聚合查询越来越慢?——详解Elasticsearch的Global Ordinals与High Cardinality
Posted Mr-Bruce
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聚合查询越来越慢?——详解Elasticsearch的Global Ordinals与High Cardinality相关的知识,希望对你有一定的参考价值。
Elasticsearch中的概念很多,本文将从笔者在实践过程中遇到的问题出发,逐步详细介绍 Global Ordinals 和 High Cardinality ,这也是笔者的认知过程。文中的Elasticsearch 版本为5.5。
背景
故事是这样的,因为业务需要,我们在项目中设计了一种针对Elasticsearch数据的异步去重方法(注:关于Elasticsearch数据去重,笔者会在另一篇博文中更加详细介绍),基本思路是:
- 为每一条数据计算hash值,作为document的一个字段(keyword类型)插入到Elasticsearch中,数据格式简化如下:
"timestamp": 1540099182,
"msgType": 1210,
......
"hash": "31a2c683dccb83ef8b8d1ee43290df62"
- 每隔一段时间,运行一次检测脚本,检查Elasticsearch中的数据是否有重复,相关查询语句如下(这里,terms聚合用于发现给定时间范围内是否有超过2条hash值一样的数据,top_hits聚合用于找出重复数据组中的具体数据信息,然后删除掉重复的数据即可):
"size": 0,
"query":
"bool":
"filter": [
"range":
"timestamp":
"gte": 1540087200,
"lt": 1540087500
]
,
"aggs":
"duplications":
"terms":
"field": "hash",
"min_doc_count": 2,
"size": 500
,
"aggs":
"top_duplications":
"top_hits":
"size": 3
这样一个方案,因为只是在数据集中增加了一个hash字段,并且去重是异步的,不会影响到原有的设计,所以在通过相关的功能性测试后就上线了。然而,运行一段时间后,出现了严重问题:
- 随着新数据的写入,上述的查询语句变得越来越慢,从秒级逐步变成要20多秒,并且在数据量超过10亿条后,每次查询都会使内存超过80%;
- index的存储空间比原先增加了近一倍
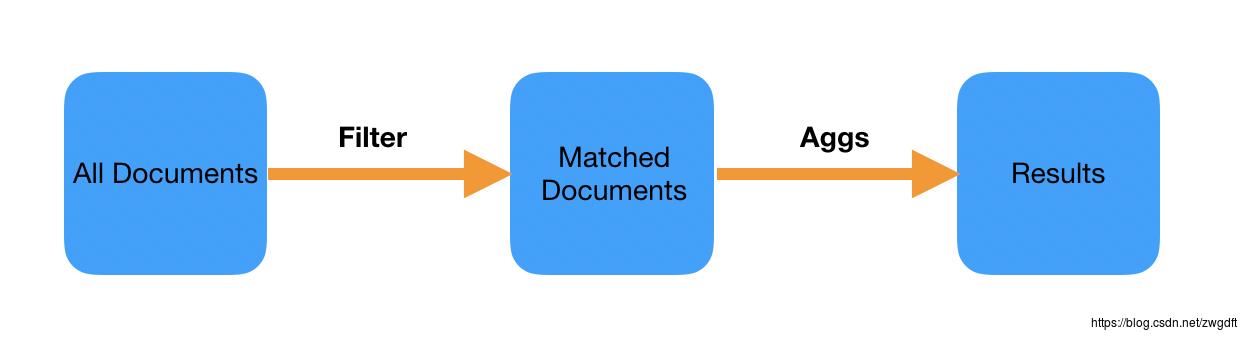
对于类似上述的查询语句,Elasticsearch会先根据Filter条件找出匹配的document,然后再进行聚合运算。在我们的业务中,每次查询2小时内的数据,并且数据的写入是匀速的,这意味着每次匹配出来的document个数基本是固定的,那么为何会出现这个查询越来越慢的问题?而且,我们发现,即使Filter匹配的document个数为0,也同样需要很久才能返回结果。
另一方面,经过对比验证,可以确定是新增加的hash字段导致了数据存储空间比原先增加了近一倍。
带着这些问题,笔者进行了详细的调研,最终锁定Global Ordinals与High Cardinality两个核心概念。其中,github上面的一个issue Terms aggregation speed is proportional to field cardinality 给了很大的启发。
Global Ordinals
什么是Ordinals?
