面试官:关于CPU你了解多少?
Posted Sivan_Xin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试官:关于CPU你了解多少?相关的知识,希望对你有一定的参考价值。
CPU是如何执行程序的?
程序执行的基本过程

- 第一步,CPU 读取「程序计数器」的值,这个值是指令的内存地址,然后 CPU 的「控制单元」操作「地址总线」指定需要访问的内存地址,接着通知内存设备准备数据,数据准备好后通过「数据总线」将指令数据传给 CPU,CPU 收到内存传来的数据后,将这个指令数据存入到「指令寄存器」。
- 第二步,「程序计数器」的值自增,表示指向下一条指令。这个自增的大小,由 CPU 的位宽决定,比如 32 位的 CPU,指令是 4 个字节,需要 4 个内存地址存放,因此「程序计数器」的值会自增 4;
- 第三步,CPU 分析「指令寄存器」中的指令,确定指令的类型和参数,如果是计算类型的指令,就把指令交给「逻辑运算单元」运算;如果是存储类型的指令,则交由「控制单元」执行;
简单总结:一个程序执行的时候,CPU 会根据程序计数器里的内存地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后程序计数器根据指令长度自增,开始顺序读取下一条指令。
- 在指令寄存器中,CPU会分析指令寄存器中的指令,确定指令的类型和参数,如果是计算类型的指令,就把指令交给「逻辑运算单元」运算;如果是存储类型的指令,则交由「控制单元」执行;
- 程序计数器自增的长度与CPU位宽决定,比如 32 位的 CPU,指令是 4 个字节,需要 4 个内存地址存放,因此「程序计数器」的值会自增 4;
CPU 从程序计数器读取指令、到执行、再到下一条指令,这个过程会不断循环,直到程序执行结束,这个不断循环的过程被称为 CPU 的指令周期。
-
冯诺依曼模型定义了计算机基本结构:运算器、控制器、存储器、输入输出设备。
-
内存
我们的程序和数据都是存储在内存,存储的区域是线性的。
在计算机数据存储中,存储数据的基本单位是字节(byte),1 字节等于 8 位(8 bit)。每一个字节都对应一个内存地址。
-
中央处理器(CPU)
中央处理器也就是我们常说的 CPU,32 位和 64 位 CPU 最主要区别在于一次能计算多少字节数据。这里的32位和64位,通常表示CPU的位宽。
- 32 位 CPU 一次可以计算 4 个字节;(4个字节就是32位 4 * 8)
- 64 位 CPU 一次可以计算 8 个字节;
CPU内部还有一些组件,常见的有寄存器,控制单元和逻辑运算单元
-
控制单元:负责控制CPU的工作。
-
逻辑运算单元:负责运算。
-
寄存器:存储计算时的数据,由于内存离CPU太远了,而寄存器就在CPU内部,计算速度更快。寄存器有以下几种:
- 通用寄存器:存放需要运算的数据。
- 程序计数器:存储CPU要执行的下一条指令的地址。
- 指令寄存器:存放当前正在执行的指令。
-
总线
负责各种设备之间的通信。比如CPU读取内存数据时,要通过三个总线:
- 先通过地址总线来指定内存的地址。
- 再通过控制总线来指定读或写的命令。
- 最后通过数据总线来传递数据。
-
线路位宽与CPU位宽
-
线路位宽:数据在线路中传输,其实是通过操作电压,低电压表示0,高电压表示1。这样一位一位进行传输的方式称为串行,想要一次性多传输数据,可以增加线路的位宽。比如CPU 想要操作内存地址就需要地址总线,可以通过增加线路位宽的方式,增加CPU能操作的最大内存地址数量。(注意,不是说同时操作的最大内存地址数量)
