CS231n-2022 Module1: 神经网络3:Learning之参数更新
Posted 笨牛慢耕
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CS231n-2022 Module1: 神经网络3:Learning之参数更新相关的知识,希望对你有一定的参考价值。
目录
2. SGD及其花式变体(bells and whistles)
3. 学习率退火处理Annealing the learning rate
5. Per-parameter adaptive learning rate methods
1. 前言
本文编译自斯坦福大学的CS231n课程(2022) Module1课程中神经网络部分之一,原课件网页参见:https://cs231n.github.io/neural-networks-3/
本文(本系列)不是对原始课件网页内容的完全翻译,只是作为学习笔记的摘要总结,主要是自我参考,而且也可能夹带一些私货(自己的理解和延申,不保证准确性)。如果想要了解更具体的细节,还请服用原文。如果本摘要恰巧也对小伙伴们有所参考则纯属无心插柳概不认账^-^。
本文属于“CS231n-2022 Module1: 神经网络概要3:Learning and Evaluation”的一部分(因为篇幅较长,所以单列一篇)。
在反向传播(backpropagation)中计算得到的解析梯度(analytic gradient, 与之相对的是在梯度检查中以数值近似方式计算的数值梯度numeric gradient)用于参数更新。以下介绍一些常用的参数更新的方法,主要侧重于这些方法背后的直觉知识(intuition),而非详细的分析。
2. SGD及其花式变体(bells and whistles)
2.1 Vanilla update
Vanilla意指常规的、普通的、朴素的、最简单的,与naive的意思相当。这里是指SGD(Stochatis gradicent descent:随机梯度下降)的最基本方法。
最简单的更新方式就是沿着梯度相反的方向进行参数更新,更新量则由梯度的幅度以及学习率(可以理解为步长系数)决定。为什么是与梯度相反的方向,因为梯度指示着loss增长的方向,而我们优化的目标是要降低loss。考虑一个参数向量 x 以及梯度向量记为 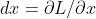 ,Vanilla update示例代码如下:
,Vanilla update示例代码如下:
# Vanilla update
x += - learning_rate * dx
learning_rate是一个超参数,一个固定的常数(在一个batch或者一个epoch中。后面会提到,在实际的神经网络训练中,通常会逐步减小学习率)。当一个数据集足够大,而学习率率足够小的话,总是能保证损失函数以递减(虽然可能不一定严格单调)的方式的变化。
2.2 Momentum update
动量更新的灵感来自于从物理的视角来考察优化问题(physical perspective)。损失可以被看作是丘陵地带的海拔高度(或者说势能,因为势能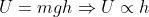 )。参数随机初始化等价于将一个粒子以零初速度放在某个随机地点。优化过程因此可以等价于粒子从初始地点沿着地形滚下的表征粒子的参数向量的模拟。
)。参数随机初始化等价于将一个粒子以零初速度放在某个随机地点。优化过程因此可以等价于粒子从初始地点沿着地形滚下的表征粒子的参数向量的模拟。
作用在粒子上的力与势能的梯度相关: ,即是说,以势能比作loss的话,粒子所受的力恰好就是负的梯度。进一步,由
,即是说,以势能比作loss的话,粒子所受的力恰好就是负的梯度。进一步,由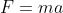 可知(在这种观点下,in this view)负的梯度与粒子的加速度成正比。注意与前述的Vanilla SGD的区别,在SGD中梯度直接积分得到位置(即梯度被看作是速度量纲的量),而这种物理学观点下,梯度是被看作是加速度量纲的量,它直接影响速度的更细,然后由速度进一步影响位置。 如以下例码所示:
可知(在这种观点下,in this view)负的梯度与粒子的加速度成正比。注意与前述的Vanilla SGD的区别,在SGD中梯度直接积分得到位置(即梯度被看作是速度量纲的量),而这种物理学观点下,梯度是被看作是加速度量纲的量,它直接影响速度的更细,然后由速度进一步影响位置。 如以下例码所示:
# Momentum update
v = mu * v - learning_rate * dx # integrate velocity
x += v # integrate position
如上所示,一个新的变量 v 和一个超参数(mu)被引入到更新中。作为一个非常不幸的用词不当( misnomer)的例子,这个变量(mu)在优化理论中被指称为动量(能让正统的物理学家狂打喷嚏,其典型值是大概0.9),而其物理含义其实与摩擦系数(coefficient of friction)更相配。从其效果来看,这个变量会抑制速度的增长,降低系统的动能。如果没有它的话,粒子即便到了山脚也将永远不会停下来(想象一下,没有摩擦力从高处滚落的粒子当然停不下来)。在交叉验证中,这个参数通常被设置为诸如[0.5, 0.9, 0.95, 0.99]。与针对学习率的退火处理过程( annealing schedules,后面将讨论到 )相类似,在学习的后期阶段逐步提高动量系数通常也能得到更好一些的优化结果。典型的设定是从大概0.5左右开始,然后逐步(over multiple epochs)提高到0.99左右。
With Momentum update, the parameter vector will build up velocity in any direction that has consistent gradient.
