HiveSQL源码之语法词法编译文件解析一文详解
Posted fanstuck
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HiveSQL源码之语法词法编译文件解析一文详解相关的知识,希望对你有一定的参考价值。
目录
前言
工欲善其事必先利其器,首先要了解HiveSQL的编译语法的流程,还是需要懂得HiveSQL的执行流程以及编译规则。曾经在Hive数仓搭建的时候写过部分HiveSQL编译原理:
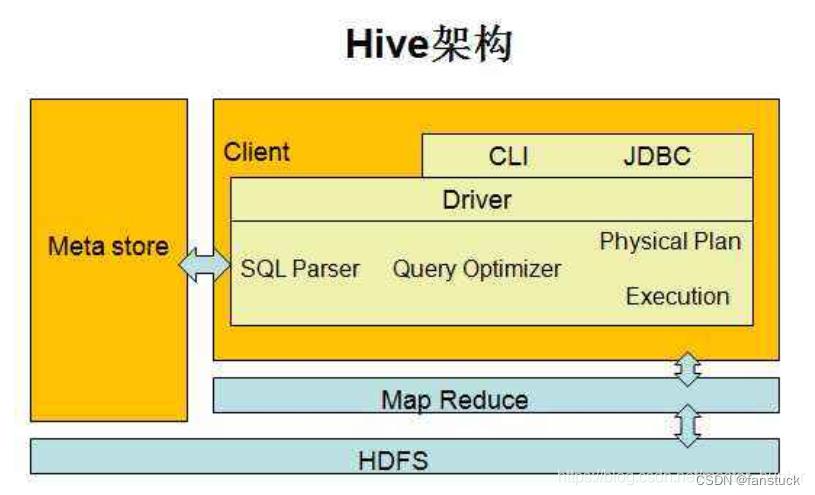
我们现在主要研究SQL Parser语法解析这块内容。语法解析可以说是研究一门编程语言的基础了,我们编程语言本身就是告诉计算机要帮助我们做什么事。antlr是编译原理领域比较著名的工具了,这次借助研究hivesql的机会,安装使用一下antlr。
一、Hive SQL编译流程
我们可以这么理解HiveSQL执行以及编译的过程,我们人与人之间的交流可以映射到人与计算机的关系之中,我们可以将计算机视为一个不懂我们本身母语以及其他你熟悉的语言,就像一个外国人你们无法交流。但是我们可以通过翻译器,就像百度翻译一样你输入你的语言,这个翻译器将其翻译为外语,再给外国人看,你们就能懂彼此之间的意思了。人与计算机也是一样的,但是中间的翻译器将需要处理纷繁复杂的语法逻辑问题,中文转英文也存在很多逻辑上面的不同之处,这些都是需要翻译器根据语言逻辑来处理的问题。
我们回顾一下Hive SQL编译流程:

- Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree
- 遍历AST Tree,抽象出查询的基本组成单元QueryBlock
- 遍历QueryBlock,翻译为执行操作树OperatorTree
- 逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量
- 遍历OperatorTree,翻译为MapReduce任务
- 物理层优化器进行MapReduce任务的变换,生成最终的执行计划
