从 0 到 1 搭建一套 Flink 的监控系统
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从 0 到 1 搭建一套 Flink 的监控系统相关的知识,希望对你有一定的参考价值。
本文带大家讲解一下如何搭建一套完整的 Flink 监控系统,如果你所在的公司没有专门的监控平台,那么可以根据本文的内容来为公司搭建一套属于自己公司的 Flink 监控系统。
利用 API 获取监控数据
熟悉 Flink 的朋友都知道 Flink 的 UI 上面已经详细地展示了很多监控指标的数据,并且这些指标还是比较重要的,所以如果不想搭建额外的监控系统,那么直接利用 Flink 自身的 UI 就可以获取到很多重要的监控信息。这里要讲的是这些监控信息其实也是通过 Flink 自身的 Rest API 来获取数据的,所以其实要搭建一个粗糙的监控平台,也是可以直接利用现有的接口定时去获取数据,然后将这些指标的数据存储在某种时序数据库中,最后用些可视化图表做个展示,这样一个完整的监控系统就做出来了。
这里通过 Chrome 浏览器的控制台来查看一下有哪些 REST API 是用来提供监控数据的。
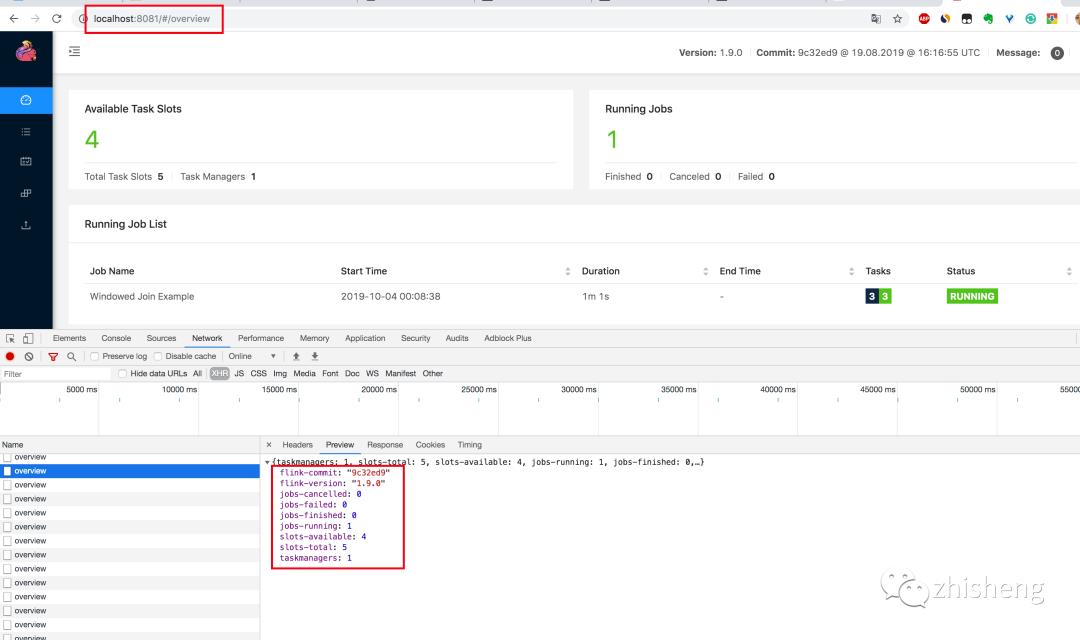
1.在 Chrome 浏览器中打开 http://localhost:8081/overview 页面,可以获取到整个 Flink 集群的资源信息:TaskManager 个数(TaskManagers)、Slot 总个数(Total Task Slots)、可用 Slot 个数(Available Task Slots)、Job 运行个数(Running Jobs)、Job 运行状态(Finished 0 Canceled 0 Failed 0)等,如下图所示。
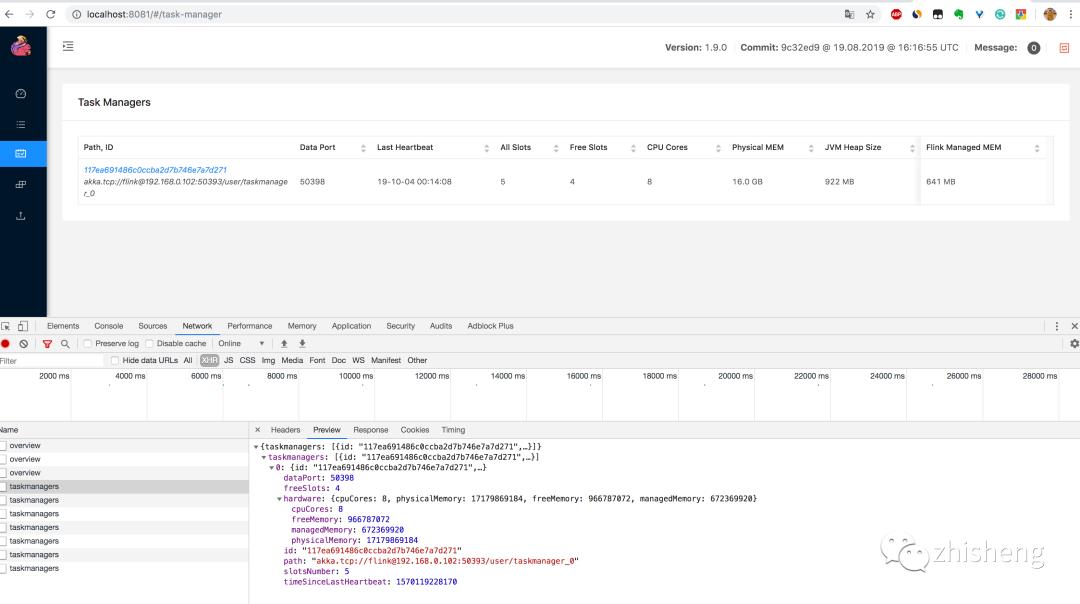
2.通过 http://localhost:8081/taskmanagers 页面查看 TaskManager 列表,可以知道该集群下所有 TaskManager 的信息(数据端口号(Data Port)、上一次心跳时间(Last Heartbeat)、总共的 Slot 个数(All Slots)、空闲的 Slot 个数(Free Slots)、以及 CPU 和内存的分配使用情况,如下图所示。
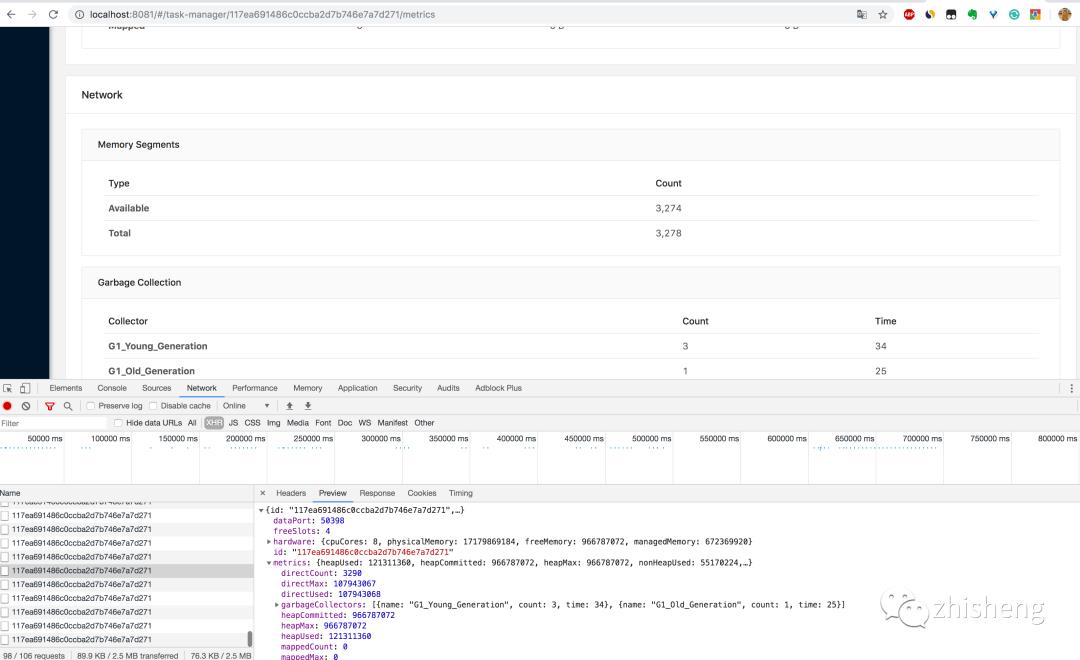
3.通过 http://localhost:8081/taskmanagers/tm_id 页面查看 TaskManager 的具体情况(这里的 tm_id 是个随机的 UUID 值)。在这个页面上,除了上一条的监控信息可以查看,还可以查看该 TaskManager 的 JVM(堆和非堆)、Direct 内存、网络、GC 次数和时间,如下图所示。内存和 GC 这些信息非常重要,很多时候 TaskManager 频繁重启的原因就是 JVM 内存设置得不合理,导致频繁的 GC,最后使得 OOM 崩溃,不得不重启。
另外如果你在 /taskmanagers/tm_id 接口后面加个 /log 就可以查看该 TaskManager 的日志,注意,在 Flink 中的日志和平常自己写的应用中的日志是不一样的。在 Flink 中,日志是以 TaskManager 为概念打印出来的,而不是以单个 Job 打印出来的,如果你的 Job 在多个 TaskManager 上运行,那么日志就会在多个 TaskManager 中打印出来。如果一个 TaskManager 中运行了多个 Job,那么它里面的日志就会很混乱,查看日志时会发现它为什么既有这个 Job 打出来的日志,又有那个 Job 打出来的日志,如果你之前有这个疑问,那么相信你看完这里,就不会有疑问了。
对于这种设计是否真的好,不同的人有不同的看法,在 Flink 的 Issue 中就有人提出了该问题,Issue 中的描述是希望日志可以是 Job 与 Job 之间的隔离,这样日志更方便采集和查看,对于排查问题也会更快。对此国内有公司也对这一部分做了改进,不知道正在看文的你是否有什么好的想法可以解决 Flink 的这一痛点。
