论文阅读一种端到端的对抗生成式视频数字水印算法
Posted fuhanghang@yeah.net
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读一种端到端的对抗生成式视频数字水印算法相关的知识,希望对你有一定的参考价值。
2021.07中国科技论文
【摘要】提出了一种端到端的对抗生成式视频盲水印嵌入提取算法。该算法主要由编码器和解码器组成,编码器用于生成包含水印信息的视频,解码器用于提取视频中所包含的水印信息。不同于传统的基于频域或空域的视频水印方法,用端到端的训练方式的同时优化编码器和解码器网络。在编码器训练过程中模拟不同的信号和几何攻击类型,生成对抗样本,优化整个网络,以保证所生成水印样本的不可感知性和鲁棒性。实验结果表明:该算法对缩放、平移、裁剪等几何类攻击和压缩、噪声等信号类攻击都具有较强的鲁棒性;同时,该算法独立地训练每一个关键帧,因此还可以抵抗视频中的时间同步攻击。
算法主要包含编码器和解码器 2 部分。
编码器根据 Goodfellow 等[1 6]提出的快速递度符号法(fastgradient sign method,FGSM)为视频关键帧 X 添加扰动p ,生成对抗性样本 X’,ε为扰动强度,取值范围为[0,1],ε越大,扰动越明显,在降低模型精度方面越有效,但同时原始图像的改变也越容易被人眼察觉。
解码器 D 由 1 个深度神经网络构成,将对抗性样本解码为与水印W 长度相同的序列W’。
编码器与解码器采用对抗的方式进行优化。编码器通过加入扰动 p ,生成让解码器解码错误的对抗性样本;解码器将对抗性样本解码成功,即W’=W。
利用编码器生成包含噪声样本进行对抗训练时主要包括 2 个过程[17-18]:
1)生成使预测损失最大化的扰动 p
2)更新使预测损失最小化的模型参数θ
通过不断迭代对抗训练的过程,学习可得可抵抗几何攻击的嵌入水印。端到端的对抗生成式视频数字水印算法流程如图 1 所示。
采用了在期望最大化框架下训练解码器的方法。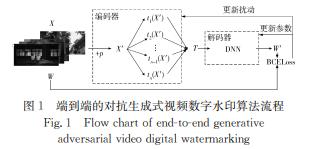
客观评价视频数字水印性能主要有峰值信噪比(peak signal to noise ratio,PSNR)和归一化相关系数(normalized cross-correlation,NC)这 2 种方法。
峰值信噪比
图像在嵌入水印后,像素级别会与原始图像有差异,PSNR 值越大,含水印图像与原图像的差异越小,意味着水印的不可见性越高,表示为
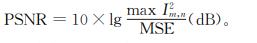
式中,MSE 为均方误差,且有
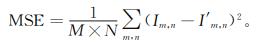
式中:I 为原始图像;I’ 为嵌入水印的图像;m×n 和M×N 为图像的大小。
归一化相关系数
原始水印序列和提取出来的水印序列的相似程度可以用归一化相关系数来衡量,表示为
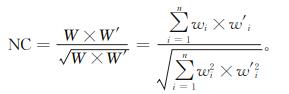
