2023-Python实现百度翻译接口调用
Posted 抄代码抄错的小牛马
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2023-Python实现百度翻译接口调用相关的知识,希望对你有一定的参考价值。
目录
学习记录:百度翻译
👉1、目标网址
百度翻译:百度翻译-200种语言互译、沟通全世界!

👉2、接口分析调试

查看其参数:

初看感觉:sign 和 token 会变,多测试几次翻译后发现:sign 会变,但是输入相同的字符去请求翻译,携带的 sign 是同一个,对于 token ,它是一直没有变化的。那就先去解决token 试试,老办法,直接搜索它。

点击去找到它了:在首次进入页面的网页中:re 取出即可
https://fanyi.baidu.com/?aldtype=16047token:√
再去找 sign:搜到相关接口,点击进入查看
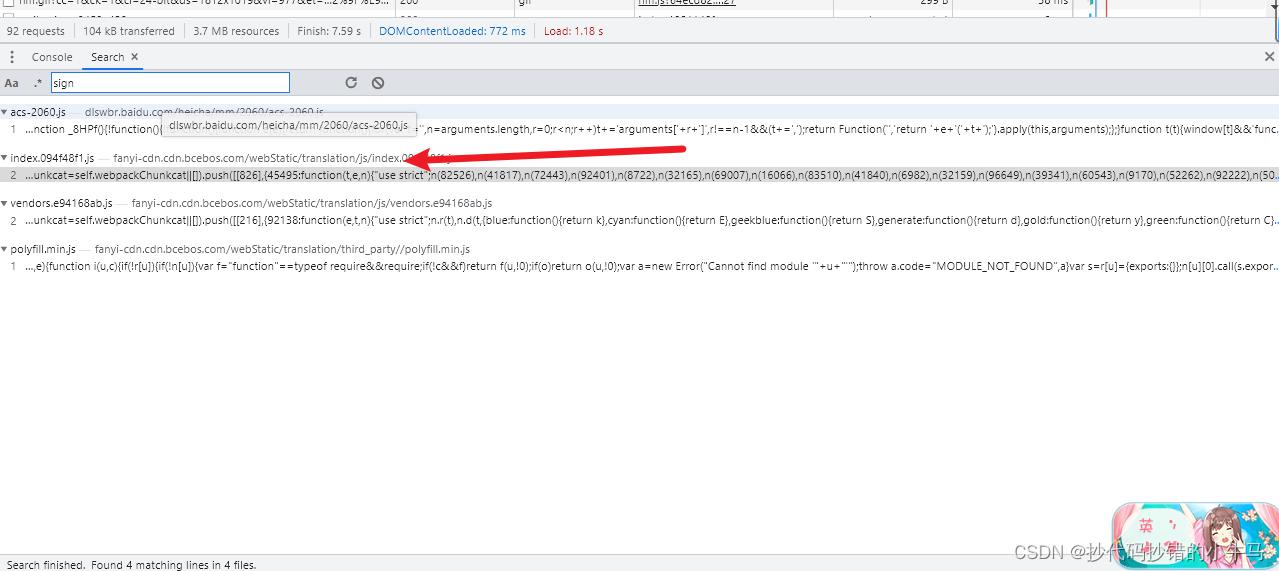
先不管其他的,直接进去ctr + f 搜索 sign

一直enter 我找到了两处可能是sign参数生成的地方:
1、

2、
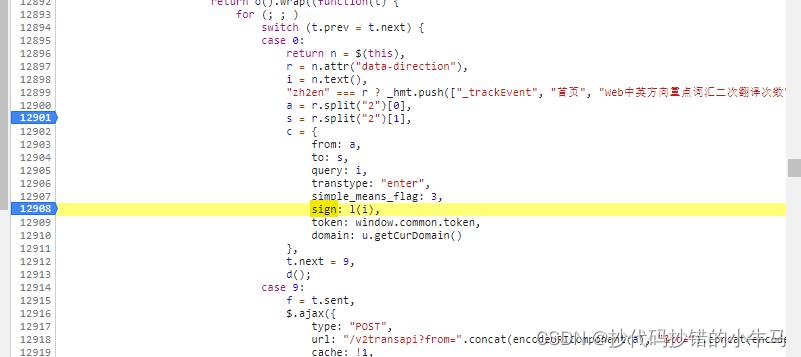
对照前面网页请求的参数,发现他们都很可疑,这样的话,打上断点进行调试:
发现1图出才是我们想要的JS:

如下:

sign:√
主要的sign 定位到了,其他参数再慢慢测试即可:
👉3、python 代码实现
这里直接扣下JS,python调用实现加密,首先要有 node 环境,安装node.js 插件,pycharm专业版。我之前pycharm是社区版的。重新去安装一个专业版即可。
pycharm 破解版:
https://pan.baidu.com/s/1CVmOhZUXkZuLigjp8N87XA
提取码: hrrj
JS:
// 安装 node.js 插件 即可 右键运行
function n(t, e)
for (var n = 0; n < e.length - 2; n += 3)
var r = e.charAt(n + 2);
r = "a" <= r ? r.charCodeAt(0) - 87 : Number(r),
r = "+" === e.charAt(n + 1) ? t >>> r : t << r,
t = "+" === e.charAt(n) ? t + r & 4294967295 : t ^ r
return t
// var window = '320305.131321201';
var r = null;
function a(t,gtk) // 翻译对象
var window = gtk;
var o, i = t.match(/[\\uD800-\\uDBFF][\\uDC00-\\uDFFF]/g);
if (null === i)
var a = t.length;
a > 30 && (t = "".concat(t.substr(0, 10)).concat(t.substr(Math.floor(a / 2) - 5, 10)).concat(t.substr(-10, 10)))
else
for (var s = t.split(/[\\uD800-\\uDBFF][\\uDC00-\\uDFFF]/), c = 0, l = s.length, u = []; c < l; c++)
"" !== s[c] && u.push.apply(u, function (t)
if (Array.isArray(t))
return e(t)
(o = s[c].split("")) || function (t)
if ("undefined" != typeof Symbol && null != t[Symbol.iterator] || null != t["@@iterator"])
return Array.from(t)
(o) || function (t, n)
if (t)
if ("string" == typeof t)
return e(t, n);
var r = Object.prototype.toString.call(t).slice(8, -1);
return "Object" === r && t.constructor && (r = t.constructor.name),
"Map" === r || "Set" === r ? Array.from(t) : "Arguments" === r || /^(?:Ui|I)nt(?:8|16|32)(?:Clamped)?Array$/.test(r) ? e(t, n) : void 0
(o) || function ()
throw new TypeError("Invalid attempt to spread non-iterable instance.\\nIn order to be iterable, non-array objects must have a [Symbol.iterator]() method.")
()),
c !== l - 1 && u.push(i[c]);
var p = u.length;
p > 30 && (t = u.slice(0, 10).join("") + u.slice(Math.floor(p / 2) - 5, Math.floor(p / 2) + 5).join("") + u.slice(-10).join(""))
for (var d = "".concat(String.fromCharCode(103)).concat(String.fromCharCode(116)).concat(String.fromCharCode(107)), h = (null !== r ? r : (r = window || "") || "").split("."), f = Number(h[0]) || 0, m = Number(h[1]) || 0, g = [], y = 0, v = 0; v < t.length; v++)
var _ = t.charCodeAt(v);
_ < 128 ? g[y++] = _ : (_ < 2048 ? g[y++] = _ >> 6 | 192 : (55296 == (64512 & _) && v + 1 < t.length && 56320 == (64512 & t.charCodeAt(v + 1)) ? (_ = 65536 + ((1023 & _) << 10) + (1023 & t.charCodeAt(++v)),
g[y++] = _ >> 18 | 240,
g[y++] = _ >> 12 & 63 | 128) : g[y++] = _ >> 12 | 224,
g[y++] = _ >> 6 & 63 | 128),
g[y++] = 63 & _ | 128)
