电信客服项目笔记
Posted 程序员小憨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了电信客服项目笔记相关的知识,希望对你有一定的参考价值。
电信客服案例笔记
如需获取项目源码请点击访问:https://gitee.com/fanggaolei/learning-notes-warehouse
1.0 Hadoop准备
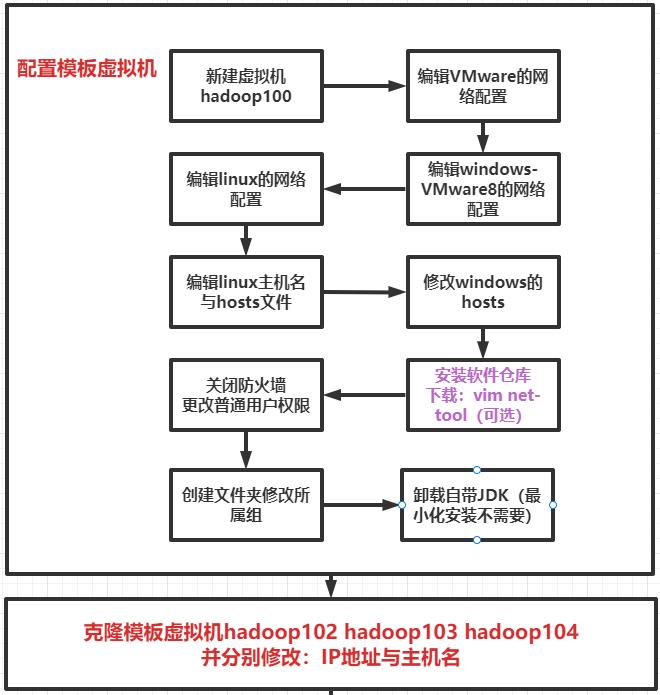
1.1克隆虚拟机102,103,104
(1)修改克隆虚拟机的静态IP
vim /etc/sysconfig/network-scripts/ifcfg-ens33
(2)修改主机名
vim /etc/hostname
(3)连接xshell和XFTP
1.2伪分布式的测试

(1)将下面六个文件放入/opt/software目录下
apache-flume-1.9.0-bin.tar.gz
apache-zookeeper-3.5.7-bin.tar.gz
hadoop-3.1.3.tar.gz
hbase-2.4.11-bin.tar.gz
jdk-8u212-linux-x64.tar.gz
kafka_2.12-3.0.0.tgz
(2)将JDK和Hadoop两个文件分别解压
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
(3)添加JDK和Hadoop的环境变量
sudo vim /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
最后让文件生效:
source /etc/profile
(4)对虚拟机进行重启并验证hadoop和JDK是否安装成功
java -version
hadoop version Hadoop 3.1.3
可以看到
Hadoop 3.1.3
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
Compiled by ztang on 2019-09-12T02:47Z
Compiled with protoc 2.5.0
From source with checksum ec785077c385118ac91aadde5ec9799
This command was run using /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
跳过伪分布式启动
1.3完全分布式搭建
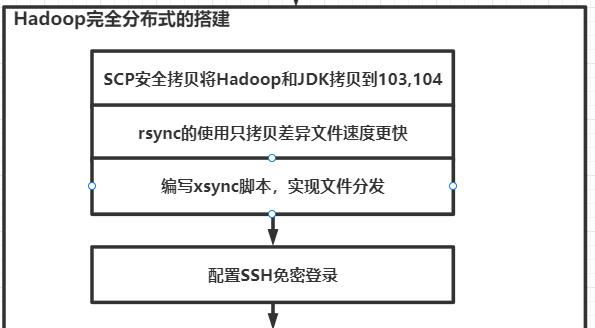
(1)首先进行ssh免密登录
生成公钥和私钥
[atguigu@hadoop102 .ssh]$ pwd
/home/atguigu/.ssh
[atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登录的目标机器上(每个机器上均执行以下三个命令)
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop104
(2)测试成功后进行xsync配置
(a)在/home/atguigu/bin目录下创建xsync文件
[atguigu@hadoop102 opt]$ cd /home/atguigu
[atguigu@hadoop102 ~]$ mkdir bin
[atguigu@hadoop102 ~]$ cd bin
[atguigu@hadoop102 bin]$ vim xsync
在该文件中编写如下代码
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
(b)修改脚本 xsync 具有执行权限
[atguigu@hadoop102 bin]$ chmod +x xsync
(c)测试脚本
[atguigu@hadoop102 ~]$ xsync /home/atguigu/bin
(d)将脚本复制到/bin中,以便全局调用
[atguigu@hadoop102 bin]$ sudo cp xsync /bin/
(e)同步环境变量配置(root所有者)
[atguigu@hadoop102 ~]$ sudo ./bin/xsync /etc/profile.d/my_env.sh
注意:如果用了sudo,那么xsync一定要给它的路径补全。
让环境变量生效
[atguigu@hadoop103 bin]$ source /etc/profile
[atguigu@hadoop104 opt]$ source /etc/profile
(3)检查103 104 上的环境变量是否生效,若果没有生效可以重启虚拟机再次检查
java -version
hadoop version Hadoop 3.1.3
1.4对配置文件进行配置

(1)核心配置文件
[atguigu@hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop
[atguigu@hadoop102 hadoop]$ vim core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value> !!!记得换成自己的用户名
</property>
</configuration>
(2)HDFS 配置文件
[atguigu@hadoop102 hadoop]$ vim hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
(3)YARN 配置文件
[atguigu@hadoop102 hadoop]$ vim yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
(4)MapReduce 配置文件
[atguigu@hadoop102 hadoop]$ vim mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
</configuration>
(5)配置 workers
[atguigu@hadoop102 hadoop]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
hadoop102
hadoop103
hadoop104
同步所有配置
[atguigu@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc
(6)初始化NameNode
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
(7)编写myhadoop.sh脚本
[atguigu@hadoop102 ~]$ cd /home/atguigu/bin
[atguigu@hadoop102 bin]$ vim myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
记得添加执行权限
[atguigu@hadoop102 bin]$ chmod +x myhadoop.sh
(8)编写jpsall脚本
[atguigu@hadoop102 ~]$ cd /home/atguigu/bin
[atguigu@hadoop102 bin]$ vim jpsal
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done
添加脚本并分发脚本
[atguigu@hadoop102 bin]$ chmod +x jpsall
[atguigu@hadoop102 ~]$ xsync /home/atguigu/bin/
在103 104上添加执行权限
(9)启动集群
myhadoop.sh start 启动集群
jpsall 查看所有节点是否启动
(10)查看3个网址是否可以正常访问
http://hadoop102:9870
http://hadoop103:8088/
http://hadoop102:19888/jobhistory
如果节点都正常启动,页面无法访问,检查hosts文件是否修改,如果无误,可以重写启动,并进行测试
2.0 zookeeper准备
2.1解压安装
解压
[atguigu@hadoop102 software]$ tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
更名
[atguigu@hadoop102 module]$ mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7
2.2文件配置
配置服务器编号
(1)在/opt/module/zookeeper-3.5.7/这个目录下创建 zkData
[atguigu@hadoop102 zookeeper-3.5.7]$ mkdir zkData
(2)在/opt/module/zookeeper-3.5.7/zkData 目录下创建一个 myid 的文件
[atguigu@hadoop102 zkData]$ vi myid
在文件中添加与 server 对应的编号(注意:上下不要有空行,左右不要有空格)
2
[atguigu@hadoop102 module ]$ xsync zookeeper-3.5.7
