PyTroch随笔 - 多GPU分布式训练
Posted SpikeKing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTroch随笔 - 多GPU分布式训练相关的知识,希望对你有一定的参考价值。
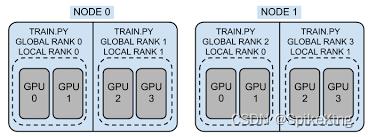
- Distributed Data-Parallel Training,DDP,分布式数据并行训练
- torch.nn.parallel.DistributedDataParallel
- RPC-Based Distributed Training,RPC,基于RPC的分布式训练
- Collective Communication,协同通信
不要把张量当入日志中输出,使用“.item()”转换为python的数据类型
logging.warning(f"epoch_index: epoch_index, batch_index: batch_index, ema_loss: ema_loss.item()")
PyTorch分布式训练
-
数据并行:数据放在不同的GPU上跑,模型放在同一个GPU上,并行。
-
模型并行:模型较大,拆分为不同模块,放在不同的GPU上运行,在第1个GPU的输出结果,输入到第2个GPU运行,串行。
单机单卡:
- 模型拷贝:
model.cuda(),inplace - 数据拷贝(每步):
data = data.cuda(),不是inplace需要赋值操作 - 基于
torch.cuda.is_available()来判断是否可用 - 模型保存与加载:
- torch.save 模型、优化器、其他变量(epoch、loss等)
torch.load(file.pt, map_location=torch.device(["cuda"/"cuda:0"/"cpu"])),map_location表明模型加载的位置。
单机多卡:
-
检测CPU数目
torch.cuda.device_count()- 可以通过命令行
CUDA_VISIBLE_DEVICES=""来控制GPU卡的使用
-
torch.nn.DataParallel(v1.0版本,已经很少使用 )- 简单一行代码,包裹mode即可
model = DataParallel(model.cuda(), device_ids=[0,1,2,3])data = data.cuda()
- 模型保存与加载
torch.save注意模型需要调用model.module_state_dict(),原model.state_dict()troch.load需要注意map_location的使用
- 缺点:
- 单进程,效率慢
- 不支持多机情况
- 不支持模型并行
- 注意事项:此处的batch_size,应该是每个GPU的batch_size的总和
- 简单一行代码,包裹mode即可
-
torch.nn.parallel.DistributedDataParallel(推荐),简称DDP-
优点:多进程执行多卡训练,效率高
-
代码编写流程
-
torch.distributed.init_process_group(backend="nccl", world_size=n_gpus, rank=args.local_rank)- 参考:torch.distributed.init_process_group
- nccl的通讯方式,NVIDIA Collective Communications Library,NVIDIA协同通信库
word_size是GPU卡的数量
-
torch.cuda.set_device(args.local_rank),该语句作用相当于CUDA_VISIBLE_DEVICES环境变量。 -
model = DistributedDataParallel(mode.cuda(args. local_rank), device_ids=[args. local_rank])- 模型包裹
-
train_sampler = DistributedSampler(train_dataset),源码位于torch/utils/data/distributed.pyfrom torch.utils.data.distributed import DistributedSampler- sampler对每张卡的数据进行分配
- 默认是传入dataset即可
- num_samples,每张卡的样本数量
- 每个迭代周期,返回一个sampler,给dataloader
- 数据随机种子,
g.manual_seed(self.seed + self.epoch) - 调用
sampler.set_epoch()方法,设置epoch,修改随机种子,indices发生shuffle变化 - 随机采样:
indices = indices[self.rank: self.total_size: self.num_replicas],间隔self.num_replicas取索引
-
train_dataloader = DataLoader(..., sampler=train_sampler)train_dataset->train_sampler->train_dataloader
-
data = data.cuda(args.local_rank),数据拷贝至GPU
-
-
执行命令
python -m torch.distributed.launch --nproc_per_node=n_gpus train.py
-
模型保存与加载:
torch.save在local_rank=0的位置进行保存,同样,注意调用model.module.state_dict()- 只在一个GPU上进行保存即可
torch.load注意map_location
-
注意事项:
- train.py中要有接受
local_rank的参数选项,launch会传入这个参数 - 每个进程的
batch_size应该是一个GPU所需要的batch_size大小 - 在每个周期开始处,调用
train_sampler.set_epoch(epoch),可以使得数据充分打乱 - 有了sampler,就不要在DataLoader中设置
shuffle=True了
- train.py中要有接受
-
多级多卡:
- torch.nn.parallel.DistributedDataParallel
- 代码编写流程:跟单机多卡中一致
- 执行命令(以两节点为例,每个节点处有n_gpus个GPU)
python -m torch.distributed.launch --nproc_per_node=n_gpus --nnodes=2 --node_rank=0 --master_addr="主节点IP" --master_port=主节点端口 train.pypython -m torch.distributed.launch --nproc_per_node=n_gpus --nnodes=2 --node_rank=1 --master_addr="主节点IP" --master_port=主节点端口 train.py
- 模型保存与加载:同单机多卡基本一致
模型并行:
- 背景:模型参数太大,单个GPU无法容纳,需要将模型的不同层拆分到多个GPU上。
- 示例:参考:https://pytorch.org/tutorials/intermediate/model_parallel_tutorial.html
- 模型保存与加载:分多个Module进行分别保存与加载
单机单卡:
判断CUDA是否可用
# step4 测试代码
if torch.cuda.is_available():
logging.warning("CUDA is available!")
