DaGAN论文解读
Posted ‘Atlas’
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DaGAN论文解读相关的知识,希望对你有一定的参考价值。
文章目录
论文: 《Depth-Aware Generative Adversarial Network for Talking Head Video Generation》
github: https://github.com/harlanhong/CVPR2022-DaGAN
解决问题
现有问题:
现有视频生成方案主要利用2D表征,人脸3D信息实际上对于此任务至关重要,然后标注需要大量成本;
解决方法:
本文作者提出一种自监督方案,自动从人脸视频中生成稠密3D几何信息,不需要任何标注数据;依据此信息,进一步估计稀疏人脸关键点,用于捕获人头重要移动;深度信息也用于学习3D跨模态(外观与深度)attention机制,引导生成用于扭曲原图的运动场;
本文提出的DaGAN可生成高逼真人脸,且在未见过人脸上取得不错效果;
本文贡献主要包括以下三点:
1、引入自监督方式从视频中拟合深度图,并将其用于提升生成效果;
2、提出新颖的关注深度的GAN,通过深度引导的面部关键点估计及跨模态(深度及图像)attention机制,将深度信息引入生成网络;
3、充分实验展示人脸图片的准确深度拟合,同时生成效果超越SOTA;
算法
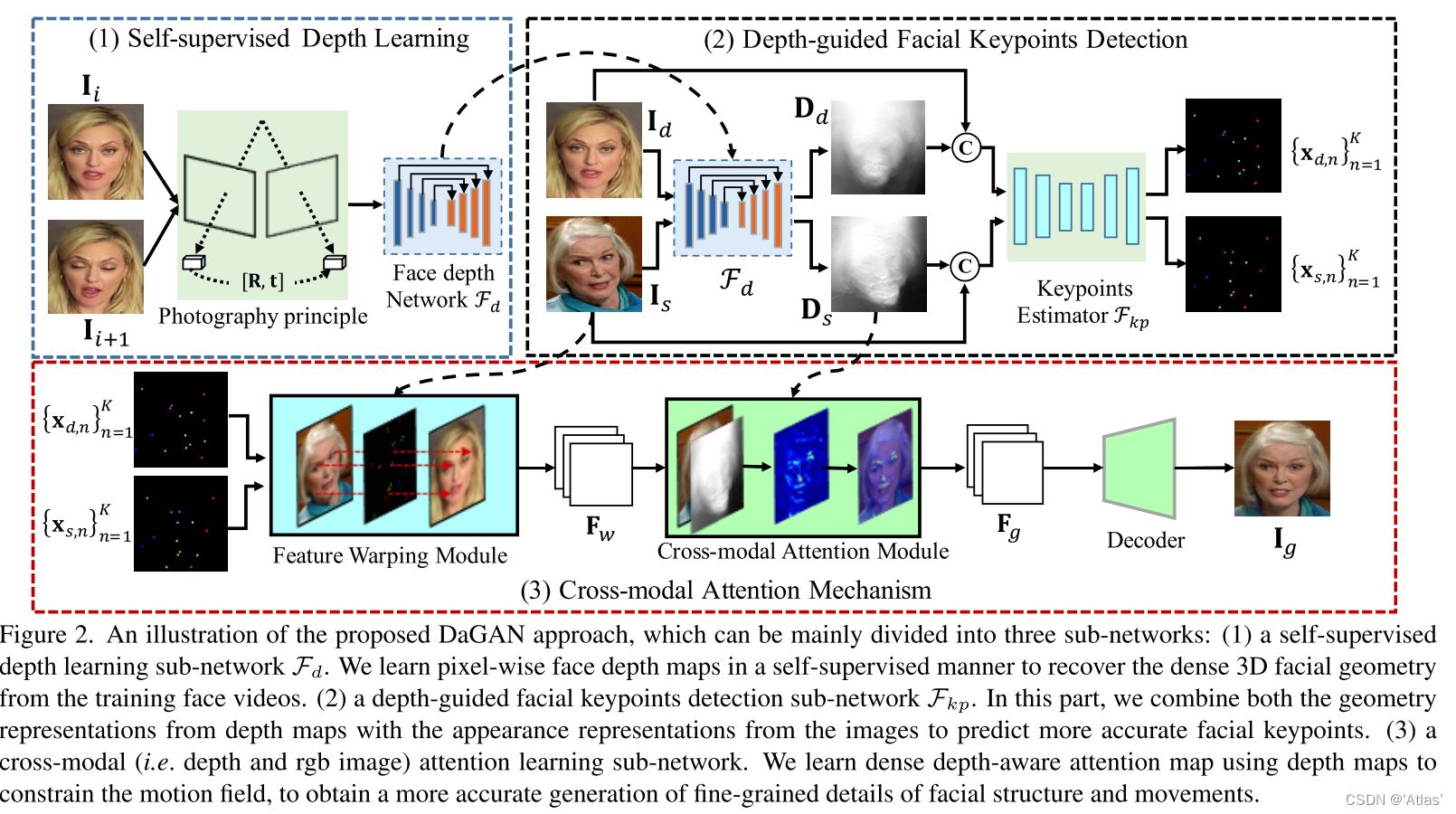
DaGAN方法如图2,由生成器和判别器构成;
生成器由三部分组成:
1、自监督深度信息学习子网络
F
d
F_d
Fd,从视频中两个连续帧自监督学习深度估计;然后固定
F
d
F_d
Fd进行整个网络训练;
2、深度信息引导的稀疏关键点检测子网络
F
k
p
F_kp
Fkp;
3、特征扭曲模块利用关键点生成变化区域,其将扭曲源图特征已将外观信息与运动信息结合,得到扭曲特征
F
w
F_w
Fw;为确保模型关注细节及面部微表情,进一步学习关注深度信息的attention map,其精细化
F
w
F_w
Fw得到
F
g
F_g
Fg,用于生成图像
I
g
I_g
Ig;
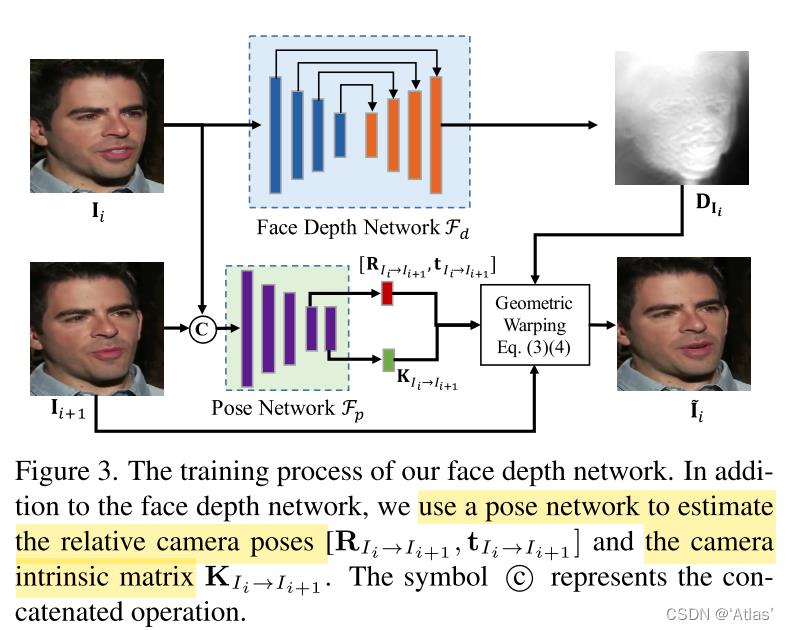
自监督Face Depth Learning
作者借鉴SfM-Learner,做出优化,使用连续帧
I
i
+
1
I_i+1
Ii+1作为源图和
I
i
I_i
Ii作为目标图,学习集合元素,深度图
D
I
i
D_I_i
DIi,相近内参矩阵
K
I
i
−
>
I
i
+
1
K_I_i->I_i+1
KIi−>Ii+1,相关相机姿态
R
I
i
−
>
I
i
+
1
R_I_i->I_i+1
RIi−>Ii+1及变换
t
I
i
−
>
I
i
+
1
t_I_i->I_i+1
tIi−>Ii+1,与SfM-Learner不同的是相机内参K需要学习;
流程如图3:
1、
F
d
F_d
