长春前端薪资水平大分析
Posted Mr_CrazyPeter
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了长春前端薪资水平大分析相关的知识,希望对你有一定的参考价值。
背景介绍
去年就发了一篇长春的前端工资分析,可以看这里。
如今过了一年,在2022年的今天
再测一次,看看大环境变的怎么样了

数据分析
数据来源和采集方法
数据内容来自身边人都喜欢用的"Bxx聘",对平台上的数据最熟悉,同时参照了其他的渠道(”如猎xx“),总体差异不大。
所有的工作都是通过javascript进行的,以下是技术清单
* 数据是通过headless浏览器来采集
* 数据处理:因为各个项目比较零碎,直接使用了js原生功能,并没有使用框架
* 可视化视图 Echarts
* 无头浏览器操作框架是puppeteer
* 页面解析cheerio
对于应用的技术大就大概这么一介绍,咱们主要还是看数据。
薪资待遇
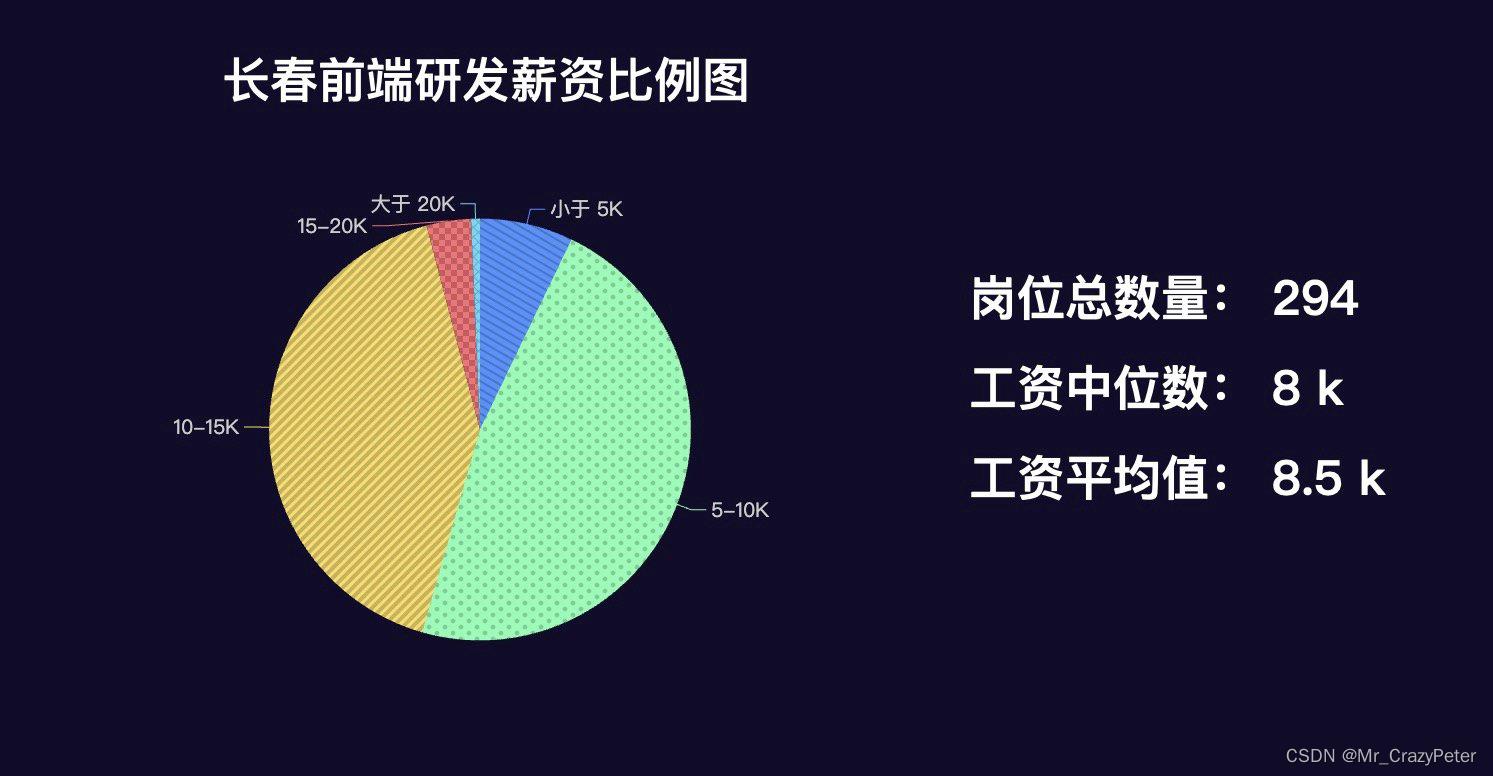
这个数据相当稳定啊,和去年基本一致
平均值就是北京那边的一半
所以北上广深回东北的同学们,在薪资待遇上做好平衡
从岗位需求数量上看并不多,一共294个
侧面印证了长春是个“抬头不见低头见”的地方
大家换工作的时候都悠着点
来来回回可能还得回自己公司

地区分布
地图影响力的权重设置如下:
职位工资>10k 权重1.2
职位工资<10k 权重1
职位工资>15 权重1.5
各地区权重值总加和。
因为各个区的给高新企业的扶植政策不同,
IT产业有着明显的集聚现象,而且重心偏南
和去年数据不同的是
散点增多,小微企业的量起来了
大家如果要找工作的话,还是需要考虑通勤,综合考虑
公司行业类型
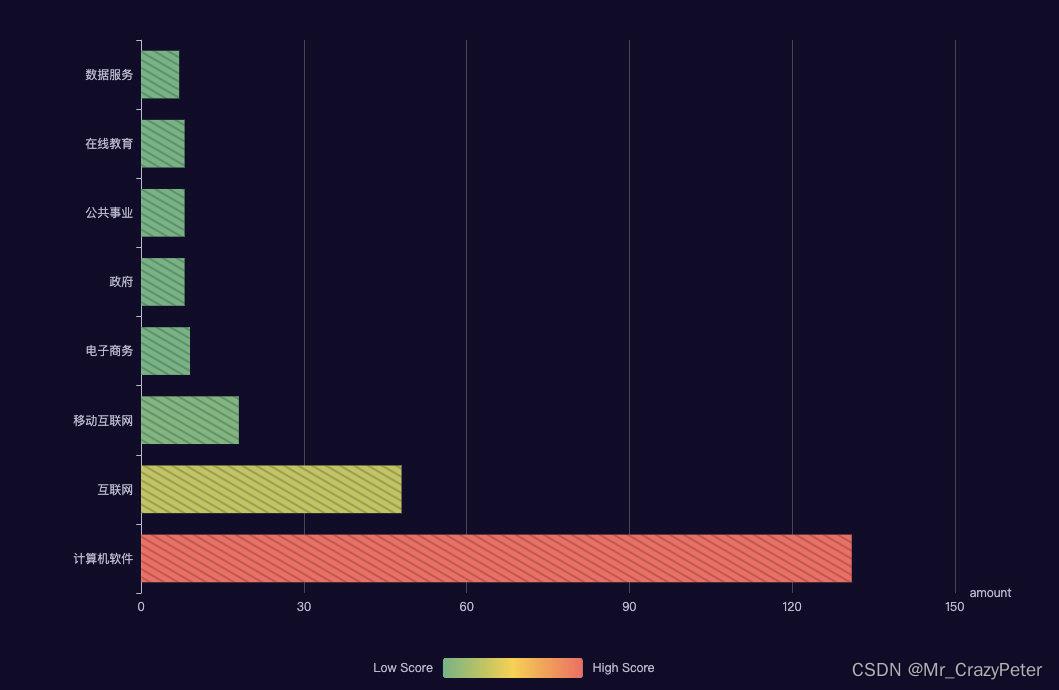
剔除了占比比较少的数据
行业分类和其他地区比起来相对单一一些
因为长春的互联网公司很少,IT开发基本都是软件服务为主
所以数据看起来比较极端。
公司福利

这里是公司给出的福利标签做的统计,不以实际情况为主。就IT行业的加班情况,敢在公司详情页说明“偶尔加班”的,就算是良心了。
最大的三个标签是:五险一金 节日福利 带薪年假
这三个吧写了约等于没写
技能要求

可以看到,现在前端工作基本都要求ES6了。
框架要求最多的就是Vue了
和去年相比,移动端需求的比例下降
小程序冒头的数量越来越多了
不知道各位对小程序的技术栈了解的如何
简短总结
数据上就是这样了,希望大家能对市场有个大致的了解。
新人不易,欢迎大家强势关注,长春本地技术公众号 - 阿丰在长春━(`∀´)ノ亻!

