吴恩达机器学习--线性回归
Posted Want595
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了吴恩达机器学习--线性回归相关的知识,希望对你有一定的参考价值。
文章目录
前言
线性回归:是一种通过属性的线性组合来进行预测的线性模型
其目的是找到一条直线或者一个平面或者更高维的超平面,使得预测值与真实值之间的误差最小化。
一、单变量线性回归
1.导入必要的库
导入pandas、numpy和matplotlib.pyplot库
import pandas as pd #导入pandas库
import numpy as np #导入numpy库
import matplotlib.pyplot as plt #导入matplotlib.pyplot库
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
2.读取数据
使用pandas库的read_csv()函数读取数据文件,数据文件中包含了人口和收益两列数据
data=pd.read_csv(r"d:线性回归/regress_data1.csv") #读取数据
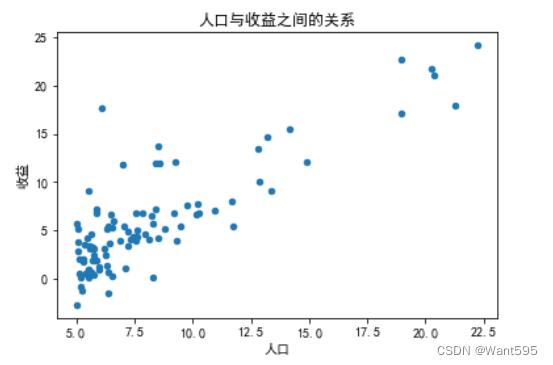
3.绘制散点图
使用data.plot()函数绘制散点图,展示人口与收益之间的关系
data.plot(kind="scatter",x="人口",y="收益") #绘制散点图
plt.xlabel("人口",fontsize=10) #横坐标
plt.ylabel("收益",fontsize=10) #纵坐标
plt.title("人口与收益之间的关系") #标题
plt.show() #画图
4.划分数据
这里是为了方便后面计算,将一列全为1的列插入到数据中
将数据分为训练集和测试集,这里只使用了训练集
data.insert(0,"ones",1) #插入列,便于后面计算
col_num=data.shape[1] #训练特征个数
m=data.shape[0] #训练标签个数
X=data.iloc[:,:col_num-1].values #训练集的特征
y=data.iloc[:,col_num-1].values #训练集的标签
y=y.reshape((m,1))
5.定义模型函数
定义h(X,w)函数用来计算模型预测值,这里采用的是线性模型
def h(X,w):
return X@w
6.定义损失函数
定义cost(X,y,w)函数用来计算模型误差
def cost(X,y,w):
return np.sum(np.power(h(X,w)-y,2))/(2*m)
7.求权重向量w
7.1 梯度下降函数
定义函数gradient_descent(X,y,w,n,a)用来执行梯度下降算法,更新权重向量w,并返回最终的权重向量和误差列表
def gradient_descent(X,y,w,n,a):
t=w
cost_lst=[]
for i in range(n):
error=h(X,w)-y
for j in range(col_num-1):
t[j][0]=w[j][0]-((a/m)*np.sum(error.ravel()*X[:,j].ravel()))
w=t
