当你碰到了MySQL中的死锁,你了解这些机制吗?
Posted Java_LingFeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了当你碰到了MySQL中的死锁,你了解这些机制吗?相关的知识,希望对你有一定的参考价值。
mysql死锁怎么来的?
当两个及以上的事务,双方都在等待对方释放已经持有的锁或因为加锁顺序不一致造成循环等待锁资源,就会出现“死锁”。
总结一下生产死锁的4个条件:
-
两个或者两个以上事务
-
每个事务都已经持有锁并且申请新的锁
-
锁资源同时只能被同一个事务持有或者不兼容
-
事务之间因为持有锁和申请锁导致彼此循环等待
举个例子:用户表,id是主键
| 事务1 | 事务2 | |
| begin;update user set username = '旭阳' where id = 10; | ||
| begin;update user set username = 'alvin' where id = 20; | ||
| update user set username = 'alvin' where id = 20; | ||
| update user set username = '旭阳' where id = 10; |
-
事务1优先获得了id=10的记录锁
-
事务2其次获得了id=20的记录锁
-
然后事务1现在请求id=20的记录锁资源,发现已经被占用了,阻塞等待其他事务释放
-
同理,事务2请求id=10的记录锁资源,却被事务1占用了
-
由于事务1和事务2都没有提交,所以他们不会释放锁,导致死锁,得到下面的报错:

死锁的关键在于:两个(或以上)的事务加锁的顺序不一致。如果上面的事务2也是先锁id=10的记录,再锁id=20的记录,就不会出现死锁。
但是这很难达成,因为我们不同的业务,会有不同的逻辑处理,肯定会出现加锁顺序不一样的情况,特别是在高并发的场景下。
MySQL遇到死锁怎么办?
MySQL发生了死锁,总不能一直让事务现场等在那里,多蠢啊,那它采用什么策略解决死锁问题呢?
-
等待,直到超时
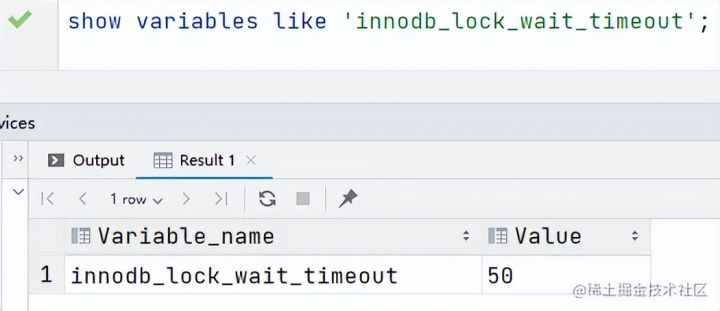
即当两个事务互相等待时,当一个事务等待时间超过设置的阈值时,就将其回滚,另外事务继续进行。innoDB存储引擎中,通过innodb_lock_wait_timeout配置设置超时时间,默认50秒。
优点:
-
简单有效
缺点:
-
如果真的发生死锁,等待50s这么久一般难以接受,设置太短比如1s, 2s,有可能误触发正常的锁等待。
-
使用死锁检测处理死锁程序
由于上面等待的方式太过被动,那有没有可以主动检测出是否存在死锁的方式呢?