Fd提取目标图
I
i
I_i
Ii的深度图
D
I
i
D_I_i
DIi;
2、
F
p
F_p
Fp提取可学习参数
R
、
t
、
K
R、t、K
R、t、K;
3、根据等式3、4将源图
I
i
+
1
I_i+1
Ii+1进行几何变换得到
I
i
′
I'_i
Ii′

q
k
q_k
qk表示源图
I
i
+
1
I_i+1
Ii+1上扭曲的像素;
p
j
p_j
pj表示目标图
I
i
I_i
Ii上原像素;
损失函数
P
e
P_e
Pe如式5所示,使用L1损失和SSIM损失
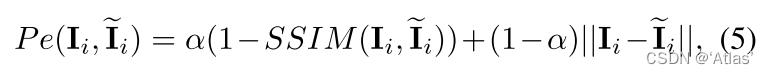
稀疏关键点运动建模
1、将RGB与
F
d
F_d
Fd提取深度图进行concat;
2、通过关键点估计模块
F
k
p
F_kp
Fkp获取人脸稀疏关键点,如式6,由于引入深度图,使得预测关键点更加准确;

特征扭曲策略,如图4
1、如式7,计算原图与驱动图之间初始偏移
O
n
O_n
On;
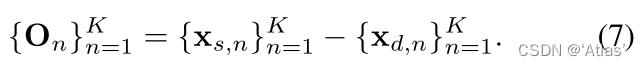
2、生成2D坐标map z;
3、将O应用于z,得到运动区域
w
m
w_m
wm;
4、使用
w
m
w_m
wm扭曲降采样后的图片得到初始扭曲的特征图;
5、遮挡估计器
τ
\\tau
τ通过扭曲的特征图预测运动流mask
M
m
M_m
Mm及遮挡图
M
o
M_o
Mo;
6、使用
M
m
M_m
Mm扭曲
I
s
I_s
Is经过编码器
ϵ
I
\\epsilon_I
ϵI获得的外观特征图,将其与
M
o
M_o
Mo融合生成
F
w
F_w
Fw,如式8。
F
w
F_w
Fw既保留原图信息又提取两张脸之间运动信息。
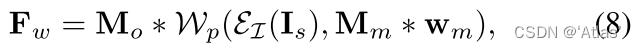
跨模态attention机制
为了有效利用学习到的深度图提升生成能力,作者提出跨模态attention机制,如图5.
1、通过深度编码器
ϵ
d
\\epsilon_d
ϵd提取深度图
D
s
z
D_sz
Dsz特征图
F
d
F_d
Fd;
2、 分别通过三个1X1卷积层将
F
d
F_d
Fd、
F
w
F_w
Fw映射为3个隐特征层
F
q
F_q
Fq、
F
k
F_k
Fk、
F
v
F_v
Fv;
3、如式9,通过attention生成
F
g
F_g
Fg。
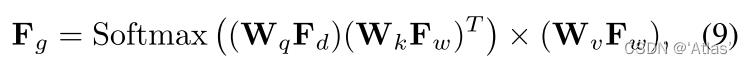
4、通过解码器精细化
F
g
F_g
Fg生成最终图像
I
g
I_g
Ig。
训练
