Java集合遍历方式(for循环与stream()&forEach())比较
Posted 袋鼠先森
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java集合遍历方式(for循环与stream()&forEach())比较相关的知识,希望对你有一定的参考价值。
【说在前面:本文我们先搞清楚Lambda的底层原理,然后基于底层原理再分析得出结论】
本文基于以下问题:
- Collection.forEach()
- Collection.stream().forEach()
- for 循环
以上三种集合遍历方式有什么区别?
Collection.forEach() 和 for( Item item: Connectionx) 都是迭代器的语法糖,单纯就循环执行效率上没有什么区别,forEach传入lambda表达式函数,for循环正常写过程代码。
所以以上问题实际上对比的是:Lambda表达式和直接过程函数(或内部类)的区别;迭代器循环和stream的区别。
要搞清楚上面两个问题,我们首先来回答下Lambda表达式是怎样执行的:
Lambda
Lambda到底是不是语法糖?
如果你只是想要一个简单的答案,那么可惜了,这个答案还真不简单,回答是或者不是都有道理。
下面我们看一下Lambda表达式的实现原理:
测试代码:以下是一个简单Lambda表达式代码:
public class TestLambda
public static void main(String[] args)
List<String> stringList = new ArrayList<>();
stringList.add("str1");
stringList.add("str2");
stringList.forEach(str -> System.out.println(str));
new Thread(
() -> System.out.println("Thread run()")
).start();
javap -c -p TestLambda.class 反编译一下:
public class TestLambda
public TestLambda();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: new #2 // class java/util/ArrayList
3: dup
4: invokespecial #3 // Method java/util/ArrayList."<init>":()V
7: astore_1
8: aload_1
9: ldc #4 // String str1
11: invokeinterface #5, 2 // InterfaceMethod java/util/List.add:(Ljava/lang/Object;)Z
16: pop
17: aload_1
18: ldc #6 // String str2
20: invokeinterface #5, 2 // InterfaceMethod java/util/List.add:(Ljava/lang/Object;)Z
25: pop
26: aload_1
27: invokedynamic #7, 0 // InvokeDynamic #0:accept:()Ljava/util/function/Consumer;
32: invokeinterface #8, 2 // InterfaceMethod java/util/List.forEach:(Ljava/util/function/Consumer;)V
37: new #9 // class java/lang/Thread
40: dup
41: invokedynamic #10, 0 // InvokeDynamic #1:run:()Ljava/lang/Runnable;
46: invokespecial #11 // Method java/lang/Thread."<init>":(Ljava/lang/Runnable;)V
49: invokevirtual #12 // Method java/lang/Thread.start:()V
52: return
private static void lambda$main$1();
Code:
0: getstatic #13 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #14 // String Thread run()
5: invokevirtual #15 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
private static void lambda$main$0(java.lang.String);
Code:
0: getstatic #13 // Field java/lang/System.out:Ljava/io/PrintStream;
3: aload_0
4: invokevirtual #15 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
7: return
反编译后可以看到Lambda表达式被封装成了主类的一个私有方法,并通过invokedynamic指令进行调用。
由于lambdab表达式与匿名内部类有这诸多渊源,特别是idea经常提示将匿名内部类转换为lambda,很多人认为lambda是函数式接口内名内部类实现的语法糖,这种理解是错误的。
从另一个角度分析我们再来继续分析下Lambda这种语法糖的幕后到底是什么?
JDK7 (JSR-292) 引入的 3 个 features;
+ MethodHandle
+ invokedynamic
+ VM Anonymous Class
MethodHandle
用一个示例展示一下用法:
import org.apache.commons.lang3.RandomUtils;
public class MethodHandleTest
static class ClassA
public void println(String s)
System.out.println("Hi, " + s + ", I'm ClassA");
static class ClassB
public void println(String s)
System.out.println("Hi, " + s + ", I'm ClassB");
public static void main(String[] args) throws Throwable
Object obj = RandomUtils.nextInt(0, 100) % 2 == 0 ? new ClassA()
: new ClassB();
getPrintlnMH(obj).invokeExact("MethodHandle");
private static MethodHandle getPrintlnMH(Object obj) throws Throwable
MethodType mt = MethodType.methodType(void.class, String.class);
return MethodHandles.lookup().findVirtual(obj.getClass(), "println", mt).bindTo(obj);
执行一个println方法,实际执行的代码并不干线obj的具体类型,只要实现了这个"println"防范就能够被调用;看到这里会想到这不就是Java的反射么?的确MethodHandle与Reflection实现的功能有很多相似的地方,都是运行时解析方法调用,但是他们之间有着本质的区别;
MethodHandle与Reflection都可以分派方法调用,但是MethodHandle比Reflection更强大,他是模拟字节层次的方法分派;MethodHandle.Lookup提供了findStatic、findVirtual、findSpecial三个方法(后续有机会单独写文章介绍下 虚分派)
MethodHandle是结合invokedynamic指令一起为动态语言服务的,可以说MethodHandle是服务于所有运行与JVM上的语言,而Reflection则只适用于Java语言本身。
invokedynamic
invokedynamic在字节码层面实现了MethodHandle的功能。对比之前 java 字节码所有的方法分派均依赖于单纯的符号引用,即在编译生成的.class字节码文件中,4条方法调用指令(invokevirtual、invokespecial、invokestatic、invokeinterface)后面跟的操作数均为明确的CONSTANT_Methodref_info 或 CONSTANT_InterfaceMethodref_info 常量池符号引用,这就意味着在编译期就提前把方法调用绑定到了某类型及其子类型,如下图是源码System.out.println("Hello")和编译后字节码对比截图:

实现了println (Ljava/lang/String;)V方法的类必须是java/io/PrintStream的子类;但是对于动态语言来说,编译期间是不关心这个类是什么类型的,于是便新增了 invokedynamic 方法分派指令,该指令所在的位置被称为 "动态调用点"(Dynamic Call Site);下面我们简单分析下 invokedynamic 指令;