4.通过 http://localhost:8081/#/job-manager/config 页面可以看到可 JobManager 的配置信息,另外通过 http://localhost:8081/jobmanager/log 页面可以查看 JobManager 的日志详情。
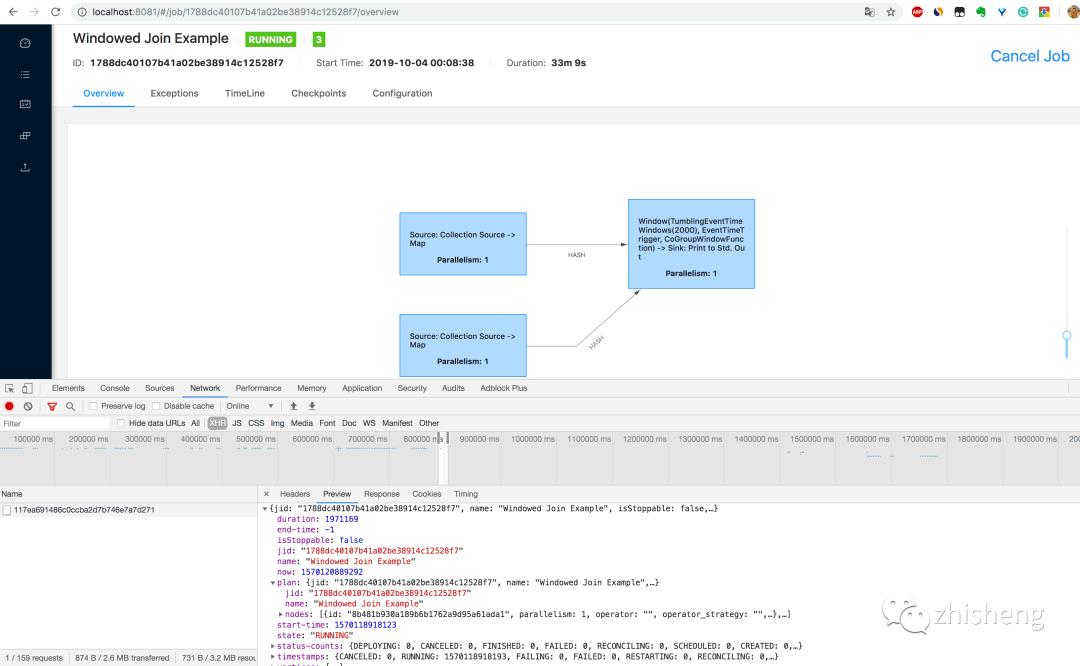
5.通过 http://localhost:8081/jobs/job_id 页面可以查看 Job 的监控数据,如下图所示,由于指标(包括了 Job 的 Task 数据、Operator 数据、Exception 数据、Checkpoint 数据等)过多,大家可以自己在本地测试查看。
上面列举了几个 REST API(不是全部),主要是为了告诉大家,其实这些接口我们都知道,那么我们也可以利用这些接口去获取对应的监控数据,然后绘制出更酷炫的图表,用更直观的页面将这些数据展示出来,这样就能更好地控制。
除了利用 Flink UI 提供的接口去定时获取到监控数据,其实 Flink 还提供了很多的 reporter 去上报监控数据,比如 JMXReporter、PrometheusReporter、PrometheusPushGatewayReporter、InfluxDBReporter、StatsDReporter 等,这样就可以根据需求去定制获取到 Flink 的监控数据,下面教大家使用几个常用的 reporter。
相关 Rest API 可以查看官网链接:rest-api-integration
Metrics 类型简介
可以在继承自 RichFunction 的函数中通过 getRuntimeContext().getMetricGroup() 获取 Metric 信息,常见的 Metrics 的类型有 Counter、Gauge、Histogram、Meter。
Counter
Counter 用于计数,当前值可以使用 inc()/inc(long n) 递增和 dec()/dec(long n) 递减,在实现 RichFunction 中的函数的 open 方法注册 Counter。
private transient Counter counter;
@Override
public void open(Configuration config)
this.counter = getRuntimeContext()
.getMetricGroup()
.counter("zhisheng_counter");
//或者自定义 Counter
@Override
public void open(Configuration config)
this.counter = getRuntimeContext()
.getMetricGroup()
.counter("zhisheng_counter", new CustomCounter());
@Override
public String map(String value) throws Exception
this.counter.inc();
return value;
Gauge
Gauge 根据需要提供任何类型的值,要使用 Gauge 的话,需要实现 Gauge 接口,返回值没有规定类型。
private transient int valueToExpose = 0;
@Override
public void open(Configuration config)
getRuntimeContext()
.getMetricGroup()
.gauge("zhisheng_gauge", new Gauge<Integer>()
@Override
public Integer getValue()
return valueToExpose;
);
@Override
