视频质量评价工具vmaf分析
Posted DogDaoDao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视频质量评价工具vmaf分析相关的知识,希望对你有一定的参考价值。
vmaf介绍
-
VMAF,即Video Muitimethod Assessment Fusion(视频多方法评价融合);由 Netflix 推出的视频质量评价工具,用来解决传统指标不能反映多种场景、多种特征的视频情况。该指标是目前互联网视频最主流的客观视频评价指标,适用于衡量大规模环境中流播视频质量的观感。
-
vmaf是一种视频质量指标,将人类视觉建模与机器学习相结合,由Netflix和南加州大学C.-C Jay Kuo教授之间的研究合作;之后德克萨斯大学奥斯汀分校Alan Bovik教授和南特大学Patrick Le Callet教授之间展开合作,用来提高与人类主观感知有关的vmaf准确性,并扩大其范围涵盖更多用例;2016年6月完成开源。
-
vmaf可以用作优化准则,以获得更好的编码决策;VMAF被用于我们的整个生产流程中,不仅可以测量编码过程的结果,还可以指导编码达到最佳质量。在我们的动态优化器中,有一个关于如何在编码中使用VMAF的重要示例 Dynamic Optimizer,其中,每镜头的编码决策由每个编码器选项的比特率和质量测量确定。在优化过程中,VMAF 分数对于获取准确的质量测量以及选择 凸壳上的最终分辨率/比特率点至关重要。
-
VMAF分数范围从 0 到 100,其中 0 表示最低质量,100表示最高。思考VMAF分数的一种好方法是将其线性映射到人的意见量表,在此条件下可获得训练分数。例如,默认模型 v0.6.1 使用由绝对类别评分(ACR)方法收集的分数进行训练,该分数使用 1080p 显示屏,观看距离为3H。观看者对视频质量的评分为“很差”,“差”,“一般”,“好”和“优秀”,并且粗略地讲,“差”被映射为VMAF级别20,“优秀”为100。
-
视频数据源的内容特征:
○ 动漫、室内、室外、镜头摇移、面部拉近、人物、水面、显著的物体、多个物体;
○ 不同亮度、不同对比度、不同材质、不同活动、颜色变化、色泽浓郁度、锐利度;
○ 块效应、振铃效应、胶片颗粒度、蚊式噪声;
编译
https://blog.csdn.net/yanceyxin/article/details/108075460
原理
- 三种指标:视觉信息保真度(VIF:visual quality fidelity)、细节损失指标(DLM:detail loss measure)、时域运动指标/平均相关位置像素差(TI:temporal information)。其中VIF和DLM是空间域的,一帧画面之内的特征。TI 是时间域的,多帧画面之间相关性的特征。这些特性之间融合计算总分的过程使用了训练好的SVM来预测。

- VIF:视觉信息保真度指标来源于论文《image information and visual quality》https://ieeexplore.ieee.org/document/1576816。它是一种基于自然场景统计模型NSS、图像失真、和人类视觉失真建模的新判断;该指标认为人眼看到的图像是图像通过HVS过滤出来的信息,HVS本身就是一个失真通道,即人类视觉失真通道,而失真图像只是比原始图像在经过HVS之前又多了一个图像失真通道,故可以使用信息论的知识将人眼提取的信息与从原始图像提取的信息进行比较,得出最终评测结果。
- DLM:细节损失指标来源于论文《Image Quality Assessment by Separately Evaluating Detail Losses and Additive Impairments》https://ieeexplore.ieee.org/document/5765502。该算法分别评估细节损失(Detail Loss Measure, DLM)和附加损伤(Additive Impairment Measure, AIM)。细节损失是指影响内容可视性的有用视觉信息的损失,加性损伤是指多余的视觉信息,即在测试图像中出现的分散观众对有用内容的注意力的信息,从而导致不好的观看体验。为了分离细节损失和加性损伤,首先将原始参考图像和被测图像通过一种小波域解耦算法进行分离,分离出小波变换系数O、修复图像的小波变换系数R以及加性损伤的小波变换系数A。经过对比敏感度函数和对比掩膜效应函数两种近似HVS敏感度的特性处理后,得到了O’、R’、A’,再通过两种简单的质量测量方法,得到两种质量结果q1和q2,最后将细节损失和附加损伤两个质量度量的输出与视觉质量相关联,得到总体质量指数s。在VMAF中只使用细节损失q1作为基本指标,但也对一些特殊情况采取了必要的措施,如导致原始公式中的数值计算失效的黑帧。

- TI :时域运动指标/平均相关位置像素差是一种衡量相邻帧之间时域差分的算法;这个仅仅计算像素亮度分量的均值作差即可得到该值。
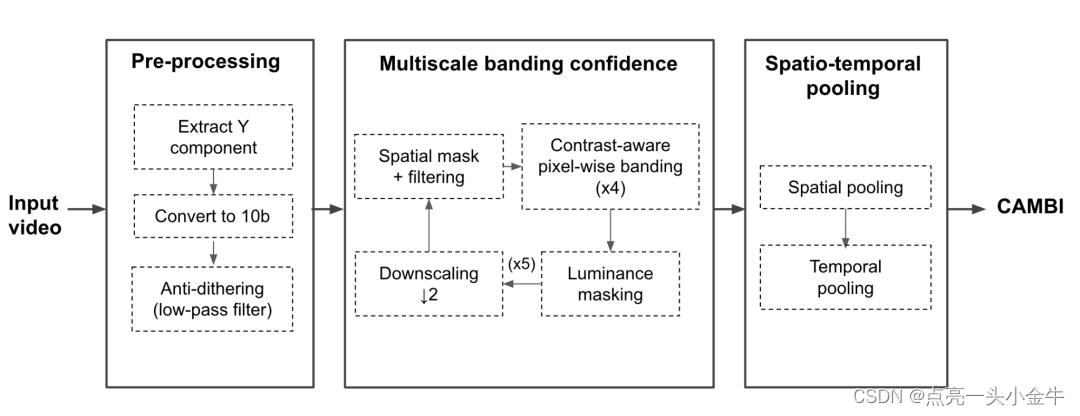
CAMBI【新加入的算法,检测条带失真】


新版本增加的检测条带失真;netfix用传统的、非神经网络(NNN,non-neural network)的方法设计了一种算法来满足我们的要求,具体如下:
模型分析