式中:W 为原始水印序列;W’ 为提取出来的水印序列。
算法效果:
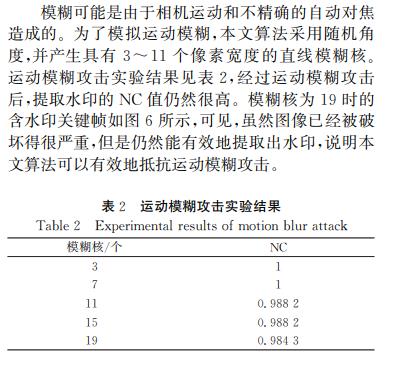
运动模糊攻击:
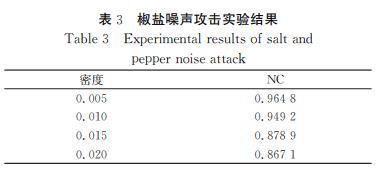
椒盐噪声:

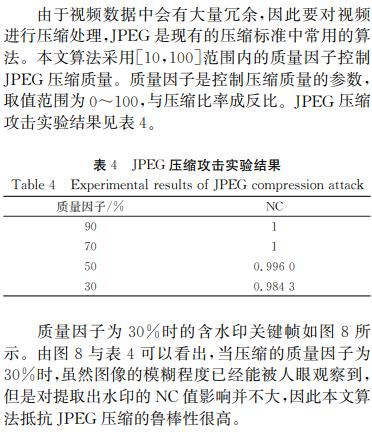
JPEG 压缩:
旋转:

缩放:

平移:

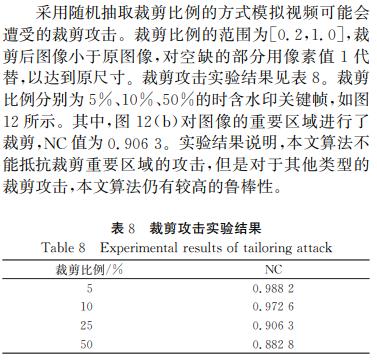
裁剪:
时间同步攻击:
发明专利
优点:提出了一种端到端的对抗生成式视频水印方法,利用对抗样本的思想,生成对抗扰动作为水印(水印为二值的一维数组,水印的前32位设置为固定的标志位,提取 水 印 时 可 以 根 据 标 志 位 匹 配 提
取的序列是否为水印。),除了对常见的图像处理攻击具有鲁棒性,还可抵抗几何攻击,算法独立的训练每一个关键帧,还可抵抗时间同步攻击。
首 先 读 取 视 频,抽 取 视 频 的关键帧,记录关键帧在原视频中的位置,对于每个关键帧,都进行图像归一化操作,随机初始化解码器的参数和扰动p的大小,开始训练网络,根据原始的关键帧和扰动生成对抗 性 样 本 X′,将 X′ 作 为 网 络 的输入。
缺点:旋转范围小,未考虑水平、垂直翻转如视频开镜像等情况,以及去水印攻击、混淆攻击、摄像机攻击
常见的几种噪声:
(1)高斯噪声
(2) 椒盐噪声
(3)泊松噪声
(4)乘性噪声
深度学习AI美颜系列---AutoRetouch端到端美颜方案
AI美颜的其中一种模式,就是直接使用端到端的训练模式。
这里详细介绍一种端到端的美颜算法,使用的论文是:AutoRetouch:Automatic Professional Face Retouching
这篇论文是一个典型的端到端美颜模式,即原图输入网络,美颜后的效果图输出,这种模式基本上都是使用Pix2Pix类似的GAN网络架构来实现。此类模式,非常适合美颜类特效的处理。理论上,只要有成对的有规律的数据,使用Pix2Pix就是个不错的选择。这也是一种偷懒的方式,因为你不必理会效果中缩包含的复杂的算法,你缩担心的问题只有数据。
原版的Pix2Pix有些问题,比如清晰度不够,无法生成高清图像等,因此有了Pix2PixHD版本,这些内容大家可以到网上自行了解,这里要讲的是论文算法。
论文的网络结构:G和D网络
D网络使用了Pix2Pix的原版D网络;
G网络如下:
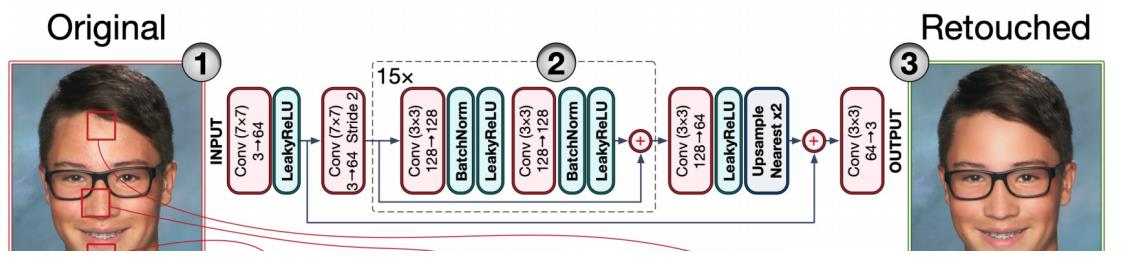
这个网络也比较简单,截图来自论文,输入3通道的原图,输出美颜后的效果图。原图输入后先做了一个大核7X7的卷积,通道扩增为64,然后是LeakyReLU层,接着是卷积下采样(这里下采样通道数好像写错了,应该是64-128),下采样之后是个15层的Resblock模块,每个模块中包含两次卷积+BN+LeakyReLU,最后是跳跃层Add。Resblock之后,是卷积和上采样,同时与前面对应层进行连接Add,在卷积输出效果图。整体上看是一个极简单的Unet结构,只是用了一次下采样,一次连接层。论文中说这样做的目的是为了更好的保留细节纹理。
