JupyterNumpyPandas
Posted Zephyr丶J
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JupyterNumpyPandas相关的知识,希望对你有一定的参考价值。
jupyter的下载和使用
下载numpy、pandas、matplotlib三个必备的包
交互式环境ipyhon
pip install ipython
建议使用jupyter(基于ipython)
pip install jupyter
jupyter会自动保存
然后在要打开jupyter的路径下启动命令窗口
然后输入jupyter notebook
就可以以这个路径为根目录打开jupyter
然后自动会在默认浏览器打开jupyter,或者复制命令行中的链接,在浏览器中打开
ipynb文件是mardown语法的
选中一个单元,按A会在上方创建一个单元,按住B会下下方创建
对于每一个小的单元,按两次D键删除
按Z键撤销,恢复
crtl+回车 运行单元里面的代码
M,变成markdown模式
按Tab自动补全
shift+Tab提示函数参数(一次Tab是简单的提示,两次Tab详细提示)
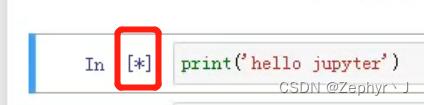
代码在执行的时候,前面会有*号,窗口会有漏斗标志
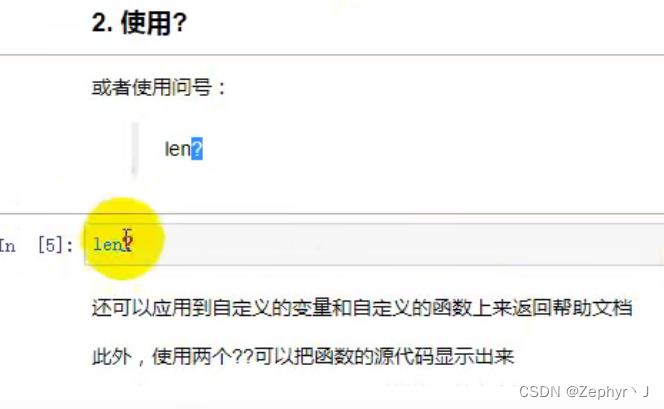
一个?打印docstring,两个??打印源码
?也可以使用在自己写的函数上
%run xxx.py(相对路径或者绝对路径)
执行外部的脚本或者python文件
如果执行了外部的文件,那么该文件内的函数就能直接在当前会话中使用

运行记时:%time statement,只能记录运行一次的时间
运行多次的平均时间 %timeit statement
也可以通过参数指定跑多少次


如果想测多条语句的运行时间,%%timeit

如果运行结果太长,会自动将结果折叠起来,需要滚动查看;点击左边会展开;双击会隐藏

%who 当前窗口中所有的变量和函数
%whos who的详细信息
%who_ls 返回一个字符串列表,里面是当前会话中的所有变量和函数名称,可以直接用列表中的变量使用

如果要执行系统命令,用!+命令 的形式执行
相当于将命令行搬到了jupyter中
lsmagic 显示出支持的所有魔法命令


%matplotlib inline 可以在Ipython编译器里直接使用,功能是可以内嵌绘图,并且可以省略掉plt.show()这一步。
Numpy
numpy提供的不是真正的矩阵,可以当作优化过的多维列表
scipy提供熟悉意义上的矩阵
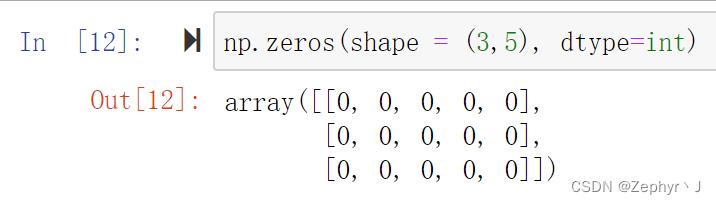
创建
-
由列表创建