另外最近疫情又起,大家出门一定要小心哦。
数据挖掘的10大分析方法
不仅仅是选中的十大算法,其实参加评选的18种算法,实际上随便拿出一种来都可以称得上是经典算法,它们在数据挖掘领域都产生了极为深远的影响。
C4.5算法是机器学习算法中的一种分类决策树算法,其核心算法是ID3算法.C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进:
1)用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;
2)在树构造过程中进行剪枝;
3)能够完成对连续属性的离散化处理;
4)能够对不完整数据进行处理。
C4.5算法有如下优点:产生的分类规则易于理解,准确率较高。其缺点是:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。
k-meansalgorithm算法是一个聚类算法,把n的对象根据他们的属性分为k个分割
支持向量机,英文为SupportVectorMachine,简称SV机(论文中一般简称SVM)。它是一种监督式学习的方法,它广泛的应用于统计分类以及回归分析中。支持向量机将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面。分隔超平面使两个平行超平面的距离最大化。假定平行超平面间的距离或差距越大,分类器的总误差越小。一个极好的指南是C.J.CBurges的《模式识别支持向量机指南》。vanderWalt和Barnard将支持向量机和其他分类器进行了比较。
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。其核心是基于两阶段频集思想的递推算法。该关联规则在分类上属于单维、单层、布尔关联规则。在这里,所有支持度大于最小支持度的项集称为频繁项集,简称频集。
在统计计算中,最大期望(EM,Expectation–Maximization)算法是在概率(probabilistic)模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量(LatentVariabl)。最大期望经常用在机器学习和计算机视觉的数据集聚(DataClustering)领域。
PageRank是Google算法的重要内容。2001年9月被授予美国专利,专利人是Google创始人之一拉里·佩奇(LarryPage)。因此,PageRank里的page不是指网页,而是指佩奇,即这个等级方法是以佩奇来命名的。
PageRank根据网站的外部链接和内部链接的数量和质量俩衡量网站的价值。
PageRank背后的概念是,每个到页面的链接都是对该页面的一次投票,被链接的越多,就意味着被其他网站投票越多。这个就是所谓的“链接流行度”——衡量多少人愿意将他们的网站和你的网站挂钩。PageRank这个概念引自学术中一篇论文的被引述的频度——即被别人引述的次数越多,一般判断这篇论文的权威性就越高。
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。其算法本身是通过改变数据分布来实现的,它根据每次训练集之中每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改过权值的新数据集送给下层分类器进行训练,最后将每次训练得到的分类器最后融合起来,作为最后的决策分类器。
K最近邻(k-NearestNeighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
在众多的分类模型中,应用最为广泛的两种分类模型是决策树模型(DecisionTreeModel)和朴素贝叶斯模型(NaiveBayesianModel,NBC)。朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响。在属性个数比较多或者属性之间相关性较大时,NBC模型的分类效率比不上决策树模型。而在属性相关性较小时,NBC模型的性能最为良好。
CART,ClassificationandRegressionTrees。在分类树下面有两个关键的思想。第一个是关于递归地划分自变量空间的想法;第二个想法是用验证数据进行剪枝。
在大数据时代,数据挖掘是最关键的工作。大数据的挖掘是从海量、不完全的、有噪声的、模糊的、随机的大型数据库中发现隐含在其中有价值的、潜在有用的信息和知识的过程,也是一种决策支持过程。其主要基于人工智能,机器学习,模式学习,统计学等。通过对大数据高度自动化地分析,做出归纳性的推理,从中挖掘出潜在的模式,可以帮助企业、商家、用户调整市场政策、减少风险、理性面对市场,并做出正确的决策。目前,在很多领域尤其是在商业领域如银行、电信、电商等,数据挖掘可以解决很多问题,包括市场营销策略制定、背景分析、企业管理危机等。大数据的挖掘常用的方法有分类、回归分析、聚类、关联规则、神经网络方法、Web 数据挖掘等。这些方法从不同的角度对数据进行挖掘。
(1)分类。分类是找出数据库中的一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到摸个给定的类别中。可以应用到涉及到应用分类、趋势预测中,如淘宝商铺将用户在一段时间内的购买情况划分成不同的类,根据情况向用户推荐关联类的商品,从而增加商铺的销售量。
(2)回归分析。回归分析反映了数据库中数据的属性值的特性,通过函数表达数据映射的关系来发现属性值之间的依赖关系。它可以应用到对数据序列的预测及相关关系的研究中去。在市场营销中,回归分析可以被应用到各个方面。如通过对本季度销售的回归分析,对下一季度的销售趋势作出预测并做出针对性的营销改变。
(3)聚类。聚类类似于分类,但与分类的目的不同,是针对数据的相似性和差异性将一组数据分为几个类别。属于同一类别的数据间的相似性很大,但不同类别之间数据的相似性很小,跨类的数据关联性很低。
(4)关联规则。关联规则是隐藏在数据项之间的关联或相互关系,即可以根据一个数据项的出现推导出其他数据项的出现。关联规则的挖掘过程主要包括两个阶段:第一阶段为从海量原始数据中找出所有的高频项目组;第二阶段为从这些高频项目组产生关联规则。关联规则挖掘技术已经被广泛应用于金融行业企业中用以预测客户的需求,各银行在自己的ATM 机上通过捆绑客户可能感兴趣的信息供用户了解并获取相应信息来改善自身的营销。