- HDTV模式:针对客厅电视场景设计,参照 SMPTE EG-18-1994 标准,所有训练集的主观数据 (EMOS) 是遵循这种方式收集的:将视频 scale 成 1080p,并以三倍于屏幕高度 (3H) 的观看距离或 60 像素/度的角度分辨率进行显示。可以说,VMAF 模型试图捕捉的是 3H 外显示的 1080p 视频的感知质量。这是默认 VMAF 模型的隐含假设。因此,我们在对除 1080p 以外的其他分辨率进行 VMAF 计算时,需要将视频先 scale 成1080p,才能保证结果的准确性。试想一下,如果将一个 480p 的视频用 HDTV 模式来做评测,会发生什么情况呢?这就好像 480p 视频是从 1080p 视频中剪切出来的一样。如果 480p 视频的高度为 H ',则 H = 1080 / 480 * H ',其中 H 为所显示的 1080p 视频的高度。因此,VMAF 建模的是 3H = 6.75H ’ 的观看距离。换句话说,如果你计算 480p 分辨率的视频对的 VMAF,你将预测观看距离是其高度的 6.75 倍时的感知质量。在此观看距离会隐藏大量主观画质的感知细节,从而让 VMAF 分数可能偏高。
- phone模式:默认的 vmaf_float_v0.6.1.pkl 模型也提供了移动设备场景的画质评估功能,可以通过参数 “–phone-model” 开启。在此模式下,每个受试者在他/她感到舒适的距离观看视频。在训练过的模型中,分数在 0 - 100 之间,与主观投票量表呈线性关系,粗略的 “bad” 映射为20分,“excellent” 映射为 100 分。横向对比可以发现,如果将一部 540p 的视频分别放在标准电视、手机设备、4K 设备显示,在手机设备上的 VMAF 质量会比其他两者更快的逼近 100 分的临界值。
- 4K模式:由于 vmaf_float_v0.6.1.pkl 模型的训练集中包括了 4K 和 1080p 的视频源,当需要对比 A/B 两个 4K 视频哪一个画质更好时,也能使用此模型。但是由于默认模型采用的是 1080p + 3H 观看距离的方式采集的 EMOS 数据,无法算出准确的 4K VMAF 分数。Netflix 后来专门提供了 vmaf_4k_v0.6.1.pkl 用于 4K 的画质评估。
API介绍
//初始化,分配并打开vmaf实例
int vmaf_init(VmafContext**vmaf, VmafConfigurationcfg);
//注册特定的“VmafModel”所需的特征提取器。这可以使用不同的模型调用多次。在这种情况下,注册的特征提取器将形成一个集合,多个模型所需的特征只提取一次
int vmaf_use_features_from_model(VmafContext*vmaf, VmafModel*model);
//注册特定的“VmafModelCollection”所需的特征提取器,可以多次使用
int vmaf_use_features_from_model_collection(VmafContext*vmaf, VmafModelCollection*model_collection);
//注册特定特征提取器,当需要一个特定的/附加的特性时(比如psnr、ssim、msssim等),通常是一个 不是已经由模型通过' vmaf_use_features_from_model() '提供的。
int vmaf_use_feature(VmafContext*vmaf, constchar*feature_name, VmafFeatureDictionary*opts_dict);
//导入外部特性评分。当预先计算的功能分数可用时很有用。 在所需特性没有libvmaf特性提取器实现的情况下也很有用。
int vmaf_import_feature_score(VmafContext*vmaf, constchar*feature_name, doublevalue, unsignedindex);
//读一组图片,并将它们排队等待最终的特征提取。这应该在特征提取器通过' vmaf_use_features_from_model() '和/或' vmaf_use_feature() '注册后调用。' VmafContext '将获得' VmafPicture ' (' ref ' and ' dist ')和' vmaf_picture_unref() '的所有权。
int vmaf_read_pictures(VmafContext*vmaf,VmafPicture*ref,VmafPicture*dist, unsignedindex);
//预测具体指标的VMAF得分。
int vmaf_score_at_index(VmafContext*vmaf, VmafModel *model,double*score, unsignedindex);
//使用模型集合预测特定指数的VMAF得分。
int vmaf_score_at_index_model_collection(VmafContext*vmaf, VmafModelCollection*model_collection, VmafModelCollectionScore*score, unsignedindex);
//获取特定索引的特性评分。
int vmaf_feature_score_at_index(VmafContext*vmaf,constchar*feature_name, double*score,unsignedindex);
//指定间隔的VMAF评分池。
int vmaf_score_pooled(VmafContext*vmaf, VmafModel *model,enumVmafPoolingMethodpool_method,double*score,unsignedindex_low,unsignedindex_high);
//使用模型集合的特定间隔的池VMAF评分。
int vmaf_score_pooled_model_collection(VmafContext*vmaf,VmafModelCollection*model_collection,enumVmafPoolingMethodpool_method,VmafModelCollectionScore*score,