那么这里我们就需要了解一下Antrl到底是何方神器了,可以将我们输入的sql语言转换为可识别的语法树。
二、Antrl
Antlr是一种语言识别的工具,可以用来构造领域语言。
使用antlr需要我们提前定义好识别字符流的词法规则和用于解释Token流的语法分析规则。然后,antlr会根据我们提供的语法文件自动生成相应的词法/语法分析器。hive借助Antlr定义SQL的词法规则和语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree。HiveSql后续的编译过程全都基于AST Tree,所以我们想要完整理解hive sql的编译过程,需要前置了解一下antlr是怎么工作的。

- 词法分析器(Lexer):功能如其名,解析字符流的逻辑关系将其分割为离散的Token字符组,供给语法分析器使用。
- 语法分析器(Parser):将上一步得到的Token流转换为语法定义的树结构。
- 树分析器(TreeParser):将对语法分析生成的抽象语法数进行遍历,分析处理获得基于语句块的内部查询表达式。
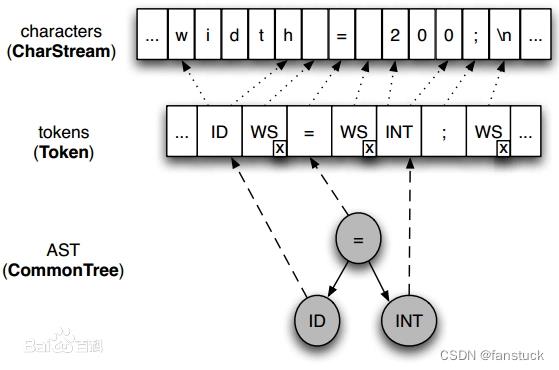
ANTLR将上述结合起来,它允许我们定义识别字符流的词法规则和用于解释Token流的语法分析规则。然后,ANTLR将根据用户提供的语法文件自动生成相应的词法/语法分析器。用户可以利用他们将输入的文本进行编译,并转换成其他形式(如AST—Abstract Syntax Tree,抽象的语法树)。
我们可以使用antlr来进一步理解antlr是如何做到解析过程的。
三、ANTLRWorks
通过ANTLRWorks可以更加直观的理解解析过程,下载:antlrworks-1.5.1.jar
该程序下载完即可使用,AntlWorks是一个用于构建ANTLR v3语法的GUI开发环境。它是一个独立的Java应用程序,只需单击即可开始使用ANTLR。它包含所有必要的JAR,是开始使用ANTLR的最简单方法。1.5.1是最新的稳定版本,包含ANTLR v3.5.2。
下载完毕之后:
建立一个新的.g文件:
可输入这段测试代码:
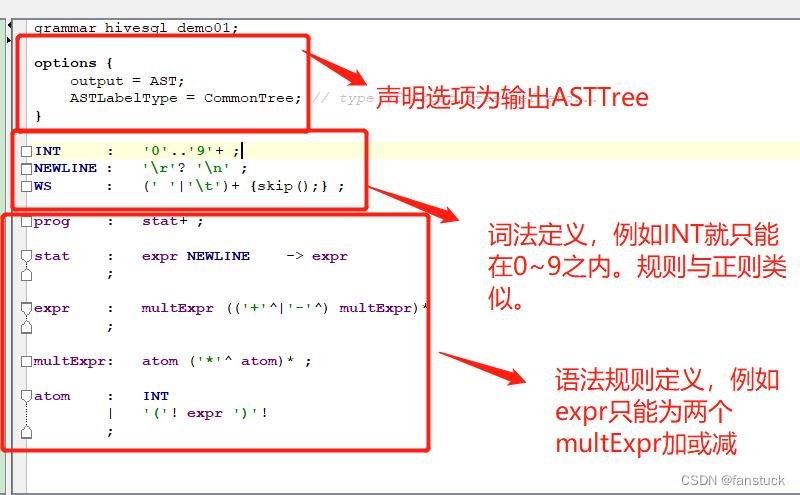