(5)神经网络方法。神经网络作为一种先进的人工智能技术,因其自身自行处理、分布存储和高度容错等特性非常适合处理非线性的以及那些以模糊、不完整、不严密的知识或数据为特征的处理问题,它的这一特点十分适合解决数据挖掘的问题。典型的神经网络模型主要分为三大类:第一类是以用于分类预测和模式识别的前馈式神经网络模型,其主要代表为函数型网络、感知机;第二类是用于联想记忆和优化算法的反馈式神经网络模型,以Hopfield 的离散模型和连续模型为代表。第三类是用于聚类的自组织映射方法,以ART 模型为代表。虽然神经网络有多种模型及算法,但在特定领域的数据挖掘中使用何种模型及算法并没有统一的规则,而且人们很难理解网络的学习及决策过程。
(6)Web数据挖掘。Web数据挖掘是一项综合性技术,指Web 从文档结构和使用的集合C 中发现隐含的模式P,如果将C看做是输入,P 看做是输出,那么Web 挖掘过程就可以看做是从输入到输出的一个映射过程。
当前越来越多的Web 数据都是以数据流的形式出现的,因此对Web 数据流挖掘就具有很重要的意义。目前常用的Web数据挖掘算法有:PageRank算法,HITS算法以及LOGSOM 算法。这三种算法提到的用户都是笼统的用户,并没有区分用户的个体。目前Web 数据挖掘面临着一些问题,包括:用户的分类问题、网站内容时效性问题,用户在页面停留时间问题,页面的链入与链出数问题等。在Web 技术高速发展的今天,这些问题仍旧值得研究并加以解决。
(分析方法):
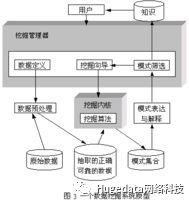
· 分类 (Classification)
· 估计(Estimation)
· 预测(Prediction)
· 相关性分组或关联规则(Affinity grouping or association rules)
· 聚类(Clustering)
· 描述和可视化(Description and Visualization)
· 复杂数据类型挖掘(Text, Web ,图形图像,视频,音频等)
以上七种数据挖掘的分析方法可以分为两类:直接数据挖掘;间接数据挖掘
· 直接数据挖掘
目标是利用可用的数据建立一个模型,这个模型对剩余的数据,对一个特定的变量(可以理解成数据库中表的属性,即列)进行描述。
· 间接数据挖掘
目标中没有选出某一具体的变量,用模型进行描述;而是在所有的变量中建立起某种关系 。
· 分类、估值、预言属于直接数据挖掘;后四种属于间接数据挖掘
·分类 (Classification)
首先从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术,建立分类模型,对于没有分类的数据进行分类。
例子:
a. 信用卡申请者,分类为低、中、高风险
b. 故障诊断:中国宝钢集团与上海天律信息技术有限公司合作,采用数据挖掘技术对钢材生产的全流程进行质量监控和分析,构建故障地图,实时分析产品出现瑕疵的原因,有效提高了产品的优良率。
注意: 类的个数是确定的,预先定义好的
· 估计(Estimation)
估计与分类类似,不同之处在于,分类描述的是离散型变量的输出,而估值处理连续值的输出;分类
的类别是确定数目的,估值的量是不确定的。
例子:
a. 根据购买模式,估计一个家庭的孩子个数
b. 根据购买模式,估计一个家庭的收入
c. 估计real estate的价值
一般来说,估值可以作为分类的前一步工作。给定一些输入数据,通过估值,得到未知的连续变量的值,然后,根据预先设定的阈值,进行分类。例如:银行对家庭贷款业务,运用估值,给各个客户记分(Score 0~1)。然后,根据阈值,将贷款级别分类。
· 预测(Prediction)
通常,预测是通过分类或估值起作用的,也就是说,通过分类或估值得出模型,该模型用于对未知变量的预言。从这种意义上说,预言其实没有必要分为一个单独的类。预言其目的是对未来未知变量的预测,这种预测是需要时间来验证的,即必须经过一定时间后,才知道预言准确性是多少。
· 相关性分组或关联规则(Affinity grouping or association rules)
决定哪些事情将一起发生。
例子:
a. 超市中客户在购买A的同时,经常会购买B,即A => B(关联规则)
b. 客户在购买A后,隔一段时间,会购买B (序列分析)
· 聚类(Clustering)
聚类是对记录分组,把相似的记录在一个聚集里。聚类和分类的区别是聚集不依赖于预先定义好的类,不需要训练集。
例子:
a. 一些特定症状的聚集可能预示了一个特定的疾病
b. 租VCD类型不相似的客户聚集,可能暗示成员属于不同的亚文化群
聚集通常作为数据挖掘的第一步。例如,"哪一种类的促销对客户响应最好?",对于这一 类问题,首先对整个客户做聚集,将客户分组在各自的聚集里,然后对每个不同的聚集,回答问题,可能效果更好。
· 描述和可视化(Description and Visualization)
是对数据挖掘结果的表示方式。一般只是指数据可视化工具,包含报表工具和商业智能分析产品(BI)的统称。譬如通过Yonghong Z-Suite等工具进行数据的展现,分析,钻取,将数据挖掘的分析结果更形象,深刻的展现出来。
1.C4.5:是机器学习算法中的一种分类决策树算法,其核心算法是ID3算法。
2. K-means算法:是一种聚类算法。
3.SVM:一种监督式学习的方法,广泛运用于统计分类以及回归分析中
4.Apriori :是一种最有影响的挖掘布尔关联规则频繁项集的算法。
5.EM:最大期望值法。
6.pagerank:是google算法的重要内容。
7. Adaboost:是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器然后把弱分类器集合起来,构成一个更强的最终分类器。
8.KNN:是一个理论上比较成熟的的方法,也是最简单的机器学习方法之一。
9.Naive Bayes:在众多分类方法中,应用最广泛的有决策树模型和朴素贝叶斯(Naive Bayes)
10.Cart:分类与回归树,在分类树下面有两个关键的思想,第一个是关于递归地划分自变量空间的想法,第二个是用验证数据进行减枝。
需要是发明之母。近年来,数据挖掘引起了信息产业界的极大关注,其主要原因是存在大量数据,可以广泛使用,并且迫切需要将这些数据转换成有用的信息和知识。获取的信息和知识可以广泛用于各种应用,包括商务管理,生产控制,市场分析,工程设计和科学探索等。
数据挖掘利用了来自如下一些领域的思想:
(1) 来自统计学的抽样、估计和假设检验,
(2) 人工智能、模式识别和机器学习的搜索算法、建模技术和学习理论。数据挖掘也迅速地接纳了来自其他领域的思想,这些领域包括最优化、进化计算、信息论、信号处理、可视化和信息检索。一些其他领域也起到重要的支撑作用。特别地,需要数据库系统提供有效的存储、索引和查询处理支持。源于高性能(并行)计算的技术在处理海量数据集方面常常是重要的。分布式技术也能帮助处理海量数据,并且当数据不能集中到一起处理时更是至关重要。
折叠编辑本段其他资料
折叠数据挖掘中的关联规则
折叠什么是关联规则