unsignedindex_low,unsignedindex_high);
//在特定的时间间隔内的汇集特性得分。
int vmaf_feature_score_pooled(VmafContext*vmaf,constchar*feature_name, enumVmafPoolingMethodpool_method,double*score, unsignedindex_low,unsignedindex_high);
//关闭一个VMAF实例并释放所有相关内存。
int vmaf_close(VmafContext*vmaf);
//将VMAF统计数据写入输出文件。
int vmaf_write_output(VmafContext*vmaf,constchar*output_path, enumVmafOutputFormatfmt);
compute_vmaf demo代码逻辑分析
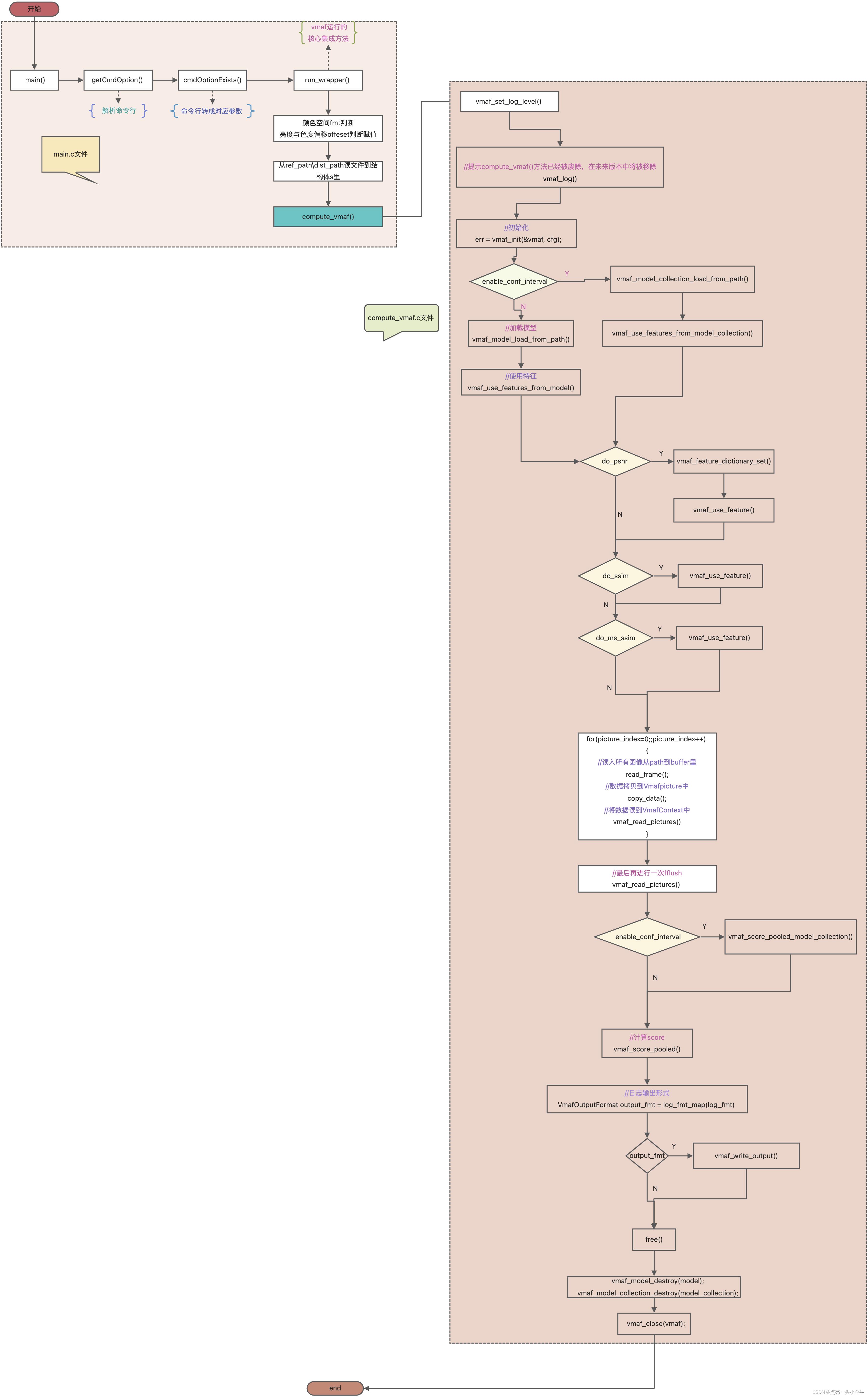
command line tool源码分析
[vmaf.c]
int main(int argc, char *arg[])
int err = 0;
//文件流相关操作
const int istty = isatty(fileno(stderr));
//解析命令行,传入CLISettings结构体中
CLISettings c;
cli_parse(argc, argv, &c);
//输出VMAF版本号
if (istty && !c.quiet)
fprintf(stderr, "VMAF version %s\\n", vmaf_version());
//从路径读入视频数据
FILE *file_ref = fopen(c.path_ref, "rb");
if (!file_ref)
fprintf(stderr, "could not open file: %s\\n", c.path_ref);
return -1;
FILE *file_dist = fopen(c.path_dist, "rb");
if (!file_dist)
fprintf(stderr, "could not open file: %s\\n", c.path_dist);
return -1;
//从FILE中传入video_input结构体里
video_input vid_ref;
if (c.use_yuv)
err = raw_input_open(&vid_ref, file_ref,
c.width, c.height, c.pix_fmt, c.bitdepth);
else
err = video_input_open(&vid_ref, file_ref);
if (err)
fprintf(stderr, "problem with reference file: %s\\n", c.path_ref);
return -1;
video_input vid_dist;
if (c.use_yuv)
err = raw_input_open(&vid_dist, file_dist,
c.width, c.height, c.pix_fmt, c.bitdepth);
else
err = video_input_open(&vid_dist, file_dist);
if (err)
fprintf(stderr, "problem with distorted file: %s\\n", c.path_dist);
return -1;
//验证ref和dist视频的相容性
err = validate_videos(&vid_ref, &vid_dist);
if (err)
fprintf(stderr, "videos are incompatible, %d %s.\\n",
err, err == 1 ? "problem" : "problems");
return -1;
//configure信息
VmafConfiguration cfg =
.log_level = VMAF_LOG_LEVEL_INFO,
.n_threads = c.thread_cnt,
.n_subsample = c.subsample,
.cpumask = c.cpumask,
;
//1. 初始化,vmaf是上下文,cfg是选择结构体用来初始化上下文
VmafContext *vmaf;
err = vmaf_init(&vmaf, cfg);
if (err)
fprintf(stderr, "problem initializing VMAF context\\n");
return -1;
//内存申请
VmafModel **model;
const size_t model_sz = sizeof(*model) * c.model_cnt;
model = malloc(model_sz);
memset(model, 0, model_sz);
VmafModelCollection **model_collection;
const size_t model_collection_sz =
sizeof(*model_collection) * c.model_cnt;
model_collection = malloc(model_sz);
memset(model_collection, 0, model_collection_sz);
const char *model_collection_label[c.model_cnt];
