python编程从入门到实践
Posted xiongsheng666
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python编程从入门到实践相关的知识,希望对你有一定的参考价值。
1、计算机核心基础
1.1 什么是语言?什么是编程语言?为何要有编程语言?
语言其实就是人与人之间沟通的介质,如英语,汉语,俄语等。
编程语言则是人与计算机之间沟通的介质,
编程的目的就是为了让计算机按照人类的思维逻辑(程序)自发地去工作从而把人力解放出来
二 计算机组成原理
2.1、什么是计算机?
俗称电脑,即通电的大脑,电脑二字蕴含了人类对计算机的终极期望,希望它能真的像人脑一样去工作,从而解放人力。
2.2、为什么要用计算机?
世界是由聪明的懒人统治的,任何时期,总有一群聪明的懒人想要奴隶别人。在奴隶制社会,聪明的懒人奴役的是真正的人,而人是无法不吃、不喝、不睡觉一直工作的,但是计算机作为一台机器是可以做到的,所以把计算机当奴隶是上上之选
2.3、计算机的五大组成部分
1.控制器
:控制器是计算机的指挥系统,用来控制计算机其他组件的运行,相当于人类的大脑
2.运算器
:运算器是计算机的运算功能,用来做算术运算和逻辑运算,相当于人脑
ps:控制器+运算器=CPU,cpu相当于人的大脑
3.存储器
:存储器是计算机的记忆功能,用来存取数据。
存储器主要分为内存与外存:
内存相当于人的短期记忆。断电数据丢失
外存(如磁盘),相当于记事的本子,断电数据不会丢失,是用来永久保存数据的
ps:内存的存取速度要远远高于外存
4.输入设备input
:输入设备是计算接收外界输入数据的工具,如键盘、鼠标,相当于人的眼睛或耳朵。
5.输出设备output
:输出设备是计算机向外输出数据的工具,如显示器、打印机,相当于人说的话,写出的文章。
ps:存储器如内存、磁盘等既是输入设备又是输出设备,统称为IO设备
三大核心硬件为CPU、内存、硬盘。
程序最先是存放于硬盘中的,程序的运行是先从硬盘把代码加载到内存中,然后cpu是从内存中读取指令运行。
三 操作系统概述
3.1、操作系统的由来
操作系统的功能就是帮我们把复杂的硬件的控制封装成简单的接口,对于开发应用程序来说只需要调用操作系统提供给我们的接口即可
3.2、系统软件与应用软件
硬件以上运行的都是软件,而软件分为两类:
一、应用软件(例如qq、word、暴风影音,我们学习python就是为了开发应用软件的)
二、操作系统,操作系统应用软件与硬件之间的一个桥梁,是协调、管理、控制计算机硬件与应用软件资源的控制程序。
3.3、计算机系统三层结构
应用程序
操作系统
计算机硬件
硬件 + 操作系统 == 平台
2、编程语言与Python介绍
编程语言分类:
机器语言
机器语言是站在计算机(奴隶)的角度,说计算机能听懂/理解的语言,而计算机能直接理解的就是二进制指令,所以机器语言就是直接用二进制编程,这意味着机器语言是直接操作硬件的,因此机器语言属于低级语言,此处的低级指的是底层、贴近计算机硬件
#机器语言
用二进制代码0和1描述的指令称为机器指令,由于计算机内部是基于二进制指令工作的,所以机器语言是直接控制计算机硬件。
用机器语言编写程序,编程人员要首先熟记所用计算机的全部指令代码以及代码的含义,然后在编写程序时,程序员得自己处理每条指令和每一数据的存储分配和输入输出,还得记住编程过程中每步所使用的工作单元处在何种状态。这是一件十分繁琐的工作。编写程序花费的时间往往是实际运行时间的几十倍或几百倍。而且,编出的程序全是些0和1的指令代码,直观性差,不便阅读和书写,还容易出错,且依赖于具体的计算机硬件型号,局限性很大。除了计算机生产厂家的专业人员外,绝大多数的程序员已经不再去学习机器语言了。
机器语言是被微处理器理解和使用的,存在有多至100000种机器语言的指令,下述是一些简单示例
#指令部份的示例
0000 代表 加载(LOAD)
0001 代表 存储(STORE)
...
#暂存器部份的示例
0000 代表暂存器 A
0001 代表暂存器 B
...
#存储器部份的示例
000000000000 代表地址为 0 的存储器
000000000001 代表地址为 1 的存储器
000000010000 代表地址为 16 的存储器
100000000000 代表地址为 2^11 的存储器
#集成示例
0000,0000,000000010000 代表 LOAD A, 16
0000,0001,000000000001 代表 LOAD B, 1
0001,0001,000000010000 代表 STORE B, 16
0001,0001,000000000001 代表 STORE B, 1[1]
总结机器语言
# 1、执行效率最高
编写的程序可以被计算机无障碍理解、直接运行,执行效率高 。
# 2、开发效率最低
复杂,开发效率低
# 3、跨平台性差
贴近\\依赖具体的硬件,跨平台性差
汇编语言
汇编语言仅仅是用一个英文标签代表一组二进制指令,毫无疑问,比起机器语言,汇编语言是一种进步,但汇编语言的本质仍然是直接操作硬件,因此汇编语言仍是比较低级/底层的语言、贴近计算机硬件
#汇编语言
汇编语言的实质和机器语言是相同的,都是直接对硬件操作,只不过指令采用了英文缩写的标识符,更容易识别和记忆。它同样需要编程者将每一步具体的操作用命令的形式写出来。汇编程序的每一句指令只能对应实际操作过程中的一个很细微的动作。例如移动、自增,因此汇编源程序一般比较冗长、复杂、容易出错,而且使用汇编语言编程需要有更多的计算机专业知识,但汇编语言的优点也是显而易见的,用汇编语言所能完成的操作不是一般高级语言所能够实现的,而且源程序经汇编生成的可执行文件不仅比较小,而且执行速度很快。
汇编的hello world,打印一句hello world, 需要写十多行,如下
; hello.asm
section .data ; 数据段声明