cost_lst.append(cost(X,y,w))
return w,cost_lst
7.2 最小二乘法
定义函数least_square(X,y)用来执行最小二乘法,直接求出权重向量w,但是当n>10000时由于时间复杂度太大将导致程序运行超时
def least_square(X,y):
w=np.linalg.inv(X.T@X)@X.T@y
return w
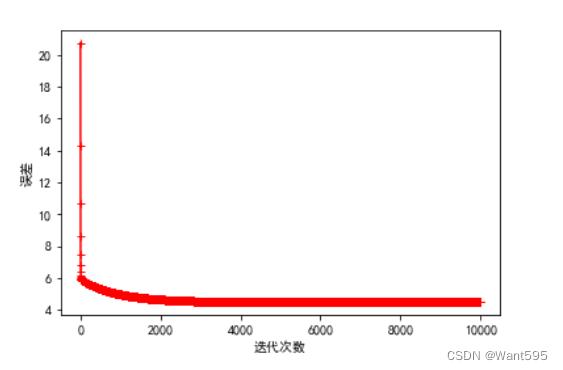
8.训练模型
调用gradient_descent()函数训练模型,并输出误差随迭代次数变化的图像,用来观察模型的学习效果
其中,迭代次数越大,训练效果越好,学习率适中,既不可太大,也不可过小
n=10000 #迭代次数越多越好
a=0.003 #学习率适中,不能太大,也不能太小
w=np.zeros((col_num-1,1)) #初始化权重向量
w,cost_lst=gradient_descent(X,y,w,n,a) #调用梯度下降函数
plt.plot(range(n),cost_lst,"r-+")
plt.xlabel("迭代次数")
plt.ylabel("误差")
plt.show()
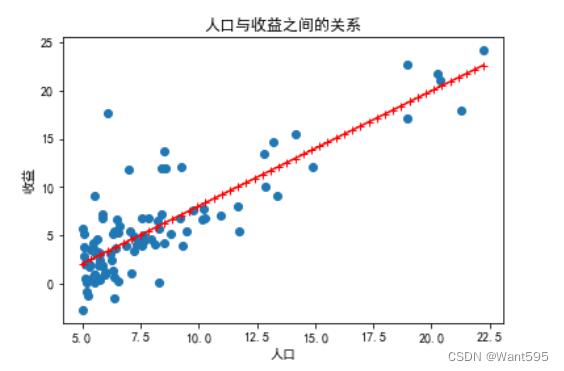
9.绘制预测曲线
使用训练好的权重向量w绘制预测曲线,并将其与原始数据一起绘制在图像上,用来观察模型的预测效果
x=np.linspace(data["人口"].min(),data["人口"].max(),50) #预测特征
y1=w[0,0]*1+w[1,0]*x #预测标签
plt.scatter(data["人口"],data["收益"], label='训练数据') #训练集
plt.plot(x,y1,"r-+",label="预测线") #预测集
plt.xlabel("人口",fontsize=10)
plt.ylabel("收益",fontsize=10)
plt.title("人口与收益之间的关系")
plt.show()
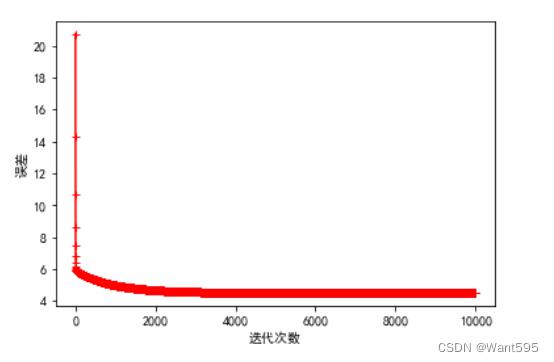
10.试试正则化
使用L2正则化(岭回归)防止过拟合
def gradient_descents(X,y,w,n,a,l):
t=w
cost_lst=[]
for i in range(n):
error=h(X,w)-y
for j in range(col_num-1):
t[j][0]=w[j][0]-((a/m)*(np.sum(error.ravel()*X[:,j].ravel())+2*l*w[j,0]))
w=t
cost_lst.append(cost(X,y,w))
return w,cost_lst
n=10000 #迭代次数越多越好
a=0.003 #学习率适中,不能太大,也不能太小
l=1 #λ
w=np.zeros((col_num-1,1))
w,cost_lst=gradient_descents(X,y,w,n,a,l)
plt.plot(range(n),cost_lst,"r-+")
plt.xlabel("迭代次数")
plt.ylabel("误差")
plt.show()
11.绘制预测曲线