public String map(String value) throws Exception
valueToExpose++;
return value;
Histogram
Histogram 统计数据的分布情况,比如最小值,最大值,中间值,还有分位数等。使用情况如下:
private transient Histogram histogram;
@Override
public void open(Configuration config)
this.histogram = getRuntimeContext()
.getMetricGroup()
.histogram("zhisheng_histogram", new MyHistogram());
@Override
public Long map(Long value) throws Exception
this.histogram.update(value);
return value;
Meter
Meter 代表平均吞吐量,使用情况如下:
private transient Meter meter;
@Override
public void open(Configuration config)
this.meter = getRuntimeContext()
.getMetricGroup()
.meter("myMeter", new MyMeter());
@Override
public Long map(Long value) throws Exception
this.meter.markEvent();
return value;
利用 JMXReporter 获取监控数据
JMX 对于大家来说应该不太陌生,在 Flink 中默认提供了 JMXReporter 获取到监控数据,不需要额外添加依赖项,但是需要在 flink-conf.yaml 配置文件中加入如下配置即可开启 JMX:
metrics.reporter.jmx.factory.class: org.apache.flink.metrics.jmx.JMXReporterFactory
metrics.reporter.jmx.port: 8789
然后利用 JDK 自带的 jconsole 可以查看 MBean 信息,首先需要启动 jconsole,操作如下图所示。
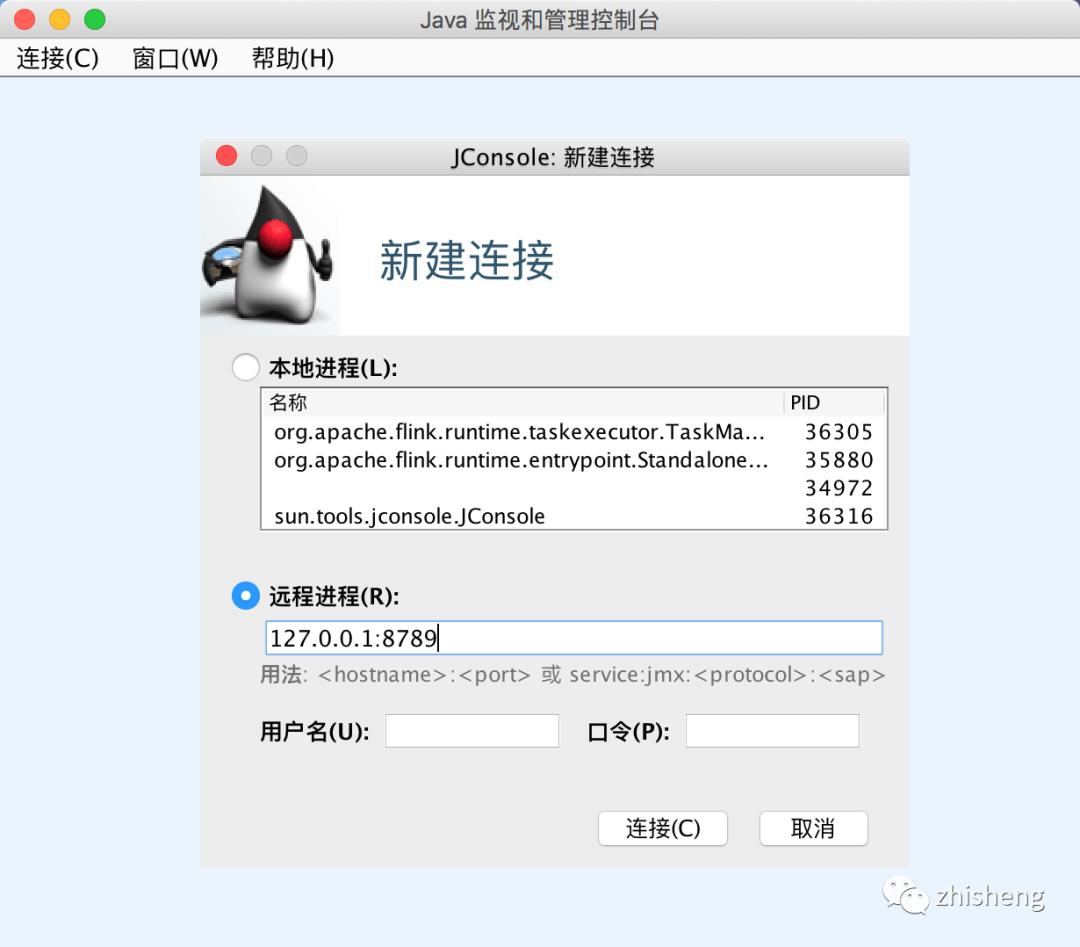
然后要配置与进程进行建立连接,如下图所示。
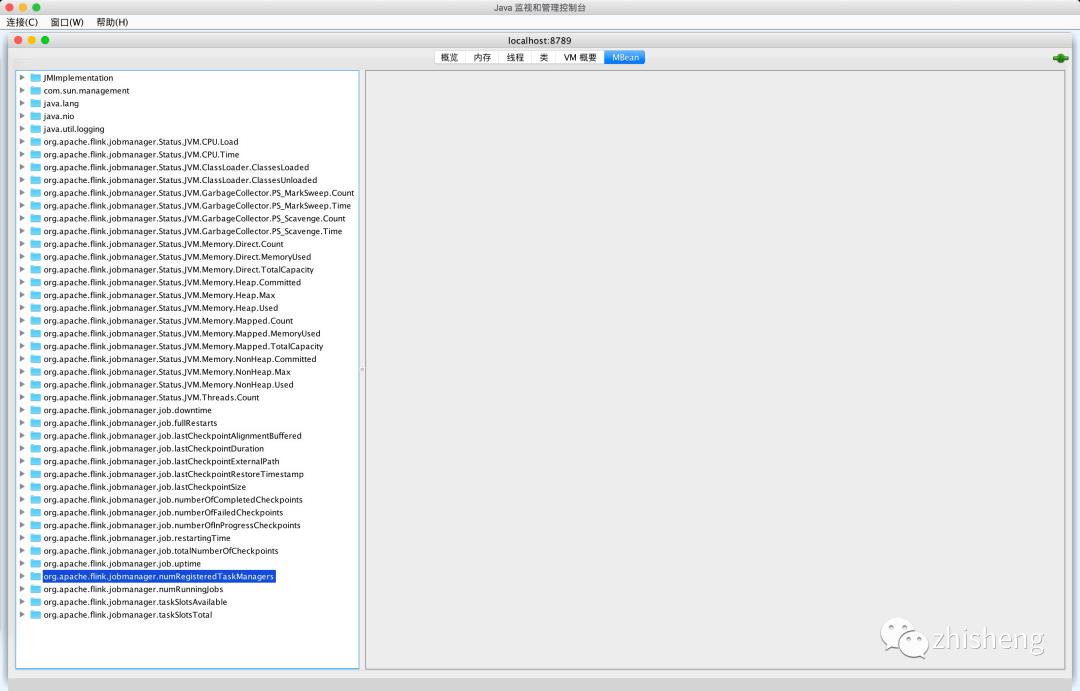
连接成功的话,你可以看到左侧是有很多的监控指标,如果点进去是可以查看到每个指标对应的 value 值,如下图所示。
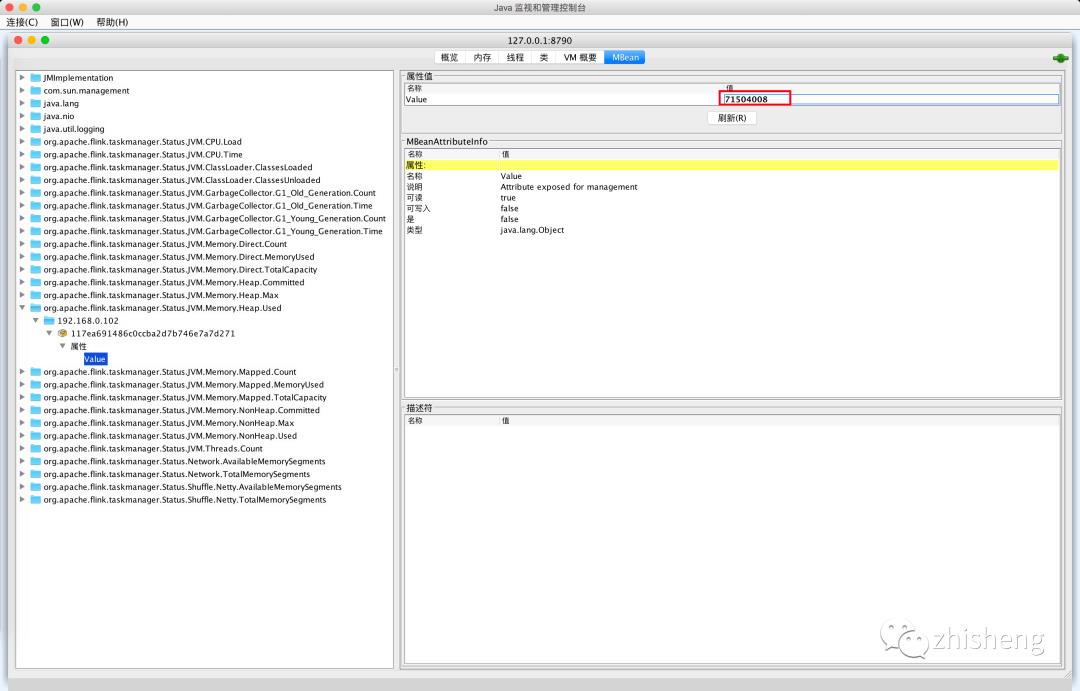
但是你有没有发现这些指标只有 JobManager 的监控指标,没有 TaskManager 的监控指标,如果你在同一台服务器上面既运行了 JobManager,又运行了 TaskManager,那么只开启一个端口号那么是只能够监听到一个的数据,如果你要监听多个数据,那么就需要在端口设置里填写一个范围(这里需要特别注意一下),具体配置如下:
# jmx reporter
metrics.reporter.jmx.factory.class: org.apache.flink.metrics.jmx.JMXReporterFactory
metrics.reporter.jmx.port: 8789-8799
这样就表示监听了多个端口(从 8789 ~ 8799),那么再通过 jconsole 连接 8790 端口就会出现 TaskManager 的监控指标数据了,如下图所示。
查看日志也可以看到开启 JMX 成功的日志,如下所示。
2019-10-07 10:52:51,839 INFO org.apache.flink.metrics.jmx.JMXReporter - Started JMX server on port 8789.