MySQL提供了一种主动的死锁检测机制, 相当于将锁等待的信息保存下来,绘制出一个等待的有向图,如下:
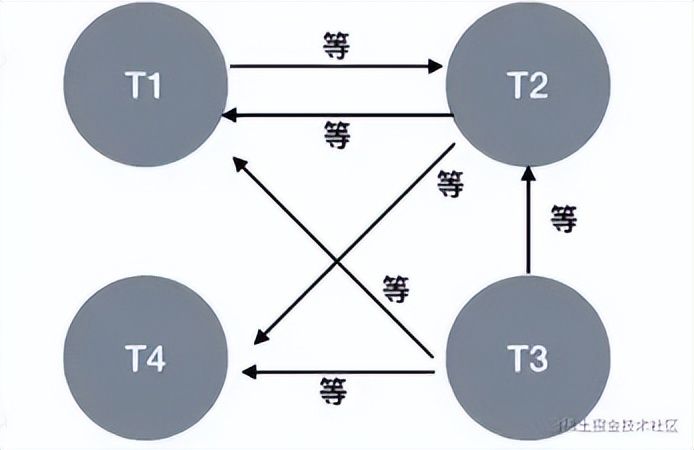
如果检测到存在环,说明有死锁,那么InnoDB存储引擎会选择回滚undo量最小的事务,让其他事务继续执行。
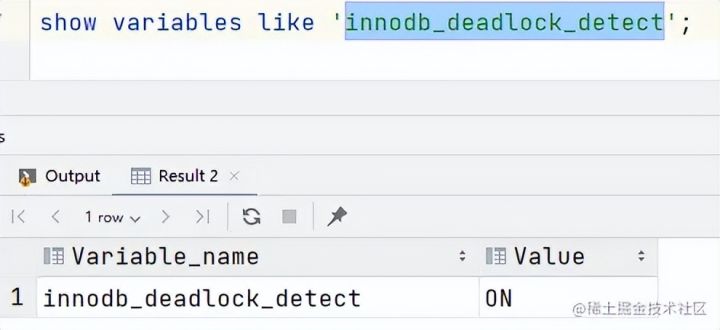
这种机制通过配置 innodb_deadlock_detect控制,默认打开。
优点:
-
主动检测,时效性低
缺点: 并发越高,图形越庞大,检测越耗时。每个新的被阻塞的线程,都要判断是不是由于自己的加入导致了死锁,这个操作时间复杂度是O(n)。如果100个并发线程同时更新同一行,意味着要检测100*100=1万次,1万个线程就会有1千万次检测。
上面两种方式并不冲突,默认情况下,MySQL都处于开启状态。
死锁日志怎么看?
虽然MySQL提供了默认的死锁处理机制,更重要的还是我们需要去从业务逻辑代码层面分析发生死锁的根本原因,然后去合理的规避死锁。那为了能够快速定位到死锁相关的业务代码,我们还需要会分析死锁日志。
死锁日志在哪呢?
-
通过show engine innodb status命令可以查看最近一次发生死锁的日志。
-
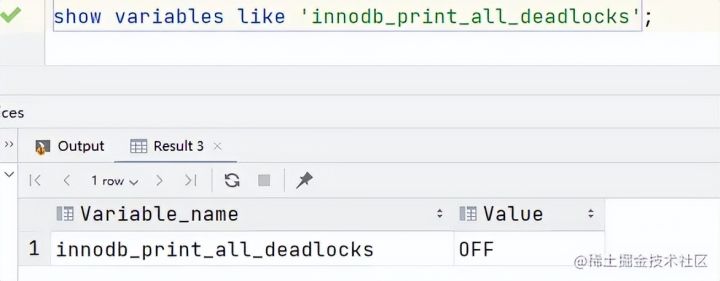
通过命令set global innodb_print_all_deadlocks = 1;开启死锁日志记录到MySQL错误日志中,默认情况是不开启的。
死锁例子超详细解读
我们以上面的用户表为例,解读下死锁日志。
执行命令show engine innodb status获取死锁日志如下图所示:
LATEST DETECTED DEADLOCK表示InnoDB引擎上次发生的死锁。死锁是至少需要有两个事务参与的,所以在其内部包含了发生死锁的具体两个事务。
-
第一个事务 (1) TRANSACTION
-
TRANSACTION 2415258889, ACTIVE 31 sec starting index read
说明: 事务号为2415258889,活跃 31秒,starting index read 表示事务状态为根据索引读取数据。注意删除和更新InnoDB内部也是要进行读操作的。
-
mysql tables in use 1, locked 1
说明: 说明当前的事务使用一个表,并且有一个表锁,DML操作会对表施加意向锁,本例是IX。
-
LOCK WAIT 3 lock struct(s), heap size 1136, 2 row lock(s)
说明: LOCK WAIT 表示正在等待锁,3 lock struct(s)表示 trx->trx_locks 锁链表的长度为3,每个链表节点代表该事务持有的一个锁结构,包括表锁,记录锁以及自增锁等。2 row lock(s)表示当前事务持有的行记录锁/ gap 锁的个数。
-
MySQL thread id 4576535
说明: 表示执行事务的线程id是4576535,即 show processlist; 展示的 ID。
-
update user set username = 'alvin' where id = 20
说明: 表示事务执行正在阻塞的SQL,注意不会显示事务全部执行的SQL
-
(1) WAITING FOR THIS LOCK TO BE GRANTED:
说明: 这行信息表示等待的锁是一个record lock,空间id是221580,页编号为3,大概位置在页的80位处,锁发生在表user的主键索引上,是一个X锁,但是不是gap lock,waiting表示正在等待锁
-
第二个事务 (2) TRANSACTION
第二个事务基本上和第一个事务分析是一样的,我们挑选重要的和不一样的点:
-
(2) HOLDS THE LOCK(S)
说明: 表明了事务二持有的锁正是事务1想要获取的锁。
-
WE ROLL BACK TRANSACTION (2)
由于发生了死锁,最终回滚事务2。
我们可以借助死锁日志分析死锁发生可能的原因,但是由于死锁日志只记录发生阻塞的SQL,所以仅仅根据日志也很难以分析死锁的问题的根本原因,但是可以有一定的帮助。
怎么尽量避免死锁?