2.3 Nesterov Momentum
Nesterov Momentum(以下简记为NM)是Momentum Update的一个轻微变种。NM在理论上有更强的(作为凸函数的)收敛性的保证,在实践中也的确表现比标准的动量更新要好一些。
NM背后的核心idea是预测(lookahead),将原来的对参数更新贡献的两个部分并行做改为分先后两步走:
第一步是进行动量更新;
第二步在第一步所到达的新的位置进行梯度计算并进行更新。
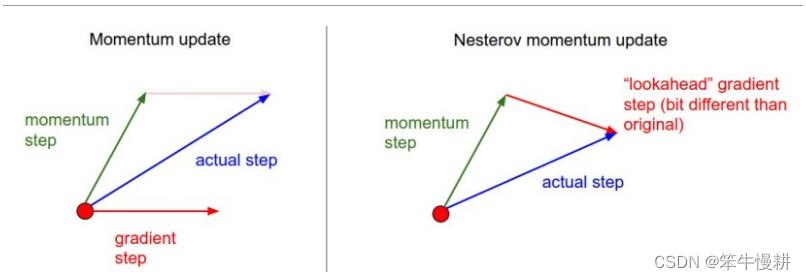
如上图所示,在Nesterov momentum方法中,不是估计原点(红点)处的梯度,而是在由动量更新所到达的绿色箭头处估计梯度并进行更新。示例代码如下:
x_ahead = x + mu * v
# evaluate dx_ahead (the gradient at x_ahead instead of at x)
v = mu * v - learning_rate * dx_ahead
x += v
实际上人们通常喜欢把描述方式略作修改使得它们长得更像vanilla SGD or momentum update。具体做法是,将更新式改为针对上述的x_ahead,这样,存储和更新的对象都由原来的x变为x_ahead (but renaming it back to x),这样处理后更新方程变为:
v_prev = v # back this up
v = mu * v - learning_rate * dx # velocity update stays the same
x += -mu * v_prev + (1 + mu) * v # position update changes form
Further reading to understand the source of these equations and the mathematical formulation of Nesterov’s Accelerated Momentum (NAG):
- Advances in optimizing Recurrent Networks by Yoshua Bengio, Section 3.5.
- Ilya Sutskever’s thesis (pdf) contains a longer exposition of the topic in section 7.2
3. 学习率退火处理Annealing the learning rate
根据百度百科:退火(annealing)是一种金属热处理工艺,指的是将金属缓慢加热到一定温度,保持足够时间,然后以适宜速度冷却。
对学习率进行退火处理的意思是指在神经训练过程中,一开始用比较大的学习率,训练到达一定程度后,逐渐降低学习率(降低炼丹温度)。
学习率意味着神经网络具有高的动能,参数向量或相对剧烈来回跳动,因而导致loss也难以收敛到较窄的范围内。
如何执行退火(降低学习率)处理需要一些技巧:减得太慢了会浪费计算,神经网络收敛要花费更长的时间;减得太快了会导致系统冷却太快因而无法到达本可到达的最佳状态。有三种基本的实现降低学习率的策略。
3.1 Step decay
每过几个epochs将学习率减小一定程度。比如说,每5 epochs学习率减半,或者,每20epochs学习率减小0.1。具体选择需要根据实际问题和模型case-by-case分析。
一个启发式(heuristic )的方法是监测验证错误,每当验证错误不再改善时就将学习率减小一些(比如说,减半。。。)。
3.2 Exponential decay
数学表达式为:
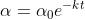
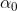 和k为超参数,t代表时间,可以是以iteration为单位也可以以epoch为单位。
和k为超参数,t代表时间,可以是以iteration为单位也可以以epoch为单位。
3.3 1/t decay
数学表达式为:
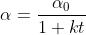
和k为超参数,t代表时间,以iteration为单位。
3.4 比较
实践中我们发现“step decay”相对更好使一些,因为它所需要的超参数(the fraction of decay and the step timings in units of epochs) 相比另外两种方法中的超参数k可解释性更强一些。
最后,如果你的计算力预算充分的话,稳妥的策略是选择较慢的decaying策略,这样需要的训练时间会更长一些(当然也应该得到更好一些的结果)。
4. 二阶方法,Second order methods
在深度学习中另一组比较流行的优化方法是基于牛顿方法( Newton’s method ),其迭代更新方法可以表示如下:
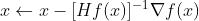