msg db "Hello, world!", 0xA ; 要输出的字符串
len equ $ - msg ; 字串长度
section .text ; 代码段声明
global _start ; 指定入口函数
_start: ; 在屏幕上显示一个字符串
mov edx, len ; 参数三:字符串长度
mov ecx, msg ; 参数二:要显示的字符串
mov ebx, 1 ; 参数一:文件描述符(stdout)
mov eax, 4 ; 系统调用号(sys_write)
int 0x80 ; 调用内核功能
; 退出程序
mov ebx, 0 ; 参数一:退出代码
mov eax, 1 ; 系统调用号(sys_exit)
int 0x80 ; 调用内核功能
总结汇编语言
# 1、执行效率高
相对于机器语言,使用英文标签编写程序相对简单,执行效率高,但较之机器语言稍低,
# 2、开发效率低:
仍然是直接操作硬件,比起机器语言来说,复杂度稍低,但依旧居高不下,所以开发效率依旧较低
# 3、跨平台性差
同样依赖具体的硬件,跨平台性差
高级语言
高级语言是站在人(奴隶主)的角度,说人话,即用人类的字符去编写程序,而人类的字符是在向操作系统发送指令,而非直接操作硬件,所以高级语言是与操作系统打交道的,此处的高级指的是高层、开发者无需考虑硬件细节,因而开发效率可以得到极大的提升,但正因为高级语言离硬件较远,更贴近人类语言,人类可以理解,而计算机则需要通过翻译才能理解,所以执行效率会低于低级语言。
按照翻译的方式的不同,高级语言又分为两种:
编译型(如C语言):
类似谷歌翻译,是把程序所有代码编译成计算机能识别的二进制指令,之后操作系统会拿着编译好的二进制指令直接操作硬件,详细如下
# 1、执行效率高
编译是指在应用源程序执行之前,就将程序源代码“翻译”成目标代码(即机器语言),
因此其目标程序可以脱离其语言环境独立执行,使用比较方便,执行效率较高。
# 2、开发效率低:
应用程序一旦需要修改,必须先修改源代码,然后重新编译、生成新的目标文件才能执行,
而在只有目标文件而没有源代码,修改会很不方便。所以开发效率低于解释型
# 3、跨平台性差
编译型代码是针对某一个平台翻译的,当前平台翻译的结果无法拿到不同的平台使用,针对不同的平台必须重新编译,即跨平台性差
# 其他
现在大多数的编程语言都是编译型的。
编译程序将源程序翻译成目标程序后保存在另一个文件中,该目标程序可脱离编译程序直接在计算机上多次运行。
大多数软件产品都是以目标程序形式发行给用户的,不仅便于直接运行,同时又使他人难于盗用其中的技术。
C、C++、Ada、Pascal都是编译实现的
解释型(如python):
类似同声翻译,需要有一个解释器,解释器会读取程序代码,一边翻译一边执行,详细如下
# 1、执行效率低
解释型语言的实现中,翻译器并不产生目标机器代码,而是产生易于执行的中间代码。
这种中间代码与机器代码是不同的,中间代码的解释是由软件支持的,不能直接使用硬件,
软件解释器通常会导致执行效率较低。
# 2、开发效率高
用解释型语言编写的程序是由另一个可以理解中间代码的解释程序执行的,与编译程序不同的是,
解释程序的任务是逐一将源程序的语句解释成可执行的机器指令,不需要将源程序翻译成目标代码再执行。
解释程序的优点是当语句出现语法错误时,可以立即引起程序员的注意,而程序员在程序开发期间就能进行校正。
# 3、跨平台性强
代码运行是依赖于解释器,不同平台有对应版本的解释器,所以解释型的跨平台性强
# 其他
对于解释型Basic语言,需要一个专门的解释器解释执行Basic程序,每条语句只有在执行时才被翻译,
这种解释型语言每执行一次就翻译一次,因而效率低下。一般地,动态语言都是解释型的,
例如:Tcl、Perl、Ruby、VBScript、javascript等
ps:混合型语言
java是一类特殊的编程语言,Java程序也需要编译,但是却没有直接编译为机器语言,而是编译为字节码,
然后在Java虚拟机上以解释方式执行字节码。
总结
综上选择不同编程语言来开发应用程序对比
#1、执行效率:机器语言>汇编语言>高级语言(编译型>解释型)
#2、开发效率:机器语言<汇编语言<高级语言(编译型<解释型)
#3、跨平台性:解释型具有极强的跨平台型
三 python介绍
谈及python,涉及两层意思,一层代表的是python这门语言的语法风格,另外一层代表的则是专门用来解释该语法风格的应用程序:python解释器。
Python崇尚优美、清晰、简单,是一个优秀并广泛使用的语言
Python解释器的发展史
从一出生,Python已经具有了:类,函数,异常处理,包含表和词典在内的核心数据类型,以及模块为基础的拓展系统。
Python解释器有哪些种类?
官方的Python解释器本质就是基于C语言开发的一个软件,该软件的功能就是读取以.py结尾的文件内容,然后按照Guido定义好的语法和规则去翻译并执行相应的代码。
# Jython
JPython解释器是用JAVA编写的python解释器,可以直接把Python代码编译成Java字节码并执行,它不但使基于java的项目之上嵌入python脚本成为可能,同时也可以将java程序引入到python程序之中。
# IPython
IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。这就好比很多国产浏览器虽然外观不同,但内核其实都是调用了IE。
CPython用>>>作为提示符,而IPython用In [序号]:作为提示符。
# PyPy
PyPy是Python开发者为了更好地Hack Python而用Python语言实现的Python解释器。PyPy提供了JIT编译器和沙盒功能,对Python代码进行动态编译(注意不是解释),因此运行速度比CPython还要快。
# IronPython
IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