之前提到原有的4条方法分配指令 invokevirtual、invokespecial、invokestatic、invokeinterface 的操作数类型是 CONSTANT_Methodref_info 或 CONSTANT_InterfaceMethodref_info;在 invokedynamic 则换成了 CONSTANT_InvokeDynamic_info;我们抛开这些概念上的定义,本质上 invokedynamic 后面跟着三个参数,分别是引导方法(Bootstrap Method), 调用的方法签名,调用的方法名称;Bootstrap Method 根据方法名称和方法签名返回运行时调用点(Call Site)。
+ Bootstrap Method 由编译器自身指定,包括参数;
+ Bootstrap Method 职责是返回运行时真正的调用点 Call Site;至于 Call Site 如何产生,JVM 是不关心的,那是 Bootstrap Method 负责去做的,只要符合调用要求就行;
VM Anonymous Class
一般意义上的匿名类本质上和普通类没什么区别,需要 ClassLoader 去加载、字节码安全验证、管理访问权限、链接,类初始化;当然匿名类也并不匿名,它有自己的类名,通过 Class.forName 可以索引到对应的 Class;在动态语言中,单纯为了执行一段代码,却要额外做这么多操作显然是不能忍受的,所以在 JDK7 中引入了 VM Anonymous Class 这一真正意义上的匿名类;不需要 ClassLoader 加载,没有类名,当然也没其他权限管理等操作,这意味着效率更高(不必要的锁操作)、GC 更方便(没有 ClassLoader);VM Anonymous Class 通过调用sun.misc.Unsafe.defineAnonymousClass 生成;
Lambda的底层实现
在设计 Lambda 表达式的解析方案时,主要考虑下面两点:
+ 可扩展性,不把解析方案写死在字节码上;
+ 解析 Lambda 表达式后,对字节码文件干扰尽量降到最低,起码保证一定的可读性;
正式基于以上两点考虑, invokedynamic 指令被运用到解析 Lambda 表达式;优势如下:
+ 字节码表示简单,利用 invokedynamic 指令本身的特性(引导方法),把 Lambda 表达式在字节码文件的表示和真正的解析分离;
+ Lambda 表达式的链接解析发生运行期而非编译期,由 invokedynamic 的引导方法执行,扩展性强;
Lambda 是面向方法接口编程,其实我更多认为是JDK8 提供的语法糖; 因为对非方法引用的 lambda 表达式,编译器都会为其生成一个方法实现 lambda 表达式的逻辑(即为上文中所提到的私有方法),并出现在编译后的字节码文件中;这个方法的生成是 Lambda 表达式解析的关键;
编译器为 Lambda 表达式都生成了一个方法,但是细心的同学会发现,虽然都是实现函数式接口,但是最后生成的方法区别很大,不仅static/非static,而且参数类型都不一样,这是为什么呢?Lambda 表达式的解析分成三个阶段:
+ 链接阶段, 负责生成动态调用点;
+ 变量捕获,闭包中的变量访问;
+ Lambda 表达式调用;
之所以造成上面同一个函数接口生成的方法(desugaring method)不一致,是因为变量捕获不一样导致的;
+ 最终生成desugaring method 的参数列表是函数接口方法参数列表加上变量捕获列表;
+ 如果在lambda表达式中使用到了enclosing class 实例(比如this, super, 或者其实例变量),那么最终的 desugaring method 则是private 实例方法;否则是private 静态方法;
上面提到了 Lambda 表达式的解析分成三个阶段, 链接阶段由invokedynamic指令后面跟随的Bootstrap Method 引导方法完成,生成动态调用点;我们先来看 Lambda 表达式解析用的最多的一个引导方法 java.lang.invoke.LambdaMetafactory#metafactory:
public static CallSite metafactory(MethodHandles.Lookup caller,
String invokedName,
MethodType invokedType,
MethodType samMethodType,
MethodHandle implMethod,
MethodType instantiatedMethodType)
throws LambdaConversionException
AbstractValidatingLambdaMetafactory mf;
mf = new InnerClassLambdaMetafactory(caller, invokedType,
invokedName, samMethodType,
implMethod, instantiatedMethodType,
false, EMPTY_CLASS_ARRAY, EMPTY_MT_ARRAY);
mf.validateMetafactoryArgs();
return mf.buildCallSite();
该启动方法以及参数都是编译器指定,下面来解释下这几个参数的含义:
+ caller 参考前面提到的 MethodHandle,lookupClass 指向 enclosing object
+ invokedName 需要实现的函数式接口方法名
+ invokedType 变量捕获列表
+ samMethodType 需要实现的函数式接口方法签名(sam 是 single abstract method )
+ implMethod 指向生成的 desugaring method
+ instantiatedMethodType 对应运行时 sam 的方法签名,运行时签名验证,在非泛型情况下,和samMethodType相同;比如下面代码中,samMethodType是(Ljava/lang/Object)V, instantiatedMethodType则是(Ljava/lang/String)V;
引导方法 metaMethod 根据这些参数生成 java.lang.invoke.CallSite 动态调用点对象支持 Lambda 表达式的调用执行。在引导方法中会动态生成一个模板匿名类,查看这个类的字节码可以通过加上 -Djdk.internal.lambda.dumpProxyClasses 参数指定dump的目录;该匿名是一个模板类,其特点如下:
+ 实现函数式接口,内部逻辑很简单,调用上面提到的脱糖方法(desugaring method)
+ 生成一个构造方法, 构造方法参数为被捕获参数变量,所有变量存储为类实例变量
+ 如果被捕获参数变量列表不为空, 则会生成一个工厂方法 get$lambad,方法签名和构造方法相同;该工厂方法的作用是避免重复调用asm生成匿名类字节码,提升性能;在下一节的性能分析中会提到这个方法的作用;
性能分析
参考 http://www.oracle.com/technetwork/java/jvmls2013kuksen-2014088.pdf
这是13年官方给出的lambda和普通匿名类的性能对比分析;性能差异主要体现在链接阶段,文章中提到的 lambda 冷启动和热启动;所谓热启动是包括生成匿名类字节码并生成class的过程,热启动是比匿名类稍微差点,对相同ambda表达式来说,热启动过程只发生一次,后面都是调用工厂方法即可;直接调用已有的匿名类称之为冷启动,他的性能接近为匿名类的100倍。
Lambda总结
以上这些,我们可以做个总结了:
+ 对于非方法引用 Lambda 表达式,编译器都会生成对应的 desugaring method;
+ desugaring method 参数列表是接口方法参数列表加上变量捕获列表
+ 变量捕获由虚拟机提供,是闭包访问变量的基础;闭包变量分为两种,instance-capturing 和 non-instance-capturing,如果在lambda中使用了 enclosing object 实例(比如this, super, 或者其实例变量),desugaring method 是私有实例方法,否则是私有静态方法;
+ invokedynamic 和 lambda 的实现并没有因果关系,lambda的解析可以不依赖invokdynamic指令,之所以采用该指令,考虑到以下两点:
+ 可扩展性强,lambda解析方案放在引导方法运行时执行,而不是编译器写在 class 文件中;
+ 对class文件干扰尽量降到最低,字节码简单,可读性强;
- 引导方法 java.lang.invoke.LambdaMetafactory#metaFactory 动态生成一个虚拟机级别的匿名模板类(VM Anonymous Class),在改匿名类中定义了和函数接口方法签名相同的方法, 方法体则是调用 desugaring method 方法;比较特殊的是该匿名类是真正意义上的匿名类,不需要 ClassLoader 加载,直接通过sun.misc.Unsafe#defineAnonymousClass 加载,较普通匿名类有以下优点:
-
- 效率更高,没有类加载、字节码安全验证、管理访问权限、链接,类初始化等一系列(锁)操作;
- GC 更友好,不涉及任何ClassLoader;
- lambda 引导方法动态生成一个匿名类字节码,这个匿名类有如下特点:
-
- 实现函数式接口,内部逻辑调用脱糖方法(desugaring method)
- 包含一个构造方法, 构造方法参数为被捕获参数变量,所有变量存储为类实例变量
- 如果捕获参数变量列表不为空, 则会生成一个工厂方法 get$lambad,方法签名和构造方法相同;该工厂方法的作用是避免重复调用asm生成匿名类字节码,提升性能;