unsigned model_collection_cnt = 0;
//对model次数进行循环操作
for (unsigned i = 0; i < c.model_cnt; i++)
//根据判断version是否使用来调用不同的方法load模型
if (c.model_config[i].version)
//加载默认内置模型之一
err = vmaf_model_load(&model[i], &c.model_config[i].cfg,
c.model_config[i].version);
else
//从系统文件读取模型文件
err = vmaf_model_load_from_path(&model[i], &c.model_config[i].cfg,
c.model_config[i].path);
//加载模型错误的情况下
if (err)
// check for model_collection before failing
// this is implicit because the `--model` option could take either
// a model or model_collection
if (c.model_config[i].version)
err = vmaf_model_collection_load(&model[i],
&model_collection[model_collection_cnt],
&c.model_config[i].cfg,
c.model_config[i].version);
else
err = vmaf_model_collection_load_from_path(&model[i],
&model_collection[model_collection_cnt],
&c.model_config[i].cfg,
c.model_config[i].path);
if (err)
fprintf(stderr, "problem loading model: %s\\n",
c.model_config[i].version ?
c.model_config[i].version : c.model_config[i].path);
return -1;
model_collection_label[model_collection_cnt] =
c.model_config[i].version ?
c.model_config[i].version : c.model_config[i].path;
for (unsigned j = 0; j < c.model_config[i].overload_cnt; j++)
err = vmaf_model_collection_feature_overload(
model[i],
&model_collection[model_collection_cnt],
c.model_config[i].feature_overload[j].name,
c.model_config[i].feature_overload[j].opts_dict);
if (err)
fprintf(stderr,
"problem overloading feature extractors from "
"model collection: %s\\n",
c.model_config[i].version ?
c.model_config[i].version : c.model_config[i].path);
return -1;
err = vmaf_use_features_from_model_collection(vmaf,
model_collection[model_collection_cnt]);
if (err)
fprintf(stderr,
"problem loading feature extractors from "
"model collection: %s\\n",
c.model_config[i].version ?
c.model_config[i].version : c.model_config[i].path);
return -1;
model_collection_cnt++;
continue;
//
for (unsigned j = 0; j < c.model_config[i].overload_cnt; j++)
err = vmaf_model_feature_overload(model[i],
c.model_config[i].feature_overload[j].name,
c.model_config[i].feature_overload[j].opts_dict);
if (err)
fprintf(stderr,
"problem overloading feature extractors from "
"model: %s\\n",
c.model_config[i].version ?
c.model_config[i].version : c.model_config[i].path);
return -1;
//使用' vmaf_use_features_from_model() '注册模型所需的所有特征提取器
err = vmaf_use_features_from_model(vmaf, model[i]);
if (err)
fprintf(stderr,
"problem loading feature extractors from model: %s\\n",
c.model_config[i].version ?
