Python(黄金时代)——mysql数据库基础
Posted 程序猿知秋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python(黄金时代)——mysql数据库基础相关的知识,希望对你有一定的参考价值。
数据库基本介绍
RDBMS(Relational Database Managerment System) :关系型数据库管理系统
关系型数据库的主要产品如下
-
mysql:web时代使用最广泛的关系型数据库
-
oracel:大型项目使用较多,如银行、电信等
-
ms sql server:普遍用于微软的项目
-
db2:IBM 的产品,主要用于大型项目
-
sqlite:轻量级数据库,主要应用于移动平台
SQL(Structured Query Language)
SQL是结构化查询语言,是一种用来操作 RDBMS的数据库语言,当前的关系型数据库都支持使用SQL语言进行操作
注:对于程序员来讲,最重要的就是对数据的curd(增、删、改、查),即DQL和DML
-
SQL语句主要分为
-
DQL:数据库查询语言,用于对数据进行查询
-
DML:数据库操作语言,用于对数据进行增加、修改、删除等操作
-
TPL:事务处理语言,对事务进行处理
-
DCL:数据库控制语言,进行授权与权限回收
-
DDL:数据库定义语言,进行数据库、表的管理
-
CCL:指针控制语言,通过控制指针完成对表的操作
-
MySQL 简介
-
直接查看MySQL官方网站(https://www.mysql.com/)
-
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB公司开发,后来被Sun公司收购,之后又被Oracle收购,目前 属于Oracle旗下产品
MySQL的特点
-
使用c和c++编写,并使用了多种编译器进行测试,保证源代码的可移植性
-
支持多种操作系统,如Linux、Windows、MacOS... 等
-
为多种编程语言提供了API,如C、C++、JAVA、Python ... 等
-
支持多线程,充分利用 CPU资源
-
多编码支持 GB2312、UTF-8 等
-
支持多种存储引擎
-
MySQL 采用双授权政策,分为社区版和商业版,并且源码开源
-
复制全局事务标识
-
复制无崩溃从机
-
复制多线程从机
-
...
最主要的是 开源,免费、不要钱,并且使用范围广,跨平台支持性好,是学习数据库开发的首选
MySQL服务器与客户端的安装步骤较多,请自行百度(注,不同的操作系统,对应的mysql版本不一样)
Navicat
-
Navicat 是数据库管理工具,专为简化数据库的管理及降低系统管理成本而设。Navicat 是以直觉化的图形用户界面而建的,让你可以以安全并且简单的方式创建、组织、访问并共用信息
-
Navicat提供多达 7 种语言供客户选择,被公认为全球最受欢迎的数据库前端用户界面工具。
-
它可以用来对本机或远程的 MySQL、SQL Server、SQLite、Oracle 及 PostgreSQL 数据库进行管理及开发
Navicat 的安装及基本使用,请自行百度
安装完成之后,可以自己创建数据库
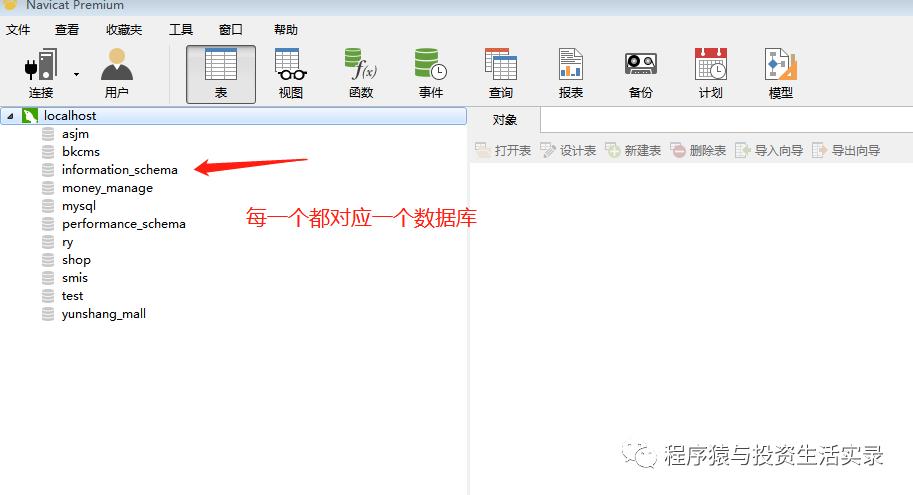
数据库中表的数据类型与约束
-
常用的数据类型
-
整数:tinyint、int、bigint
-