我们在平时的开发设计有没有一些准则可以帮助我们避免死锁发生?
-
合理的设计索引,区分度高的列放到组合索引前面,使业务 SQL 尽可能通过索引定位更少的行,减少锁竞争。
-
调整业务逻辑 SQL 执行顺序, 避免 update/delete 长时间持有锁的 SQL 在事务前面。
-
避免大事务,尽量将大事务拆成多个小事务来处理,小事务发生锁冲突的几率也更小。
-
以固定的顺序访问表和行。比如两个更新数据的事务,事务 A 更新数据的顺序为 1,2;事务 B 更新数据的顺序为 2,1。这样更可能会造成死锁。
-
在并发比较高的系统中,不要显式加锁,特别是是在事务里显式加锁。如 select … for update 语句,如果是在事务里(运行了 start transaction 或设置了autocommit 等于0),那么就会锁定所查找到的记录。
-
尽量按主键/索引去查找记录,范围查找增加了锁冲突的可能性。
-
降低隔离级别。如果业务允许,将隔离级别调低也是较好的选择,比如将隔离级别从RR调整为RC,可以避免掉很多因为gap锁造成的死锁。
总结一下: 也就是在业务允许的情况下,尽量缩短一个事务持有锁的时间、减小锁的粒度以及锁的数量。
总结
本文讲解了MySQL中死锁发生的原因,以及如何通过日志排查死锁,最后给了一些平时开发过程中避免死锁的建议。虽然MySQL会自动解除死锁,但是这个死锁问题以后绝对会再次出现,一定要记住去排除业务SQL的执行逻辑,找到产生死锁的业务,然后调整业务SQL的执行顺序,这样才能从根源上避免死锁产生。
如果本文对你有帮助的话,请留下一个赞吧
Java——你真的了解Java异常处理机制吗?
目录
1.初识异常
我们在写代码的时候都或多或少碰到了大大小小的异常,例如:
public class Test public static void main(String[] args) int[] arr = 1,2,3; System.out.println(arr[5]);当我们数组越界时,编译器会给我们报数组越界,并提示哪行出了错。
再比如:
class Test int num = 10; public static void main(String[] args) Test test = null; System.out.println(test.num);当我们尝试用使用空对象时,编译器也会报空指针异常:
那么究竟什么是异常?
所谓异常指的就是程序在 运行时 出现错误时通知调用者的一种机制 .关键字 "运行时" ,有些错误是这样的, 例如将 System.out.println 拼写错了, 写成了
system.out.println. 此时编译过程中就会出 错, 这是 "编译期" 出错.
而运行时指的是程序已经编译通过得到 class 文件了 , 再由 JVM 执行过程中出现的错误 .


