Hadoop综合案例之陌陌聊天数据分析
Posted 黑马程序员官方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop综合案例之陌陌聊天数据分析相关的知识,希望对你有一定的参考价值。
一、陌陌聊天数据分析案例需求
背景介绍
陌陌作为聊天平台每天都会有大量的用户在线,会出现大量的聊天数据,通过对聊天数据的统计分析,可以更好的 对用户构建精准的用户画像,为用户提供更好的服务以及实现高ROI的平台运营推广,给公司的发展决策提供精确的数据支撑。

目标
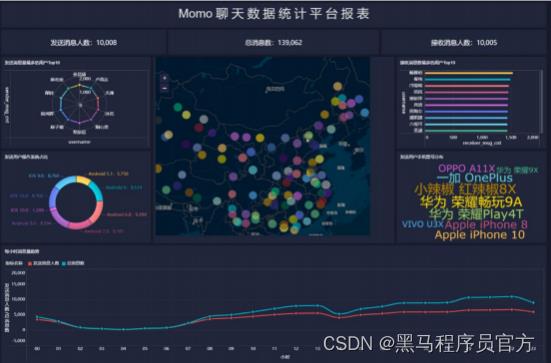
基于Hadoop和Hive实现聊天数据统计分析,构建聊天数据分析报表。

需求
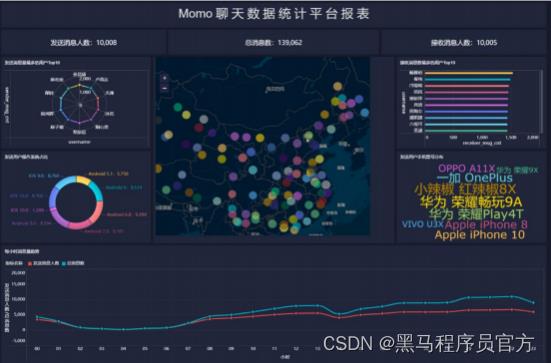
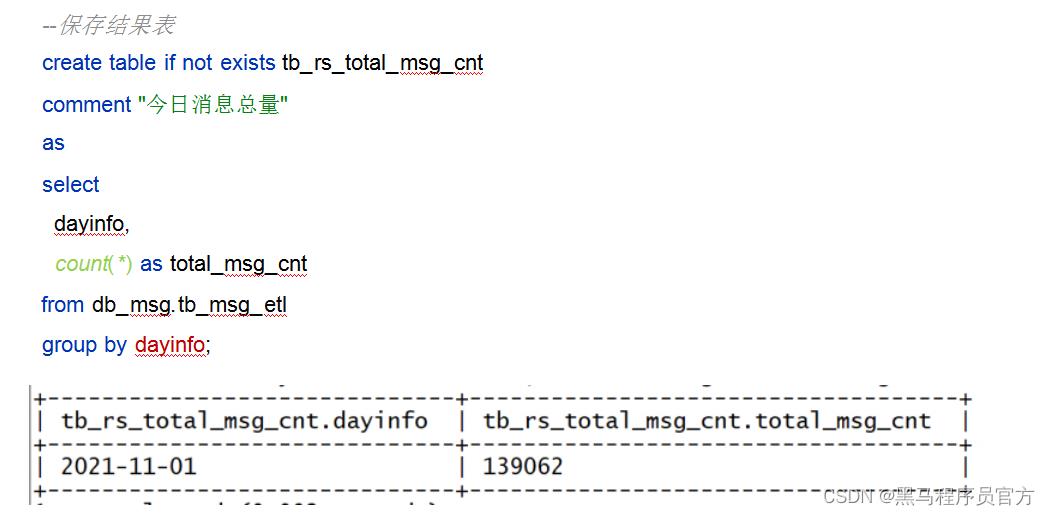
- 统计今日总消息量
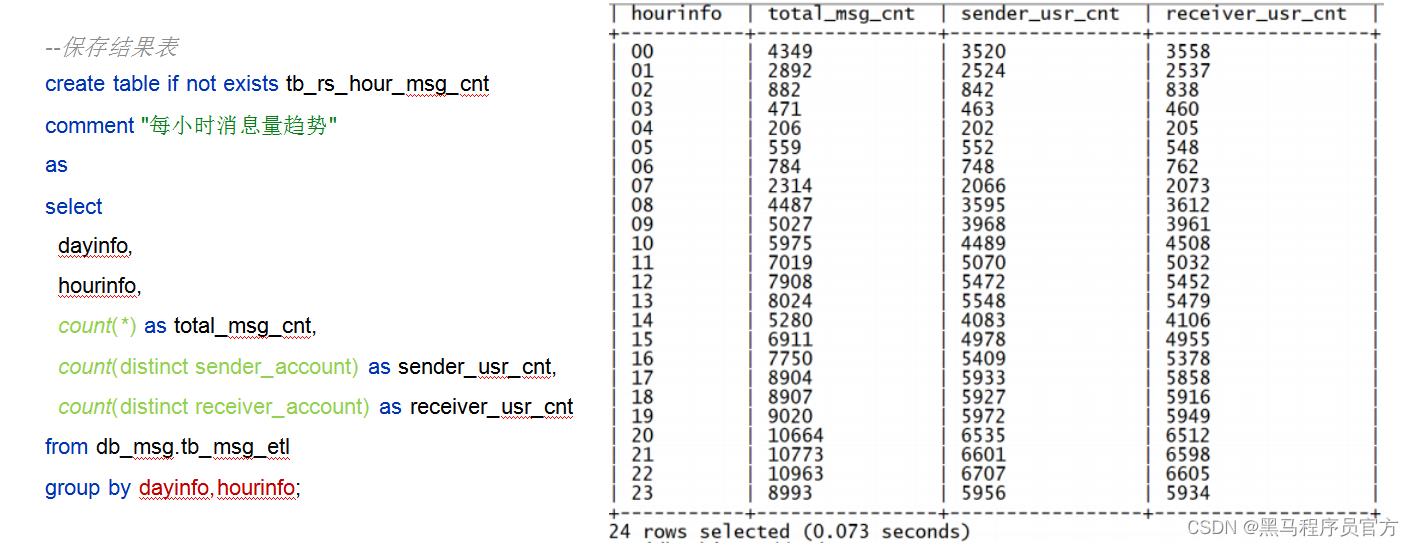
- 统计今日每小时消息量、发送和接收用户数
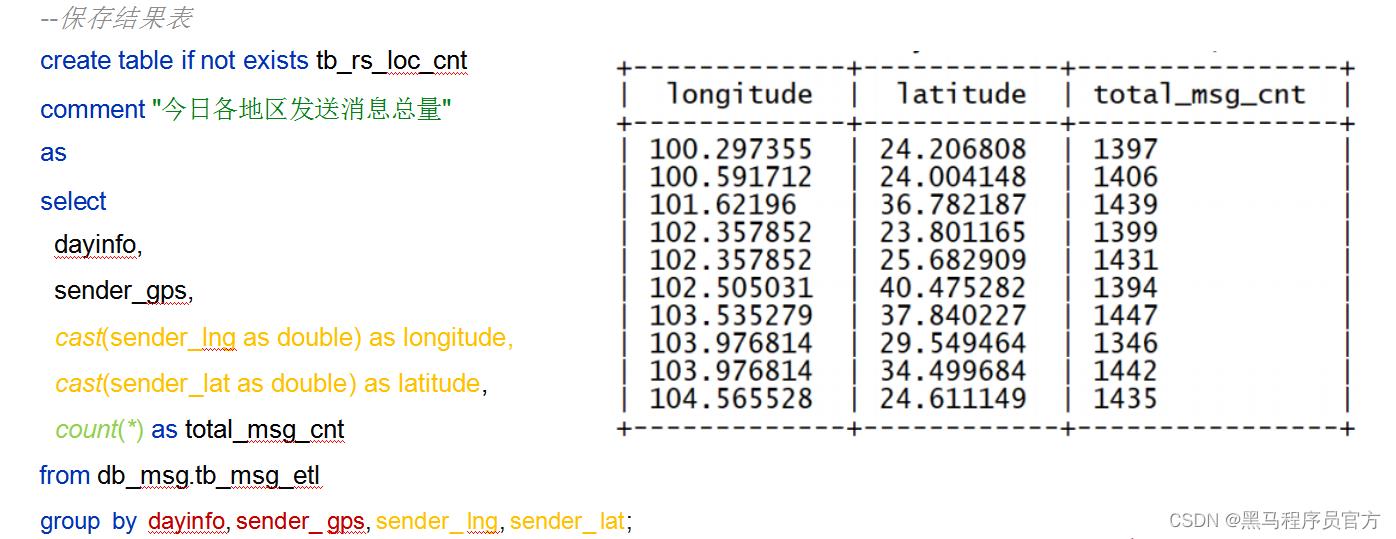
- 统计今日各地区发送消息数据量
- 统计今日发送消息和接收消息的用户数
- 统计今日发送消息最多的Top10用户
- 统计今日接收消息最多的Top10用户
- 统计发送人的手机型号分布情况
- 统计发送人的设备操作系统分布情况
数据内容
- 数据大小:两个文件共14万条数据
- 列分隔符: 制表符 \\t
- 数据字典及样例数据