在描述有关关联规则的一些细节之前,我们先来看一个有趣的故事: "尿布与啤酒"的故事。
数据关联是数据库中存在的一类重要的可被发现的知识。若两个或多个变量的取值之间存在某种规律性,就称为关联。关联可分为简单关联、时序关联、因果关联。关联分析的目的是找出数据库中隐藏的关联网。有时并不知道数据库中数据的关联函数,即使知道也是不确定的,因此关联分析生成的规则带有可信度。关联规则挖掘发现大量数据中项集之间有趣的关联或相关联系。Agrawal等于1993年首先提出了挖掘顾客交易数据库中项集间的关联规则问题,以后诸多的研究人员对关联规则的挖掘问题进行了大量的研究。他们的工作包括对原有的算法进行优化,如引入随机采样、并行的思想等,以提高算法挖掘规则的效率;对关联规则的应用进行推广。关联规则挖掘在数据挖掘中是一个重要的课题,最近几年已被业界所广泛研究。
关联规则挖掘过程主要包含两个阶段:第一阶段必须先从资料集合中找出所有的高频项目组(FrequentItemsets),第二阶段再由这些高频项目组中产生关联规(Association Rules)。
关联规则挖掘的第一阶段必须从原始资料集合中,找出所有高频项目组(Large Itemsets)。高频的意思是指某一项目组出现的频率相对于所有记录而言,必须达到某一水平。一项目组出现的频率称为支持度(Support),以一个包含A与B两个项目的2-itemset为例,我们可以经由公式(1)求得包含{A,B}项目组的支持度,若支持度大于等于所设定的最小支持度(Minimum Support)门槛值时,则{A,B}称为高频项目组。一个满足最小支持度的k-itemset,则称为高频k-项目组(Frequent k-itemset),一般表示为Large k或Frequent k。算法并从Large k的项目组中再产生Large k+1,直到无法再找到更长的高频项目组为止。
关联规则挖掘的第二阶段是要产生关联规则(Association Rules)。从高频项目组产生关联规则,是利用前一步骤的高频k-项目组来产生规则,在最小信赖度(Minimum Confidence)的条件门槛下,若一规则所求得的信赖度满足最小信赖度,称此规则为关联规则。例如:经由高频k-项目组{A,B}所产生的规则AB,其信赖度可经由公式(2)求得,若信赖度大于等于最小信赖度,则称AB为关联规则。
就沃尔马案例而言,使用关联规则挖掘技术,对交易资料库中的纪录进行资料挖掘,首先必须要设定最小支持度与最小信赖度两个门槛值,在此假设最小支持度min_support=5% 且最小信赖度min_confidence=70%。因此符合此该超市需求的关联规则将必须同时满足以上两个条件。若经过挖掘过程所找到的关联规则「尿布,啤酒」,满足下列条件,将可接受「尿布,啤酒」的关联规则。用公式可以描述Support(尿布,啤酒)>=5%且Confidence(尿布,啤酒)>=70%。其中,Support(尿布,啤酒)>=5%于此应用范例中的意义为:在所有的交易纪录资料中,至少有5%的交易呈现尿布与啤酒这两项商品被同时购买的交易行为。Confidence(尿布,啤酒)>=70%于此应用范例中的意义为:在所有包含尿布的交易纪录资料中,至少有70%的交易会同时购买啤酒。因此,今后若有某消费者出现购买尿布的行为,超市将可推荐该消费者同时购买啤酒。这个商品推荐的行为则是根据「尿布,啤酒」关联规则,因为就该超市过去的交易纪录而言,支持了“大部份购买尿布的交易,会同时购买啤酒”的消费行为。
从上面的介绍还可以看出,关联规则挖掘通常比较适用与记录中的指标取离散值的情况。如果原始数据库中的指标值是取连续的数据,则在关联规则挖掘之前应该进行适当的数据离散化(实际上就是将某个区间的值对应于某个值),数据的离散化是数据挖掘前的重要环节,离散化的过程是否合理将直接影响关联规则的挖掘结果。
按照不同情况,关联规则可以进行分类如下:
1.基于规则中处理的变量的类别,关联规则可以分为布尔型和数值型。
布尔型关联规则处理的值都是离散的、种类化的,它显示了这些变量之间的关系;而数值型关联规则可以和多维关联或多层关联规则结合起来,对数值型字段进行处理,将其进行动态的分割,或者直接对原始的数据进行处理,当然数值型关联规则中也可以包含种类变量。例如:性别=“女”=>职业=“秘书” ,是布尔型关联规则;性别=“女”=>avg(收入)=2300,涉及的收入是数值类型,所以是一个数值型关联规则。
2.基于规则中数据的抽象层次,可以分为单层关联规则和多层关联规则。
在单层的关联规则中,所有的变量都没有考虑到现实的数据是具有多个不同的层次的;而在多层的关 联规则中,对数据的多层性已经进行了充分的考虑。例如:IBM台式机=>Sony打印机,是一个细节数据上的单层关联规则;台式机=>Sony打印机,是一个较高层次和细节层次之间的多层关联规则。
3.基于规则中涉及到的数据的维数,关联规则可以分为单维的和多维的。
在单维的关联规则中,我们只涉及到数据的一个维,如用户购买的物品;而在多维的关联规则中,要处理的数据将会涉及多个维。换成另一句话,单维关联规则是处理单个属性中的一些关系;多维关联规则是处理各个属性之间的某些关系。例如:啤酒=>尿布,这条规则只涉及到用户的购买的物品;性别=“女”=>职业=“秘书”,这条规则就涉及到两个字段的信息,是两个维上的一条关联规则。
1.Apriori算法:使用候选项集找频繁项集
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。其核心是基于两阶段频集思想的递推算法。该关联规则在分类上属于单维、单层、布尔关联规则。在这里,所有支持度大于最小支持度的项集称为频繁项集,简称频集。
该算法的基本思想是:首先找出所有的频集,这些项集出现的频繁性至少和预定义的最小支持度一样。然后由频集产生强关联规则,这些规则必须满足最小支持度和最小可信度。然后使用第1步找到的频集产生期望的规则,产生只包含集合的项的所有规则,其中每一条规则的右部只有一项,这里采用的是中规则的定义。一旦这些规则被生成,那么只有那些大于用户给定的最小可信度的规则才被留下来。为了生成所有频集,使用了递推的方法。
可能产生大量的候选集,以及可能需要重复扫描数据库,是Apriori算法的两大缺点。
2.基于划分的算法
Savasere等设计了一个基于划分的算法。这个算法先把数据库从逻辑上分成几个互不相交的块,每次单独考虑一个分块并对它生成所有的频集,然后把产生的频集合并,用来生成所有可能的频集,最后计算这些项集的支持度。这里分块的大小选择要使得每个分块可以被放入主存,每个阶段只需被扫描一次。而算法的正确性是由每一个可能的频集至少在某一个分块中是频集保证的。该算法是可以高度并行的,可以把每一分块分别分配给某一个处理器生成频集。产生频集的每一个循环结束后,处理器之间进行通信来产生全局的候选k-项集。通常这里的通信过程是算法执行时间的主要瓶颈;而另一方面,每个独立的处理器生成频集的时间也是一个瓶颈。
