大模型系统和应用——Transformer&预训练语言模型
Posted 愤怒的可乐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大模型系统和应用——Transformer&预训练语言模型相关的知识,希望对你有一定的参考价值。
引言
最近在公众号中了解到了刘知远团队退出的视频课程《大模型交叉研讨课》,看了目录觉得不错,因此拜读一下。
观看地址: https://www.bilibili.com/video/BV1UG411p7zv
目录:
- 自然语言处理&大模型基础
- 神经网络基础
- Transformer&PLM
- Prompt Tuning & Delta Tuning
- 高效训练&模型压缩
- 基于大模型的文本理解与生成
- 大模型与生物医学
- 大模型与法律智能
- 大模型与脑科学
注意力机制
原理
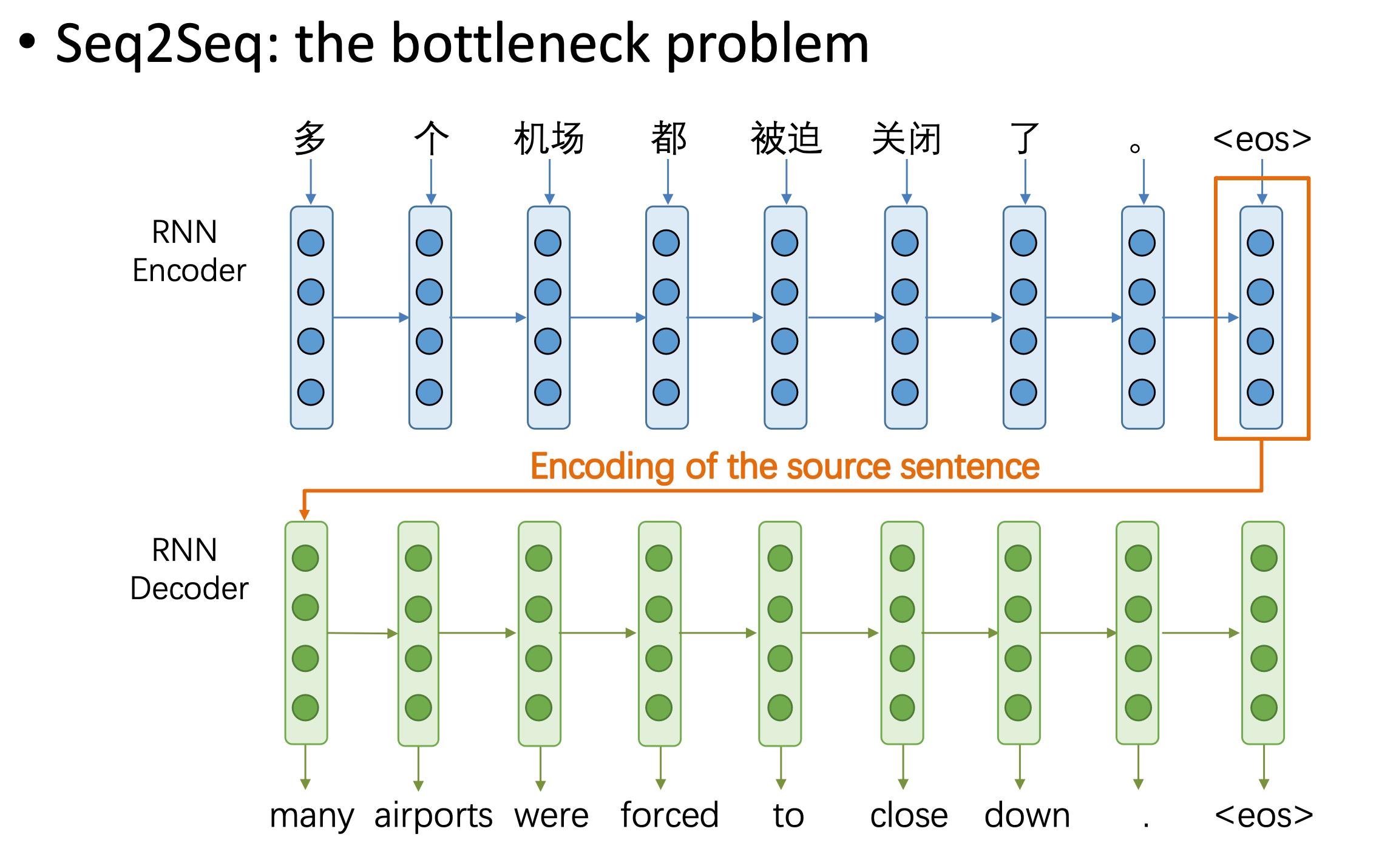
我们先看常规的seq2seq模型,该模型存在一个信息瓶颈的问题。
即解码器需要从编码器最后生成的向量中得到句子的所有信息。但由于该向量时定长的,它并不一定能表达任意长度的句子信息。