二、基于Hive数仓实现需求开发
2.1 建库建表、加载数据
建库建表
--如果数据库已存在就删除
drop database if exists db_msg cascade ;
--创建数据库
create database db_msg ;
--切换数据库
use db_msg ;
--列举数据库
show databases ;


加载数据
- HDFS上创建目录
hdfs dfs -mkdir -p /momo/data
- 上传到HDFS
hdfs dfs -put /export/data/data1.tsv /momo/data/
hdfs dfs -put /export/data/data2.tsv /momo/data/
- 加载到Hive表中
load data inpath '/momo/data/data1.tsv' into table db_msg.tb_msg_source;
load data inpath '/momo/data/data2.tsv' into table db_msg.tb_msg_source;

验证结果
select
msg_time,sender_name,sender_ip,sender_phonetype,receiver_name,receiver_network
from tb_msg_source limit 10;

2.2 ETL数据清洗
原始数据内容
数据来源: 聊天业务系统中导出的2021年11月01日一天24小时的用户聊天数据,以TSV文本形式存储在文件中

数据问题
问题1:当前数据中,有一些数据的字段为空, 不是合法数据

问题2:需求中,需要统计每天、每个小时的消息量, 但是数据中没有天和小时字段,只有整体时间字段,不好处理

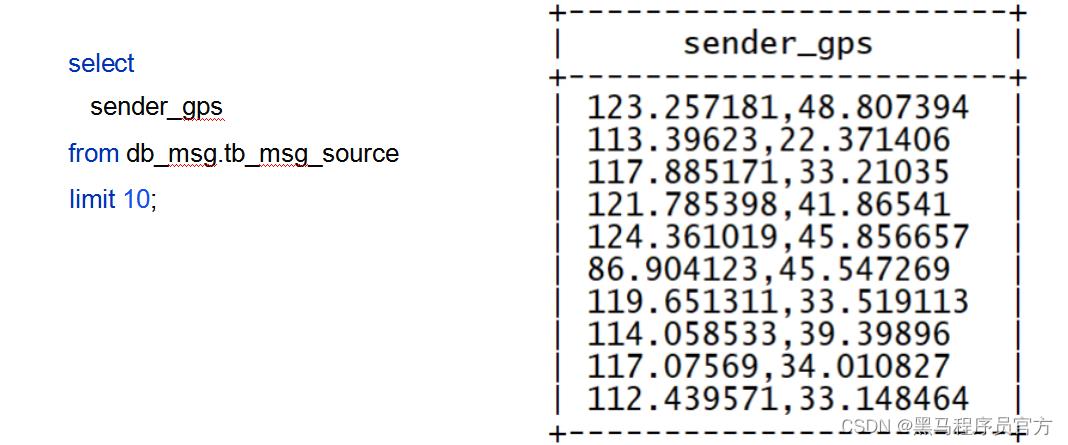
问题3:需求中,需要对经度和维度构建地区的可视化地图, 但是数据中GPS经纬度为一个字段,不好处理
ETL需求
需求1:对字段为空的不合法数据进行过滤
• Where过滤
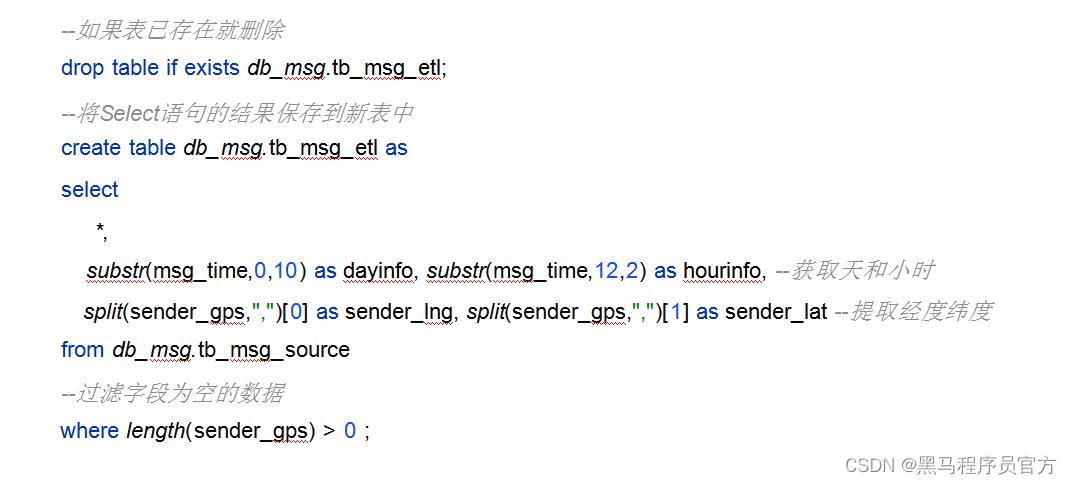
需求2:通过时间字段构建天和小时字段
• Substr函数
需求3:从GPS的经纬度中提取经度和维度
• Split函数
需求4:将ETL以后的结果保存到一张新的Hive表中
• Create table …… as select ……
ETL实现
查看结果
select
msg_time,dayinfo,hourinfo,sender_gps,sender_lng,sender_lat from db_msg.tb_msg_etl
limit 10;

2.3 需求指标统计
需求
- 统计今日总消息量
- 统计今日每小时消息量、发送和接收用户数
- 统计今日各地区发送消息数据量
- 统计今日发送消息和接收消息的用户数
- 统计今日发送消息最多的Top10用户
- 统计今日接收消息最多的Top10用户
- 统计发送人的手机型号分布情况
- 统计发送人的设备操作系统分布情况
查询类SQL编写思路举例
- 表: t_user(id, name, age, sex, city)
- 需求:统计每个城市男女人数与男女平均年龄
- 分组字段: 每个城市、男女
也就意味着同一个城市, 性别相同的人应该分到同一组,因此这里需要根据两个字段进行分组
- 聚合字段: 人数、平均年龄
count(id)就是统计每个分组中的条数-- >人数
avg(age)就是统计每个分组中年龄的平均值-- >平均年龄
需求指标统计
- 指标1:统计今日消息总量
- 指标2: 统计每小时消息量、发送和接收用户数
- 指标3: 统计今日各地区发送消息总量
- 指标4: 统计今日发送和接收用户人数
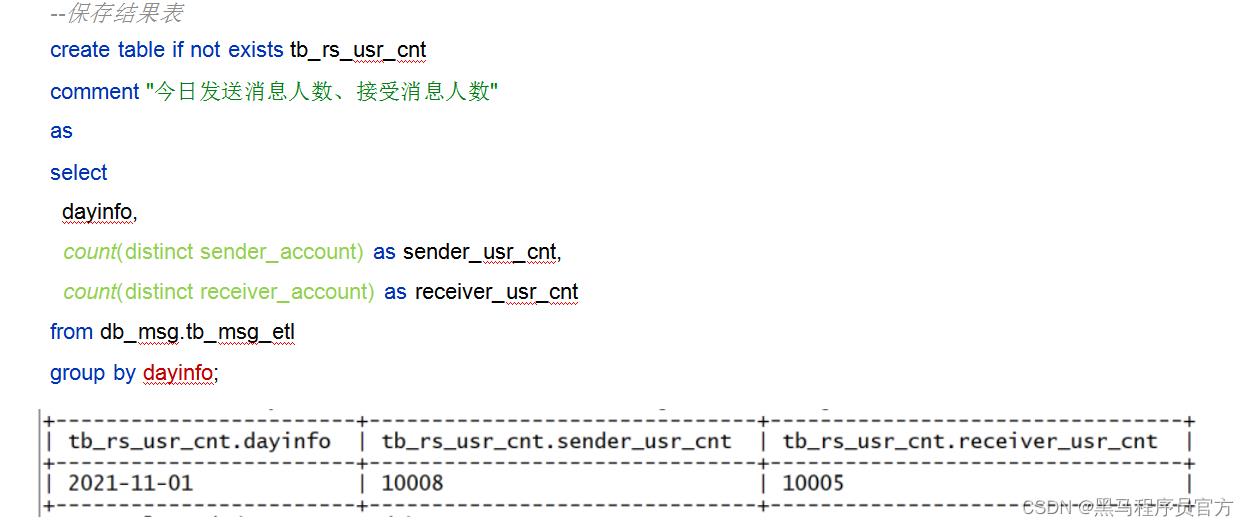
- 指标5: 统计发送消息条数最多的Top10用户