Stream
Stream与loop对比结论:

我们先报结论摆出来,collections的直接操作有更好的性能,特别是小集合场景下。Streams拥有更好的编码风格和可理解程度。
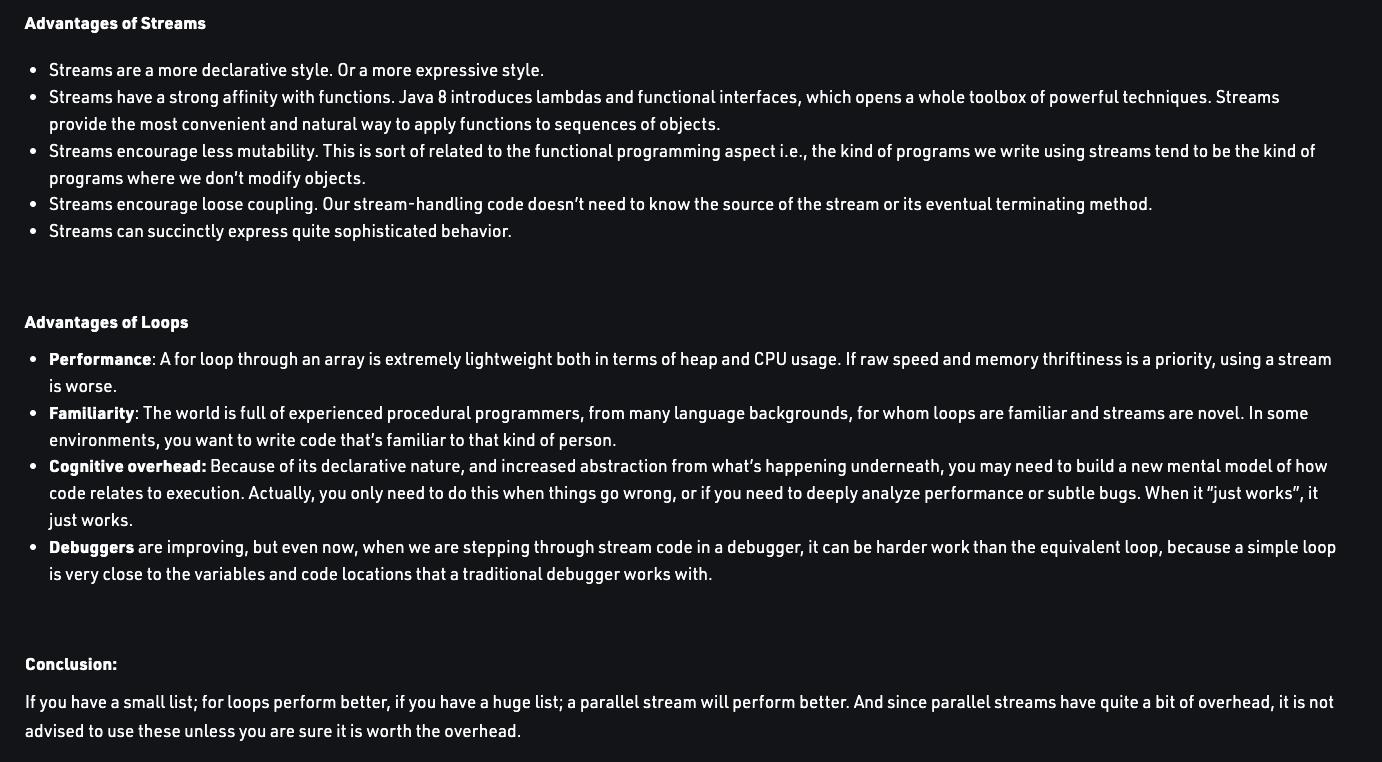
Comparing Streams to Loops in Java - GeeksforGeeks
下面我们详细讲解下Stream,感兴趣的同学可以继续阅读。

理解Stream我们更关心的是另外两个问题:流水线和自动并行。
虽然大部分情况下stream是容器调用Collection.stream()方法得到的,但stream和collections有以下不同:
- 无存储。stream不是一种数据结构,它只是某种数据源的一个视图,数据源可以是一个数组,Java容器或I/O channel等。
- 为函数式编程而生。对stream的任何修改都不会修改背后的数据源,比如对stream执行过滤操作并不会删除被过滤的元素,而是会产生一个不包含被过滤元素的新stream。
- 惰式执行。stream上的操作并不会立即执行,只有等到用户真正需要结果的时候才会执行。
- 可消费性。stream只能被“消费”一次,一旦遍历过就会失效,就像容器的迭代器那样,想要再次遍历必须重新生成。
对stream的操作分为为两类,中间操作(intermediate operations)和结束操作(terminal operations),二者特点是:
- 中间操作总是会惰式执行,调用中间操作只会生成一个标记了该操作的新stream,仅此而已。
- 结束操作会触发实际计算,计算发生时会把所有中间操作积攒的操作以pipeline的方式执行,这样可以减少迭代次数。计算完成之后stream就会失效。
下表汇总了Stream接口的部分常见方法:
| 操作类型 | 接口方法 |
| 中间操作 | concat() distinct() filter() flatMap() limit() map() peek() |
| 结束操作 | allMatch() anyMatch() collect() count() findAny() findFirst() |
区分中间操作和结束操作最简单的方法,就是看方法的返回值,返回值为stream的大都是中间操作,否则是结束操作。
stream方法使用
stream跟函数接口关系非常紧密,没有函数接口stream就无法工作。回顾一下:函数接口是指内部只有一个抽象方法的接口。通常函数接口出现的地方都可以使用Lambda表达式,所以不必记忆函数接口的名字。
forEach()
我们对forEach()方法并不陌生,在Collection中我们已经见过。方法签名为void forEach(Consumer<? super E> action),作用是对容器中的每个元素执行action指定的动作,也就是对元素进行遍历。
// 使用Stream.forEach()迭代
Stream<String> stream = Stream.of("I", "love", "you", "too"); stream.forEach(str -> System.out.println(str));
由于forEach()是结束方法,上述代码会立即执行,输出所有字符串。
filter()
函数原型为Stream<T> filter(Predicate<? super T> predicate),作用是返回一个只包含满足predicate条件元素的Stream。
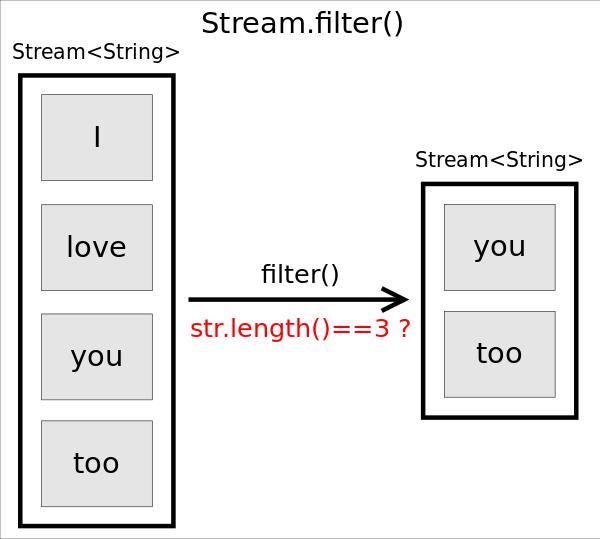
// 保留长度等于3的字符串
Stream<String> stream= Stream.of("I", "love", "you", "too"); stream.filter(str -> str.length()==3) .forEach(str -> System.out.println(str));
上述代码将输出为长度等于3的字符串you和too。注意,由于filter()是个中间操作,如果只调用filter()不会有实际计算,因此也不会输出任何信息。
map()
函数原型为<R> Stream<R> map(Function<? super T,? extends R> mapper),作用是返回一个对当前所有元素执行执行mapper之后的结果组成的Stream。直观的说,就是对每个元素按照某种操作进行转换,转换前后Stream中元素的个数不会改变,但元素的类型取决于转换之后的类型。

Stream<String> stream = Stream.of("I", "love", "you", "too"); stream.map(str -> str.toUpperCase()) .forEach(str -> System.out.println(str));
上述代码将输出原字符串的大写形式。
flatMap()
函数原型为<R> Stream<R> flatMap(Function<? super T,? extends Stream<? extends R>> mapper),作用是对每个元素执行mapper指定的操作,并用所有mapper返回的Stream中的元素组成一个新的Stream作为最终返回结果。说起来太拗口,通俗的讲flatMap()的作用就相当于把原stream中的所有元素都"摊平"之后组成的Stream,转换前后元素的个数和类型都可能会改变。

Stream<List<Integer>> stream = Stream.of(Arrays.asList(1,2), Arrays.asList(3, 4, 5));
stream.flatMap(list -> list.stream())
.forEach(i -> System.out.println(i));
上述代码中,原来的stream中有两个元素,分别是两个List<Integer>,执行flatMap()之后,将每个List都“摊平”成了一个个的数字,所以会新产生一个由5个数字组成的Stream。所以最终将输出1~5这5个数字。
reduce()
规约操作(reduction operation)又被称作折叠操作(fold),是通过某个连接动作将所有元素汇总成一个汇总结果的过程。元素求和、求最大值或最小值、求出元素总个数、将所有元素转换成一个列表或集合,都属于规约操作。Stream类库有两个通用的规约操作reduce()和collect(),也有一些为简化书写而设计的专用规约操作,比如sum()、max()、min()、count()等。
最大或最小值这类规约操作很好理解(至少方法语义上是这样),我们着重介绍reduce()和collect(),这是比较有魔法的地方。
reduce操作可以实现从一组元素中生成一个值,sum()、max()、min()、count()等都是reduce操作,将他们单独设为函数只是因为常用。reduce()的方法定义有三种重写形式:
- Optional<T> reduce(BinaryOperator<T> accumulator)
- T reduce(T identity, BinaryOperator<T> accumulator)
- <U> U reduce(U identity, BiFunction<U,? super T,U> accumulator, BinaryOperator<U> combiner)
虽然函数定义越来越长,但语义不曾改变,多的参数只是为了指明初始值(参数identity),或者是指定并行执行时多个部分结果的合并方式(参数combiner)。reduce()最常用的场景就是从一堆值中生成一个值。用这么复杂的函数去求一个最大或最小值,你是不是觉得设计者有病。其实不然,因为“大”和“小”或者“求和"有时会有不同的语义。
需求:从一组单词中找出最长的单词。这里“大”的含义就是“长”。
// 找出最长的单词
Stream<String> stream = Stream.of("I", "love", "you", "too");
Optional<String> longest = stream.reduce((s1, s2) -> s1.length()>=s2.length() ? s1 : s2);
System.out.println(longest.get());
上述代码会选出最长的单词love,其中Optional是(一个)值的容器,使用它可以避免null 值的麻烦。
collect()
不夸张的讲,如果你发现某个功能在Stream接口中没找到,十有八九可以通过collect()方法实现。collect()是Stream接口方法中最灵活的一个,学会它才算真正入门Java函数式编程。先看几个热身的小例子:
// 将Stream转换成容器或Map
Stream<String> stream = Stream.of("I", "love", "you", "too");
List<String> list = stream.collect(Collectors.toList()); // (1) //
Set<String> set = stream.collect(Collectors.toSet()); // (2) //
Map<String, Integer> map = stream.collect(Collectors.toMap(Function.identity(), String::length)); // (3)
上述代码分别列举了如何将Stream转换成List、Set和Map。虽然代码语义很明确,可是我们仍然会有几个疑问:
- Function.identity()是干什么的?