点击Generate生产代码:
成功生产之后调试: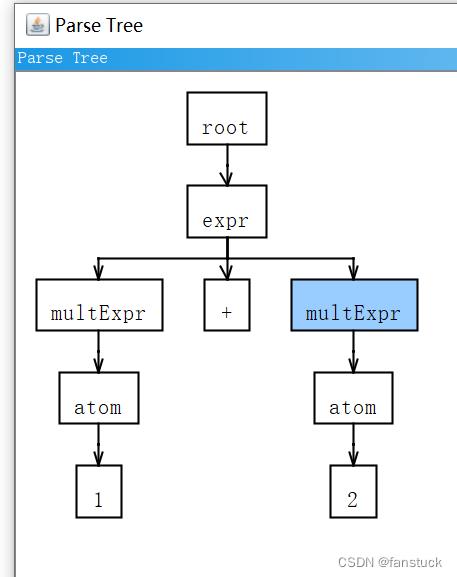
输入txt选择expr模式,这就是解析sql语法程序运行结果。
根据此原因我们可以去看Hive开源文档中有关sql的语法定义规则:
https://github.com/apache/hive/tree/branch-3.1/ql/src/java/org/apache/hadoop/hive/ql/parse
通过选择branch可以调整Hive版本,里面不难发现存在多个.g文件,这些文件就是HiveSQL编译的语法定义文件,一句SQL将拆分成很多文件去处理。
共有这么几个,其中文件名称很明显对应着各个语法定义规则。
- HiveLexer.g:词法解析文件,定义了所有用到的token。
- HiveParser.g:语法解析文件,实现了所有的Hive语法解析。
- FromClauseParser.g:FROM语句解析。
- IdentifiersParser.g:自定义函数解析,标识符定义 函数名称、系统函数、关键字等。
- nonReserved,非保留的关键字可以作为标识符的。比如 select a as date from mytable 这个date不添加转义会报错的,但是该处如果添加 “ | KW_DATE ” date可直接作为标识符使用。
- SelectClauseParser.g:select语句解析。
- HintParser.g:hive的hint语法解析。
- ResourcePlanParser.g:资源操作语法解析。
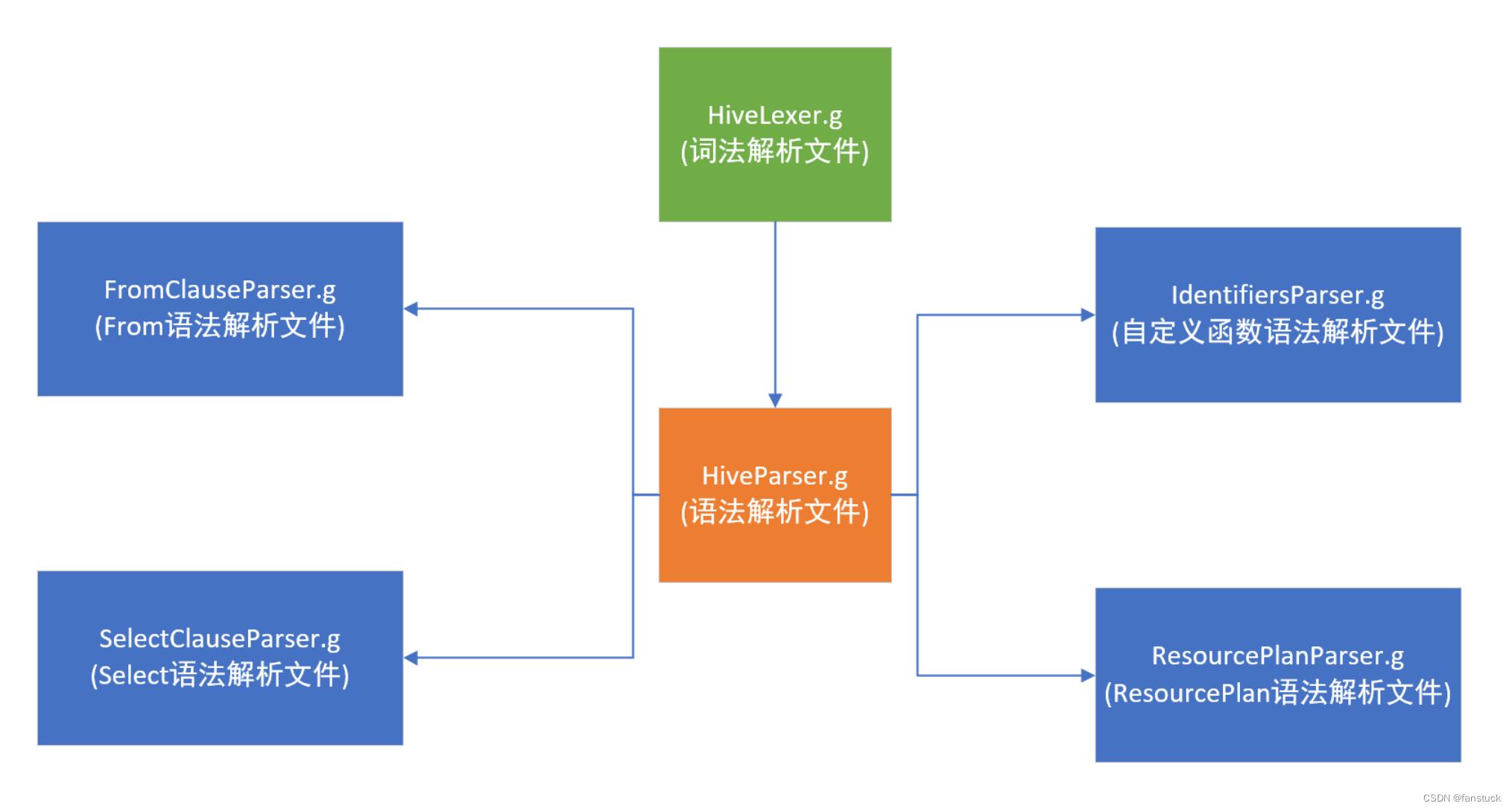
我们可以发现HiveParser.g文件中存在:
也就是将一句SQL给分割开来分别根据每个SQL语句标识符进行解析,解决把所有语法塞入到一个文件里导致编译出来的java文件过大和逻辑多了之后不容易阅读的问题。而HintParser.g并不包括在HiveParser.g内,是独立存在的一个处理文件。
参阅
以上是关于HiveSQL源码之语法词法编译文件解析一文详解的主要内容,如果未能解决你的问题,请参考以下文章