Hashtable与ConcurrentHashMap的区别
Posted 哔卟哔卟_: )
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hashtable与ConcurrentHashMap的区别相关的知识,希望对你有一定的参考价值。
HashTable与ConcurrentHashMap的区别
多线程下使用哈希表
(1)HashMap 线程不安全(不建议使用)
(2)Hashtable 线程安全(不建议使用)
(3)ConcurrentHashMap 线程安全(建议使用)
🔎Hashtable
Hashtable 只是简单的把关键方法加上了锁
如图
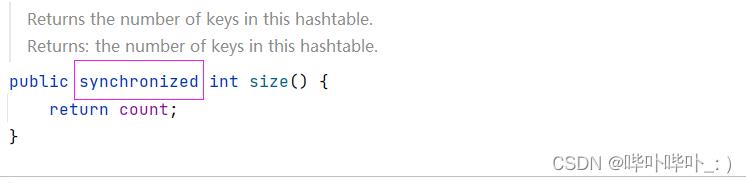
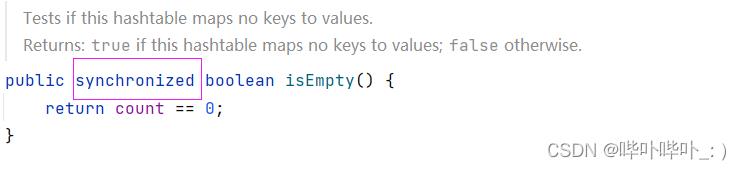


这相当于对Hashtable本身加锁
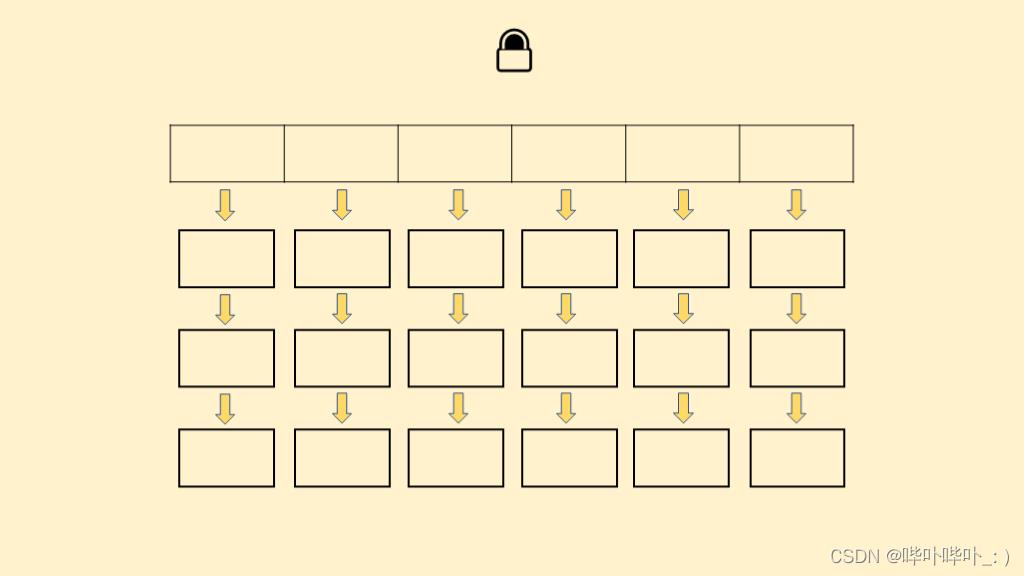
无论做什么都需要加锁
🔎ConcurrentHashMap
注意
ConcurrentHashMap 是JDK1.8引入的
ConcurrentHashMap 仍然是使用 synchronized 进行加锁
但不是锁住整个对象
而是用每个链表的头节点作为锁的对象
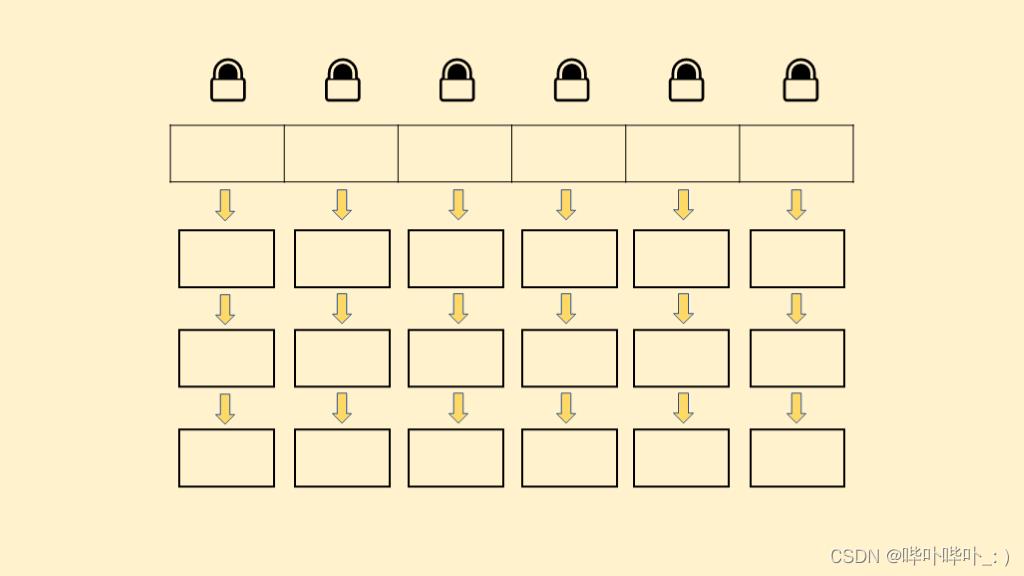
🔎区别
(1)加锁粒度不同
对于 Hashtable, 直接为整个哈希表加锁🥝
当多个线程插入多个不同的元素(多线程修改多个不同的变量)
线程1在下标1位置上插入元素
线程2在下标2位置上插入元素
这种操作不会引起线程安全问题, 但由于对整个哈希表都加了锁, 所以也会产生锁冲突
对于 ConcurrentHashMap, 将每个链表的头节点作为一把锁🥝
当多个线程插入多个不同的元素(多线程修改多个不同的变量)
线程1在下标1位置上插入元素
线程2在下标2位置上插入元素
由于将每个链表的头节点作为一把锁, 所以这种情况下不会产生锁冲突
(2)利用了CAS
对于 Hashtable🥝
size 属性通过 synchronized 操作更新(较慢)
对于 ConcurrentHashMap🥝
size 属性通过 CAS 更新(较快)
(3)扩容策略的调整
对于 Hashtable🥝
一旦触发扩容给操作, 就需要持有锁的线程完成整个扩容过程(将旧的元素搬运到新的内存空间, 搬运完毕将旧的内存空间释放), 该过程涉及到大量的元素拷贝, 效率较低
对于 ConcurrentHashMap🥝
化整为零
扩容操作不会一次性将所有元素全部搬运,而是只搬运一小部分
扩容时, 新旧空间同时存在
后续的线程也会执行上述操作, 直到将所有元素全部搬运完毕
由于每次只需要拷贝少量元素, 效率较高
(在扩容期间)
插入元素会插入在新开辟的内存空间
查找元素会同时查找新旧两块空间
删除元素会同时查找新旧两块空间,在哪块空间就删除哪块空间的元素
🔎结尾
创作不易,如果对您有帮助,希望您能点个免费的赞👍
大家有什么不太理解的,可以私信或者评论区留言,一起加油
HashMap与Hashtable
HashMap与Hashtable数据结构几乎是相同的(数组+链表),核心方法的实现也大致相同
主要讨论不同,比较两者不同从JDK源码入手
一、父类不同
HashMap父类AbstractMap
Hashtable父类Dictionary
Dictionary类源码已注释被弃用
Hashtable类源码注释也表明Hashtable已被淘汰
* Java Collections Framework</a>. Unlike the new collection * implementations, {@code Hashtable} is synchronized. If a * thread-safe implementation is not needed, it is recommended to use * {@link HashMap} in place of {@code Hashtable}. If a thread-safe * highly-concurrent implementation is desired, then it is recommended * to use {@link java.util.concurrent.ConcurrentHashMap} in place of * {@code Hashtable}.