训练过程中原图与驱动图是相同的,损失函数如式10, BERT:【 Pre-training of Deep Bidirectional Transformers for ○ 将预训练语言模型应用在下游任务中,一般有两种策略: 作者认为影响当前预训练语言模型的 瓶颈是——“模型是单向的” 。如 GPT 选择从左到右的架构,这使得每个 token 只能注意到它前面的 token,这对 sentence 级的任务影响还是次要的,但对于 token 级的任务来说影响就很巨大。例如问答任务,从两个方向结合上下文是至关重要的。 BERT 通过使用受完形填空任务启发的 Mask Language Model (MLM)缓解了先前模型的单向性约束问题。MLM 随机 mask 掉一些输入文本中的 token,然后根据剩下的上下文预测 masked 的 token。除了 Mask Language Model,作者还提出了 Next Sequence Predict 任务,来联合训练文本对表示。 论文中BERT的改进如下: 预训练前的一般语言表征有着悠久历史,本节我们简要回顾一下最广泛使用的方法。 2.1 基于特征的无监督方法 : 这些方法已被推广到更粗糙的粒度,例如句子嵌入(Kiros等人,2015;Logeswaran和Lee,2018)或段落嵌入(Le和Mikolov,2014)。为了训练句子表征,之前的工作已经使用了目标对候选下一个句子进行排序(Jernite等人,2017;Logeswaran和Lee,2018),根据前一个句子的表征从左到右生成下一个句子单词(Kiros等人,2015),或去噪自动编码器衍生的目标(Hill等人,2016)。 ELMo 及其前身(Peters等人,20172018a)从不同的维度概括了传统的单词嵌入研究。它们通过从左到右和从右到左的语言模型中提取上下文敏感的特征。每个标记的上下文表示是从左到右和从右到左表示的 串联 。在将上下文单词嵌入与现有任务特定架构相结合时,ELMo推进了几个主要NLP基准(Peters等人,2018a)的最新技术,包括问答(Rajpurkar等人,2016年)、情感分析(Socher等人,2013年)和命名实体识别(Tjong Kim-Sang和De Meulder,2003年)。Melamud等人(2016年)提出通过一项任务来学习语境表征,即使用 LSTM 从左右语境中预测单个单词。与ELMo类似,他们的模型是基于特征的,而不是深度双向的。Fedus等人(2018)表明,完形填空任务可以用来提高文本生成模型的 稳健性 。 2.2 无监督微调方法: 与 基于特征feature-based 的方法一样,第一种方法只在未标记文本中预先训练单词嵌入参数的情况下才朝这个方向工作。最近,产生上下文标记表示的句子或文档编码器已经从未标记的文本和文本中预训练出来针对受监督的下游任务进行了 微调fine-tuned 。 注解 :BERT的整体预训练和微调程序。除了输出层之外,在预训练和微调中使用相同的体系结构。相同的预训练模型参数用于初始化不同下游任务的模型。在微调过程中,所有参数都会微调。 2.3 基于监督数据的迁移学习: 本节将介绍BERT及其详细实现。在我们的框架中有两个步骤:预训练和微调。 BERT的一个显著特点是其跨不同任务的统一体系结构 。预训练的体系结构和最终的下游体系结构之间的差异最小。 