vim /opt/module/zookeeper-3.5.7/zkData/myid
并分别在 hadoop103、hadoop104 上修改 myid 文件中内容为 3、4
(3)配置zoo.cfg文件
(1)重命名/opt/module/zookeeper-3.5.7/conf 这个目录下的 zoo_sample.cfg 为 zoo.cfg
[atguigu@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg
(2)打开 zoo.cfg 文件
[atguigu@hadoop102 conf]$ vim zoo.cfg
#修改数据存储路径配置
dataDir=/opt/module/zookeeper-3.5.7/zkData
#增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
(3)同步 zoo.cfg 配置文件
[atguigu@hadoop102 conf]$ xsync zoo.cfg
(4)编写启停脚本
1)在 hadoop102 的/home/atguigu/bin 目录下创建脚本
[atguigu@hadoop102 bin]$ vim zk.sh
#!/bin/bash
case $1 in
"start")
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
;;
"stop")
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
;;
"status")
for i in hadoop102 hadoop103 hadoop104
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"
done
;;
esac
2)增加脚本执行权限
[atguigu@hadoop102 bin]$ chmod u+x zk.sh
3)Zookeeper 集群启动脚本
[atguigu@hadoop102 module]$ zk.sh start
4)Zookeeper 集群停止脚本
[atguigu@hadoop102 module]$ zk.sh stop
输入jpsall正常启动即可
(5)zookeeper的操作
启动zookeeper客户端
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkCli.sh -server hadoop102:2181
查看zookeeper节点信息
[zk: hadoop102:2181(CONNECTED) 0] ls /
3.0HBase准备
HBase 通过 Zookeeper 来做 master 的高可用、记录 RegionServer 的部署信息、并且存储有 meta 表的位置信息。
HBase 对于数据的读写操作时直接访问 Zookeeper 的,在 2.3 版本推出 Master Registry 模式,客户端可以直接访问 master。使用此功能,会加大对 master 的压力,减轻对 Zookeeper的压力。
3.1解压安装、环境变量
1)解压 Hbase 到指定目录
[atguigu@hadoop102 software]$ tar -zxvf hbase-2.4.11-bin.tar.gz -C /opt/module/
[atguigu@hadoop102 software]$ mv /opt/module/hbase-2.4.11 /opt/module/hbase
2)配置环境变量
[atguigu@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh
添加
:
3)使用 source 让配置的环境变量生效
[atguigu@hadoop102 module]$ source /etc/profile.d/my_env.sh
[fang@hadoop102 hbase]$ sudo /home/fang/bin/xsync /etc/profile.d/my_env.sh
3.2文件配置
1)hbase-env.sh 修改内容,可以添加到最后:
在hbase/conf目录下
[fang@hadoop102 conf]$ vim hbase-env.sh
最后面添加一句
export HBASE_MANAGES_ZK=false
2)hbase-site.xml 修改内容: 把原先标签内的内容删掉,直接替换成下方的即可
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
<description>The directory shared by RegionServers.
</description>
</property>
<!-- <property>-->
<!-- <name>hbase.zookeeper.property.dataDir</name>-->
<!-- <value>/export/zookeeper</value>-->
<!-- <description> 记得修改 ZK 的配置文件 -->
<!-- ZK 的信息不能保存到临时文件夹-->
<!-- </description>-->
<!-- </property>-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop102:8020/hbase</value>
<description>The directory shared by RegionServers.
</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
3)修改regionservers
hadoop102
hadoop103
hadoop104
4)解决 HBase 和 Hadoop 的 log4j 兼容性问题,修改 HBase 的 jar 包,使用 Hadoop 的 jar 包
[atguigu@hadoop102hbase]$mv /opt/module/hbase/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar /opt/module/hbase/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar.bak
发送到其他
xsync hbase/
5)Hbase启停
[atguigu@hadoop102 hbase]$ bin/start-hbase.sh
[atguigu@hadoop102 hbase]$ bin/stop-hbase.sh
4.0 Flume准备
4.1解压安装
解压
[atguigu@hadoop102 software]$ tar -zxf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/module/
改名
[atguigu@hadoop102 module]$ mv /opt/module/apache-flume-1.9.0-bin /opt/module/flume
将 lib 文件夹下的 guava-11.0.2.jar 删除以兼容 Hadoop 3.1.3
[atguigu@hadoop102 lib]$ rm /opt/module/flume/lib/guava-11.0.2.jar
4.2 配置
(1)安装 netcat 工具
[atguigu@hadoop102 software]$ sudo yum install -y nc
(2)判断 44444 端口是否被占用
[atguigu@hadoop102 flume-telnet]$ sudo netstat -nlp | grep 44444
(3)创建 Flume Agent 配置文件 flume-netcat-logger.conf
(4)在 flume 目录下创建 job 文件夹并进入 job 文件夹。
[atguigu@hadoop102 flume]$ mkdir job
[atguigu@hadoop102 flume]$ cd job/
(5)在 job 文件夹下创建 Flume Agent 配置文件 flume-netcat-logger.conf。
[atguigu@hadoop102 job]$ vim flume-netcat-logger.conf
(6)在 flume-netcat-logger.conf 文件中添加如下内容。
添加内容如下:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
(7)先开启 flume 监听端口
[atguigu@hadoop102 flume]$ bin/flume-ng agent -c conf/ -n a1 -f job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console
复制102会话
(8)使用 netcat 工具向本机的 44444 端口发送内容
[atguigu@hadoop102 ~]$ nc localhost 44444
到这就可以了,项目中会继续进行配置
5.0 Kafka准备
5.1解压安装配置环境变量
解压