- String::length是什么意思?
- Collectors是个什么东西?
接口的静态方法和默认方法
Function是一个接口,那么Function.identity()是什么意思呢?这要从两方面解释:
-
- Java 8允许在接口中加入具体方法。接口中的具体方法有两种,default方法和static方法,identity()就是Function接口的一个静态方法。
- Function.identity()返回一个输出跟输入一样的Lambda表达式对象,等价于形如t -> t形式的Lambda表达式。
方法引用
诸如String::length的语法形式叫做方法引用(method references),这种语法用来替代某些特定形式Lambda表达式。如果Lambda表达式的全部内容就是调用一个已有的方法,那么可以用方法引用来替代Lambda表达式。方法引用可以细分为四类:
| 方法引用类别 | 举例 |
| 引用静态方法 | Integer::sum |
| 引用某个对象的方法 | list::add |
| 引用某个类的方法 | String::length |
| 引用构造方法 | HashMap::new |
我们会在后面的例子中使用方法引用。
收集器
收集器(Collector)是为Stream.collect()方法量身打造的工具接口(类)。考虑一下将一个Stream转换成一个容器(或者Map)需要做哪些工作?我们至少需要两样东西:
-
- 目标容器是什么?是ArrayList还是HashSet,或者是个TreeMap。
- 新元素如何添加到容器中?是List.add()还是Map.put()。
- 多个部分结果如何合并成一个。(如果并行的进行规约,还需要告诉collect() )
结合以上分析,collect()方法定义为<R> R collect(Supplier<R> supplier, BiConsumer<R,? super T> accumulator, BiConsumer<R,R> combiner),三个参数依次对应上述三条分析。不过每次调用collect()都要传入这三个参数太麻烦,收集器Collector就是对这三个参数的简单封装,所以collect()的另一定义为<R,A> R collect(Collector<? super T,A,R> collector)。Collectors工具类可通过静态方法生成各种常用的Collector。举例来说,如果要将Stream规约成List可以通过如下两种方式实现:

// 将Stream规约成List
Stream<String> stream = Stream.of("I", "love", "you", "too");
List<String> list = stream.collect(ArrayList::new, ArrayList::add, ArrayList::addAll);// 方式1
//List<String> list = stream.collect(Collectors.toList());// 方式2
System.out.println(list);
通常情况下我们不需要手动指定collect()的三个参数,而是调用collect(Collector<? super T,A,R> collector)方法,并且参数中的Collector对象大都是直接通过Collectors工具类获得。实际上传入的收集器的行为决定了collect()的行为。
使用collect()生成Collection
前面已经提到通过collect()方法将Stream转换成容器的方法,这里再汇总一下。将Stream转换成List或Set是比较常见的操作,所以Collectors工具已经为我们提供了对应的收集器,通过如下代码即可完成:
// 将Stream转换成List或Set
Stream<String> stream = Stream.of("I", "love", "you", "too");
List<String> list = stream.collect(Collectors.toList()); // (1)
Set<String> set = stream.collect(Collectors.toSet()); // (2)
上述代码能够满足大部分需求,但由于返回结果是接口类型,我们并不知道类库实际选择的容器类型是什么,有时候我们可能会想要人为指定容器的实际类型,这个需求可通过Collectors.toCollection(Supplier<C> collectionFactory)方法完成。
// 使用toCollection()指定规约容器的类型
ArrayList<String> arrayList = stream.collect(Collectors.toCollection(ArrayList::new));// (3)
HashSet<String> hashSet = stream.collect(Collectors.toCollection(HashSet::new));// (4)
上述代码(3)处指定规约结果是ArrayList,而(4)处指定规约结果为HashSet。一切如你所愿。
使用collect()生成Map
前面已经说过Stream背后依赖于某种数据源,数据源可以是数组、容器等,但不能是Map。反过来从Stream生成Map是可以的,但我们要想清楚Map的key和value分别代表什么,根本原因是我们要想清楚要干什么。通常在三种情况下collect()的结果会是Map:
-
- 使用Collectors.toMap()生成的收集器,用户需要指定如何生成Map的key和value。
- 使用Collectors.partitioningBy()生成的收集器,对元素进行二分区操作时用到。
- 使用Collectors.groupingBy()生成的收集器,对元素做group操作时用到。
情况1:使用toMap()生成的收集器,这种情况是最直接的,前面例子中已提到,这是和Collectors.toCollection()并列的方法。如下代码展示将学生列表转换成由<学生,GPA>组成的Map。
非常直观,无需多言。
// 使用toMap()统计学生GPA
Map<Student, Double> studentToGPA = students.stream().collect(Collectors.toMap(Function.identity(),// 如何生成key
student -> computeGPA(student)));// 如何生成value
情况2:使用partitioningBy()生成的收集器,这种情况适用于将Stream中的元素依据某个二值逻辑(满足条件,或不满足)分成互补相交的两部分,比如男女性别、成绩及格与否等。下列代码展示将学生分成成绩及格或不及格的两部分。
// Partition students into passing and failing
Map<Boolean, List<Student>> passingFailing = students.stream()
.collect(Collectors.partitioningBy(s -> s.getGrade() >= PASS_THRESHOLD));
情况3:使用groupingBy()生成的收集器,这是比较灵活的一种情况。跟SQL中的group by语句类似,这里的groupingBy()也是按照某个属性对数据进行分组,属性相同的元素会被对应到Map的同一个key上。下列代码展示将员工按照部门进行分组:
// Group employees by department
Map<Department, List<Employee>> byDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment));
以上只是分组的最基本用法,有些时候仅仅分组是不够的。在SQL中使用group by是为了协助其他查询,比如1. 先将员工按照部门分组,2. 然后统计每个部门员工的人数。Java类库设计者也考虑到了这种情况,增强版的groupingBy()能够满足这种需求。增强版的groupingBy()允许我们对元素分组之后再执行某种运算,比如求和、计数、平均值、类型转换等。这种先将元素分组的收集器叫做上游收集器,之后执行其他运算的收集器叫做下游收集器(downstream Collector)。
// 使用下游收集器统计每个部门的人数
Map<Department, Integer> totalByDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment,
Collectors.counting()));// 下游收集器