四 安装Cpython解释器
Python解释器目前已支持所有主流操作系统,在Linux,Unix,Mac系统上自带Python解释器,在Windows系统上需要安装一下,具体步骤如下。
4.1、下载python解释器
https://www.python.org
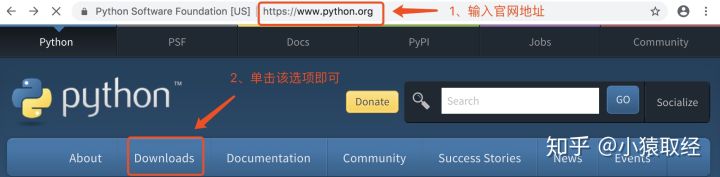

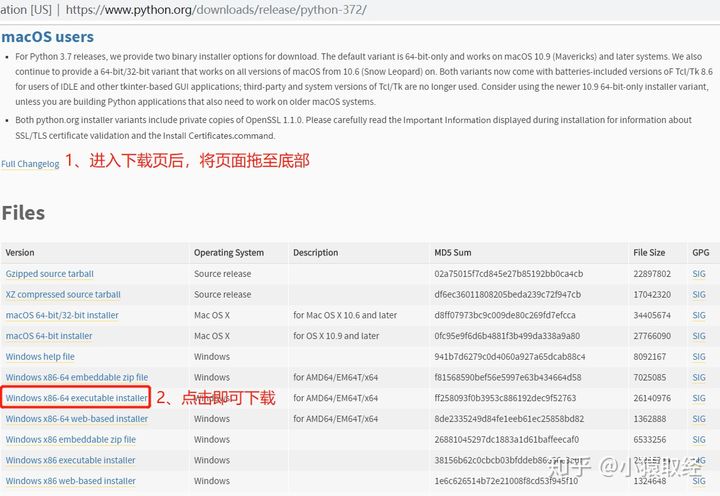
4.2、安装python解释器


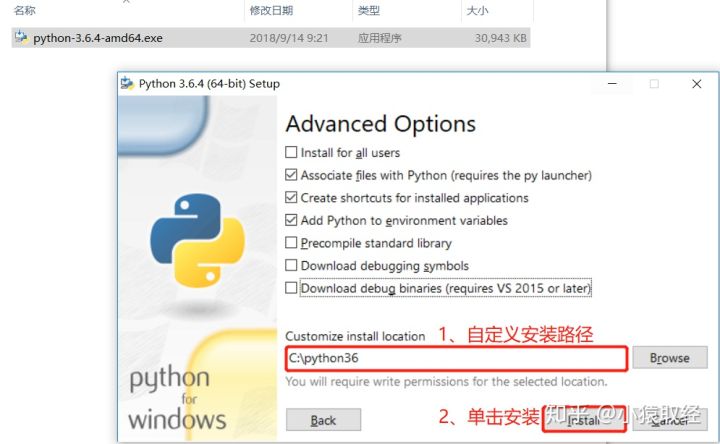
4.3、测试安装是否成功
windows --> 运行 --> 输入cmd ,然后回车,弹出cmd程序,输入python,如果能进入交互环境 ,代表安装成功。


五 第一个python程序
5.1 运行python程序有两种方式
方式一: 交互式模式

方式二:脚本文件
# 1、打开一个文本编辑工具,写入下述代码,并保存文件,此处文件的路径为D:\\test.py。强调:python解释器执行程序是解释执行,解释的根本就是打开文件读内容,因此文件的后缀名没有硬性限制,但通常定义为.py结尾
print('hello world')
# 2、打开cmd,运行命令,如下图

总结:
#1、交互式模式下可以即时得到代码执行结果,调试程序十分方便
#2、若想将代码永久保存下来,则必须将代码写入文件中
#3、我们以后主要就是在代码写入文件中,偶尔需要打开交互式模式调试某段代码、验证结果
5.2 注释
在正式学习python语法前,我们必须事先介绍一个非常重要的语法:注释
1、什么是注释
注释就是就是对代码的解释说明,注释的内容不会被当作代码运行
2、为什么要注释
增强代码的可读性
3、怎么用注释?
代码注释分单行和多行注释
1、单行注释用#号,可以跟在代码的正上方或者正后方
2、多行注释可以用三对双引号""" """
4、代码注释的原则:
1、不用全部加注释,只需要为自己觉得重要或不好理解的部分加注释即可
2、注释可以用中文或英文,但不要用拼音
六 IDE工具pycharm的使用
在编写第一个python程序时,存在以下问题,严重影响开发效率
问题一:我们了解到一个python程序从开发到运行需要操作至少两个软件
1、打开一个软件:文本编辑器,创建文本来编写程序
2、打开cmd,然后输入命令执行pyton程序
问题二:在开发过程中,并没代码提示以及纠错功能
综上,如果能有一款工具能够集成n个软件的功能,同时又代码提示以及纠错等功能,那么将会极大地提升程序员的开发效率,这就是IDE的由来,IDE全称Integrated Development Environment,即集成开发环境,最好的开发Python程序的IDE就是PyCharm。
6.2、pychram安装
# 下载地址: https://www.jetbrains.com/pycharm/download 选择Professional专业版
6.3、Pycharm创建文件夹
6.4、如何创建文件并编写程序执行
创建py文件test.py
在test.py中写代码,输入关键字的开头可以用tab键补全后续,并且会有代码的错误提示
3、Python语法入门之变量
一 引入
我们学习python语言是为了控制计算机、让计算机能够像人一样去工作,所以在python这门语言中,所有语法存在的意义都是为了让计算机具备人的某一项技能,这句话是我们理解后续所有python语法的根本。
二 变量
一、什么是变量?
# 变量就是可以变化的量,量指的是事物的状态,比如人的年龄、性别,游戏角色的等级、金钱等等
二、为什么要有变量?
# 为了让计算机能够像人一样去记忆事物的某种状态,并且状态是可以发生变化的
# 详细地说:
# 程序执行的本质就是一系列状态的变化,变是程序执行的直接体现,所以我们需要有一种机制能够反映或者说是保存下来程序执行时状态,以及状态的变化。
三、怎么使用变量(先定义、后使用)
3.1、变量的定义与使用
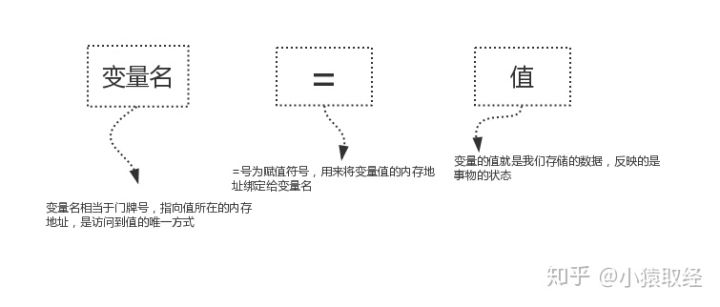
定义变量示范如下
name = 'harry' # 记下人的名字为'harry'
sex = '男' # 记下人的性别为男性
age = 18 # 记下人的年龄为18岁
salary = 30000.1 # 记下人的薪资为30000.1元
解释器执行到变量定义的代码时会申请内存空间存放变量值,然后将变量值的内存地址绑定给变量名,以变量的定义age=18为例,如下图
插图:定义变量申请内存
通过变量名即可引用到对应的值
# 通过变量名即可引用到值,我们可以结合print()功能将其打印出来
print(age) # 通过变量名age找到值18,然后执行print(18),输出:18
# 命名规范
1. 变量名只能是 字母、数字或下划线的任意组合
2. 变量名的第一个字符不能是数字
3. 关键字不能声明为变量名,常用关键字如下
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from','global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
年龄=18 # 强烈建议不要使用中文命名
3.3、变量名的命名风格
# 风格一:驼峰体
AgeOfTony = 56
NumberOfStudents = 80
# 风格二:纯小写下划线(在python中,变量名的命名推荐使用该风格)
age_of_tony = 56
number_of_students = 80
3.4、变量值的三大特性
#1、id
反应的是变量在内存中的唯一编号,内存地址不同id肯定不同
#2、type
变量值的类型
#3、value
变量值
三、常量
3.1、什么是常量?