BERT 的模型架构是 一种多层的双向 transformer encoder ,BERT 在实现上与 transformer encoder 几乎完全相同。 定义:transformer block 的个数为 L ; hidden 大小为 H; self-attentions head 的个数为 A. 作者主要展示了两种规模的 BERT 模型: 在这项工作中,我们将层数(即Transformer blocks)表示为L,隐藏大小表示为H,自我注意头的数量表示为A。我们主要报告两种型号的结果: 为了进行比较,选择BERT-base与OpenAI GPT具有相同的模型大小。然而,关键的是, BERT Transformer使用双向自注意力机制self-attention ,而 GPT Transformer使用受限自注意力机制constrained self-attention ,其中每个标记只能关注其左侧的上下文。 为了使 BERT 能处理大量不同的下游任务,作者将模型的输入设计成可以输入单个句子或句子对,这两种输入被建模成同一个 token 序列。作者使用了有 30000 个 token 的 vocabulary 词嵌入。 3.1 Pre-training BERT : Task #1: Masked LM 为了能够实现双向的深度预训练,作者选择 随机 mask 掉一些比例的 token ,然后预测这些被 masked 的 token,在这种设置下,被 masked 的 token 的隐向量表示被输出到词汇表的 softmax 上,这就与标准语言模型设置相同。作者将 这个过程称为“Masked LM”,也被称为“完形填空” 。 ○ Masked LM 预训练任务的缺点 : ○ BERT 的 mask策略: Task #2: Next Sentence Prediction (NSP) ○ Pre-training data : 3.2 Fine-tuning BERT : 对于不同的任务,只需要简单地将特定于该任务的输入输出插入到 Bert 中,然后进行 end2end 的fine-tuning。 与预训练相比,微调相对便宜。从完全相同的预训练模型开始,本文中的所有结果最多可以在单个云TPU上复制1小时,或在GPU上复制几个小时。 在本节中,我们将介绍11个NLP任务的BERT微调结果。 结果见表1。 BERT-base和BERT-large在所有任务上都比所有系统表现出色,与现有技术相比,平均准确率分别提高了4.5%和7.0% 。请注意,除了注意掩蔽,BERT-base和OpenAI GPT在模型架构方面几乎相同。 对于最大和最广泛报道的GLUE任务MNLI,BERT获得了4.6%的绝对准确率提高。在官方的GLUE排行榜10中,BERT-lagle获得80.5分,而OpenAI GPT在撰写本文之日获得72.8分。我们发现BERT-large在所有任务中都显著优于BERT-base,尤其是那些训练数据很少的任务。 4.2 SQuAD v1.1 : 如图1所示,在问答任务中,我们将输入的问题和段落表示为单个压缩序列,问题使用A嵌入,段落使用B嵌入。