2019-10-07 10:52:51,839 INFO org.apache.flink.metrics.jmx.JMXReporter - Configured JMXReporter with port:8789-8799
2019-10-07 10:52:51,840 INFO org.apache.flink.runtime.metrics.ReporterSetup - Configuring jmx with factory.class=org.apache.flink.metrics.jmx.JMXReporterFactory, port=8789-8799.
2019-10-07 10:52:51,841 INFO org.apache.flink.runtime.metrics.MetricRegistryImpl - Reporting metrics for reporter jmx of type org.apache.flink.metrics.jmx.JMXReporter.
利用 PrometheusReporter 获取监控数据
要使用该 reporter 的话,需要将 opt 目录下的 flink-metrics-prometheus-1.9.0.jar 依赖放到 lib 目录下,可以配置的参数有:
port:该参数为可选项,Prometheus 监听的端口,默认是 9249,和上面使用 JMXReporter 一样,如果是在一台服务器上既运行了 JobManager,又运行了 TaskManager,则使用端口范围,比如
9249-9259。filterLabelValueCharacters:该参数为可选项,表示指定是否过滤标签值字符,如果开启,则删除所有不匹配
[a-zA-Z0-9:_]的字符,否则不会删除任何字符。
除了上面两个可选参数,另外一个参数是必须要在 flink-conf.yaml 中配置的,那就是 metrics reporter class。比如像下面这样配置:
metrics.reporter.prom.class: org.apache.flink.metrics.prometheus.PrometheusReporter
Flink 中的 metrics 类型和 Prometheus 中 metrics 类型对比如下图所示。
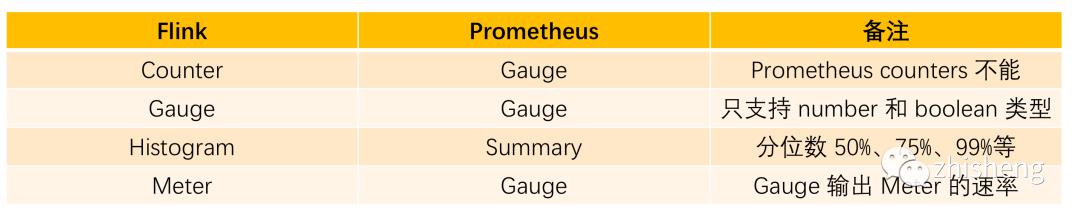
利用 PrometheusPushGatewayReporter 获取监控数据
PushGateway 是 Prometheus 生态中一个重要工具,使用它的原因主要是:
Prometheus 采用 pull 模式,可能由于 Prometheus 和其他 target 对象不在一个子网或者防火墙原因,导致 Prometheus 无法直接拉取各个 target 数据。
在监控业务数据的时候,需要将不同数据汇总, 由 Prometheus 统一收集。
那么使用 PrometheusPushGatewayReporter 的话,该 reporter 会定时将 metrics 数据推送到 PushGateway,然后再由 Prometheus 去拉取这些 metrics 数据。如果使用 PrometheusPushGatewayReporter 收集数据的话,也是需要将 opt 目录下的 flink-metrics-prometheus-1.9.0.jar 依赖放到 lib 目录下的,可配置的参数有:
deleteOnShutdown:默认值是 true,表示是否在关闭时从 PushGateway 删除指标。
filterLabelValueCharacters:默认值是 true,表示是否过滤标签值字符,如果开启,则不符合
[a-zA-Z0-9:_]的字符都将被删除。host:无默认值,配置 PushGateway 服务所在的机器 IP。