- 如果地址总线有 2 条,那么能表示 00、01、10、11 这四种地址,所以 CPU 能操作的内存地址最大数量为 4(2^2)个。那么,想要 CPU 操作 4G 大的内存,那么就需要 32 条地址总线,因为
2 ^ 32 = 4G。(32位对应有232个地址,对应的内存数是232 * 8bit=4Gbyte即4GB)
- 如果地址总线有 2 条,那么能表示 00、01、10、11 这四种地址,所以 CPU 能操作的内存地址最大数量为 4(2^2)个。那么,想要 CPU 操作 4G 大的内存,那么就需要 32 条地址总线,因为
-
CPU位宽:CPU 的位宽最好不要小于线路位宽,否则工作起来会非常复杂且麻烦。如果计算的数额不超过 32 位数字的情况下,32 位和 64 位 CPU 之间没什么区别的,只有当计算超过 32 位数字的情况下,64 位的优势才能体现出来。
- 另外,32 位 CPU 最大只能操作 4GB 内存,就算你装了 8 GB 内存条,也没用。而 64 位 CPU 寻址范围则很大,理论最大的寻址空间为
2^64。
- 另外,32 位 CPU 最大只能操作 4GB 内存,就算你装了 8 GB 内存条,也没用。而 64 位 CPU 寻址范围则很大,理论最大的寻址空间为
-
-
a = 1 + 2的执行具体过程
-
程序—>汇编语言—>计算机指令
CPU 是不认识
a = 1 + 2这个字符串,这些字符串只是方便我们程序员认识,要想这段程序能跑起来,还需要把整个程序翻译成汇编语言的程序,这个过程称为编译成汇编代码。针对汇编代码,我们还需要用汇编器翻译成机器码,这些机器码由 0 和 1 组成的机器语言,这一条条机器码,就是一条条的计算机指令,这个才是 CPU 能够真正认识的东西。 -
程序编译过程中,编译器分析代码,发现1和2是数据,所以放在内存中的「数据段」,编译器会把a = 1 + 2翻译成4条指令,存放到正文段中。
-
编译完成后,具体执行程序的时候,程序计数器会被设置为 0x100 地址,然后依次执行这 4 条指令。
-
-
上面的例子中,由于是在 32 位 CPU 执行的,因此一条指令是占 32 位大小,所以你会发现每条指令间隔 4 个字节。而数据的大小是根据你在程序中指定的变量类型,比如
int类型的数据则占 4 个字节,char类型的数据则占 1 个字节。 -
你知道软件的 32 位和 64 位之间的区别吗?再来 32 位的操作系统可以运行在 64 位的电脑上吗?64 位的操作系统可以运行在 32 位的电脑上吗?如果不行,原因是什么?
-
64 位和 32 位软件,实际上代表指令是 64 位还是 32 位的:
- 如果 32 位指令在 64 位机器上执行,需要一套兼容机制,就可以做到兼容运行了。但是如果 64 位指令在 32 位机器上执行,就比较困难了,因为 32 位的寄存器存不下 64 位的指令;
- 操作系统其实也是一种程序,我们也会看到操作系统会分成 32 位操作系统、64 位操作系统,其代表意义就是操作系统中程序的指令是多少位,比如 64 位操作系统,指令也就是 64 位,因此不能装在 32 位机器上。
总之,硬件的 64 位和 32 位指的是 CPU 的位宽,软件的 64 位和 32 位指的是指令的位宽。
-
-
CPU时钟频率:1GHz表示该CPU的时钟频率是1G,表示1秒会发出1G次数的脉冲信号,每一次脉冲信号的高低电平就是一个时钟周期。时钟周期时间越短,CPU运算的越快。
磁盘比内存慢几万倍?
