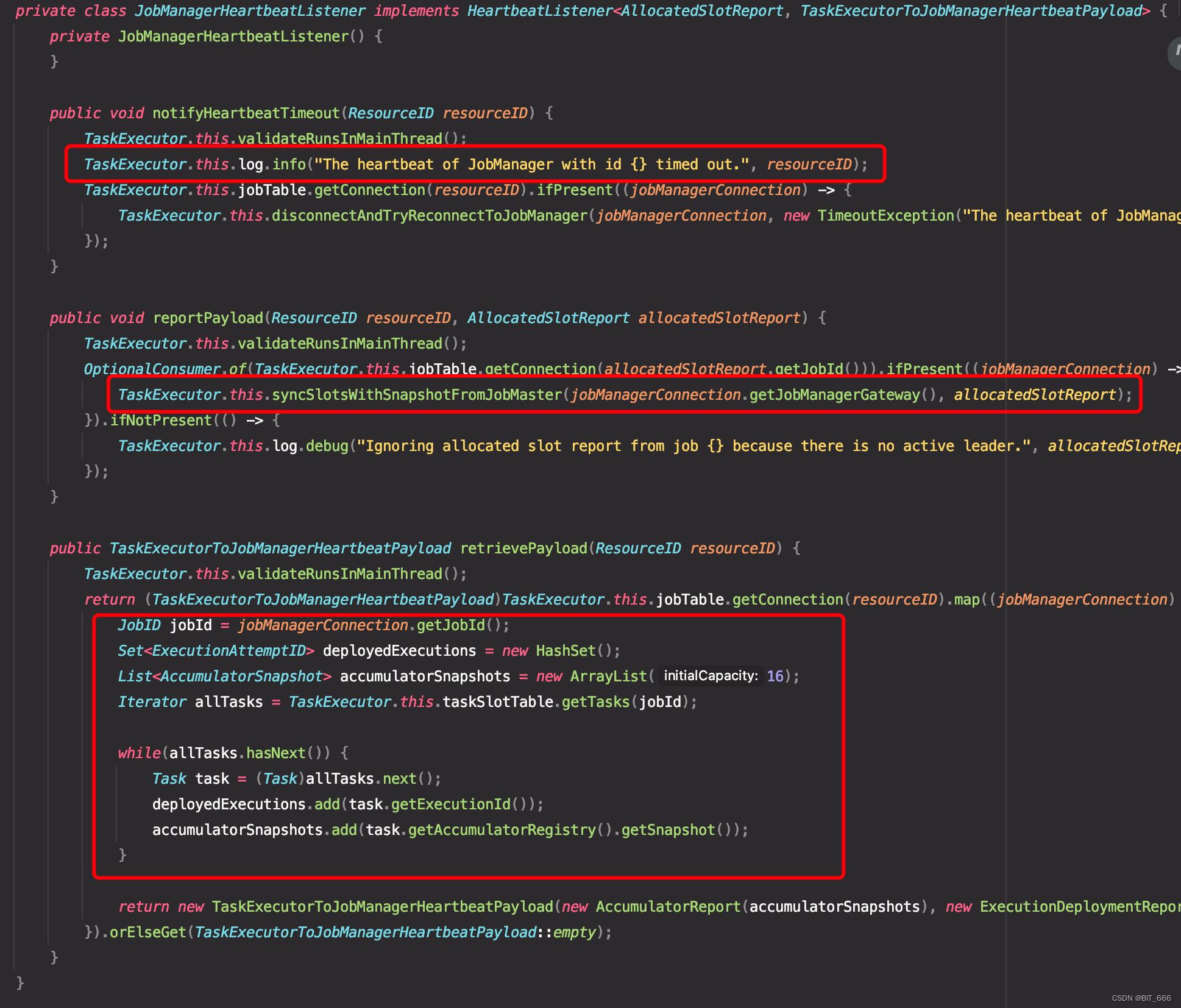
notifyHeartbeatTimeout:处理心跳超时的情况,这里超时的话报警 JM Timeout
reportPayload:处理节点发送的 Payload 荷载,这里 TM 接收了 JM 的 slot 信息
retrievePayload:获取对某节点发下一次心跳请求 Payload 的荷载 ,这里 TM 把 Slot 的 Snapshot 快照发送给 JM
5.5 TM 处理 Hearbeat 心跳