常量指在程序运行过程中不会改变的量
3.2、为什么要有常量?
在程序运行过程中,有些值是固定的、不应该被改变,比如圆周率 3.141592653…
3.3、怎么使用常量?
在Python中没有一个专门的语法定义常量,约定俗成是用全部大写的变量名表示常量。如:PI=3.14159。所以单从语法层面去讲,常量的使用与变量完全一致。
4、Python语法入门之基本数据类型
一 引入
变量值也有不同的类型
salary = 3.1 # 用浮点型去记录薪资
age = 18 # 用整型去记录年龄
name = 'lili' # 用字符串类型去记录人名
二 数字类型
2.1 int整型
2.1.1 作用
用来记录人的年龄,出生年份,学生人数等整数相关的状态
2.1.2 定义
age=18
birthday=1990
student_count=48
2.2 float浮点型
2.2.1 作用
用来记录人的身高,体重,薪资等小数相关的状态
2.2.2 定义
height=172.3
weight=103.5
salary=15000.89
2.3 数字类型的使用
1 、数学运算
>>> a = 1
>>> b = 3
>>> c = a + b
>>> c
4
2、比较大小
>>> x = 10
>>> y = 11
>>> x > y
False
三 字符串类型str
3.1 作用
用来记录人的名字,家庭住址,性别等描述性质的状态
3.2 定义
name = 'harry'
address = '上海市浦东新区'
sex = '男'
用单引号、双引号、多引号,都可以定义字符串,本质上是没有区别的,但是
#1、需要考虑引号嵌套的配对问题
msg = "My name is Tony , I'm 18 years old!" #内层有单引号,外层就需要用双引号
#2、多引号可以写多行字符串
msg = '''
天下只有两种人。比如一串葡萄到手,一种人挑最好的先吃,另一种人把最好的留到最后吃。
照例第一种人应该乐观,因为他每吃一颗都是吃剩的葡萄里最好的;第二种人应该悲观,因为他每吃一颗都是吃剩的葡萄里最坏的。
不过事实却适得其反,缘故是第二种人还有希望,第一种人只有回忆。
'''
3.3 使用
数字可以进行加减乘除等运算,字符串呢?也可以,但只能进行"相加"和"相乘"运算。
>>> name = 'tony'
>>> age = '18'
>>> name + age #相加其实就是简单的字符串拼接
'tony18'
>>> name * 5 #相乘就相当于将字符串相加了5次
'tonytonytonytonytony'
四 列表list
4.1 作用
如果我们需要用一个变量记录多个学生的姓名,用数字类型是无法实现,字符串类型确实可以记录下来,比如
stu_names=‘张三 李四 王五’,但存的目的是为了取,此时若想取出第二个学生的姓名实现起来相当麻烦,而列表类型就是专门用来记录多个同种属性的值(比如同一个班级多个学生的姓名、同一个人的多个爱好等),并且存取都十分方便
4.2 定义
>>> stu_names=['张三','李四','王五']
4.3 使用
# 1、列表类型是用索引来对应值,索引代表的是数据的位置,从0开始计数
>>> stu_names=['张三','李四','王五']
>>> stu_names[0]
'张三'
>>> stu_names[1]
'李四'
>>> stu_names[2]
'王五'
# 2、列表可以嵌套,嵌套取值如下
>>> students_info=[['tony',18,['jack',]],['jason',18,['play','sleep']]]
>>> students_info[0][2][0] #取出第一个学生的第一个爱好
'play'
五 字典dict
5.1 作用
如果我们需要用一个变量记录多个值,但多个值是不同属性的,比如人的姓名、年龄、身高,用列表可以存,但列表是用索引对应值的,而索引不能明确地表示值的含义,这就用到字典类型,字典类型是用key:value形式来存储数据,其中key可以对value有描述性的功能
5.2 定义
>>> person_info='name':'tony','age':18,'height':185.3
5.3 使用
# 1、字典类型是用key来对应值,key可以对值有描述性的功能,通常为字符串类型
>>> person_info='name':'tony','age':18,'height':185.3
>>> person_info['name']
'tony'
>>> person_info['age']
18
>>> person_info['height']
185.3
# 2、字典可以嵌套,嵌套取值如下
>>> students=[
... 'name':'tony','age':38,'hobbies':['play','sleep'],
... 'name':'jack','age':18,'hobbies':['read','sleep'],
... 'name':'rose','age':58,'hobbies':['music','read','sleep'],
... ]
>>> students[1]['hobbies'][1] #取第二个学生的第二个爱好
'sleep'
六 布尔bool
6.1 作用
用来记录真假这两种状态
6.2 定义
>>> is_ok = True
>>> is_ok = False
6.3 使用
通常用来当作判断的条件,我们将在if判断中用到它
5、Python语法入门之垃圾回收机制
一 引入
解释器在执行到定义变量的语法时,会申请内存空间来存放变量的值,而内存的容量是有限的,这就涉及到变量值所占用内存空间的回收问题,当一个变量值没有用了(简称垃圾)就应该将其占用的内存给回收掉,那什么样的变量值是没有用的呢?
单从逻辑层面分析,我们定义变量将变量值存起来的目的是为了以后取出来使用,而取得变量值需要通过其绑定的直接引用(如x=10,10被x直接引用)或间接引用(如l=[x,],x=10,10被x直接引用,而被容器类型l间接引用),所以当一个变量值不再绑定任何引用时,我们就无法再访问到该变量值了,该变量值自然就是没有用的,就应该被当成一个垃圾回收。
毫无疑问,内存空间的申请与回收都是非常耗费精力的事情,而且存在很大的危险性,稍有不慎就有可能引发内存溢出问题,好在Cpython解释器提供了自动的垃圾回收机制来帮我们解决了这件事。
二、什么是垃圾回收机制?
垃圾回收机制(简称GC)是Python解释器自带一种机,专门用来回收不可用的变量值所占用的内存空间
三、为什么要用垃圾回收机制?