-
机械硬盘、固态硬盘、内存这三个存储器,到底和
CPU L1 Cache相比速度差多少倍呢?-
CPU L1 Cache 随机访问延时是 1 纳秒,内存则是 100 纳秒,所以 CPU L1 Cache 比内存快 100 倍左右。
-
SSD 随机访问延时是 150 微秒,所以 CPU L1 Cache 比 SSD 快 150000 倍左右。
-
最慢的机械硬盘随机访问延时已经高达 10 毫秒,CPU L1 Cache 比机械硬盘快 10000000 倍左右;
-
-
寄存器
寄存器用来存储计算的数据,是最靠近 CPU 的控制单元和逻辑计算单元的存储器。
寄存器的价格很贵,数量通常在几十到几百之间,每个寄存器可以用来存储一定的字节(byte)的数据。比如:
- 32 位 CPU 中大多数寄存器可以存储 4 个字节;
- 64 位 CPU 中大多数寄存器可以存储 8 个字节。
寄存器的访问速度非常快,一般要求在半个 CPU 时钟周期内完成读写,CPU 时钟周期跟 CPU 主频息息相关,比如 2 GHz 主频的 CPU,那么它的时钟周期就是 1/2G,也就是 0.5ns(纳秒)。
-
CPU Cache
CPU Cache 用的是一种叫 SRAM(Static Random-Access Memory,静态随机存储器) 的芯片。静态,说明有电时数据一直存在,但掉电数据丢失。
在 SRAM 里面,一个 bit 的数据,通常需要 6 个晶体管,所以 SRAM 的存储密度不高,同样的物理空间下,能存储的数据是有限的,不过也因为 SRAM 的电路简单,所以访问速度非常快。
CPU 的高速缓存,通常可以分为 L1、L2、L3 三层高速缓存,也称为一级缓存、二级缓存、三级缓存。
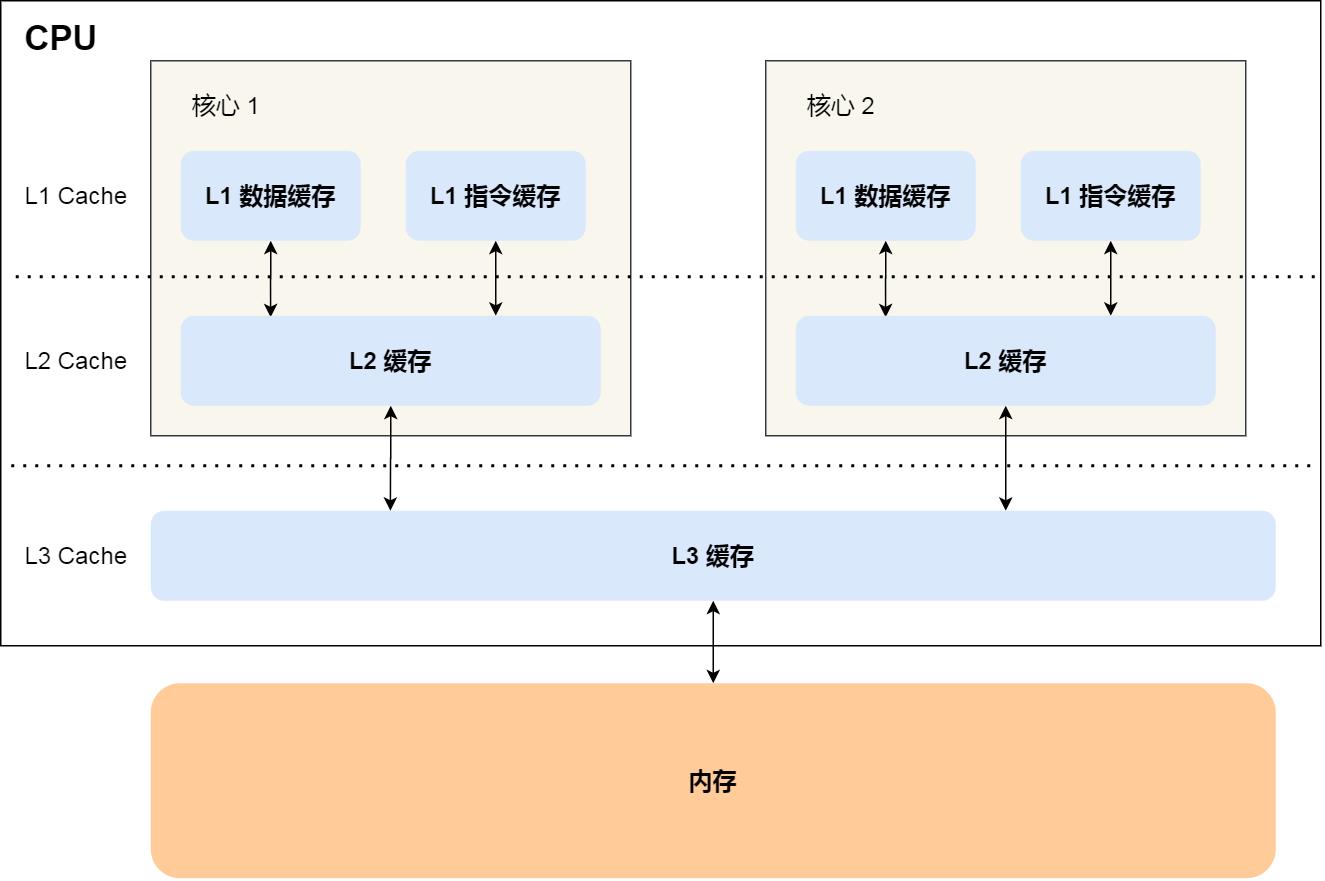
-
L1 高速缓存是每个CPU Core独有的,访问速度快,只需要 2~4 个时钟周期。大小在几十 KB 到几百 KB 不等。
L1 高速缓存的指令和数据是分开存放的,所以 L1 高速缓存通常分成指令缓存和数据缓存。
-
L2 高速缓存同样每个 CPU 核心都有,但是 L2 比L1 距离 CPU 核心更远,访问速度则更慢,速度在 10~20 个时钟周期。但大小比 L1 更大,通常大小在几百 KB 到几 MB不等,
-
L3 高速缓存通常是多个 CPU 核心共用的,位置比 L2 高速缓存距离 CPU 核心 更远,访问速度相对也比较慢一些,访问速度在 20~60 个时钟周期。大小也会更大些,通常大小在几 MB 到几十 MB 不等。
-
-
内存