有了G和D网络,剩下的就是LOSS,这篇论文依旧采用很普遍的LOSS:

LOSS使用的是标准GAN 的LOSS和感知LOSS以及MSE三者的加权,权重选择如上所示。单独使用 MSE 损失可以得到平滑的图像,加入 perceptual loss(感知损失)可以改善这种情况。但是,感知损失仍然不能保留精细的细节。加上 adversarial loss 可以促使网络对图像进行尽可能少的改变。
整体上看,这篇论文是个中规中矩的GAN网络训练论文,本文只是借此来说一下这种美颜的模式。
论文效果图如下:
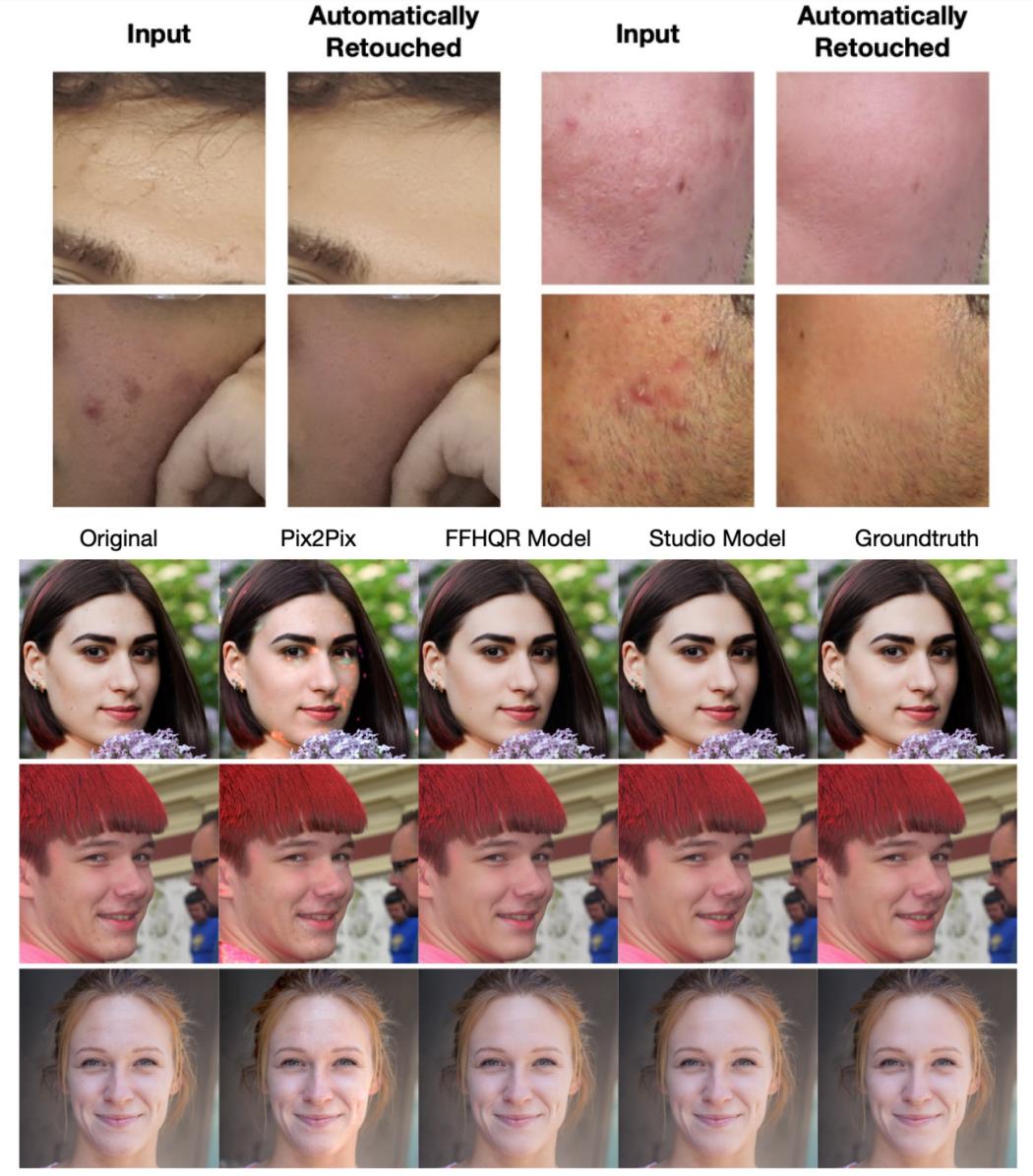
论文使用的数据集是FFHQR Dataset,地址:https://github.com/skylab-tech/ffhqr-dataset
论文地址:
本人复现的代码如下:
def resblock(self, inputs, out_channel = 32):
x = Conv2D(out_channel, kernel_size = (3,3), padding = "same")(inputs)
x = BatchNormalization(momentum=0.8)(x)
x = LeakyReLU(alpha = 0.2)(x)
x = Conv2D(out_channel, kernel_size = (3,3), padding = "same")(x)
x = BatchNormalization(momentum=0.8)(x)
x = LeakyReLU(alpha = 0.2)(x)
return Add()([x, inputs])
#G网络定义
def build_generator(self,input_shape=(None,None,3)):
inputs = Input(shape = input_shape, name="inputs")
channel = 64
x = Conv2D(channel, kernel_size = (7,7),strides = (1,1), padding = "same")(inputs) #1024*1024
x = LeakyReLU(alpha = 0.2)(x)
x0 = x
x = Conv2D(channel * 2, kernel_size = (3,3),strides = (2,2), padding = "same")(x) #512*512
for idx in range(15):
x = self.resblock(inputs = x, out_channel = channel * 2)
x = Conv2D(channel, kernel_size = (3,3),strides = (1,1), padding = "same")(x) #512*512
x = LeakyReLU(alpha = 0.2)(x)
x = UpSampling2D((2,2))(x)