3.FP-树频集算法
针对Apriori算法的固有缺陷,J. Han等提出了不产生候选挖掘频繁项集的方法:FP-树频集算法。采用分而治之的策略,在经过第一遍扫描之后,把数据库中的频集压缩进一棵频繁模式树(FP-tree),同时依然保留其中的关联信息,随后再将FP-tree分化成一些条件库,每个库和一个长度为1的频集相关,然后再对这些条件库分别进行挖掘。当原始数据量很大的时候,也可以结合划分的方法,使得一个FP-tree可以放入主存中。实验表明,FP-growth对不同长度的规则都有很好的适应性,同时在效率上较之Apriori算法有巨大的提高。
同时,一些知名的电子商务站点也从强大的关联规则挖掘中的受益。这些电子购物网站使用关联规则中规则进行挖掘,然后设置用户有意要一起购买的捆绑包。也有一些购物网站使用它们设置相应的交叉销售,也就是购买某种商品的顾客会看到相关的另外一种商品的广告。
但是目前在我国,“数据海量,信息缺乏”是商业银行在数据大集中之后普遍所面对的尴尬。目前金融业实施的大多数数据库只能实现数据的录入、查询、统计等较低层次的功能,却无法发现数据中存在的各种有用的信息,譬如对这些数据进行分析,发现其数据模式及特征,然后可能发现某个客户、消费群体或组织的金融和商业兴趣,并可观察金融市场的变化趋势。可以说,关联规则挖掘的技术在我国的研究与应用并不是很广泛深入。
由于许多应用问题往往比超市购买问题更复杂,大量研究从不同的角度对关联规则做了扩展,将更多的因素集成到关联规则挖掘方法之中,以此丰富关联规则的应用领域,拓宽支持管理决策的范围。如考虑属性之间的类别层次关系,时态关系,多表挖掘等。近年来围绕关联规则的研究主要集中于两个方面,即扩展经典关联规则能够解决问题的范围,改善经典关联规则挖掘算法效率和规则兴趣性。
一个经常问的问题是,数据挖掘和OLAP到底有何不同。下面将会解释,他们是完全不同的工具,基于的技术也大相径庭。
OLAP是决策支持领域的一部分。传统的查询和报表工具是告诉你数据库中都有什么(what happened),OLAP则更进一步告诉你下一步会怎么样(What next)、和如果我采取这样的措施又会怎么样(What if)。用户首先建立一个假设,然后用OLAP检索数据库来验证这个假设是否正确。比如,一个分析师想找到什么原因导致了贷款拖欠,他可能先做一个初始的假定,认为低收入的人信用度也低,然后用OLAP来验证他这个假设。如果这个假设没有被证实,他可能去察看那些高负债的账户,如果还不行,他也许要把收入和负债一起考虑,一直进行下去,直到找到他想要的结果或放弃。
也就是说,OLAP分析师是建立一系列的假设,然后通过OLAP来证实或推翻这些假设来最终得到自己的结论。OLAP分析过程在本质上是一个演绎推理的过程。但是如果分析的变量达到几十或上百个,那么再用OLAP手动分析验证这些假设将是一件非常困难和痛苦的事情。
数据挖掘与OLAP不同的地方是,数据挖掘不是用于验证某个假定的模式(模型)的正确性,而是在数据库中自己寻找模型。他在本质上是一个归纳的过程。比如,一个用数据挖掘工具的分析师想找到引起贷款拖欠的风险因素。数据挖掘工具可能帮他找到高负债和低收入是引起这个问题的因素,甚至还可能发现一些分析师从来没有想过或试过的其他因素,比如年龄。
数据挖掘和OLAP具有一定的互补性。在利用数据挖掘出来的结论采取行动之前,你也许要验证一下如果采取这样的行动会给公司带来什么样的影响,那么OLAP工具能回答你的这些问题。
而且在知识发现的早期阶段,OLAP工具还有其他一些用途。可以帮你探索数据,找到哪些是对一个问题比较重要的变量,发现异常数据和互相影响的变量。这都能帮你更好的理解你的数据,加快知识发现的过程。
数据挖掘利用了人工智能(AI)和统计分析的进步所带来的好处。这两门学科都致力于模式发现和预测。
数据挖掘不是为了替代传统的统计分析技术。相反,他是统计分析方法学的延伸和扩展。大多数的统计分析技术都基于完善的数学理论和高超的技巧,预测的准确度还是令人满意的,但对使用者的要求很高。而随着计算机计算能力的不断增强,我们有可能利用计算机强大的计算能力只通过相对简单和固定的方法完成同样的功能。
一些新兴的技术同样在知识发现领域取得了很好的效果,如神经元网络和决策树,在足够多的数据和计算能力下,他们几乎不用人的关照自动就能完成许多有价值的功能。
数据挖掘就是利用了统计和人工智能技术的应用程序,他把这些高深复杂的技术封装起来,使人们不用自己掌握这些技术也能完成同样的功能,并且更专注于自己所要解决的问题。
使数据挖掘这件事情成为可能的关键一点是计算机性能价格比的巨大进步。在过去的几年里磁盘存储器的价格几乎降低了99%,这在很大程度上改变了企业界对数据收集和存储的态度。如果每兆的价格是¥10,那存放1TB的价格是¥10,000,000,但当每兆的价格降为1毛钱时,存储同样的数据只有¥100,000!
计算机计算能力价格的降低同样非常显著。每一代芯片的诞生都会把CPU的计算能力提高一大步。内存RAM也同样降价迅速,几年之内每兆内存的价格由几百块钱降到现在只要几块钱。通常PC都有64M内存,工作站达到了256M,拥有上G内存的服务器已经不是什么新鲜事了。
在单个CPU计算能力大幅提升的同时,基于多个CPU的并行系统也取得了很大的进步。目前几乎所有的服务器都支持多个CPU,这些SMP服务器簇甚至能让成百上千个CPU同时工作。
基于并行系统的数据库管理系统也给数据挖掘技术的应用带来了便利。如果你有一个庞大而复杂的数据挖掘问题要求通过访问数据库取得数据,那么效率最高的办法就是利用一个本地的并行数据库。
所有这些都为数据挖掘的实施扫清了道路,随着时间的延续,我们相信这条道路会越来越平坦。
折叠NO.1DataMining和统计分析有什么不同?
硬要去区分Data Mining和Statistics的差异其实是没有太大意义的。一般将之定义为Data Mining技术的CART、CHAID或模糊计算等等理论方法,也都是由统计学者根据统计理论所发展衍生,换另一个角度看,Data Mining有相当大的比重是由高等统计学中的多变量分析所支撑。但是为什么Data Mining的出现会引发各领域的广泛注意呢?主要原因在相较于传统统计分析而言,Data Mining有下列几项特性:
1.处理大量实际数据更强势,且无须太专业的统计背景去使用Data Mining的工具;
2.数据分析趋势为从大型数据库抓取所需数据并使用专属计算机分析软件,Data Mining的工具更符合企业需求;
3. 纯就理论的基础点来看,Data Mining和统计分析有应用上的差别,毕竟Data Mining目的是方便企业终端用户使用而非给统计学家检测用的。
折叠NO.2数据仓库和数据挖掘的关系为何?