c.model_config[i].version : c.model_config[i].path);
return -1;
//如果有辅助指标,使用‘vmaf_use_feature()’直接注册
for (unsigned i = 0; i < c.feature_cnt; i++)
err = vmaf_use_feature(vmaf, c.feature_cfg[i].name,
c.feature_cfg[i].opts_dict);
if (err)
fprintf(stderr, "problem loading feature extractor: %s\\n",
c.feature_cfg[i].name);
return -1;
//循环读取所有图像
float fps = 0.;
const time_t t0 = clock();
unsigned picture_index;
for (picture_index = 0 ;; picture_index++)
if (c.frame_cnt && picture_index >= c.frame_cnt)
break;
//核心就是封装了vmaf_picture_alloc,要分配“VmafPicture”,请使用“vmaf_picture_alloc”。分配之后,可以用像素数据填充缓冲区。
VmafPicture pic_ref, pic_dist;
int ret1 = fetch_picture(&vid_ref, &pic_ref);
int ret2 = fetch_picture(&vid_dist, &pic_dist);
if (ret1 && ret2)
break;
else if (ret1 < 0 || ret2 < 0)
fprintf(stderr, "\\nproblem while reading pictures\\n");
break;
else if (ret1)
fprintf(stderr, "\\n\\"%s\\" ended before \\"%s\\".\\n",
c.path_ref, c.path_dist);
break;
else if (ret2)
fprintf(stderr, "\\n\\"%s\\" ended before \\"%s\\".\\n",
c.path_dist, c.path_ref);
break;
if (istty && !c.quiet)
if (picture_index > 0 && !(picture_index % 10))
fps = (picture_index + 1) /
(((float)clock干货 | VMAF视频质量评估在视频云转码中的应用
作者介绍:姜生,PP云高级技术经理,10余年视频编解码算法设计优化,流媒体应用等领域开发经验。
一 、VMAF 技术介绍:
VMAF 的全称是:Visual Multimethod Assessment Fusion,视频质量多方法评价融合。这项技术是由美国Netflix公司开发的一套主观视频质量评价体系。2016年1月,VMAF 正式开源;