else:
logging.warning("CUDA is not available!")
# 直接 return
设置所使用的CUDA:
-
命令行:使用
CUDA_VISIBLE_DEVICES="",例如CUDA_VISIBLE_DEVICES="0,1" -
代码:使用os.envisorn,例如
os.environ['CUDA_VISIBLE_DEVICES']='0,1',参考os.environ模块环境变量详解、os.environ详解
加载完模型数据,可以进行模型的拷贝,model.cuda(),原地操作,源码:nn.modules.module.py。
- 模型中所有参数都会被拷贝到GPU上。
数据拷贝需要赋值,不是原地操作,源码:torch.Tensor.cuda()
- 返回在CUDA内存中,这个对象的复制。Returns a copy of this object in CUDA memory.
保存模型,不需要修改,加载模型,需要修改:
model.cuda() # 模型拷贝,复制到GPU
token_index = token_index.cuda() # 数据拷贝,复制到GPU
target = target.cuda() # 数据拷贝
checkpoint = torch.load(resume, map_location=torch.devivce("cuda:0")) # 加载模型
单机多卡 - torch.nn.DataParallel
验证是否多GPU是否可用:
if torch.cuda.device_count() > 1:
logging.warning(f"Find torch.cuda.device_count() GPUs!")
else:
logging.warning(f"Too few GPU! Find torch.cuda.device_count() GPUs!")
修改模型,使用2个GPU:
# model.cuda() # 模型拷贝,复制到GPU
model = nn.DataParallel(model.cuda(), device_ids=[0,1]) # 模型拷贝,放入DataParallel
存储模型,需要修改,加载模型,不需修改:
# "model_state_dict": model.state_dict(),
"model_state_dict": model.module.state_dict(),
checkpoint = torch.load(resume, map_location=torch.devivce("cuda:0"))
model.load_state_dict(checkpoint['model_state_dict']) # 加载不需要修改
单机多卡 - torch.nn.parallel.DistributedDataParallel
argparse,从命令行中接收参数,Argparse 教程,设置local_rank参数:
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", help="local device id on current node", type=int)
args = parser.parse_args()
设置分布式程序,local_rank自动设置为0或1:
# DistributedDataParallel
torch.distributed.init_process_group("nccl", world_size=n_gpus, rank=args.local_rank)
torch.cuda.set_devices(args.local_rank)
模型拷贝:
# model.cuda() # 模型拷贝,复制到GPU
# model = nn.DataParallel(model.cuda(), device_ids=[0,1]) # 模型拷贝,放入DataParallel
model = nn.parallel.DistributedDataParallel(model.cuda(local_rank), device_ids=[local_rank]) # 模型拷贝,放入DistributedDataParallel
加载数据:
# 由dataloader替换为dataset
train(args.local_rank, to_map_style_dataset(train_data_iter), to_map_style_dataset(eval_data_iter), model, optimizer, num_epoch=10, log_step_interval=20, save_step_interval=500, eval_step_interval=300, save_path="./log_imdb_text_classification", resume=resume)
# 加载数据
train_sampler = DistributedSampler(train_dataset)
train_data_loader = torch.utils.data.DataLoader(train_dataset, batch_size=BATCH_SIZE, collate_fn=collate_fn, sampler=train_sampler)
eval_data_loader = torch.utils.data.DataLoader(eval_dataset, batch_size=8, collate_fn=collate_fn)
# 数据拷贝到local_rank
token_index = token_index.cuda(local_rank) # 数据拷贝,复制到GPU
target = target.cuda(local_rank) # 数据拷贝
存储模型:
if step % save_step_interval == 0 and local_rank == 0:
os.makedirs(save_path, exist_ok=True)
save_file = os.path.join(save_path, f"step_step.pt")
torch.save(
"epoch": epoch_index,
"step": step,
# "model_state_dict": model.state_dict(),
"model_state_dict": model.module.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': bce_loss,
, save_file)
logging.warning(f"checkpoint has been saved in save_file")
模型并行:
- net1,运行在cuda:0
- net2,运行在cuda:1
源码:
import torch
import torch.nn as nn
import torch.optim as optim