使用训练好的权重向量w绘制预测曲线,并将其与原始数据一起绘制在图像上,用来观察模型的预测效果
x=np.linspace(data["人口"].min(),data["人口"].max(),50)
y1=w[0,0]*1+w[1,0]*x
plt.scatter(data["人口"],data["收益"], label='训练数据')
plt.plot(x,y1,"r-+",label="预测线")
plt.xlabel("人口",fontsize=10)
plt.ylabel("收益",fontsize=10)
plt.title("人口与收益之间的关系")
plt.show()
12.试试sklearn库
import pandas as pd #导入pandas库
import numpy as np #导入numpy库
import matplotlib.pyplot as plt #导入matplotlib.pyplot库
import sklearn #导入sklearn库
from sklearn import linear_model
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
# 2.读取数据:使用pandas库的read_csv()函数读取数据文件。数据文件中包含了人口和收益两列数据。
data=pd.read_csv(r"d:线性回归/regress_data1.csv") #读取数据
data.insert(0,"ones",1) #插入列
col_num=data.shape[1] #列数
m=data.shape[0] #行数
# 5.划分数据:将数据分为训练集和测试集,这里只使用了训练集。
X=data.iloc[:,:col_num-1].values #训练集的特征
y=data.iloc[:,col_num-1].values #训练集的标签
y.reshape((m,1))
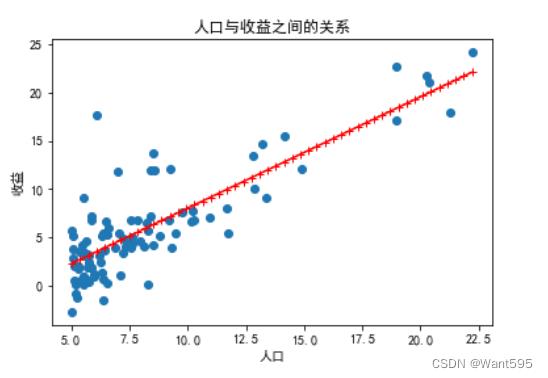
mod=linear_model.LinearRegression()
mod.fit(X,y)
Y=mod.predict(X)
plt.scatter(X[:,1],y,marker='o',color='b')
plt.plot(X,Y,marker='+',color='r')
plt.xlabel("人口")
plt.ylabel("收益")
plt.show()
二、多变量线性回归
1.导入库
import pandas as pd #导入pandas库
import numpy as np #导入numpy库
import matplotlib.pyplot as plt #导入matplotlib.pyplot库
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
2.读取数据
datas=pd.read_csv(r"d:/线性回归/regress_data2.csv") #读取数据
datas=(datas-datas.mean())/datas.std() #正则化
3.划分数据
datas.insert(0,'ones',1) #插入列
col_num=datas.shape[1] #训练特征个数
m=datas.shape[0] #训练标签