[atguigu@hadoop102 software]$ tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/
改名
[atguigu@hadoop102 module]$ mv kafka_2.12-3.0.0/ kafka
进入到/opt/module/kafka 目录,修改配置文件
[atguigu@hadoop102 kafka]$ cd config/
[atguigu@hadoop102 config]$ vim server.properties
修改三个地方:记得找对相应的位置
#broker 的全局唯一编号,不能重复,只能是数字。
broker.id=0
#kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以
配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/opt/module/kafka/datas
# 检查过期数据的时间,默认 5 分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
#配置连接 Zookeeper 集群地址(在 zk 根目录下创建/kafka,方便管理)
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
分发
[atguigu@hadoop102 module]$ xsync kafka/
分别在 hadoop103 和 hadoop104 上修改配置文件
[fang@hadoop102 flume]$ vim /opt/module/kafka/config/server.properties
中的 broker.id=1、broker.id=2
在/etc/profile.d/my_env.sh 文件中增加 kafka 环境变量配置
[atguigu@hadoop102 module]$ sudo vim /etc/profile.d/my_env.sh
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
刷新
[atguigu@hadoop102 module]$ source /etc/profile
分发并刷新
[atguigu@hadoop102 module]$ sudo /home/atguigu/bin/xsync /etc/profile.d/my_env.sh
[atguigu@hadoop103 module]$ source /etc/profile
[atguigu@hadoop104 module]$ source /etc/profile
5.2集群启动
(1)先启动 Zookeeper 集群,然后启动 Kafka。
[atguigu@hadoop102 kafka]$ zk.sh start
(2)集群脚本
1)在/home/atguigu/bin 目录下创建文件 kf.sh 脚本文件
[atguigu@hadoop102 bin]$ vim kf.sh
#! /bin/bash
case $1 in
"start" )
for i in hadoop102 hadoop103 hadoop104;
do
echo "==============$i start=============="
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
;;
"stop" )
for i in hadoop102 hadoop103 hadoop104;
do
echo "==============$i stop=============="
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh"
done
;;
esac
2)添加执行权限
[atguigu@hadoop102 bin]$ chmod +x kf.sh
3)启动集群命令
[atguigu@hadoop102 ~]$ kf.sh start
4)停止集群命令
[atguigu@hadoop102 ~]$ kf.sh stop
6.0Redis环境配置
1.将软件包上传到/opt/softwere目录下,解压到/opt/modul下
[root@linux softwere]# tar -zxvf redis-3.0.0.tar.gz -C /opt/module/
2.进入redis目录进行启动
[root@linux redis-3.0.0]# make
出现如下报错:没有找到gcc,此时需要安装gcc
[root@linux module]# yum -y install gcc
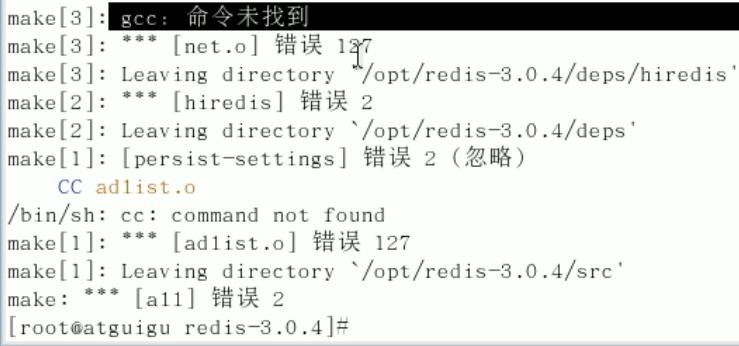
安装完成后验证是否安装成功
[root@linux module]# gcc -v
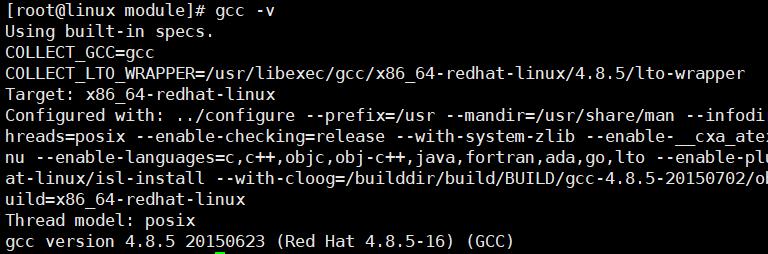
3.再次进行make出现如下报错

此时执行
#清理残余文件
make distclean
#再次进行make
make
执行成功
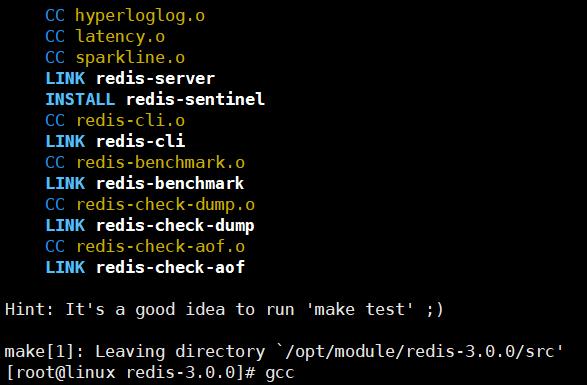
4.执行
make install
5.查看安装目录
[root@linux redis-3.0.0]# cd /usr/local/bin/
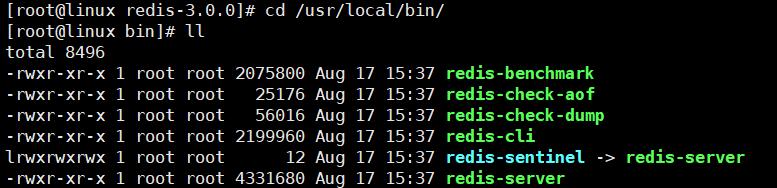
6.回到Redis目录备份文件
#在根目录创建文件夹
[root@linux /]# mkdir myredis
#将redis.conf移动到文件夹汇总
[root@linux redis-3.0.0]# cp redis.conf /myredis/
#在myredis目录中编辑文件
[root@linux myredis]# vi redis.conf
#切换目录
[root@linux myredis]# cd /usr/local/bin/
#启动redis
[root@linux bin]# redis-server /myredis/redis.conf
#查看客户端
[root@linux bin]# redis-cli -p 6379

测试
查看redis在后台是否启动
[root@linux bin]# ps -ef|grep redis

集群环境查看
此时输入:jpsall 可查看到一下节点相应信息
| 软件 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|
| Hadoop HDFS | NameNode | SecondaryNameNode | |
| DataNode | DataNode | DataNode | |
| Hadoop YARN | ResourceManager | ||
| NodeManager | NodeManager | NodeManager | |
| Hadoop历史服务器 | JobHistoryServer | ||
| Zookeeper | QuorumPeerMain | QuorumPeerMain | QuorumPeerMain |
| Kafka | Kafka | Kafka | Kafka |
| HBase | HMaster | ||
| HRegionServer | HRegionServer | HRegionServer | |
| jsp | jsp | jsp |
集群停止脚本:**
Hadoop启停:
myhadoop.sh start
myhadoop.sh stop
HBase启停:
bin/start-hbase.sh
bin/stop-hbase.sh
Zookeeper启停: 先启停Zookeeper再启停Kafka
zk.sh start
zk.sh stop
KafKa启停:
kf.sh start
kf.sh stop
各大网址:
http://hadoop102:9870
http://hadoop103:8088/
http://hadoop102:19888/jobhistory
http://hadoop102:16010/master-status
注意:
Hbase启动前先启动zookeeper再启动Hadoop
必须先关闭KafKa再关闭Zookeeper
7.0业务流程
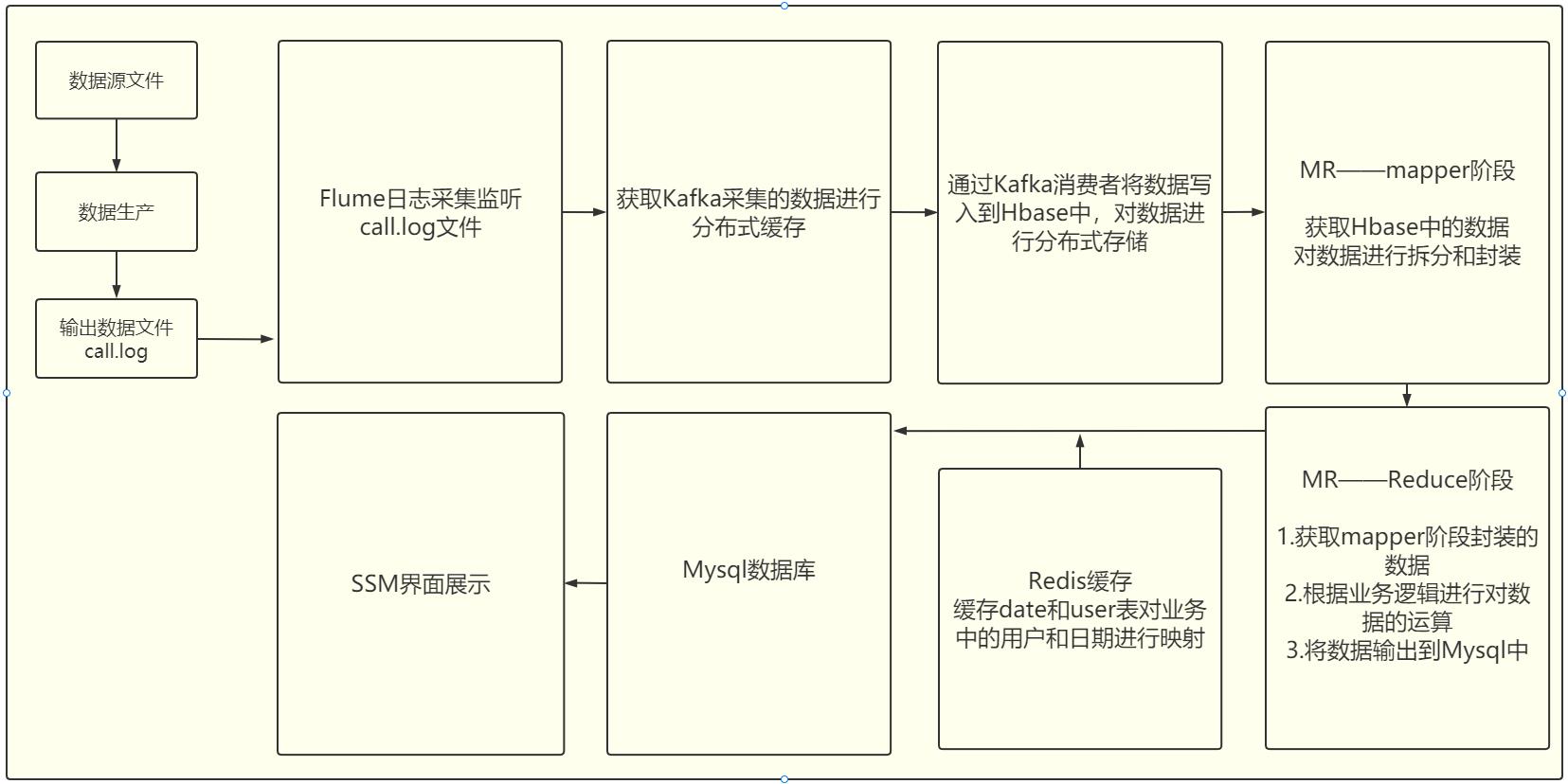
7.1 模块①—数据的生产-采集-消费(P1-P13)
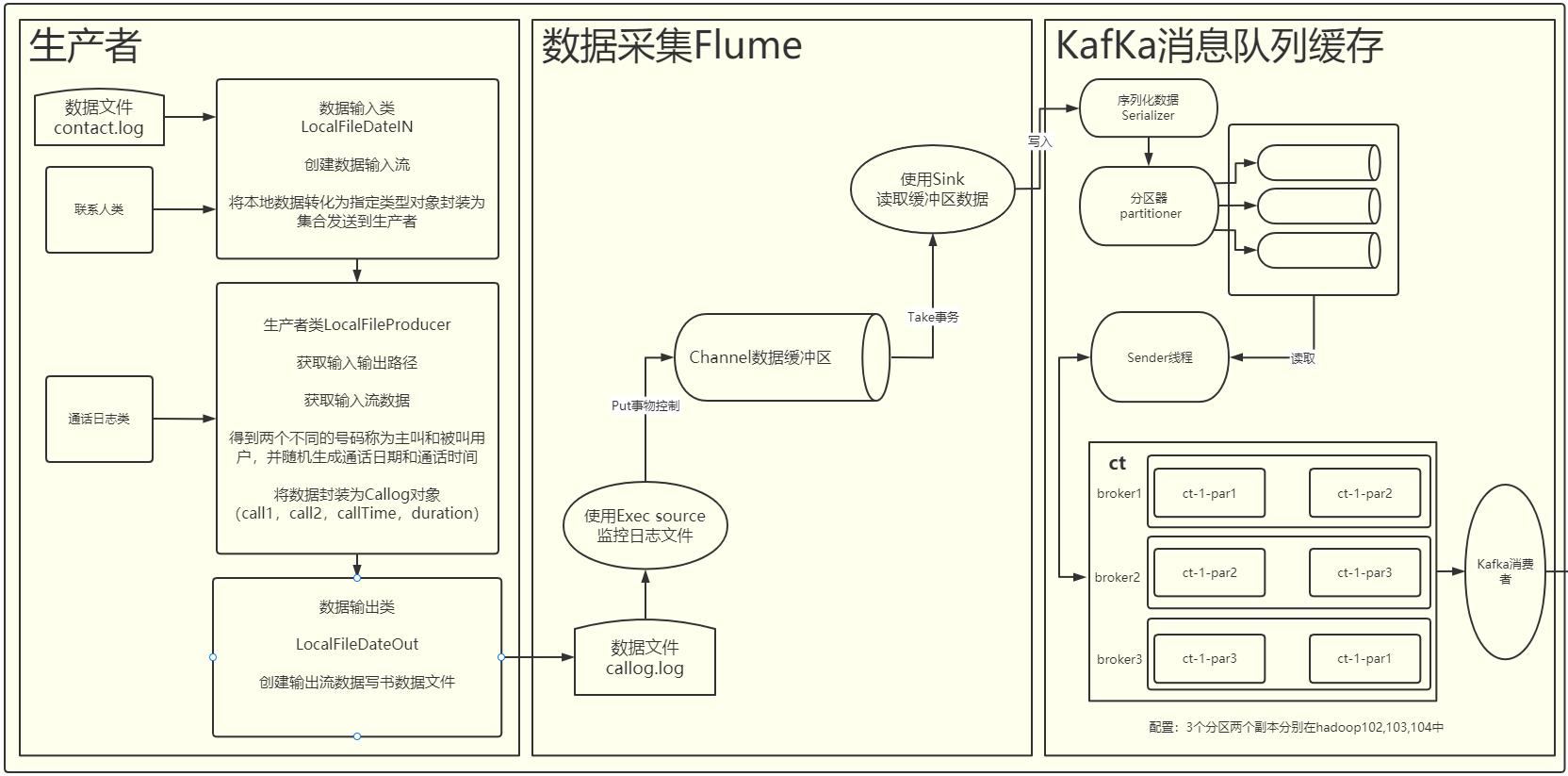
7.1.1创建生产者
P6尚硅谷_数据生产 - 创建生产者对象04:25
public class Bootstrap
public static void main(String[] args) throws IOException
if(args.length<2)
System.out.println("系统参数不正确,请按照指定格式传递");
System.exit(1);
//构建生产者对象
Producer producer=new LocalFileProducer();
// producer.setIn(new LocalFileDataIn("D:\\\\大数据学习资料\\\\尚硅谷大数据技术之电信客服综合案例\\\\2.资料\\\\辅助文档\\\\contact.log"));
