Monitor 监控架构
Posted cpuCode
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Monitor 监控架构相关的知识,希望对你有一定的参考价值。
Monitor 监控架构
采集器: 负责采集监控数据的,采集到数据之后传输给服务端,通常是直接写入时序库
对时序库的数据 :
- 分析部分: 告警规则判断, 并进行通知
- 可视化: 通过各种图表来合理地渲染各类监控数据
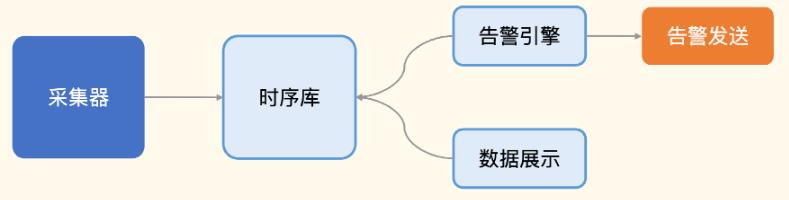
采集器
采集器:负责采集监控数据
采集器的部署方式 :
- 跟随监控对象部署,如: 所有的机器上都部署一个采集器,采集机器的 CPU、内存、硬盘、IO、网络相关的指标
- 远程探针式,如: 选取一个中心机器做探针,同时探测很多机器的 PING 连通性
采集器的数据,推给服务端的两种方法 :
- 直接推给时序库
- 先推给 Kafka,再由 Kafka 写到时序库。更复杂情况,可能会用 Kafka + Flink + 时序库
| 采集器 | 优点 | 缺点 | 推荐场景 |
|---|---|---|---|
| Telegraf | 指标的全家桶 | 不适合 Prometheus 生态 | 配合 InfluxDB 使用 |
| Exporters | 生态庞大 | Exporter 水平参差不齐 | Kubermetes |
| Grafana-Agent | 指标, 日志, 链路统一 | 采集器集成不全 | Kubermetes |
| Categraf | 指标, 日志, 链路统一 | 采集器集成不全 | 物理机, 虚拟机, 容器都适用 |
Telegraf
Telegraf 是 InfluxData 公司的产品
- All-In-One 采集器,支持各种采集插件
- 与 Prometheus、Graphite、Datadog、OpenTSDB、InfluxDB 配合存储
Telegraf 采集数据多为字符串类型,这类数据推给 Prometheus,VictoriaMetrics、M3DB、Thanos (数值型时序数据) 要转为数值型存储
对于标签变化的指标 (标签非稳态结构) ,与 Prometheus 生态的时序库对接时 ,要把这类标签丢弃掉
- 设置 Telegraf :
metric_version = 2 - drop_tag : 删除不要的标签
Exporters
Exporter : 专门对接 Prometheus 生态的组件
- Exporter 组件众多,如: mysqld_exporter,redis_exporter,snmp_exporter,jmx_exporter