小数:decimal
-
字符串:varchar、char
-
日期时间:date、time、datetime
-
枚举类型:enum
-
类型说明
-
decimal表示浮点数,如decimal(5,2)表示共存5位数,小数占2位
-
char表示固定长度的字符串,如char(3),如果填充 'ab' 时会补一个空格为 'ab '
-
varchar表示可变长度的字符串,如varchar(3),填充'ab'时,就只会存储'ab'
-
字符串text表示存储大文本,当字符串大于4000时推荐使用
-
-
-
约束
-
主键索引primary key:物理上存储的顺序(默认是唯一索引)
-
非空not null:此字段不允许填写空值
-
唯一索引 unique:此字段的值不允许重复
-
默认default:当不填写此值时会使用默认值,如果填写,则以填写为准
-
外键foreign key:对关系字段进行约束,当为关系字符填写值时,会到关联的表中查询此值是否存在
-
说明:虽然外键约束可以保证数据的有效性,但是在进行数据的crud时(增、删、改、查)时,都会降低数据库的性能,所以一般不推荐使用。在实际开发中,一般是通过业务逻辑控制数据的有效性
-
常用数据类型
| 类型 | 字节大小 | 有符号范围 | 无符号范围 |
| TINYINT | 1 | -128~127 | 0~255 |
| SMALLINT | 2 | -32768~32767 | 0~65535 |
| MEDIUMINT | 3 | -8388608~8388607 | 0~16777215 |
| INT/INTEGER | 4 | -2147483648~2147483647 | 0~4294967295 |
| BIGINT | 8 | -9223372036854775808~9223372036854775807 | 0~18446744073709551615 |
字符串
| 类型 | 字节大小 | 示例 |
| CHAR | 0~255 | char(3) ,输入'ab',存储为'ab',输入'abcd',存储为'abc' |
| VARCHAR | 0~255 | varchar(3),输'ab',存储为'ab',输入'abcd',存储为'abc |
| TEXT | 0~65535 | 大文本 |
日期
| 类型 | 字节大小 | 示例 |
| DATE | 4 | ’2021-01-01‘ |
| TIME | 3 | '23:59:59' |
| DATETIME | 8 | '2021-01-01 23:59:59' |
| YEAR | 1 | '2021' |
| TIMESTAMP | 4 | '1991-01-01 00:00:59' UTC - '2033-01-0100:00:59' UTC |
数据库操作
通过命令行操作数据库
连接数据库
-
mysql -u用户名 -p密码
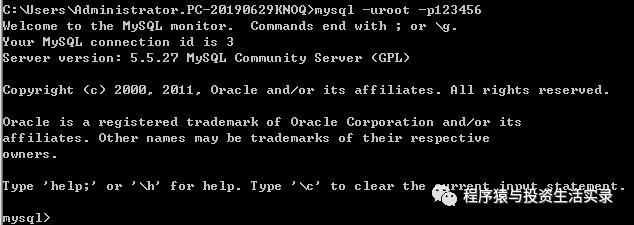
退出数据库连接
-
exit/quit/ctrl+c
查看所有数据库
-
show databases;

显示时间
-
select now();
查看数据库版本
-
select version();
创建数据库并指定编码为utf8
-
create database python01 charset=utf8;

删除数据库
-
drop database python01;