在微调过程,我们只引入一个起始向量S和一个端向量E。单词i作为答案范围开始的概率计算为Ti和S之间的点积,然后是段落中所有单词的softmax: 答案范围结束时使用类似公式。候选人从位置 i 到位置 j 的得分定义为:S·Ti + E·Tj ,最大得分跨度为 j≥ i 被用作预测。训练目标是正确起始位置和结束位置的对数概率之和。我们微调了3个阶段,学习率为5e-5,批量大小为32。 表2显示了顶级排行榜条目以及顶级发布系统的结果。SQuAD排行榜的前几名没有最新的公共系统描述,并且允许在训练系统时使用任何公共数据。因此,在我们的系统中使用适度的数据扩充,首先在TriviaQA上进行微调,然后再对团队进行微调。 我们表现最好的系统在ensembling方面的表现优于排名第一的系统,在ensembling方面的表现优于排名第一的系统+1.5 F1,在单一系统方面的表现优于排名第一的系统+1.3 F1得分。事实上,我们的单BERT模型在F1成绩方面优于顶级合奏系统。如果没有TriviaQA微调数据,我们只会损失0.1-0.4 F1,仍然远远超过所有现有系统。 其他实验:略 在本节中,我们对BERT的许多方面进行了消融实验,以便更好地了解它们的相对重要性。其他消融研究见附录C。 5.1 预训练任务的效果 : ○ 进行了如下消融测试: ○ 结果如下: 5.2 模型大小的影响 : ○ 结果如下: 作者证明了 :如果模型经过充分的预训练,即使模型尺寸扩展到很大,也能极大改进训练数据规模较小的下游任务。 5.3 将 Bert 应用于 Feature-based 的方法 : ○ feature-based 的方法是从预训练模型中提取固定的特征,不对具体任务进行微调 。 作者进行了如下实验:在 CoNLL-2003 数据集上完成 NER 任务,不使用 CRF 输出,而是从一到多个层中提取出激活值,输入到 2 层 768 维的 BiLSTM 中,再直接分类。结果如下: 结果说明:无论是否进行微调,Bert 模型都是有效的。 个人认为 Bert 的意义在于: 由于语言模型的迁移学习,最近的经验改进表明,丰富的、无监督的预训练是许多语言理解系统的一个组成部分。特别是,这些结果使得即使是低资源任务也能从深层单向体系结构中受益。我们的主要贡献是将这些发现进一步推广到深层双向体系结构中,使相同的预训练模型能够成功地处理广泛的NLP任务。 以上是关于DaGAN论文解读的主要内容,如果未能解决你的问题,请参考以下文章
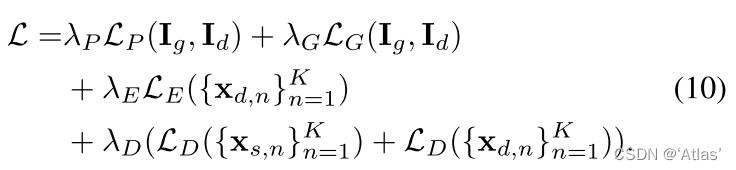
L
P
L_P
LP为感知损失;
L
G
L_G
L
参考技术A
Language Understanding】
几十年来,学习广泛适用的词汇表征一直是一个活跃的研究领域,包括非神经系统、神经系统方法。预训练的词嵌入是现代NLP系统的一个组成部分,与从头学习的嵌入相比,它提供了显著的改进(Turian等人,2010)。为了预先训练单词嵌入向量,已经使用了从左到右的语言建模目标(Mnih和Hinton,2009),以及在左右上下文中区分正确单词和错误单词的目标(Mikolov等人,2013)。