内存用的芯片和 CPU Cache 有所不同,它使用的是一种叫作 DRAM (Dynamic Random Access Memory,动态随机存取存储器) 的芯片。动态,因为数据会被存储在电容里,电容会不断漏电,所以需要定时刷新电容,才能保证数据不会被丢失。
相比 SRAM,DRAM 的密度更高,功耗更低,有更大的容量,而且造价比 SRAM 芯片便宜很多。存储一个 bit 数据,只需要一个晶体管和一个电容就能存储。
DRAM 的数据访问电路和刷新电路都比 SRAM 更复杂,所以访问的速度会更慢,内存速度大概在 200~300 个 时钟周期之间。
-
SSD/HDD硬盘
固态硬盘(Solid-state disk,SSD) 结构和内存类似。相比寄存器/Cache/内存的优点是断电后数据还存在;缺点是读写速度很慢。
机械硬盘(Hard Disk Drive, HDD),通过物理读写的方式来访问数据的,因此它访问速度是非常慢的,它的速度比内存慢 10W 倍左右。由于 SSD 的价格快接近机械硬盘了,因此机械硬盘已经逐渐被 SSD 替代了。
-
存储器的层次关系

CPU 并不会直接和每一种存储器设备直接打交道,而是每一种存储器设备只和它相邻的存储器设备打交道。比如,CPU Cache 的数据是从内存加载过来的,写回数据的时候也只写回到内存,再从内存写回到硬盘中。
- 另外,当 CPU 需要访问内存中某个数据的时候,如果寄存器有这个数据,CPU 就直接从寄存器取数据即可,如果寄存器没有这个数据,CPU 就会查询 L1 高速缓存,如果 L1 没有,则查询 L2 高速缓存,L2 还是没有的话就查询 L3 高速缓存,L3 依然没有的话,才去内存中取数据,并把内存中的数据读入到 Cache 中,CPU 再从 CPU Cache 读取数据。
不同的存储器之间性能差距很大,构造存储器分级很有意义,分级的目的是要构造缓存体系。这样的访问机制,跟我们使用「内存作为硬盘的缓存」的逻辑是一样的。
如何写出让CPU跑的更快的代码?
-
CPU Cache有多快?
根据摩尔定律,CPU 的访问速度每 18 个月就会翻倍,相当于每年增长 60% 左右,内存的速度当然也会不断增长,但是增长的速度远小于 CPU,平均每年只增长 7% 左右。于是,CPU 与内存的访问性能的差距不断拉大。到现在,一次内存访问所需时间是 200~300 多个时钟周期,这意味着 CPU 和内存的访问速度已经相差 200~300 多倍了。
为了弥补 CPU 与内存两者之间的性能差异,就在 CPU 内部引入了 CPU Cache,也称高速缓存。
-
CPU Cache 数据结构?