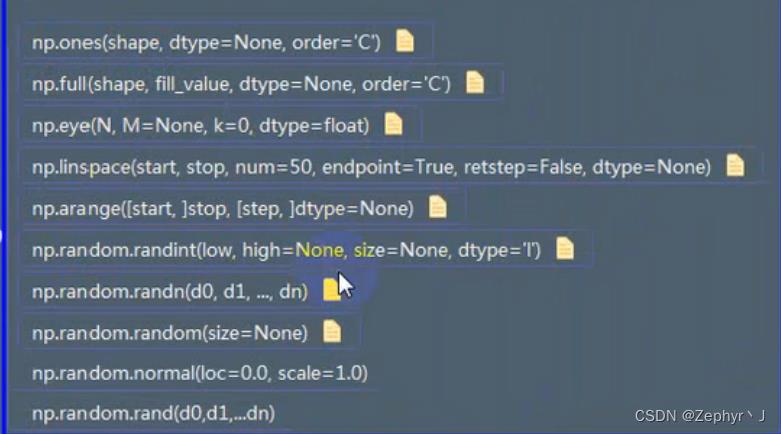


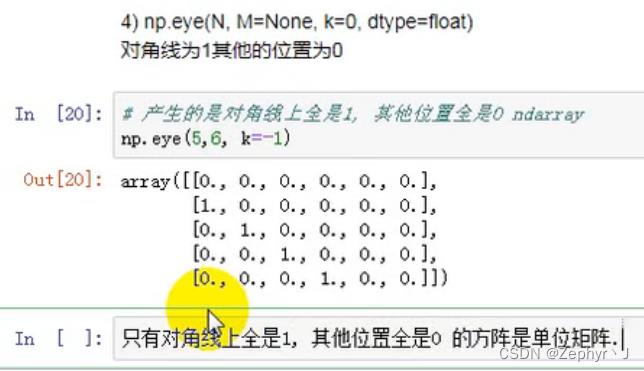
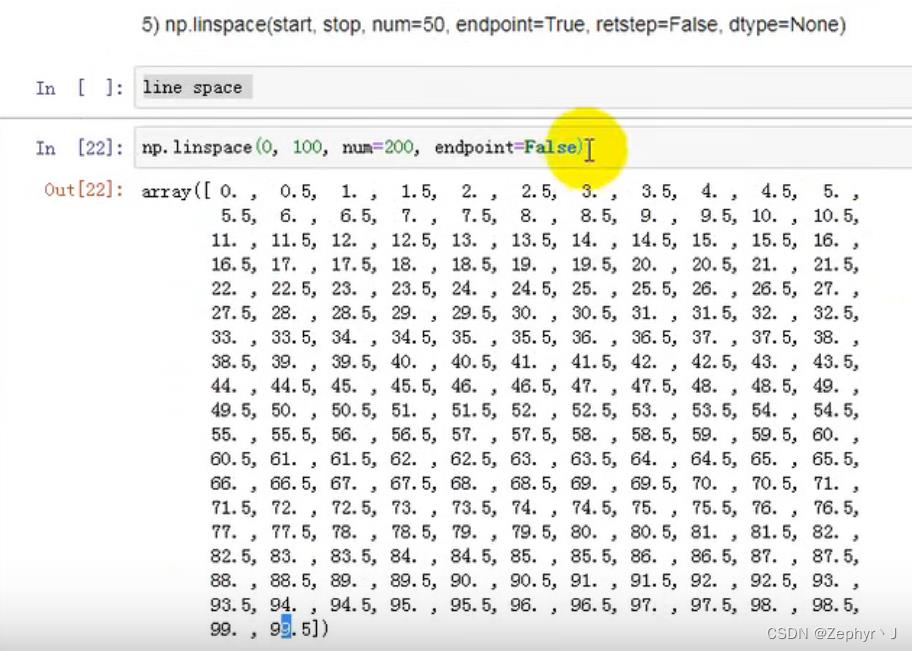
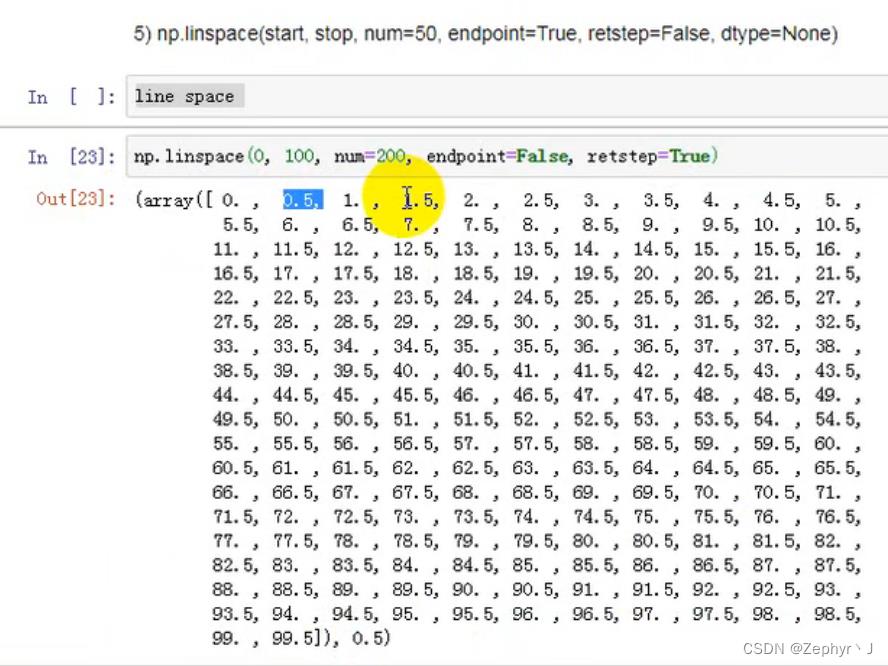
retstep加上以后变成元组


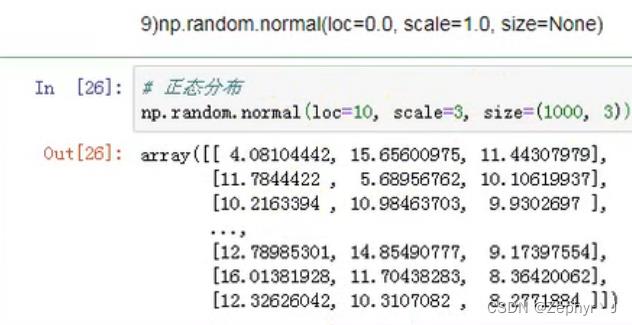
产生正态分布的数据,loc均值,scale标准差
标准正态分布,参数是各个维度

可以用这个直接写,不需要加size=(),和np.random.random()一样
属性

基本操作
一维的和列表是一样的
多维的索引操作

切片

取多个任意位置的数,需要用到np.ix_()方法

变形
reshape,参数是一个元组,总体元素个数不能变
数组本身没有发生变化,需要用一个变量去接收改变后的值


级联concatenate
增加行数叫垂直级联,即上下拼接vertical
增加列数叫水平级联,即左右拼接,horizontal
axis 轴
axes 轴的复数形式
axis=0表示对行操作,即垂直级联
axis=1表示对列操作,即水平级联