若将Data Warehousing(数据仓库)比喻作矿坑,Data Mining就是深入矿坑采 矿的工作。毕竟Data Mining不是一种无中生有的魔术,也不是点石成金的炼金术,若没有够丰富完整的数据,是很难期待Data Mining能挖掘出什么有意义的信息的。
要将庞大的数据转换成为有用的信息,必须先有效率地收集信息。随着科技的进步,功能完善的数据库系统就成了最好的收集数据的工具。数据仓库,简单地说,就是搜集来自其它系统的有用数据,存放在一整合的储存区内。所以其实就是一个经过处理整合,且容量特别大的关系型数据库,用以储存决策支持系统(Decision Support System)所需的数据,供决策支持或数据分析使用。从信息技术的角度来看,数据仓库的目标是在组织中,在正确的时间,将正确的数据交给正确的人。
许多人对于Data Warehousing和Data Mining时常混淆,不知如何分辨。其实,数据仓库是数据库技术的一个新主题,利用计算机系统帮助我们操作、计算和思考,让作业方式改变,决策方式也跟着改变。
数据仓库本身是一个非常大的数据库,它储存着由组织作业数据库中整合而来的数据,特别 是指事务处理系统OLTP(On-Line Transactional Processing)所得来的数据。将这些整合过的数据置放于数据仓库中,而公司的决策者则利用这些数据作决策;但是,这个转换及整合数据的过程,是建立一个数据仓库最大的挑战。因为将作业中的数据转换成有用的的策略性信息是整个数据仓库的重点。综上所述,数据仓库应该具有这些数据:整合性数据(integrated data)、详细和汇总性的数据(detailed and summarized data)、历史数据、解释数据的数据。从数据仓库挖掘出对决策有用的信息与知识,是建立数据仓库与使用Data Mining的最大目的,两者的本质与过程是两回事。换句话说,数据仓库应先行建立完成,Data mining才能有效率的进行,因为数据仓库本身所含数据是干净(不会有错误的数据参杂其中)、完备,且经过整合的。因此两者关系或许可解读为Data Mining是从巨大数据仓库中找出有用信息的一种过程与技术。

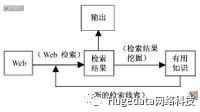
大部分情况下,数据挖掘都要先把数据从数据仓库中拿到数据挖掘库或数据集市中(见图1)。
从数据仓库中直接得到进行数据挖掘的数据有许多好处。就如我们后面会讲到的,数据仓库的数据清理和数据挖掘的数据清理差不多,如果数据在导入数据仓库时已经清理过,那很可能在做数据挖掘时就没必要在清理一次了,而且所有的数据不一致的问题都已经被你解决了。
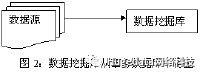
数据挖掘库可能是你的数据仓库的一个逻辑上的子集,而不一定非得是物理上单独的数据库。但如果你的数据仓库的计算资源已经很紧张,那你最好还是建立一个单独的数据挖掘库。
当然为了数据挖掘你也不必非得建立一个数据仓库,数据仓库不是必需的。建立一个巨大的数据仓库,把各个不同源的数据统一在一起,解决所有的数据冲突问题,然后把所有的数据导到一个数据仓库内,是一项巨大的工程,可能要用几年的时间花上百万的钱才能完成。只是为了数据挖掘,你可以把一个或几个事务数据库导到一个只读的数据库中,就把它当作数据集市,然后在他上面进行数据挖掘。
折叠NO.3OLAP能不能代替DataMining?
所谓OLAP(Online Analytical Process)意指由数据库所连结出来的在线分析处理程序。有些人会说:「我已经有OLAP的工具了,所以我不需要Data Mining。」事实上两者间是截然不同的,主要差异在于Data Mining用在产生假设,OLAP则用于查证假设。简单来说,OLAP是由使用者所主导,使用者先有一些假设,然后利用OLAP来查证假设是否成立;而Data Mining则是用来帮助使用者产生假设。所以在使用OLAP或其它Query的工具时,使用者是自己在做探索(Exploration),但Data Mining是用工具在帮助做探索。
举个例子来看,一市场分析师在为超市规划货品架柜摆设时,可能会先假设婴儿尿布和婴儿奶粉会是常被一起购买的产品,接着便可利用OLAP的工具去验证此假设是否为真,又成立的证据有多明显;但Data Mining则不然,执行Data Mining的人将庞大的结帐数据整理后,并不需要假设或期待可能的结果,透过Mining技术可找出存在于数据中的潜在规则,于是我们可能得到例如尿布和啤酒常被同时购买的意料外之发现,这是OLAP所做不到的。
Data Mining常能挖掘出超越归纳范围的关系,但OLAP仅能利用人工查询及可视化的报表来确认某些关系,是以Data Mining此种自动找出甚至不会被怀疑过的数据模型与关系的特性,事实上已超越了我们经验、教育、想象力的限制,OLAP可以和Data Mining互补,但这项特性是Data Mining无法被OLAP取代的。
折叠NO.4完整的DataMining包含哪些步骤?
1、数据挖掘环境
数据挖掘是指一个完整的过程,该过程从大型数据库中挖掘先前未知的,有效的,可实用的信息,并使用这些信息做出决策或丰富知识. 数据挖掘环境可示意如下图:
2、数据挖掘过程图
下图描述了数据挖掘的基本过程和主要步骤
数据挖掘的基本过程和主要步骤
3、数据挖掘过程工作量
在数据挖掘中被研究的业务对象是整个过程的基础,它驱动了整个数据挖掘过程,也是检验最后结果和指引分析人员完成数据挖掘的依据和顾问.图2各步骤是按一定顺序完成的,当然整个过程中还会存在步骤间的反馈.数据挖掘的过程并不是自动的,绝大多数的工作需要人工完成.图3给出了各步骤在整个过程中的工作量之比.可以看到,60%的时间用在数据准备上,这说明了数据挖掘对数据的严格要求,而后挖掘工作仅占总工作量的10%.
图3数据挖掘过程工作量比例
4、数据挖掘过程简介
过程中各步骤的大体内容如下:
(1). 确定业务对象
清晰地定义出业务问题,认清数据挖掘的目的是数据挖掘的重要一步.挖掘的最后结构是不可预测的,但要探索的问题应是有预见的,为了数据挖掘而数据挖掘则带有盲目性,是不会成功的.
(2). 数据准备
1)、数据的选择
搜索所有与业务对象有关的内部和外部数据信息,并从中选择出适用于数据挖掘应用的数据.
2)、数据的预处理
研究数据的质量,为进一步的分析作准备.并确定将要进行的挖掘操作的类型.