- 指标6: 统计接收消息条数最多的Top10用户

- 指标7: 统计发送人的手机型号分布情况

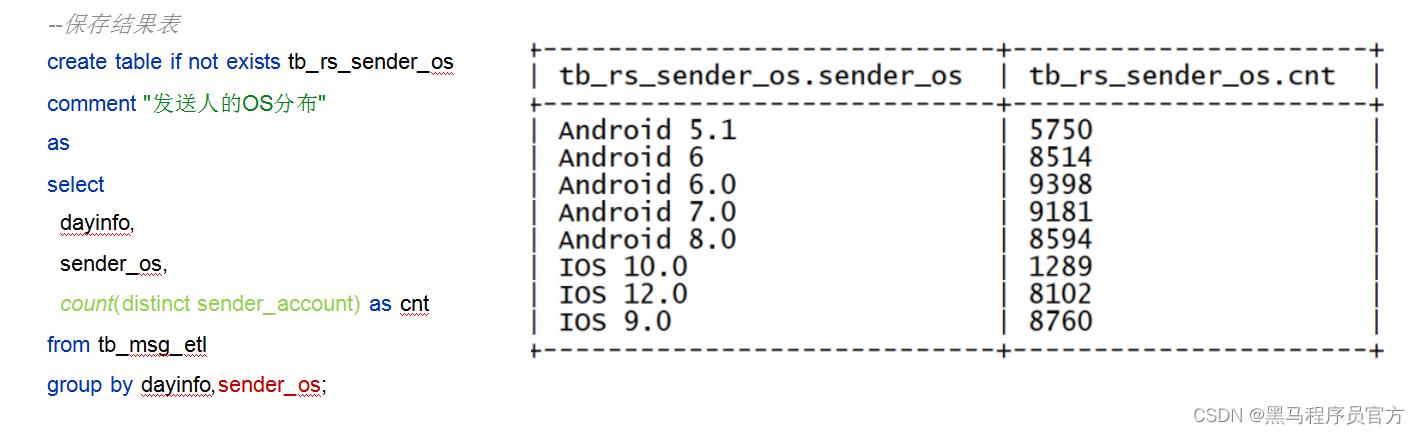
- 指标8: 统计发送人的操作系统分布
三、FineBI实现可视化报表
3.1 FineBI的介绍及安装
FineBI的介绍: https://www.finebi.com/
FineBI 是帆软软件有限公司推出的一款商业智能 ( Business Intelligence)产品 。 FineBI 是定位于自助大数据分 析的 BI 工具,能够帮助企业的业务人员和数据分析师,开展以问题导向的探索式分析。
FineBI的特点
- 通过多人协作来实现最
终的可视化构建
- 不需要通过复杂代码来
实现开发,通过可视化
操作实现开发
- 适合于各种数据可视化
的应用场景
- 支持各种常见的分析图
表和各种数据源
- 支持处理大数据

- FineBI的安装
参考《 FineBI Windows版安装手册》
- FineBI的界面
启动登陆
目录: 首页大屏及帮助文档
仪表盘: 用于构建所有可视化报表
数据准备: 用于配置各种报表的数据来源
管理系统: 用于管理整个FineBI的使用: 用户管理、数据源管理、插件管理、权限管理等
3.2 FineBI配置数据源及数据准备
FineBI与Hive集成的官方文档: https://help.fanruan.com/finebi/doc-view-301.html
驱动配置
问题:如果使用FineBI连接Hive,读取Hive的数据表,需要在FineBI中添加Hive的驱动jar包
解决:将Hive的驱动jar包放入FineBI的lib目录下
step1:找到提供的【Hive连接驱动】
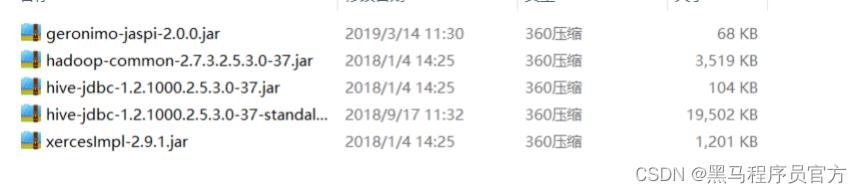
step2:将这些文件放入FineBI的安装目录下的:webapps\\webroot\\WEB- INF\\lib目录中

插件安装
问题:我们自己放的Hive驱动包会与FineBI自带的驱动包产生冲突,导致FineBI无法识别我们自己的驱动包
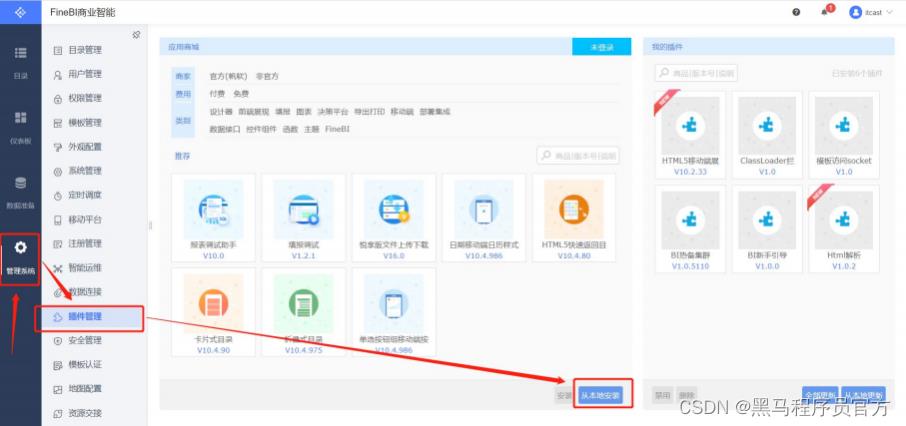
解决:安装FineBI官方提供的驱动包隔离插件
step1:找到隔离插件 
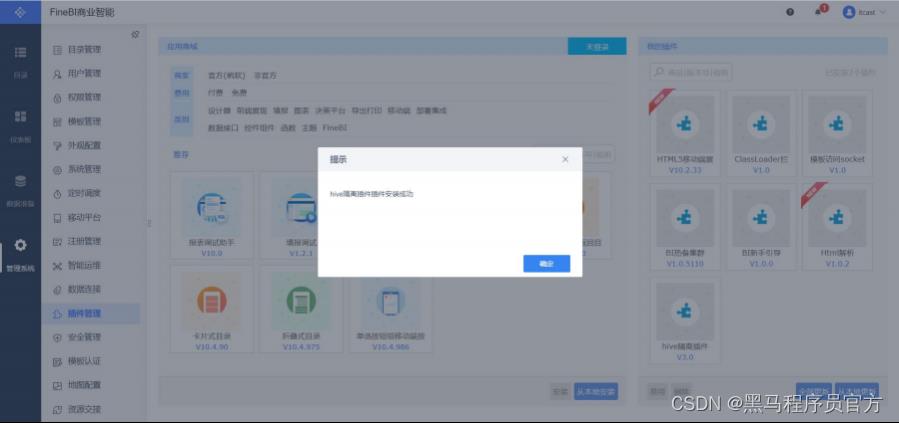
step2:安装插件
step3:重启FineBI
- 构建连接
新建连接
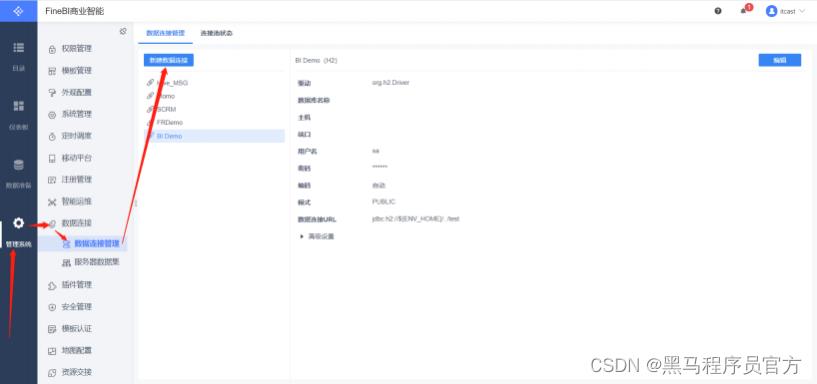