X=datas.iloc[:,:col_num-1].values #训练特征
y=datas.iloc[:,col_num-1].values #训练标签
y=y.reshape((m,1))
4.定义假设函数
def h(X,w):
return X@w
5.定义损失函数
def cost(X,y,w):
return np.sum(np.power(h(X,w)-y,2))/(2*m)
6.定义梯度下降函数
def gradient_descent(X,y,w,n,a):
t=w
cost_lst=[]
for i in range(n):
error=h(X,w)-y
for j in range(col_num-1):
t[j,0]=w[j,0]-((a/m)*np.sum(error.ravel()*X[:,j].ravel()))
w=t
cost_lst.append(cost(X,y,w))
return w,cost_lst
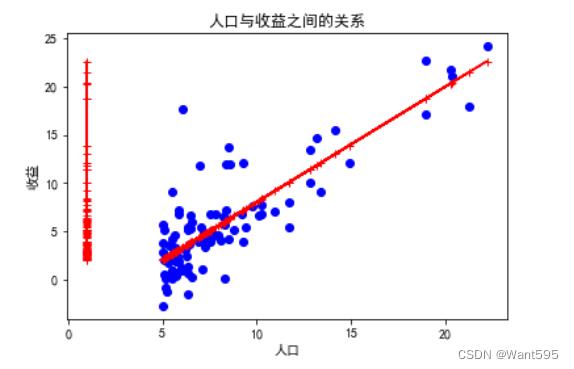
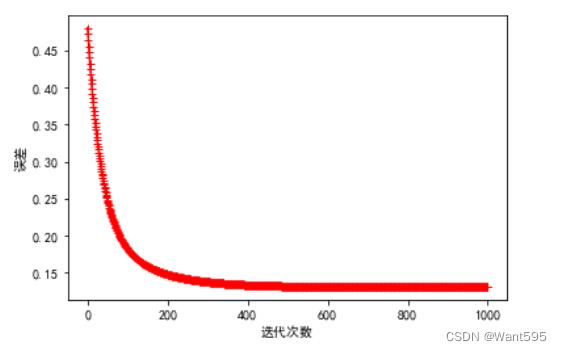
7.训练模型
n=1000 #迭代次数
a=0.01 #学习率
w=np.zeros((col_num-1,1)) #初始化特征向量w
w,cost_lst=gradient_descent(X,y,w,n,a)
plt.plot(range(n),cost_lst,'r+-')
plt.xlabel("迭代次数")
plt.ylabel("误差")
plt.show()
8.运用sklearn绘图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
from sklearn.preprocessing import PolynomialFeatures
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取数据
datas = pd.read_csv(r"d:线性回归/regress_data2.csv")
datas = (datas - datas.mean()) / datas.std()
X = datas.iloc[:, :-1].values
y = datas.iloc[:, -1].values.reshape(-1, 1)
# 多项式回归
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
mod = linear_model.LinearRegression()
mod.fit(X_poly, y)
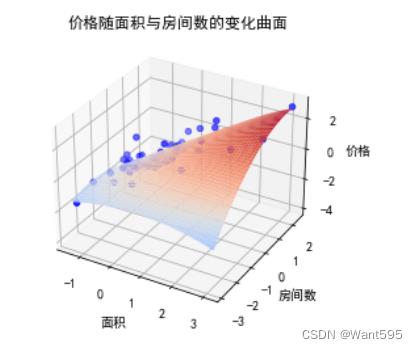
# 绘制拟合曲线
x1 = np.linspace(datas["面积"].min(), datas["面积"].max(), 50)
x2 = np.linspace(datas["房间数"].min(), datas["房间数"].max(), 50)
x1, x2 = np.meshgrid(x1, x2)
X_grid = np.column_stack((x1.flatten(), x2.flatten()))