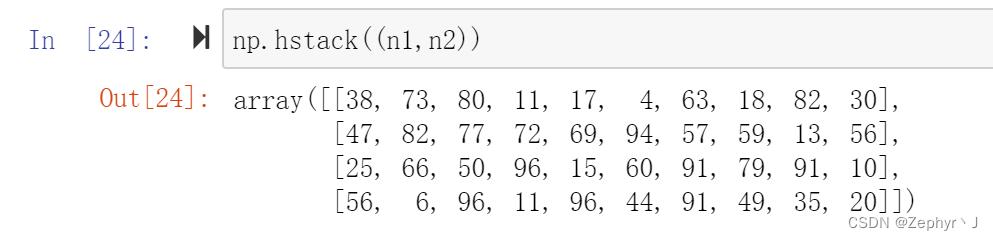
hstack(元组),水平级联
vstack(),垂直级联
切分 split
np.split
np.vsplit
np.hsplit
axis=0 表示对行进行切割



拷贝副本copy() 深拷贝
如果要对数据进行修改,可以先copy(),直接赋值会修改原数据
聚合操作
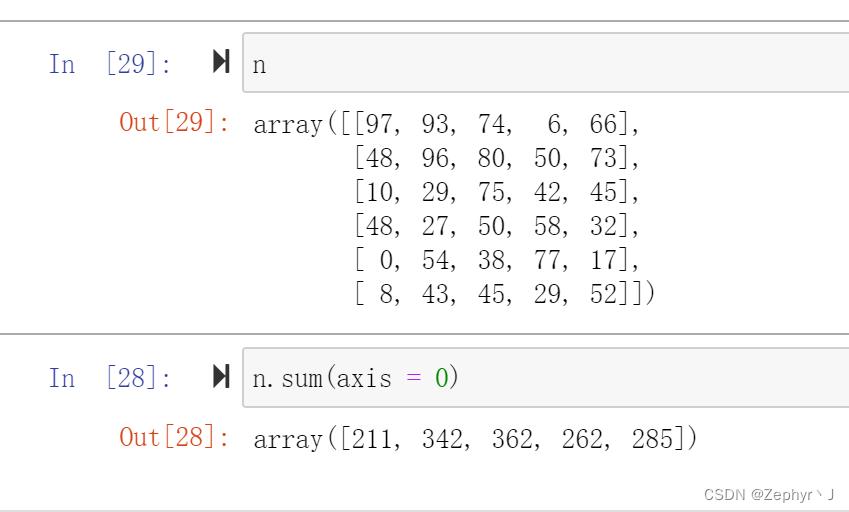
np.sum(),np.max()/min()
默认axis=None,表示聚合成0维,也就是一个值
axis=0 表示对行操作,行没了,剩下列,也就是把每一列加起来
np.sum(array, axis=None) 一样
argmin,返回最小值的索引

any只要有true返回true,all只要有false,返回false

np.nan 表示numpy,pandas中的空数据 Not a number
np.nansum()非空数据相加

矩阵操作
基本矩阵操作
n+1每个元素加1
n1 +n2 对应元素相加

a *b 普通的乘法,对应元素相乘
np.dot(a, b) 矩阵的积
广播机制
两条规则:
为缺失的维度补1
假定缺失元素用已有值填充
当参与运算的ndarray的shape不一致时,会触发广播机制,使维度变得一致
如下面这个例子,因为a只有一个维度,首先补一个维度,然后用已有值填充,变成两行0 1 2

排序
np.sort() 不会修改原数组
ndarray.sort() 修改原数组
部分排序
np.partition()
相当于找到最极端的几个值
最大的五个,-5,只是找出来,没有排序

