LLMs大模型带来的新范式#Mixlab Insight
Posted shadowcz007
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LLMs大模型带来的新范式#Mixlab Insight相关的知识,希望对你有一定的参考价值。

MixGPT
今天为大家带来一些启发性的insight,如果对你有帮助,请留言讨论。
大模型LLM带来了哪些全新的范式?我先举几个例子。

shadow
#人机交互新范式
更自然的语音交互、无处不在的屏幕,普适计算提前到来。普适计算——1991年马克·维瑟提出,通过对环境的充分感知和计算,采用自然的交互方式,实现和环境融为一体的计算。
ChatGPT 为交互式 3D 角色提供支持
全息显示供应商 Looking Glass 正在使用 OpenAI 的 ChatGPT 为名为“兔子叔叔”的 3D 角色提供支持,该角色可以与用户进行对话。Looking Glass 演示了与3D 角色的交互。用户请兔子叔叔完成歌曲“Never Gonna Give You Up”的歌词。3D角色认出了这首歌,并创作了自己编造的、以兔子为主题的歌词,与歌曲的其余部分押韵。
#软件开发新范式
基于LLM的新型软件开发模式将兴起。基于LLMs的推荐系统,以前搭建一个推荐系统,冷启动、各种特征的处理、推荐效果不如意等等,有了LLM,一切都变得更为简单而有效。

Chat-REC
Towards Interactive and Explainable LLMs-Augmented Recommender System
一种用 LLMs 增强传统推荐的范式 Chat-Rec。通过将用户画像和历史交互转为 Prompt,LLMs 可以有效地学习用户的偏好,关键是它不需要训练,而是完全依赖于上下文学习,并可以有效推理出偏好和推荐内容的联系。

微软提供基于LLM的软件开发指南,也值得学习⬆️。
#工具链新范式
可调用各种App或模型完成复杂任务,软件生态被进一步激活。
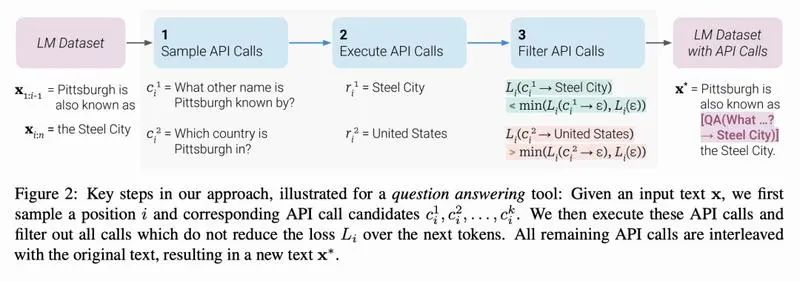
Toolformer
Language Models Can Teach Themselves to Use Tools
Toolformer,一种让LLMs学会使用外部工具的技术。通过 API 以自监督方式学习使用外部工具,论文展示了 Toolformer 学习使用一系列的工具,包括计算器、问答系统、搜索引擎、翻译系统和日历。


HuggingGPT
Solving AI Tasks with ChatGPT and its Friends in HuggingFace
LLMs(ChatGPT)作为控制器,协调管理现有的各种AI模型,通过语言text作为通用接口来增强机器的理解和运算能力。
#群体协作新范式
得益于LLMs,释放了个体的创造力,再通过线上高效率的群体链接,群体创造力正在爆发ing
🔥AIGC医疗人Mix的聊天记录
————— 2023-4-3 —————
这个可以 多方位融合
#
我们不是还有个云端建筑师群,联动一下
我们还有AIGC快乐制造相关的🙋 somehow关注心理健康 哈哈哈哈哈
哈哈 可以 你做心理治疗室
这个挺好的,大城市打工人很需要
角色扮演 群里可欢乐了,欢迎来玩
选一个你想扮演的角色!带你短暂逃离现实世界
这个很好玩的
疾病预防,康复管理,我研究生的topic[耶],突然感觉人生经历都串联起来了
#
可以结合,果然思路都是碰撞出来的
Mixlab许愿池,拥有促进idea发生碰撞的魔力
*加入方式:角色扮演、AIGC儒释道、基于AI的未来设计 - AIGC分布式创新联盟
除了个体的协作,多个LLM还可以协同工作,相互补充提高性能。例如,语音识别系统可以调用多个LLM来获得更可靠的识别结果;机器翻译可以调用源语言模型、目标语言模型和翻译模型进行翻译。
@MixGPT 你觉得还有哪些新范式?
#