上面代码的逻辑是不是越看越像SQL?高度非结构化。还有更狠的,下游收集器还可以包含更下游的收集器,这绝不是为了炫技而增加的把戏,而是实际场景需要。考虑将员工按照部门分组的场景,如果我们想得到每个员工的名字(字符串),而不是一个个Employee对象,可通过如下方式做到:
// 按照部门对员工分布组,并只保留员工的名字
Map<Department, List<String>> byDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment,
Collectors.mapping(Employee::getName,// 下游收集器
Collectors.toList())));// 更下游的收集器
如果看到这里你还没有对Java函数式编程失去信心,恭喜你,你已经顺利成为Java函数式编程大师了。
Stream Pipelines
前面我们已经学会如何使用Stream API,用起来真的很爽,但简洁的方法下面似乎隐藏着无尽的秘密,如此强大的API是如何实现的呢?比如Pipeline是怎么执行的,每次方法调用都会导致一次迭代吗?自动并行又是怎么做到的,线程个数是多少?本节我们学习Stream流水线的原理,这是Stream实现的关键所在。
Stream API中大量使用Lambda表达式作为回调方法,但这并不是关键。理解Stream我们更关心的是另外两个问题:流水线和自动并行。使用Stream或许很容易写入如下形式的代码:
int longestStringLengthStartingWithA
= strings.stream()
.filter(s -> s.startsWith("A"))
.mapToInt(String::length)
.max();
上述代码求出以字母A开头的字符串的最大长度,一种直白的方式是为每一次函数调用都执一次迭代,这样做能够实现功能,但效率上肯定是无法接受的。类库的实现着使用流水线(Pipeline)的方式巧妙的避免了多次迭代,其基本思想是在一次迭代中尽可能多的执行用户指定的操作。为讲解方便我们汇总了Stream的所有操作。
| Stream操作分类 | ||
| 中间操作 (Intermediate operations) | 无状态(Stateless) | unordered() filter() map() mapToInt() mapToLong() mapToDouble() flatMap() flatMapToInt() flatMapToLong() flatMapToDouble() peek() |
| 有状态(Stateful) | distinct() sorted() sorted() limit() skip() | |
| 结束操作 (Terminal operations) | 非短路操作 | forEach() forEachOrdered() toArray() reduce() collect() max() min() count() |
| 短路操作(short-circuiting) | anyMatch() allMatch() noneMatch() findFirst() findAny() | |
Stream上的所有操作分为两类:中间操作和结束操作,中间操作只是一种标记,只有结束操作才会触发实际计算。中间操作又可以分为无状态的(Stateless)和有状态的(Stateful),无状态中间操作是指元素的处理不受前面元素的影响,而有状态的中间操作必须等到所有元素处理之后才知道最终结果,比如排序是有状态操作,在读取所有元素之前并不能确定排序结果;结束操作又可以分为短路操作和非短路操作,短路操作是指不用处理全部元素就可以返回结果,比如找到第一个满足条件的元素。之所以要进行如此精细的划分,是因为底层对每一种情况的处理方式不同。 为了更好的理解流的中间操作和终端操作,可以通过下面的两段代码来看他们的执行过程。
IntStream.range(1, 10)
.peek(x -> System.out.print("\\nA" + x))
.limit(3)
.peek(x -> System.out.print("B" + x))
.forEach(x -> System.out.print("C" + x));
输出为: A1B1C1 A2B2C2 A3B3C3。
中间操作是懒惰的,也就是中间操作不会对数据做任何操作,直到遇到了最终操作。而最终操作,都是比较热情的。他们会往前回溯所有的中间操作。也就是当执行到最后的forEach操作的时候,它会回溯到它的上一步中间操作,上一步中间操作,又会回溯到上上一步的中间操作,...,直到最初的第一步。 第一次forEach执行的时候,会回溯peek 操作,然后peek会回溯更上一步的limit操作,然后limit会回溯更上一步的peek操作,顶层没有操作了,开始自上向下开始执行,输出:A1B1C1
第二次forEach执行的时候,然后会回溯peek 操作,然后peek会回溯更上一步的limit操作,然后limit会回溯更上一步的peek操作,顶层没有操作了,开始自上向下开始执行,输出:A2B2C2...
当第四次forEach执行的时候,然后会回溯peek 操作,然后peek会回溯更上一步的limit操作,到limit的时候,发现limit(3)这个job已经完成,这里就相当于循环里面的break操作,跳出来终止循环。
再来看第二段代码:
IntStream.range(1, 10)
.peek(x -> System.out.print("\\nA" + x))
.skip(6)
.peek(x -> System.out.print("B" + x))
.forEach(x -> System.out.print("C" + x));
输出为: A1 A2 A3 A4 A5 A6 A7B7C7 A8B8C8 A9B9C9。
第一次forEach执行的时候,会回溯peek操作,然后peek会回溯更上一步的skip操作,skip回溯到上一步的peek操作,顶层没有操作了,开始自上向下开始执行,执行到skip的时候,因为执行到skip,这个操作的意思就是跳过,下面的都不要执行了,也就是就相当于循环里面的continue,结束本次循环。输出:A1
第二次forEach执行的时候,会回溯peek操作,然后peek会回溯更上一步的skip操作,skip回溯到上一步的peek操作,顶层没有操作了,开始自上向下开始执行,执行到skip的时候,发现这是第二次skip,结束本次循环。输出:A2
...
第七次forEach执行的时候,会回溯peek操作,然后peek会回溯更上一步的skip操作,skip回溯到上一步的peek操作,顶层没有操作了,开始自上向下开始执行,执行到skip的时候,发现这是第七次skip,已经大于6了,它已经执行完了skip(6)的job了。这次skip就直接跳过,继续执行下面的操作。输出:A7B7C7
...
直到循环结束。
设想一种直白的pipeline实现方式
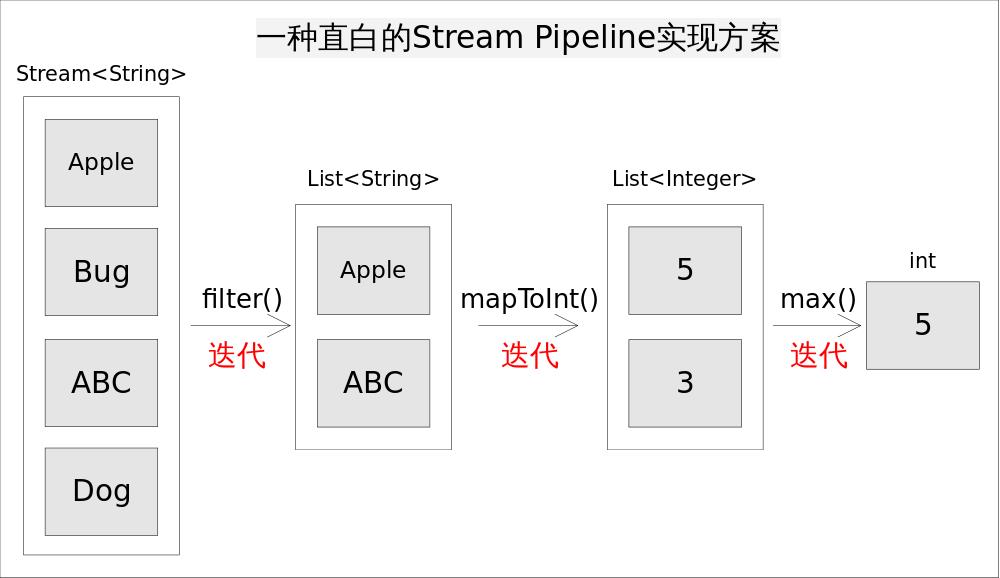
仍然考虑上述求最长字符串的程序,一种直白的流水线实现方式是为每一次函数调用都执一次迭代,并将处理中间结果放到某种数据结构中(比如数组,容器等)。具体说来,就是调用filter()方法后立即执行,选出所有以A开头的字符串并放到一个列表list1中,之后让list1传递给mapToInt()方法并立即执行,生成的结果放到list2中,最后遍历list2找出最大的数字作为最终结果。程序的执行流程如如所示:
这样做实现起来非常简单直观,但有两个明显的弊端:
-
- 迭代次数多。迭代次数跟函数调用的次数相等。
- 频繁产生中间结果。每次函数调用都产生一次中间结果,存储开销无法接受。
这些弊端使得效率底下,根本无法接受。如果不使用Stream API我们都知道上述代码该如何在一次迭代中完成,大致是如下形式:
int longest = 0;
for(String str : strings)
if(str.startsWith("A"))// 1. filter(), 保留以A开头的字符串
int len = str.length();// 2. mapToInt(), 转换成长度
longest = Math.max(len, longest);// 3. max(), 保留最长的长度
采用这种方式我们不但减少了迭代次数,也避免了存储中间结果,显然这就是流水线,因为我们把三个操作放在了一次迭代当中。只要我们事先知道用户意图,总是能够采用上述方式实现跟Stream API等价的功能,但问题是Stream类库的设计者并不知道用户的意图是什么。
Stream流水线解决方案
我们大致能够想到,应该采用某种方式记录用户每一步的操作,当用户调用结束操作时将之前记录的操作叠加到一起在一次迭代中全部执行掉。沿着这个思路,有几个问题需要解决:
-
- 用户的操作如何记录?
