mysql调优排序优化,子查询优化
Posted 村东头老张
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql调优排序优化,子查询优化相关的知识,希望对你有一定的参考价值。
mysql调优
排序优化
-
消除using fileshort:
场景一:select id from table order by col1
为排序字段(col1)添加索引(索引本身是有序的)
场景二:select id form table order by col1,col2
错误的做法:给他们添加单列索引
正确的做法:给col1 和col2添加联合索引,顺序要跟排序order by后顺序一致
场景三:select id from table order by col1 asc,col2 desc
直接创建索引,默认都是升序,依然会using filesort
ALERT TABLE ta ADD INDEX idx_col1_col2(col1,col2)
解决方法是:创建索引的时候指定升降序(8版本才支持)
ALERT TABLE ta ADD INDEX idx_col1_col2(col1 asc,col2 desc)
以下sql是否能避免using filesort(idx_col1_col2(col1 ,col2 ,col3))
select id from table order by col2,col1,col3; 否
select id form table order by col1,col3; 否
一定要满足最左前缀原则
1 a x 1 a y 1 b x 1 b z 2 a y 2 a z 2 c x 2 c z select id from table where col1=100 order by col2
最好给col1 和 col2 加联合索引,条件不允许的情况下优先对col1添加索引,最大过滤数据
以下sql能不能避免using filesort:
select id from table where col1 in(100,102) order by col2; 否
select id from table where col1>=100 and col1<102 order by col2; 否
经过前面的条件筛选后排序字段都是无序的,只有col1 在具体等于某个值的情况下col2才是有序的。
场景四:select * from table order by col1,id limit 10000;
给col1添加索引后也不一定走索引排序,因为MySQL会考虑回表成本。
优化方式:
- order by 和select 字段加联合索引
- 采用手动回表的方式:
select a.* from table a inner join(select id from table order by col1,id limit 10000 )b on a.id=b.id;
mysql排序内存排序以及外部磁盘辅助进行排序,当sort buffer 一次装不下的情况下会写入文件,保证文件内部有序,然后采用归并算法让所有数据都有序。
排序方式:
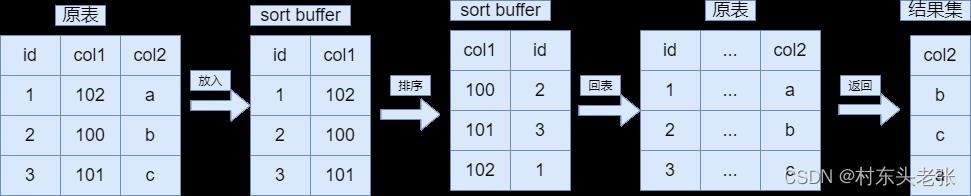
- rowid排序(双路排序):将排序字段和rowid(主键)组成键值对存入sort buffer因为取值和回表需要两次操作磁盘所以叫双路排序,好处就是占用sort buffer 小,坏处就是要回表
例子:select col2 from table order by col1;
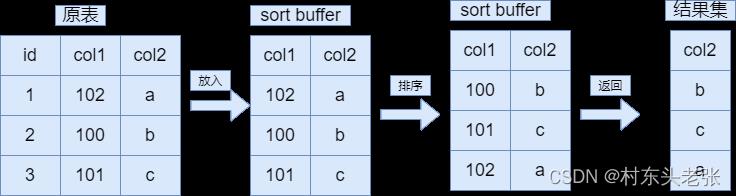
- 全字段排序:将排序的字段和需要返回的字段组成键值对,存入sort buffer,好处不需要回表,坏处占用sort buffer 多,更容易使用临时文件
- 打包全字段排序:全字段的改良,对查询字段进行压缩,以便于存放更多记录到sort buffer
sort_buffer_size:参数解释执行排序使用的缓冲大小
设置排序缓存命令:
查看参数值:show variable like ‘sort_buffer_size’;
修改参数的值:(session和global级别)
session sort_buffer_size = 1023*1024;
set global sort_buffer_size 1024*1024;
设置永久有效修改/etc/my.cnf
innodb_sort_buffer_size设置的是创建innodb索引时使用到的sort_buffer的大小,与排序无关。
max_length_for_sort_data:参数解释提供给用户控制排序算法的参数,8版本废除