使用数据库
-
use python01;
查看当前使用的数据库
-
select database();
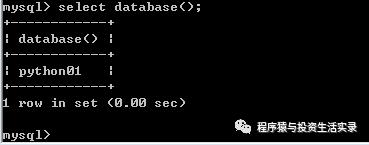
数据表的操作
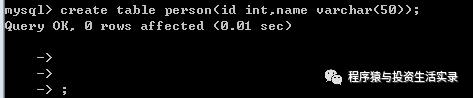
创建表
-
create table 表名字(字段 类型 约束)
-
例:create table person(id int,name varchar(50));
查看所有的表
-
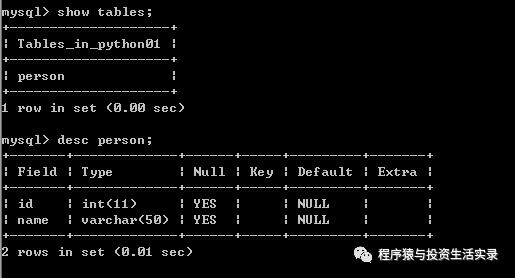
show tables;
查看表结构
-
desc person;
修改表-添加字段
-
alter table 表名 add 列名 类型;
-
例:alter table person add age int;
修改表-修改字段
-
alter table 表名 change 原名 新名 类型及约束;
-
例:alter table person change age sex int not null;
修改表-删除字段
-
alter table 表名 drop 列名;
-
例:alter table person drop sex;
删除表
-
drop table 表名;
-
例:drop table person;
数据表的基本增删改查(curd)
-
添加数据两种方式
-
方式一:insert into person(id,name) values(1,'zs');
-
方式二:insert into person values(2,'ls');
-
-
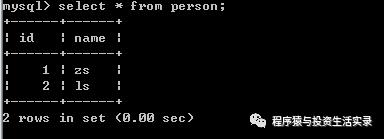
查询全部表数据
-
select * from person;
-
-
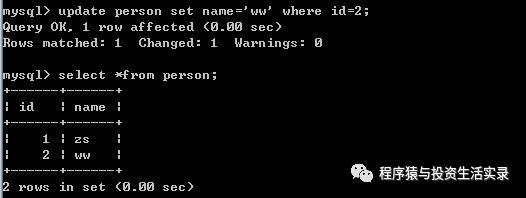
修改表数据
-
update person set name='ww' where id=2;
-
-
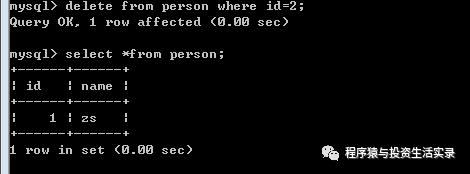
删除表数据
-
delete from person where id=2;
-
数据表的查询
-
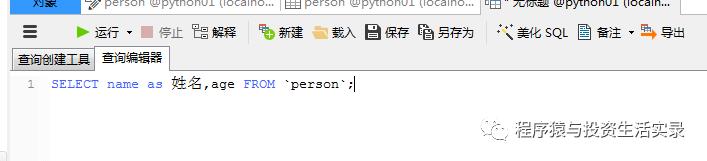
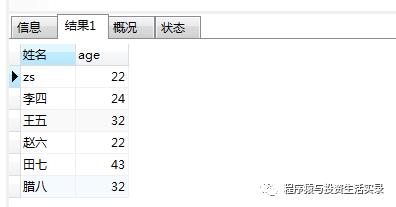
使用as 给字段起别名
-
select name as 姓名,age from person;
-
-
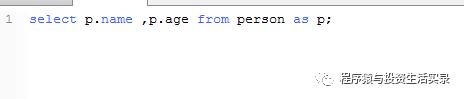
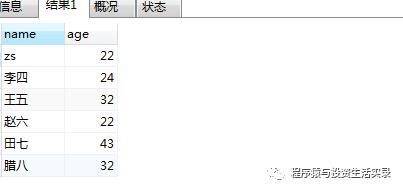
使用as 给表起别名
-
select p.name ,p.age from person as p;
-
-
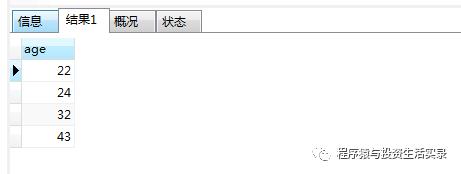
去除重复的年龄 (DISTINCT )
-
SELECT DISTINCT age from person;
-
-
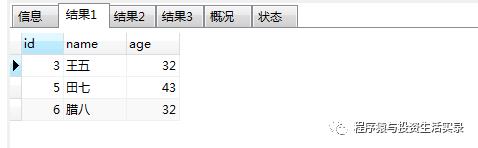
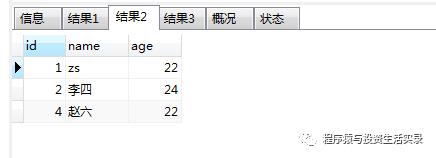
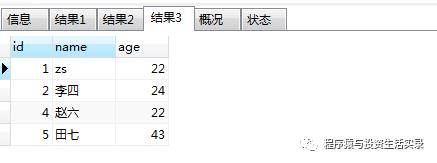