jobName:无默认值,要上报 Metrics 的 Job 名称。
port:默认值是 -1,这里配置 PushGateway 服务的端口。
randomJobNameSuffix:默认值是 true,指定是否将随机后缀名附加到作业名。
在 flink-conf.yaml 中配置的样例如下:
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
metrics.reporter.promgateway.host: localhost
metrics.reporter.promgateway.port: 9091
metrics.reporter.promgateway.jobName: zhisheng
metrics.reporter.promgateway.randomJobNameSuffix: true
metrics.reporter.promgateway.deleteOnShutdown: false
利用 InfluxDBReporter 获取监控数据
Flink 里面提供了 InfluxDBReporter 支持将 Flink 的 metrics 数据直接存储到 InfluxDB 中,在源码中该模块是通过 MetricMapper 类将 MeasurementInfo(这个类是 metric 的数据结构,里面含有两个字段 name 和 tags) 和 Gauge、Counter、Histogram、Meter 组装成 InfluxDB 中的 Point 数据,Point 结构如下(主要就是构造 metric name、fields、tags 和 timestamp):
private String measurement;
private Map<String, String> tags;
private Long time;
private TimeUnit precision;
private Map<String, Object> fields;
然后在 InfluxdbReporter 类中将 metric 数据导入 InfluxDB,该类继承自 AbstractReporter 抽象类,实现了 Scheduled 接口,有下面 3 个属性:
private String database;
private String retentionPolicy;
private InfluxDB influxDB;
在 open 方法中获取配置文件中的 InfluxDB 设置,然后初始化 InfluxDB 相关的配置,构造 InfluxDB 客户端:
public void open(MetricConfig config)
//获取到 host 和 port
String host = getString(config, HOST);
int port = getInteger(config, PORT);
//判断 host 和 port 是否合法
if (!isValidHost(host) || !isValidPort(port))
throw new IllegalArgumentException("Invalid host/port configuration. Host: " + host + " Port: " + port);
//获取到 InfluxDB database
String database = getString(config, DB);
if (database == null)
throw new IllegalArgumentException("'" + DB.key() + "' configuration option is not set");
String url = String.format("http://%s:%d", host, port);
//获取到 InfluxDB username 和 password