x = Add()([x, x0])
x = Conv2D(3, kernel_size = (3,3), padding = "same", activation='tanh')(x)
model = Model(inputs, x)
model.summary()
return model
#D网络定义
def build_discriminator(self):
# layer 0
def d_layer(layer_input, filters, f_size=4, bn=True):
"""Discriminator layer"""
d = Conv2D(filters, kernel_size=f_size, strides=2, padding='same')(layer_input)
d = LeakyReLU(alpha=0.2)(d)
if bn:
d = BatchNormalization(momentum=0.8)(d)
return d
img_A = Input(shape=self.img_shape)
img_B = Input(shape=self.img_shape)
# Concatenate image and conditioning image by channels to produce input
combined_imgs = Concatenate(axis=-1)([img_A, img_B])
d1 = d_layer(combined_imgs, self.df, bn=False)
d2 = d_layer(d1, self.df*2)
d3 = d_layer(d2, self.df*4)
d4 = d_layer(d3, self.df*8)
validity = Conv2D(1, kernel_size=4, strides=1, padding='same')(d4)
model = Model([img_A, img_B], validity)
model.summary()
return model这里说下本人实现时遇到的问题,本人用了FFHQR中前面两万张数据进行训练,但是网络无法收敛,经常模型坍塌,后来发现有两个原因:
①数据太少,应该把7万数据都拿来训练,才能学到规律;
②数据中有些样本效果有问题,比如脸上的痘印,有些图去除的很干净,相反有些图却没有去掉,这种样本较多,导致了样本的无规律性,因此,如果样本数量较少,无法学到规律;
举例如下图所示:左边为效果图,右边为原图,可以看到左边效果图中的人脸痘痘根本没有去除;

上述就是端到端通用解决方案的介绍,完整的代码工程下载:关注微信公众号“SF图像算法”,回复“AutoRetouch"即可获取免费下载连接!
本人QQ:1358009172,AI美颜算法交流群:600926436,欢迎技术交流!
以上是关于论文阅读一种端到端的对抗生成式视频数字水印算法的主要内容,如果未能解决你的问题,请参考以下文章
带你读AI论文丨LaneNet基于实体分割的端到端车道线检测