3)、数据的转换
将数据转换成一个分析模型.这个分析模型是针对挖掘算法建立的.建立一个真正适合挖掘算法的分析模型是数据挖掘成功的关键.
(3). 数据挖掘
对所得到的经过转换的数据进行挖掘.除了完善从选择合适的挖掘算法外,其余一切工作都能自动地完成.
(4). 结果分析
解释并评估结果.其使用的分析方法一般应作数据挖掘操作而定,通常会用到可视化技术.
(5). 知识的同化
将分析所得到的知识集成到业务信息系统的组织结构中去.
5、数据挖掘需要的人员
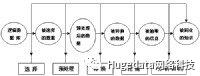
数据挖掘过程的分步实现,不同的步会需要是有不同专长的人员,他们大体可以分为三类.
业务分析人员:要求精通业务,能够解释业务对象,并根据各业务对象确定出用于数据定义和挖掘算法的业务需求.
数据分析人员:精通数据分析技术,并对统计学有较熟练的掌握,有能力把业务需求转化为数据挖掘的各步操作,并为每步操作选择合适的技术.
数据管理人员:精通数据管理技术,并从数据库或数据仓库中收集数据.
从上可见,数据挖掘是一个多种专家合作的过程,也是一个在资金上和技术上高投入的过程.这一过程要反复进行牞在反复过程中,不断地趋近事物的本质,不断地优先问题的解决方案。数据重组和细分添加和拆分记录选取数据样本可视化数据探索聚类分析神经网络、决策树数理统计、时间序列结论综合解释评价数据知识数据取样数据探索数据调整模型化评价。
折叠NO.5DataMining运用了哪些理论与技术?
Data Mining是近年来数据库应用技术中相当热门的议题,看似神奇、听来时髦,实际上却也不是什么新东西,因其所用之诸如预测模型、数据分割,连结分析(Link Analysis)、偏差侦测(Deviation Detection)等,美国早在二次世界大战前就已应用运用在人口普查及军事等方面。
随着信息科技超乎想象的进展,许多新的计算机分析工具问世,例如关系型数据库、模糊计算理论、基因算法则以及类神经网络等,使得从数据中发掘宝藏成为一种系统性且可实行的程序。
一般而言,Data Mining的理论技术可分为传统技术与改良技术两支。传统技术以统计分析为代表,统计学内所含序列统计、概率论、回归分析、类别数据分析等都属于传统数据挖掘技术,尤其 Data Mining 对象多为变量繁多且样本数庞大的数据,是以高等统计学里所含括之多变量分析中用来精简变量的因素分析(Factor Analysis)、用来分类的判别分析(Discriminant Analysis),以及用来区隔群体的分群分析(Cluster Analysis)等,在Data Mining过程中特别常用。
在改良技术方面,应用较普遍的有决策树理论(Decision Trees)、类神经网络(Neural Network)以及规则归纳法(Rules Induction)等。决策树是一种用树枝状展现数据受各变量的影响情形之预测模型,根据对目标变量产生之效应的不同而建构分类的规则,一般多运用在对客户数据的分析上,例如针对有回函与未回含的邮寄对象找出影响其分类结果的变量组合,常用分类方法为CART(Classification and Regression Trees)及CHAID(Chi-Square Automatic Interaction Detector)两种。
类神经网络是一种仿真人脑思考结构的数据分析模式,由输入之变量与数值中自我学习并根据学习经验所得之知识不断调整参数以期建构数据的型样(patterns)。类神经网络为非线性的设计,与传统回归分析相比,好处是在进行分析时无须限定模式,特别当数据变量间存有交互效应时可自动侦测出;缺点则在于其分析过程为一黑盒子,故常无法以可读之模型格式展现,每阶段的加权与转换亦不明确,是故类神经网络多利用于数据属于高度非线性且带有相当程度的变量交感效应时。
规则归纳法是知识发掘的领域中最常用的格式,这是一种由一连串的「如果…/则…(If / Then)」之逻辑规则对数据进行细分的技术,在实际运用时如何界定规则为有效是最大的问题,通常需先将数据中发生数太少的项目先剔除,以避免产生无意义的逻辑规则。
折叠NO.6DataMining包含哪些主要功能?
Data Mining实际应用功能可分为三大类六分项来说明:Classification和Clustering属于分类区隔类;Regression和Time-series属于推算预测类;Association和Sequence则属于序列规则类。
Classification是根据一些变量的数值做计算,再依照结果作分类。(计算的结果最后会被分类为几个少数的离散数值,例如将一组数据分为 "可能会响应" 或是 "可能不会响应" 两类)。Classification常被用来处理如前所述之邮寄对象筛选的问题。我们会用一些根据历史经验已经分类好的数据来研究它们的特征,然后再根据这些特征对其他未经分类或是新的数据做预测。这些我们用来寻找特征的已分类数据可能是来自我们的现有的客户数据,或是将一个完整数据库做部份取样,再经由实际的运作来测试;譬如利用一个大型邮寄对象数据库的部份取样来建立一个Classification Model,再利用这个Model来对数据库的其它数据或是新的数据作分类预测。
Clustering用在将数据分群,其目的在于将群间的差异找出来,同时也将群内成员的相似性找出来。Clustering与Classification不同的是,在分析前并不知道会以何种方式或根据来分类。所以必须要配合专业领域知识来解读这些分群的意义。
Regression是使用一系列的现有数值来预测一个连续数值的可能值。若将范围扩大亦可利用Logistic Regression来预测类别变量,特别在广泛运用现代分析技术如类神经网络或决策树理论等分析工具,推估预测的模式已不在止于传统线性的局限,在预测的功能上大大增加了选择工具的弹性与应用范围的广度。
Time-Series Forecasting与Regression功能类似,只是它是用现有的数值来预测未来的数值。两者最大差异在于Time-Series所分析的数值都与时间有关。Time-Series Forecasting的工具可以处理有关时间的一些特性,譬如时间的周期性、阶层性、季节性以及其它的一些特别因素(如过去与未来的关连性)。
Association是要找出在某一事件或是数据中会同时出现的东西。举例而言,如果A是某一事件的一种选择,则B也出现在该事件中的机率有多少。(例如:如果顾客买了火腿和柳橙汁,那么这个顾客同时也会买牛奶的机率是85%。)
Sequence Discovery与Association关系很密切,所不同的是Sequence Discovery中事件的相关是以时间因素来作区隔(例如:如果A股票在某一天上涨12%,而且当天股市加权指数下降,则B股票在两天之内上涨的机率是 68%)。
折叠NO.7DataMining在各领域的应用情形为何?