String username = getString(config, USERNAME);
String password = getString(config, PASSWORD);
this.database = database;
//InfluxDB 保留政策
this.retentionPolicy = getString(config, RETENTION_POLICY);
if (username != null && password != null)
//如果有用户名和密码,根据 url 和 用户名密码来创建连接
influxDB = InfluxDBFactory.connect(url, username, password);
else
//否则就根据 url 连接
influxDB = InfluxDBFactory.connect(url);
log.info("Configured InfluxDBReporter with host:, port:, db:, and retentionPolicy:", host, port, database, retentionPolicy);
然后在 report 方法中调用一个内部 buildReport 方法来构造 BatchPoints,将一批 Point 放在该对象中,BatchPoints 对象的属性如下:
private String database;
private String retentionPolicy;
private Map<String, String> tags;
private List<Point> points;
private ConsistencyLevel consistency;
private TimeUnit precision;
通过 buildReport 方法返回的 BatchPoints 如果不为空,则会通过 write 方法将 BatchPoints 写入 InfluxDB:
if (report != null)
influxDB.write(report);
在使用 InfluxDBReporter 时需要注意:
1.必须复制 Flink 安装目录下的 /opt/flink-metrics-influxdb-1.9.0.jar 到 flink 的 lib 目录下,否则运行起来会报 ClassNotFoundException 错误,详细错误如下图所示:

2.如下所示,在 flink-conf.yaml 中添加 InfluxDB 相关的配置。
metrics.reporter.influxdb.class:org.apache.flink.metrics.influxdb.InfluxdbReporter
metrics.reporter.influxdb.host:localhost # InfluxDB服务器主机
metrics.reporter.influxdb.port: 8086 # 可选)InfluxDB 服务器端口,默认为 8086
metrics.reporter.influxdb.db:zhisheng # 用于存储指标的 InfluxDB 数据库
metrics.reporter.influxdb.username:zhisheng # (可选)用于身份验证的 InfluxDB 用户名
metrics.reporter.influxdb.password:123456 # (可选)InfluxDB 用户名用于身份验证的密码
metrics.reporter.influxdb.retentionPolicy: one_hour #(可选)InfluxDB 数据保留策略,默认为服务器上数据库定义的保留策略
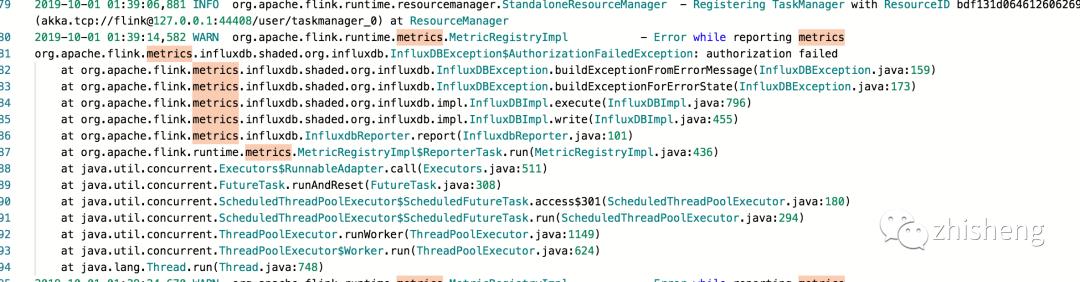
如果填错了密码会报鉴权失败的错误,错误信息如下图所示。
安装 InfluxDB 和 Grafana