- 操作如何叠加?
- 叠加之后的操作如何执行?
- 执行后的结果(如果有)在哪里?
操作如何记录

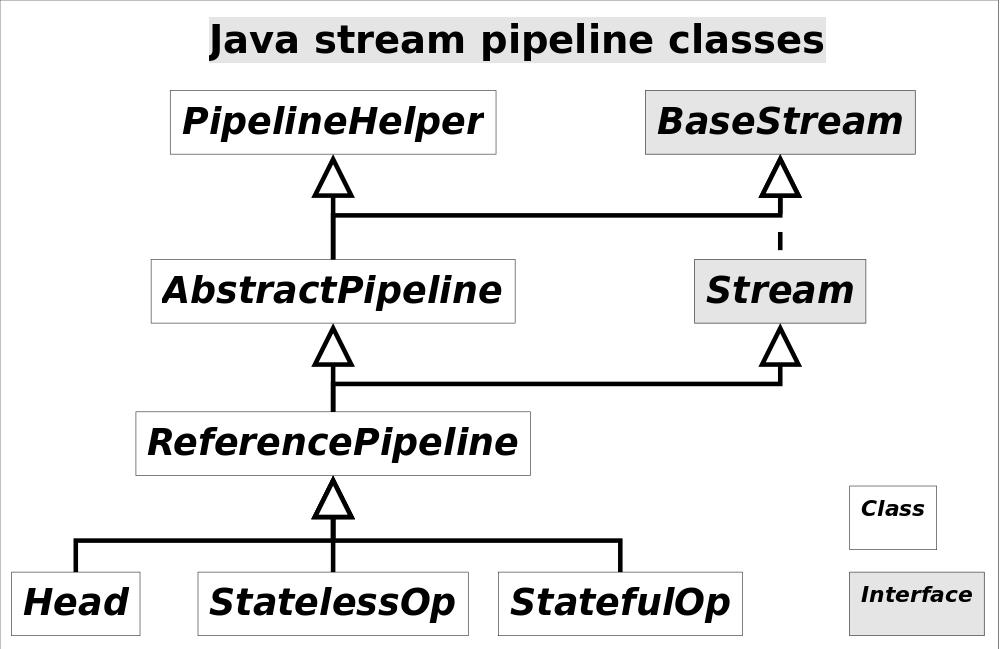
注意这里使用的是“操作(operation)”一词,指的是“Stream中间操作”的操作,很多Stream操作会需要一个回调函数(Lambda表达式),因此一个完整的操作是<数据来源,操作,回调函数>构成的三元组。Stream中使用Stage的概念来描述一个完整的操作,并用某种实例化后的PipelineHelper来代表Stage,将具有先后顺序的各个Stage连到一起,就构成了整个流水线。跟Stream相关类和接口的继承关系图示。
还有IntPipeline, LongPipeline, DoublePipeline没在图中画出,这三个类专门为三种基本类型(不是包装类型)而定制的,跟ReferencePipeline是并列关系。图中Head用于表示第一个Stage,即调用调用诸如Collection.stream()方法产生的Stage,很显然这个Stage里不包含任何操作;StatelessOp和StatefulOp分别表示无状态和有状态的Stage,对应于无状态和有状态的中间操作。
Stream流水线组织结构示意图如下:
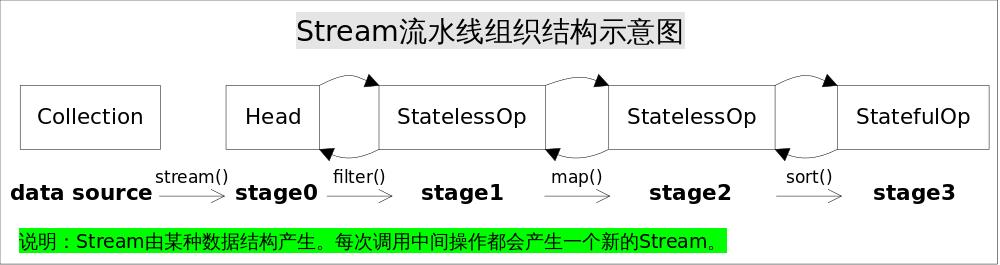
图中通过Collection.stream()方法得到Head也就是stage0,紧接着调用一系列的中间操作,不断产生新的Stream。这些Stream对象以双向链表的形式组织在一起,构成整个流水线,由于每个Stage都记录了前一个Stage和本次的操作以及回调函数,依靠这种结构就能建立起对数据源的所有操作。这就是Stream记录操作的方式。
操作如何叠加
以上只是解决了操作记录的问题,要想让流水线起到应有的作用我们需要一种将所有操作叠加到一起的方案。你可能会觉得这很简单,只需要从流水线的head开始依次执行每一步的操作(包括回调函数)就行了。这听起来似乎是可行的,但是你忽略了前面的Stage并不知道后面Stage到底执行了哪种操作,以及回调函数是哪种形式。换句话说,只有当前Stage本身才知道该如何执行自己包含的动作。这就需要有某种协议来协调相邻Stage之间的调用关系。
这种协议由Sink接口完成,Sink接口包含的方法如下表所示:
| 方法名 | 作用 |
| void begin(long size) | 开始遍历元素之前调用该方法,通知Sink做好准备。 |
| void end() | 所有元素遍历完成之后调用,通知Sink没有更多的元素了。 |
| boolean cancellationRequested() | 是否可以结束操作,可以让短路操作尽早结束。 |
| void accept(T t) | 遍历元素时调用,接受一个待处理元素,并对元素进行处理。Stage把自己包含的操作和回调方法封装到该方法里,前一个Stage只需要调用当前Stage.accept(T t)方法就行了。 |
有了上面的协议,相邻Stage之间调用就很方便了,每个Stage都会将自己的操作封装到一个Sink里,前一个Stage只需调用后一个Stage的accept()方法即可,并不需要知道其内部是如何处理的。当然对于有状态的操作,Sink的begin()和end()方法也是必须实现的。比如Stream.sorted()是一个有状态的中间操作,其对应的Sink.begin()方法可能创建一个盛放结果的容器,而accept()方法负责将元素添加到该容器,最后end()负责对容器进行排序。对于短路操作,Sink.cancellationRequested()也是必须实现的,比如Stream.findFirst()是短路操作,只要找到一个元素,cancellationRequested()就应该返回true,以便调用者尽快结束查找。Sink的四个接口方法常常相互协作,共同完成计算任务。实际上Stream API内部实现的的本质,就是如何重写Sink的这四个接口方法。
有了Sink对操作的包装,Stage之间的调用问题就解决了,执行时只需要从流水线的head开始对数据源依次调用每个Stage对应的Sink.begin(), accept(), cancellationRequested(), end()方法就可以了。一种可能的Sink.accept()方法流程是这样的:
void accept(U u)
1. 使用当前Sink包装的回调函数处理u
2. 将处理结果传递给流水线下游的Sink
Sink接口的其他几个方法也是按照这种[处理->转发]的模型实现。下面我们结合具体例子看看Stream的中间操作是如何将自身的操作包装成Sink以及Sink是如何将处理结果转发给下一个Sink的。先看Stream.map()方法:
// Stream.map(),调用该方法将产生一个新的Stream
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper)
...