程序运行过程中会申请大量的内存空间,而对于一些无用的内存空间如果不及时清理的话会导致内存使用殆尽(内存溢出),导致程序崩溃,因此管理内存是一件重要且繁杂的事情,而python解释器自带的垃圾回收机制把程序员从繁杂的内存管理中解放出来。
四、理解GC原理需要储备的知识
4.1、堆区与栈区
在定义变量时,变量名与变量值都是需要存储的,分别对应内存中的两块区域:堆区与栈区
# 1、变量名与值内存地址的关联关系存放于栈区
# 2、变量值存放于堆区,内存管理回收的则是堆区的内容,
4.2 直接引用与间接引用
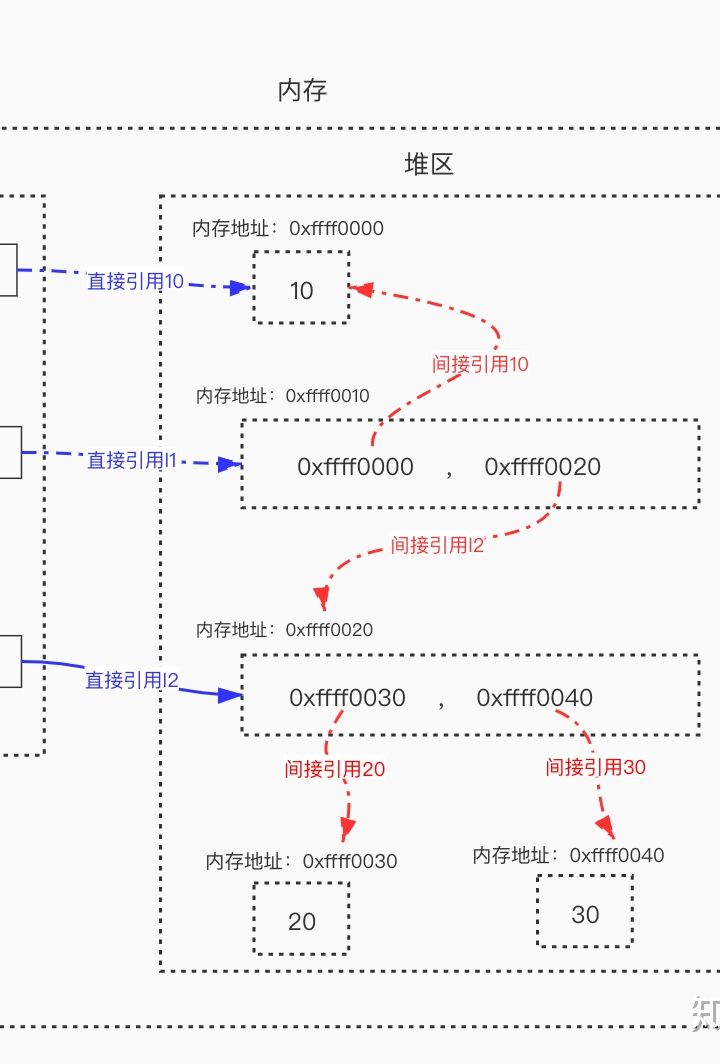
直接引用指的是从栈区出发直接引用到的内存地址。
间接引用指的是从栈区出发引用到堆区后,再通过进一步引用才能到达的内存地址。
如
l2 = [20, 30] # 列表本身被变量名l2直接引用,包含的元素被列表间接引用
x = 10 # 值10被变量名x直接引用
l1 = [x, l2] # 列表本身被变量名l1直接引用,包含的元素被列表间接引用
五、垃圾回收机制原理分析
Python的GC模块主要运用了“引用计数”(reference counting)来跟踪和回收垃圾。在引用计数的基础上,还可以通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用的问题,并且通过“分代回收”(generation collection)以空间换取时间的方式来进一步提高垃圾回收的效率。
5.1、引用计数
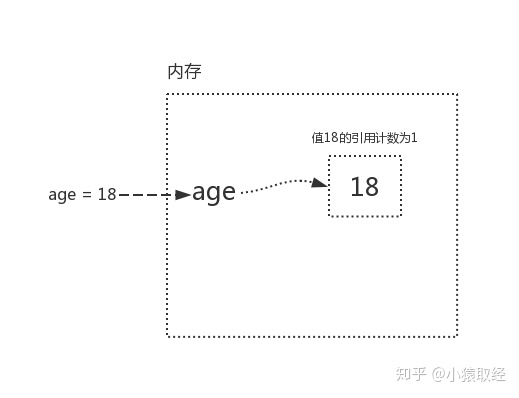
引用计数就是:变量值被变量名关联的次数
如:age=18
变量值18被关联了一个变量名age,称之为引用计数为1
引用计数增加:
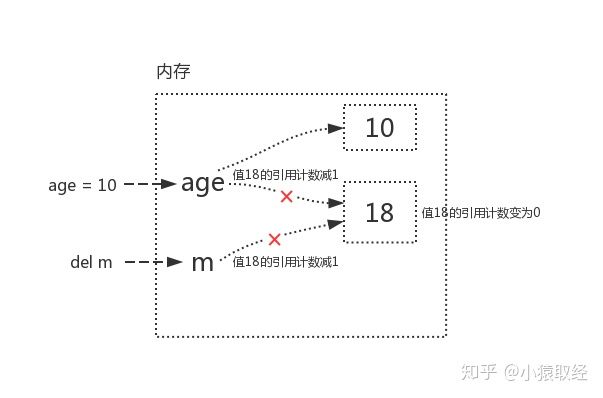
age=18 (此时,变量值18的引用计数为1)
m=age (把age的内存地址给了m,此时,m,age都关联了18,所以变量值18的引用计数为2)

引用计数减少:
age=10(名字age先与值18解除关联,再与3建立了关联,变量值18的引用计数为1)
del m(del的意思是解除变量名x与变量值18的关联关系,此时,变量18的引用计数为0)
值18的引用计数一旦变为0,其占用的内存地址就应该被解释器的垃圾回收机制回收
5.2、引用计数的问题与解决方案
5.2.1 问题一:循环引用
引用计数机制存在着一个致命的弱点,即循环引用(也称交叉引用)
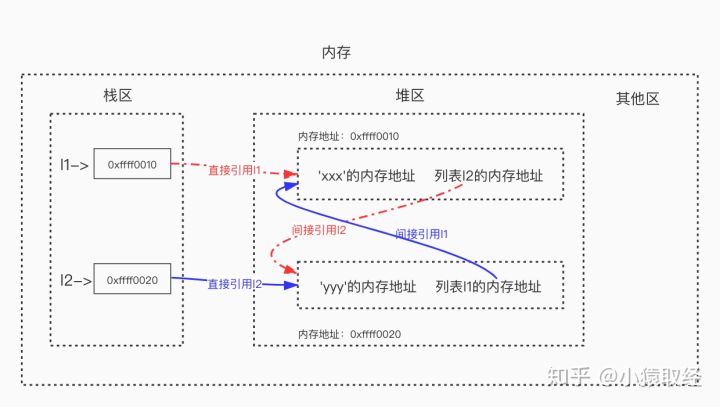
# 如下我们定义了两个列表,简称列表1与列表2,变量名l1指向列表1,变量名l2指向列表2
>>> l1=['xxx'] # 列表1被引用一次,列表1的引用计数变为1
>>> l2=['yyy'] # 列表2被引用一次,列表2的引用计数变为1
>>> l1.append(l2) # 把列表2追加到l1中作为第二个元素,列表2的引用计数变为2
>>> l2.append(l1) # 把列表1追加到l2中作为第二个元素,列表1的引用计数变为2
# l1与l2之间有相互引用
# l1 = ['xxx'的内存地址,列表2的内存地址]
# l2 = ['yyy'的内存地址,列表1的内存地址]
>>> l1
['xxx', ['yyy', [...]]]