配置连接

测试连接
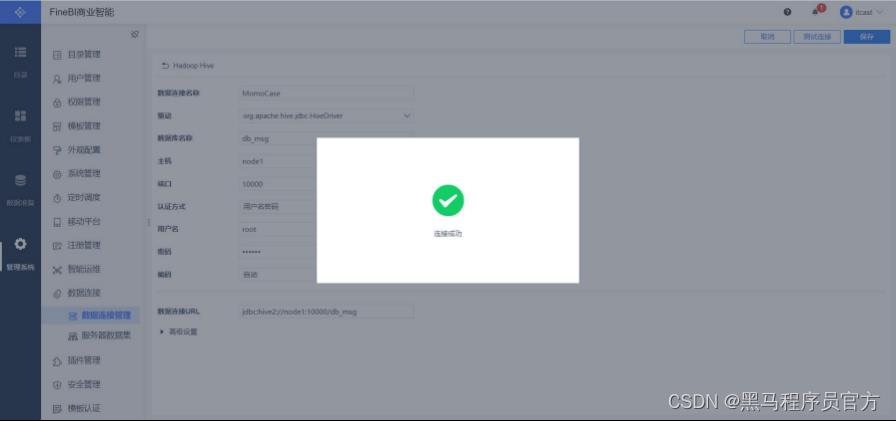
保存连接
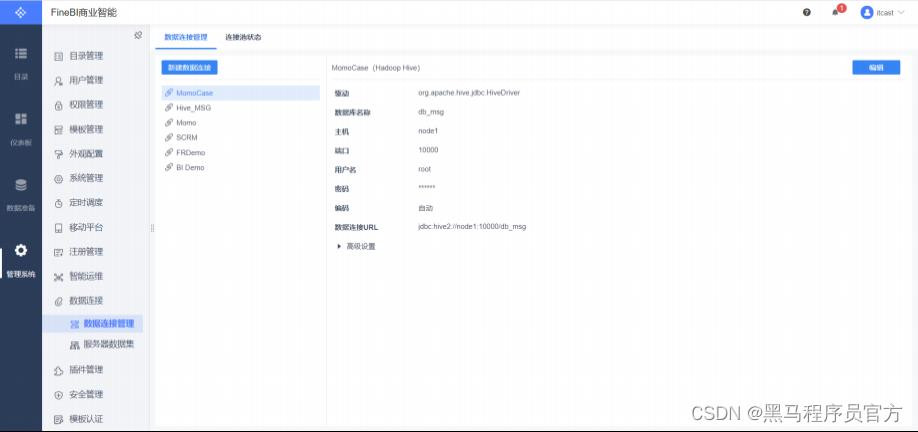
新建分组
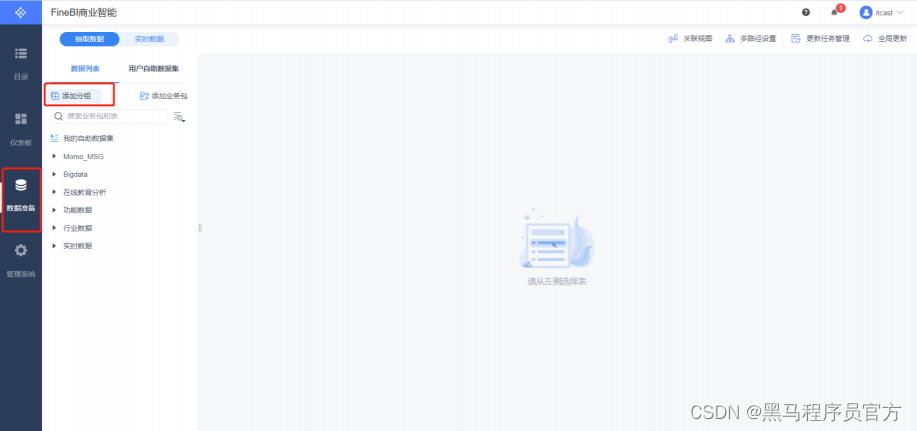
添加业务包
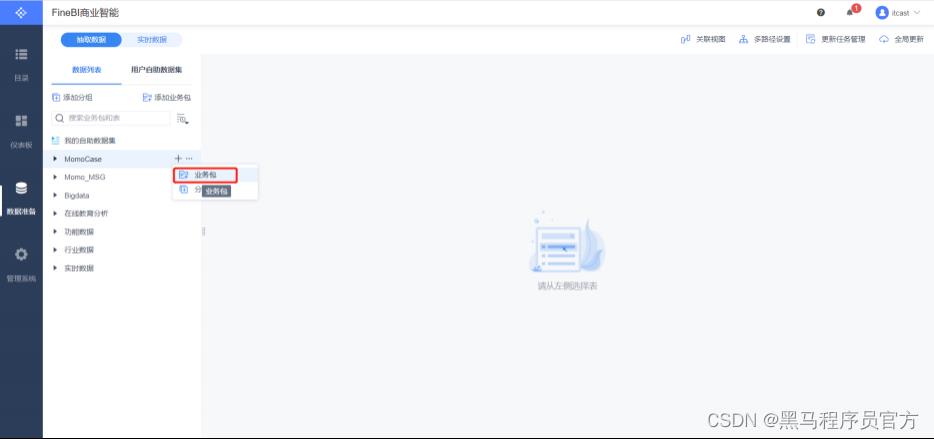
添加表


