CycleGAN原理及实验(TensorFlow)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CycleGAN原理及实验(TensorFlow)相关的知识,希望对你有一定的参考价值。
参考技术A生成对抗网络(GAN)是一个十分有效的深度学习模型,由此衍生了CycleGAN。
先简单介绍一下GAN。
网络中有生成器G(generator)和鉴别器(Discriminator)。
有两个数据域分别为X,Y。G 负责把X域中的数据拿过来拼命地模仿成真实数据并把它们藏在真实数据中,而 D 就拼命地要把伪造数据和真实数据分开。经过二者的博弈以后,G 的伪造技术越来越厉害,D 的鉴别技术也越来越厉害。直到 D 再也分不出数据是真实的还是 G 生成的数据的时候,这个对抗的过程达到一个动态的平衡。
传统的GAN是单向的:
训练这个单向GAN需要两个loss:生成器的重建Loss和判别器的判别Loss。
1. 重建Loss :希望生成的图片Gba(Gab(a))与原图a尽可能的相似。
CycleGAN本质上是两个镜像对称的GAN,构成了一个环形网络。
两个GAN共享两个生成器,并各自带一个判别器,即共有两个判别器和两个生成器。一个单向GAN两个loss,两个即共四个loss。
论文里最终使用均方误差损失表示:
CycleGAN的网络架构如图所示:
可以实现无配对的两个图片集的训练是CycleGAN与Pixel2Pixel相比的一个典型优点。但是我们仍然需要通过训练创建这个映射来确保输入图像和生成图像间存在有意义的关联,即输入输出共享一些特征。
简而言之,该模型通过从域DA获取输入图像,该输入图像被传递到第一个生成器GeneratorA→B,其任务是将来自域DA的给定图像转换到目标域DB中的图像。然后这个新生成的图像被传递到另一个生成器GeneratorB→A,其任务是在原始域DA转换回图像CyclicA,这里可与自动编码器作对比。这个输出图像必须与原始输入图像相似,用来定义非配对数据集中原来不存在的有意义映射。