// producer.setOut(new LocalFileDataOut("D:\\\\大数据学习资料\\\\尚硅谷大数据技术之电信客服综合案例\\\\2.资料\\\\辅助文档\\\\call.log"));
producer.setIn(new LocalFileDataIn(args[0]));
producer.setOut(new LocalFileDataOut(args[1]));
//生产数据
producer.producer();
//关闭生产者对象
producer.close();
P7尚硅谷_数据生产 - 获取通讯录数据33:32
创建输入流,将数据保存到集合中
public class LocalFileDataIn implements DataIn
private BufferedReader reader = null;
/**
* 构造方法
* @param path
*/
public LocalFileDataIn(String path)
setPath(path);
/**
* 设置路径
* 创建输入流
* @param path
*/
public void setPath(String path)
try
reader = new BufferedReader(new InputStreamReader(new FileInputStream(path), "UTF-8"));
catch (UnsupportedEncodingException e)
e.printStackTrace();
catch (FileNotFoundException e)
e.printStackTrace();
public Object read() throws IOException
return null;
/**
* 读取数据,将数据返回到集合中
*
* @param <T>
* @param clazz
* @throws IOException
* @return
*/
public <T extends Data> List<T> read(Class<T> clazz) throws IOException
List<T> ts = new ArrayList<T>();
try
//从数据文件中读取所有的数据
String line = null;
while ((line = reader.readLine()) != null)
//将数据转换为指定类型的对象,封装为集合返回
T t = (T) clazz.newInstance();
t.setValue(line);
ts.add(t);
catch (Exception e)
e.printStackTrace();
return ts;
/**
* 关闭资源
* @throws IOException
*/
public void close() throws IOException
if (reader!=null)
reader.close();
P8尚硅谷_数据生产 - 随机生成主被叫电话号码12:59
从集合中获取两条数据构成主叫和被叫,并随机生成通话 日期和时间
/**
* 本地数据文件的生产者
*/
public class LocalFileProducer implements Producer
/**
* 数据来源
* @param in
*/
private DataIn in;
private DataOut out;
private volatile boolean flg=true; //增强内存可见性
public void setIn(DataIn in)
this.in=in;
/**
* 数据输出
* @param out
*/
public void setOut(DataOut out)
this.out=out;
/**
* 数据生产
*/
public void producer()
/**
* 数据返回类型为一个对象
*/
try
List<Contact> contacts=in.read(Contact.class);
//读取通讯录的数据
while ( flg )
int call1Index=new Random().nextInt(contacts.size());
int call2Index;
while (true)
call2Index=new Random().nextInt(contacts.size());
if (call1Index!=call2Index)
break;
Contact call1=contacts.get(call1Index);
Contact call2=contacts.get(call2Index);
//生成随机的通话时间
String startDate="20180101000000"; //开始时间
String endDate="20190101000000"; //结束时间
long startTime= DataUtil.parse(startDate,"yyyyMMddHHmmss").getTime();
//通话时间
long endtime=DataUtil.parse(endDate,"yyyyMMddHHmmss").getTime();
//通话时间字符串
long calltime=startTime+(long)((endtime-startTime)* Math.random());
//通话时间字符串
String callTimeString=DataUtil.format(new Date(calltime),"yyyyMMddHHmmss");
//生成随机的通话时长
String duration= NumberUtil.format(new Random().nextInt(3000),4);
//生成通话记录
Callog log=new Callog(call1.getTel(),call2.getTel(),callTimeString,duration);
System.out.println(log);
//将通话记录写入到数据文件中
out.write(log);
Thread.sleep(500);
catch (Exception e)
e.printStackTrace();
/**
* 关闭生产者
* @throws IOException
*/
public void close() throws IOException
if (in!=null)
in.close();
if (out!=null)
out.close();
P9尚硅谷_数据生产 - 构建通话记录25:40
将数据封装为对象输出到通话日志中
/**
* 本地文件数据输出
*/
public class LocalFileDataOut implements DataOut
private PrintWriter writer=null;
public LocalFileDataOut(String path)
setPath(path);
/**
* 设置路径
* @param path
*/
public void setPath(String path)
try
writer=new PrintWriter(new OutputStreamWriter(new FileOutputStream(path),"UTF-8"));
catch (UnsupportedEncodingException e)
e.printStackTrace();
catch (FileNotFoundException e)
e.printStackTrace();
public void write(Object data) throws Exception
write(data.toString());
/**
* 将数据字符串生成到文件中
* @param data
* @throws Exception
*/
public void write(String data) throws Exception
writer.println(data);
writer.flush();
/**
* 释放资源
* @throws IOException
*/
public void close() throws IOException
if(writer!=null)
writer.close();
public class Callog
private String call1;
private String call2;
private String calltime;
private String duration;
public Callog(String call1, String call2, String calltime, String duration)
this.call1 = call1;
this.call2 = call2;
this.calltime = calltime;
this.duration = duration;
@Override
public String toString()
return call1+"\\t"+call2+"\\t"+calltime+"\\t"+duration;
public String getCall1()
return call1;