更新业务包

3.3 FineBI构建可视化报表
step1 :创建报表
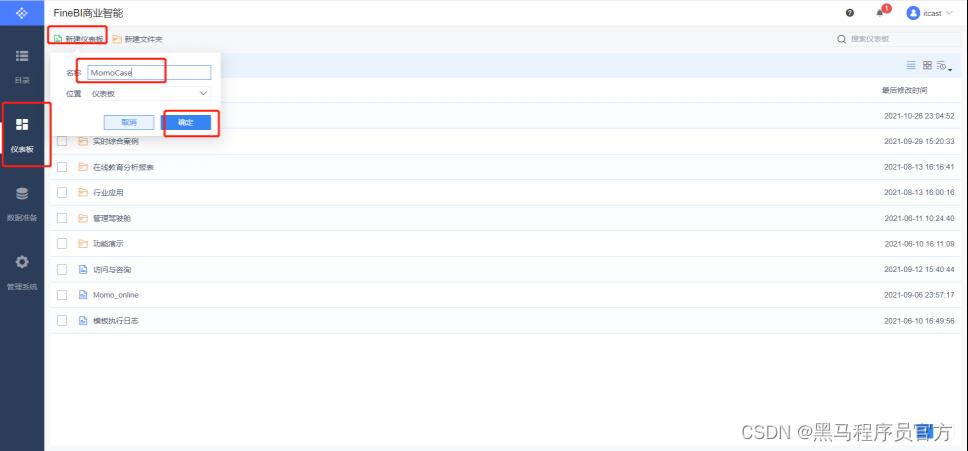
step2:选择仪表板样式

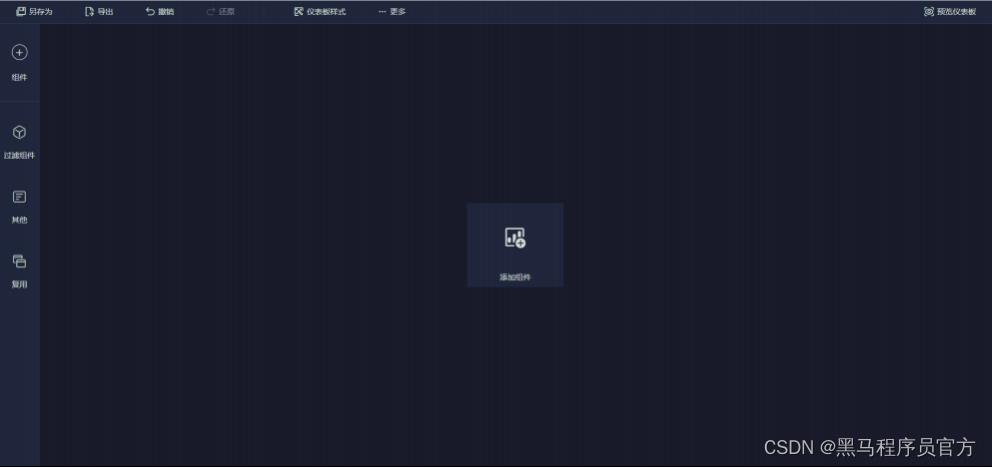
step3:添加标题
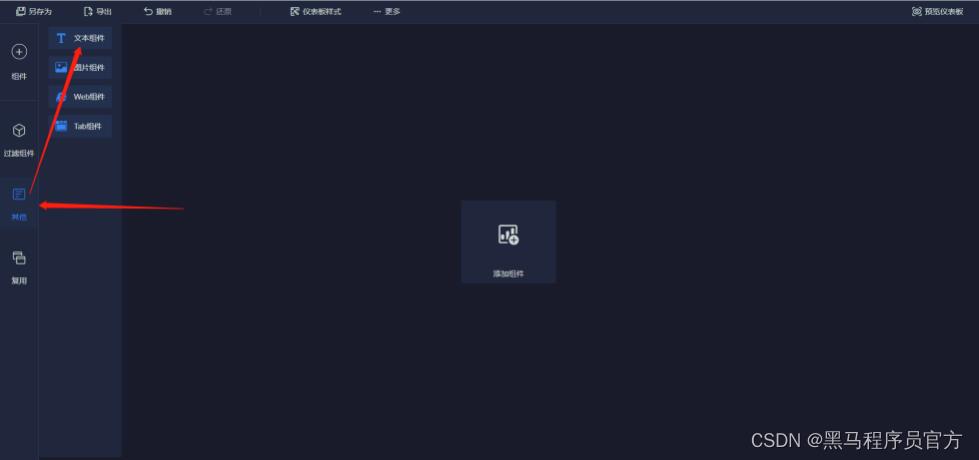
step4:编辑标题文本框(注意字体大小、居中、文本框位置可调整)
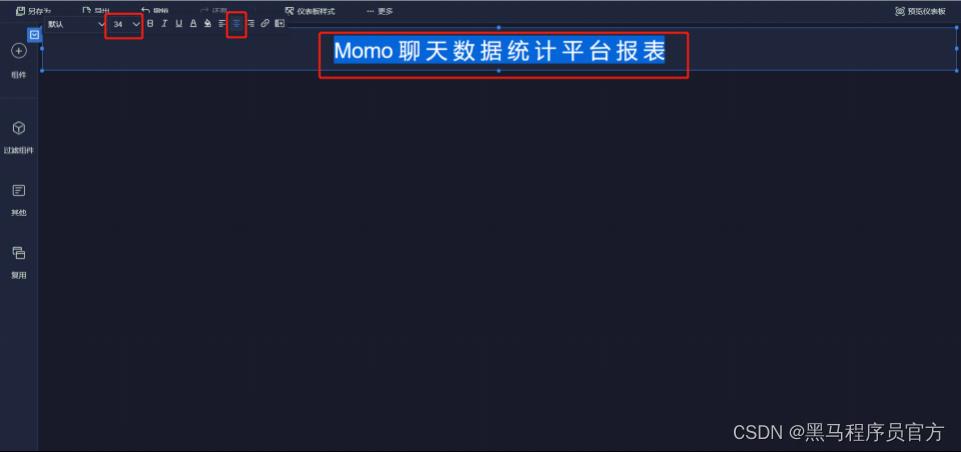
step5:添加文本内容(1/10)
step5:添加文本内容 (2/10) 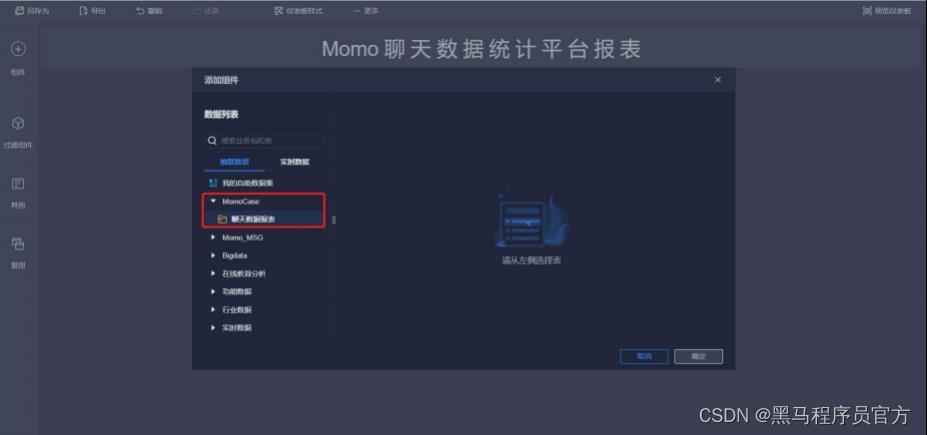
step5:添加文本内容 (3/10)
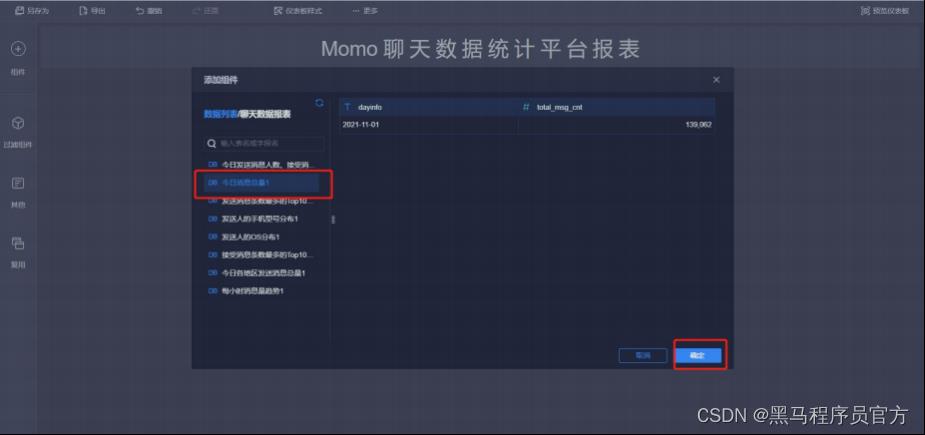
step5:添加文本内容 (4/10)

step5:添加文本内容 (5/10)
step5:添加文本内容 (6/10)
step5:添加文本内容 (7/10)
step5:添加文本内容 (8/10)

step5:添加文本内容 (9/10)

step5:添加文本内容 (10/10)
同理添加总发送消息人数和总接收消息人数

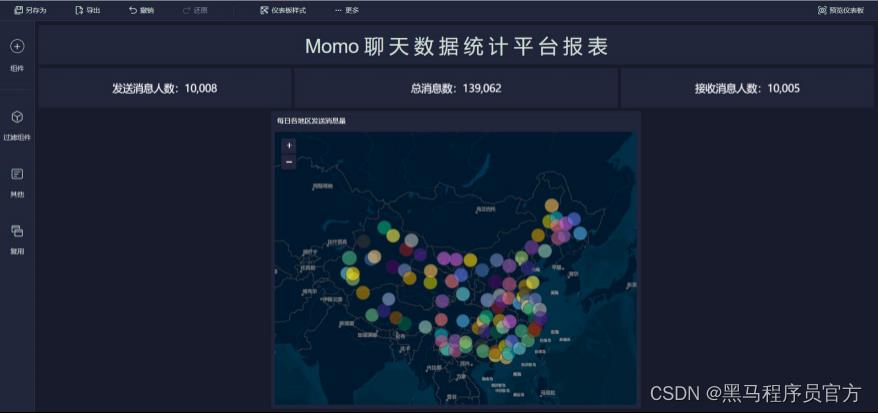
step6:添加地图(1/9)
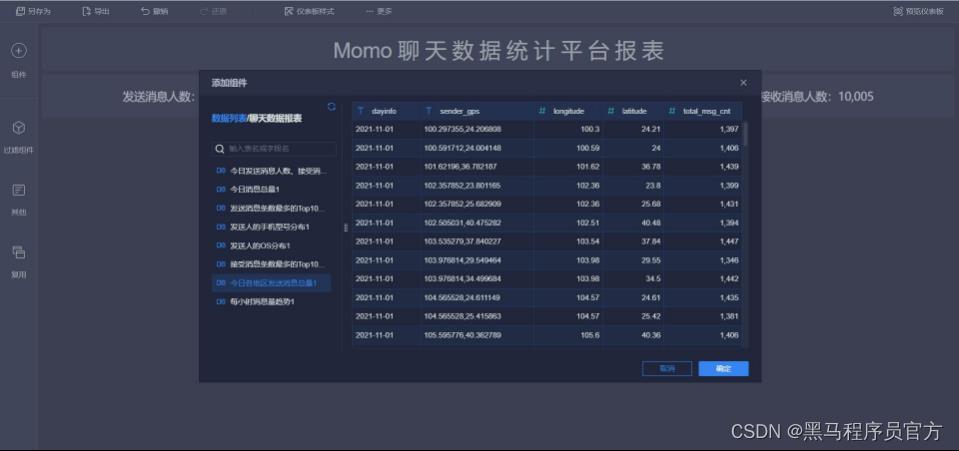
step6:添加地图 (2/9)
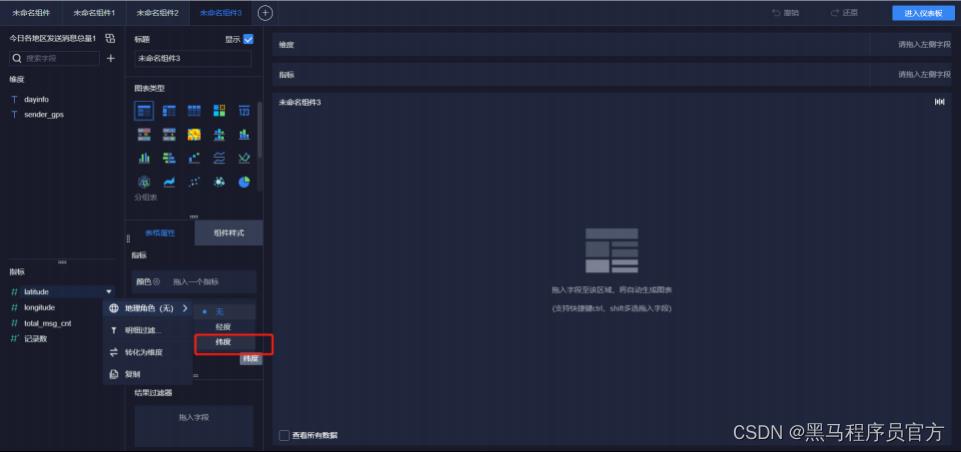
step6:添加地图 (3/9)