由于 Prometheus 影响较大,很多中间件都内置暴露 /metrics 监控数据的接口
- 如: kube-apiserver、kube-proxy、kube-scheduler ,etcd,ZooKeeper、 RabbitMQ、HAProxy
Grafana-Agent
Grafana-Agent 是 Grafana 公司推出的 All-In-One 采集器
- 能采集指标数据,也能采集日志数据 , 链路数据
Grafana-Agent 有个框架,方便导入各类 Exporter,如: Node-Exporter、Kafka-Exporter、Elasticsearch-Exporter、Mysqld-Exporter
- 用 PUSH 方式推送监控数据,完全兼容 Node-Exporter 指标
- 支持用 PULL 方式去抓取其他 Exporter 的数据,再通过 Remote Write 将采集到的数据转发给服务端
- 对日志采集,集成了 Loki 生态的日志采集器 Promtail
- 对链路数据,集成了 OpenTelemetry Collector
Categraf
Categraf 是快猫团队开源的一款监控采集器
- 支持 metrics、logs、traces 的采集
- 只采集数值型时序数据 (标签是稳态结构) ,通过 Remote Write 方式推送数据给后端存储(Prometheus、VictoriaMetrics、M3DB、Thanos)
- 支持读取
prometheus.yml的 scrape 配置,对接各类服务发现机制
时序库
| 时序库 | 优点 | 缺点 |
|---|---|---|
| OpenTSDB | 指标设计较灵活 | 基于 Hbase, Cassandra 架构较复杂 |
| influxDB | 与 Grafana , Telegraf 整合良好 | 只开源单机版本 |
| TDEngine | 集群爸爸开源 , 针对设备场景优化设计 | 不支持 Prometheus Querier 接口 |
| M3DB | 抗住大容量 , 扩展方便 | 对 CPU,内存要求较高 , 架构复杂 |
| VictoriaMetrics | 集群版 , 架构简单 , 支持 Prometheus Querier 接口 | |
| TimescaleDB | 基于 PostgreSQL 开发 | 国内应用较少 |
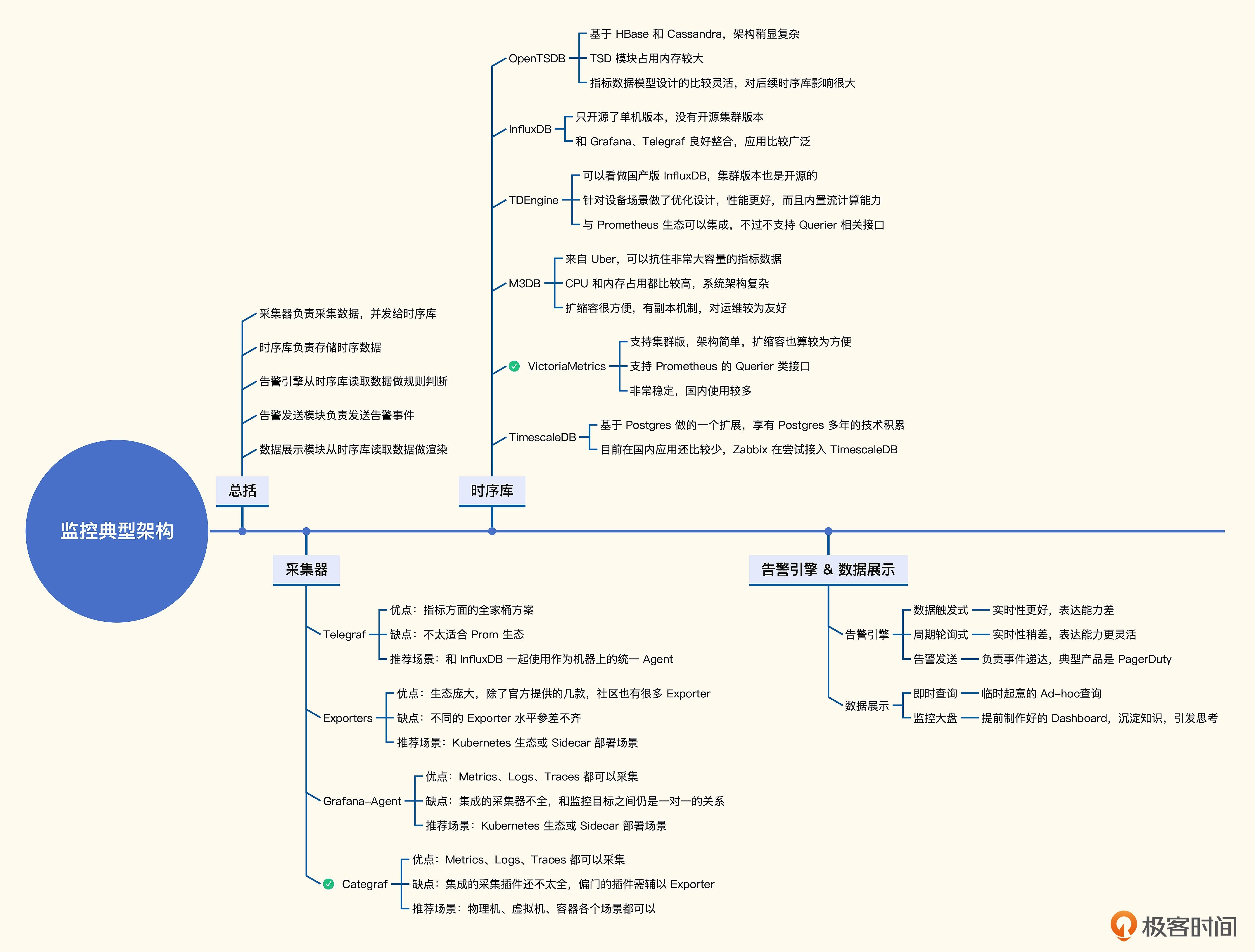
OpenTSDB
OpenTSDB 出现较早,2010 年左右就有了
- OpenTSDB 是基于 HBase 封装或 基于 Cassandra 封装
架构图 :