MixGPT
大模型LLMs带来了许多全新的范式,我来总结下:
1. 人机交互新范式:
基于LLM的语音助手,它可以通过语音识别和自然语言处理技术来理解用户的问题,并提供相应的答案。智能音箱可以根据语境理解用户的意图,并作出恰当的响应;虚拟接待员可以与用户进行复杂会话。
2. 推荐系统新范式:
基于LLM的推荐系统,它可以分析用户的观看历史和评分,从而提供个性化的电影和电视剧推荐。
3. 工具链新范式:
一个基于LLM的工具链,它提供了各种预训练的模型和工具,使得普通用户可以使用这些模型和工具来完成各种任务;一个机器翻译系统可以调用LLM来获得更好的翻译候选结果;各种应用可以组合使用LLM的功能来实现更复杂的功能。
4. 群体协作新范式:
一个基于LLM的群体协作工具,它可以分析群体成员的历史行为和兴趣,从而提供更准确的建议和推荐。利用LLM技术,使得群体成员可以更好地理解彼此的需求和意图。
另外,我提一个新的范式:
知识学习新范式
LLM中的知识可以被提取出来,构建知识图谱等结构化知识库。例如,从Wikipedia和BookCorpus中预训练的知识可以被提取出来组成概念网;通过对话历史提取出常识知识构建知识库;LLM还能根据你的理解能力和知识背景为你讲解新知识。
今天的聊天很有启发。

shadow

如果你觉得本文具备启发性,欢迎转载or传播📣

opus
加入社群请联系~

低调的彩蛋 ⬇️

http://www.mix-copilot.com
大语言模型(LLMs)和新兴机器学习技术栈
作者 | Harrison Chase & Brian Raymond
编译 | 岳扬
01 现有的NLP技术栈
直到最近,NLP开发人员都一直依赖于传统优化NLP任务的技术栈,如文本分类(text classification)、命名实体识别(Named Entity Recognition)、命名实体消歧(Named Entity Disambiguation)。这种技术栈通常由数据预处理管道(data preprocessing pipeline)、机器学习管道(machine learning pipeline)和各种存储嵌入和结构化数据的数据库组成。
这种架构在生成大量的三元组(triples)、词嵌入(word embeddings)、句子嵌入(sentence embeddings)、Seq2Seq模型的输出(sequence-to-sequence outputs)、语言模型概率值(language model probabilities)、注意力机制的权重(attention weights)等方面运作良好。开发人员通常会将这些结构化输出数据存储在ElasticSearch、Postgres或Neo4j数据库中,他们会将这些数据作为用户(或服务)可以查询的知识图谱来使用。

图1. 现有的NLP技术栈
02 新兴的大语言模型(LLM)技术栈
自2022年秋季以来,一个旨在充分挖掘LLM潜力的新技术栈开始出现。与之前的技术栈相比,该技术栈着重于实现文本生成——与早期的机器学习模型相比,现代LLM最擅长这项任务。
这个新的技术栈由四个主要部分组成:数据预处理管道(data preprocessing pipeline)、嵌入终端(embeddings endpoint )+向量存储(vector store)、LLM终端(LLM endpoints)和LLM编程框架(LLM programming framework) 。
旧的技术栈和新的技术栈之间有几个很大的不同之处:
-
首先,新的技术栈不那么依赖存储结构化数据的知识图谱(如三元组),因为诸如ChatGPT、Claude和Flan T-5等LLM比早期的GPT 2等模型编码了更多的信息。
-
第二,较新的技术栈使用现成的LLM终端(LLM endpoint)作为模型,而不是定制的ML管道(ML pipeline)(至少在刚开始时)。 这意味着今天的开发人员花费更少的时间来训练专门的信息提取模型(例如命名实体识别、关系提取和情感分析),并且可以在比较少的时间(和成本)内启动解决方案。