返回列的总长度>max_length_for_sort_data ? rowid排序:全字段/打包全字段排序
查看参数值:show variables where variable_name ='max_length_for_sort_data' 默认1024字节
修改参数值:set max_length_for_sort_data=1024;
开优化器追踪命令
查看排序sql使用了哪种排序方式:optimizer trace
-
查询:
show variables where variable_name='optimizer_trace'; -
开启:
set optimizer_trace = ‘enable=on’; -
控制最多展示多少结果:
set optimizer_trace_limit =5; -
第一个要展示的optimizer_trace偏移量(默认1):
set optimizer_trace_offset=1; -
执行排序sql
-
查询追踪信息:
select *from INFORMATION_SCHEMA.OPTIMIZER_TRACE;
子查询优化
案例:
select * from orders where id in (select order_id from order_details where product_code =“xxx”)
外层每一行都对子查询进行调用 select_type(DEPENDENT SUBQUERY),8版本后对子查询会进行优化,第一次子查询的结果保存为临时表,后续对子查询的访问直接通过临时表获得,整个过程中对子查询只需要执行一次。
优化sql:
select t1.* from orders t1 inner join order_details t2 on t1.id=t2.order_id where t2.prodict_code=‘xxx’
添加索引:
联合索引 ADD INDEX idx_pcode_oid(prodict_code,order_id)
总结:
- 使用表连接替代子查询,尤其是子查询的结果集较大
- 添加符合索引及逆行优化,其中字段包含were条件字段与关联字段
- 符合索引中字段的顺序要遵循最左前缀原则
- mysql8 自动对子查询进行优化,性能接近表连接
- 尽量做到小表驱动大表
MySQL高级第八篇:关联查询子查询和排序相关优化
MySQL高级第八篇:关联查询、子查询和排序相关优化
一、关联查询的优化
情况1:左外连接(和右外连接相似)
- 对于左外连接来说:
SELECT SQL_NO_CACHE * FROM a LEFT JOIN b ON a.字段 = b.字段;
- 如果不加索引,他们两个表都会进行全表扫描,MySQL会自动使用上
缓存提高效率。 - 如果只添加一个索引,一定要
给被驱动表,也就是 b 表加, 因为 a 为主表,无论加与不加都会全部查询出来。 - 但 a,b 表的那俩条件字段一定要相同类型,否则
类型转换会导致索引失效。
情况2:内连接
SELECT SQL_NO_CACHE * FROM a INNER JOIN b ON a.字段 = b.字段;
- 对于内连接来说,查询优化器可以决定谁作为驱动表,谁作为被驱动表出现的
- 如果表的连接条件中只能有一个字段有索引,则有索引的字段所在的表会被作为被驱动表出现。
- 在两个表的连接条件都存在索引的情况下,会选择小表作为驱动表。
小表驱动大表
JOIN 语句原理
- JOIN 方式连接多个表,本质是各个表之间数据的
循环匹配。 - MySQL5.5版本之前,MySQL只支持一种表间关联方式,就是
嵌套循环(Nested Loop Join)。如果关联表的数据量很大,则 JOIN 关联的执行时间会非常长。 - 在MySQL5.5以后的版本中,MySQL通过引入BNLJ算法来优化嵌套执行。
如下:
- 驱动表就是主表,被驱动表就是从表、非驱动表。
- 简单嵌套循环
- 两个表都没有索引,每次从主表A取一条数据,遍历从表B匹配,将匹配到的数据放到 result
- 索引嵌套循环
- 其优化的思路主要是
为了减少内层表数据的匹配次数,所以要求被驱动表上必须有索引才行。 - 通过外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每条记录去进行比较,这样极大的减少了对内层表的匹配次数。
- 如果被驱动表加索引,效率是非常高的,但如果索引不是主键索引,所以还得进行一次
回表查询。相比,被驱动表的索引是主键索引,效率会更高。
- 其优化的思路主要是
- 块嵌套循环连接
- 如果存在索引,那么会使用index的方式进行join,如果join的列没有索引,被驱动表要扫描的次数太多了。每次访问被驱动表,其表中的记录都会被加载到内存中,然后再从驱动表中取一条与其匹配,匹配结束后清除内存,然后再从驱动表中加载一条记录,然后把被驱动表的记录在加载到内存匹配,这样周而复始,