for (var b = f, w = "".concat(String.fromCharCode(43)).concat(String.fromCharCode(45)).concat(String.fromCharCode(97)) + "".concat(String.fromCharCode(94)).concat(String.fromCharCode(43)).concat(String.fromCharCode(54)), k = "".concat(String.fromCharCode(43)).concat(String.fromCharCode(45)).concat(String.fromCharCode(51)) + "".concat(String.fromCharCode(94)).concat(String.fromCharCode(43)).concat(String.fromCharCode(98)) + "".concat(String.fromCharCode(43)).concat(String.fromCharCode(45)).concat(String.fromCharCode(102)), x = 0; x < g.length; x++)
b = n(b += g[x], w);
return b = n(b, k),
(b ^= m) < 0 && (b = 2147483648 + (2147483647 & b)),
"".concat((b %= 1e6).toString(), ".").concat(b ^ f)
python:
""""
CSDN:抄代码抄错的小牛马
"""
import execjs
import requests
import re
# 获取 sign
def use_JS(gtk):
# 读取js文件
with open('./sign.js', encoding='utf-8') as f:
js = f.read()
# 通过compile命令转成一个js对象
docjs = execjs.compile(js)
t = '我'
# 调用function ==> 调用的方法名, 参数1 参数2
sign = docjs.call('a', t, gtk)
print('sign:', sign)
return sign
# 获取 gtk, token, session 等信息
def get_data():
token_url = 'https://fanyi.baidu.com/?aldtype=16047'
headers =
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'fanyi.baidu.com',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="8"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.2242 SLBChan/25',
session = requests.session()
# 要先请求一次 拿到cookie 保存 cookie
session.get(token_url, headers=headers)
html = session.get(token_url, headers=headers).text
token = re.search(r"token: '(?P<token>.*?)',", html).group('token')
gtk = re.search(r'window.gtk = "(?P<gtk>.*?)";', html).group('gtk')
print('token:', token, 'gtk:', gtk, end='\\n\\n')
return gtk, token, session
# 获取 自动识别 lan_type
def get_lan(session, query):
langdetect = 'https://fanyi.baidu.com/langdetect'
form_data =
'query': query,
lan_resp = session.post(url=langdetect, data=form_data).json()
lan_type = lan_resp['lan']
print('自动识别的语言为:', lan_type)
return lan_type
pass
# 实现 翻译
def get_translation(query, sign, token, session, lan_type):
fanyi_api = 'https://fanyi.baidu.com/v2transapi?from=zh&to=en'
headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.2242 SLBChan/25',
form_data =
'from': lan_type,
'to': 'en',
'query': query,
'simple_means_flag': '3',
'sign': sign,
'token': token,
'domain': 'common',
fanyi_rsp = session.post(url=fanyi_api, headers=headers, data=form_data).json()
end_resp = fanyi_rsp['trans_result']['data'][0]['dst']
print('-------------百度翻译-------------')
print('翻译前:', query)
print('翻译后:', end_resp)
pass
if __name__ == '__main__':
query = '我'
gtk, token, session = get_data()
lan_type = get_lan(session, query)
sign = use_JS(gtk)
get_translation(query, sign, token, session, lan_type)
pass
运行结果:

.net core 和 WPF 开发升讯威在线客服系统:调用百度翻译接口实现实时自动翻译
业余时间用 .net core 写了一个在线客服系统。并在博客园写了一个系列的文章,写介绍这个开发过程。
我把这款业余时间写的小系统丢在网上,陆续有人找我要私有化版本,我都给了,毕竟软件业的初衷就是免费和分享,后来我索性就官方发了一个私有化版直接给别人下载。希望能够打造: 开放、开源、共享。努力打造 .net 社区的一款优秀开源产品。
2021年下半年,陆续有朋友联系我,表示从事外贸行业,希望客服系统能够实现客服与访客之间双向的实时自动翻译。
一开始我想的比较复杂,拖着没做这个功能,后来询问的朋友越来越多,我仔细调研了一下这个需求,发现通过公有云上的接口实现起来,非常的简单!整个对接实现过程不夸张的说,10 分钟就完成了。
本文将详细的介绍百度翻译接口的注册、开通、对接全过程,以及 源代码 ,希望对你有用。
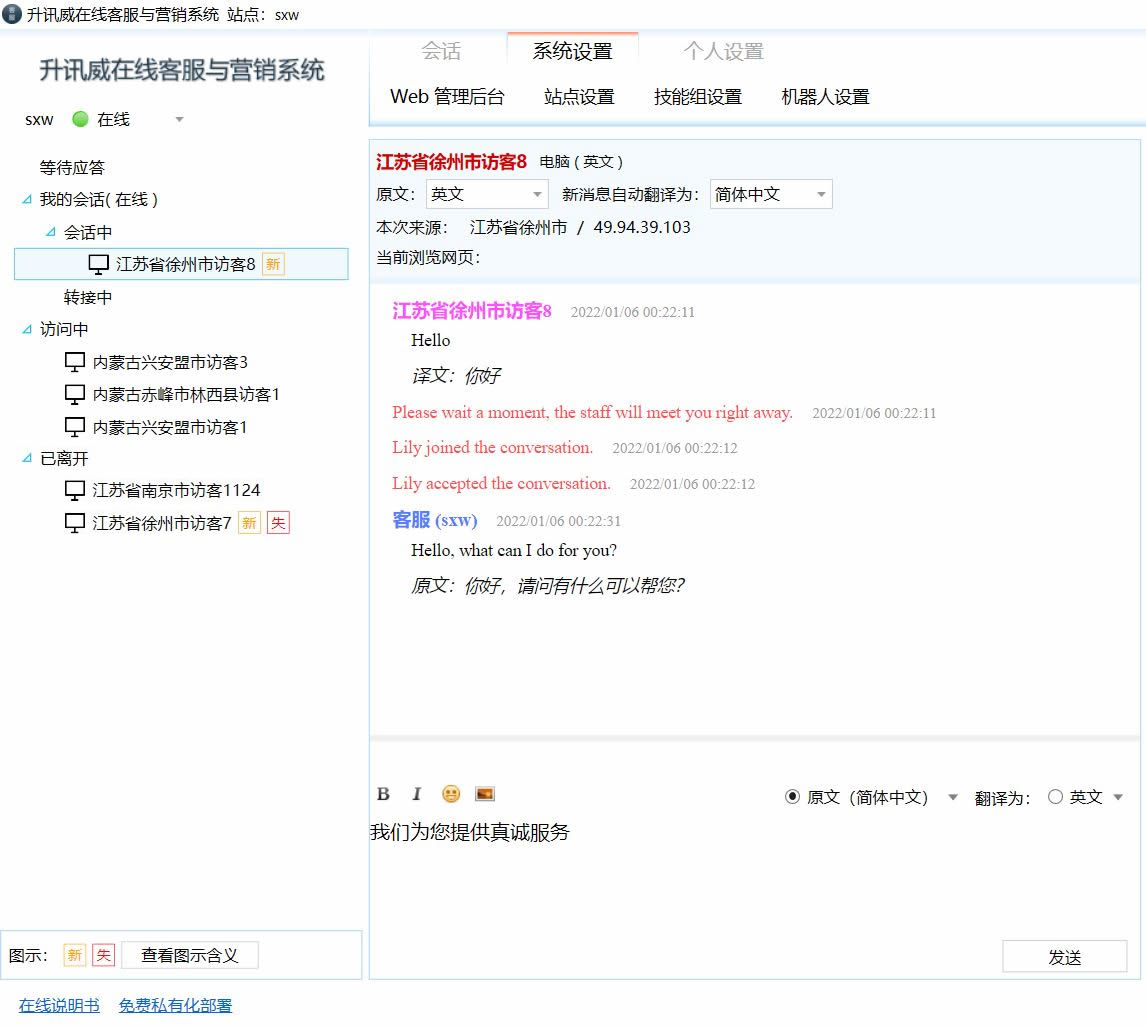
先看实现效果
客服端程序以原文和译文对照的方式显示。
访客端以访客语言显示。
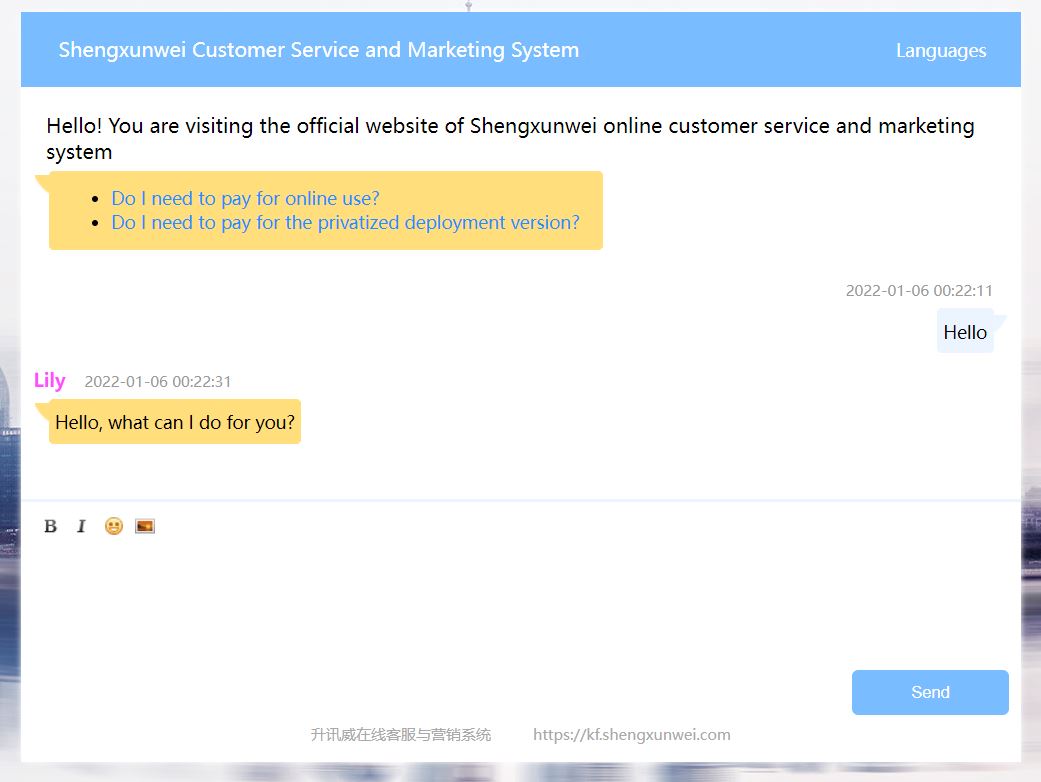
以设置默认翻译所有访客的消息,也可以由客服根据不同访客自行决定是否翻译。
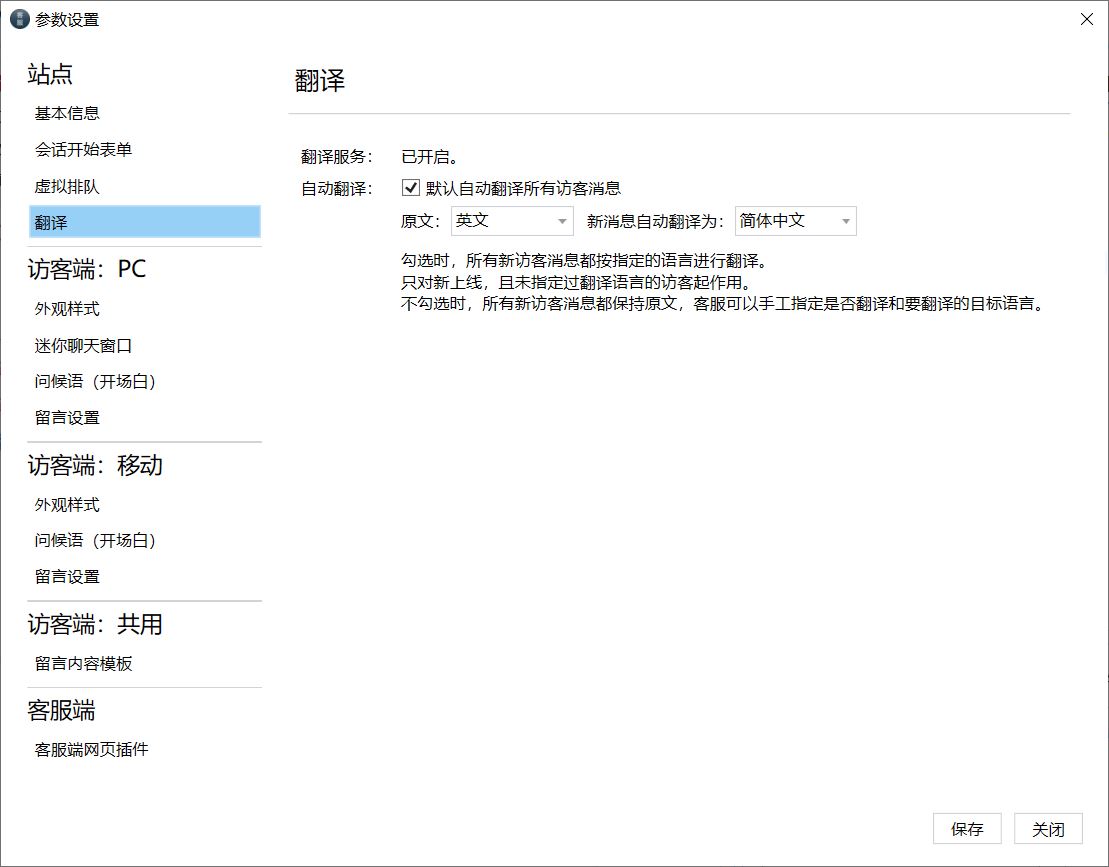
简介
升讯威在线客服与营销系统是基于 .net core / WPF 开发的一款在线客服软件,宗旨是: 开放、开源、共享。努力打造 .net 社区的一款优秀开源产品。
完整私有化包下载地址
以上是关于2023-Python实现百度翻译接口调用的主要内容,如果未能解决你的问题,请参考以下文章