这些方法的 优点是 ,很少有参数需要从头学习。至少部分由于这一优势,OpenAI GPT在GLUE基准测试的许多句子级任务上取得了之前的最新成果。从左到右的语言建模和自动编码器目标已用于此类模型的预训练。
也有研究表明,在大数据集的监督任务中,如自然语言推理和机器翻译可以有效地进行转换。计算机视觉研究也证明了 从大型预训练模型中进行迁移学习的重要性 ,其中一个有效的方法是对使用ImageNet预训练模型进行微调。
我们不使用传统的从左到右或从右到左的语言模型来预训练BERT。相反,我们使用本节所述的两个无监督任务对BERT进行预训练。这一步如图1的左半部分所示。
标准的语言模型只能实现从左到右或从右到左的训练,不能实现真正的双向训练,这是因为双向的条件是每个单词能直接“看到自己”,并且模型可以在多层上下文中轻松的预测出目标词。
在于由于 [MASK] 标记不会出现在微调阶段,这就造成了预训练和微调阶段的不一致。为了解决该问题,作者提出了 一种折中的方案 :
很多下游任务都是基于对两句话之间的关系的理解,语言模型不能直接捕获这种信息。为了训练模型理解这种句间关系,作者 设计了 next sentence prediction 的二分类任务 。具体来说,就是选择两个句子作为一个训练样本,有 50% 的概率是下一句关系,有 50% 的概率是随机选择的句子对, 预测将 [CLS] 的最终隐状态 C 输入 sigmoid 实现 。
作者选用了BooksCorpus (800M words) 和 English Wikipedia (2,500M words) 作为预训练的语料库,作者只选取了 Wikipedia 中的文本段落,忽略了表格、标题等。为了获取长的连续文本序列,作者选用了 BIllion Word Benchmark 这样的文档级语料库,而非打乱的句子级语料库。
因为 transformer 中的 self-attention 机制适用于很多下游任务,所以可以直接对模型进行微调。对于涉及文本对的任务,一般的做法是独立 encode 文本对,然后再应用双向的 cross attention 进行交互。Bert 使用 self-attention 机制统一了这两个阶段,该机制直接能够实现两个串联句子的交叉编码。
4.1 GLUE:
GLUE (General Language Understanding Evaluation) 是多个 NLP 任务的集合。作者设置 batch size 为 32;训练 3 个 epochs;在验证集上从(5e-5, 4e-5, 3e-5, 2e-5)中选择最优的学习率。结果如下:
斯坦福问答数据集(SQuAD v1.1)收集了10万对众包问答对。给出一个问题和一段维基百科中包含答案的文章,任务是预测文章中的答案文本。
○ 这样的方法也有一定的优点 :