下载地址:
https://github.com/Netflix/vmaf
二 、通行视频质量评价方法的局限:
评价一个编码后的视频流与压缩前的视频流质量对比值,通行的方法是PSNR(峰值信噪比),或者SSIM(结构相似度)。这些是客观评价方法。这些方法评价的结果与主观的感受有时候相差很大,请看下图(来自Netflix 的官网):

图一
上面四幅图,取自4幅静态画面,畸变程度不一样。用PSNR指标来评分,上面两幅图的PSNR值大约为31dB, 下方两个的PSNR值约为34dB,这表明上面两幅图PNSR 值相当,下面两幅图的PSNR值也相当。如果让人眼来主观评价呢,对于左侧上下两幅“人群”图片,很难察觉有何差异,但是右侧两幅“狐狸”视频的差异就很明显了。Netflix综合不同观众的评价,对上下两个“人群”给出的主观分数是82(上方)和96(下方),而两个“狐狸”的分数分别是27(上方)和58(下方)。
上面的示例说明PSNR一类的客观评价与实际的主观感受相差较大。这说明这种方法不足以全面正确的评价视频的质量,为此Netflix 决定寻找新的方法。
三、Neflix对视频源特性的分析:
- 收集与用例密切相关的数据集:
虽然针对视频质量指标的设计和测试已经有可以公开使用的数据库,但这些数据库的内容缺乏多样性。而多样性正是流媒体服务的最大特点。由于视频质量的评估远不仅仅是压缩失真的评估,所以应该考虑更广范围的画质损失,不仅有压缩导致的损失,还有传输过程中的损失、随机噪声,以及几何变形等情况。
- 视频源的特性:
作为流媒体公司, Netflix 提供了适合各类人群观看的大量影视内容,例如儿童内容、动漫、动作片、纪录片,视频讲座等. 另外这些内容还包含各种底层源素材特征,例如胶片颗粒、传感器噪声、计算机生成的材质、始终暗淡的场景或非常明亮的色彩等。过去通行的质量指标并没有考虑不同类型的源内容,如动漫或者视频讲座一类,也未考虑胶片颗粒,而在专业娱乐内容中这些都是非常普遍的信号特征。
- 失真的来源:
一般而言,流播视频是通过TCP传输的,丢包和误码绝对不会导致视觉损失。这就使得编码过程中的两类失真最终影响到观众所感受到的体验质量(QoE):压缩失真以及缩放失真。
为了针对不同的用例构建数据集,Netflix选择了34个源短片作为样本(参考视频),每个短片长度是6秒,主要来自于流行的电视剧和电影。源短片包含具备各种高级特征的内容(动漫、室内/室外、镜头摇移、面部拉近、人物、水面、显著的物体、多个物体)以及各种底层特性(胶片噪声、亮度、对比度、材质、活动、颜色变化、色泽浓郁度、锐度)。将这些源短片编码为H.264/AVC格式的视频流,分辨率介于384x288到1920x1080之间,码率介于375kbps到20,000kbps之间,最终获得了大约300个畸变(Distorted)视频。这些视频涵盖了很大范围的视频码率和分辨率,足以反映实际生活中多种多样的网络环境。