>>> l2
['yyy', ['xxx', [...]]]
>>> l1[1][1][0]
'xxx'
python引入了“标记-清除” 与“分代回收”来分别解决引用计数的循环引用与效率低的问题
5.2.2 解决方案:标记-清除
容器对象(比如:list,set,dict,class,instance)都可以包含对其他对象的引用,所以都可能产生循环引用。而“标记-清除”计数就是为了解决循环引用的问题。
标记/清除算法的做法是当应用程序可用的内存空间被耗尽的时,就会停止整个程序,然后进行两项工作,第一项则是标记,第二项则是清除
5.2.3 问题二:效率问题
基于引用计数的回收机制,每次回收内存,都需要把所有对象的引用计数都遍历一遍,这是非常消耗时间的,于是引入了分代回收来提高回收效率,分代回收采用的是用“空间换时间”的策略。
5.2.4 解决方案:分代回收
代:
分代回收的核心思想是:在历经多次扫描的情况下,都没有被回收的变量,gc机制就会认为,该变量是常用变量,gc对其扫描的频率会降低,具体实现原理如下:
分代指的是根据存活时间来为变量划分不同等级(也就是不同的代)
新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,如果发现变量依然被引用,那么该对象的权重(权重本质就是个整数)加一,当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代,青春代的gc扫描的频率低于新生代(扫描时间间隔更长),假设5分钟扫描青春代一次,这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间,接下来,青春代中的对象,也会以同样的方式被移动到老年代中。也就是等级(代)越高,被垃圾回收机制扫描的频率越低
回收:
回收依然是使用引用计数作为回收的依据

虽然分代回收可以起到提升效率的效果,但也存在一定的缺点:
例如一个变量刚刚从新生代移入青春代,该变量的绑定关系就解除了,该变量应该被回收,但青春代的扫描频率低于新生代,这就到导致了应该被回收的垃圾没有得到及时地清理。
没有十全十美的方案:
毫无疑问,如果没有分代回收,即引用计数机制一直不停地对所有变量进行全体扫描,可以更及时地清理掉垃圾占用的内存,但这种一直不停地对所有变量进行全体扫描的方式效率极低,所以我们只能将二者中和。
综上
垃圾回收机制是在清理垃圾&释放内存的大背景下,允许分代回收以极小部分垃圾不会被及时释放为代价,以此换取引用计数整体扫描频率的降低,从而提升其性能,这是一种以空间换时间的解决方案目录
6、Python语法入门之与用户交互、运算符
一 程序与用户交互
1.1、什么是与用户交互
用户交互就是人往计算机中input/输入数据,计算机print/输出结果
1.2、为什么要与用户交互?
为了让计算机能够像人一样与用户沟通交流
1.3、如何与用户交互
交互的本质就是输入、输出
1.3.1 输入input:
# 在python3中input功能会等待用户的输入,用户输入任何内容,都存成字符串类型,然后赋值给等号左边的变量名
>>> username=input('请输入您的用户名:')
请输入您的用户名:jack # username = "jack"
>>> password=input('请输入您的密码:')
请输入您的密码:123 # password = "123"
# 了解知识:
# 1、在python2中存在一个raw_input功能与python3中的input功能一模一样
# 2、在python2中还存在一个input功能,需要用户输入一个明确的数据类型,输入什么类型就存成什么类型
>>> l=input('输入什么类型就存成什么类型: ')
输入什么类型就存成什么类型: [1,2,3]
>>> type(l)
<type 'list'>
1.3.2 输出print:
>>> print('hello world') # 只输出一个值
hello world
>>> print('first','second','third') # 一次性输出多个值,值用逗号隔开
first second third
# 默认print功能有一个end参数,该参数的默认值为"\\n"(代表换行),可以将end参数的值改成任意其它字符
print("aaaa",end='')
print("bbbb",end='&')
print("cccc",end='@')
#整体输出结果为:aaaabbbb&cccc@
1.3.3 输出之格式化输出
(1)什么是格式化输出?
把一段字符串里面的某些内容替换掉之后再输出,就是格式化输出。
(2)为什么要格式化输出?
我们经常会输出具有某种固定格式的内容,比如:'亲爱的xxx你好!你xxx月的话费是xxx,余额是xxx‘,我们需要做的就是将xxx替换为具体的内容。
(3)如何格式化输出?
