机器学习中有关概率论知识的小结
Posted Terry_dong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习中有关概率论知识的小结相关的知识,希望对你有一定的参考价值。
一、引言
最近写了许多关于机器学习的学习笔记,里面经常涉及概率论的知识,这里对所有概率论知识做一个总结和复习,方便自己查阅,与广大博友共享,所谓磨刀不误砍柴工,希望博友们在这篇博文的帮助下,阅读机器学习的相关文献时能够更加得心应手!这里只对本人觉得经常用到的概率论知识点做一次小结,主要是基本概念,因为机器学习中涉及概率论的地方,往往知道基本概念就不难理解,后面会不定期更新,希望博友们多留言补充。
二、古典概率论中的几个重要的公式

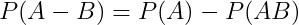
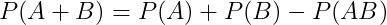
-
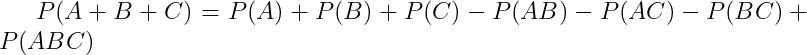
- 对于
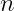 个事件
个事件 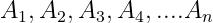 ,两两互斥,则
,两两互斥,则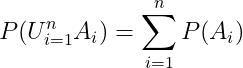
二、贝叶斯(Bayes)公式
通常把事件 A 的概率 P(A)叫做实验前的假设概率,即先验概率(prior probability),如果有另一个事件 B 与事件 A 有某种关系,即事件 A 和 B 不是互相独立的,那么当事件 B 确实发生之后,则应当重新估计事件 A 的概率,即 P(A | B), 这叫做条件概率或者试验后的假设概率,即后验概率(posterior probability).
公式一: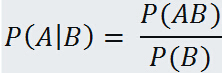
再引入全概率公式:设事件A当前仅当互不相容的事件(即任意两个事件不可能同时发生的)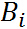 (i = 1, 2 , ... n) 中的任意一个事件发生时才可能发生,已知事件 的概率
(i = 1, 2 , ... n) 中的任意一个事件发生时才可能发生,已知事件 的概率 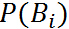 及事件 A 在 已发生的条件下的条件概率,则事件 A 发生的概率为:
及事件 A 在 已发生的条件下的条件概率,则事件 A 发生的概率为:
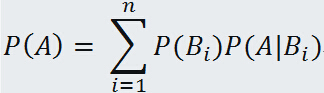
这就是全概率公式.
根据概率乘法定理:
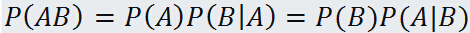
我们可以得到:

于是:
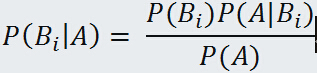
再根据上面介绍的全概率公式,则可得到传说中的贝叶斯公式:
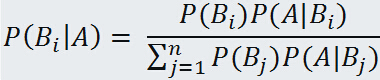
这些公式定理几乎贯穿整个机器学习,很基本,也很重要!
三、常用的离散随见变量分布
- “0-1”分布": 设随机变量 X 只能取得两个数值:0与1,而概率函数是:
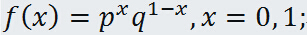 通常把这种分布叫做“0-1”分布或者两点分布,
通常把这种分布叫做“0-1”分布或者两点分布,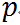 是分布参数.
是分布参数. - 二项分布(binomial distribution): 设随机变量 X 可能的的值是0, 1, 2, ..., n, 而概率函数是:
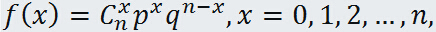
其中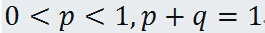 ,这种分布叫做二项分布,含有两个参数
,这种分布叫做二项分布,含有两个参数 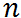 和 ,通常把这种分布记作
和 ,通常把这种分布记作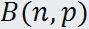 ,如果随见变量 X 服从二项分布,记作
,如果随见变量 X 服从二项分布,记作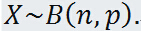
3. 泊松(Possion)分布: 设随机变量 X 的可能值是一切非负整数,而概率函数是:
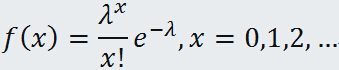
其中λ > 0 为常数,这种分布叫做泊松分布。泊松分布就含有一个参数λ ,记作P(λ), 如果随机变量 X 服从泊松分布,则记作X~P(λ)
四、随机变量的分布函数
设 x 是任何实数,考虑随机变量 X 取得的值不大于 x 的概率,即事件 X ≤ x 的概率,记作 F(x) = P(X ≤ x), 这个函数叫做随机变量 X 的概率分布函数或者分布函数,注意区别于上面讲到的概率函数.
如果已知随机变量 X 的分布函数 F(X), 则随见变量 X 落在半开区间 (x1, x2] 内的概率:P(x1 < X ≤ x2) = F(x2) -F(x1)
五、连续随机变量的概率密度
连续随机变量的概率密度就是分布函数的导函数
六、随机变量的数学期望
如果随机变量 X 只能取得有限个值:

而取得有限个值得概率分别是:
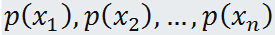
则数学期望:
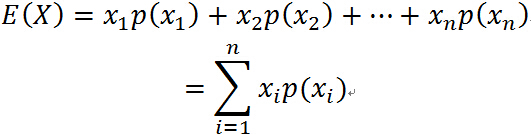
如果连续随机变量 X 的概率密度为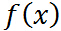 ,则连续随机变量的数学期望:
,则连续随机变量的数学期望:
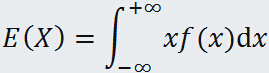
一个常数的的数学期望等于这个常数本身。
定理:两个独立随机变量的乘积的数学期望等于它们数学期望的乘积。证明如下:
对于离散随机变量 X 与 Y 独立:
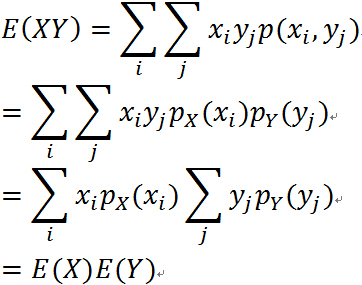
对于连续随机变量 X 与 Y 独立:
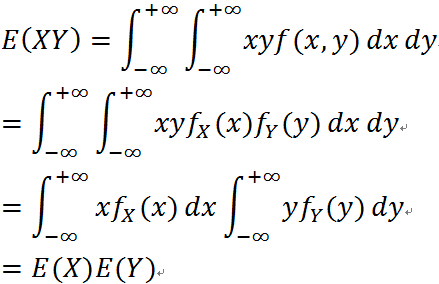
七、方差与标准差
随机变量 X 的方差记作 D(X),定义为:
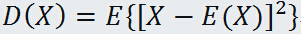
下面证明一个很有用的公式(会用到性质:一个常数的的数学期望等于这个常数本身):
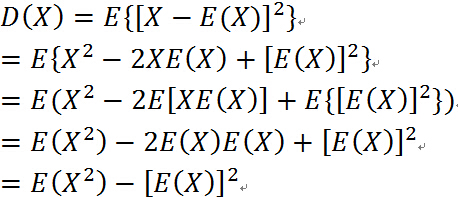
简而言之:随机变量的方差等于变量平方的期望减去期望的平方.
标准差就是方差的算术平方根。
常数的方差为0.
八、协方差与相关系数
随机变量 X 与 随机变量 Y 的协方差记作:
进一步推导可得:
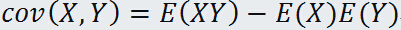
因为两个独立随机变量乘积的期望等于两个随机变量各自期望的乘积,于是当两个随机变量独立使,很容易得到它们的协方差为0.
两个随机变量 X 与 Y 的 相关系数为:
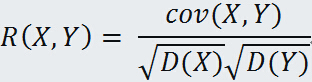
两个随机变量的相关系数的绝对值不大于1.
当且仅当随机变量 Y 与 X 之间存在线性关系:
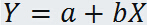
时,相关系数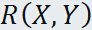 的绝对值等于1,并且
的绝对值等于1,并且
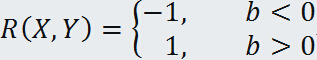
九、正态分布
正态分布又叫高斯分布,设连续随机变量 X 的概率密度
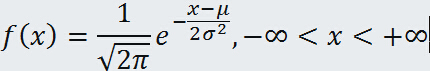
其中 μ 及 σ>0 都是常数,这种分布就是正态分布.
正态分布含有两个参数 μ 及 σ>0,其中μ等于正态分布的数学期望,而 σ 等于正态分布的标准差,通常把这种分布记作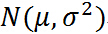 ,随机变量 X 服从正态分布,则记为:
,随机变量 X 服从正态分布,则记为:
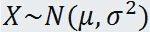
定理 设随机变量 X 服从正态分布,则 X 的线性函数 Y= a + bX(b≠0)也服从正态分布,且有
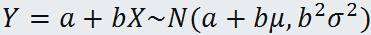
先总结这么多,以后遇到重要的概率论知识点会继续补充!
以上是关于机器学习中有关概率论知识的小结的主要内容,如果未能解决你的问题,请参考以下文章