接着,通过主观测试确定非专业观察者对于源短片编码后视频画质损失的评价。参考视频和畸变视频将按顺序显示在家用级别的电视机上。如果畸变视频编码后的分辨率小于参考视频,则会首先放大至源分辨率随后才显示在电视上。将所有观察者针对每个畸变视频的分数汇总在一起计算出微分平均意见分数(Differential Mean Opinion Score)即DMOS,并换算成0-100的标准分,其中100分是指参考视频的分数。
四、评价的结果:
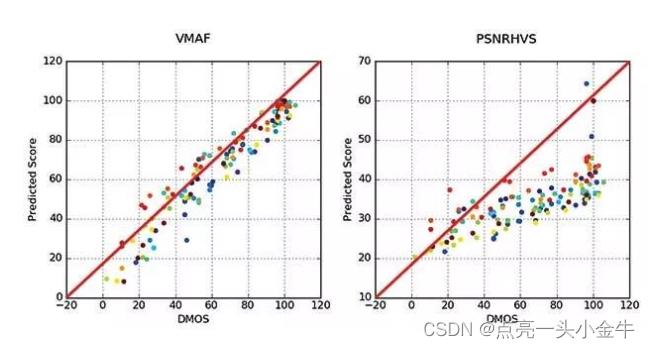
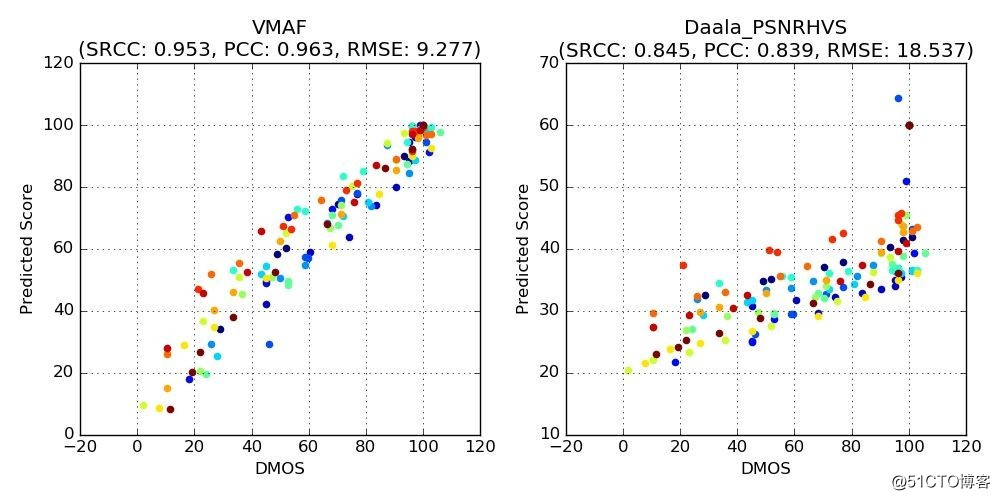
Netflix 推出了二维散点图来说明上面分析的结果,我从中选取四幅有代表性的散点图。
散点图中,横轴对应了观察者给出的DMOS分数,纵轴对应了不同质量指标预测的分数。每一个点代表了一个畸变视频。我们为下列四个指标绘制了散点图:
-
PSNR亮度分量(Luminancecomponent)
-
SSIM
-
Multiscale FastSSIM
- PSNR-HVS
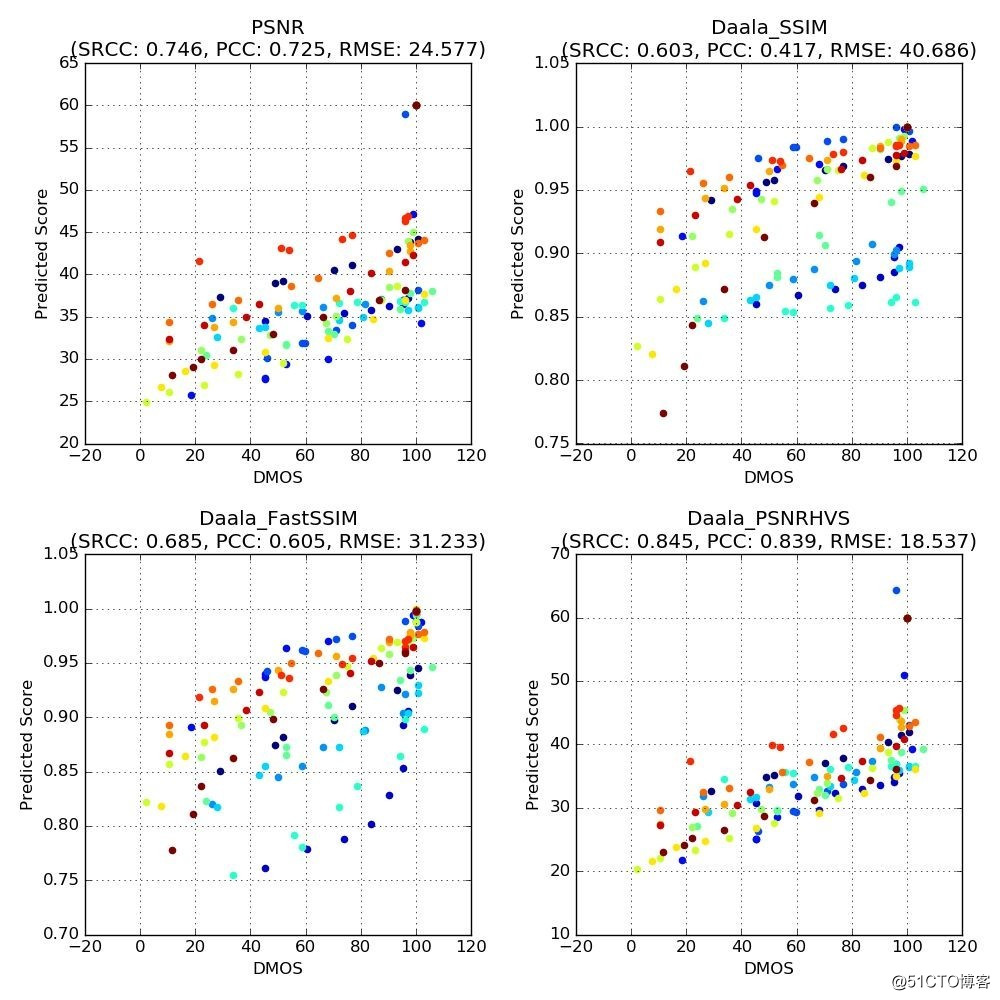
图二
注意:相同颜色的点对应了畸变视频和相应参考视频的结果。从图中可以看出,这些指标的分数与观察者给出的DMOS分数并非始终一致。以左上角的PSNR图为例,PSNR值约为35dB,而“人工校正”的DMOS值的范围介于10(存在恼人的画质损失)到100(画质损失几乎不可察觉)之间。
上图中的专有名词:
斯皮尔曼等级相关系数(Spearman’srank correlation coefficient,SRCC)
皮尔森积差相关系数(Pearsonproduct-moment correlation coefficient,PCC)
上面的SRCC, PCC属于概率统计的概念,可以参考相关文档,这两个值越大越好。
为了找到一个有效的评价标准,必须选定一个有效的指标,指标必须呈现与DMOS 有限的单调性。下图中选定了三个典型的参考视频:一个高噪声视频,一个CG动漫,一个电视剧,并用每个视频的不同畸变版本的预测分数与DMOS分数创建散点图。为了获得有效的相对质量分数,我们希望不同视频短片在质量曲线的相同范围内可以实现一致的斜率(Slope)。
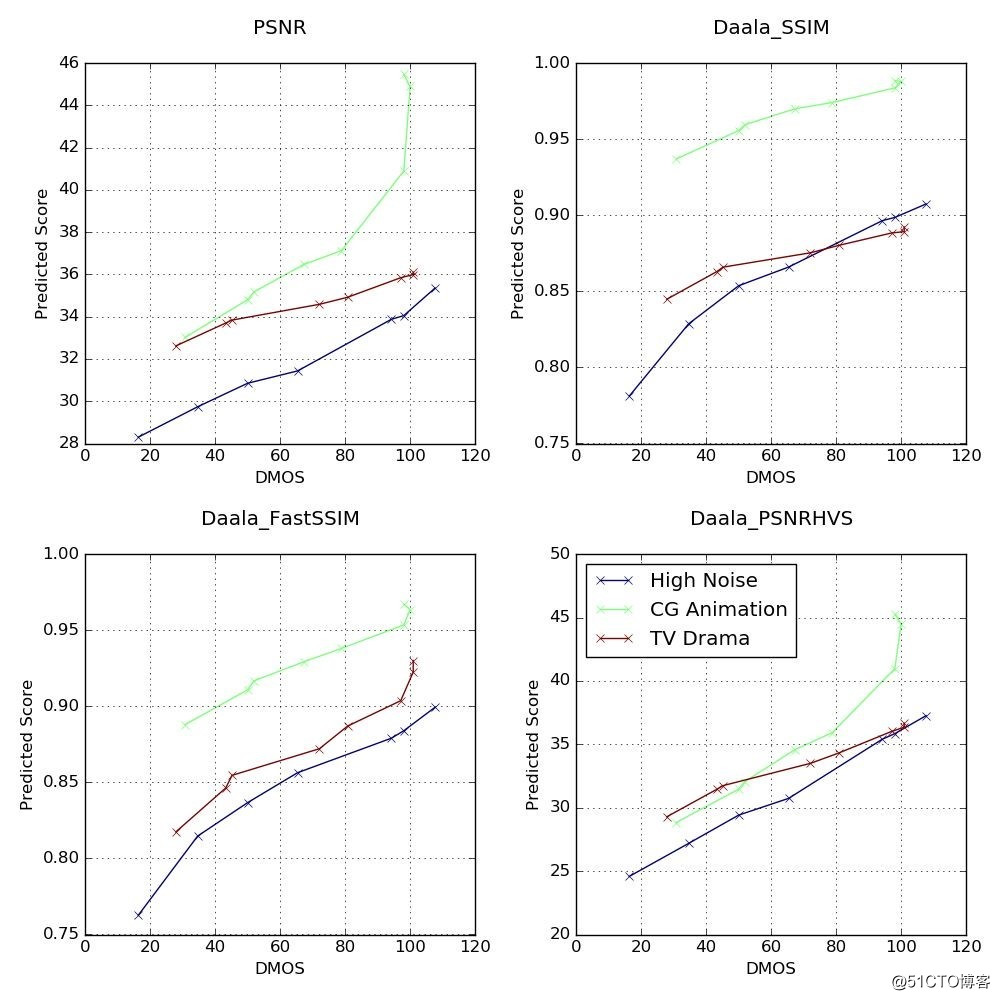
PSNR散点图中,在34dB到36dB的范围内,电视剧PSNR数值大约2dB的变化对应的DMOS数值变化约为50(50到100),但CG动漫同样范围内类似的2dB数值变化对应的DMOS数值变化低于20(40到60)。虽然CG动漫和电视剧短片的SSIM和FastSSIM体现出更为一致的斜率但表现依然不够理想。
简单总结来说,传统指标不适合用来评价视频质量。为了解决这一问题,我们使用了一种基于机器学习的模型设计能真实反映人对视频质量感知情况的指标。下文将介绍这一指标。
五、 VMAF 方法:
基本想法:
面对不同特征的源内容、失真类型,以及扭曲程度,每个基本指标各有优劣。通过使用机器学习算法(支持向量机(Support Vector Machine,SVM)回归因子)将基本指标“融合”为一个最终指标,可以为每个基本指标分配一定的权重,这样最终得到的指标就可以保留每个基本指标的所有优势,借此可得出更精确的最终分数。我们还使用主观实验中获得的意见分数对这个机器学习模型进行训练和测试。