X_grid_poly = poly.fit_transform(X_grid)
y_pred = mod.predict(X_grid_poly)
fig=plt.figure()
ax = fig.add_subplot(projection='3d')
ax.scatter(X[:,0], X[:,1], y, marker='o', color='b')
ax.plot_surface(x1, x2, y_pred.reshape(x1.shape), cmap='coolwarm')
ax.set_title("价格随面积与房间数的变化曲面")
ax.set_xlabel("面积")
ax.set_ylabel("房间数")
ax.set_zlabel("价格")
plt.show()
总结
线性回归三大要素
- 假设函数 h(X,w)
- 损失函数 cost(X,y,w)
- 梯度下降/最小二乘函数(求解权重向量w的函数)
普通线性回归步骤
- 导入库
- 读取数据
- 划分数据
- 假设函数(模型函数)
- 损失函数
- 梯度下降/最小二乘
- 训练模型
- 绘图预测
调用sklearn库进行线性回归的步骤
- 导入库
- 读取数据
- 调用sklearn库
- 绘图
吴恩达《机器学习》课程总结单变量线性回归
2.1模型表示
(1)监督学习中的回归问题案例房价预测
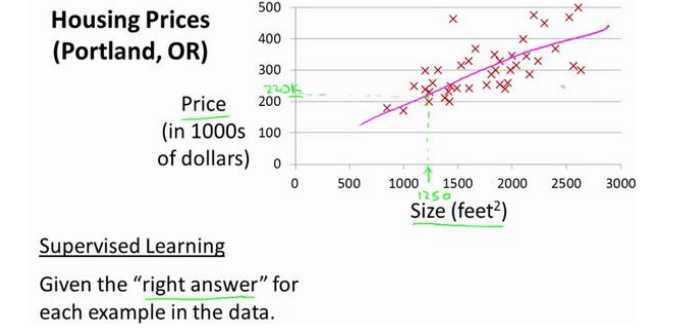
(2)监督算法的工作方式
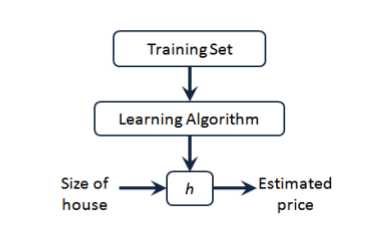
案例中:m表示训练集的数量,x代表特征/输入变量,y代表目标变量/输出变量,(x,y)代表实例,(x(i),y(i))代表第i个观察实例,h代表假设/函数/输入到输出的映射。
(3)房价预测的一种表达方式:h(Θ)=Θ0+Θ1x,只有一个变量,所以成为当变量线性回归问题。
2.2代价函数
(1)对于回归问题常用的代价函数是平方误差代价函数:
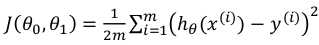
我们的目标选取合适的参数Θ使得误差函数最小,即直线最逼近真实情况。
2.3代价函数的直观理解I
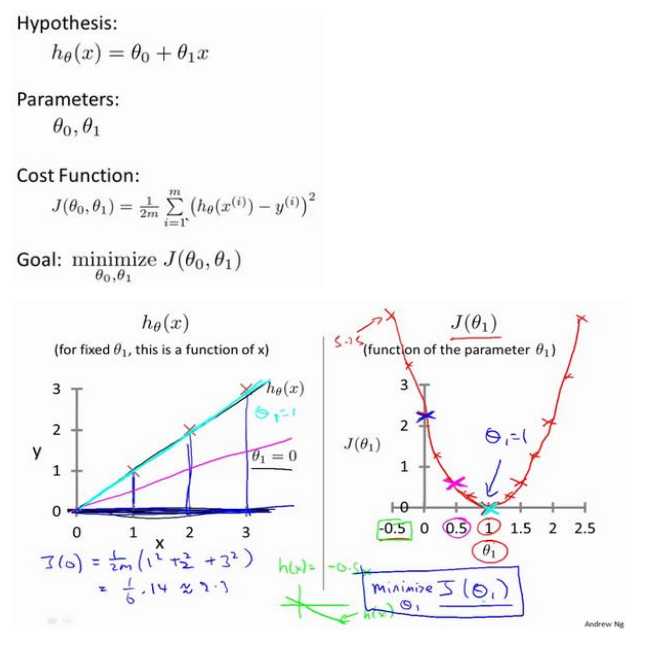
2.4代价函数的直观理解II
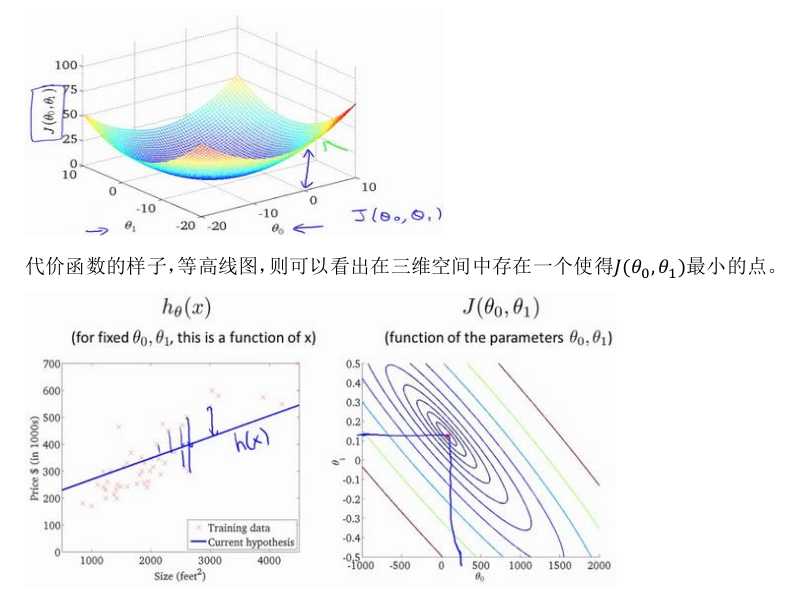
2.5梯度下降

需要注意:参数是要同时更新的;不要算出一个倒数更新一个倒数,再用更新后的式子去计算其他倒数,这样是不对的。
其中α叫学习率,表示沿着下降程度最大的方向迈出的步子大小。
2.6梯度下降的直观理解
(1)梯度下降法可以最小化任何代价函数,而不仅仅局限于线性回归中的代价函数。
(2)当越来越靠近局部最小值时,梯度值会变小,所以即使学习率不变,参数变化的幅度也会随之减小。
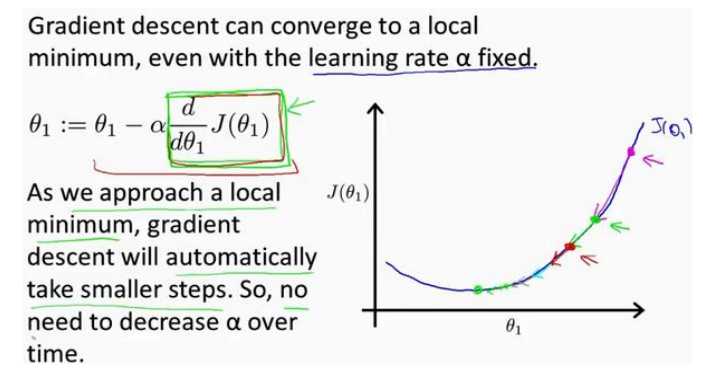
(3)学习率过小时参数变化慢,到达最优点的时间长,学习率大时,可能导致代价函数无法收敛,甚至发散。
(4)梯度就是某一点的斜率。
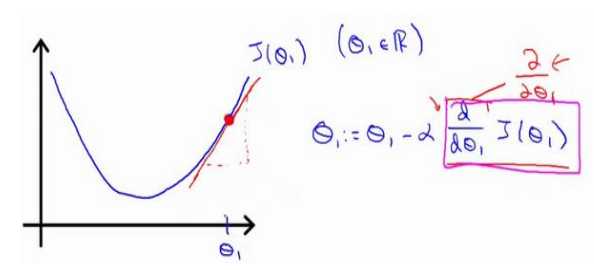
2.7梯度下降的线性回归

以上是关于吴恩达机器学习--线性回归的主要内容,如果未能解决你的问题,请参考以下文章