// 如果你不需要线程安全,那么使用HashMap,如果需要线程安全,那么使用ConcurrentHashMap。HashTable已经被淘汰了,不要在新的代码中再使用它。
二、Synchronize
Hashtable是线程安全的,它的每个方法中都加入了Synchronize方法。
HashMap不是线程安全的,在多线程并发的环境下,使用HashMap时就必须要自己增加同步处理。
(虽然HashMap不是线程安全的,但是它的效率会比Hashtable要好很多。这样设计是合理的。在我们的日常使用当中,大部分时间是单线程操作的。HashMap把这部分操作解放出来了。当需要多线程操作的时候可以使用线程安全的ConcurrentHashMap。ConcurrentHashMap虽然也是线程安全的,但是它的效率比Hashtable要高好多倍。因为ConcurrentHashMap使用了分段锁,并不对整个数据进行锁定。)
三、初始容量和扩充容量
HashMap初始容量16,扩容默认为原来容量的2倍
Hashtable初始容量11,扩容默认为原来容量的2倍+1
四、hash值算法不同
HashMap: 具体原因可参考JDK源码学习笔记——HashMap
1.int hash = (h = key.hashCode()) ^ (h >>> 16) ;
2.int index = (table.length - 1) & hash;
3.tableSizeFor()方法保证数组容量一定是2的次幂
Hashtable:
1.int hash = key.hashCode();
2.int index = (hash & 0x7FFFFFFF) % tab.length;
五、put时的不同
1、HashMap支持key==null value==null,hash方法专门有对key==null的处理
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
Hashtable不支持null
public synchronized V put(K key, V value) { // Make sure the value is not null if (value == null) {// value==null抛异常 throw new NullPointerException(); } // Makes sure the key is not already in the hashtable. Entry<?,?> tab[] = table; int hash = key.hashCode();// key==null抛异常 int index = (hash & 0x7FFFFFFF) % tab.length; @SuppressWarnings("unchecked") Entry<K,V> entry = (Entry<K,V>)tab[index]; for(; entry != null ; entry = entry.next) { if ((entry.hash == hash) && entry.key.equals(key)) { V old = entry.value; entry.value = value; return old; } } addEntry(hash, key, value, index); return null; }
2、JDK1.8 HashMap引入了红黑树,链表超过最大长度(8),将链表改为红黑树再添加元素
3、hash碰撞之后的处理
HashMap:在链表尾加入元素
Hashtable:在链表头加入元素
参考资料:
以上是关于Hashtable与ConcurrentHashMap的区别的主要内容,如果未能解决你的问题,请参考以下文章