查询大于30岁的人; 小于30岁的人; 不等于32岁的人; (>,<,<>)
-
SELECT * from person where age>30;
-
SELECT * from person where age<30;
-
SELECT * from person where age<>32;
-
-
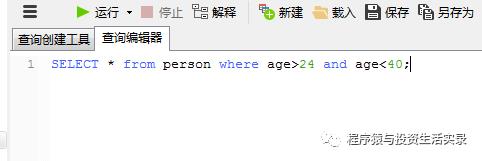
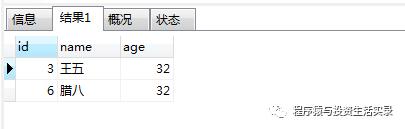
查询年龄在 24到40之间的人 (> ,<)
-
SELECT * from person where age>24 and age<40;
-
-
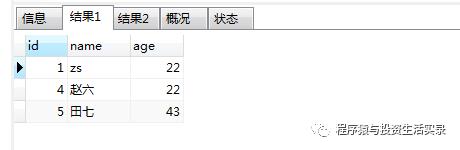
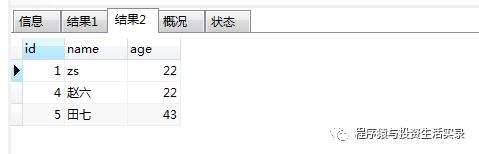
查询年龄是22或43的人 (or 或 in)
-
方式一:SELECT * from person where age=22 or age=43;
-
方式二:SELECT * from person where age in (22,43);
-
-
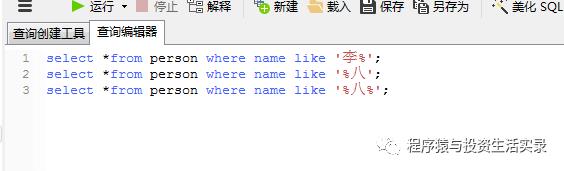
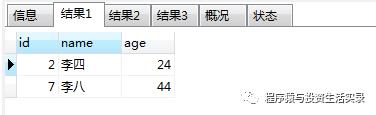
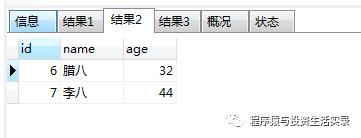
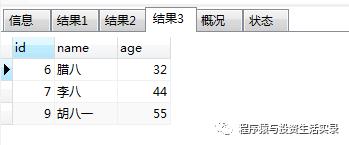
查询名字前面是李 开头的 ( like 'xxx%');查询后面是八 结尾的( like '%xxx');查询名字中间有八的 ( like '%xxx%')
-
select *from person where name like '李%';
-
select *from person where name like '%八';
-
select *from person where name like '%八%';
-
-
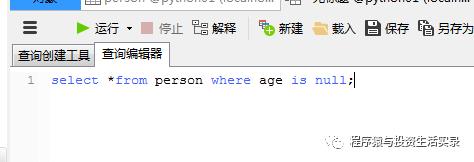
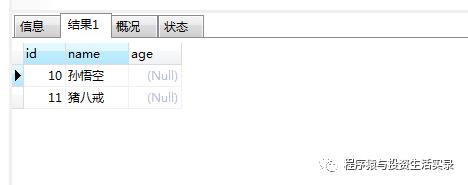
查询年龄为null的人 (is null)
-
select *from person where age is null;
-
-
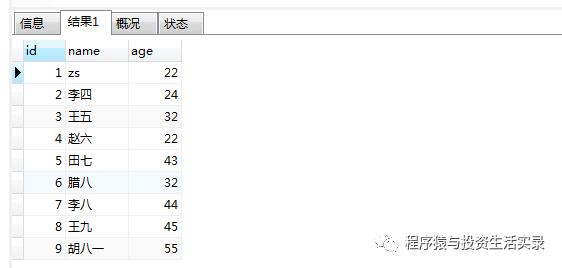
查询年龄不为null的人 ( is not null )
-
select *from person where age is not null;
-
-
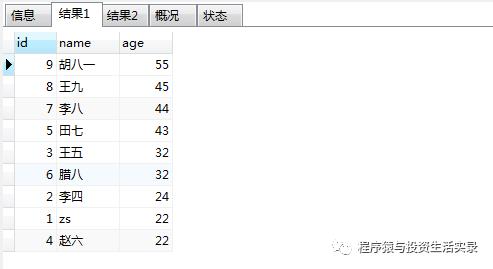
按年龄从大到小排序(order by xxx desc);按年龄从小到大排序 (order by xxx asc)
-
select *from person where age is not null order by age desc;
-
select *from person where age is not null order by age asc;
-
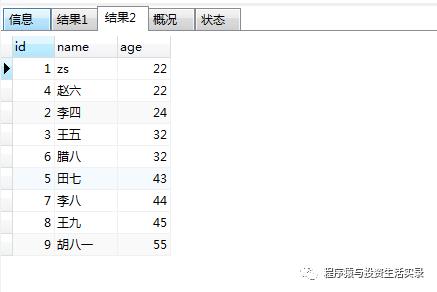
-
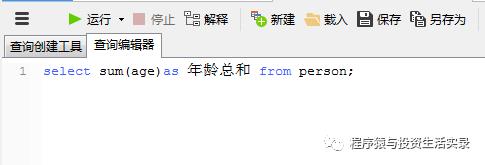