鉴别器将一张图像作为输入,并尝试预测其为原始图像或是生成器的输出图像。
鉴别器本身属于卷积网络,需要从图像中提取特征,再通过添加产生一维输出的卷积层来确定提取的特征是否属于特定类别。
分别有大约2万张男人与女人的脸作为输入的训练集。
项目中提供了build_data.py脚本,修改训练集的路径,运行即可。
将data/test.jpg替换为对应的输入图片地址
训练时踩了比较多坑。由于急于看结果用了比较高的学习率。大概迭代五万次的时候可以有一点能看的结果,10万次时多数还可以接受。但是仍然有许多问题,比如戴眼镜,脸上亮度不均匀,角度奇异等都可能引起生成的图像中噪声较大的问题。
转换的特征通常为面部五官特征以及肤色亮度等,不包括发型,因此男女转化之后显得比较诡异。。
比如
未完待续。。
CycleGAN的原理及Pytorch实现
follow this video: https://www.youtube.com/watch?v=4LktBHGCNfw
paper: https://arxiv.org/pdf/1703.10593.pdf
只讲我关注到的,与Pix2Pix的区别之处
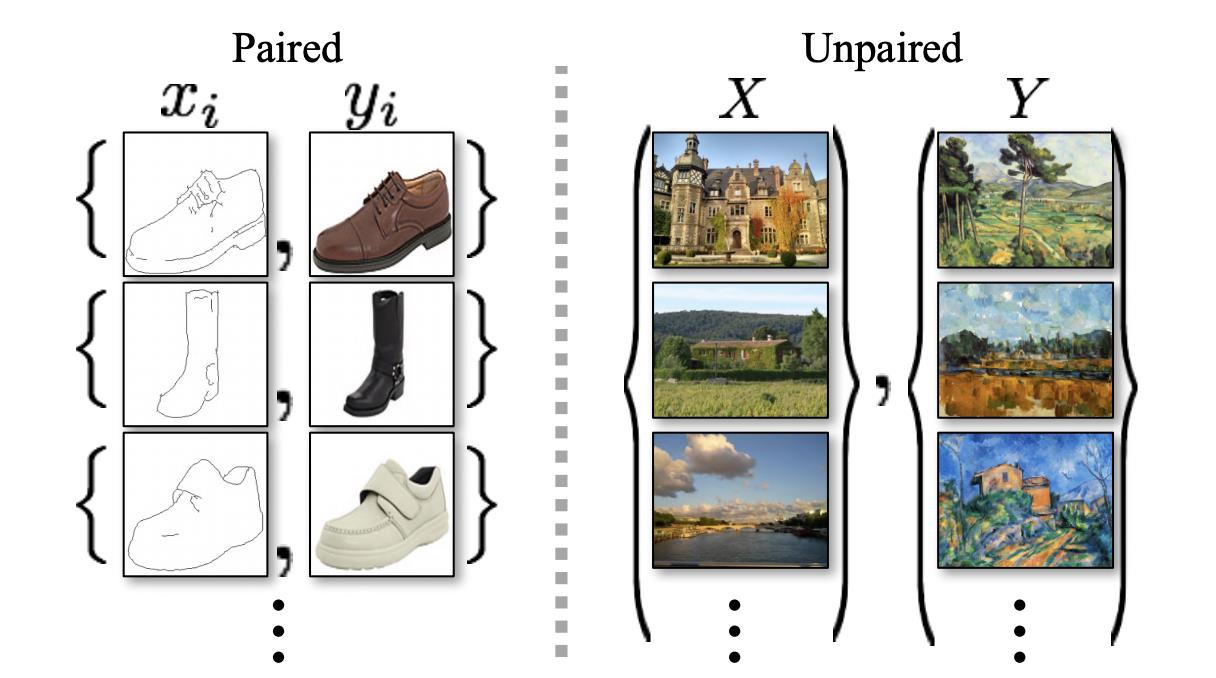
区别一:不需要成对匹配的数据
CycleGAN是两个集合的转换,不需要建立元素的一一映射
区别二:增加了cycle-consistency loss
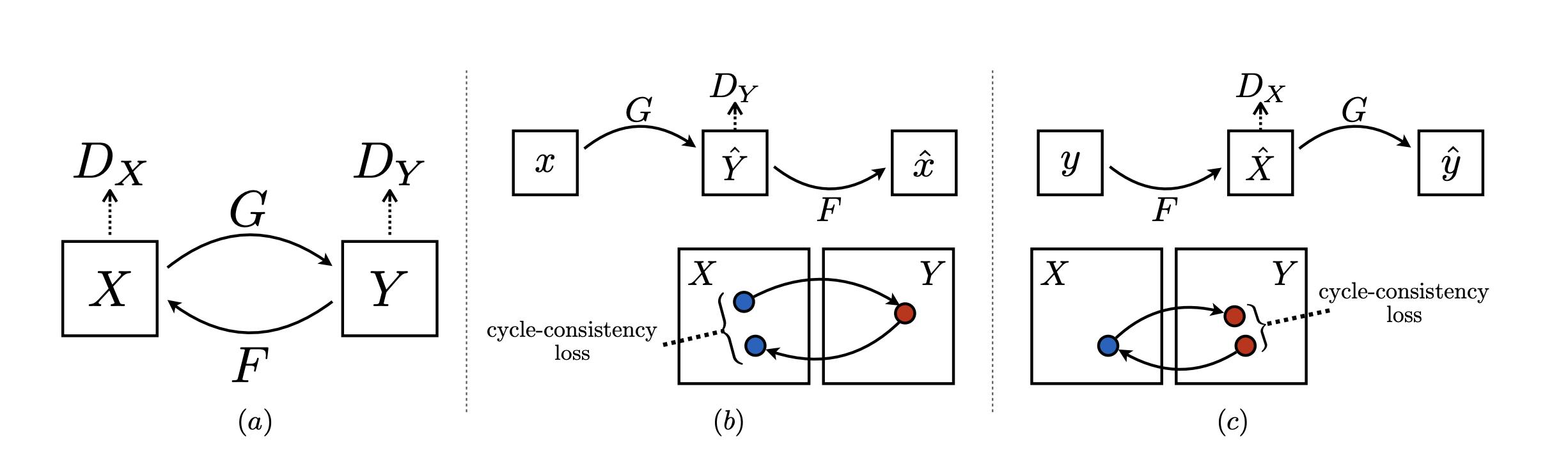
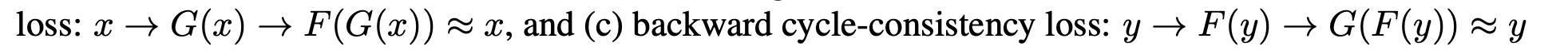
每种loss代表什么实际含义呢?