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT)
@Override /*opWripSink()方法返回由回调函数包装而成Sink*/
Sink<P_OUT> opWrapSink(int flags, Sink<R> downstream)
return new Sink.ChainedReference<P_OUT, R>(downstream)
@Override
public void accept(P_OUT u)
R r = mapper.apply(u);// 1. 使用当前Sink包装的回调函数mapper处理u
downstream.accept(r);// 2. 将处理结果传递给流水线下游的Sink
;
;
上述代码看似复杂,其实逻辑很简单,就是将回调函数mapper包装到一个Sink当中。由于Stream.map()是一个无状态的中间操作,所以map()方法返回了一个StatelessOp内部类对象(一个新的Stream),调用这个新Stream的opWripSink()方法将得到一个包装了当前回调函数的Sink。
再来看一个复杂一点的例子。Stream.sorted()方法将对Stream中的元素进行排序,显然这是一个有状态的中间操作,因为读取所有元素之前是没法得到最终顺序的。抛开模板代码直接进入问题本质,sorted()方法是如何将操作封装成Sink的呢?sorted()一种可能封装的Sink代码如下:
// Stream.sort()方法用到的Sink实现
class RefSortingSink<T> extends AbstractRefSortingSink<T>
private ArrayList<T> list;// 存放用于排序的元素
RefSortingSink(Sink<? super T> downstream, Comparator<? super T> comparator)
super(downstream, comparator);
@Override
public void begin(long size)
...
// 创建一个存放排序元素的列表
list = (size >= 0) ? new ArrayList<T>((int) size) : new ArrayList<T>();
@Override
public void end()
list.sort(comparator);// 只有元素全部接收之后才能开始排序
downstream.begin(list.size());
if (!cancellationWasRequested) // 下游Sink不包含短路操作
list.forEach(downstream::accept);// 2. 将处理结果传递给流水线下游的Sink
else // 下游Sink包含短路操作
for (T t : list) // 每次都调用cancellationRequested()询问是否可以结束处理。
if (downstream.cancellationRequested()) break;
downstream.accept(t);// 2. 将处理结果传递给流水线下游的Sink
downstream.end();
list = null;
@Override
public void accept(T t)
list.add(t);// 1. 使用当前Sink包装动作处理t,只是简单的将元素添加到中间列表当中
上述代码完美的展现了Sink的四个接口方法是如何协同工作的:
-
- 首先begin()方法告诉Sink参与排序的元素个数,方便确定中间结果容器的的大小;
- 之后通过accept()方法将元素添加到中间结果当中,最终执行时调用者会不断调用该方法,直到遍历所有元素;
- 最后end()方法告诉Sink所有元素遍历完毕,启动排序步骤,排序完成后将结果传递给下游的Sink;
- 如果下游的Sink是短路操作,将结果传递给下游时不断询问下游cancellationRequested()是否可以结束处理。
叠加之后的操作如何执行

Sink完美封装了Stream每一步操作,并给出了[处理->转发]的模式来叠加操作。这一连串的齿轮已经咬合,就差最后一步拨动齿轮启动执行。是什么启动这一连串的操作呢?也许你已经想到了启动的原始动力就是结束操作(Terminal Operation),一旦调用某个结束操作,就会触发整个流水线的执行。
结束操作之后不能再有别的操作,所以结束操作不会创建新的流水线阶段(Stage),直观的说就是流水线的链表不会在往后延伸了。结束操作会创建一个包装了自己操作的Sink,这也是流水线中最后一个Sink,这个Sink只需要处理数据而不需要将结果传递给下游的Sink(因为没有下游)。对于Sink的[处理->转发]模型,结束操作的Sink就是调用链的出口。
我们再来考察一下上游的Sink是如何找到下游Sink的。一种可选的方案是在PipelineHelper中设置一个Sink字段,在流水线中找到下游Stage并访问Sink字段即可。但Stream类库的设计者没有这么做,而是设置了一个Sink AbstractPipeline.opWrapSink(int flags, Sink downstream)方法来得到Sink,该方法的作用是返回一个新的包含了当前Stage代表的操作以及能够将结果传递给downstream的Sink对象。为什么要产生一个新对象而不是返回一个Sink字段?这是因为使用opWrapSink()可以将当前操作与下游Sink(上文中的downstream参数)结合成新Sink。试想只要从流水线的最后一个Stage开始,不断调用上一个Stage的opWrapSink()方法直到最开始(不包括stage0,因为stage0代表数据源,不包含操作),就可以得到一个代表了流水线上所有操作的Sink,用代码表示就是这样:
// AbstractPipeline.wrapSink()
// 从下游向上游不断包装Sink。如果最初传入的sink代表结束操作,
// 函数返回时就可以得到一个代表了流水线上所有操作的Sink。
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink)
...
for (AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage)
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
return (Sink<P_IN>) sink;
现在流水线上从开始到结束的所有的操作都被包装到了一个Sink里,执行这个Sink就相当于执行整个流水线,执行Sink的代码如下:
// AbstractPipeline.copyInto(), 对spliterator代表的数据执行wrappedSink代表的操作。
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator)
...
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags()))
wrappedSink.begin(spliterator.getExactSizeIfKnown());// 通知开始遍历
spliterator.forEachRemaining(wrappedSink);// 迭代
wrappedSink.end();// 通知遍历结束
...
上述代码首先调用wrappedSink.begin()方法告诉Sink数据即将到来,然后调用spliterator.forEachRemaining()方法对数据进行迭代(Spliterator是容器的一种迭代器,参阅),最后调用wrappedSink.end()方法通知Sink数据处理结束。逻辑如此清晰。
执行后的结果在哪里
最后一个问题是流水线上所有操作都执行后,用户所需要的结果(如果有)在哪里?首先要说明的是不是所有的Stream结束操作都需要返回结果,有些操作只是为了使用其副作用(Side-effects),比如使用Stream.forEach()方法将结果打印出来就是常见的使用副作用的场景(事实上,除了打印之外其他场景都应避免使用副作用),对于真正需要返回结果的结束操作结果存在哪里呢?
/* 特别说明:副作用不应该被滥用,也许你会觉得在Stream.forEach()里进行元素收集是个不错的选择, 就像下面代码中那样,但遗憾的是这样使用的正确性和效率都无法保证,因为Stream可能会并行执行。 大多数使用副作用的地方都可以使用归约操作更安全和有效的完成。*/ // 错误的收集求求你别在用 for循环遍历list 了,真的太low了!