查询所有人年龄的总和 ( sum )
-
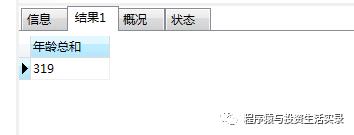
select sum(age) as 年龄总和 from person;
-
-
查询总共有多少人 (count)
-
select count(*) as 总人数 from person;
-
-
查询最大的年龄 (max);查询最小的年龄 (min)
-
select max(age) as 最大年龄 from person;
-
select min(age) as 最小年龄 from person;
-
-
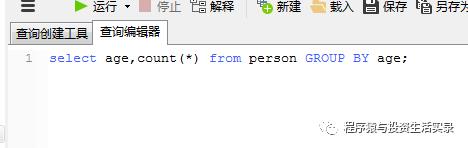
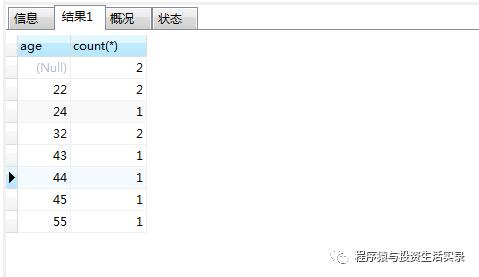
按年龄分组统计人数 (group by)
-
select age,count(*) from person GROUP BY age;
-
-
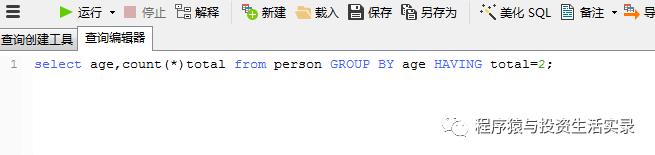
按年龄分组统计人数,并统计相同年龄人数有2个的 (HAVING )
-
select age,count(*)total from person GROUP BY age HAVING total=2;
-
程序猿与投资生活实录已改名为 程序猿知秋,WX同款,欢迎关注!
从青铜到黄金,对着mysql学,一文搞定mongoDB
Mongodb基础入门教程
项目中使用的技术五花八门,接触了很多新技术,之前也没用过mongo,今天恶补一下基础的知识,开始吧。
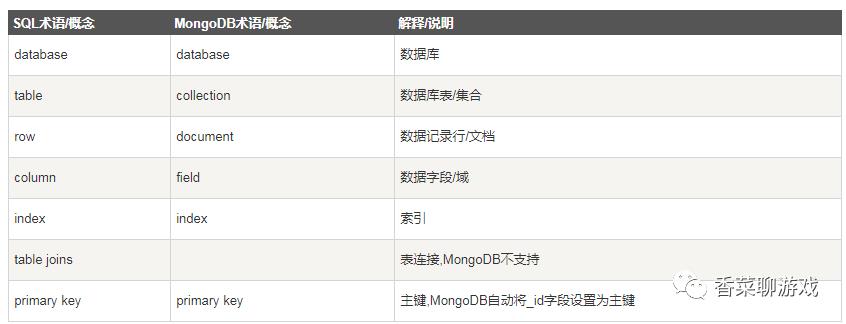
1、mongo 和 mysql 概念 对比
一个刚毕业的学生都知道mysql ,所以说关系型数据库就像我们的母语一样,在学习新的数据库的时候进行知识迁移,先来类比一下mysql 的概念。
2、插入文档
MongoDB 使用 insert() 或 save() 方法向集合中插入文档
例子
db.col.insert({title: 'MongoDB 教程',
description: 'MongoDB 是一个 Nosql 数据库',
by: '菜鸟教程',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})以上实例中 col 是我们的集合名,如果该集合不在该数据库中, MongoDB 会自动创建该集合并插入文档。
3、更新文档
update() 方法用于更新已存在的文档
save() 方法通过传入的文档来替换已有文档,_id 主键存在就更新,不存在就插入
语法:
db.getCollection('test_data_1').updateMany(
// 下面是查询条件
{"字段名1":"查找条件1","字段名2":"查找条件2"},
// 进行修改
{"$set":{"字段名":"新的数据","字段名":"新的数据"}
})-
updateOne:只更新第一条符合条件的数据
-
updateMany:更新所有符合条件的数据
4、删除文档
例子:
db.getCollection('test_data_1').deleteMany(
// 删除的条件
{"字段名1":"值","字段名2":"值2"}
)deleteOne和deleteMany。和修改数据的情况差不多,一个是删除第一条满足条件的,一个是删除所有满足条件的。
5、查询