接下来将讲解 InfluxDB 和 Grafana 的安装和配置。
安装 InfluxDB
InfluxDB 是一款时序数据库,使用它作为监控数据存储的公司也有很多,可以根据 InfluxDB 官网:https://docs.influxdata.com/influxdb/v1.7/introduction/installation/ 的安装步骤来操作。
1、配置 InfluxDB 下载源。
cat <<EOF | sudo tee /etc/yum.repos.d/influxdb.repo
[influxdb]
name = InfluxDB Repository - RHEL \\$releasever
baseurl = https://repos.influxdata.com/rhel/\\$releasever/\\$basearch/stable
enabled = 1
gpgcheck = 1
gpgkey = https://repos.influxdata.com/influxdb.key
EOF
2、根据 yum 安装命令操作。
yum install influxdb
3、启停 InfluxDB。
//启动 influxdb 命令
systemctl start influxdb
//重启 influxdb 命令
systemctl restart influxd
//停止 influxdb 命令
systemctl stop influxd
//设置开机自启动
systemctl enable influxdb
4、InfluxDB 相关的命令操作。
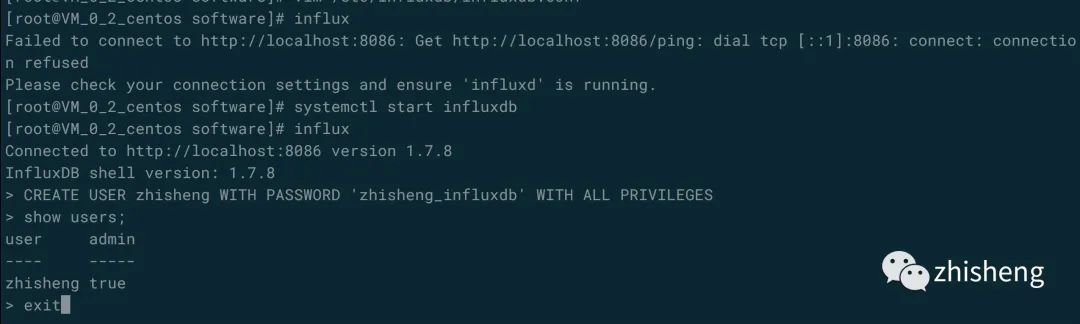
启动好 InfluxDB 后执行 influx 命令,然后使用下面命令来创建用户:
CREATE USER zhisheng WITH PASSWORD '123456' WITH ALL PRIVILEGES
然后执行 show users; 命令查看创建的用户,操作运行的结果如下图所示。
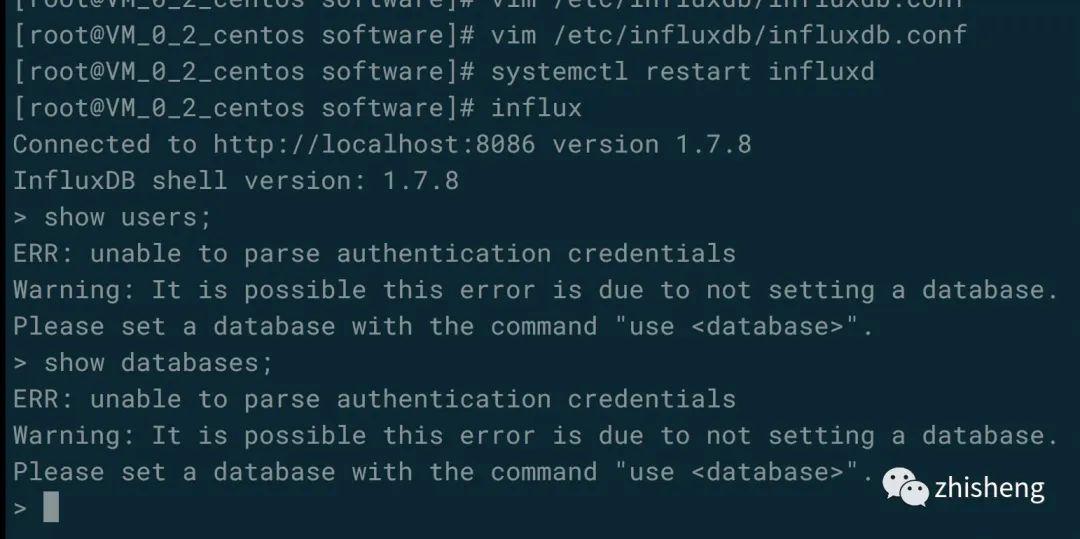
对 InfluxDB 开启身份验证,编辑 InfluxDB 配置文件 /etc/influxdb/influxdb.conf ,将 auth-enabled 设置为 true。然后重启 InfluxDB,再次使用 influx 命令进入的话,这时候查看用户或者数据的话,就会报异常(需要使用用户名和密码认证登录),异常完整信息如下图所示。
这时需要使用下面命令的命令才能够登录:
influx -username zhisheng -password 123456
重新登录就能查询到用户和数据了,查询到的结果如下图所示。
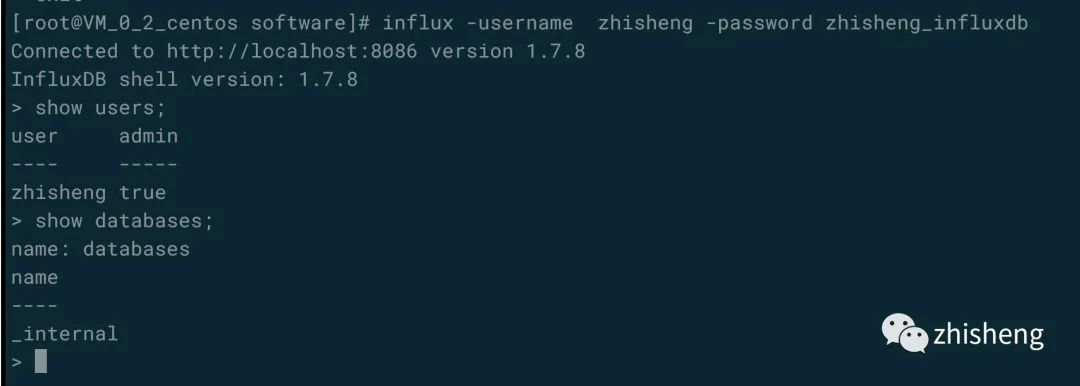
然后创建一个叫 zhisheng 的数据库,后面会将 Flink 中的监控数据全部存储到该数据库下,创建后可以查询到该数据库,效果如下图所示。
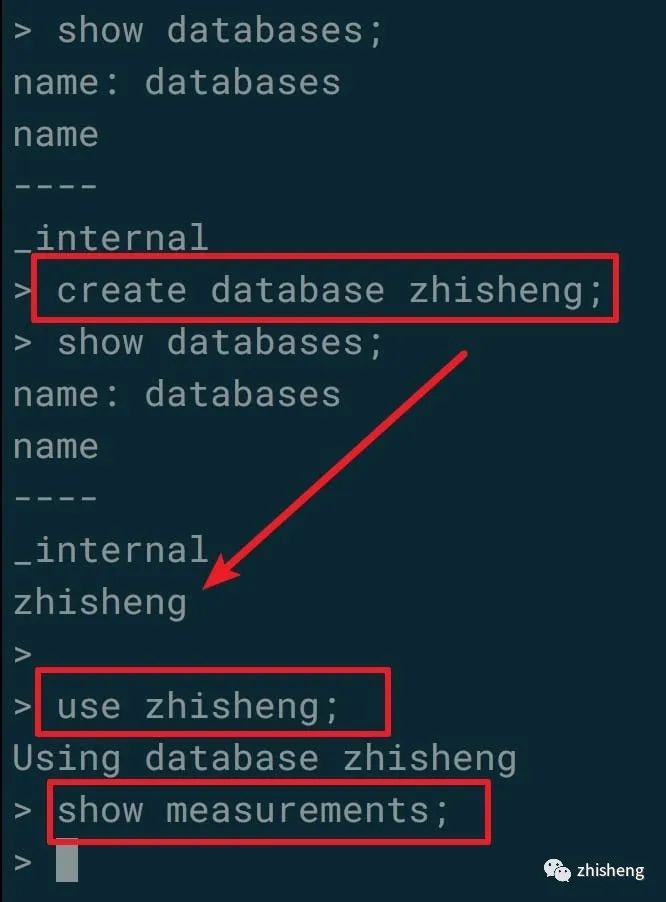
安装 Grafana
Grafana 是一款优秀的图表可视化组件,它拥有超多酷炫的图表,并支持自定义配置,用它来做监控的 Dashboard 简直特别完美。
1、下载
wget https://dl.grafana.com/oss/release/grafana-6.3.6-1.x86_64.rpm
2、安装
yum localinstall grafana-6.3.6-1.x86_64.rpm
安装完成后的效果如下图所示:
3、启停 Grafana
//启动 Grafana
systemctl start grafana-server
//停止 Grafana
systemctl stop grafana-server
//重启 Grafana
systemctl restart grafana-server