这就用到了占位符,如:%s、%d:
# %s占位符:可以接收任意类型的值
# %d占位符:只能接收数字
>>> print('亲爱的%s你好!你%s月的话费是%d,余额是%d' %('tony',12,103,11))
亲爱的tony你好!你12月的话费是103,余额是11
# 练习1:接收用户输入,打印成指定格式
name = input('your name: ')
age = input('your age: ') #用户输入18,会存成字符串18,无法传给%d
print('My name is %s,my age is %s' %(name,age))
# 练习2:用户输入姓名、年龄、工作、爱好 ,然后打印成以下格式
------------ info of Tony -----------
Name : Tony
Age : 22
Sex : male
Job : Teacher
------------- end -----------------
二 基本运算符
2.1 算术运算符
python支持的算数运算符与数学上计算的符号使用是一致的,我们以x=9,y=2为例来依次介绍它们

2.2 比较运算符
比较运算用来对两个值进行比较,返回的是布尔值True或False,我们以x=9,y=2为例来依次介绍它们

2.3 赋值运算符
python语法中除了有=号这种简单的赋值运算外,还支持增量赋值、链式赋值、交叉赋值、解压赋值,这些赋值运算符存在的意义都是为了让我们的代码看起来更加精简。我们以x=9,y=2为例先来介绍一下增量赋值
2.3.1 增量赋值

2.3.2 链式赋值
如果我们想把同一个值同时赋值给多个变量名,可以这么做
>>> z=10
>>> y=z
>>> x=y
>>> x,y,z
(10, 10, 10)
链式赋值指的是可以用一行代码搞定这件事
>>> x=y=z=10
>>> x,y,z
(10, 10, 10)
2.3.3 交叉赋值
我们定义两个变量m与n
如果我们想将m与n的值交换过来,可以这么做
>>> temp=m
>>> m=n
>>> n=temp
>>> m,n
(20, 10)
交叉赋值指的是一行代码可以搞定这件事
>>> m=10
>>> n=20
>>> m,n=n,m # 交叉赋值
>>> m,n
(20, 10)
2.3.4 解压赋值
如果我们想把列表中的多个值取出来依次赋值给多个变量名,可以这么做
>>> nums=[11,22,33,44,55]
>>>
>>> a=nums[0]
>>> b=nums[1]
>>> c=nums[2]
>>> d=nums[3]
>>> e=nums[4]
>>> a,b,c,d,e
(11, 22, 33, 44, 55)
解压赋值指的是一行代码可以搞定这件事
>>> a,b,c,d,e=nums # nums包含多个值,就好比一个压缩包,解压赋值因此得名
>>> a,b,c,d,e
(11, 22, 33, 44, 55)
注意,上述解压赋值,等号左边的变量名个数必须与右面包含值的个数相同,否则会报错
#1、变量名少了
>>> a,b=nums
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: too many values to unpack (expected 2)
#2、变量名多了
>>> a,b,c,d,e,f=nums
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: not enough values to unpack (expected 6, got 5)
但如果我们只想取头尾的几个值,可以用*_匹配
>>> a,b,*_=nums
>>> a,b
(11, 22)
ps:字符串、字典、元组、集合类型都支持解压赋值
2.4 逻辑运算符
逻辑运算符用于连接多个条件,进行关联判断,会返回布尔值True或False

2.4.1 连续多个and
可以用and连接多个条件,会按照从左到右的顺序依次判断,一旦某一个条件为False,则无需再往右判断,可以立即判定最终结果就为False,只有在所有条件的结果都为True的情况下,最终结果才为True。
>>> 2 > 1 and 1 != 1 and True and 3 > 2 # 判断完第二个条件,就立即结束,得的最终结果为False
False
2.4.2 连续多个or
可以用or连接多个条件,会按照从左到右的顺序依次判断,一旦某一个条件为True,则无需再往右判断,可以立即判定最终结果就为True,只有在所有条件的结果都为False的情况下,最终结果才为False
>>> 2 > 1 or 1 != 1 or True or 3 > 2 # 判断完第一个条件,就立即结束,得的最终结果为True
True
2.4.3 优先级not>and>or
#1、三者的优先级关系:not>and>or,同一优先级默认从左往右计算。
>>> 3>4 and 4>3 or 1==3 and 'x' == 'x' or 3 >3
False
#2、最好使用括号来区别优先级,其实意义与上面的一样
'''
原理为:
(1) not的优先级最高,就是把紧跟其后的那个条件结果取反,所以not与紧跟其后的条件不可分割
(2) 如果语句中全部是用and连接,或者全部用or连接,那么按照从左到右的顺序依次计算即可
(3) 如果语句中既有and也有or,那么先用括号把and的左右两个条件给括起来,然后再进行运算
'''
>>> (3>4 and 4>3) or (1==3 and 'x' == 'x') or 3 >3
False
#3、短路运算:逻辑运算的结果一旦可以确定,那么就以当前处计算到的值作为最终结果返回
>>> 10 and 0 or '' and 0 or 'abc' or 'egon' == 'dsb' and 333 or 10 > 4
我们用括号来明确一下优先级
>>> (10 and 0) or ('' and 0) or 'abc' or ('egon' == 'dsb' and 333) or 10 > 4
短路: 0 '' 'abc'
假 假 真
返回: 'abc'
#4、短路运算面试题:
>>> 1 or 3
1
>>> 1 and 3
3
>>> 0 and 2 and 1
0
>>> 0 and 2 or 1
1
>>> 0 and 2 or 1 or 4
1
>>> 0 or False and 1
False
2.5 成员运算符

注意:虽然下述两种判断可以达到相同的效果,但我们推荐使用第二种格式,因为not in语义更加明确
>>> not 'lili' in ['jack','tom','robin']
True
>>> 'lili' not in ['jack','tom','robin']
True
2.6 身份运算符

需要强调的是:==双等号比较的是value是否相等,而is比较的是id是否相等
#1. id相同,内存地址必定相同,意味着type和value必定相同
#2. value相同type肯定相同,但id可能不同,如下
>>> x='Info Tony:18'
>>> y='Info Tony:18'
>>> id(x),id(y) # x与y的id不同,但是二者的值相同
(4327422640, 4327422256)
>>> x == y # 等号比较的是value
True
>>> type(x),type(y) # 值相同type肯定相同
(<class 'str'>, <class 'str'>)
>>> x is y # is比较的是id,x与y的值相等但id可以不同
False
7、Python语法入门之流程控制
一 引子:
流程控制即控制流程,具体指控制程序的执行流程,而程序的执行流程分为三种结构:顺序结构(之前我们写的代码都是顺序结构)、分支结构(用到if判断)、循环结构(用到while与for)
二 分支结构
2.1 什么是分支结构
分支结构就是根据条件判断的真假去执行不同分支对应的子代码
2.2 为什么要用分支结构
人类某些时候需要根据条件来决定做什么事情,比如:如果今天下雨,就带伞
所以程序中必须有相应的机制来控制计算机具备人的这种判断能力
2.3 如何使用分支结构
2.3.1 if语法
用if关键字来实现分支结构,完整语法如下
if 条件1: # 如果条件1的结果为True,就依次执行:代码1、代码2,......
代码1
代码2
......
elif 条件2: # 如果条件2的结果为True,就依次执行:代码3、代码4,......
代码3
代码4
......
elif 条件3: # 如果条件3的结果为True,就依次执行:代码5、代码6,......
代码5
代码6
......
else: # 其它情况,就依次执行:代码7、代码8,......
代码7
代码8
......