CPU Cache 是由很多个 Cache Line 组成的,Cache Line (缓存块)是 CPU 从内存读取数据的基本单位。
Cache Line 结构
- 有效位(Valid bit):标记对应Cache Line 中数据是否有效的有效位。
- 组标记(Tag):为了区分不同的内存块,在对应的CPU Cache LIne中会存储一个组标记,用来记录当前CPU Cache Line 中存储的数据对应的内存块,区分不同的内存块。
- 数据(Data):从内存加载过来的数据。
-
内存地址与Cache Line的直接映射
CPU 访问内存数据时,是一小块一小块数据读取的,具体这一小块数据的大小,取决于 coherency_line_size 的值,一般 64 字节。在内存中,这一块的数据我们称为内存块(Block),读取的时候我们要拿到数据所在内存块的地址。
一个内存的访问地址,包括组标记、CPU Cache Line 索引、偏移量这三种信息,于是 CPU 就能通过这些信息,在 CPU Cache 中找到缓存的数据。
- 对于直接映射 Cache 采用的策略,就是把内存块的地址始终映射在一个 CPU Cache Line 的地址,至于映射关系实现方式,则是使用取模运算,取模运算的结果就是内存块地址对应的 CPU Cache Line(缓存块) 的地址。
- 使用偏移量,可以在CPU Cache Line 中的数据块找到对应的字。
-
CPU Cache 读写过程?

-
根据内存地址中索引信息,计算在 CPU Cache 中的索引,也就是找出对应的 CPU Cache Line 的地址;
-
找到对应 CPU Cache Line 后,判断 CPU Cache Line 中的有效位,确认 CPU Cache Line 中数据是否是有效的,如果是无效的,CPU 就会直接访问内存,并重新加载数据,如果数据有效,则往下执行;
-
对比内存地址中组标记和 CPU Cache Line 中的组标记,确认 CPU Cache Line 中的数据是我们要访问的内存数据,如果不是的话,CPU 就会直接访问内存,并重新加载数据,如果是的话,则往下执行;
-
根据内存地址中偏移量信息,从 CPU Cache Line 的数据块中,读取对应的字。
- CPU 在从 CPU Cache 读取数据的时候,并不是读取 CPU Cache Line 中的整个数据块,而是读取 CPU 所需要的一个数据片段,这样的数据统称为一个字(Word)。
-
-
写出让CPU跑得更快的程序
CPU操作L1 Cache的速度是很快的,提升CPU运行速度,可以提升访问L1 Cache的速度。
那么L1 Cache 通常分为「数据缓存」和「指令缓存」,因此要分别提高「数据缓存」和「指令缓存」的缓存命中率。
-
提升数据缓存的命中率
CPU会一次从内存中加载多少元素到 CPU Cache ,可以在Linux 里通过 coherency_line_size 配置查看 它的大小,通常是 64 个字节。
如果遇到遍历数组之类的情况时,按照内存布局顺序访问,将可以有效的利用 CPU Cache 带来的好处,这样我们代码的性能就会得到很大的提升。
-
提升指令缓存的命中率
使用显式分支预测工具,如果分支预测可以预测到接下来要执行 if 里的指令,还是 else 指令的话,就可以「提前」把这些指令放在指令缓存中,这样 CPU 可以直接从 Cache 读取到指令,于是执行速度就会很快。
- 比如:如果你肯定代码中的 if 中的表达式判断为 true 的概率比较高,我们可以使用显示分支预测工具,比如在 C/C++ 语言中,如果 if 条件为 ture 的概率大,则可以用 likely 宏把 if 里的表达式包裹起来。
还可以提升多核CPU的缓存命中率
-
L2 Cache和L1 Cache 是每个核心独有的,如果一个线程在不同核心来回切换,各个核心的缓存命中率就会受到影响,可以把线程绑定到某一个CPU核心上。
在 Linux 上提供了 sched_setaffinity 方法,来实现将线程绑定到某个 CPU 核心这一功能。
-
整理自:小林coding
面试官:关于Glide常问的几个问题你掌握多少?答对了直接绿卡!

面试官1:Glide的三级缓存有了解过么?