其中, Hf(x)为黑塞矩阵( Hessian matrix ), 即f(x)的二阶偏微分函数矩阵,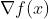 则表示梯度向量。直觉上来说,黑塞矩阵描述了损失函数的局部的曲率,将梯度用黑塞矩阵的逆进行加权(乘)会导致优化在曲率较小的方向迈更大(more aggressive)的步子,而在曲率较大的方向则采用较小的步长进行更新,基于此可以做更高效的更新。 注意,最关键的是在这个更新方程中不再需要任何超参数,这个被这种方法的推崇者认为是相较于一阶方法的很大的优点。
则表示梯度向量。直觉上来说,黑塞矩阵描述了损失函数的局部的曲率,将梯度用黑塞矩阵的逆进行加权(乘)会导致优化在曲率较小的方向迈更大(more aggressive)的步子,而在曲率较大的方向则采用较小的步长进行更新,基于此可以做更高效的更新。 注意,最关键的是在这个更新方程中不再需要任何超参数,这个被这种方法的推崇者认为是相较于一阶方法的很大的优点。
天下没有免费的午餐。对于绝大多数的深度学习来说这种方法没有实际使用价值,因为计算黑塞矩阵及其逆的计算的计算量巨大(无论是空间--即存储量--还是时间)。比如说一个有一百万个参数的神经网络,它的黑塞矩阵的大小是 [1,000,000 x 1,000,000],大概需要3725 gigabytes的内存空间。人们开发了很多准牛顿方法(quasi-Newton methods)用于求近似的逆黑塞矩阵,其中最有名的是 L-BFGS, 它利用梯度随时间变化的信息来隐式地(implicitly)得到近似值(i.e. the full matrix is never computed).
然而,即便排除内存问题,傻傻地使用L-BFGS的一个很大的缺点是它必须遍历整个训练集进行计算,而包含上百万个样本的训练集并不少见。与mini-batch SGD比一样, 想要在 mini-batches上适用L-BFGS需要更深的技巧,现在依然是一个活跃的研究领域。
基于以上理由,实际上, 在大规模深度学习和卷积神经网络上使用L-BFGS或类似的二阶方法很少见。更常见的是基于(Nesterov’s) momentum的SGD变体,因为它们更简单而且更容易扩展到大数据集上( scale more easily)。
Additional references:
- Large Scale Distributed Deep Networks is a paper from the Google Brain team, comparing L-BFGS and SGD variants in large-scale distributed optimization.
- SFO algorithm strives to combine the advantages of SGD with advantages of L-BFGS.
5. Per-parameter adaptive learning rate methods
前面的各种方法的学习率都是针对所有参数一视同仁。研究者们进一步开发了很多自适应地、甚至逐参数方式地调制学习率的方法。这些方法中很多依然需要依赖超参数,但是支持它们的论据是这些超参数通常具有很宽的可工作范围(相比前面的那些更基本的方法)。本节介绍其中几种典型的方法。
5.1 Adagrad
Adagrad是由 Duchi et al.提出的自适应调节学习率的优化方法。其示例代码如下:
# Assume the gradient dx and parameter vector x
cache += dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
cache用于跟踪每个参数的梯度平方和(per-parameter sum of squared gradients),然后用于各参数的更新。梯度大的参数的学习率自然地被调小了,反之亦然。有趣的是,其中的平方根处理是不可或缺的,没有它的话,算法的表现会变得很差。eps (通常取值范围为1e-4 to 1e-8)是用于避免除以0的运算,是一种非常常见的数值运算技巧。Adagrad的缺点是,在深度学习中,单调的学习率被证明过于激进(aggressive)会导致学习早早停止。
5.2 RMSprop
RMSprop虽然未被公开发表过,但是确实一种非常有效的自适应学习率方法。有趣的是,每个使用RMSprop的人都是引用 slide 29 of Lecture 6 of Geoff Hinton’s Coursera class。RMSprop针对Adagrad做了一些简单的调整,具体来说,使用了梯度平方的移动平均值来替代原是的(瞬时)梯度平方值(这里容我哔哔一句,深度学习中用到的好多这种小技巧都是信号处理中古老而简单的小飞刀啊。Per-parameter adaptive method就类似于OFDM通信中的频域均衡嘛。。。):
cache = decay_rate * cache + (1 - decay_rate) * dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