2.异常的基本用法
Java异常处理依赖于5个关键字:try、catch、finally、throws、throw。下面来逐一介绍下。
①try:try块中主要放置可能会产生异常的代码块。如果执行try块里的业务逻辑代码时出现异
常,系统会自动生成一个异常对象,该异常对象被提交给运行环境,这个过程被称为抛出
(throw)异常。Java环境收到异常对象时,会寻找合适的catch块(在本方法或是调用方
法)。
②catch: catch 代码块中放的是出现异常后的处理行为,也可以写此异常出错的原因或者打
印栈上的错误信息。但catch语句不能为空,因为一旦将catch语句写为空,就代表忽略了此
异常。如:
空的catch块会使异常达不到应有的目的,即强迫你处理异常的情况。忽略异常就如同忽略
火警信号一样——若把火警信号关掉了,当真正的火灾发生时,就没有人能看到火警信号
了。或许你会侥幸逃过一劫,或许结果将是灾难性的。每当见到空的catch块时,我们都应该
警钟长鸣。
当然也有一种情况可以忽略异常,即关闭fileinputstream(读写本地文件)的时候。因为你还
没有改变文件的状态,因此不必执行任何恢复动作,并且已经从文件中读取到所需要的信
息,因此不必终止正在进行的操作。
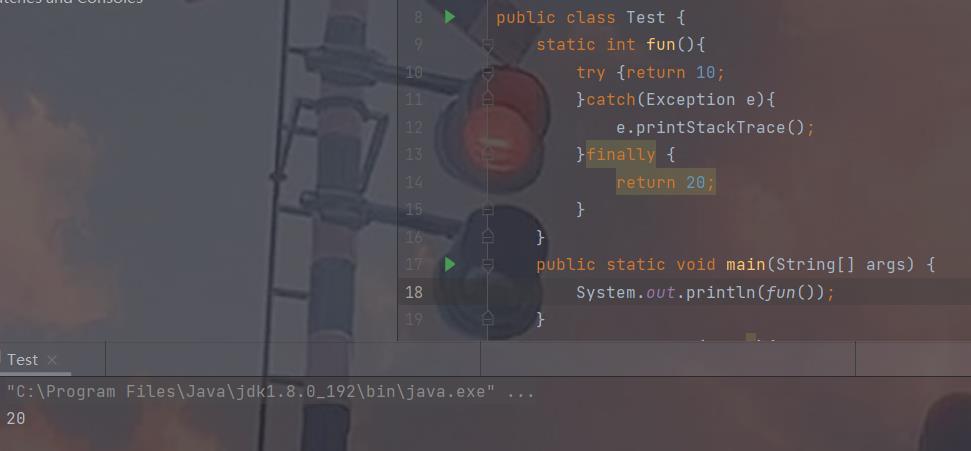
③finally:finally 代码块中的代码用于处理善后工作, 会在最后执行,也一定会被执行。当遇
到try或catch中return或throw之类可以终止当前方法的代码时,jvm会先去执行finally中的语
句,当finally中的语句执行完毕后才会返回来执行try/catch中的return,throw语句。如果
finally中有return或throw,那么将执行这些语句,不会在执行try/catch中的return或throw语
句。finally块中一般写的是关闭资源之类的代码。但是我们一般不在finally语句中加入return
语句,因为他会覆盖掉try中执行的return语句。例如:
finally将最后try执行的return 10覆盖了,最后结果返回了20.
④throws:在方法的签名中,用于抛出此方法中的异常给调用者,调用者可以选择捕获或者
抛出,如果所有方法(包括main)都选择抛出(或者没有合适的处理异常的方式,即异常类
型不匹配)那么最终将会抛给JVM,就会像我们之前没使用try、catch语句一样。JVM打印出
栈轨迹(异常链)。
⑤throw:用于抛出一个具体的异常对象。常用于自定义异常类中。
ps:
关于 "调用栈",方法之间是存在相互调用关系的, 这种调用关系我们可以用 "调用栈" 来描述.
在 JVM 中有一块内存空间称为 "虚拟机栈" 专门存储方法之间的调用关系. 当代码中出现异常
的时候, 我们就可以使用 e.printStackTrace() 的方式查看出现异常代码的调用栈,一般写在catch语句中。
异常处理流程
程序先执行 try 中的代码
如果 try 中的代码出现异常, 就会结束 try 中的代码, 看和 catch 中的异常类型是否匹配.
如果找到匹配的异常类型, 就会执行 catch 中的代码
如果没有找到匹配的异常类型, 就会将异常向上传递到上层调用者.
无论是否找到匹配的异常类型, finally 中的代码都会被执行到(在该方法结束之前执行).
如果上层调用者也没有处理的了异常, 就继续向上传递.
一直到 main 方法也没有合适的代码处理异常, 就会交给 JVM 来进行处理, 此时程序就会异常终止.

3.为什么要使用异常?