//设置开机自启动
systemctl enable grafana-server
然后访问 http://54tianzhisheng.cn:3000 就可以登录了。第一次登录的默认账号密码是 admin/admin,会提示修改密码。
配置 Grafana 展示监控数据
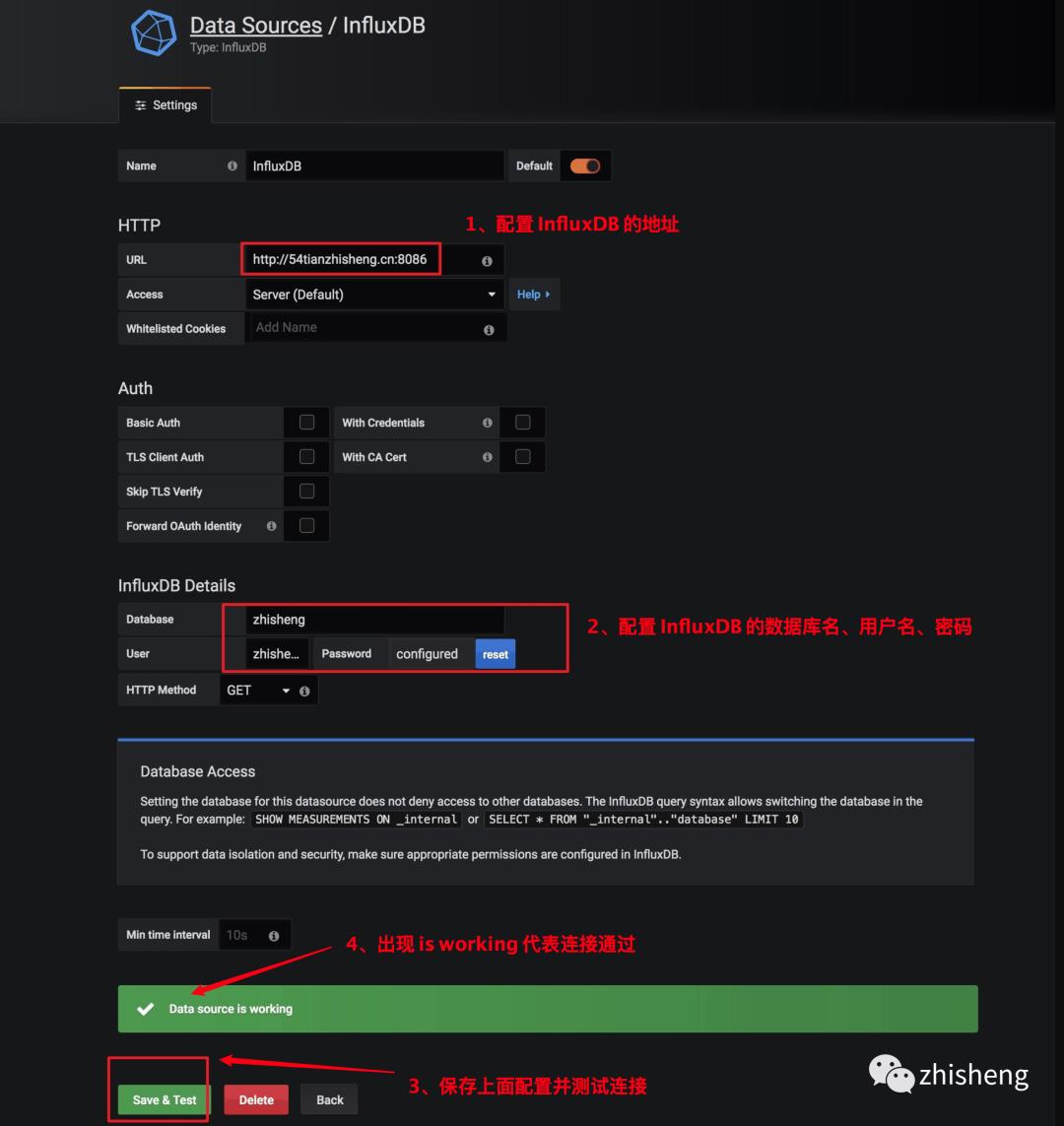
登录 Grafana 后,需要配置数据源,Grafana 支持的数据源有很多,比如 InfluxDB、Prometheus 等,选择不同的数据源都可以绘制出很酷炫的图表,如果你公司有使用 Prometheus 做监控系统的,那么可以选择 Prometheus 作为数据源,这里演示就选择 InfluxDB,然后填写 InfluxDB 的地址和用户名密码,操作步骤如下图所示。
配置好数据源之后,接下来就是要根据数据源来添加数据图表,因为构造数据图表首先得知道有哪些指标,所以这里先看下分别有哪些指标,这里分 JobManager、TaskManager 和 Job 三大类。具体有哪些指标其实是可以根据 InfluxDB 里面的 measurements 来查看的,我在 GitHub 放了一份完整的 measurements 列表 以供大家查阅,在 8.1.4 和 8.2.1 节中也都讲解了比较关心的指标,这里展示下如何在 Grafana 中根据这些指标来配置可视化图表。
1、添加图表
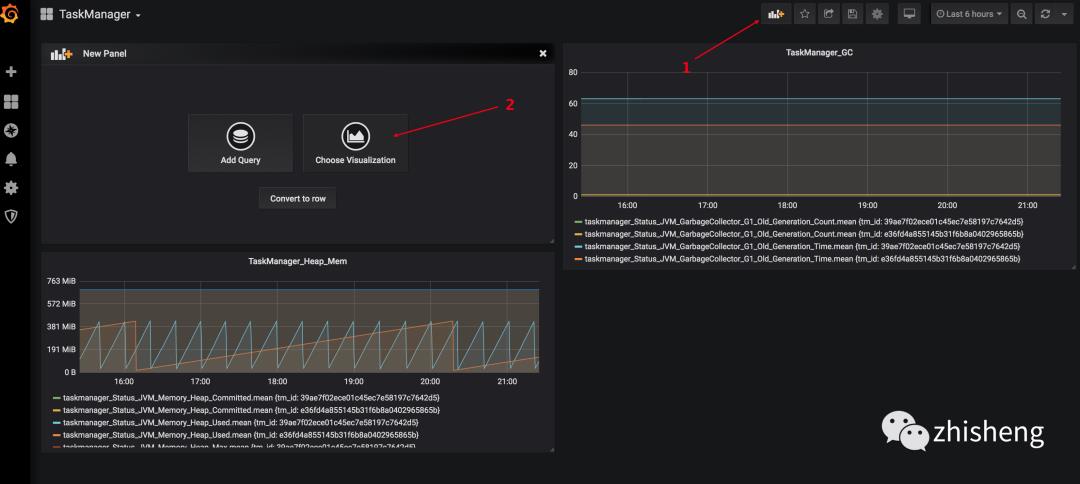
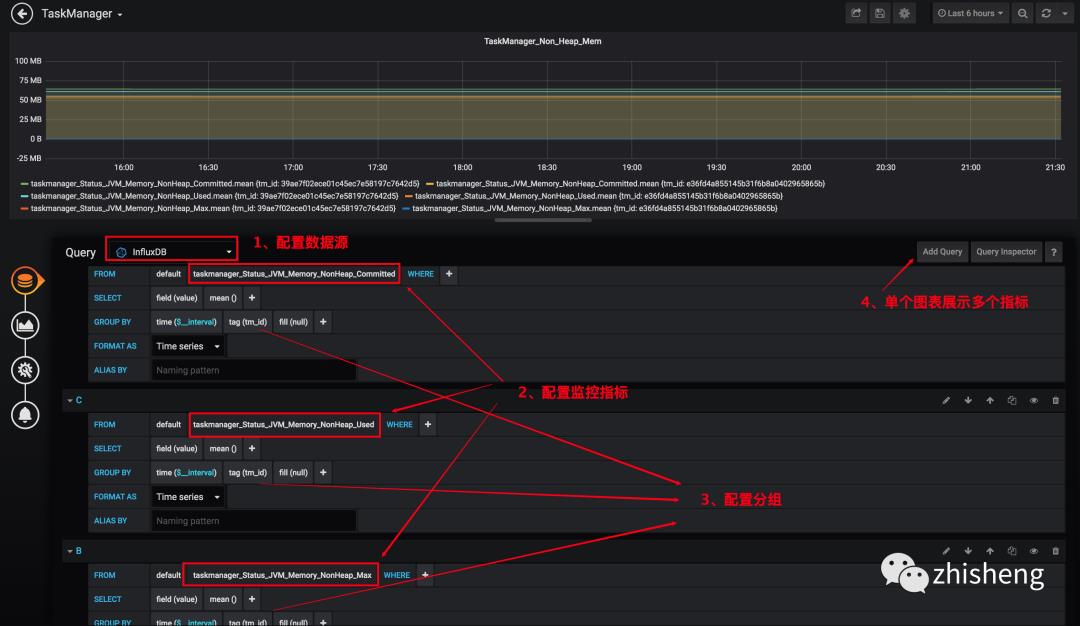
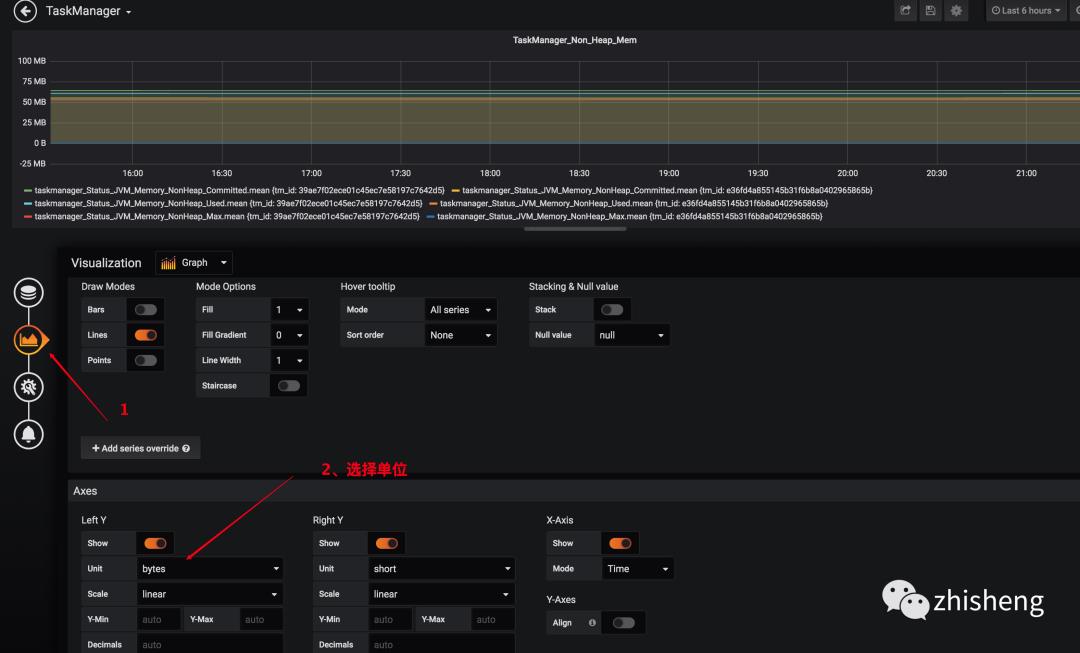
2、配置图表从哪个数据源获取数据、选择哪种指标、选择分组、选择单位、添加多个指标、图表命名
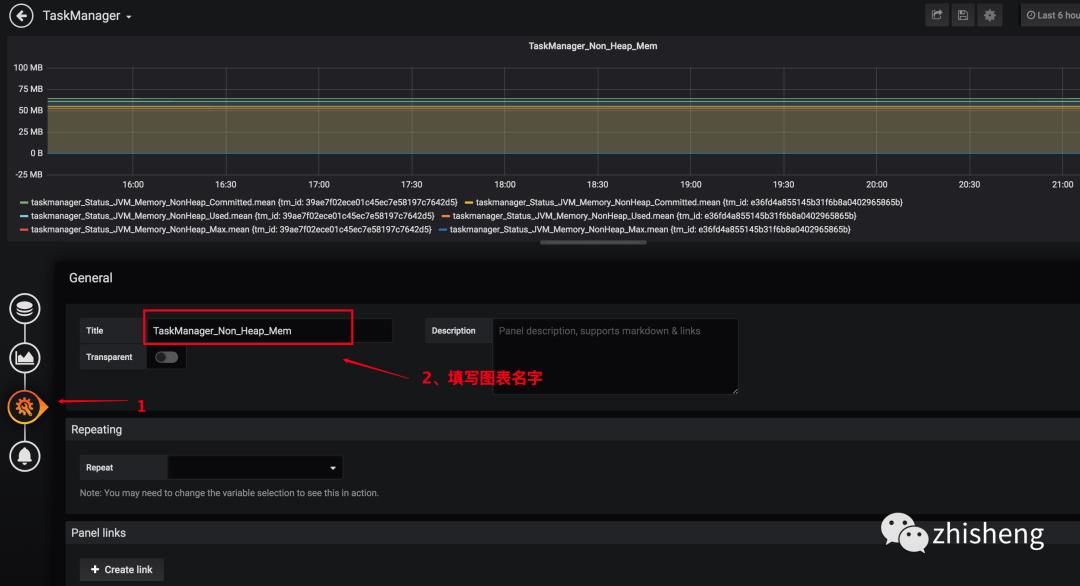
3、配置告警
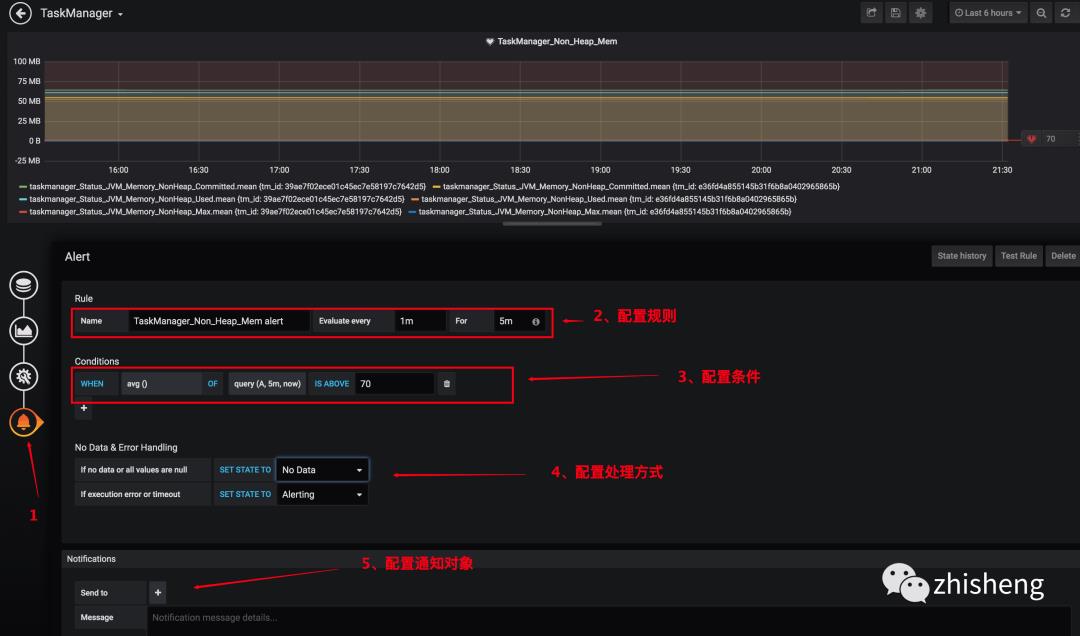
这样一个完整的监控图表就配置出来了,有些指标可能直接用数字展示就比较友好,另外还有就是要注意单位,大家可以好好琢磨研究一下 Grafana 的自定义可视化图表的配置,配置好了比较重要的监控指标之后,JobManager 和 TaskManager 的效果分别如下两图所示。
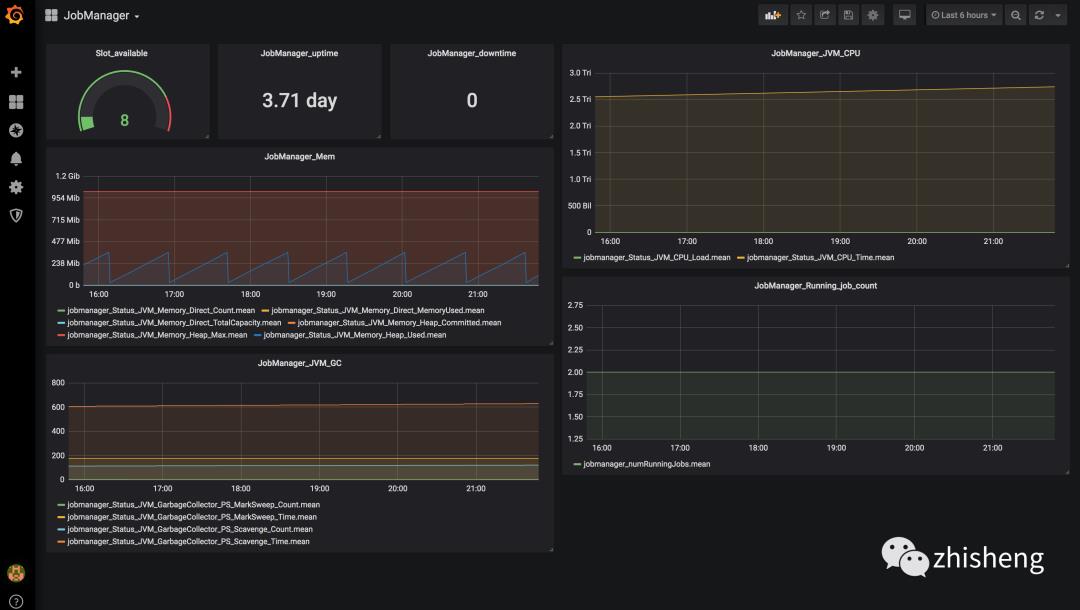
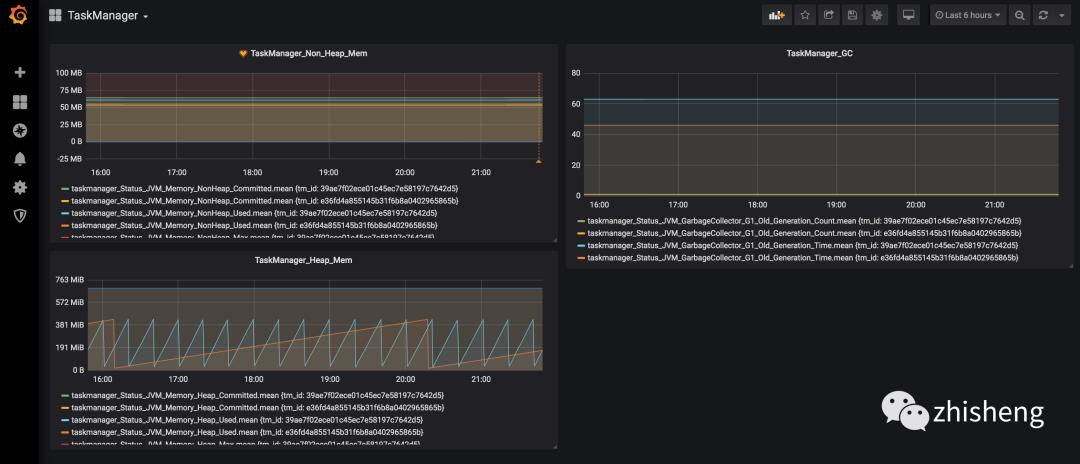
好了,一个 Flink 的监控系统已经完全搭建好了,从数据采集、数据存储、数据展示、告警整个链路都支持,可以适应大部分公司的场景了,如果还需要做更多的定制化,比如添加更多的监控指标,那么你可以在你的 Job 里面自定义 metrics 做埋点,然后还是通过 reporter 进行数据上报,最后依旧用 Grafana 配置图表展示。
小结与反思
本节讲了如何利用 API 去获取监控数据,对 Metrics 的类型进行介绍,然后还介绍了怎么利用 Reporter 去将 Metrics 数据进行上报,并通过 InfluxDB + Grafana 搭建了一套 Flink 的监控系统。另外你还可以根据公司的需要使用其他的存储方案来存储监控数据,Grafana 也支持不同的数据源,你们公司的监控系统架构是怎么样的,是否可以直接接入这套监控系统?
猜你喜欢1、面试必知的 Spark SQL 几种 Join 实现2、如何使用 Spark 3.0 中新加的 Structured Streaming UI 来进行异常分析3、Spark on K8S 的最佳实践和需要注意的坑4、基于Apache Iceberg打造T+0实时数仓
以上是关于从 0 到 1 搭建一套 Flink 的监控系统的主要内容,如果未能解决你的问题,请参考以下文章
实战手把手教你从 0 到 1 搭建一套 RocketMQ 集群