这里,decay_rate是一个超参数,典型值为 [0.9, 0.99, 0.999]. “x+= update”处理与Adagrad相同,差异在于 cache 采用了移动平均的方式进行计算(通常也称为指数滤波exponential filtering、忘却滤波forget filtering、Leaky intergrator。。。)。因此,RMSprop依然是基于每个参数的梯度的幅度来进行学习率的调节,获得了类似于均衡(equalization)的效果。然而(由于采用了梯度平方的移动平均)又克服了Adagrad的缺点。
5.3 Adam
Adam 有点像 RMSProp 与动量方法的结合,其(简化的)更新方法如下所示:
m = beta1*m + (1-beta1)*dx
v = beta2*v + (1-beta2)*(dx**2)
x += - learning_rate * m / (np.sqrt(v) + eps)
注意其最后更新的表达式与RMSprop完全相同,差异在于用梯度的平滑滤波m替代了原始的(hence maybe noisy)梯度向量 dx. 论文中关于各参数的推荐值分别为 eps = 1e-8, beta1 = 0.9, beta2 = 0.999。
实际上,现在Adam几乎被当作缺省的算法使用,其效果通常略优于RMSprop。当然, SGD+Nesterov Momentum通常也只是一试( as an alternative)。
完整版的 Adam 还包含一项 bias correction 机制,它主要用于最初几步的补偿,因为这些参数最初都是初始化为0,需要一段时间的预热( “warm up”)才能到达正常幅度水平。包含 bias correction 机制的完全Adam更新方法如下所示:
# t is your iteration counter going from 1 to infinity
m = beta1*m + (1-beta1)*dx
mt = m / (1-beta1**t)
v = beta2*v + (1-beta2)*(dx**2)
vt = v / (1-beta2**t)
x += - learning_rate * mt / (np.sqrt(vt) + eps)
需要注意到,以上更新方法中引入了时间参数(iteration次数)。
Additional References:
- Unit Tests for Stochastic Optimization proposes a series of tests as a standardized benchmark for stochastic optimization.
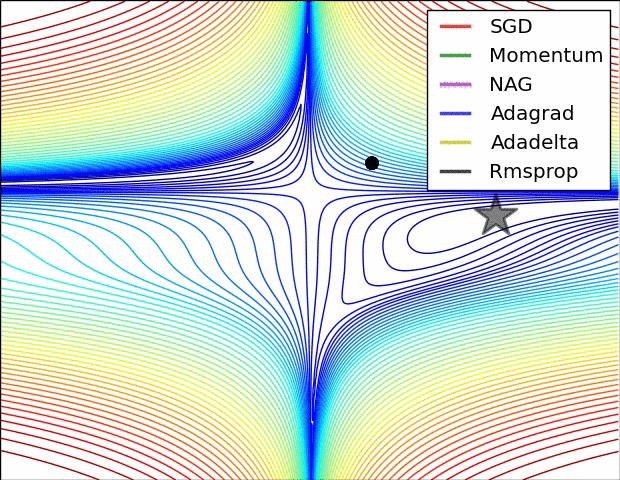
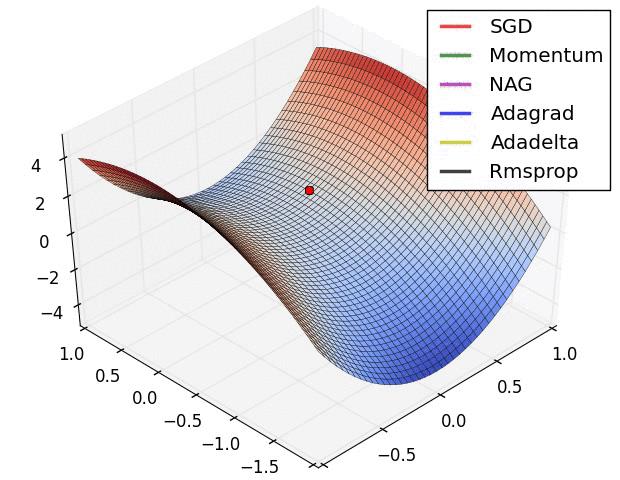
Animations that may help your intuitions about the learning process dynamics. Left: Contours of a loss surface and time evolution of different optimization algorithms. Notice the "overshooting" behavior of momentum-based methods, which make the optimization look like a ball rolling down the hill. Right: A visualization of a saddle point in the optimization landscape, where the curvature along different dimension has different signs (one dimension curves up and another down). Notice that SGD has a very hard time breaking symmetry and gets stuck on the top. Conversely, algorithms such as RMSprop will see very low gradients in the saddle direction. Due to the denominator term in the RMSprop update, this will increase the effective learning rate along this direction, helping RMSProp proceed. Images credit: Alec Radford.
另参见:
CS231n-2022 Module1: 神经网络1:Setting Up the Architecture
CS231n-2022 Module1: 神经网络3:Learning之梯度检查
以上是关于CS231n-2022 Module1: 神经网络3:Learning之参数更新的主要内容,如果未能解决你的问题,请参考以下文章