Pandas
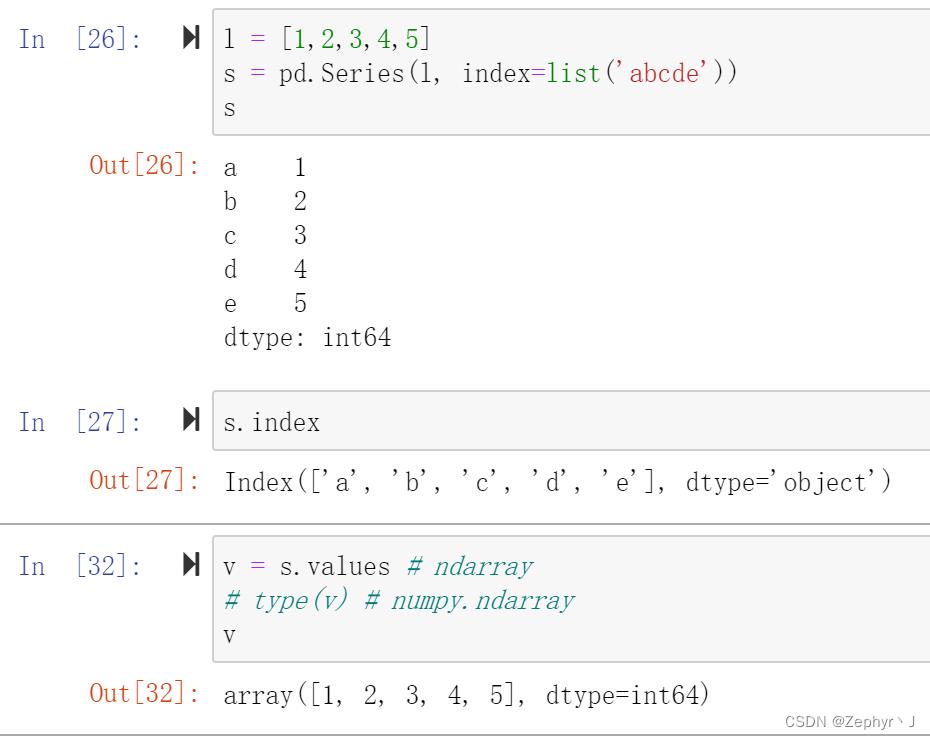
Series
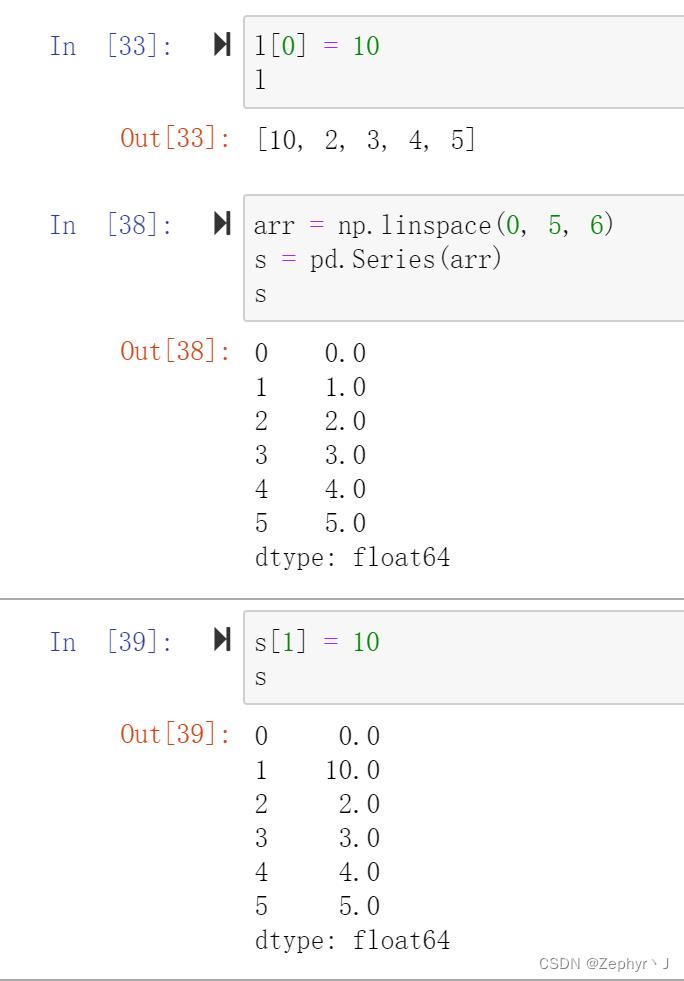
如果由ndarray创建Series,传递的是该对象的引用,修改Series中的内容,ndarray中的内容会改变
而如果由列表创建的话,传递的是列表的拷贝,修改Series不会影响原列表中的内容
由字典创建

索引和切片
显示索引,就是用存在的索引
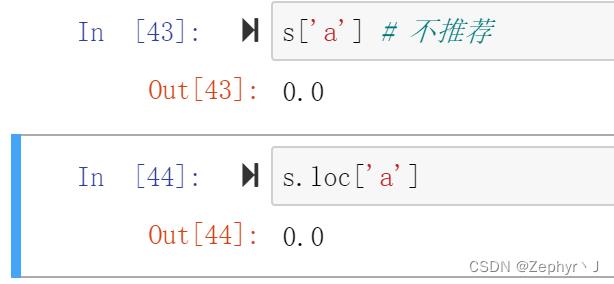

隐式索引,就是系统分配的,0123…

如果要返回索引和数值一起的情况
再套一层中括号