- 先来了解一下我们常说的图片三级缓存:
一般是强引用,软引用和文件系统,Android系统中提供了LruCache,通过维护一个LinkedHashMap来保存我们需要的各种类型数据,例如我们这里需要的Bitmap。LruCache一般我们会设置为系统最大存储空间的八分之一,而它的机制就是我们常说的最近最少使用原则,如果Lru中的图片大小超过了默认大小,则会把最久使用的图片移除。
当图片被Lru移除时,我们需要手动将图片添加到软引用(SoftRefrence)中。需要维护一个软应用的集合在我们的项目中。
- 简单概括一下常用的三级缓存的流程:
先去Lru中找,有则直接取。
没有,则去SoftRefrence中找,有则取,同时将图片放回Lru中。
没有的话去文件系统找,有则取,同时将图片添加到Lru中。
没有就走下载图片逻辑,保存到文件系统中,并放到Lru中。
下面介绍一下Glide的缓存结构:
Glide缓存严格意义上说只有内存缓存和磁盘缓存,内存缓存中又分为Lru和弱引用缓存。
所以Glide的三级缓存可以分为:Lru缓存,弱引用缓存,磁盘缓存。
下面我们看一下Glide的读取顺序,这里有一点不同,我用的是Glide4.8版本,跟之前版本的写入顺序稍有不同。
截取部分源码:
@NonNull
Glide build(@NonNull Context context) {
if (memoryCache == null) {
memoryCache = new LruResourceCache(memorySizeCalculator.getMemoryCacheSize());
}
if (engine == null) {
engine =
new Engine(
memoryCache,
diskCacheFactory,
diskCacheExecutor,
sourceExecutor,
GlideExecutor.newUnlimitedSourceExecutor(),
GlideExecutor.newAnimationExecutor(),
isActiveResourceRetentionAllowed);
}
- memoryCache就是Glide使用的内存缓存,LruResourceCache类继承了LruCache,这部分可以自行查看一下源码。
通过上面可以看到,GLide#build()方法中实例化memoryCache作为Glide的内存缓存,并将其传给Engine作为构造器的入参。
- Engine.class 截取部分源码
{
//生成缓存key
EngineKey key = keyFactory.buildKey(model, signature, width, height, transformations,
resourceClass, transcodeClass, options);
//从弱应用中读取缓存
EngineResource<?> active = loadFromActiveResources(key, isMemoryCacheable);
if (active != null) {
cb.onResourceReady(active, DataSource.MEMORY_CACHE);
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Loaded resource from active resources", startTime, key);
}
return null;
}
//从LruCache中读取缓存
EngineResource<?> cached = loadFromCache(key, isMemoryCacheable);
if (cached != null) {
cb.onResourceReady(cached, DataSource.MEMORY_CACHE);
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Loaded resource from cache", startTime, key);
}
return null;
}
EngineJob<R> engineJob =
engineJobFactory.build(
key,
isMemoryCacheable,
useUnlimitedSourceExecutorPool,
useAnimationPool,
onlyRetrieveFromCache);
jobs.put(key, engineJob);
engineJob.addCallback(cb);
//开启线程池,加载图片
engineJob.start(decodeJob);
}
从上可知,Glide加载过程中使用loadFromActiveResources方法和loadFromCache方法来获取内存缓存的。
大致总结一下:
首先从弱引用读取缓存,没有的话通过Lru读取,有则取,并且加到弱引用中,如果没有会开启EngineJob进行后面的图片加载逻辑。
下面直接看之后的缓存部分代码:
- Engine#onEngineJobComplete()
public void onEngineJobComplete(EngineJob<?> engineJob, Key key, EngineResource<?> resource) {
Util.assertMainThread();
// A null resource indicates that the load failed, usually due to an exception.