点击上方关注 “终端研发部”
设为“星标”,和你一起掌握更多数据库知识简介
Java 8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。
Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。
熟悉Linux的同学对这种风格一定不陌生,因为它跟Linux的|管道符的思想如出一辙。上面这段话引用自runoob.com,但是其教学代码都是基于String列表进行演示,考虑到实际情况百分之80的时候都是对PO、VO进行处理,因此以下通过一个PO进行讲解。
对比起for循环操作list,最大的弊端就是代码太长太乱了,如果涉及3-4张表的操作,也就是涉及多个PO操作,那个括号简直就是俄罗斯套娃,写到最后真的自己都不知道在写什么
流
+--------------------+ +------+ +------+ +---+ +-------+ | stream of elements +-----> |filter+-> |sorted+-> |map+-> |collect| +--------------------+ +------+ +------+ +---+ +-------+PO代码
public class UserPo private String name; private Double score; // 省略构造函数及getter、setter以下操作均以UserPo进行讲解
filter
filter:过滤,就是过滤器,符合条件的通过,不符合条件的过滤掉
// 筛选出成绩不为空的学生人数 count = list.stream().filter(p -> null != p.getScore()).count();map
map:映射,他将原集合映射成为新的集合,在VO、PO处理的过程中较常见。在本例子中,原集合就是PO集合,新集合可以自定义映射为成绩集合,同时也可以对新集合进行相关操作
// 取出所有学生的成绩 List<Double> scoreList = list.stream().map(p -> p.getScore()).collect(Collectors.toList()); // 将学生姓名集合串成字符串,用逗号分隔 String nameString = list.stream().map(p -> p.getName()).collect(Collectors.joining(","));sorted
sorted:排序,可以根据指定的字段进行排序
// 按学生成绩逆序排序 正序则不需要加.reversed() filterList = list.stream().filter(p -> null != p.getScore()).sorted(Comparator.comparing(UserPo::getScore).reversed()).collect(Collectors.toList());forEach
forEach:这个应该是最常用的,也就是为每一个元素进行自定义操作
除了forEach操作会改变原集合的数据,其他的操作均不会改变原集合,这点务必引起注意
// 学生成绩太差了,及格率太低,给每个学生加10分,放个水 // forEach filterList.stream().forEach(p -> p.setScore(p.getScore() + 10));collect
collect:聚合,可以用于GroudBy按指定字段分类,也可以用于返回列表或者拼凑字符串
// 按成绩进行归集 Map<Double, List<UserPo>> groupByScoreMap = list.stream().filter(p -> null != p.getScore()).collect(Collectors.groupingBy(UserPo::getScore)); for (Map.Entry<Double, List<UserPo>> entry : groupByScoreMap.entrySet()) System.out.println("成绩:" + entry.getKey() + " 人数:" + entry.getValue().size()); // 返回list List<Double> scoreList = list.stream().map(p -> p.getScore()).collect(Collectors.toList()); // 返回string用逗号分隔 String nameString = list.stream().map(p -> p.getName()).collect(Collectors.joining(","));statistics
statistics:统计,可以统计中位数,平均值,最大最小值
DoubleSummaryStatistics statistics = filterList.stream().mapToDouble(p -> p.getScore()).summaryStatistics(); System.out.println("列表中最大的数 : " + statistics.getMax()); System.out.println("列表中最小的数 : " + statistics.getMin()); System.out.println("所有数之和 : " + statistics.getSum()); System.out.println("平均数 : " + statistics.getAverage());parallelStream
parallelStream:并行流,可以利用多线程进行流的操作,提升效率。但是其不具备线程传播性,因此使用时需要充分评估是否需要用并行流操作
// 并行流 count = list.parallelStream().filter(p -> null != p.getScore()).count();完整代码
package com.cmx.tcn.stream; /** * @author: Cai MinXing **/ public class UserPo private String name; private Double score; public UserPo(String name, Double score) this.name = name; this.score = score; public String getName() return name; public void setName(String name) this.name = name; public Double getScore() return score; public void setScore(Double score) this.score = score; @Override public String toString() return "UserPo" + "name='" + name + '\\'' + ", score=" + score + '';package com.cmx.tcn.stream; import java.util.ArrayList; import java.util.Comparator; import java.util.DoubleSummaryStatistics; import java.util.List; import java.util.Map; import java.util.stream.Collectors; /** * @author: Cai MinXing * @create: 2020-03-25 18:15 **/ public class StreamTest // +--------------------+ +------+ +------+ +---+ +-------+ // | stream of elements +-----> |filter+-> |sorted+-> |map+-> |collect| // +--------------------+ +------+ +------+ +---+ +-------+ public static void main(String args[]) List<UserPo> list = new ArrayList<>(); list.add(new UserPo("小一", 10.d)); list.add(new UserPo("小五", 50.d)); list.add(new UserPo("小六", 60.d)); list.add(new UserPo("小6", 60.d)); list.add(new UserPo("小空", null)); list.add(new UserPo("小九", 90.d)); long count = 0; List<UserPo> filterList = null; // filter 过滤器的使用 // 筛选出成绩不为空的学生人数 count = list.stream().filter(p -> null != p.getScore()).count(); System.out.println("参加考试的学生人数:" + count); // collect // 筛选出成绩不为空的学生集合 filterList = list.stream().filter(p -> null != p.getScore()).collect(Collectors.toList()); System.out.println("参加考试的学生信息:"); filterList.stream().forEach(System.out::println); // map 将集合映射为另外一个集合 // 取出所有学生的成绩 List<Double> scoreList = list.stream().map(p -> p.getScore()).collect(Collectors.toList()); System.out.println("所有学生的成绩集合:" + scoreList); // 将学生姓名集合串成字符串,用逗号分隔 String nameString = list.stream().map(p -> p.getName()).collect(Collectors.joining(",")); System.out.println("所有学生的姓名字符串:" + nameString); // sorted排序 // 按学生成绩逆序排序 正序则不需要加.reversed() filterList = list.stream().filter(p -> null != p.getScore()).sorted(Comparator.comparing(UserPo::getScore).reversed()).collect(Collectors.toList()); System.out.println("所有学生的成绩集合,逆序排序:"); filterList.stream().forEach(System.out::println); System.out.println("按学生成绩归集:"); Map<Double, List<UserPo>> groupByScoreMap = list.stream().filter(p -> null != p.getScore()) .collect(Collectors.groupingBy(UserPo::getScore)); for (Map.Entry<Double, List<UserPo>> entry : groupByScoreMap.entrySet()) System.out.println("成绩:" + entry.getKey() + " 人数:" + entry.getValue().size()); // forEach filterList.stream().forEach(p -> p.setScore(p.getScore() + 10)); System.out.println("及格人数太少,给每个人加10分"); filterList.stream().forEach(System.out::println); // count count = filterList.stream().filter(p -> p.getScore() >= 60).count(); System.out.println("最后及格人数" + count); DoubleSummaryStatistics statistics = filterList.stream().mapToDouble(p -> p.getScore()).summaryStatistics(); System.out.println("列表中最大的数 : " + statistics.getMax()); System.out.println("列表中最小的数 : " + statistics.getMin()); System.out.println("所有数之和 : " + statistics.getSum()); System.out.println("平均数 : " + statistics.getAverage()); // 并行流 使用 count = list.parallelStream().filter(p -> null != p.getScore()).count(); System.out.println("并行流处理参加考试的学生人数:" + count);原文:bugpool.blog.csdn.net/article/details/105122681
回复 【idea激活】即可获得idea的激活方式 回复 【Java】获取java相关的视频教程和资料 回复 【SpringCloud】获取SpringCloud相关多的学习资料 回复 【python】获取全套0基础Python知识手册 回复 【2020】获取2020java相关面试题教程 回复 【加群】即可加入终端研发部相关的技术交流群 阅读更多 用 Spring 的 BeanUtils 前,建议你先了解这几个坑! lazy-mock ,一个生成后端模拟数据的懒人工具 在华为鸿蒙 OS 上尝鲜,我的第一个“hello world”,起飞! 字节跳动一面:i++ 是线程安全的吗? 一条 SQL 引发的事故,同事直接被开除!! 太扎心!排查阿里云 ECS 的 CPU 居然达100% 一款vue编写的功能强大的swagger-ui,有点秀(附开源地址) 相信自己,没有做不到的,只有想不到的在这里获得的不仅仅是技术! 喜欢就给个“在看”以上是关于Java集合遍历方式(for循环与stream()&forEach())比较的主要内容,如果未能解决你的问题,请参考以下文章