InfluxDB
InfluxDB 来自 InfluxData
- 针对时序存储场景专门设计了存储引擎、数据结构、存取接口,国内使用范围较广泛
- InfluxDB 配合 Grafana、Telegraf 使用,生态非常完备
- InfluxDB 开源版本是单机
TDEngine
TDEngine 是国产版 InfluxDB,针对物联网设备的场景做了优化,性能很好,能配合 Grafana、Telegraf 使用
- 集群版是开源
- 内置支持了流式计算
- 支持 Prometheus 的 remote_read 和 remote_write 接口
M3DB
M3DB 是 Uber 的时序数据库
- 声称能抗住 66 亿监控指标,
- M3DB 是全开源,但架构原理较复杂
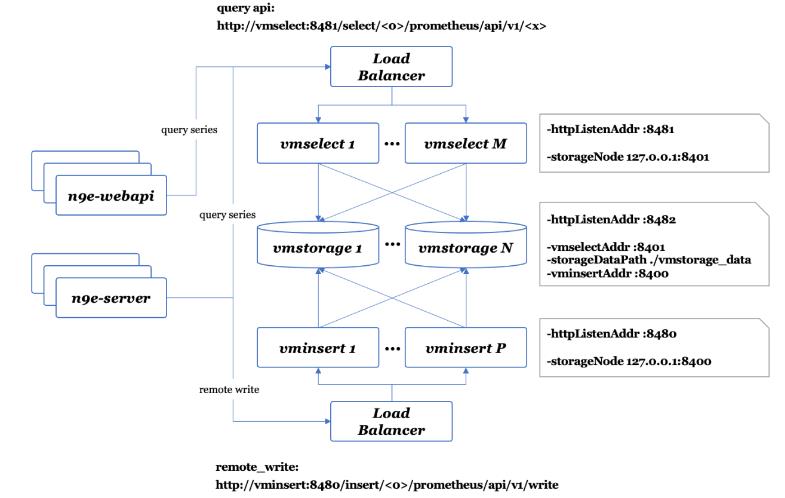
VictoriaMetrics
VM (VictoriaMetrics) : 架构非常简单清晰,采用 merge read 方式,避免数据迁移
- 用一批云上虚拟机,挂上云硬盘,部署 VM 集群,用单副本,是非常轻量可靠的集群方式
- 实现了 Prometheus 的 Query 类接口,如:
/api/v1/query、/api/v1/query_range、/api/v1/label/<label-key>/values - 能当 Prometheus 的 Backend,或 Prometheus 的替代品
VM 架构图 :
TimescaleDB
TimescaleDB : timescale.inc 开发的一款时序数据库,基于 PostgreSQL 设计
- 当数据量到百亿或千亿行时,数据库性能会下降
告警引擎
告警引擎 : 处理告警规则,生成告警事件
告警引擎的两种架构 :
- 数据触发式 : 服务端接收到监控数据后,还会发给告警引擎,告警引擎判断是否告警
- 周期轮询式 : 架构简单,指标关联计算较容易实现。产品如: Prometheus、Nightingale、Grafana
生成事件后,给告警发送的模块
- 该模块负责事件聚合、收敛,并通知不同的接收者
- 告警发送的产品: PagerDuty,能接收各类事件源的事件,只用配置 OnCall 响应
数据展示
监控数据的可视化用 Grafana
- 采用插件式架构,支持不同类型的数据源,图表非常丰富
- 很多公司的商业化产品中,甚至直接内嵌了 Grafana
- 新版本已修改了开源协议 (AGPLv3) ,基于 Grafana 二次开发,要公开代码
监控数据可视化的两类需求 :
- 即时查询 : 临时起意,要追查监控数据
- 监控大盘(Dashboard) : 日常巡检和问题排查,放重点关注的指标
VMCloud云平台进阶篇Monitor监控
终于到了这一篇,从数据层到应用层都是完全基于QCloud平台优化,完全将微软系应用架构搬到了国内云平台上,也算是国内第一例了。
牛皮吹完,说说正事儿,QCloud的监控虽然看起来非常“丰富”:

而且似乎没有统一的监控界面:

但实际上能够支持Windows企业级应用(前几篇构建的应用架构已经属于典型的传统应用,重数据层、重应用层),比如iis上的.net缓冲池、错误连接等,所以能够深入以业务级别来监控还需要专业的监控,而目前来说Windows方面最最专业的肯定不是Zabbix(至少开发成本来说),而是SCOM(System Center Operations Manager,同时也是我本人MVP研究的方向统称CDM方向),由于本篇不是基础篇,搭建过程及基本设置请参考《VMCloud基础篇》:http://vmcloud.info/?cat=131(红色为已完成搭建,蓝色是本次文章涉及的区域):

1、 根据基础篇准备好各项环境,第一个需要优化的就是系统相关监控项目,管理包的导入分为两种一个是主包,一个是语言包,语言包通常是后缀带_chs之类的,如下图(需要先导入主包才可以导入语言包):

2、 如何判断导入并应用是否成功?这里可以看两个地方:
a) 2110日志:

b) 看面板,将操作系统列调出,可以看到从原来未监控变成“正常”状态:

3、 我们确认下相关的规则是否被正常创建:

4、 现在就可以看到比QCloud平台更多的性能参数了,比如Nonpaged Pool、Pool Paged Bytes这些重要的内存参数:

5、 接着我们在SCOM创建一个自定义面板,来集中展示这些监控数据,就可以观察每台子机的内存使用情况,先新建一个管理包来集中收集变更的数据:


6、 创建一个文件夹来集中安放这些面板,并选择放在新建的MP上:


7、 默认会显示很多非必要的面板,这里做多一层优化,将多余的面板隐藏掉,点击查看——显示隐藏视图:

8、 勾选必要的面板即可:

9、 现在看起来就清爽多了:

10、 选择新建仪表板:

11、 选择网格布局并输入相关名字:

12、 现在可以添加小组件:

13、 这里要特别注意 组 与 计数器是有对应关系的:

(比如在“windows 服务器实例组”里可能不存在任何内存相关的计数器,这里可以通过打开某个计数器规则来检查对应对象)
14、 如果觉得计算机目标这块比较别扭,可以尝试更改下监控的对象:

更改成“性能视图”,这样可读性就高多了:

15、 以下为成品仪表板(左上为可用内存 性能视图、右边是SLA视图、左下是内存警告),当服务器发生异常时可以结合警告查看问题原因:

PS1:SCOM2016+SQL2016有个小坑,默认SCOM管理员账户若是SQL DB管理员,则默认权限的MSDB会丢失(https://blogs.technet.microsoft.com/kevinholman/2016/10/22/enabling-scheduled-maintenance-in-scom-2016-ur1/):

若不进行补全则会出现“The data access service account might not have the required permissions”错误
PS2:SCOM 2016安装MOM Agent还有一个坑,默认的本地账户没有授权,需要手动授权,会出现以下提示:

所以需要在DC上手动执行以下命令(https://blogs.technet.microsoft.com/kevinholman/2016/11/04/deploying-scom-2016-agents-to-domain-controllers-some-assembly-required/):
C:\Program Files\Microsoft Monitoring Agent\Agent>HSLockdown.exe QCloud_VMC_MG
/R “NT AUTHORITY\SYSTEM”

以上是关于Monitor 监控架构的主要内容,如果未能解决你的问题,请参考以下文章