机器学习之pandas基础——pandas与概率论的简短碰面
Posted 肥猪猪爸
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习之pandas基础——pandas与概率论的简短碰面相关的知识,希望对你有一定的参考价值。
活动地址:CSDN21天学习挑战赛
概率论和机器学习
概率论是研究随机现象数量规律的数学分支,是一门研究事情发生的可能性的学问。机器学习中随处可见概率论的影子,最典型的当属最大似然估计,它的基本思想就是:存在即合理,最大似然估计通过使当前数据的概率最大来估计目标函数参数。再比如贝叶斯估计、隐马尔可夫模型、皮尔逊相关系数等等等等。
本文借助pandas的介绍,来简单说明一下pandas中与概率论相关的概念。
pandas数据结构简介
Series 结构,也称 Series 序列,是 Pandas 常用的数据结构之一,它是一种类似于一维数组的结构,由一组数据值(value)和一组标签组成,其中标签与数据值之间是一一对应的关系,其结构图如下所示:

DataFrame 一个表格型的数据结构,既有行标签(index),又有列标签(columns),它也被称异构数据表,所谓异构,指的是表格中每列的数据类型可以不同,比如可以是字符串、整型或者浮点型等。其结构图下所示:
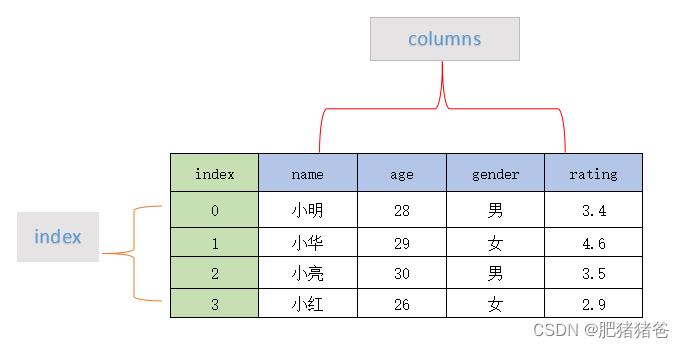
DataFrame 的每一行数据都可以看成一个 Series 结构,只不过,DataFrame 为这些行中每个数据值增加了一个列标签。因此 DataFrame 其实是从 Series 的基础上演变而来。在数据分析任务中 DataFrame 的应用非常广泛,因为它描述数据的更为清晰、直观。
相关性
1.协方差(cov)
协方差是对随机变量X与Y之间联动关系的一种测度,即测量X与Y的同步性。当X与Y同时出现较大值或者较小值时,COV>0, 二者正相关。若X出现较大值时Y出现较小值,COV<0,二者负相关。该相关关系并不意味着因果关系。
import pandas as pd
import numpy as np
frame = pd.DataFrame(np.random.randn(10, 5), columns=['a', 'b', 'c', 'd', 'e'])
# 计算a与b之间的协方差值
print (frame['a'].cov(frame['b']))
# 计算所有数列的协方差值
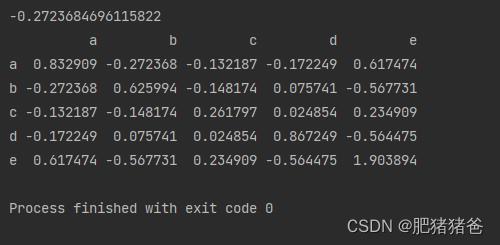
print(frame.cov())输出结果:
2.相关系数(corr)
相关系数与协方差类似,但它只反映线性相关性。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(10, 5), columns=['a', 'b', 'c', 'd', 'e'])
# 计算a与b之间的相关系数
print(df['a'].corr(df['b']))
# 计算所有数列的相关系数
print(df.corr())输出结果:

随机抽样与重采样
随机抽样,是统计学中常用的一种方法,它可以帮助我们从大量的数据中快速地构建出一组数据分析模型。
import pandas as pd
data = 'name': ["Jack", "Tom", "Helen", "John"], 'age': [28, 39, 34, 36], 'score': [98, 92, 91, 89]
info = pd.DataFrame(data)
# 默认随机选择三行
print(info.sample(n=3))
print("******************************")
# 随机选择两列
print(info.sample(n=2, axis=1))输出结果: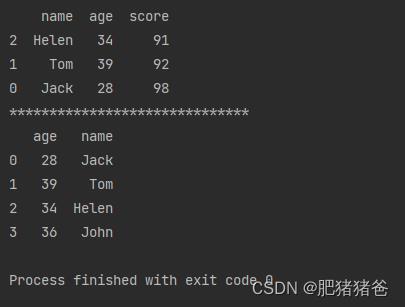
重采样
数据重采样是将时间序列从一个频率转换至另一个频率的过程,它主要有两种实现方式,分别是降采样和升采样,降采样指将高频率的数据转换为低频率,升采样则与其恰好相反。
1.降采样
比如按天计数的频率转换为按月计数。
import pandas as pd
import numpy as np
rng = pd.date_range('1/1/2021', periods=100, freq='D')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
# 降采样后并聚合
print(ts.resample('M').mean())输出结果: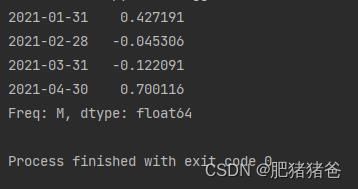
2.升采样
升采样是将低频率(时间间隔)转换为高频率。
import pandas as pd
import numpy as np
# 生成一份时间序列数据
rng = pd.date_range('1/1/2021', periods=20, freq='3D')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
print('升采样前:')
print(ts.head())
# 使用asfreq()在原数据基础上实现频率转换
print('升采样后:')
print(ts.resample('D').asfreq().head())输出结果: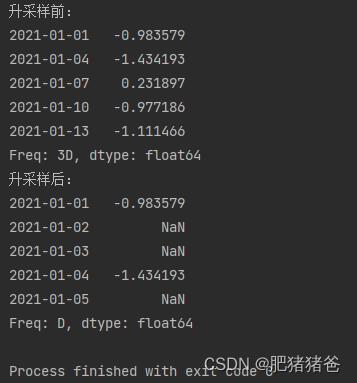
3.频率转换
asfreq() 方法不仅能够实现频率转换,还可以保留原频率对应的数值,同时它也可以单独使用
import pandas as pd
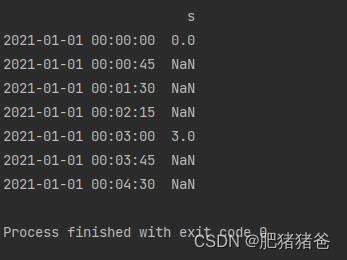
index = pd.date_range('1/1/2021', periods=6, freq='T')
series = pd.Series([0.0, None, 2.0, 3.0, 4.0, 5.0], index=index)
df = pd.DataFrame('s': series)
print(df.asfreq("45s"))输出结果:
4.插值处理
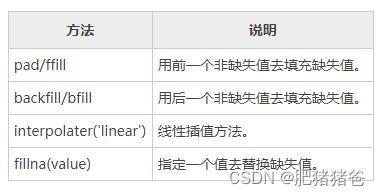
从上述示例不难看出,升采样的结果会产生缺失值,那么就需要对缺失值进行处理,一般有以下几种处理方式:
以上代码中,数据是随机生成的,所以每次执行结果可能会不同!
作者这水平有限,有不足之处欢迎留言指正
以上是关于机器学习之pandas基础——pandas与概率论的简短碰面的主要内容,如果未能解决你的问题,请参考以下文章