图2. 新兴的大模型技术栈
2.1 数据预处理管道
新技术栈的第一个主要部分(数据预处理管道)与旧的技术栈没有太大变化。这一步包括用于摄取数据的连接器(例如S3 bucket和CRM),数据变换层(data transformation layer)和下游连接器(如到向量数据库)。通常情况下,输入到LLM中最有价值的信息一般是最难处理的(PDF、PPTX、HTML等),但也有一些容易处理的文件(例如.DOCX)包含用户不希望发送到推理终端的信息(如广告、法律模板等)。
从历史上看,这一步骤一般是由数据科学家为每个应用程序手工构建的。根据所涉及的数据类型,他们可能使用现成的OCR模型和几十到几百个自定义的正则表达式来转换和清理自然语言数据(natural language data),以便在下游机器学习管道(machine learning pipeline)中进行处理。对于非结构化数据,我们正在开发一款开源工具来加速这一预处理步骤,利用一系列计算机视觉文档分割模型(computer vision document segmentation models),以及NLP模型、Python脚本和正则表达式来自动提取、清理和转换关键文档元素(例如标题、正文、页眉/页脚、列表等)。
我们(Langchain)目前正在开发一款跨时代的工具,以使开发人员能够轻松地将包含自然语言数据的大型和高度异构的语料库(例如,包含成千上万的PDF、PPTX、聊天记录、抓取的HTML等的S3 bucket)指向单个API终端,并接收干净的JSON,为嵌入终端和存储在矢量数据库中做好准备。
2.2 嵌入终端和向量存储
嵌入终端(embeddings endpoint)和向量存储(vector store) 的使用代表了数据存储和访问方式的重大演变。以前的嵌入主要用于文档聚类等专有任务(niche task)。将文档及其嵌入存储在向量数据库中,使LLM终端的critical engagement patterns得以实现(下文将详细介绍)。这种架构的主要优势之一是能够直接存储原始嵌入,而不是将它们转换为结构化格式。 这意味着数据可以以其自然格式存储,从而实现更快的处理时间和更高效的数据检索。此外,这种方法可以更轻松地处理大型数据集,因为它可以减少在训练和推理过程中需要处理的数据量。
生成和存储文档嵌入(document embeddings)以及文档的JSON版本,为LLM与向量存储的对接创造了一个简单的机制。这对于需要实时处理的应用特别有用,比如聊天机器人(chatbots)。通过最大限度地减少数据检索所需的时间,系统可以更快地响应并提供更好的用户体验。使用嵌入(以及文档索引)和向量存储的另一个优点是,它可以更容易地实现迁移学习等技术,以实现更高效的微调和更好的性能。
2.3 LLM终端
新技术栈的第三个核心组成是LLM终端。这是接收输入数据并产生LLM输出的终端。LLM终端负责管理模型的资源,包括内存和计算,并提供可扩展和容错的接口,为下游应用程序提供LLM输出。
尽管大多数LLM供应商提供了几种不同类型的终端,本文我们用LLM endpoints来指代文本生成(text-generation)终端。如上所述,这是为许多新兴应用程序提供动力的新技术解锁(与更传统的ML管道相比)。这似乎有点简化了,但这些LLM终端公开的接口是文本字段作为输入,文本字段作为输出。
2.4 LLM编程框架
新技术栈的最后一个主要内容是LLM编程框架。这些框架为使用语言模型构建应用程序提供了一组工具和抽象组件(abstractions)。 在LangChain,这正是我们正在努力构建的框架。这些框架正在迅速发展,这使得它们很难被定义。尽管如此,我们还是在收集一组abstractions,我们将在下面详细介绍。
这些框架的一个重要功能是编排所有不同的组件到目前为止,在新技术栈中,我们看到出现的组件类型有:LLM提供商(在上一节中介绍)、嵌入模型、向量存储、文档加载器、其他外部工具(谷歌搜索等) 。在LangChain中,这些组件的组合方式被称为链。例如,我们有在向量存储上做QA的链,与SQL数据库交互的链,等等。
所有这些链都涉及在某个时候调用语言模型。调用语言模型时,主要挑战来自构建传递给语言模型的提示(prompt)。这些提示(prompt)通常是从其他组件中获取的信息加上基本提示模板的组合。LangChain提供了一堆默认提示模板来开始使用这些链,同时构建了LangChainHub[1]——一个供用户分享这些提示(prompt)的地方。
03 Open Questions
索引数据的最佳方式是什么?
现在很多人都在使用向量存储作为索引数据的主要方式,以便LLM能够与之交互。然而,这只是定义这些交互应该如何工作的第一步。现在有一个正在被积极探索的领域是研究将知识图谱与文档索引及其嵌入相结合可以在多大程度上提高LLM的推理质量。 此外,在可以预见的未来,大多数企业将继续需要高质量的结构化数据(通常在图数据库中)来与现有数据集和商业智能解决方案融合。 这意味着从中期来看,企业决策者实际上可能同时依赖向量数据库和图数据库来支持现有的应用程序和工作流。
微调(Fine Tuning)/再训练(Retraining)将会是什么样子?
现在像LangChain这样的LLM编程框架经常被用来将自有数据与预训练的LLM相结合,还有另一种方法是在自有数据上对LLM进行微调。微调有一些优点和缺点,从好的方面来说,它减少了对这种编排的大量需求。然而,从坏的方面来说,它的成本和时间花费都比较高,而且需要定期进行调整以保持更新。 看看这些权衡如何随着时间的推移而演变将会很有趣。
使用嵌入(embeddings)有哪些不同方式?
虽然目前主要的使用模式仍然是将数据保存在外部数据库中,而不是对其进行微调,但也有其他方法将其与LLM结合起来,而不是当前的方法(这些方法都涉及将数据传递到提示(prompt)中) 。令人高兴的是有RETRO[2]这样的方法,它为文档获取嵌入(embeddings),然后直接处理这些嵌入(embeddings),而不是将文本作为提示(prompt)传递进来。虽然这些模型大多用于研究环境,但看看它们是否能成为主流,以及这对LLM编程框架有什么影响,将会很有意思。
04 总结 Conclusion
现在向这个新的LLM技术栈进行转变是一个令人兴奋的过程,它将使开发人员能够构建和部署更强大的NLP应用程序。新技术栈比旧技术栈更高效、更可扩展、更易于使用,而且它释放了LLM的全部潜力。随着开发人员继续寻找利用LLM力量的新方法,我们可以期待在未来几个月和几年内看到这一领域的更多创新。
END
参考资料
1.https://github.com/hwchase17/langchain-hub
2.https://arxiv.org/abs/2112.04426
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:https://medium.com/@brian_90925/llms-and-the-emerging-ml-tech-stack-6fa66ee4561a
以上是关于LLMs大模型带来的新范式#Mixlab Insight的主要内容,如果未能解决你的问题,请参考以下文章