step6:添加地图 (4/9)
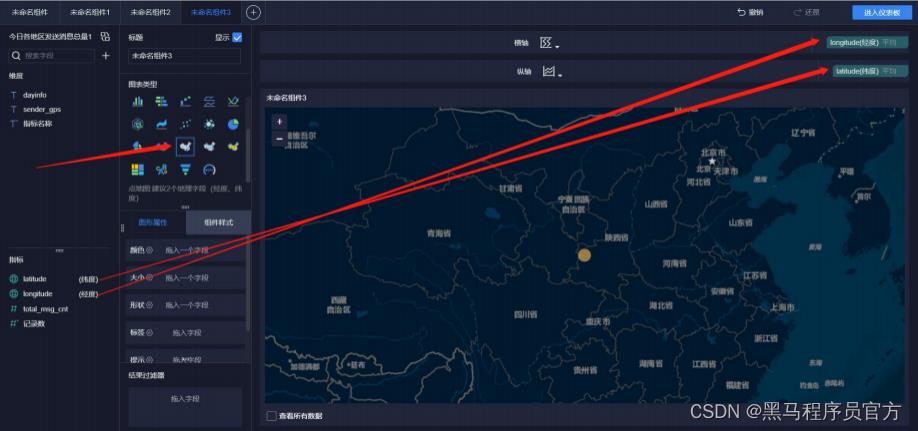
step6:添加地图 (5/9)

step6:添加地图 (6/9)
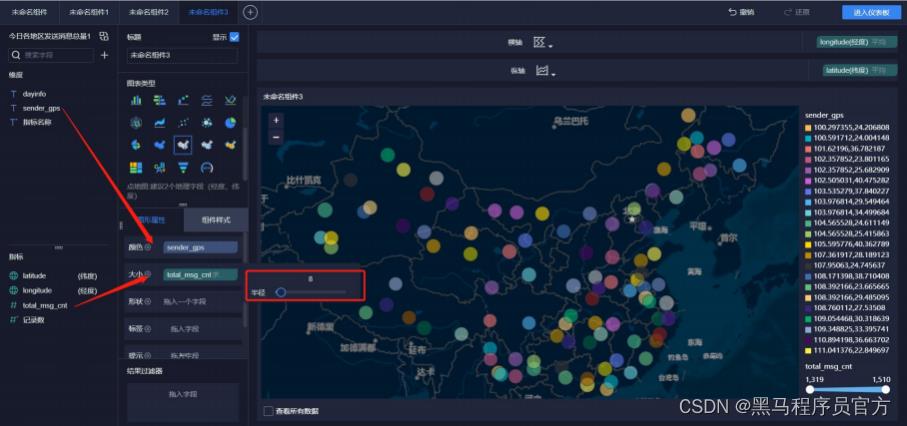
step6:添加地图 (7/9)
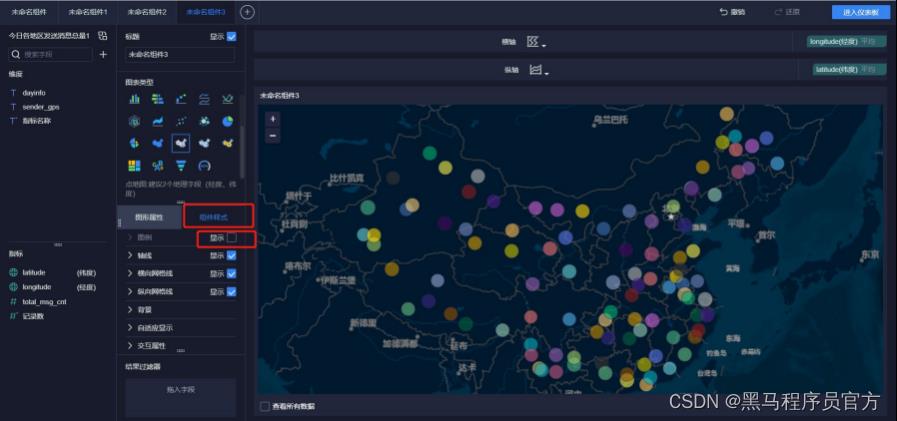
step6:添加地图 (8/9)

step6:添加地图 (9/9)
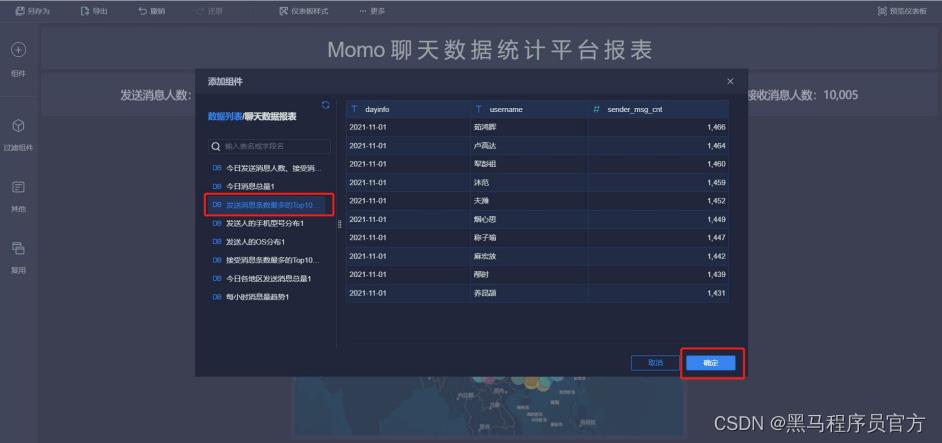
step7:添加雷达图(1/5)
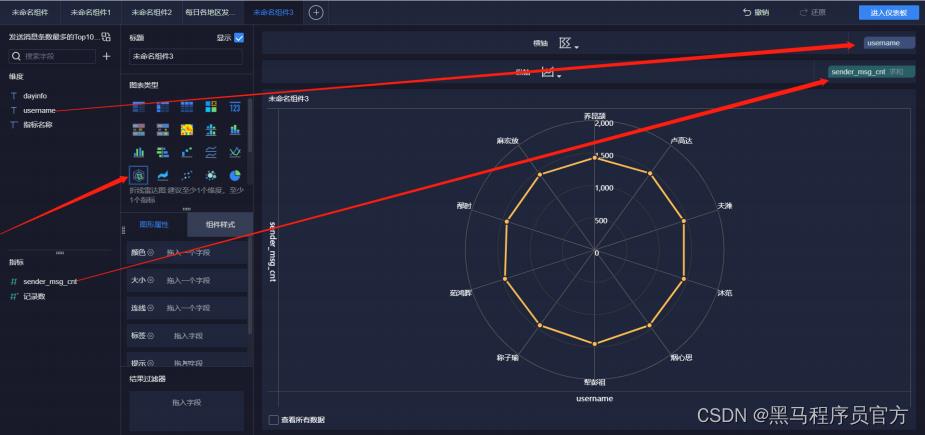
step7:添加雷达图 (2/5)
step7:添加雷达图 (3/5)
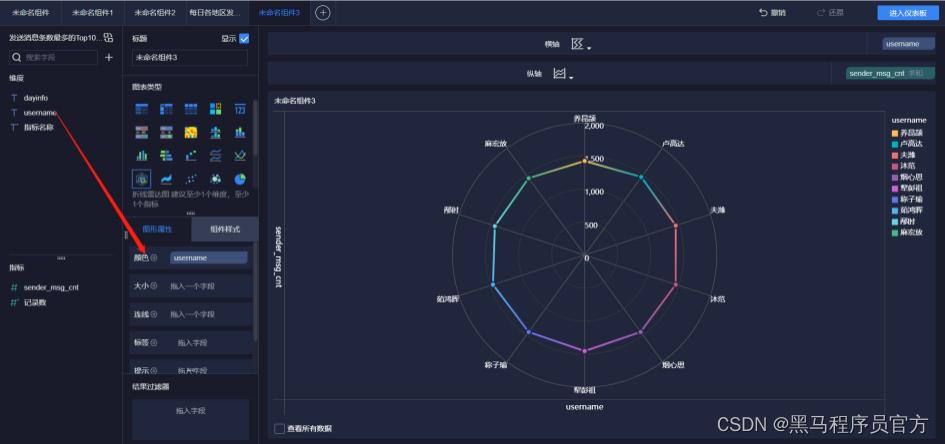
step7:添加雷达图 (4/5)
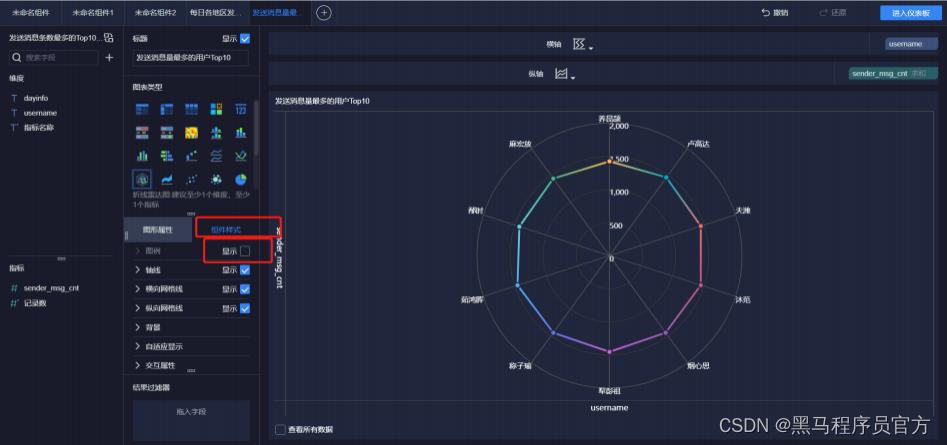
step7:添加雷达图 (5/5)
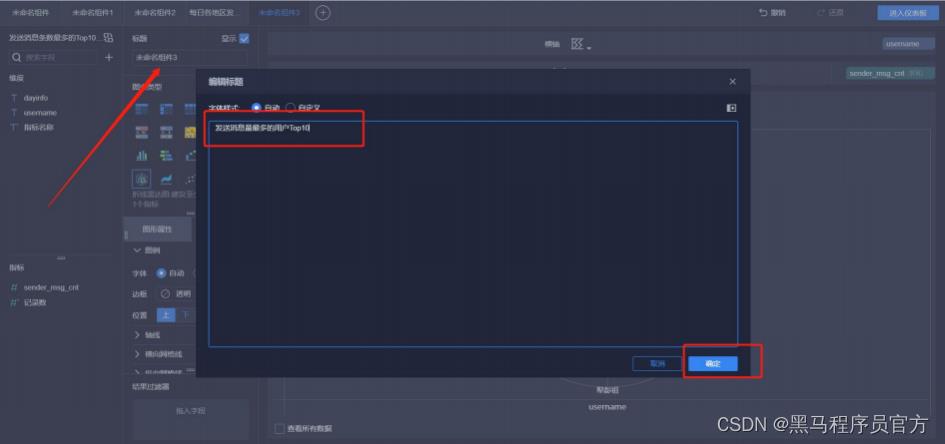
step8:添加柱状图(1/5)
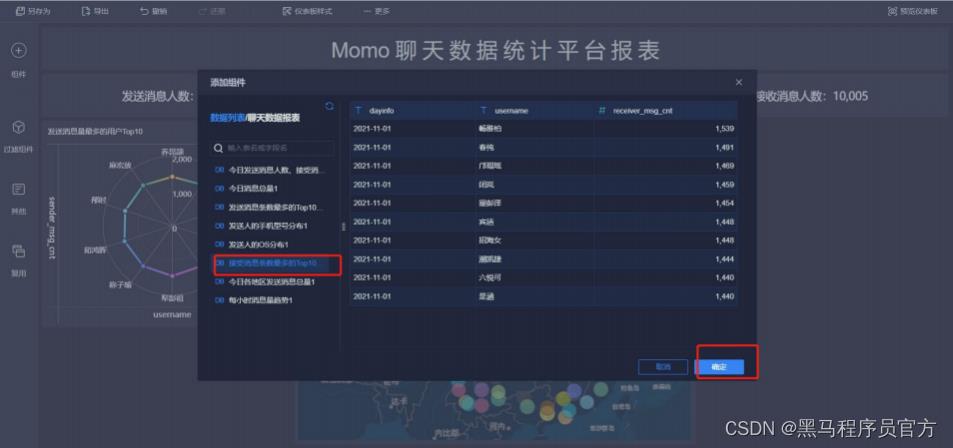
step8:添加柱状图(2/5)