public void setCall1(String call1)
this.call1 = call1;
public String getCall2()
return call2;
public void setCall2(String call2)
this.call2 = call2;
public String getCalltime()
return calltime;
public void setCalltime(String calltime)
this.calltime = calltime;
public String getDuration()
return duration;
public void setDuration(String duration)
this.duration = duration;
7.1.3数据采集和消费
配置Flume的配置文件监听日志信息和Kafka输出存储区
在kafka创建一个ct的数据存储区开启kafka获取到数据
到指定目录下配置flume
[fang@hadoop102 kafka]$ cd /opt/module/data/
[fang@hadoop102 data]$ vim flume-2-kafka.conf
# define
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F -c +0 /opt/module/data/call.log
a1.sources.r1.shell = /bin/bash -c
# sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sinks.k1.kafka.topic = ct
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
# channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动jar包:
[fang@hadoop102 data]$ java -jar ct_producer.jar contact.log call.log
在kafka目录下创建topic:
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --topic ct --partitions 3 --replication-factor 2
kafka开始消费
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 -topic ct
启动flume对数据进行采集:
bin/flume-ng agent -c conf/ -n a1 -f /opt/module/data/flume-2-kafka.conf
使用Kafka消费者API获取数据,并将数据发送到Hbase中
/**
* 启动Kafka消费者
*
*/
//使用kafka消费者获取Flume采集数据
//将数据存储到HBase中
public class Bootstrap
public static void main(String[] args) throws IOException
//创建消费者
Consumer consumer=new CallogConsumer();
//消费数据
consumer.consume();
//关闭资源
consumer.close();
/**
* 通话日志消费者
*/
public class CallogConsumer implements Consumer
/**
* 消费数据
*/
public void consume()
try
//创建配置对象
Properties prop =new Properties();
prop.load(Thread.currentThread().getContextClassLoader().getResourceAsStream("consumer.properties"));
//获取flume采集的数据
KafkaConsumer<String,String> consumer=new KafkaConsumer<String, String>(prop);
//关注主题
consumer.subscribe(Arrays.asList(Names.TOPIC.getValue()));
//HBase数据访问对象
HBaseDao dao=new HBaseDao();
dao.init();//初始化HBase
//消费数据
while (true)
ConsumerRecords<String, String> consumerRecords = consumer.poll(100);
for (ConsumerRecord<String, String> consumerRecord : consumerRecords)
System.out.println(consumerRecord.value());
dao.insertData(consumerRecord.value());//将数据插入HBase中
//Callog log=new Callog(consumerRecord.value());
//dao.insertData(log);
catch (IOException e)
e.printStackTrace();
catch (Exception e)
e.printStackTrace();
/**
* 关闭资源
* @throws IOException
*/
public void close() throws IOException
7.2 模块②—HBase数据消费(P14-P22)
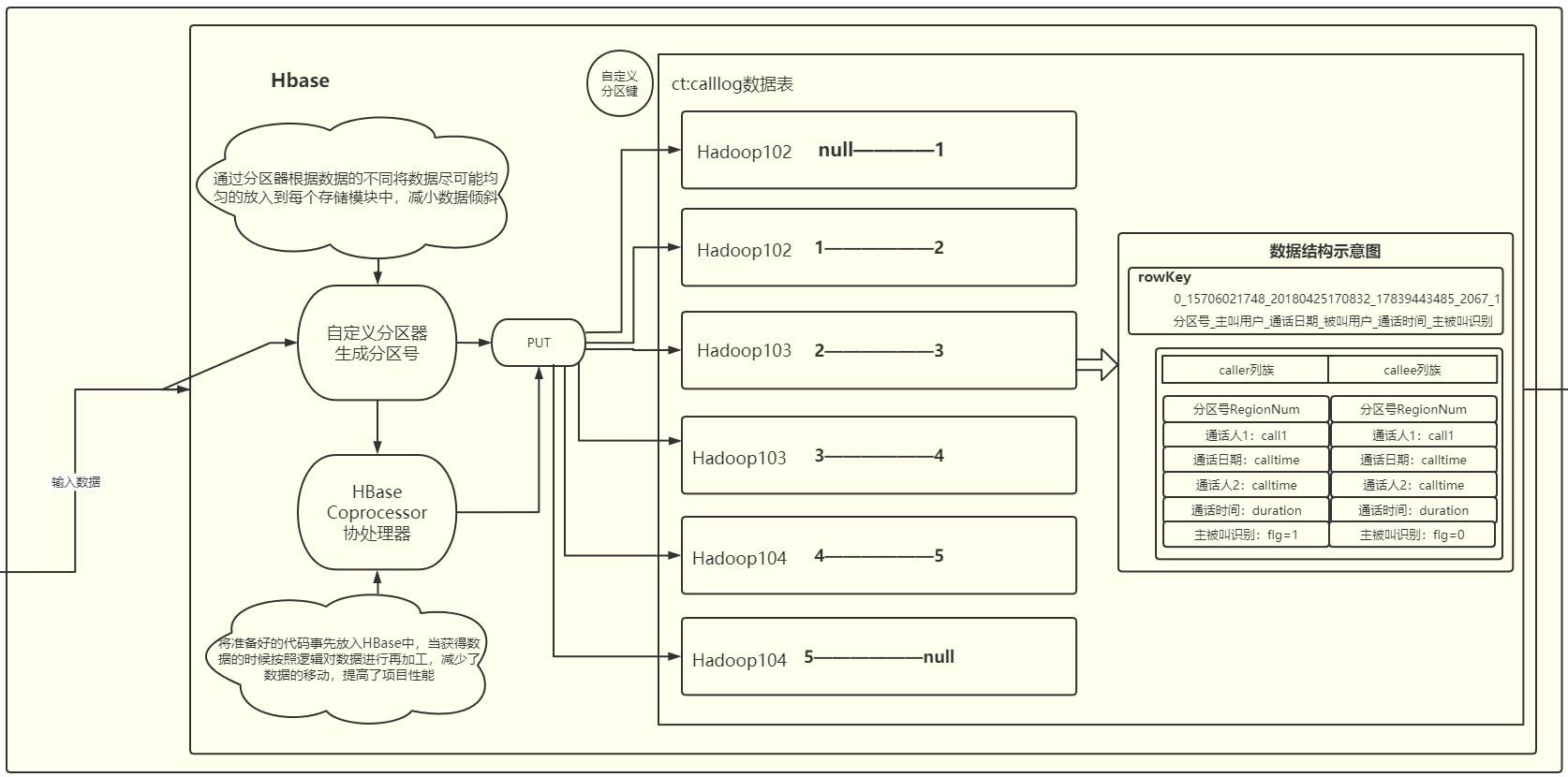
7.2.1建表
P14尚硅谷__数据消费 - Hbase数据访问封装32:21
在Hbase中创建对应的表格,设置两个列族和rowkey
/**
* HBase的数据访问对象
*/
public class HBaseDao extends BaseDao
/**
* 初始化
*/
public void init() throws Exception
start();
//创建命名空间ct
createNamespaseNX(Names.NAMESPACE.getValue());
//创建表名ct:calllog 分区数为6
createTableXX(Names.TABLE.getValue(),"com.fang.ct.consumer.coprocessor.InsertCalleeCoprocessor", 6,Names.CF_CALLER.getValue(),Names.CF_CALLEE.getValue());
end();
/**
* 插入对象
* @param log
* @throws Exception
*/
public void insertData(Callog log) throws Exception
log.setRowkey(genRegionNum(log.getCall1(),log.getCalltime())+"_"+log.getCall1()+"_"+log.getCalltime()+"_"+log.getCall2()+"_"+log.getDuration());
putData(log);
/**
* 插入数据
*/
public void insertData(String value) throws Exception
//将通话日志保存到Hbase的表中
//1.获取通话日志数据
String[] values= value.split("\\t");
String call1=values[0];
String call2=values[1];
String calltime=values[2];
String duration=values[3];
//2.创建数据对象
//rowkey设计
//主叫用户
String rowkey=genRegionNum(call1,calltime)+"_"+call1+"_"+calltime+"_"+call2+"_"+duration+ "_1";
Put put =new Put(Bytes.toBytes(rowkey));
byte[] family=Bytes.toBytes(Names.CF_CALLER.getValue());
put.addColumn(family,Bytes.toBytes("call1"),Bytes.toBytes(call1));
put.addColumn(family,Bytes.toBytes("call2"),Bytes.toBytes(call2));
put.addColumn(family,Bytes.toBytes("calltime"),Bytes.toBytes(calltime));
put.addColumn(family,Bytes.toBytes("duration"),Bytes.toBytes(duration));
put.addColumn(family, Bytes.toBytes("flg"), Bytes.toBytes("1"));