Data Mining在各领域的应用非常广泛,只要该产业拥有具分析价值与需求的数据仓储或数据库,皆可利用Mining工具进行有目的的挖掘分析。一般较常见的应用案例多发生在零售业、直效行销界、制造业、财务金融保险、通讯业以及医疗服务等。
于销售数据中发掘顾客的消费习性,并可藉由交易纪录找出顾客偏好的产品组合,其它包括找出流失顾客的特征与推出新产品的时机点等等都是零售业常见的实例;直效行销强调的分众概念与数据库行销方式在导入Data Mining的技术后,使直效行销的发展性更为强大,例如利用Data Mining分析顾客群之消费行为与交易纪录,结合基本数据,并依其对品牌价值等级的高低来区隔顾客,进而达到差异化行销的目的;制造业对Data Mining的需求多运用在品质控管方面,由制造过程中找出影响产品品质最重要的因素,以期提高作业流程的效率。
折叠NO.8WebMining和数据挖掘有什么不同?
如果将Web视为CRM的一个新的Channel,则Web Mining便可单纯看做Data Mining应用在网络数据的泛称。
该如何测量一个网站是否成功?哪些内容、优惠、广告是人气最旺的?主要访客是哪些人?什么原因吸引他们前来?如何从堆积如山之大量由网络所得数据中找出让网站运作更有效率的操作因素?以上种种皆属Web Mining 分析之范畴。Web Mining 不仅只限于一般较为人所知的log file分析,除了计算网页浏览率以及访客人次外,举凡网络上的零售、财务服务、通讯服务、政府机关、医疗咨询、远距教学等等,只要由网络连结出的数据库够大够完整,所有Off-Line可进行的分析,Web Mining都可以做,甚或更可整合Off-Line及On-Line的数据库,实施更大规模的模型预测与推估,毕竟凭借网际网络的便利性与渗透力再配合网络行为的可追踪性与高互动特质,一对一行销的理念是最有机会在网络世界里完全落实的。
整体而言,Web Mining具有以下特性:1. 数据收集容易且不引人注意,所谓凡走过必留下痕迹,当访客进入网站后的一切浏览行为与历程都是可以立即被纪录的;2. 以交互式个人化服务为终极目标,除了因应不同访客呈现专属设计的网页之外,不同的访客也会有不同的服务;3. 可整合外部来源数据让分析功能发挥地更深更广,除了log file、cookies、会员填表数据、线上调查数据、线上交易数据等由网络直接取得的资源外,结合实体世界累积时间更久、范围更广的资源,将使分析的结果更准确也更深入。
利用Data Mining技术建立更深入的访客数据剖析,并赖以架构精准的预测模式,以期呈现真正智能型个人化的网络服务,是Web Mining努力的方向。
折叠NO.9数据挖掘在CRM中扮演的角色为何?
CRM(Customer Relationship Management)是近来引起热烈讨论与高度关切的议题,尤其在直效行销的崛起与网络的快速发展带动下,跟不上CRM的脚步如同跟不上时代。事实上CRM并不算新发明,奥美直效行销推动十数年的CO(Customer Ownership)就是现在大家谈的CRM—客户关系管理。
Data Mining应用在CRM的主要方式可对应在Gap Analysis之三个部分:
针对Acquisition Gap,可利用Customer Profiling找出客户的一些共同的特征,希望能藉此深入了解客户,藉由Cluster Analysis对客户进行分群后再透过Pattern Analysis预测哪些人可能成为我们的客户,以帮助行销人员找到正确的行销对象,进而降低成本,也提高行销的成功率。
针对Sales Gap,可利用Basket Analysis帮助了解客户的产品消费模式,找出哪些产品客户最容易一起购买,或是利用Sequence Discovery预测客户在买了某一样产品之后,在多久之内会买另一样产品等等。利用 Data Mining可以更有效的决定产品组合、产品推荐、进货量或库存量,甚或是在店里要如何摆设货品等,同时也可以用来评估促销活动的成效。
针对Retention Gap,可以由原客户后来却转成竞争对手的客户群中,分析其特征,再根据分析结果到现有客户数据中找出可能转向的客户,然后设计一些方法预防客户流失;更有系统的做法是藉由Neural Network根据客户的消费行为与交易纪录对客户忠诚度进行Scoring的排序,如此则可区隔流失率的等级进而配合不同的策略。
折叠NO.10目前业界常用的数据挖掘分析工具?
Data Mining工具市场大致可分为三类:
1. 一般分析目的用的软件包
K-Miner(神通数据挖掘分析系统,MPP+SMP并行计算架构)
AlpineMiner(AlpineDataLabs)
TipDM(顶尖数据挖掘平台)
GDM(Geni-Sage Data Mining Analysis System,博通数据挖掘分析系统)
SAS Enterprise Miner
KXEN(凯森)
IBM Intelligent Miner
Unica PRW
SPSS Clementine
SGI MineSet
Oracle Darwin
Angoss KnowledgeSeeker
2. 针对特定功能或产业而研发的软件
KD1(针对零售业)
Options & Choices(针对保险业)
HNC(针对信用卡诈欺或呆帐侦测)
Unica Model 1(针对行销业)
iEM System (针对流程行业的实时历史数据)
3. 整合DSS(Decision Support Systems)/OLAP/Data Mining的大型分析系统
Cognos Scenario and Business Objects
折叠数据挖掘相关的权威期刊和会议
折叠[Journals]
1.ACM Transactions on Knowledge Discovery from Data (TKDD)
2.IEEE Transactions on Knowledge and Data Engineering (TKDE)
3.Data Mining and Knowledge Discovery
4.Knowledge and Information Systems
5.Data & Knowledge Engineering
折叠[Conferences]
1.SIGMOD:ACM Conference on Management of Data (ACM)
2.VLDB:International Conference on Very Large Data Bases (Morgan Kaufmann/ACM)
3.ICDE:IEEE International Conference on Data Engineering (IEEE Computer Society)
4.SIGKDD:ACM Knowledge Discovery and Data Mining (ACM)
5.WWW:International World Wide Web Conferences (W3C)
6.CIKM:ACM International Conference on Information and Knowledge Management (ACM)
7.PKDD:European Conference on Principles and Practice of Knowledge Discovery in Databases (Springer-VerlagLNAI)
当前数据挖掘应用主要集中在电信、零售、农业、网络日志、银行、电力、生物、天体、化工、医药等方面。看似广泛,实际应用还远没有普及。而据Gartner的报告也指出,数据挖掘会成为未来10年内重要的技术之一。而数据挖掘,也已经开始成为一门独立的专业学科。
具体发展趋势和应用方向主要有:对知识发现方法的研究进一步发展,如对Bayes和Boosting方法的研究和提高;商业工具软件不断产生和完善,注重建立解决问题的整体系统,例如Weka等软件。
数据挖掘的发展应是挖掘工具在先进理论指导下的改进,而就国内情况而言,还有至少20年的发展空间。
end
Hugedata
(ID:huge_data)
南京汇吉递特网络科技有限公司
是江苏省未来网络创新研究院对外提供网络大数据服务的经营实体。
旗下产品政府网站智能监测分析系统完全遵照国办普查指标体系,
对网站进行监测扫描,实时发现网站问题、并给出优化方案。
以上是关于长春前端薪资水平大分析的主要内容,如果未能解决你的问题,请参考以下文章
web前端开发真的会持续高薪吗?(赠超实用前端干货大合集,含特效源码)