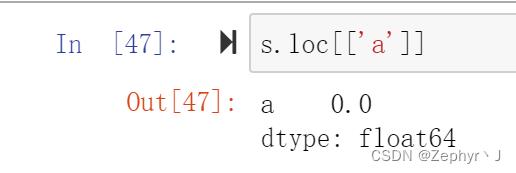
基本概念
属性shape, size, name
Series可以指定名字
方法 head(), tail()
pd.isnull() 一一判断series中所有元素是否为nan
pd.notnull()
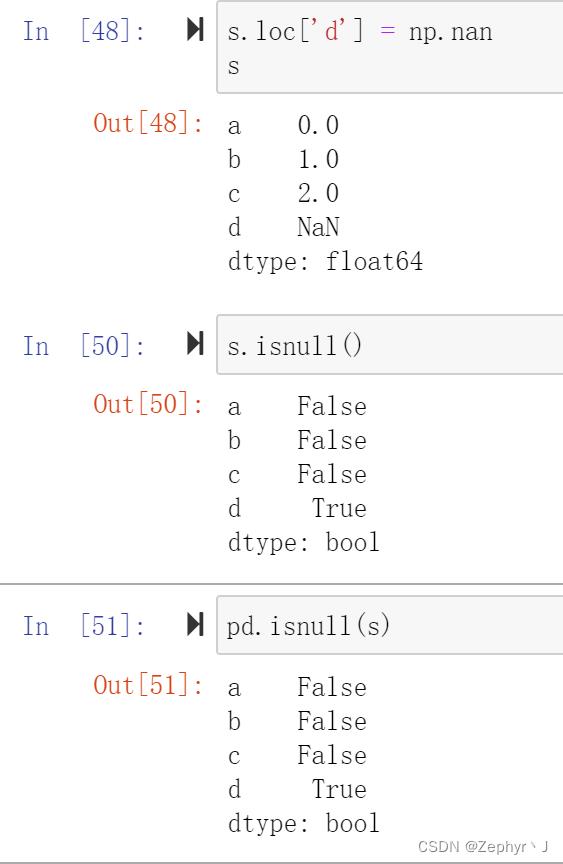
需要注意的是name是类属性
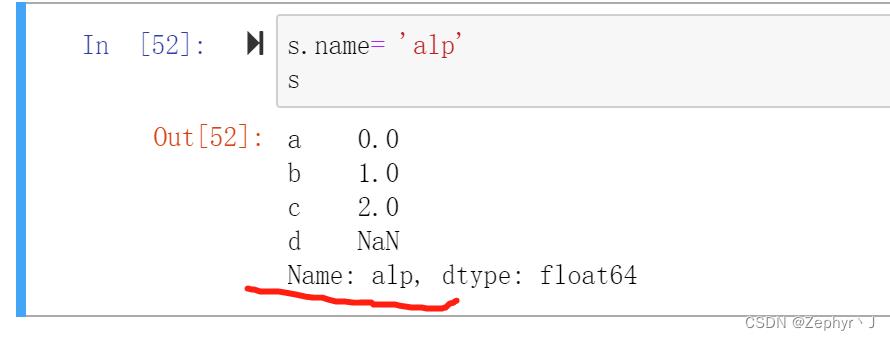
运算
适用于numpy数组的运算也适用于series
Series之间的计算:
在运算中自动对齐不同索引的数据
如果索引不对应,补nan