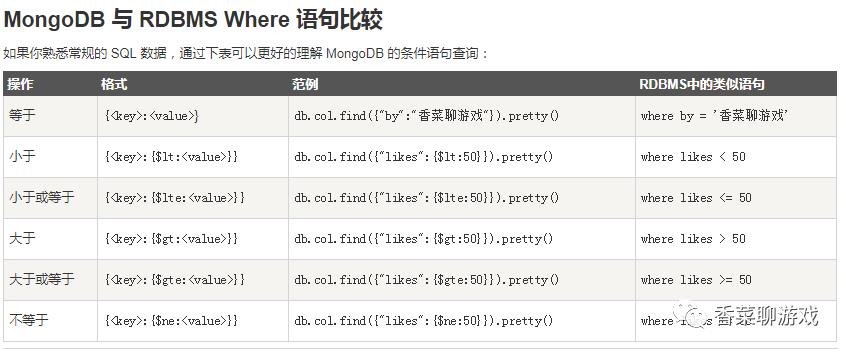
MongoDB 查询数据的语法格式如下:
db.collection.find(query, projection)-
query :可选,使用查询操作符指定查询条件
-
projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件
db.col.find({"by":"香菜聊游戏", "title":"MongoDB 教程"})等价于:WHERE by='香菜聊游戏' AND title='MongoDB 教程'
MongoDB OR 条件语句使用了关键字 $or
db.col.find({$or:[{"by":"香菜聊游戏"},{"title": "MongoDB 教程"}]})等价于:WHERE by='香菜聊游戏' or title='MongoDB 教程'
6、查询排序
在 MongoDB 中使用 sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
例子 :
db.col.find({},{"title":1,_id:0}).sort({"likes":-1})-
得到数据的条数
db.getCollection('test_data_1').find({}).count()7、索引:
单个索引
db.col.createIndex({"title":1})Key 值为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1
复合索引:
db.col.createIndex({"title":1,"description":-1})8、限制数量
db.col.find({},{"title":1,_id:0}).limit(2)除了可以使用limit()方法来读取指定数量的数据外,还可以使用skip()方法来跳过指定数量的数据,skip方法同样接受一个数字参数作为跳过的记录条数。
db.col.find({},{"title":1,_id:0}).limit(1).skip(1)9、去重
在mongodb中进行数据去重是一个很简单的操作。使用distinct即可。它可以接收两个参数,第一个参数为需要被去重的字段名,第二个参数是进行去重的条件(去重条件也就是进行查询操作的第一个参数,可以省略)。
db.getCollection('test_data_1').distinct(去重的字段名,去重的条件)db.getCollection('test_data_1').distinct("name",{"age":{"$ne":10}})最佳实践
-
集合名全部小写
-
禁止使用数字打头的库名
-
文档中的 key 禁止使用任何 " _ "(下划线)以外的特殊字符
-
尽量存放统一了大小写后的数据
-
在创建集合时,规划好索引,在集合为空的时候创建索引
-
索引的数量越少越好,
-
mongo不支持表连接
-
设定合适的MongoDB连接池大小,Java驱动的默认连接池大小是100
-
不要实例化多个MongoClient。MongoClient是个线程安全的类,自带线程池。通常在一个JVM内不要实例化多个MongoClient实例,避免连接数过多和资源的不必要浪费
以上是关于Python(黄金时代)——mysql数据库基础的主要内容,如果未能解决你的问题,请参考以下文章