String calleeRowkey = genRegionNum(call2, calltime) + "_" + call2 + "_" + calltime + "_" + call1 + "_" + duration + "_0";
// // 被叫用户
// Put calleePut = new Put(Bytes.toBytes(calleeRowkey));
// byte[] calleeFamily = Bytes.toBytes(Names.CF_CALLEE.getValue());
// calleePut.addColumn(calleeFamily, Bytes.toBytes("call1"), Bytes.toBytes(call2));
// calleePut.addColumn(calleeFamily, Bytes.toBytes("call2"), Bytes.toBytes(call1));
// calleePut.addColumn(calleeFamily, Bytes.toBytes("calltime"), Bytes.toBytes(calltime));
// calleePut.addColumn(calleeFamily, Bytes.toBytes("duration"), Bytes.toBytes(duration));
// calleePut.addColumn(calleeFamily, Bytes.toBytes("flg"), Bytes.toBytes("0"));
// 3. 保存数据
List<Put> puts = new ArrayList<Put>();
puts.add(put);
// puts.add(calleePut);
putData(Names.TABLE.getValue(), puts);
获取连接对象,设置表的相关方法,生成分区键,分区号,数据的插入,删除等
/**
* 基础的数据访问对象
*/
public abstract class BaseDao
/**
*
*/
private ThreadLocal<Connection> connHolder=new ThreadLocal<Connection>();
private ThreadLocal<Admin> adminHolder=new ThreadLocal<Admin>();
protected void start() throws Exception
getConnection();
getAdmin();
protected void end() throws Exception
Admin admin=getAdmin();
if (admin!=null)
admin.close();
adminHolder.remove();
Connection conn=getConnection();
if (conn!=null)
conn.close();;
connHolder.remove();
/**
* 创建表,如果表已经存在,name删除后创建新的
* @param name
* @param family
* @throws IOException
*/
protected void createTableXX(String name,String... family) throws Exception
createTableXX(name,null,null,family);
protected void createTableXX(String name,String coprocessorClass,Integer regionCount,String... family) throws Exception
Admin admin=getAdmin();
TableName tableName= TableName.valueOf(name);
if (admin.tableExists(tableName))
//表存在,删除表
deleteTable(name);
//创建表
createTable(name,coprocessorClass,regionCount,family);
private void createTable(String name,String coprocessorClass,Integer regionCount,String... family) throws Exception
Admin admin=getAdmin();
TableName tablename=TableName.valueOf(name);
HTableDescriptor tableDescriptor=new HTableDescriptor(tablename);
if (family==null||family.length==0)
family=new String[1];
family[0]= Names.CF_INFO.getValue();
for (String families : family)
HColumnDescriptor columnDescriptor=
new HColumnDescriptor(families);
tableDescriptor.addFamily(columnDescriptor);
if(coprocessorClass!=null&& !"".equals(coprocessorClass))
tableDescriptor.addCoprocessor(coprocessorClass);
//增加预分区
if(regionCount==null||regionCount<=0)
admin.createTable(tableDescriptor);
else
//分区键
byte[][] splitKeys=genSpliKeys(regionCount);
admin.createTable(tableDescriptor,splitKeys);
/**
* 获取查询时startrow,stoprom集合
* @return
*/
protected List<String[]> getStartStorRowkeys(String tel,String start,String end)
List<String[]> rowkeyss=new ArrayList<String[]>();
String startTime = start.substring(0, 6);
String endTime = end.substring(0, 6);
Calendar startCal = Calendar.getInstance();
startCal.setTime(DataUtil.parse(startTime, "yyyyMM"));
Calendar endCal = Calendar.getInstance();
endCal.setTime(DataUtil.parse(endTime, "yyyyMM"));
while (startCal.getTimeInMillis() <= endCal.getTimeInMillis())
// 当前时间
String nowTime = DataUtil.format(startCal.getTime(), "yyyyMM");
int regionNum = genRegionNum(tel, nowTime);
String startRow = regionNum + "_" + tel + "_" + nowTime;
String stopRow = startRow + "|";
String[] rowkeys = startRow, stopRow;
rowkeyss.add(rowkeys);
// 月份+1
startCal.add(Calendar.MONTH, 1);
return rowkeyss;
/**
* 计算分区号
* @param tel
* @param date
* @return
*/
protected int genRegionNum(String tel,String date)
String usercode=tel.substring(tel.length()-4);
String yearMonth=date.substring(0,6);
int userCodehash=usercode.hashCode();
int yearMonthHash=yearMonth.hashCode();
//crc校验采用异或算法
int crc=Math.abs(userCodehash ^ yearMonthHash);
//取模
int regionNum=crc% ValueConstant.REGION_COUNT;
return regionNum;
/**
* 生成分区键
* @return
*/
private byte[][] genSpliKeys(int regionCount)
int splitkeyCount=regionCount-1;
byte[][] bs=new byte[splitkeyCount][];
//0,1,2,3,4
List<byte[]> bsList=new ArrayList<byte[]>();
for (int i = 0; i < splitkeyCount; i++)
String splitkey=i+"|";