存在即合理,举个例子
//不使用异常 int[] arr = 1, 2, 3; System.out.println("before"); System.out.println(arr[100]); System.out.println("after");当我们不使用异常时,发现出现异常程序直接崩溃,后面的after也没有打印。
//使用异常 int[] arr = 1, 2, 3; try System.out.println("before"); System.out.println(arr[100]); System.out.println("after"); catch (ArrayIndexOutOfBoundsException e) // 打印出现异常的调用栈 e.printStackTrace(); System.out.println("after try catch");当我们使用了异常,虽然after也没有执行,但程序并没有直接崩溃,后面的sout语句还是执行了
这不就是异常的作用所在吗?
再举个例子,当玩王者荣耀时,突然断网,他不会让你直接程序崩溃吧,而是给你断线重连的机会吧:
我们再用伪代码演示一把王者荣耀的对局过程:
不使用异常处理 boolean ret = false; ret = 登陆游戏(); if (!ret) 处理登陆游戏错误; return; ret = 开始匹配(); if (!ret) 处理匹配错误; return; ret = 游戏确认(); if (!ret) 处理游戏确认错误; return; ret = 选择英雄(); if (!ret) 处理选择英雄错误; return; ret = 载入游戏画面(); if (!ret) 处理载入游戏错误; return; ......使用异常处理 try 登陆游戏(); 开始匹配(); 游戏确认(); 选择英雄(); 载入游戏画面(); ... catch (登陆游戏异常) 处理登陆游戏异常; catch (开始匹配异常) 处理开始匹配异常; catch (游戏确认异常) 处理游戏确认异常; catch (选择英雄异常) 处理选择英雄异常; catch (载入游戏画面异常) 处理载入游戏画面异常; ......我们能明显的看到不使用异常时,正确流程和错误处理代码混在一起,不易于分辨,而用了
异常后,能更易于理解代码。
当然使用异常的好处还远不止于此,我们可以在try、catch语句中加入信息提醒功能,比如你
开发了一个软件,当那个软件出现异常时,发个信息提醒你及时去修复。博主就做了一个小
小的qq邮箱信息提醒功能,源码在码云,有兴趣的可以去看看呀!需要配置qq邮箱pop3服
务,友友们可以去查查怎么开启呀,我们主旨不是这个所以不教怎么开启了。演示一下:
别群发消息哦,不然可能会被封号???
异常应只用于异常的情况
try int i = 0; while(true) System.out.println(a[i++]); catch(ArrayIndexOutOfBoundsException e)这段代码有什么用?看起来根本不明显,这正是它没有真正被使用的原因。事实证明,作为
一个要对数组元素进行遍历的实现方式,它的构想是非常拙劣的。当这个循环企图访问数组
边界之外的第一个数组元素时,用抛出(throw)、捕获(catch)、
忽略(ArrayIndexOutOfBoundsException)的手段来达到终止无限循环的目的。假定它与数
组循环是等价的,对于任何一个Java程序员来讲,下面的标准模式一看就会明白:
for(int m : a) System.out.println(m);为什么优先异常的模式,而不是用行之有效标准模式呢?
可能是被误导了,企图利用异常机制提高性能,因为jvm每次访问数组都需要判断下标是否越界,他们认为循环终止被隐藏了,但是在foreach循环中仍然可见,这无疑是多余的,应该避