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = torch.nn.Linear(10, 10).to('cuda:0')
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to('cuda:1')
def forward(self, x):
x = self.relu(self.net1(x.to('cuda:0')))
return self.net2(x.to('cuda:1'))
源码汇总,可直接运行:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import utils
import torchtext
from tqdm import tqdm
from torchtext.datasets import IMDB
from torchtext.datasets.imdb import NUM_LINES
from torchtext.data import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
from torchtext.data.functional import to_map_style_dataset
from torch.utils.data.distributed import DistributedSampler
import argparse
import os
import sys
import logging
import logging
logging.basicConfig(
level=logging.WARN, stream=sys.stdout, \\
format="%(asctime)s (%(module)s:%(lineno)d) %(levelname)s: %(message)s")
VOCAB_SIZE = 15000
# step1 编写GCNN模型代码,门(Gate)卷积网络
class GCNN(nn.Module):
def __init__(self, vocab_size=VOCAB_SIZE, embedding_dim=64, num_class=2):
super(GCNN, self).__init__()
self.embedding_table = nn.Embedding(vocab_size, embedding_dim)
nn.init.xavier_uniform_(self.embedding_table.weight)
# 都是1维卷积
self.conv_A_1 = nn.Conv1d(embedding_dim, 64, 15, stride=7)
self.conv_B_1 = nn.Conv1d(embedding_dim, 64, 15, stride=7)
self.conv_A_2 = nn.Conv1d(64, 64, 15, stride=7)
self.conv_B_2 = nn.Conv1d(64, 64, 15, stride=7)
self.output_linear1 = nn.Linear(64, 128)
self.output_linear2 = nn.Linear(128, num_class)
def forward(self, word_index):
"""
定义GCN网络的算子操作流程,基于句子单词ID输入得到分类logits输出
"""
# 1. 通过word_index得到word_embedding
# word_index shape: [bs, max_seq_len]
word_embedding = self.embedding_table(word_index) # [bs, max_seq_len, embedding_dim]
# 2. 编写第一层1D门卷积模块,通道数在第2维
word_embedding = word_embedding.transpose(1, 2) # [bs, embedding_dim, max_seq_len]
A = self.conv_A_1(word_embedding)
B = self.conv_B_1(word_embedding)
H = A * torch.sigmoid(B) # [bs, 64, max_seq_len]
A = self.conv_A_2(H)
B = self.conv_B_2(H)
H = A * torch.sigmoid(B) # [bs, 64, max_seq_len]
# 3. 池化并经过全连接层
pool_output = torch.mean(H, dim=-1) # 平均池化,得到[bs, 4096]
linear1_output = self.output_linear1(pool_output)
# 最后一层需要设置为隐含层数目
logits = self.output_linear2(linear1_output) # [bs, 2]
return logits
# PyTorch官网的简单模型
class TextClassificationModel(nn.Module):
"""
简单版embedding.DNN模型
"""
def __init__(self, vocab_size=VOCAB_SIZE, embed_dim=64, num_class=2):
super(TextClassificationModel, self).__init__()
self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=False)
self.fc = nn.Linear(embed_dim, num_class)
def forward(self, token_index):
# 词袋
embedded = self.embedding(token_index) # shape: [bs, embedding_dim]
return self.fc(embedded)
# step2 构建IMDB Dataloader
BATCH_SIZE = 64
def yeild_tokens(train_data_iter, tokenizer):
for i, sample in enumerate(train_data_iter):
label, comment = sample
yield tokenizer(comment) # 字符串转换为token索引的列表
train_data_iter = IMDB(root="./data", split="train") # Dataset类型的对象
tokenizer = get_tokenizer("basic_english")
# 只使用出现次数大约20的token
vocab = build_vocab_from_iterator(yeild_tokens(train_data_iter, tokenizer), min_freq=20, specials=["<unk>"])