假设有10亿条数据,每条数据有一个字段status(keyword类型),其值有三种可能性:status_pending、status_published、status_deleted,那么每条数据至少需要14-16 Bytes,也就是说需要将近15GB内存才能装下所有数据。
Doc | Term
-------------------------------
0 | status_pending
1 | status_deleted
2 | status_published
3 | status_pending
为了减少内存使用,考虑将字符串排序后进行编号,形成一张映射表,然后在每条数据中使用相应字符串的序号来表示。通过这样的设计,可以将所需内存从15 GB减少为1 GB左右。
这里的映射表,或者说映射表中的序号,就是Ordinals。
Ordinal | Term
-------------------------------
0 | status_deleted
1 | status_pending
2 | status_published
Doc | Ordinal
-------------------------------
0 | 0 # deleted
1 | 2 # published
2 | 1 # pending
3 | 0 # deleted
什么是Global Ordinals?
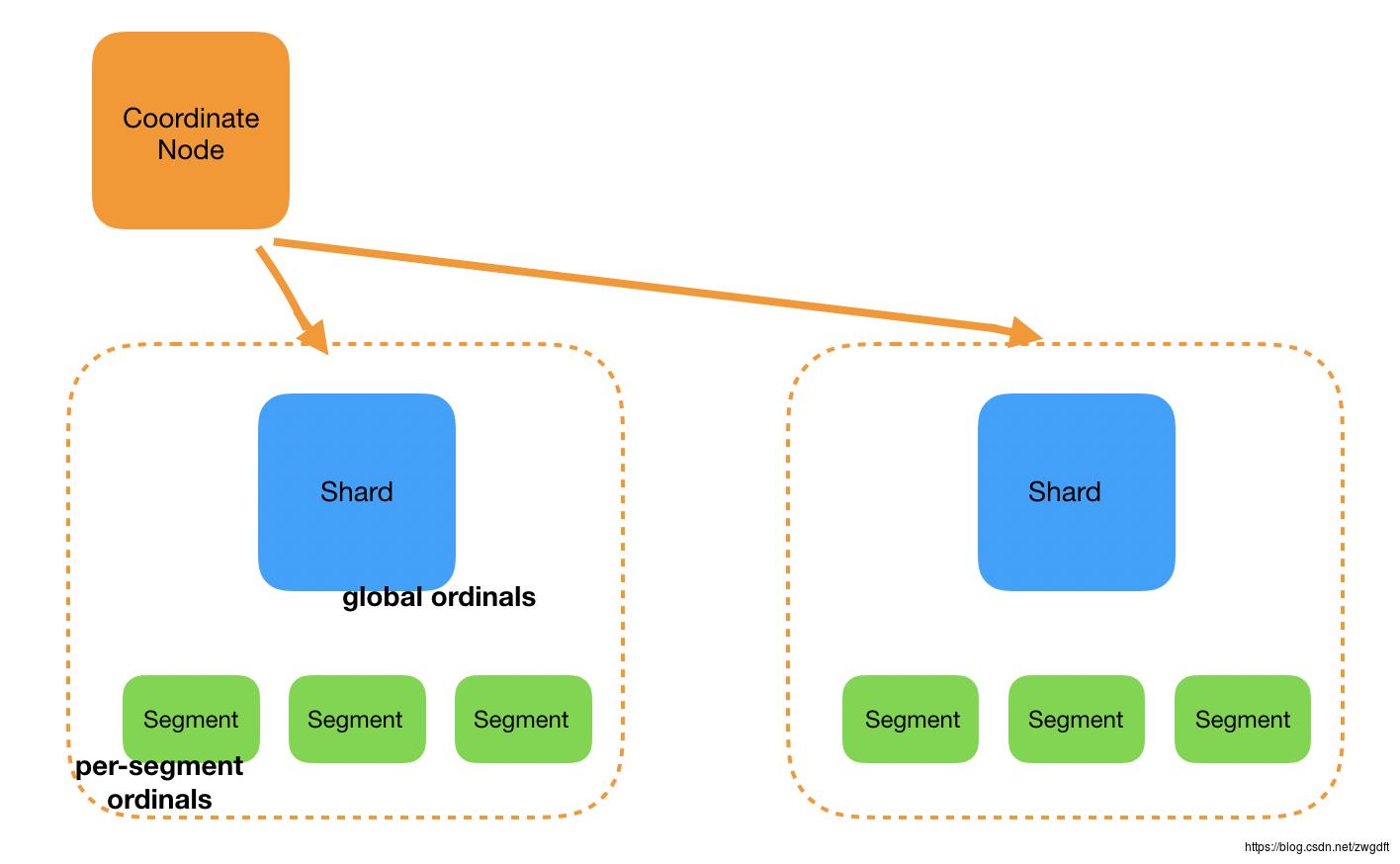
当我们对status字段做Terms聚合查询时,请求会透过Coordinate Node分散到Shard所在的Node中执行,而针对每个Shard的查询又会分散到多个Segment中去执行。
上述的Ordinals是per-segment ordinals,是针对每个Segment里面的数据而言,意味着同一个字符串在不同的per-segment ordinals中可能对应的序号是不同的。比如,在Segment 1中只有status_deleted(0)和status_published(1)两个值,而Segment 2中有3个值:status_deleted(0),status_pending(1),status_published(2)。
这样就面临一个抉择:方案一,在完成per-segment的查询后,将相应的序号转换成字符串,返回到Shard层面进行合并;方案二,构建一个Shard层面的Global Ordinals,实现与per-segment ordinals的映射,就可以在Shard层面完成聚合后再转换成字符串。
经过权衡,Elasticsearch(Lucene)选择了方案二作为默认方法:构建Global Ordinals。
为何会影响聚合查询?