TaskManager 内实现了 hearbeatFromJobManager 的方法,由于这里初始化的是 HeartbeatManagerImpl ,所以对应的 requestHeartbeat 方法如下:

heartbeatTarget 通过 report 方法获取,如果非 null 且存在 Payload,则执行对应 reportPayload 方法,最后调用 reveiverHearbeat 方法向 JM 回复心跳。

这里 HeartbeatTarget 的 receive 方法是通过 JobMasterGateway 实现,与上面 request 通过 taskExecutorGateway 实现类似。
5.6 JM 接收 TM 心跳回复

TM 通过 Listener 的 retirevePayload 将 Slot 的 Snapshot 快照发送给 JM,JM 执行相应的 receiveHeartbeat 操作:
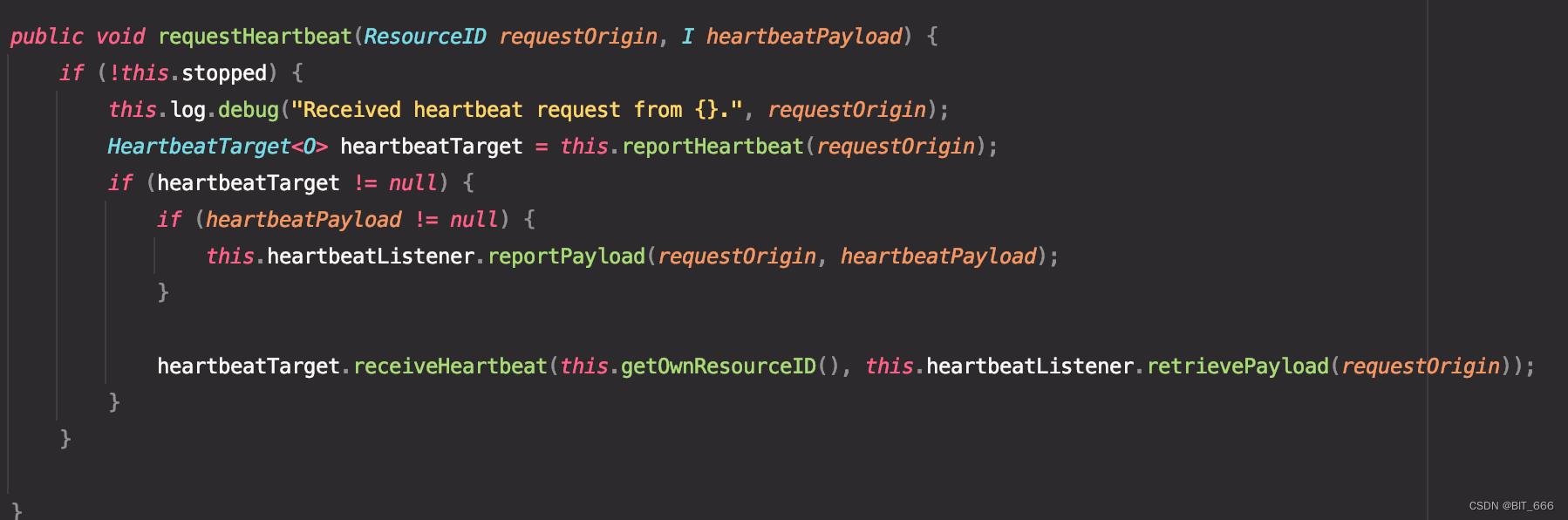
这里需要查看对应 TaskHeartbeatManager 初始化传入的 Listener 函数实现:

如果 JM 未正常收到 TM 传回的心跳信息,则报错,否则正常执行 Payload 相关操作:
new TimeoutException("Heartbeat of TaskManager with id " + resourceID.getStringWithMetadata() + " timed out.")是不是和我们最开始遇到的错似曾相识,终于回到最初的起点。至此一次 JM 到 TM 的心跳检测遍完成,总结一下:
- A. JM 与 TM 初始化对方的 ManagerHeatbeat 处理
- B. JM 负责 Sender 即 Request,TM 负责 Receiver 即 Receive
- C. JM 与 TM 通过 RPC 与对应 Gateway 通信
- D. JM 与 TM 之间传递信息通过 Payload 为载体
以上是关于Flink - The heartbeat of TaskManager with id container timed out 分析与 Heartbeat 简介的主要内容,如果未能解决你的问题,请参考以下文章