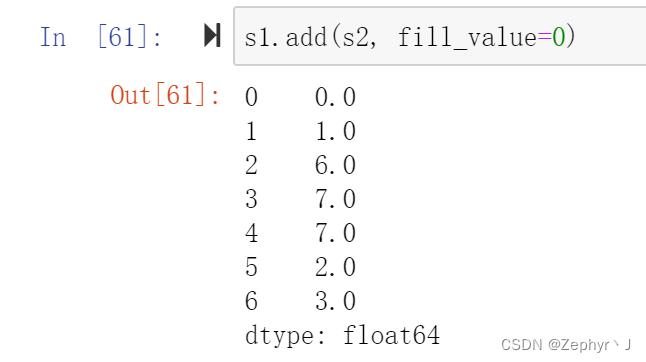
可以使用pandas封装的add()函数,保留原始的index的值
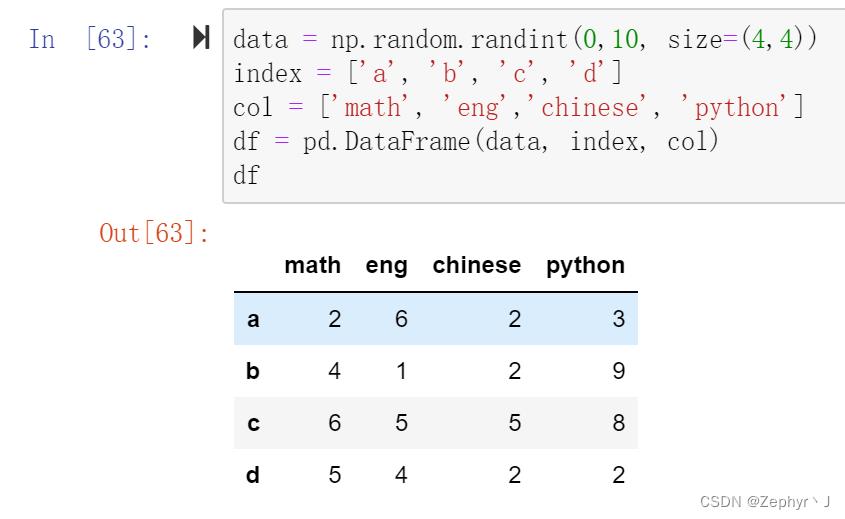
DataFrame
行索引:index
列索引:columns
值:values
分块创建,也可以采用字典创建
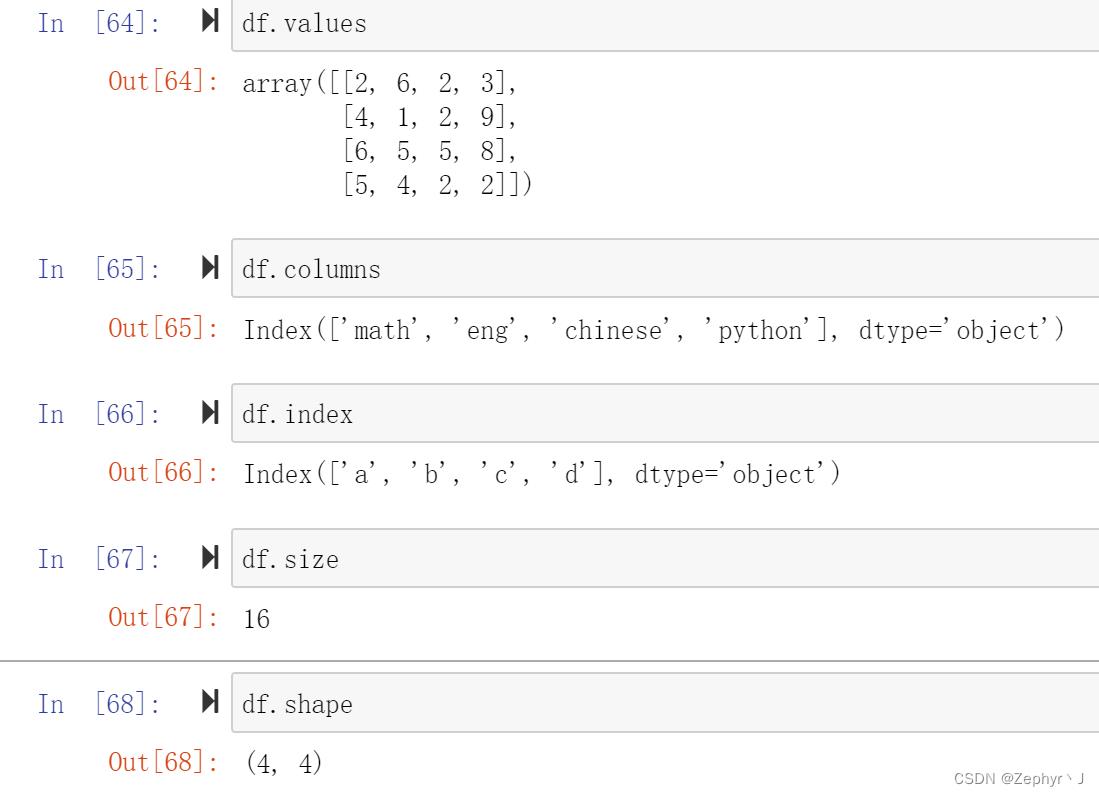
属性
values, columns, index, shape
索引
对行操作,要用loc,列操作,直接括号
对列进行索引:
注意新增一列的时候,不能使用属性的写法