构建Global Ordinals的目的是为了减少内存使用、加快聚合统计,在大多数情况下其表现出来的性能都非常好。之所以会影响到查询性能,与其构建时机有关:
- 由于Global Ordinals是Shard级别的,因此当一个Shard的Segment发生变动时就需要重新构建Global Ordinals,比如有新数据写入导致产生新的Segment、Segment Merge等情况。当然,如果Segment没有变动,那么构建一次后就可以一直利用缓存了(适用于历史数据)。
- 默认情况下,Global Ordinals是在收到聚合查询请求并且该查询会命中相关字段时构建,而构建动作是在查询最开始做的,即在Filter之前。
这样的构建方式,在遇到某个字段的值种类很多(即下文所述的High Cardinary问题)时会变的非常慢,会严重影响聚合查询速度,即使Filter出来的document很少也需要花费很久,也就是上文笔者遇到的问题,即在High Cardinary情况下,构建Global Ordinals非常慢。因为我们新加的hash字段对于每条数据都不一样,所以当写入越来越多的数据后,聚合查询越来越慢(大概超过5000W条之后)。
有哪些优化方法?
虽然在Lucene 7.1中,针对global ordinals的构建有些优化(LUCENE-7905),但是仍然不能避免这样的问题。目前有这样几种优化方法(或者说是缓解之法,目前尚未发现完美的方法):
- 增加Shard个数。因为Global Ordinals是Shard层面的,增加Shard个数也许可以缓解问题,前提是:第一,要能确定有问题的字段的值种类可以通过该方式减少在单个Shard中的量;第二,确保Shard的个数增加不会影响到整体的性能。
- 延长refresh interval,即减少构建Global Ordinals的次数来缓解其影响,前提是要能接受数据的非实时性。
- 修改execution_hint的值。在Terms聚合中,可以设置执行方式是map还是global_ordinals,前者的意思是直接使用该字段的字符串值来做聚合,即无需构建Global Ordinals。这样的方式,适用于可以确定匹配文档数据量的场景,并且不会引起内存的暴增,比如在笔者的业务场景中,每次只查询2小时内的数据量。这也是当前我们的优化方法。
GET /_search
"aggs" :
"tags" :
"terms" :
"field" : "status",
"execution_hint": "map"
High Cardinality
相信看完上文,读者已经知道什么是High Cardinality了。所谓High Cardinality,指的是Large Number of Unique Values,即某个字段的值有很多很多种,比如笔者业务中的那个hash字段。在Elasticsearch,High Cardinality会带来各种问题,百害而无一利,所以应该尽量避免,避免不了也要做到心中有数,在出问题时可以及时调整。
- High Cardinality会导致构建Global Ordinals过程变慢,从而导致聚合查询变慢、内存使用过高。
- High Cardinality会导致压缩比率降低,从而导致存储空间增加,特别是像hash值这样完全随机的字符串。
- 对High Cardinality字段执行Cardinality聚合查询时,会受到精度控制从而导致结果不精确。
本文结合笔者在实践过程中遇到的由High Cardinality引起Global Ordinals构建过慢,从而导致聚合查询变慢的问题,阐述了Global Ordinals和High Cardinality两个核心概念,希望对遇到类似问题的人有所帮助。目前,针对我们的业务场景,相关的调整有:第一,使用"execution_hint": "map"来避免构建Global Ordinals;第二,尝试在数据上传端增加对压缩友好的唯一键来作为去重对象,比如uuid4;第三,减小index的切割时间,比如从weekly index变成daily index,从而降低index中单个shard的数据量。
(全文完,本文地址:https://blog.csdn.net/zwgdft/article/details/83215977 )
(版权声明:本人拒绝不规范转载,所有转载需征得本人同意,并且不得更改文字与图片内容。大家相互尊重,谢谢!)
Bruce
2018/10/22 下午
以上是关于聚合查询越来越慢?——详解Elasticsearch的Global Ordinals与High Cardinality的主要内容,如果未能解决你的问题,请参考以下文章