而注意力机制(Attention)就是为了解决该问题而提出的。
其核心思想是在解码器中每一步都能看到编码器中所有时间步生成的向量(隐藏状态)。这样解码器根据自己当前的状态来自动选择需要使用的信息和向量。
下面我们通过一个具体的例子来理解。

首先看到的是一个编码器, 用蓝色来表示。而解码器,用绿色来表示。
这里编码器得到了7个隐藏状态向量。这里可以看到解码器的第一个隐藏状态 s 1 s_1 s1。
与之前的不同的是,我们不是用这个 s 1 s_1 s1来计算这一步生成的单词概率,而是利用它来选关注输入句子中的哪些部分。并计算一个新的隐向量,来计算生成单词的概率。
具体地,首先计算所谓注意力分数,怎么做呢?
将
s
1
s_1
s1与编码器中所有时间步的向量进行点积,比如,第一步是与
h
1
h_1
h1进行点积,得到一个标量
e
1
1
=
s
1
T
h
1
e^1_1=s_1^Th_1
e11=s1Th1,作为分数表示。

随后让
s
1
s_1
s1与编码器第二个向量进行点乘,得到
e
2
1
e^1_2
e21。可以看到,
e
2
1
e^1_2
e21表示由解码器第一个时间步的向量与编码器第二个时间步的向量计算。