step8:添加柱状图(3/5)

step8:添加柱状图(4/5)
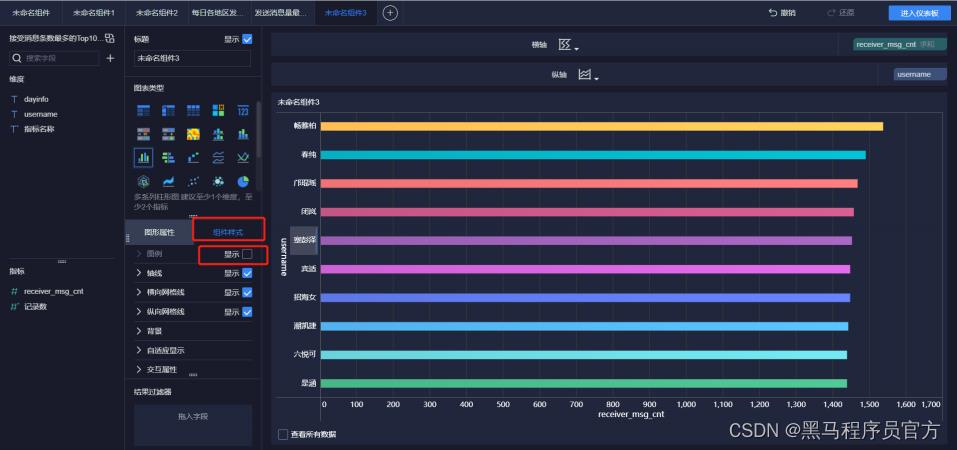
step8:添加柱状图(5/5)

step9:添加环饼状图(1/6)
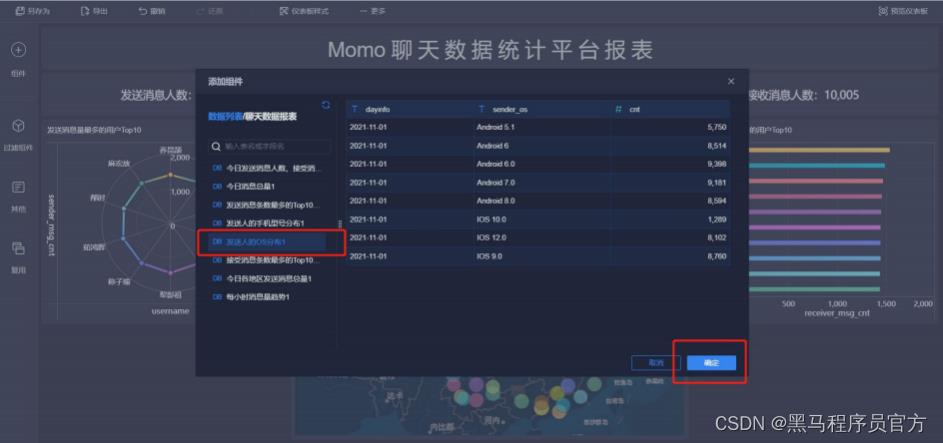
step9:添加环饼状图(2/6)
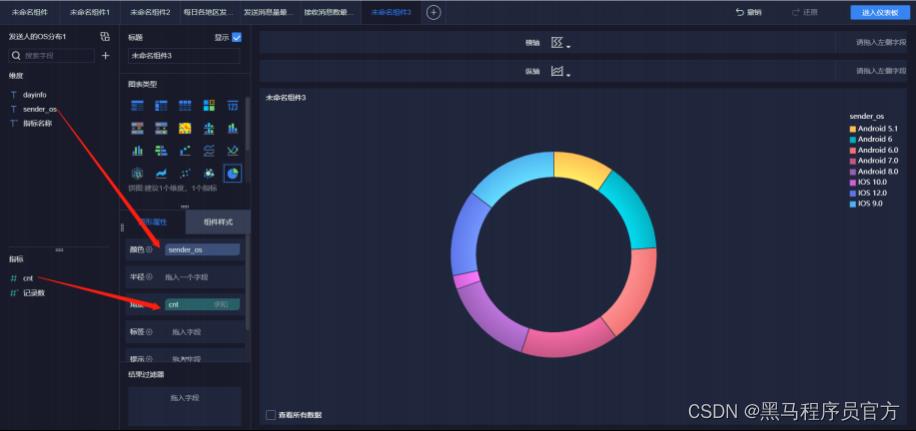
step9:添加环饼状图(3/6)
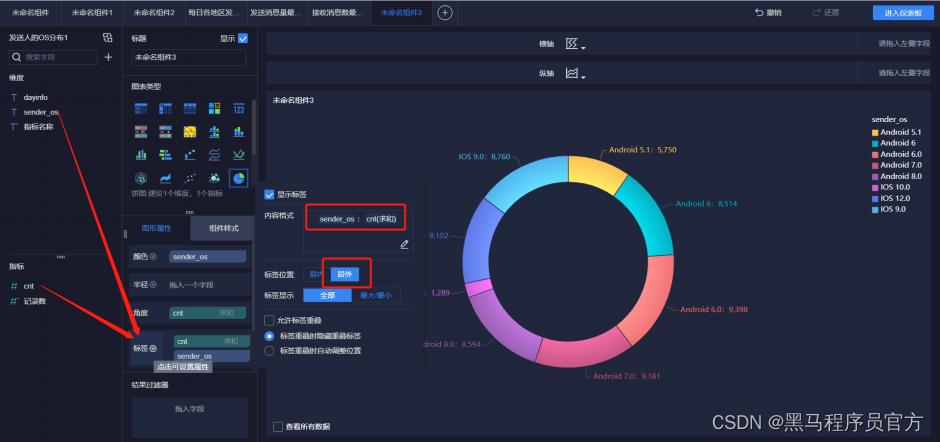
step9:添加环饼状图(4/6)
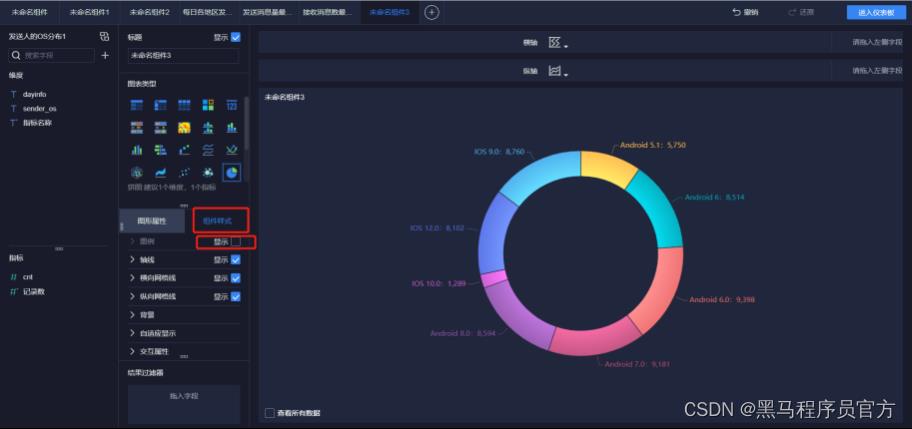
step9:添加环饼状图(5/6)