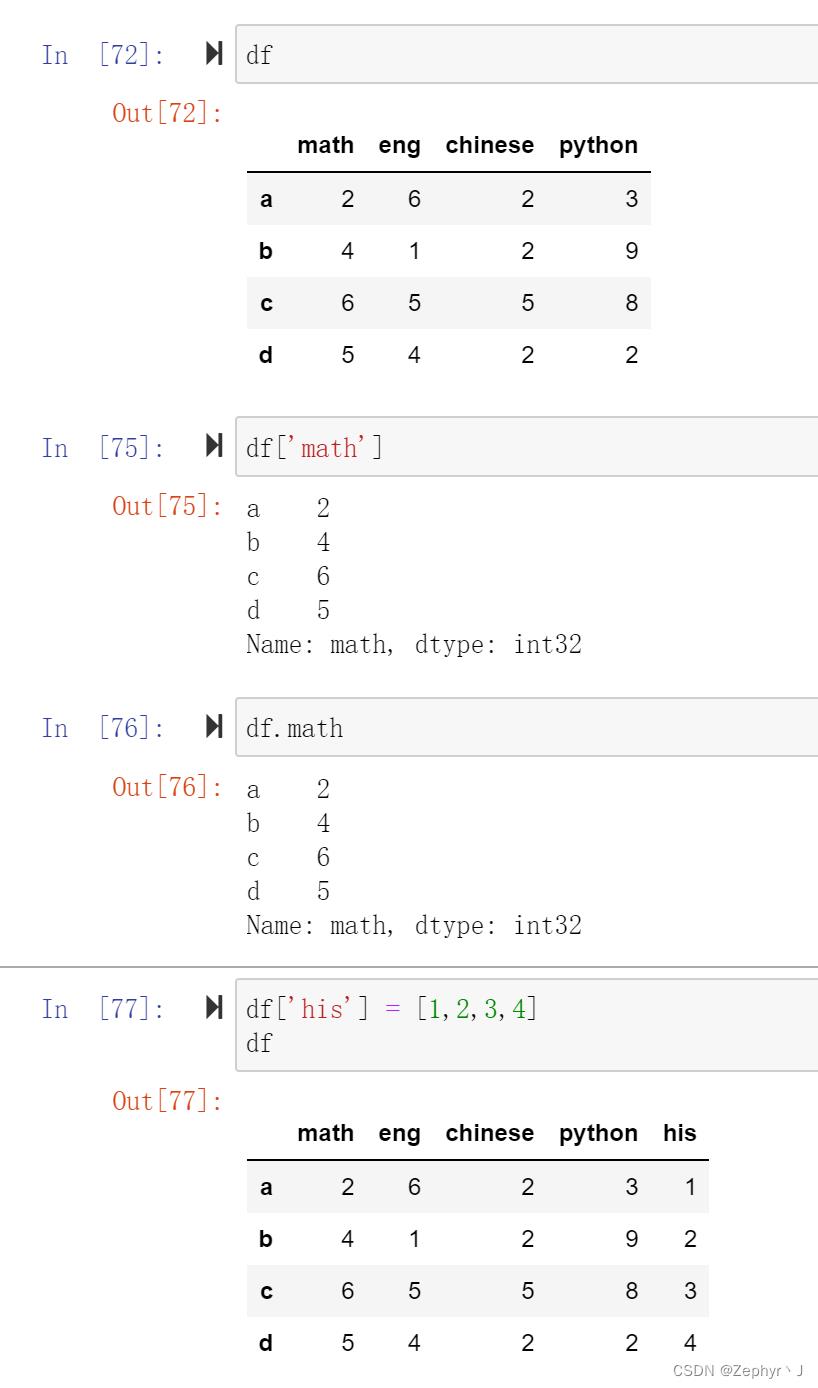
对行索引:
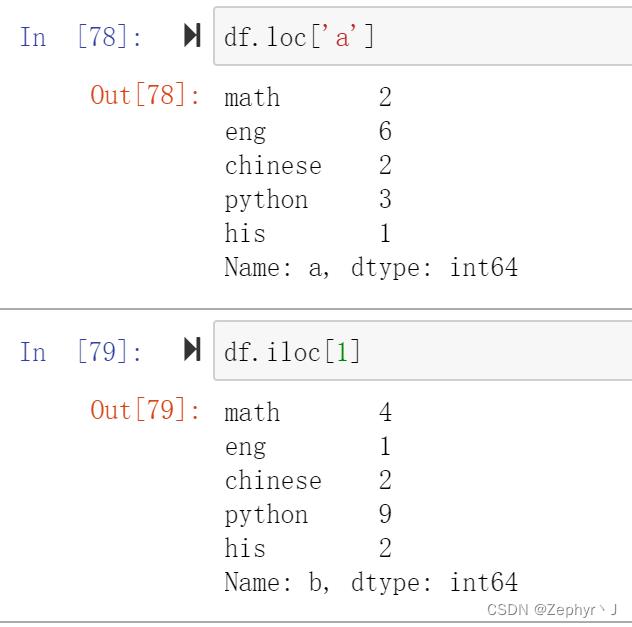
对元素的索引:
先列后行
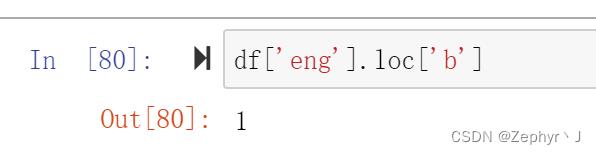
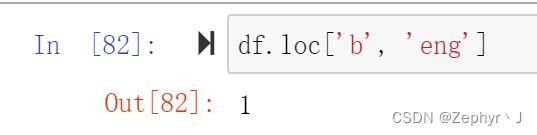
先行后列
下面这个推荐写法,上面的链式索引不推荐
切片
什么也不返回,是因为直接使用这个,是在进行行切片
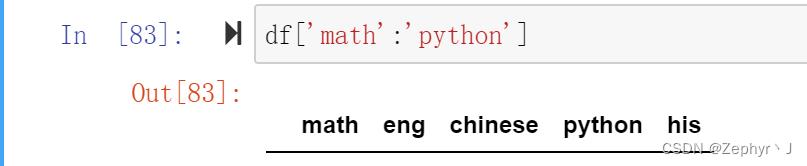
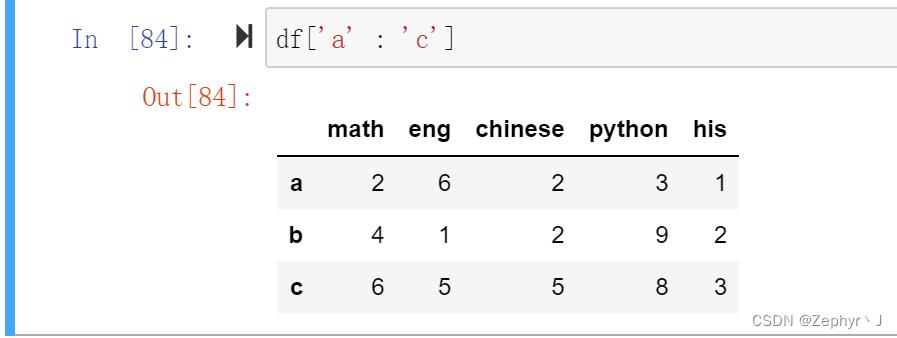