bsList.add(Bytes.toBytes(splitkey));
//Collections.sort(bsList,new Bytes.ByteArrayComparator());
bsList.toArray(bs);
return bs;
/**
* 增加对象:自动封装数据,将对象数据直接保存到Hbase中
* @param obj
* @throws Exception
*/
protected void putData(Object obj) throws Exception
// 反射
Class clazz = obj.getClass();
TableRef tableRef = (TableRef)clazz.getAnnotation(TableRef.class);
String tableName = tableRef.value();
Field[] fs = clazz.getDeclaredFields();
String stringRowkey = "";
for (Field f : fs)
Rowkey rowkey = f.getAnnotation(Rowkey.class);
if ( rowkey != null )
f.setAccessible(true);
stringRowkey = (String)f.get(obj);
break;
//获取表对象
Connection connection=getConnection();
Table table = connection.getTable(TableName.valueOf(tableName));
Put put=new Put(Bytes.toBytes(stringRowkey));
for (Field f : fs)
Column column = f.getAnnotation(Column.class);
if (column != null)
String family = column.family();
String colName = column.column();
if (colName == null || "".equals(colName))
colName = f.getName();
f.setAccessible(true);
String value = (String) f.get(obj);
put.addColumn(Bytes.toBytes(family), Bytes.toBytes(colName), Bytes.toBytes(value));
//增加数据
table.put(put);
//关闭表
table.close();
/**
* 增加多条数据
* @param name
* @param puts
* @throws IOException
*/
protected void putData( String name, List<Put> puts ) throws Exception
// 获取表对象
Connection conn = getConnection();
Table table = conn.getTable(TableName.valueOf(name));
// 增加数据
table.put(puts);
// 关闭表
table.close();
/**
* 增加数据
* @param name
* @param put
*/
protected void putData(String name, Put put) throws IOException
//获取表对象
Connection connection=getConnection();
Table table = connection.getTable(TableName.valueOf(name));
//增加数据
table.put(put);
//关闭表
table.close();
/**
* 删除表格
* @param name
* @throws Exception
*/
protected void deleteTable(String name) throws Exception
TableName tableName=TableName.valueOf(name);
Admin admin=getAdmin();
admin.disableTable(tableName);
admin.deleteTable(tableName);
/**
* 创建命名空间,如果命名空间已经存在,不需要创建,否则创建新的
* @param namespace
*/
protected void createNamespaseNX(String namespace) throws IOException
Admin admin =getAdmin();
try
admin.getNamespaceDescriptor(namespace);
catch (NamespaceNotFoundException e)
admin.createNamespace(NamespaceDescriptor.create(namespace).build());
/**
* 获取管理对象
*/
protected synchronized Admin getAdmin() throws IOException
Admin admin = adminHolder.get();
if(admin==null)
admin=getConnection().getAdmin();
adminHolder.set(admin);
return admin;
/**
* 获取连接对象
* @return
*/
protected synchronized Connection getConnection() throws IOException
Connection conn=connHolder.get();
if(conn==null)
Configuration conf= HBaseConfiguration.create();
conn= ConnectionFactory.createConnection(conf);
connHolder.set(conn);
return conn;
7.2.4配置协处理器
用于区分主叫和被叫,减少数据的插入量
/**
*
* 使用协处理器保存被叫用户的数据
*
* 协处理器的使用
* 1. 创建类
* 2. 让表找到协处理类(和表有关联)
* 3. 将项目打成jar包发布到hbase中(关联的jar包也需要发布),并且需要分发
*/
public class InsertCalleeCoprocessor extends BaseRegionObserver
// 方法的命名规则
// login
// logout
// prePut
// doPut :模板方法设计模式
// 存在父子类:
// 父类搭建算法的骨架
// 1. tel取用户代码,2时间取年月,3,异或运算,4 hash散列
// 子类重写算法的细节
// do1. tel取后4位,do2,201810, do3 ^, 4, % &
// postPut
/**
* 保存主叫用户数据之后,由Hbase自动保存被叫用户数据
* @param e
* @param put
* @param edit
* @param durability
* @throws IOException
*/
@Override
public void postPut(ObserverContext<RegionCoprocessorEnvironment> e, Put put, WALEdit edit, Durability durability) throws IOException
// 获取表
Table table = e.getEnvironment().getTable(TableName.valueOf(Names.TABLE.getValue()));
// 主叫用户的rowkey
String rowkey = Bytes.toString(put.getRow());
// 1_133_2019_144_1010_1
String[] values = rowkey.split("_");
CoprocessorDao dao = new CoprocessorDao();
String call1 = values[1];
String call2 = values[3];
String calltime = values[2];
String duration = values[4];
String flg = values[5];
if ( "1".equals(flg) )
// 只有主叫用户保存后才需要触发被叫用户的保存
String calleeRowkey = dao.getRegionNum(call2, calltime) + "_" + call2 + "_" + calltime + "_" + call1 + "_" + duration + "_0";
// 保存数据
Put calleePut = new Put(Bytes.toBytes(calleeRowkey));
byte[] calleeFamily = Bytes.toBytes(Names.CF_CALLEE.getValue());