step9:添加环饼状图(6/6)

step10:添加词汇云图(1/5)
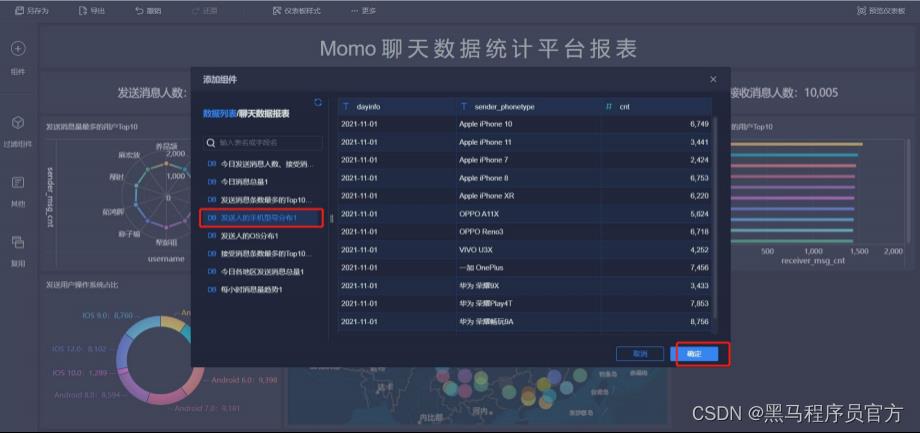
step10:添加词汇云图(2/5)
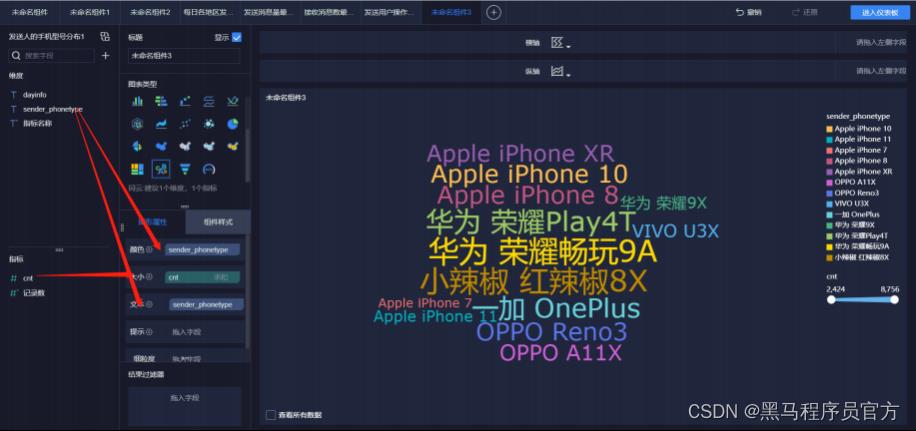
step10:添加词汇云图(3/5)
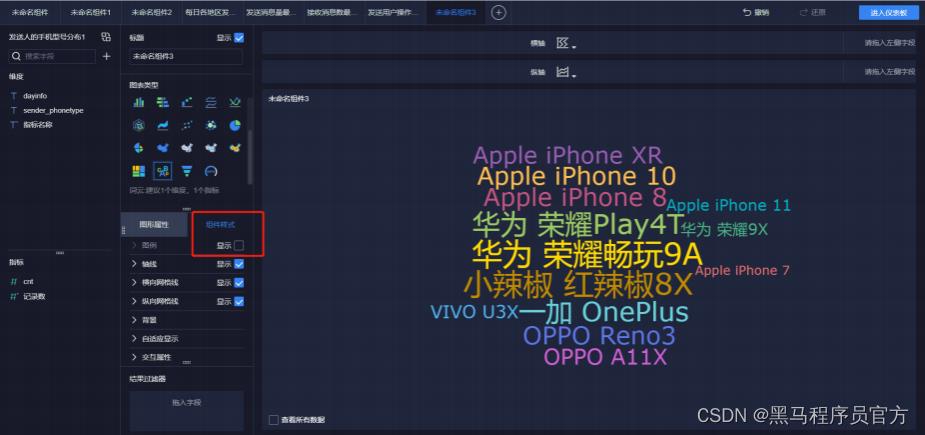
step10:添加词汇云图(4/5)

step10:添加词汇云图(5/5)

step11 :添加趋势曲线图(1/5)
 step11 :添加趋势曲线图(2/5)
step11 :添加趋势曲线图(2/5)
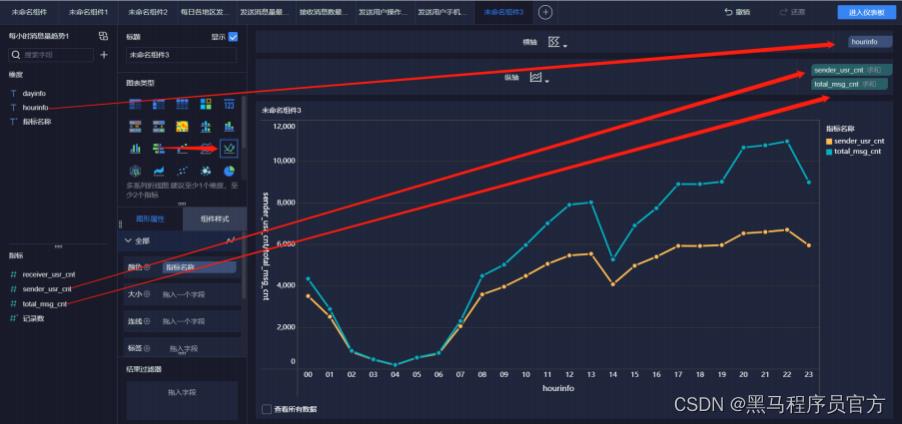
step11 :添加趋势曲线图(3/5)
step11 :添加趋势曲线图(4/5)
step11 :添加趋势曲线图(5/5)

step12:报表预览
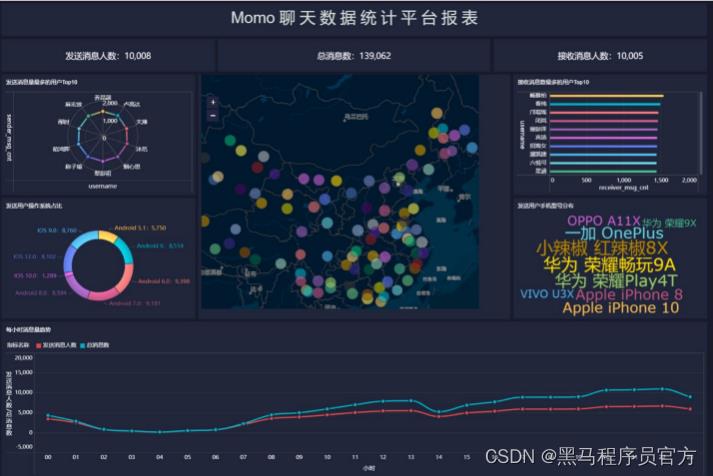
以上是关于Hadoop综合案例之陌陌聊天数据分析的主要内容,如果未能解决你的问题,请参考以下文章
❤️让人心跳加速的陌陌案例,大数据必需学会的基础案例!❤️ 推荐收藏