以此类推,我们计算编码器所有这7个隐藏状态向量的注意力得分。
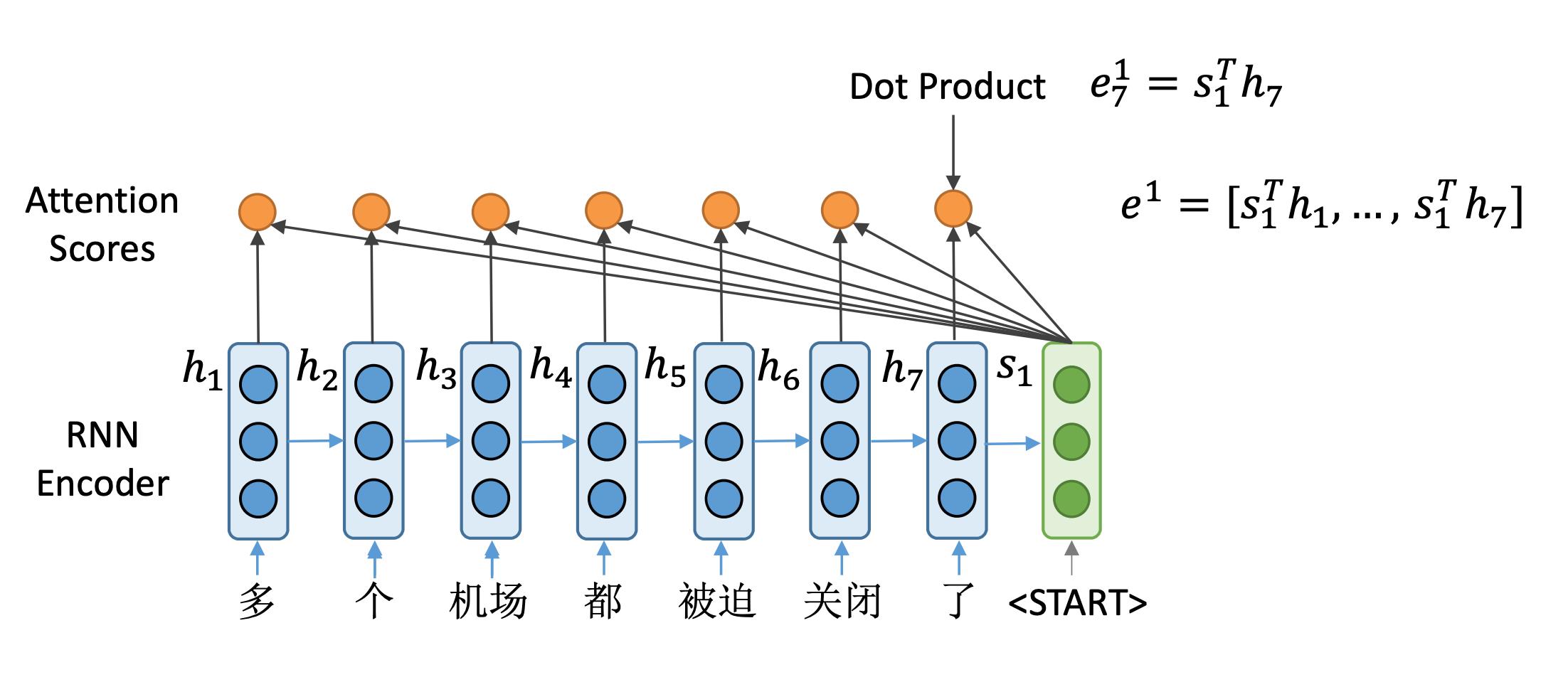
这样得到了一个长度为7的向量 e 1 e^1 e1,它就是解码器端隐藏状态向量的一个注意力分数。表示了 s 1 s_1 s1与每一个编码器端隐向量的相似程度。

有了这样一个注意力分数之后呢,经过Softmax就可以变成一个概率分布。可以看到,在本例中前两个向量的概率值比较高,说明解码器在第一步最关心的是前两个输入。
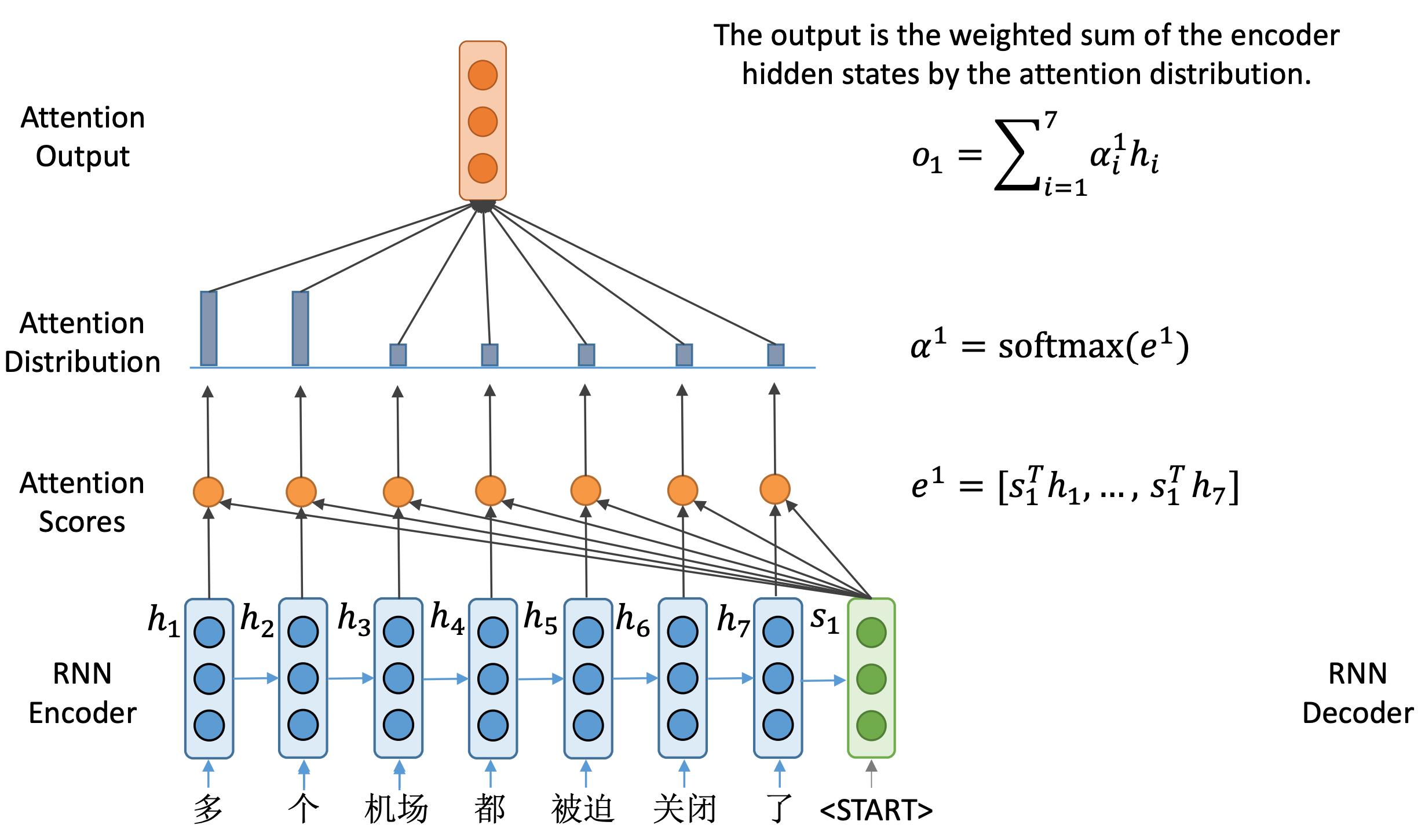
我们然后通过这样一个注意力概率分布对编码器端的隐藏状态做一个加权和,得到与隐藏状态维度相同的输出向量
o
1
o_1
o1。该向量包含了解码器当前所需要的编码器端的所有信息。
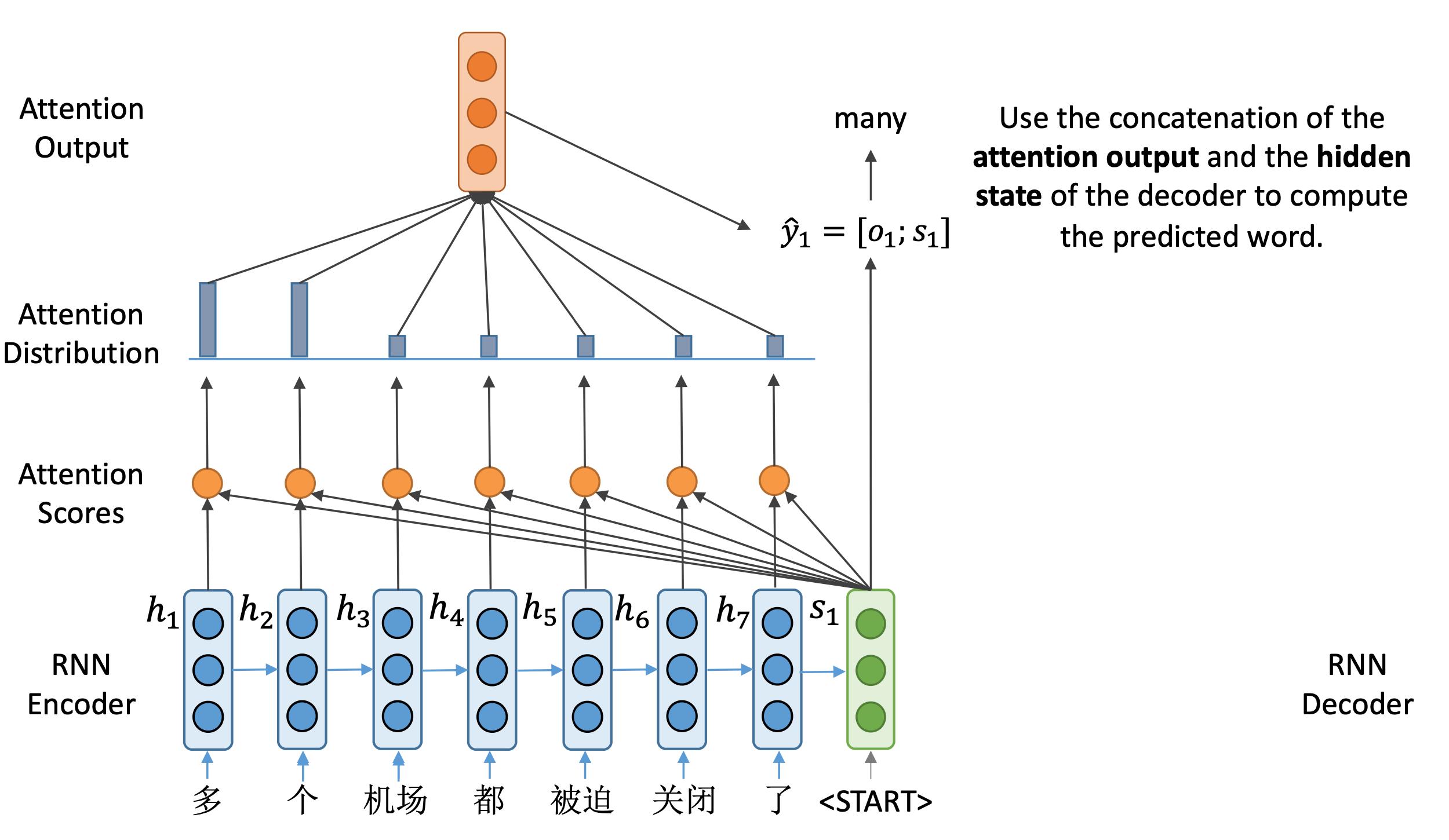
最后让
o
1
o_1
o1与解码器得到的隐藏状态进行拼接得到
y
^
1
=
[
o
1
;
s
1
]
\\hat y_1 =[o_1;s_1]
y^1=[o1;s1],来计算当前时刻输出单词的概率分布。在本例中,我们得到many这样一个输出,对应输入中两个字:“多"和"个”。