if (resource != null) {
resource.setResourceListener(key, this);
if (resource.isCacheable()) {
activeResources.activate(key, resource);
}
}
jobs.removeIfCurrent(key, engineJob);
}
void activate(Key key, EngineResource<?> resource) {
ResourceWeakReference toPut =
new ResourceWeakReference(
key,
resource,
getReferenceQueue(),
isActiveResourceRetentionAllowed);
ResourceWeakReference removed = activeEngineResources.put(key, toPut);
if (removed != null) {
removed.reset();
}
}
这里可以看到activeResources.activate(key, resource)把EngineResource放到了弱引用中,至于lru的放置逻辑如下:
- EngineResource#release()
void release() {
if (acquired <= 0) {
throw new IllegalStateException("Cannot release a recycled or not yet acquired resource");
}
if (!Looper.getMainLooper().equals(Looper.myLooper())) {
throw new IllegalThreadStateException("Must call release on the main thread");
}
if (--acquired == 0) {
listener.onResourceReleased(key, this);
}
}
当acquired变量大于0的时候,说明图片正在使用中,也就应该放到activeResources弱引用缓存当中。而经过release()之后,如果acquired变量等于0了,说明图片已经不再被使用了,那么此时会调用listener的onResourceReleased()方法来释放资源。
- Engine#onResourceReleased()
@Override
public void onResourceReleased(Key cacheKey, EngineResource<?> resource) {
Util.assertMainThread();
activeResources.deactivate(cacheKey);
if (resource.isCacheable()) {
cache.put(cacheKey, resource);
} else {
resourceRecycler.recycle(resource);
}
}
这里首先会将缓存图片从activeResources中移除,然后再将它put到LruResourceCache当中。这样也就实现了正在使用中的图片使用弱引用来进行缓存,不在使用中的图片使用LruCache来进行缓存的功能。
接下来就是Glide的磁盘缓存,磁盘缓存简单来说就是根据Key去DiskCache中取缓存,有兴趣可以自行看一下源码。
面试官2:为什么选择Glide不选择其他的图片加载框架?
- Glide和Picasso
前者要更加省内存,可以按需加载图片,默认为ARGB_565,后者为ARGB_8888。
前者支持Gif,后者并不支持。
- Glide和Fresco
Fresco低版本有优势,占用部分native内存,但是高版本一样是java内存。
Fresco加载对图片大小有限制,Glide基本没有。
Fresco推荐使用SimpleDraweeView,涉及到布局文件,这就不得不考虑迁移的成本。
Fresco有很多native的实现,想改源码成本要大的多。
Glide提供对中TransFormation帮助处理图片,Fresco并没有。
Glide版本迭代相对较快。
Glide的几个显著的优点:
- 生命周期的管理
GLide#with
@NonNull
public static RequestManager with(@NonNull Context context) {
return getRetriever(context).get(context);
}
@NonNull
public static RequestManager with(@NonNull Activity activity) {
return getRetriever(activity).get(activity);
}
@NonNull
public static RequestManager with(@NonNull FragmentActivity activity) {
return getRetriever(activity).get(activity);
}
@NonNull
public static RequestManager with(@NonNull Fragment fragment) {
return getRetriever(fragment.getActivity()).get(fragment);
}
@Deprecated
@NonNull
public static RequestManager with(@NonNull android.app.Fragment fragment) {
return getRetriever(fragment.getActivity()).get(fragment);
}
可以看到有多个重载方法,主要对两类不同的Context进行不同的处理
- Application Context 图片加载的生命周期和应用程序一样,肯定是我们不推荐的写法。
- 其余Context,会像当前Activity创建一个隐藏的Fragment,绑定生命周期。
以Activity为例:
@NonNull
public RequestManager get(@NonNull Activity activity) {