calleePut.addColumn(calleeFamily, Bytes.toBytes("call1"), Bytes.toBytes(call2));
calleePut.addColumn(calleeFamily, Bytes.toBytes("call2"), Bytes.toBytes(call1));
calleePut.addColumn(calleeFamily, Bytes.toBytes("calltime"), Bytes.toBytes(calltime));
calleePut.addColumn(calleeFamily, Bytes.toBytes("duration"), Bytes.toBytes(duration));
calleePut.addColumn(calleeFamily, Bytes.toBytes("flg"), Bytes.toBytes("0"));
table.put( calleePut );
// 关闭表
table.close();
private class CoprocessorDao extends BaseDao
public int getRegionNum(String tel, String time)
return genRegionNum(tel, time);
7.3 模块③—导出数据及运算(P23-P29)
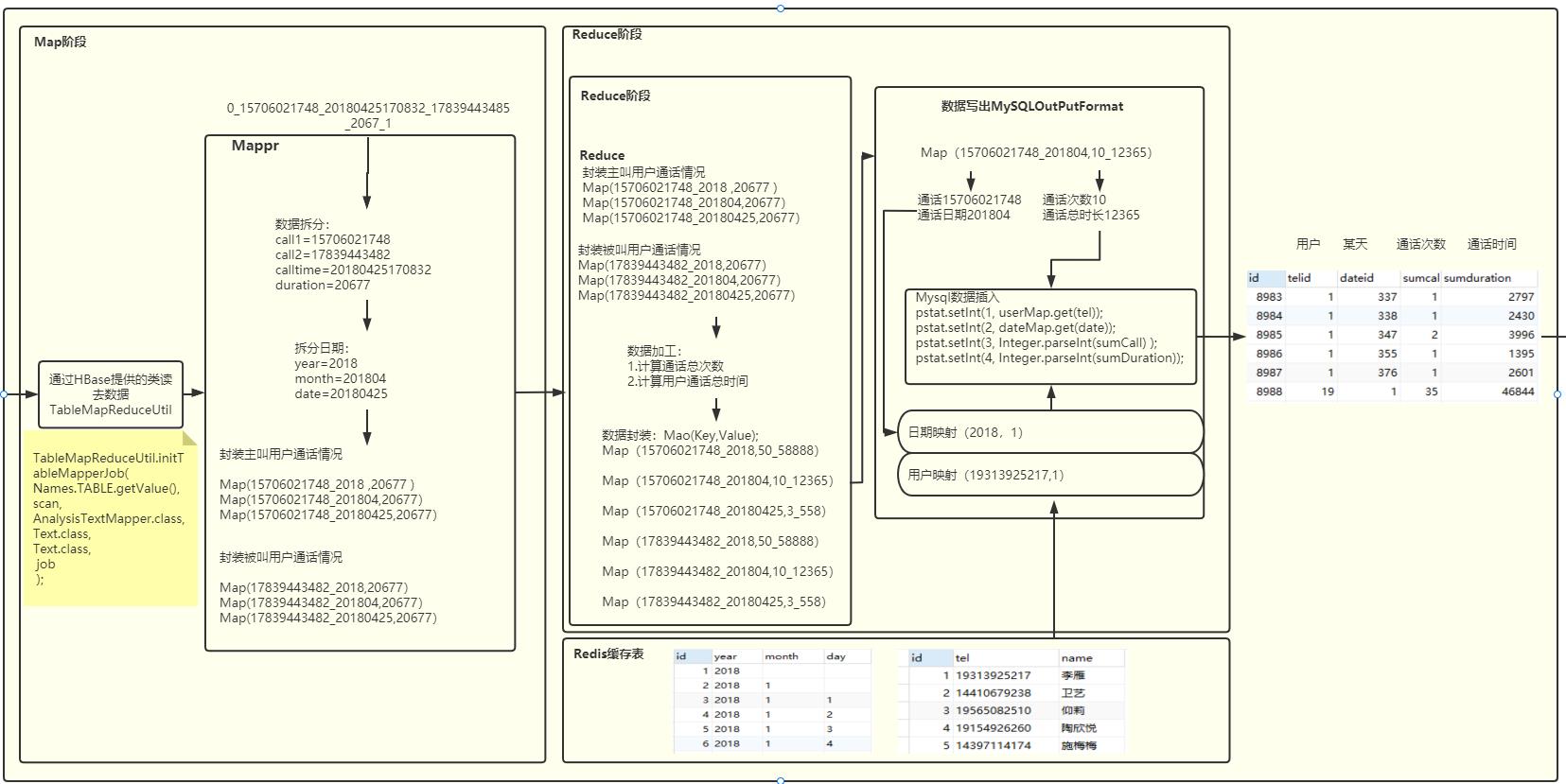
7.3.1数据库表设计
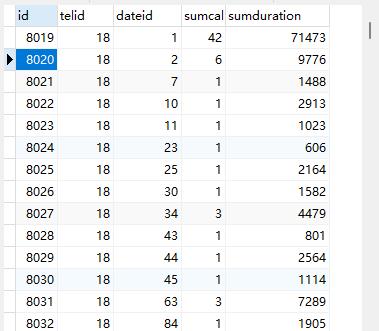
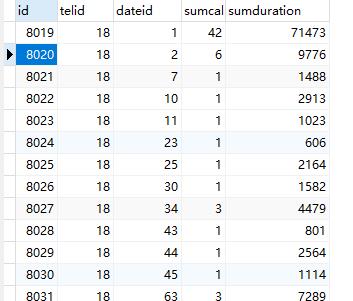
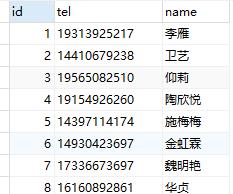
7.3.2数据计算
用于map和reduce,通过对应的方法获取Hbase的数据
/**
* 分析数据工具类
*/
public class AnalysisTextTool implements Tool
public int run(String[] args) throws Exception
Job job = Job.getInstance();
job.setJarByClass(AnalysisTextTool.class);
//从Hbase中读去数据
Scan scan = new Scan();
scan.addFamily(Bytes.toBytes(Names.CF_CALLER.getValue()));
// mapper
TableMapReduceUtil.initTableMapperJob(
Names.TABLE.getValue(),
scan,
AnalysisTextMapper.class,
Text.class,
Text.class,
job
);
// reducer
job.setReducerClass(AnalysisTextReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setOutputFormatClass(mysqlRedisTextOutputFormat.class);
boolean flg = job.waitForCompletion(true);
if ( flg )
return JobStatus.State.SUCCEEDED.getValue();
else
return JobStatus.State.FAILED.getValue();
public void setConf(Configuration configuration)
public Configuration getConf()
return null;
将从Hbase中获取到的数据进行拆封,封装为集合
/**
* maper
*/
public class AnalysisTextMapper extends TableMapper<Text, Text>
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException
String rowkey = Bytes.toString(key.get());
String[] values = rowkey.split("_");
String call1 = values[1];
String call2 = values[3];
String calltime = values[2];
String duration = values[4];
String year = calltime.substring(0, 4);
String month = calltime.substring(0, 6);
String date= calltime.substring(0, 8);
// 主叫用户 - 年
context.write(new Text(call1+"_"+year), new Text(duration));
// 主叫用户 - 月
context.write(new Text(call1+"_"+month), new Text(duration));
// 主叫用户 - 日
context.write(new Text(call1+"_"+date), new Text(duration));
// 被叫用户 - 年
context.write(new Text(call2+"_"+year), new Text(duration));
// 被叫用户 - 月
context.write(new Text(call2+"_"+month), new Text(duration));
// 被叫用户 - 日
context.write(new Text(call2+"_"+date), new Text(duration));
获取到Mapper的数据对数据进行对应的运算
/**
* 分析数据的Reducer
*/
public class AnalysisTextReducer extends Reducer<Text,Text,Text,Text>
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException
int sumCall = 0;
int sumDuration = 0;
for (Text value : values)
int duration = Integer.parseInt(value.toString());
sumDuration = sumDuration + duration;
sumCall++;
context.write(key, new Text(sumCall + "_" + sumDuration));
将数据上传到Mysql,并通过Redis对数据表进行缓存
/**
* Mysql的数据格式化输出对象
*/
public class MySQLTextOutputFormat extends OutputFormat<Text, Text>
protected static class MySQLRecordWriter extends RecordWriter<Text,Text>
private Connection connection =null;
private Map<String,Integer> userMap=new HashMap<String, Integer>();
Map<String, Integer> dateMap = new HashMap<String, Integer>();
public MySQLRecordWriter()
// 获取资源
connection = JDBCUtil.getConnection();
PreparedStatement pstat = null;
ResultSet rs = null;
try
String queryUserSql = "select id, tel from ct_user";
pstat = connection.prepareStatement(queryUserSql);
rs = pstat.executeQuery();
while ( rs.next() )
Integer id = rs.getInt(1);
String tel = rs.getString(2);
userMap.put(tel, id);
rs.close();
String queryDateSql = "select id, year, month, day from ct_date";//将整张表中的数据查出
pstat = connection.prepareStatement(queryDateSql);
rs = pstat.executeQuery();
while ( rs.next() )
Integer id = rs.getInt(1);
String year = rs.getString(2);
String month = rs.getString(3);
if ( month.length() == 1)
month = "0" + month;
String day = rs.getString(4);
if ( day.length() == 1 )
day = "0" + day;
以上是关于电信客服项目笔记的主要内容,如果未能解决你的问题,请参考以下文章