免。
上面想法有三个错误:
1.异常机制设计的初衷是用来处理不正常的情况,所以JVM很少对它们进行优化。
2.代码放在try…catch中反而阻止jvm本身要执行的某些特定优化。
3.对数组进行遍历的标准模式并不会导致冗余的检查。
这个例子的教训很简单:顾名思义,异常应只用于异常的情况下,它们永远不应该用于正常
的控制流。
总结:异常是为了在异常情况下使用而设计的,不要用于一般的控制语句。


4. 异常的种类
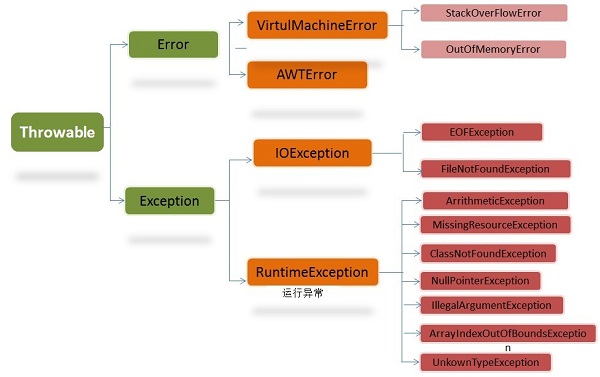
在Java中提供了三种可抛出结构:受查异常(checked exception)、运行时异常(run-time exception)和错误(error)。
(补充)
4.1 受查异常
什么是受查异常?只要不是派生于error或runtime的异常类都是受查异常。举个例子:
我们自定义两个异常类和一个接口,以及一个测试类
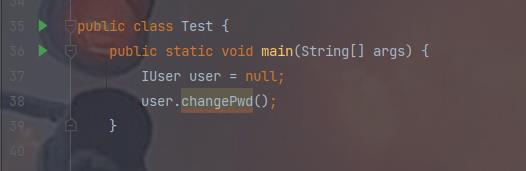
interface IUser void changePwd() throws SafeException,RejectException; class SafeException extends Exception //因为继承的是execption,所以是受查异常类 public SafeException() public SafeException(String message) super(message); class RejectException extends Exception //因为继承的是execption,所以是受查异常类 public RejectException() public RejectException(String message) super(message); public class Test public static void main(String[] args) IUser user = null; user.changePwd();
我们发现test测试类中user使用方法报错了,因为java认为checked异常都是可以再编译阶
段被处理的异常,所以它强制程序处理所有的checked异常,java程序必须显式处checked
异常,如果程序没有处理,则在编译时会发生错误,无法通过编译。
解决方案:
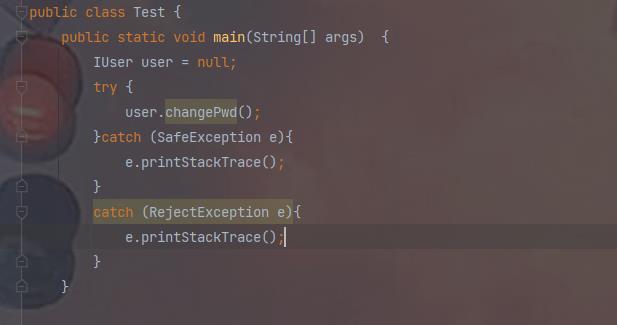
①try、catch包裹
IUser user = null; try user.changePwd(); catch (SafeException e) e.printStackTrace(); catch (RejectException e) e.printStackTrace();
②抛出异常,将处理动作交给上级调用者,调用者在调用这个方法时还是要写一遍try、catch
包裹语句的,所以这个其实是相当于声明,让调用者知道这个函数需要抛出异常
public static void main(String[] args) throws SafeException, RejectException IUser user = null; user.changePwd();
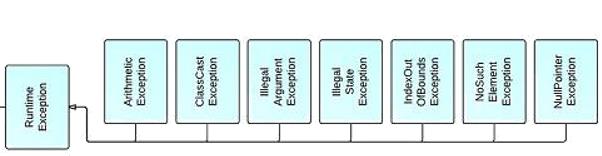
4.2非受查异常
派生于error或runtime类的所有异常类就是非受查异常。
可以这么说,我们现在写程序遇到的异常大部分都是非受查异常,程序直接崩溃,后面的也
不执行。
像空指针异常、数组越界异常、算术异常等,都是非受查异常。由编译器运行时给你检查出
来的,所以也叫作运行时异常。

5.如何使用异常
避免不必要的使用受查异常
如果不能阻止异常条件的产生,并且一旦产生异常,程序员可以立即采取有用的动作,这种