if (Util.isOnBackgroundThread()) {
return get(activity.getApplicationContext());
} else {
//判断是否是销毁状态
assertNotDestroyed(activity);
android.app.FragmentManager fm = activity.getFragmentManager();
//绑定生命周期
return fragmentGet(
activity, fm, /*parentHint=*/ null, isActivityVisible(activity));
}
}
具体看#fragmentGet()
@NonNull
private RequestManager fragmentGet(@NonNull Context context,
@NonNull android.app.FragmentManager fm,
@Nullable android.app.Fragment parentHint,
boolean isParentVisible) {
//这就是绑定的Fragment,RequestManagerFragment
RequestManagerFragment current = getRequestManagerFragment(fm, parentHint, isParentVisible);
RequestManager requestManager = current.getRequestManager();
return requestManager;
}
接着看RequestManagerFragment
public class RequestManagerFragment extends Fragment {
@Override
public void onStart() {
super.onStart();
lifecycle.onStart();
}
@Override
public void onStop() {
super.onStop();
lifecycle.onStop();
}
@Override
public void onDestroy() {
super.onDestroy();
lifecycle.onDestroy();
unregisterFragmentWithRoot();
}
}
关联lifeCycle相应的方法。
简单来说就是通过#with()方法根据穿过来的不同的Context绑定生命周期。
- Bitmap对象池
Glide提供了一个BitmapPool来保存Bitmap。
简单来说就是当需要加载一个bitmap的时候,会根据图片的参数去池子里找到一个合适的bitmap,如果没有就重新创建。BitMapPool同样是根据Lru算法来工作的。从而提高性能。
- 高效缓存
缓存相关可以看上文描述,内存和磁盘,磁盘缓存也提供了几种缓存策略。
1.NONE,表示不缓存任何内容
2.SOURCE,表示只缓存原始图片
3.RESULT,表示只缓存转换过后的图片(默认选项)
4.ALL, 表示既缓存原始图片,也缓存转换过后的图片
大厂面试前的复习准备
接下来分享的系统学习资源以详解各大互联网公司的 Android 常见面试题为主线,从面试的角度带你介绍必备知识点,以及该知识点在项目中的实际应用。
帮你在现在的基础上,重新梳理和建立 Android 开发的知识体系。无论是你短期内想提升 Android 内功实力,突破自己工作中的能力瓶颈,还是准备参加 Android 面试,都会在这份资料中有所一些收获。
从架构基础开始,分了8个模块来逐步从基础进阶到架构师的环节:
多余的话就不讲了,接下来将分享面试的一个复习路线,如果你也在准备面试但是不知道怎么高效复习,可以参考一下我的复习路线,有任何问题也欢迎一起互相交流,加油吧!
首先是超级详细得不能再详细的Android开发学习思维导图,因为图片实在是太大了,所以我就只把二级目录的内容放出来,更加详细的你们可以点击这里。

接下来就需要梳理知识,提升储备了!(Android移动架构师七大专题学习资源)
-
架构师筑基必备技能:深入Java泛型+注解深入浅出+并发编程+数据传输与序列化+Java虚拟机原理+反射与类加载+动态代理+高效IO
-
Android高级UI与FrameWork源码:高级UI晋升+Framework内核解析+Android组件内核+数据持久化
-
360°全方面性能调优:设计思想与代码质量优化+程序性能优化+开发效率优化
-
解读开源框架设计思想:热修复设计+插件化框架解读+组件化框架设计+图片加载框架+网络访问框架设计+RXJava响应式编程框架设计+IOC架构设计+Android架构组件Jetpack
-
NDK模块开发:NDK基础知识体系+底层图片处理+音视频开发
-
微信小程序:小程序介绍+UI开发+API操作+微信对接
-
Hybrid 开发与Flutter:Html5项目实战+Flutter进阶
知识梳理完之后,就需要进行查漏补缺,所以针对这些知识点,我手头上也准备了不少的电子书和笔记,这些笔记将各个知识点进行了完美的总结。

然后再是通过源码来系统性地学习
只要是程序员,不管是Java还是Android,如果不去阅读源码,只看API文档,那就只是停留于皮毛,这对我们知识体系的建立和完备以及实战技术的提升都是不利的。
真正最能锻炼能力的便是直接去阅读源码,不仅限于阅读各大系统源码,还包括各种优秀的开源库。

《486页超全面Android开发相关源码精编解析》
刷大厂面试题备战,增加大厂通过率
历时半年,整理了这份市面上最全面的安卓面试题解析大全。
1.可以通过目录索引直接翻看需要的知识点,查漏补缺。
2.五角星数表示面试问到的频率,代表重要推荐指数

《379页Android开发面试宝典》
以上这些内容均免费分享给大家,需要完整版的朋友,点这里可以看到全部内容。或者点击 【这里】 查看获取方式。
最后还有耗时一年多整理的一系列Android学习资源:Android源码解析、Android第三方库源码笔记、Android进阶架构师七大专题学习、历年BAT面试题解析包、Android大佬学习笔记等等,这些内容均免费分享给大家。
以上是关于面试官:关于CPU你了解多少?的主要内容,如果未能解决你的问题,请参考以下文章