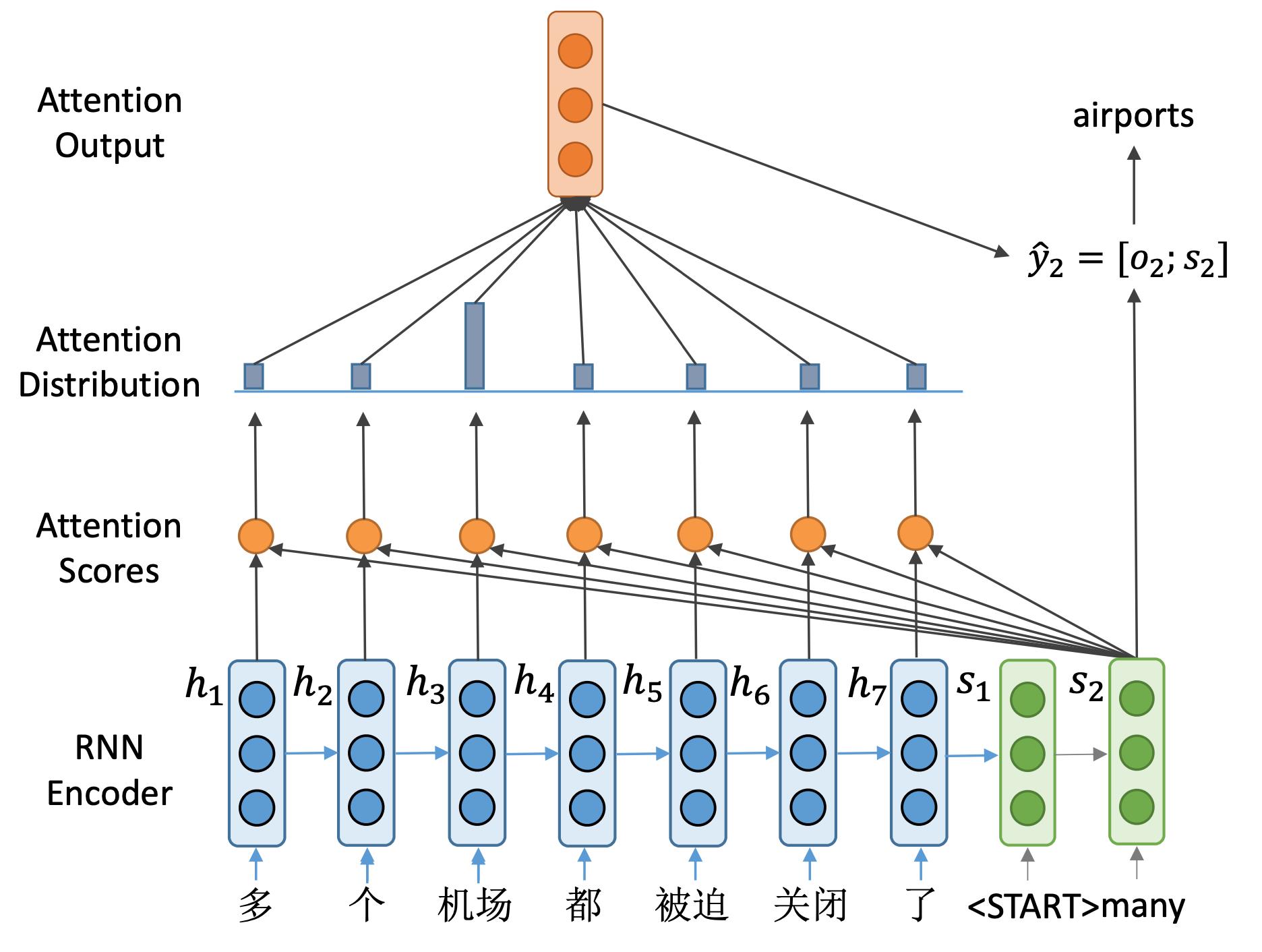
随后,将many输入到解码器,得到下一个隐藏状态
s
2
s_2
s2,通过同样的步骤,计算出
y
^
2
\\hat y_2
y^2,进行预测得到输出单词airports。

重复此过程,直到完成整个句子的翻译。
下面我们对前面提到的过程进行总结:
- 计算编码器隐藏状态 h 1 , h 2 , ⋯ , h N ∈ R h h_1,h_2,\\cdots,h_N \\in \\Bbb R^h h1,h2,⋯,hN∈Rh
- 计算解码器每步的隐藏状态 s t ∈ R h s_t \\in \\Bbb R^h st∈Rh
- 计算每步的注意力分数 e t = [ s t T h 1 , ⋯ , s t T h N ] ∈ R N e^t =[s^T_th_1,\\cdots,s_t^Th_N] \\in \\Bbb R^N et=[stTh1,⋯,stThN]∈RN
- 利用softmax得到注意力分布 α t = softmax ( e t ) ∈ R N \\alpha^t = \\textsoftmax(e^t) \\in \\Bbb R^N αt=softmax(et)∈RN