大大增加了1O的次数。 - 为了减少被驱动表的IO次数,就出现了块嵌套循环连接的方式。
不再是逐条获取驱动表的数据,而是一块一块的获取,引入了join buffer缓冲区,将驱动表join相关的部分数
据列大小缓存到join bufferr中,然后全表扫描被驱动表,被驱动表的每一条记录一次性和join buffer中的所有驱动表记录进行匹配(内存中操作),将简单嵌套循环中的多次比较合并成一次,降低了被驱动表的访问频率。

缓存时不光缓存关联表的列,select 的列也会缓存起来,所以,查询时尽量减少不必要的字段。
注意:小表驱动大表的含义——小的结果集驱动大的结果集,为了减少内存循环次数。
- 如果存在索引,那么会使用index的方式进行join,如果join的列没有索引,被驱动表要扫描的次数太多了。每次访问被驱动表,其表中的记录都会被加载到内存中,然后再从驱动表中取一条与其匹配,匹配结束后清除内存,然后再从驱动表中加载一条记录,然后把被驱动表的记录在加载到内存匹配,这样周而复始,
从MySQL8.0开始,废弃了BNLJ(块嵌套查询),加入了 hash join,hash join是大数据集连接时的常用方式,但他只能应用于等值连接。
二、子查询优化
-
使用子查询可以进行SELECT语句的
嵌套查询,即一个SELECT查询的结果作为另一个SELECT语句的条件。 -
子查询可以
一次性完成很多逻辑上需要多个步骤才能完成的SQL操作。 -
子查询是MySQL的一项重要的功能,可以帮助我们通过一个SQL语句实现比较复杂的查询。但是,子查询的执行效率不高。原因:
- ①执行子查询时,MySQL需要为内层查询语句的查询结果建立一个
临时表,然后外层查询语句从临时表中查询记录。查询完毕后,再撤销这些临时表。这样会消耗更多的CPU和I/O资源,产生大量的慢查询。 - ②子查询的结果集存储的临时表,
不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响。 - ③对于返回结果集比较大的子查询,其对查询性能的影响也就越大。
- ①执行子查询时,MySQL需要为内层查询语句的查询结果建立一个
-
在MySQL中,可以使用连接(JOIN)查询来替代子查询。
连接查询不需要建立临时表,其速度比子查询要快,如果查询中使用索引的话,性能就会更好。
三、排序相关优化
问题:WHERE条件上加了索引,为什么还要在 ORDER BY字段加索引?
- 在MySQL中,支持两种排序方式,分别是
FileSort 和 Index排序。 - lndex排序中,索引可以保证数据的有序性,不需要再进行排序,效率更高。
- FileSort排序则一般在内存中进行排序,占用CPU较多。如果待排结果较大,会产生临时文件I/O到磁盘进行排序的情况,效率较低。
优化建议:
- 1.SQL中,可以在 WHERE 子句 和 ORDER BY 子句中使用索引,目的是
在 WHERE 子句中避免全表扫描,在ORDER BY子句避免使用 FileSort 排序。 - 2.尽量使用 Index 完成 ORDER BY 排序。如果 WHERE 和 ORDER BY 后面是相同的列就使用单索引列,如果不同就使用联合索引。
- 3.无法使用lndex时,需要对 FileSort 方式进行调优。
例子:

其实具体是否使用索引,还是由优化器根据数据量计算决定的,我们添加索引,最起码是提供了一种方案。
总之,在两个索引同时存在时,MySQL会自动选择最优的方案,但是,随着数据量的变化,选择的索引也会随之变化。
当 范围条件 和 GROUP BY 或者 ORDER BY 字段出现二选一时,优先观察条件字段的过滤数量,如果过滤的足够多,而需要排序的数据不多时,优先把索引放在范围字段,反之亦然。
四、GROUP BY 注意事项
- group by使用索引的原则几乎跟order by一致,group by即使没有过滤条件用到索引,也可以直接使用索引。
- group by
先排序再分组,遵照索引建的最佳左前缀法则 where效率高于having,能写在where限定的条件就不要写在having中了- 减少使用order by,
能不排序就不排序,或将排序放到程序端去做。Order by、group by、distinct 这些语句较为耗费CPU,数据库的CPU资源是极其宝贵的。 - 包含了order by、group by、distinct这些查询的语句,where条件过滤出来的结果集请
保持在1000行以内,否则SQL会很慢。
以上是关于mysql调优排序优化,子查询优化的主要内容,如果未能解决你的问题,请参考以下文章