对列切片

索引总结
- 行索引用loc,列索引用[]
- 对元素的索引,先索引行,再列,df.loc[index, col]
- 如果还想返回dataframe,那么使用两层中括号
- 注意:直接使用中括号的时候,如果是切片,是对行进行切片
- 注意:不要使用链式索引
要使返回结果仍为dataframe,需要加中括号

这样会报错,因为找这两行,而没有math这一行

运算
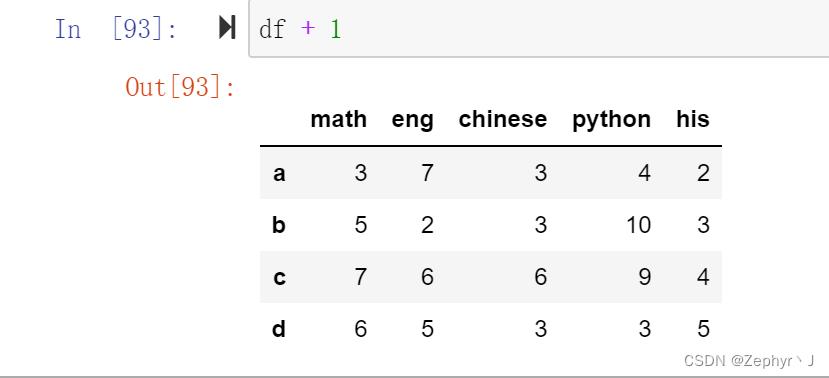
dataframe和dataframe运算,只有行列索引都相同才会运算
和series一样,如果要保留,需要用add方法,设置fill_value = 0
dataframe 和 series相加,索引一样可以相加
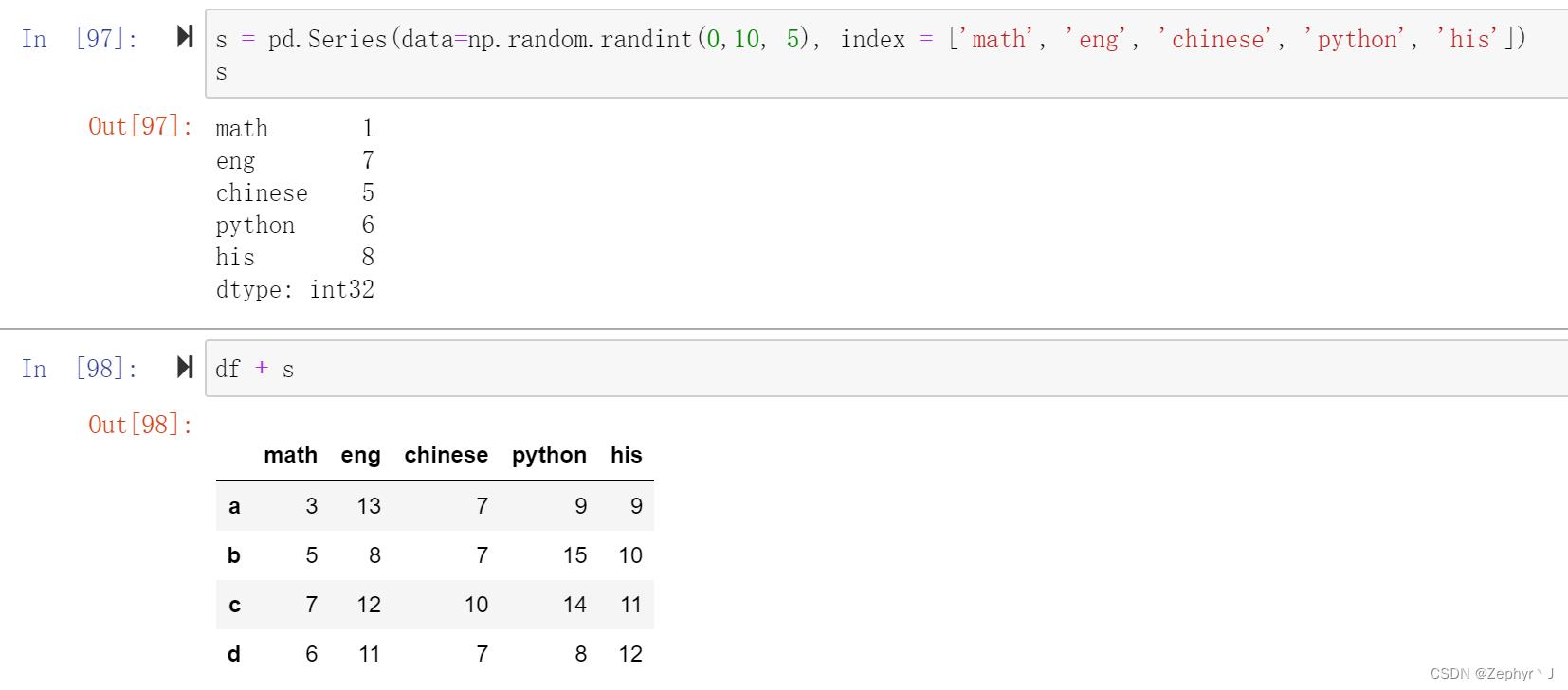
但是如果改成行索引的series
使用用算符进行操作,默认比较的df的列索引和series的行索引
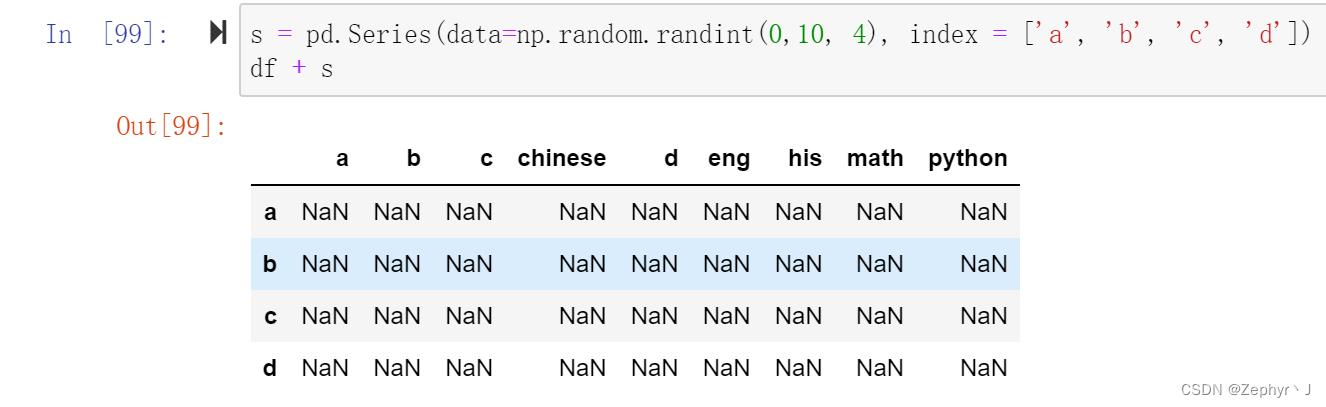
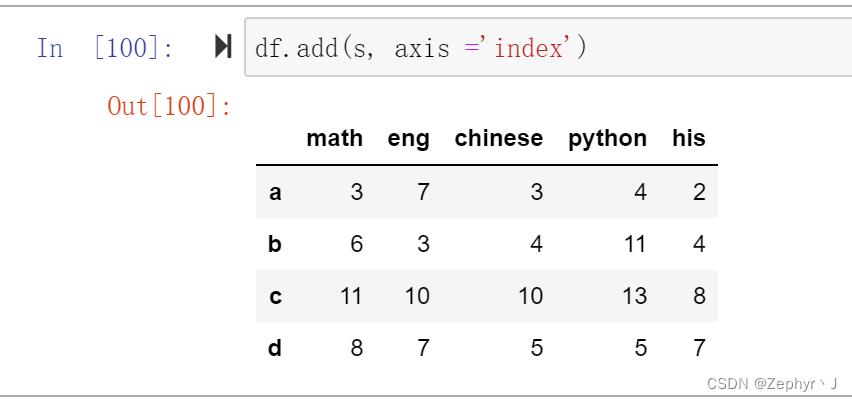
使用axis改变运算方向

以上是关于JupyterNumpyPandas的主要内容,如果未能解决你的问题,请参考以下文章