# 注意:
# 1、python用相同缩进(4个空格表示一个缩进)来标识一组代码块,同一组代码会自上而下依次运行
# 2、条件可以是任意表达式,但执行结果必须为布尔类型
# 在if判断中所有的数据类型也都会自动转换成布尔类型
# 2.1、None,0,空(空字符串,空列表,空字典等)三种情况下转换成的布尔值为False
# 2.2、其余均为True
2.3.2 if应用案例
案例1:
如果:女人的年龄>30岁,那么:叫阿姨
age_of_girl=31
if age_of_girl > 30:
print('阿姨好')
案例2:
如果:女人的年龄>30岁,那么:叫阿姨,否则:叫小姐
age_of_girl=18
if age_of_girl > 30:
print('阿姨好')
else:
print('小姐好')
案例3:
如果:女人的年龄>=18并且<22岁并且身高>170并且体重<100并且是漂亮的,那么:表白,否则:叫阿姨**
age_of_girl=18
height=171
weight=99
is_pretty=True
if age_of_girl >= 18 and age_of_girl < 22 and height > 170 and weight < 100 and is_pretty == True:
print('表白...')
else:
print('阿姨好')
案例4:
如果:成绩>=90,那么:优秀
如果成绩>=80且<90,那么:良好
如果成绩>=70且<80,那么:普通
其他情况:很差
score=input('>>: ')
score=int(score)
if score >= 90:
print('优秀')
elif score >= 80:
print('良好')
elif score >= 70:
print('普通')
else:
print('很差')
案例 5:if 嵌套
#在表白的基础上继续:
#如果表白成功,那么:在一起
#否则:打印。。。
age_of_girl=18
height=171
weight=99
is_pretty=True
success=False
if age_of_girl >= 18 and age_of_girl < 22 and height > 170 and weight < 100 and is_pretty == True:
if success:
print('表白成功,在一起')
else:
print('什么爱情不爱情的,爱nmlgb的爱情,爱nmlg啊...')
else:
print('阿姨好')
练习1: 登陆功能
name=input('请输入用户名字:').strip()
password=input('请输入密码:').strip()
if name == 'tony' and password == '123':
print('tony login success')
else:
print('用户名或密码错误')
练习2:
#!/usr/bin/env python
#根据用户输入内容打印其权限
'''
egon --> 超级管理员
tom --> 普通管理员
jack,rain --> 业务主管
其他 --> 普通用户
'''
name=input('请输入用户名字:')
if name == 'egon':
print('超级管理员')
elif name == 'tom':
print('普通管理员')
elif name == 'jack' or name == 'rain':
print('业务主管')
else:
print('普通用户')
三 循环结构
3.1 什么是循环结构
循环结构就是重复执行某段代码块
3.2 为什么要用循环结构
人类某些时候需要重复做某件事情
所以程序中必须有相应的机制来控制计算机具备人的这种循环做事的能力
3.3 如何使用循环结构
3.3.1 while循环语法
python中有while与for两种循环机制,其中while循环称之为条件循环,语法如下
while 条件:
代码1
代码2
代码3
while的运行步骤:
步骤1:如果条件为真,那么依次执行:代码1、代码2、代码3、......
步骤2:执行完毕后再次判断条件,如果条件为True则再次执行:代码1、代码2、代码3、......,如果条件为False,则循环终止

3.3.2 while循环应用案例
案例一:while循环的基本使用
用户认证程序
#用户认证程序的基本逻辑就是接收用户输入的用户名密码然后与程序中存放的用户名密码进行判断,判断成功则登陆成功,判断失败则输出账号或密码错误
username = "jason"
password = "123"
inp_name = input("请输入用户名:")
inp_pwd = input("请输入密码:")
if inp_name == username and inp_pwd == password:
print("登陆成功")
else:
print("输入的用户名或密码错误!")
#通常认证失败的情况下,会要求用户重新输入用户名和密码进行验证,如果我们想给用户三次试错机会,本质就是将上述代码重复运行三遍,你总不会想着把代码复制3次吧。。。。
username = "jason"
password = "123"
# 第一次验证
inp_name = input("请输入用户名:")
inp_pwd = input("请输入密码:")
if inp_name == username and inp_pwd == password:
print("登陆成功")
else:
print("输入的用户名或密码错误!")
# 第二次验证
inp_name = input("请输入用户名:")
inp_pwd = input("请输入密码:")
if inp_name == username and inp_pwd == password:
print("登陆成功")
else:
print("输入的用户名或密码错误!")
# 第三次验证
inp_name = input("请输入用户名:")
inp_pwd = input("请输入密码:")
if inp_name == username and inp_pwd == password:
print("登陆成功")
else:
print("输入的用户名或密码错误!")
#即使是小白的你,也觉得的太low了是不是,以后要修改功能还得修改3次,因此记住,写重复的代码是程序员最不耻的行为。
#那么如何做到不用写重复代码又能让程序重复一段代码多次呢? 循环语句就派上用场啦(使用while循环实现)
username = "jason"
password = "123"
# 记录错误验证的次数
count = 0
while count < 3:
inp_name = input("请输入用户名:")
inp_pwd = input("请输入密码:")
if inp_name == username and inp_pwd == password:
print("登陆成功")
else:
print("输入的用户名或密码错误!")
count += 1
案例二:while+break的使用
使用了while循环后,代码确实精简多了,但问题是用户输入正确的用户名密码以后无法结束循环,那如何结束掉一个循环呢?这就需要用到break了!
username = "jason"
password = "123"
# 记录错误验证的次数
count = 0
while count < 3:
inp_name = input("请输入用户名:")
inp_pwd = input("请输入密码:")
if inp_name == username and inp_pwd == password:
print("登陆成功")
break # 用于结束本层循环
else:
print("输入的用户名或密码错误!")
count += 1
案例三:while循环嵌套+break
如果while循环嵌套了很多层,要想退出每一层循环则需要在每一层循环都有一个break
username = "jason"
password = "123"
count = 0
while count < 3: # 第一层循环
inp_name = input("请输入用户名:")
inp_pwd = input("请输入密码:")
if inp_name == username and inp_pwd == password:
print("登陆成功")
while True: # 第二层循环
cmd = input('>>: ')
if cmd == 'quit':
break # 用于结束本层循环,即第二层循环
print('run <%s>' % cmd)
break # 用于结束本层循环,即第一层循环
else:
print("输入的用户名或密码错误!")
count += 1
案例四:while循环嵌套+tag的使用
针对嵌套多层的while循环,如果我们的目的很明确就是要在某一层直接退出所有层的循环,其实有一个窍门,就让所有while循环的条件都用同一个变量,该变量的初始值为True,一旦在某一层将该变量的值改成False,则所有层的循环
以上是关于python编程从入门到实践的主要内容,如果未能解决你的问题,请参考以下文章