GAN alone 和 GAN+forward 遭受了模式奔溃, 不管输入什么图片,产生相同的输出。
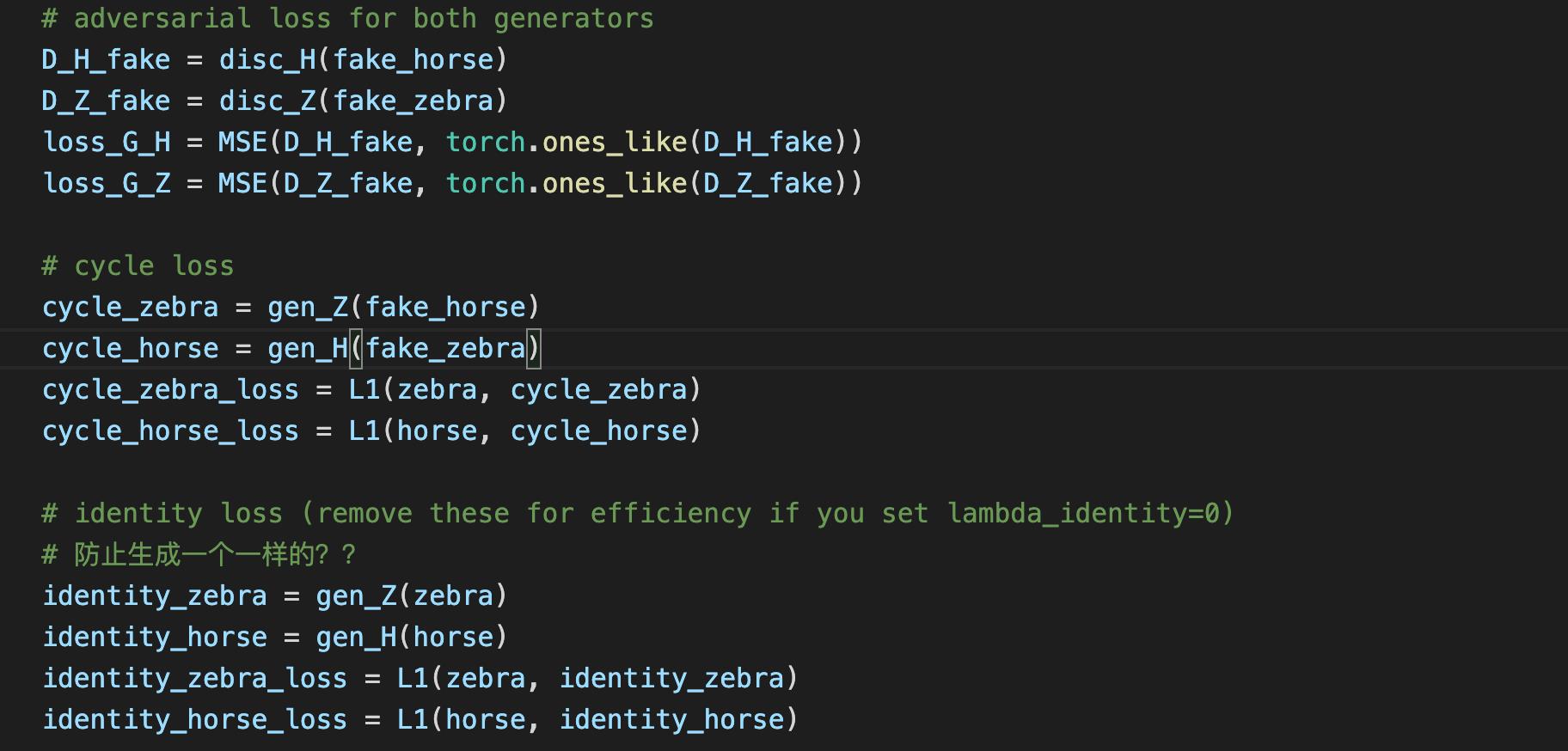
区别三:增加了identity loss
Lidentity有助于保持和输入图片一样的颜色,没有Lidentity时,生成器G和F会改变输入图片的色调当它们不需要时,例如把早上的图片映射成傍晚的图片,因为这同样满足adversarial loss和cycle consistency loss.

区别四:生成器有residual Blocks
生成器采用残差模块,虽然据说像Pix2Pix一样使用U-Net效果也不错;
识别器还是用PatchGAN,不过论文里输出是70 x 70,我实现上还是用 30 x 30;

完整代码:https://github.com/growvv/GAN-Pytorch/tree/main/CycleGAN
以上是关于CycleGAN原理及实验(TensorFlow)的主要内容,如果未能解决你的问题,请参考以下文章