- 使用该注意力分布对编码器隐藏状态计算加权和作为注意力输出 o t = ∑ i = 1 N α i t h i ∈ R h o_t = \\sum_i=1^N \\alpha_i^t h_i \\in \\Bbb R^h ot=∑i=1Nαithi∈Rh
- 拼接注意力输出和解码器隐藏状态 [ o t ; s t ] ∈ R 2 h [o_t;s_t] \\in \\Bbb R^2h [ot;st]∈R2h来进行预测
我们可以对前面计算注意力的过程给出一个更加抽象的定义。
给定一个query向量和一系列的value向量,分别对应解码器端的隐向量和编码器端的隐向量,那么注意力机制就是根据query向量对value向量进行加权和。
因此,我们可以发现——注意力机制的本质就是value向量的加权和。同时,value向量长度是非固定的。最终我们可以通过注意力机制获取综合了所有value向量的定长的向量表示。
变体
注意力机制的计算有几种常见的变体。基本的就是上面介绍的点积
e
i
=
s
T
h
i
∈
R
e_i = s^Th_i \\in \\Bbb R
ei=sThi∈R
这是基于编码器和解码器隐藏状态向量的维度是一致的情况。我们分别用
d
1
d_1
d1和
d
2
d_2
d2表示。
如果这两个向量维度不一致,那么就需要在中间加上一个权重矩阵。
e i = s T W h i ∈ R , W ∈ R d 2 × d 1 e_i = s^TWh_i \\in \\Bbb R,\\quad W \\in \\Bbb R^d_2 \\times d_1 ei=sTWhi∈R,W∈Rd2×d1
第二种变体比较复杂,它使用了单层的神经网络将两个向量变成一个标量。
e
i
=
v
T
tanh
(
W
1
h
i
+
W
2
s
)
∈
R
e_i = v^T \\tanh (W_1 h_i + W_2 s) \\in \\Bbb R
ei=vTtanh(W1hi+W2s)∈R
其中
W
1
∈
R
d
3
×
d
1
,
W
2
∈
R
d
3
×
d
2
W_1 \\in \\Bbb R^d_3 \\times d_1, W_2 \\in \\Bbb R^d_3 \\times d_2
W1∈Rd3×d1以上是关于大模型系统和应用——Transformer&预训练语言模型的主要内容,如果未能解决你的问题,请参考以下文章