VMAF可在支持向量机(SVM)回归因子中使用下列基本指标进行融合:
- 视觉信息保真度(Visual Information Fidelity,VIF):
VIF是一种获得广泛使用的图像质量指标,在最初的形式中,VIF分数是通过将四个尺度(Scale)下保真度的丢失情况结合在一起衡量的。在VMAF中我们使用了一种改进版的VIF,将每个尺度下保真度的丢失看作一种基本指标。
- 细节丢失指标(Detail LossMetric,DLM):
LM是一种图像质量指标,其基本原理在于:分别衡量可能影响到内容可见性的细节丢失情况,以及可能分散观众注意力的不必要损失。这个指标最初会将DLM和Additive Impairment Measure(AIM)结合在一起算出最终分数。
- 运动:
这是一种衡量相邻帧之间时域差分的有效措施。计算像素亮度分量的均值反差即可得到该值。
下列散点图对所选参考短片(高噪声视频、CG动漫、电视剧)得出的VMAF指标分数。为了方便对比,我们也附上了上文提到的结果最理想的PSNR-HVS指标散点图。无疑VMAF的效果更好。
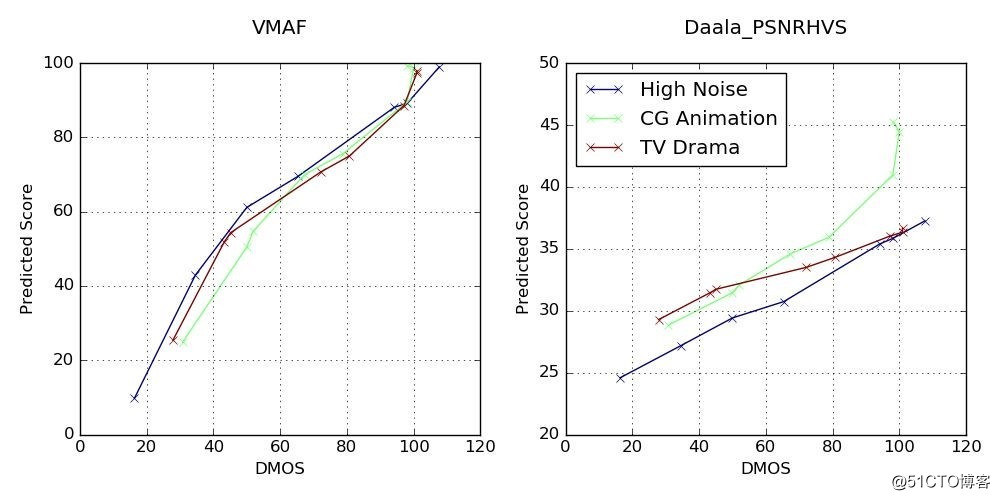
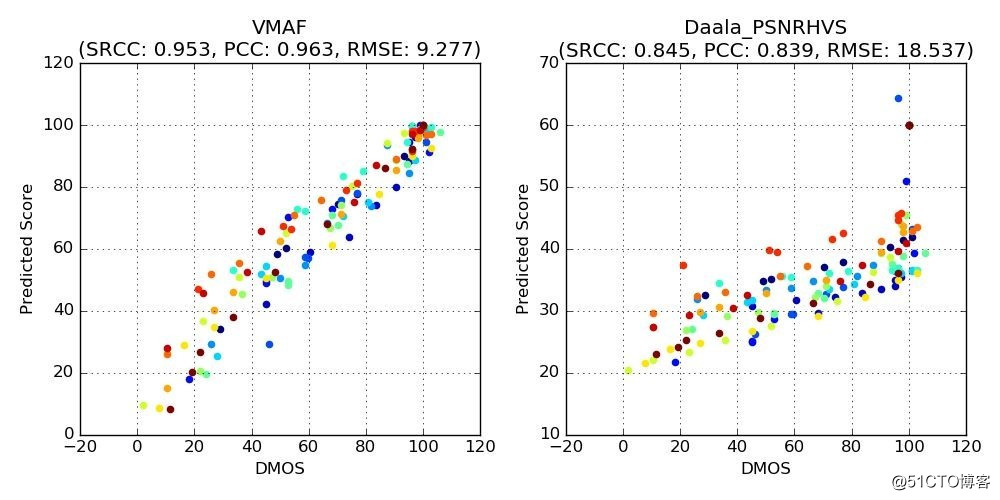
六 总结:
改善视频压缩标准,以更智能的方式确定最实用的编码系统和编码一整套参数,这些要求在当今的互联网大环境中十分重要。我们认为,使用传统的指标会妨碍到视频编码技术领域的技术进步,然而单纯依赖人工视觉测试在很多情况下并不可行。因此我们希望VMAF能解决这一问题,使用来自我们内容中的样本帮助大家设计和验证算法。
七 、拓展:
- per title 编码:
我们希望能利用VMAF 绘制每一个clip 的不同分辨率下的bitrate vs MOS 的曲线图,并保存这个曲线图。在实际点播的时候,根据resolution,MOS 选择一个最佳的bitrate,来编码:
下面是我绘制的Bkimono_1920x1080_8_24_240.yuv 的散点图:
设置编码参数时,如果需要达到MOS=80的清晰度,bitrate 可以选择2.0MB. 可以看出当bitrate 超过3MB 后,MOS 值变化非常缓慢,对于指定的MOS 值,我们可以选择一个bitrate 下降20%甚至更多的bitrate的编码参数,但是MOS 不会下降1%。
这中方法相比单纯通过优化编码器的方法,效果要明显很多,智能很多,同时实现起来要容易。应该就是当前窄带高清的理念了。
- per trunk 编码:
对于每一个clip 而言,不同的gop,或者不同的时间段,视频流的细节和运动特点不一样,可以用VMAF 的方法为每一个时间段做评价,进而实时调整编码参数,在同样的质量前提下,尽量降低码率。
以上是关于视频质量评价工具vmaf分析的主要内容,如果未能解决你的问题,请参考以下文章
ffmpeg 增加视频流媒体质量评估滤镜 (Video Multimethod Assessment Fusion, VMAF)