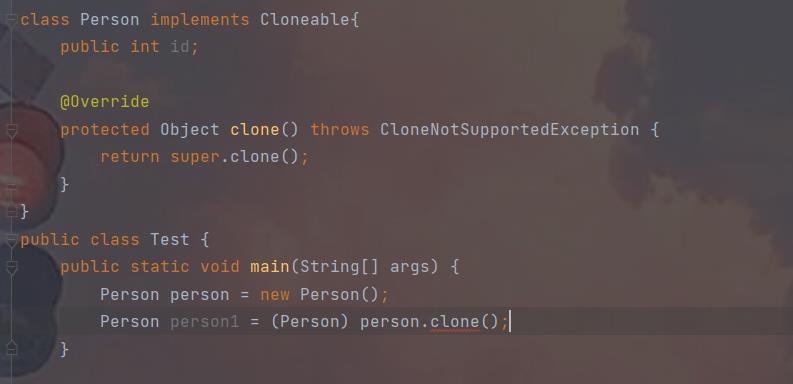
受查异常才是可取的。否则,更适合用非受查异常。这种例子就是
CloneNotSuppportedException(受查异常)。它是被Object.clone抛出来的,Object.clone
只有在实现了Cloneable的对象上才可以被调用。
被一个方法单独抛出的受查异常,会给程序员带来非常高的额外负担,如果这个方法还有其
他的受查异常,那么它被调用是一定已经出现在一个try块中,所以这个异常只需要另外一个
catch块。但当只抛出一个受查异常时,仅仅一个异常就会导致该方法不得不处于try块中,也
就导致了使用这个方法的类都不得不使用try、catch语句,使代码可读性也变低了。
受查异常使接口声明脆弱,比如一开始一个接口只有一个声明异常
interfaceUser //修改用户名,抛出安全异常 publicvoid changePassword() throws MySecurityExcepiton;但随着系统开发,实现接口的类越来越多,突然发现changePassword还需要抛出另一个异
常,那么实现这个接口的所有类也都要追加对这个新异常的处理,这个工程量就很大了。
总结:如果不是非用不可,尽量使用非受查异常,或将受查异常转为非受查异常。
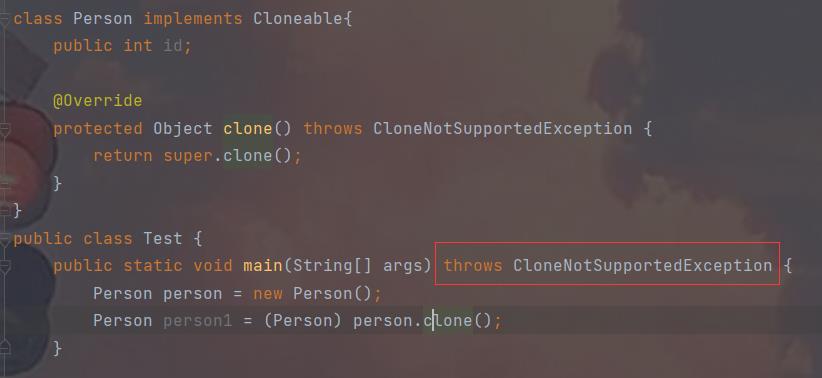
6.自定义异常
我们用自定义异常来实现一个登录报错的小应用
class NameException extends RuntimeException//用户名错误异常 public NameException(String message) super(message); class PasswordException extends RuntimeException//密码错误异常 public PasswordException(String message) super(message);test类来测试运行
public class Test private static final String name = "bit"; private static final String password ="123"; public static void Login(String name,String password) throws NameException,PasswordException try if(!Test.name.equals(name)) throw new NameException("用户名错误!"); catch (NameException e) e.printStackTrace(); try if(!Test.password.equals(password)) throw new PasswordException("密码错误"); catch (PasswordException e) e.printStackTrace(); public static void main(String[] args) Scanner scanner = new Scanner(System.in); String name = scanner.nextLine(); String password = scanner.nextLine(); Login(name,password);
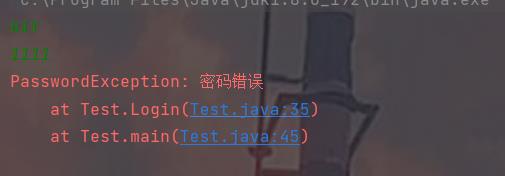
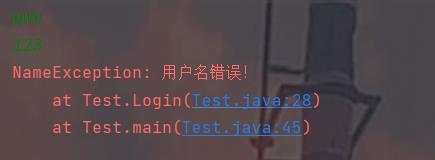
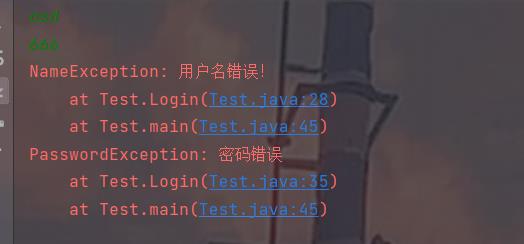
关于异常就到此为止了,怎么感觉还有点意犹未尽呢?
以上是关于当你碰到了MySQL中的死锁,你了解这些机制吗?的主要内容,如果未能解决你的问题,请参考以下文章