vocab.set_default_index(0) # 特殊索引设置为0
print(f'单词表大小: len(vocab)')
# 校对函数, batch是dataset返回值,主要是处理batch一组数据
def collate_fn(batch):
"""
对DataLoader所生成的mini-batch进行后处理
"""
target = []
token_index = []
max_length = 0 # 最大的token长度
for i, (label, comment) in enumerate(batch):
tokens = tokenizer(comment)
token_index.append(vocab(tokens)) # 字符列表转换为索引列表
# 确定最大的句子长度
if len(tokens) > max_length:
max_length = len(tokens)
if label == "pos":
target.append(0)
else:
target.append(1)
token_index = [index + [0]*(max_length-len(index)) for index in token_index]
# one-hot接收长整形的数据,所以要转换为int64
return (torch.tensor(target).to(torch.int64), torch.tensor(token_index).to(torch.int32))
# step3 编写训练代码
def train(local_rank, train_dataset, eval_dataset, model, optimizer, num_epoch, log_step_interval, save_step_interval, \\
eval_step_interval, save_path, resume=""):
"""
此处data_loader是map-style dataset
"""
start_epoch = 0
start_step = 0
if resume != "":
# 加载之前训练过的模型的参数文件
logging.warning(f"loading from resume")
checkpoint = torch.load(resume, map_location=torch.devivce("cuda:0"))
model.load_state_dict(checkpoint['model_state_dict']) # 加载不需要修改
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
start_epoch = checkpoint['epoch']
start_step = checkpoint['step']
print(f"local_rank: local_rank")
# model.cuda() # 模型拷贝,复制到GPU
# model = nn.DataParallel(model.cuda(), device_ids=[0,1]) # 模型拷贝,放入DataParallel
model = nn.parallel.DistributedDataParallel(model.cuda(local_rank), device_ids=[local_rank]) # 模型拷贝,放入DistributedDataParallel
print("model done!")
# 加载数据
train_sampler = DistributedSampler(train_dataset)
print("train_sampler done!")
train_data_loader = torch.utils.data.DataLoader(train_dataset, batch_size=BATCH_SIZE, collate_fn=collate_fn, sampler=train_sampler)
print("train_data_loader done!")
eval_data_loader = torch.utils.data.DataLoader(eval_dataset, batch_size=8, collate_fn=collate_fn)
print("eval_data_loader done!")
for epoch_index in tqdm(range(start_epoch, num_epoch), desc="epoch"):
train_sampler.set_epoch(epoch_index) # 在每个周期中,得到的数据是随机的
ema_loss = 0
num_batches = len(train_data_loader)
for batch_index, (target, token_index) in enumerate(train_data_loader):
optimizer.zero_grad()
step = num_batches*(epoch_index) + batch_index + 1
token_index = token_index.cuda(local_rank) # 数据拷贝,复制到GPU
target = target.cuda(local_rank) # 数据拷贝
logits = model(token_index)
# one-hot需要转换float32才可以训练
bce_loss = F.binary_cross_entropy(torch.sigmoid(logits), F.one_hot(target, num_classes=2).to(torch.float32))
ema_loss = 0.9 * ema_loss + 0.1 * bce_loss # 指数平均loss
bce_loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), 0.1) # 梯度的正则进行截断,保证训练稳定
optimizer.step() # 更新参数
if step % log_step_interval == 0:
# 不要把张量当入日志中输出,使用“.item()”转换为python的数据类型
logging.warning(f"epoch_index: epoch_index, batch_index: batch_index, ema_loss: ema_loss.item()")
if step % save_step_interval == 0 and local_rank == 0:
os.makedirs(save_path, exist_ok=True)
save_file = os.path.join(save_path, f"step_step.pt")
torch.save(
"epoch": epoch_index,以上是关于PyTroch随笔 - 多GPU分布式训练的主要内容,如果未能解决你的问题,请参考以下文章